
一种基于NeuMF的推荐多样性提升方法
2021-02-25 07:48刘浩翰曲昕彤贺怀清
计算机应用与软件 2021年2期
刘浩翰 曲昕彤 贺怀清
(中国民航大学计算机科学与技术学院 天津 300300)
0 引 言
在过去的20年,推荐系统的发展逐渐完善,它能将可能被用户喜欢的资讯或项目推荐给用户,从而帮助用户从海量的信息中筛选出需要的特定信息[1]。伴随着用户的个性化需求越来越高,在海量信息中找到并为用户匹配到满足其个性化需求,增强其满意度的信息,成为了专家学者和广大网络用户关心的核心问题。
随着深度学习在推荐领域取得的突破性进展,在整合的多源异构数据中构建贴合用户需求的用户模型,提高推荐系统的性能和精确度,成为解决上述问题的主流解决方案。矩阵分解[2](Matrix Factorization,MF)是最受欢迎的一种协同过滤技术,它使用潜在特征向量来表示用户或项目。但MF因为使用一个简单的固定内积,在估计低维潜在空间中用户-项目的复杂交互时会造成非线性建模能力较差的限制。He等[3]针对这一问题提出了一种神经网络结构模拟用户和项目的潜在特征,设计了基于神经网络的协同过滤通用框架(Neural Collaborative Filtering,NCF),表明MF可以被解释为NCF的特例即广义矩阵分解(Generalized Matrix Factorization,GMF),并利用多层感知机(Multi-Layer Perceptron,MLP)来赋予NCF高水平的非线性建模能力,由此提出神经矩阵分解模型NeuMF。NeuMF统一了MF在建模用户-项目潜在结构方面的线性建模优势和MLP的非线性优势,并且较一般方法提高了推荐的精确度。
然而在实际的推荐环境中,精确度并不是提高用户对推荐项目满意度的唯一标准,推荐列表的多样性也是一种重要指标。多样性反映的是推荐列表中项目种类的差异性,且提供更加多样化的推荐列表不仅可以帮助用户获取新颖的项目,开拓个人偏好空间,还有助于覆盖用户的大部分兴趣点,而且盲目崇拜精确度指标可能会伤害推荐系统,降低用户的满意度。因此,如何实现将多样性融入与深度学习结合的推荐系统中,在损失较少精确度的前提下大幅提高推荐的多样性就成为了可以尝试的研究目标。
目前提高推荐多样性的方法有多种,在典型的协同过滤算法中提高多样性的方法主要有两种:在推荐算法中提高多样性以及在推荐列表上提高多样性。具体代表性方法有:Zhang等[4]首次将物质扩散理论应用在项目-项目(item-item)网络结构上,推荐方法每一步得分的传递都会除以自己的度,从而导致用户的视野汇聚在那些度较大的节点上,能极大程度地提高推荐的精确性,但在推荐列表多样性上则表现不佳。Premchaiswadi等[5]基于每个项目的总体多样性效应,提出“总体多样性效应”的重排序推荐方法。Ren等[6]结合基于用户和项目的协同过滤算法,并为其划分权重,使用不同的多样性方法生成推荐列表,最终达到提升多样性的目的。Ho等[7]提出5D分数的概念,并把推荐分为资源分配和推荐两个阶段,资源分配阶段将推荐机会重新分配给项目,为长尾项目提供机会,并为具有良好口碑的项目留一些特权。
由于推荐多样性与推荐精确度存在着此长彼消的关系,目前提出的用来解决多样性问题的方法多以牺牲精确度来提升多样性为主,尤其是推荐列表排序法会损失较多的精确度,并且没有从根本的用户与项目交互过程中学习多样性特征,只将用户或是项目的某一属性特征与推荐算法结合或是只对推荐列表进行操作。为突破以往方法的限制,本文在NeuMF框架基础上提出了NDMF模型,利用神经网络的特质,在较少损失推荐精确度的同时提高推荐多样性。
1 NeuMF框架
NeuMF框架如图1所示。

图1 NeuMF模型框架
(1)
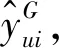
⋮
(2)
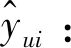
(3)
2 NDMF模型
本文在NeuMF模型保证精确度的基础上在神经网络中融合多样性特征因子,并在推荐过程的最后进行推荐列表重排序以进一步提高列表多样性。保证精确度在可接受的损失范围内提高推荐结果的多样性和用户满意度。由此形成的模型称为多样神经矩阵分解模型(Neural Diversity Matrix Factorization,NDMF)。
2.1 多样性特征因子
首先介绍两个概念。用户活跃度:表示用户产生过交互行为的项目总数;项目流行度:表示对项目产生过交互行为的用户总数。二者都符合长尾分布[8]。
2.1.1复合用户活跃度k(u)
考虑到用户的活跃度不仅体现在交互过的项目数上,也体现在用户产生交互的项目类别上,为此本文综合考虑这两个影响因素,定义复合用户活跃度如下:
k(u)=ω×k0(u)+(1-ω)×k1(u)
(4)
式中:k(u)表示用户u的复合用户活跃度,由两部分组成:一部分为用户u的活跃度,将其简单地归一化处理后记为k0(u);另一部分由kmeans聚类算法得到,记为k1(u)。项目集合通过聚类得到R个类簇,将用户u交互过的项目逐一与R个类簇对比得到r个子类簇[9],于是k1(u)表示如下:
(5)
再以阈值ω调节二者比重,以达到最理想的实验效果。kmeans聚类算法根据相似性原则将具有较高相似度的项目划分至同一类簇,并且以距离作为项目对间相似性度量的标准。本文利用项目的类别属性将项目p、q在n维空间上的特征分布表示为fp={p1,p2,…},fq={q1,q2,…}根据余弦夹角定理将项目p、q的相似性定义为:
(6)
2.1.2项目多样性推荐因子k(i)
在电商系统中,冷门(长尾)商品的销售总额比实体零售店的商品多很多,甚至会超过热门商品的销售总额,所以长尾商品的销售总额不可忽视。因此,提高推荐的多样性、丰富用户的视野,可以通过挖掘长尾商品来实现。
研究表明长尾分布用单一的函数描述不足以反映其特征,但多个函数的叠加可以达到较好的效果。文献[10]提出一种由n个底为e的指数函数线性组合(Hyper-Exponential Function,HEF)描述长尾分布函数的方法:
(7)
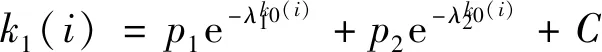
因项目流行度符合长尾分布,本文使用HEF来描述项目的长尾分布情况。将项目流行度代入式(6)后得到项目i的多样性推荐因子k1(i),为方便后续实验操作,使用函数f(x)=log(x+1)将k1(i)进行平滑处理,最后将结果归一化得到k(i)。本文将k(i)作为项目i的多样性推荐因子,并且与用户复合活跃度结合以提高推荐的多样性,应用在NDMF模型中。
2.2 模型结构
NDMF由改进后的GMF与MLP两部分组成,结构如图2所示。MLP不仅可以弥补GMF单独用向量内积描述用户与项目间的潜在交互特征带来的局限性,还提升了模型的非线性建模能力。
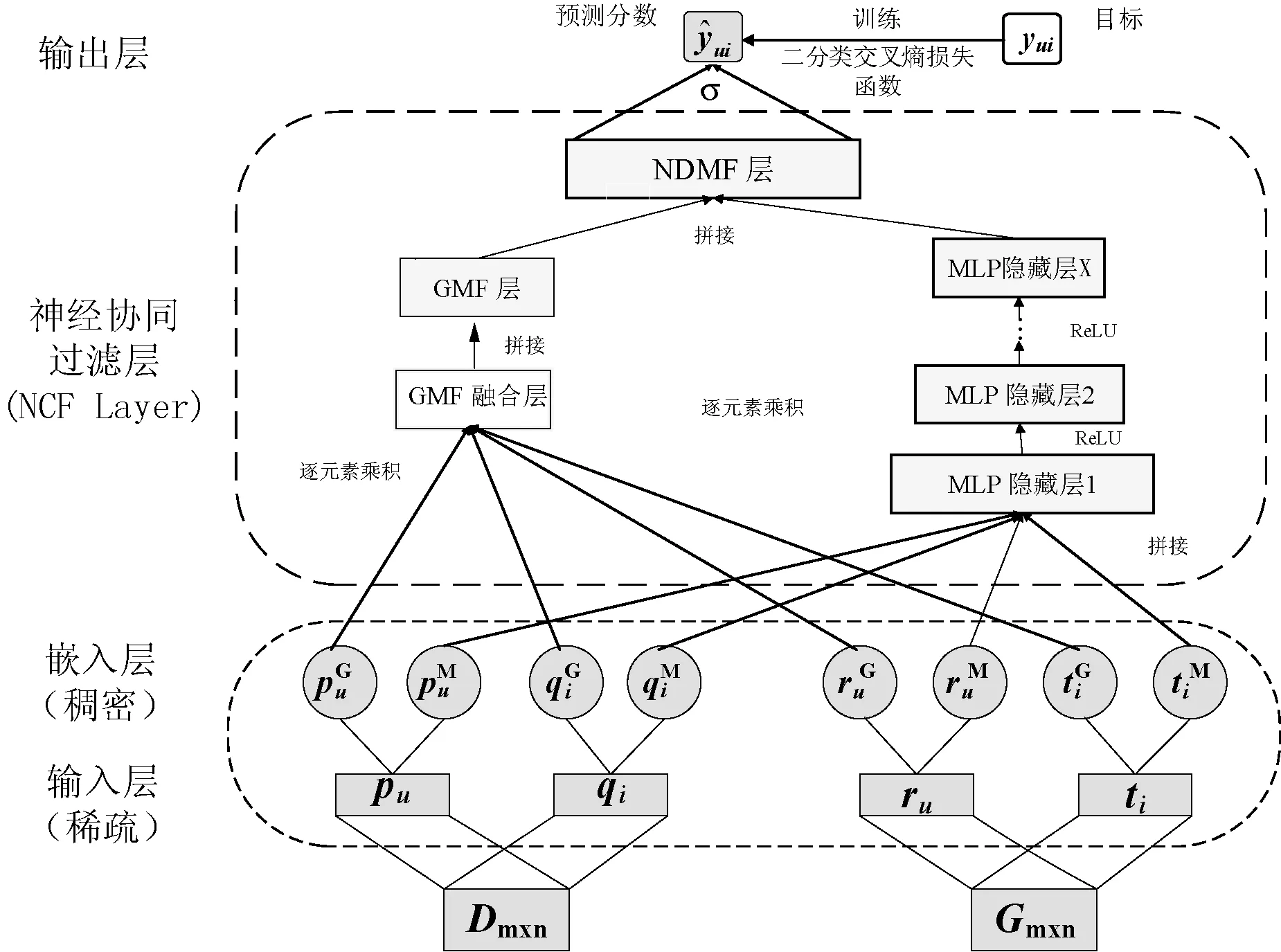
图2 NDMF模型结构图
输入层:仅使用一个用户和一个项目的特征作为输入。模型底部包括四个输入特征向量,pu和qi为用户u和项目i的交互特征向量,由用户-项目交互矩阵Dm×n得到,ru和ti为用户u的复合活跃度特征向量和项目i的多样性特征向量,由k(u)和k(i)融合的矩阵Gm×n而得。
嵌入层:它是一个全连接层,用来将输入层的四个高维稀疏特征向量映射成低维的稠密向量,为了使NDMF具有最大限度的灵活性,让GMF与MLP独立学习嵌入,并且以上角标G和M区分二者的输入。
NCF层:将嵌入层得到的嵌入向量送入各自的NCF层,在GMF部分定义NCF层的映射函数为:

(8)
式中:⊗代表向量的逐元素点乘;⊕代表将用户-项目点乘得到的交互特征向量与用户活跃度-项目长尾因子点乘得到的多样性特征向量进行拼接(concatenate)。两个特征向量融合后,交互特征与多样性特征的联合即达到提高推荐多样性的目的。在MLP部分定义NCF层结构:

(9)
式中:a、b、W分别表示激活函数、偏置向量和权重矩阵。本文中激活函数选择ReLU(Rectified Linear Unit),因为它被证明不会导致过饱和,且实验结果表明ReLU的效果较Sigmoid和双曲正切函数更好。最后将改进后的GMF与MLP进行融合得到NDMF,两部分从嵌入层开始独立学习,在最后的隐藏输出层NDMF层进行融合,方案如下:
(10)

NDMF模型使用隐式反馈[12],但yui为1并不代表用户u喜欢i,同样yui为0也不意味着用户u不喜欢i。
(11)

2.3 输入数据预处理
输入数据预处理分为两部分,采用两种自定义的one-hot编码方式得到用户-项目交互矩阵Dm×n与复合用户活跃度-项目多样性推荐因子交互矩阵Gm×n,然后根据Dm×n与Gm×n得到4个稀疏的底层输入向量。NDMF模型输入包括4个特征向量:用户特征向量,项目特征向量,复合用户活跃度特征向量,项目多样性推荐因子特征向量。
首先为了得到Dm×n,对用户和项目特征进行one-hot编码处理,即以用户数M和项目数N为横纵阶数生成矩阵,将用户与项目的交互结果(0或1)填充到矩阵中,例:若用户u对项目i有过交互则矩阵中对应位置为1,否则为0。然后为了得到Gm×n,需要将复合用户活跃度k(u)和项目多样性推荐因子k(i)进行特征结合,将k(u)和k(i)保留相同小数位后进行等倍数扩大化为整数,将k(u)化为二进制并生成m×k阶矩阵,对k(i)进行相同处理生成k×n阶矩阵,其中k为k(u)与k(i)中最大数值所需二进制化的位数。最后将得到的两个矩阵相乘得到m×n阶矩阵Gm×n,如图3所示。
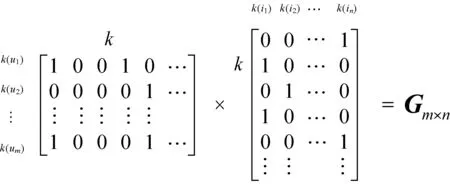
图3 复合用户活跃度矩阵与项目多样性因子矩阵
Gm×n中的每一项都结合了用户u的复合活跃度以及项目i的多样性推荐因子,因此其表征的是用户-项目对的多样性特征。多样性推荐因子本身可提高冷门项目的推荐权重,而复合用户活跃度则体现用户接受冷门项目的能力,二者相乘起到调节推荐因子所占比重的作用,即复合活跃度较高的用户相比复合活跃度低的用户更能够承受多样性推荐因子带来的冷门项目所占比重的大幅度提升。
2.4 损失函数

(12)
式(12)与二分类交叉熵损失函数[13]是相同的,原因在于我们把隐式反馈的输出当作一个二分类问题进行处理,并且使用随机梯度下降法最小化目标函数。其中y-是消极实例(负反馈),从与用户无交互的项目中进行均匀采样得到负反馈,并且可控制采样比。
2.5 候选推荐列表重排序
(13)
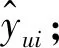
3 算法描述
本文算法步骤描述如下:
输入:Dm×n和Gm×n。
输出:评价指标HR、NDCG和ILS、损失函数loss。
Step1开始。
Step2训练特征并预测结果。
for 用户u1to 用户um
for 项目i1to 项目in

Step3候选推荐列表重排序。
for 用户u1to 用户um
利用式(13)对当前用户候选推荐列表resultui中的预测分数进行调整,进而达到对resultui中的项目分数重排序的目的。
Step4利用resultui计算并输出三个评估指标HR、NDCG和ILS,并代入式(12)计算损失值loss。
Step5结束。
4 实 验
4.1 实验数据集
本文实验数据集使用MovieLens和 Pinterest两个数据集:
(1) MovieLens显式反馈数据集。该数据集广泛应用于评估协同过滤算法,虽然它是显式反馈数据集,但我们要从显式反馈中学习隐式信息。为此,将其转换为隐式数据,其中每条数据被标记为0或1表示用户是否对该项进行评级。
(2) Pinterest隐式反馈数据集。该数据集用于评估基于内容的图像推荐算法,类似于朋友圈点赞,原始数据庞大且稀疏。例如,超过20%的用户只点赞过一次,难以用来评估协同过滤算法。因此,过滤数据集,仅保留赞过20次以上的用户。处理后得到了包含55 187个用户和1 445 621个项目交互的数据的子集。两数据集数据数量如表1所示。

表1 数据集
4.2 评价方案
本文采用了与NeuMF相同的评估方法——留一法[15](leave-one-out):对于每个用户,使用其最近的一次交互作为测试集,并将其余数据作为训练集。由于在评估过程中为每个用户排列所有项目花费的时间太多,所以随机抽取100个与用户没有过交互的项目,将测试项目排列在这100个项目中。
为了衡量推荐结果的精确度与多样性,本文采用命中率(Hit Radio,HR)、折损累计增益(Normalized Discounted Cumulative Gain,NDCG)和列表内部多样性(Intra-list Similarity,ILS)进行评估。HR衡量测试项目是否存在于TopN列表中;NDCG用来衡量测试项目在TopN列表中的位置,位置越靠前则增益越高,精确度越高;ILS针对单个用户的推荐列表,通过计算项目之间的相似度进而衡量列表的多样性,推荐列表中项目越不相似,ILS越小,推荐结果的多样性越好。为了便于观察实验结果,定义多样性评价指标Div=1-ILS,即Div越大,多样性越好。
4.3 实验过程
4.3.1类簇个数确定
在聚类算法中类簇个数K对聚类的结果有直接影响,本文使用轮廓系数法[16]对不同类簇得到的聚类结果进行评估。项目i的轮廓系数s(i)定义为:
(14)
式中:b(i)表示项目i的簇内相似度,即与簇内其他项目的距离的平均值,b(i)越小,说明项目i越应该被聚类到该簇;a(i)表示项目i的簇间相似度,即与不同簇项目的平均距离的平均值,a(i)越大,说明项目越不属于其他簇。由此可得结论,s(i)接近1,则说明项目i聚类合理;s(i)接近-1,则说明项目i更应该分类到另外的簇。为了度量整个聚类的质量,求得所有项目的平均轮廓系数:
(15)
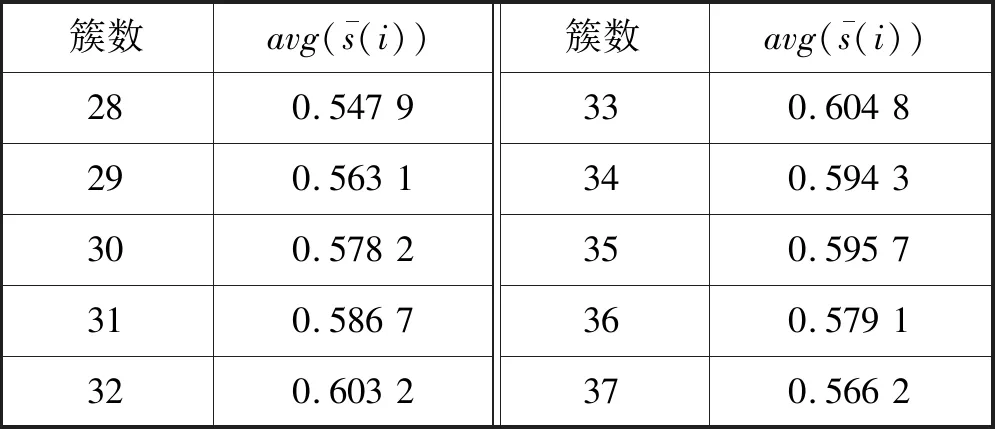
表2 在MovieLens上不同类簇数的聚类效果

表3 在Pinterest上不同类簇数的聚类效果
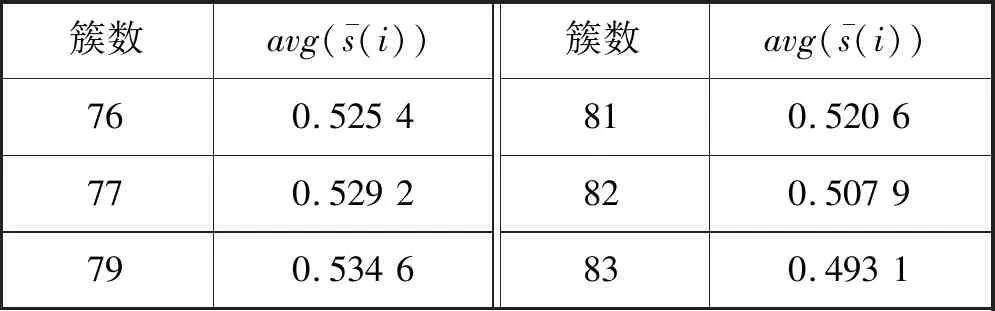
续表3
4.3.2模型参数设置
模型NDMF是基于NCF框架提出的,因此需要在NCF上调整参数来达到更高的效果。首先使用式(12)二类交叉熵损失函数学习模型,取正负采样比1∶4,对于模型参数的初始化选择高斯随机分布,并用Adam作为学习率自适应优化算法,它通过对参数进行频繁和大幅度的更新来适应每个参数的学习速率,Adam方法在NeuMF和NDMF模型上的收敛速度都比普通SGD(Stochastic Gradient Descent)快,缓解了调整学习率的难度。训练批次大小和学习速率通过测试选择最优的256和0.001,并且由于NCF的结构特性,其隐藏输出层即最后一层隐藏层决定了模型的性能,所以将其作为重要预测因素并使用[8,16,32,64]的因素大小作为模型的评估标准, 若预测因素大小为8,则NCF层即结构为32-16-8,分别为输入层,嵌入层和隐层输出的大小。由于深层的网络结构对于推荐任务也存在影响,经过实验验证选择隐藏层数为3的MLP。
4.3.3不同方法性能对比
将NDMF与GMF、MLP、NeuMF三种以NCF框架为基础的方法在两个真实数据集上进行对比,分别在隐层输出大小为[8,16,32,64]上进行实验,结果如图4所示。在MovieLens数据集上,NDMF的精确度指标HR和NDCG较NeuMF相差0.02左右,但与GMF和MLP相比相差不大,且上升趋势保持平稳,其中NDCG降低幅度大于HR的原因在于得到预测结果后对其进行了重排序,可能导致目标项目的位置后移。如果目标项目被移出TopN列表,那么HR和NDCG都会降低,如果没有移出TopN列表那么只有NDCG会降低。在多样性评价指标ILS上可以明显看出,NDMF的列表内部多样性明显高于其他三种方法,其中高于NeuMF方法0.09左右,并且随着精确度的上升会出现下降趋势。对于Pinterest数据集而言,整体趋势同上,可看出NDMF方法精确度较NeuMF方法降低幅度稍小,并且趋势平稳,且在多样性上的优势突出。由此,本文提出的NDMF方法在NCF框架中使用神经网络学习了构成的多样性特征,得到的实验结果显示,在精确度的损失在可接受范围内,并且不低于一般协同过滤推荐算法的前提下,换来了推荐列表多样性的大幅提升。
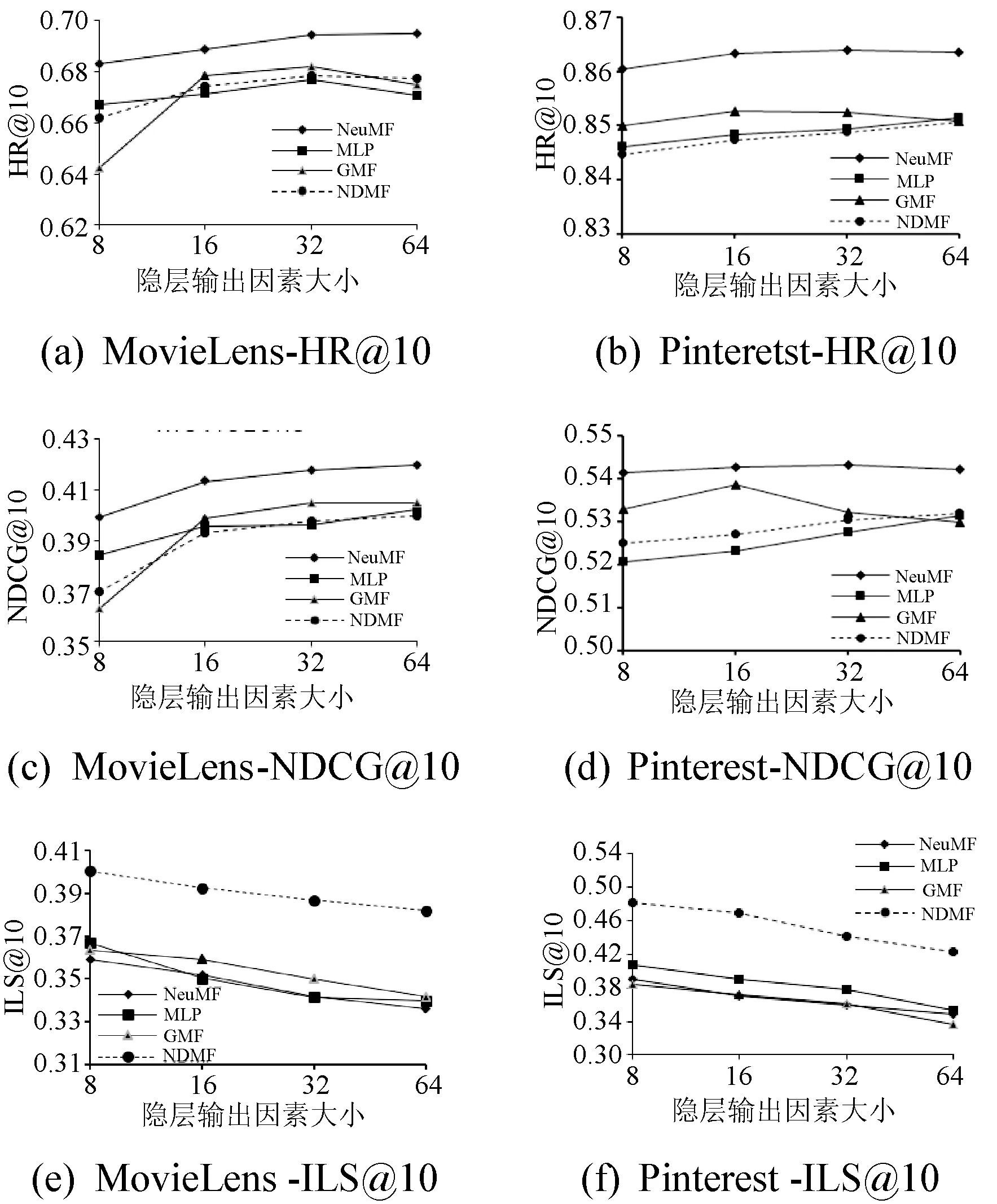
图4 在两个数据集上三个评价指标的性能比较
4.3.4对比实验
以隐层输出大小为8,从不同角度进行以下对比实验。在2.1.1节中,以两种不同的方法计算了用户的活跃度,并以ω控制二者的贡献度,图4是以ω=0.5得出的实验结果。改变两种用户活跃度所占比重并观察实验结果的变化,如表4所示,随着ω的增大精确度有较小幅度的波动而多样性则小幅度下降,ω增大表示聚类得到的用户活跃度k1(u)占比逐渐增多,相比于单纯由项目被评价的次数得到的活跃度k0(u),k1(u)携带的多样性特征更加明显,带来的增益更多。
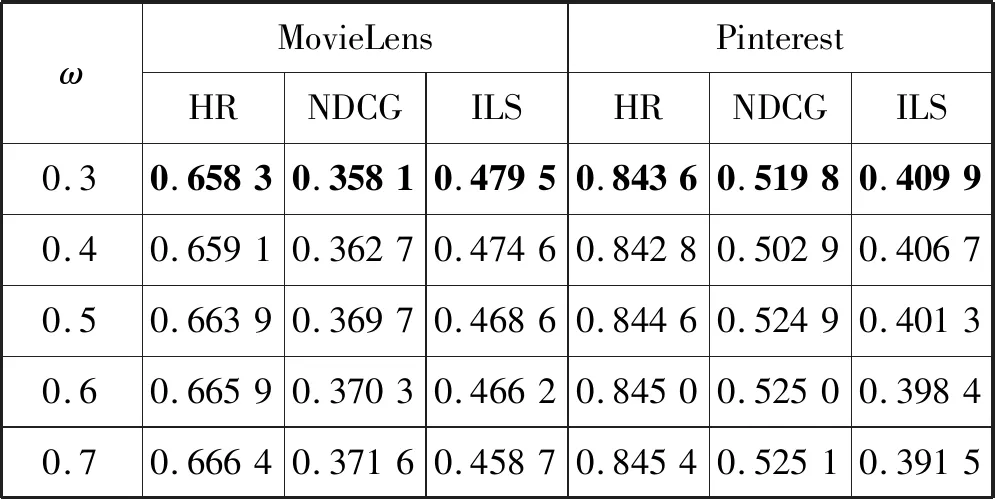
表4 ω不同时NDMF方法在两个数据集上的对比实验结果
最后选取TopN列表的长度为10和15在两个数据集进行对比,随着推荐列表长度增加,目标项目存在于列表的可能性或是其在推荐列表的排名得到提升,且由于Pinterest数据集的稀疏度较大,其精确度与多样性的变化比MovieLens要小。可以看出,在NeuMF中ILS的涨幅远小于NDMF,这是由于NDMF不仅新增了用户和项目的多样性特征,还在MLP的非线性内核从数据中学习交互函数时添加了复合用户活跃度与项目多样性推荐因子,具体实验结果见表5和表6。

表5 Top10下NeuMF与NDMF实验对比
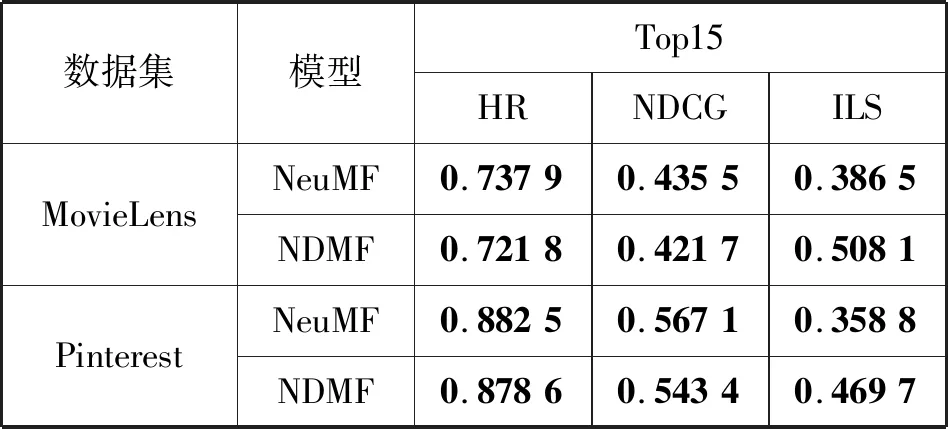
表6 Top15下NeuMF与NDMF实验对比
5 结 语
针对如何提高多样性,本文提出NDMF模型。其在GMF中以用户-项目对为单位进一步学习复合用户活跃度与多样性推荐因子结合得到的特征,同时用MLP学习用户-项目对间的潜在交互关系。NDMF不仅通过新特征的学习提高了推荐的多样性,而且在统一了用户-项目潜在结构方面MF的线性建模优势以及MLP的非线性建模优势的基础上保证了推荐的精确度。最后在得到的预测结果上进行重排序,更加确保了多样性的提升。实验结果证明,精确度的损失在可接受的范围内,且与精确度的损失相比多样性得到更大幅度的提升。
近两年,阿里巴巴提出了基于DNN模型的深度兴趣网络和它的进化版,基于用户多样性以及用户历史数据的部分有效性,在其中设计了“兴趣层”充分挖掘用户历史数据中的信息来提升CTR预估的性能。基于该研究,未来我们将尝试通过在NDMF模型中的MLP部分添加由注意力机制构成的“兴趣层”,来探索用户和项目的深度交互,进而保证推荐的精确性和多样性的同时提升。
猜你喜欢
保定学院学报(2022年2期)2022-04-07
中学生理科应试(2021年11期)2021-12-09
课堂内外(初中版)(2020年5期)2020-06-19
数学学习与研究(2018年15期)2018-11-12
新教育时代·教师版(2017年30期)2017-09-12
中学生数理化·教与学(2017年4期)2017-04-22
小学教学研究(2017年1期)2017-01-19
中学生数理化·中考版(2015年10期)2015-09-10
小说月刊(2012年3期)2012-05-08
中学生数理化·七年级数学人教版(2008年8期)2008-10-15
