
基于支持向量机的热喷涂层接触疲劳寿命预测
2021-03-05 00:57马润波董丽虹王海斗
兵工学报 2021年12期
马润波, 董丽虹, 王海斗
(1.陆军装甲兵学院 基础部, 北京 100072; 2.陆军装甲兵学院 装备再制造技术国防科技重点实验室, 北京 100072)
0 引言
热喷涂技术是再制造工程中为避免轴类、齿轮等重要旋转部件因表面损伤而提前报废的一项重要的表面处理技术。一些用于提高旋转部件表面耐磨性能的热喷涂层,如Al2O3-40%TiO2涂层(AT40涂层)在工程应用中不可避免地受到接触应力的作用,为确保再制造零部件在服役中的安全性,对涂层接触疲劳失效的研究已成为再制造工程中一项重要且有意义的工作,对涂层接触疲劳寿命的预测亦成为热点和难点问题[1-2]。
当前,使用工况多变且苛刻,热喷涂层的接触疲劳寿命不仅受到涂层厚度、显微硬度、涂层与基体的结合强度等[1]质量及表面性能参数的影响,而且受到服役中载荷、接触副转速、滑差率等因素[2]的影响。热喷涂层的接触疲劳寿命数据日益呈现高维、混杂的趋势,小样本特征日益突出。另外,由于受到噪声干扰,数据的质量不高。在热喷涂层的接触疲劳寿命预测中,经典单变量模型占据主导地位,如Weibul模型[3-4]。这一模型优良的统计特性在具体问题的运用中得到发挥,并起到了承上启下的作用。在Weibull模型基础上建立的概率- 应力- 寿命曲线(简称P-S-N曲线)[5]也是研究热喷涂层接触疲劳寿命的重要方法,然而样本容量影响了P-S-N曲线预测的精确度和可靠性;P-S-N曲线仅考虑寿命数据的分散性,并未考虑总体和样本之间的差异,当样本容量较大时才能使总体和样本之间的差异表现不显著;在样本容量较小时P-S-N曲线预测的精确度不仅较低,而且所得到的曲线并不是总体的真实曲线[4]。基于统计回归分析的寿命预测模型,是对疲劳寿命和影响因素的统计关系进行定量描述的另一类重要数学模型,它能同时研究多种影响因素与涂层接触疲劳寿命之间的关系,解决通过工艺优化或其他手段无法减小的某些因素对涂层寿命的影响问题。因为传统的统计回归模型要求数据具有正态性,热喷涂层的接触疲劳寿命一般服从Weibull分布[1-2,4,6-7],使传统回归模型的应用在一定程度上受到了限制,以至于统计学方法的应用出现错误的可能性增大,所以需要与新的方法和理论进行融合,以适应再制造工程发展的需要。支持向量机(SVM)理论是在统计学习理论[8]基础上发展起来的一种通用学习算法,具有较强的学习功能和特征,对小样本具有较好的适应性,其相关研究和应用涉及图像识别与分类[9-12]、疲劳裂纹检测[13]、结构健康检测[14]。近年来,已有学者将SVM应用到轴类和齿轮零件的故障分类[15]、故障诊断[16-17]、剩余寿命预测[18-19]、退化状态识别[20-21]中。也有学者将SVM应用到光纤涂覆层微小缺陷的识别[22]、封严涂层孔隙度估计的研究[23]、化学镀Ni-P/ZrO2复合镀层显微硬度预测研究[24]、航空材料镁合金表面涂层耐磨性预测研究[25]中,均取得了较好的效果。然而,在涂层接触疲劳寿命预测中的应用研究目前尚无相关报道。
将SVM理论与统计学方法相结合,能较好地适应热喷涂层在接触疲劳过程中损伤的偶然性、随机性、相异性等特点[26],对涂层接触疲劳寿命预测研究将有重要的作用。本文利用滚动接触疲劳试验机进行试验,采用SVM理论,预测热喷涂层的接触疲劳寿命,旨在为热喷涂层的接触疲劳寿命评估提供一种可靠且可行的数学方法。为此以超音速等离子喷涂AT40涂层为研究对象,在相同工艺参数下制备涂层,采用砂轮磨削的方式打磨涂层,得到5种不同厚度的涂层,并采用扫描电镜(SEM)对涂层截面进行观察。在中心复合设计方案下进行涂层的接触疲劳试验,获取了涂层在接触应力、滑差率、转速和涂层厚度等多因素影响下的接触疲劳寿命。采用SEM对涂层失效形貌进行观察,并总结失效形貌特征。利用统计检验方法验证接触疲劳寿命的可靠性,同时将黄金分割法与信息熵理论相结合,对接触疲劳寿命数据进行训练集和测试集的划分,基于SVM原理采用列举的方式选择参数,建立综合考虑接触应力、转速、涂层厚度和滑差率的寿命预测模型,通过残差分析验证模型的可靠性。
1 样品制备与试验设计
1.1 涂层制备
采用装备再制造技术国防科技重点实验室研制的超音速等离子喷涂设备(JET),在调质45号钢测试辊的外周面上制备涂层。喷涂前采用棕刚玉对基体表面进行喷砂处理。采用质量分数为90%Ni-10%Al的Ni/Al合金作为粘结层,以提高涂层与基体的结合强度。采用AT40涂层作为喷涂层。基体线接触长度为8 mm、外周边缘倒角为0.5 mm的辊子,涂层制备示意图如图1所示。喷涂参数如表1所示,采用相同的喷涂时间及喷涂次数,使得涂层和基体受到的冷却时间、受热状态等热力学因素影响相同,喷涂后涂层厚度为500~600 μm. 使用SEM对涂层的微观结构进行表征,如图2所示。由图2可见,粘结层与涂层无裂纹,可见典型的热喷涂层状结构。

图1 涂层制备示意图Fig.1 Schematic diagram of coating preparation
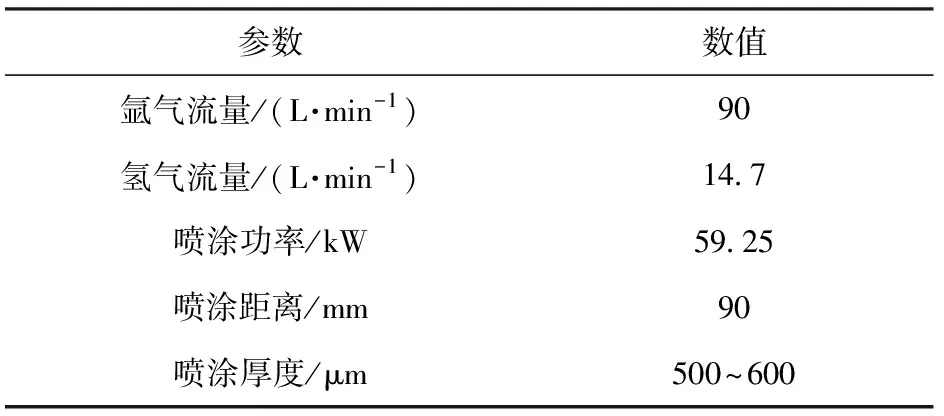
表1 超音速等离子AT40涂层喷涂参数

图2 等离子喷涂AT40 涂层横截面微观结构Fig.2 SEM photo of plasma-sprayed AT40 coating
1.2 滚动接触疲劳试验方法
在接触应力、转速、厚度、滑差率等多因素共同作用下,要获取可靠的接触疲劳试验数据,将不可避免地增加试验规模,从而导致试验成本、研究周期增加。为有效减少试验规模,需要设计有效的试验方案,使其既能涵盖影响涂层接触疲劳寿命的多个因素,又可以发挥统计学方法的优势,建立兼顾多因素的寿命预测模型。
中心复合设计[27]是兼顾影响因素独立及综合效应的统计学试验方法,其在2k因子设计的基础上,根据交互作用、弯曲度检验的显著性情况,加入中心试验点和轴试验点构成,在参数优化设计中已有广泛应用,其设计方案按照编码方式编制,具体编码方法为
xi0=(yi-y0i)/Δi,
(1)
式中:yi为第i个变量;xi0为yi的编码值,i=1,2,…,m,m为变量个数;y0i为yi取值区间的中心点;Δi为yi取值区间的半径。该试验方法共有N=mc+mr+m0个试验点,mc表示2k因子设计的试验点数,mr表示分布在m个坐标轴上的轴试验点数,m0表示中心点重复试验的次数。轴试验点到中心点的距离M为待定参数,调节M可得到正交性、旋转性等优良性。一般而言,若设计具有旋转性,则要求M4=mc.经编码变换后,新变量xi的取值范围为[-M,M].
采用装备再制造技术国防科技重点实验室研制的RM-1型多功能试验机,依中心复合设计方法进行接触疲劳试验,以喷涂AT40涂层的辊子作为测试辊,与测试辊进行接触的对偶件作为标准辊,利用Hertz公式计算线接触最大接触应力,标准辊尺寸和滚动接触示意图如图3所示。

图3 辊子尺寸及滚动接触示意图Fig.3 Schematic diagram of roller size and rolling contact
为了有效减少试验规模,对接触应力、转速、滑差率和涂层厚度等因素在涂层接触疲劳失效中的影响规律进行研究,采用3因素的中心复合试验设计方法将试验分成两组进行。第1组试验,考察接触应力、转速和滑差率3个因素,涂层厚度固定为200 μm;采用砂轮磨削方式制备涂层厚度为200 μm的测试辊,各因素取值水平如表2所示。第2组试验,考察接触应力、滑差率和涂层厚度3个因素,转速固定为300 r/min;经计算可得涂层厚度分别为216 μm、250 μm、300 μm、350 μm、384 μm. 为处理方便,砂轮磨削方式制备的涂层厚度为200 μm、250 μm、300 μm、350 μm、400 μm. 各因素取值水平如表2所示。
2 分析与讨论
2.1 疲劳寿命特征
依据中心复合设计原理,对于3因素试验,有M=1.68,mc=8,m0=5,mr=6. 第1组试验采用的参数及结果如表2中试验编号1~19所示,其中:试验编号1~8是2k因子设计的试验点;试验编号9~14是轴试验点;试验编号15~19是中心点,是接触应力、转速和滑差率取相同参数值的5次重复试验。第2组试验采用的参数及结果如表2中试验编号20~38所示,其中:试验编号20~27是2k因子设计的试验点;试验编号28~33是轴试验点;试验编号34~38是中心点,是接触应力、滑差率和涂层厚度取相同参数值的5次重复试验。
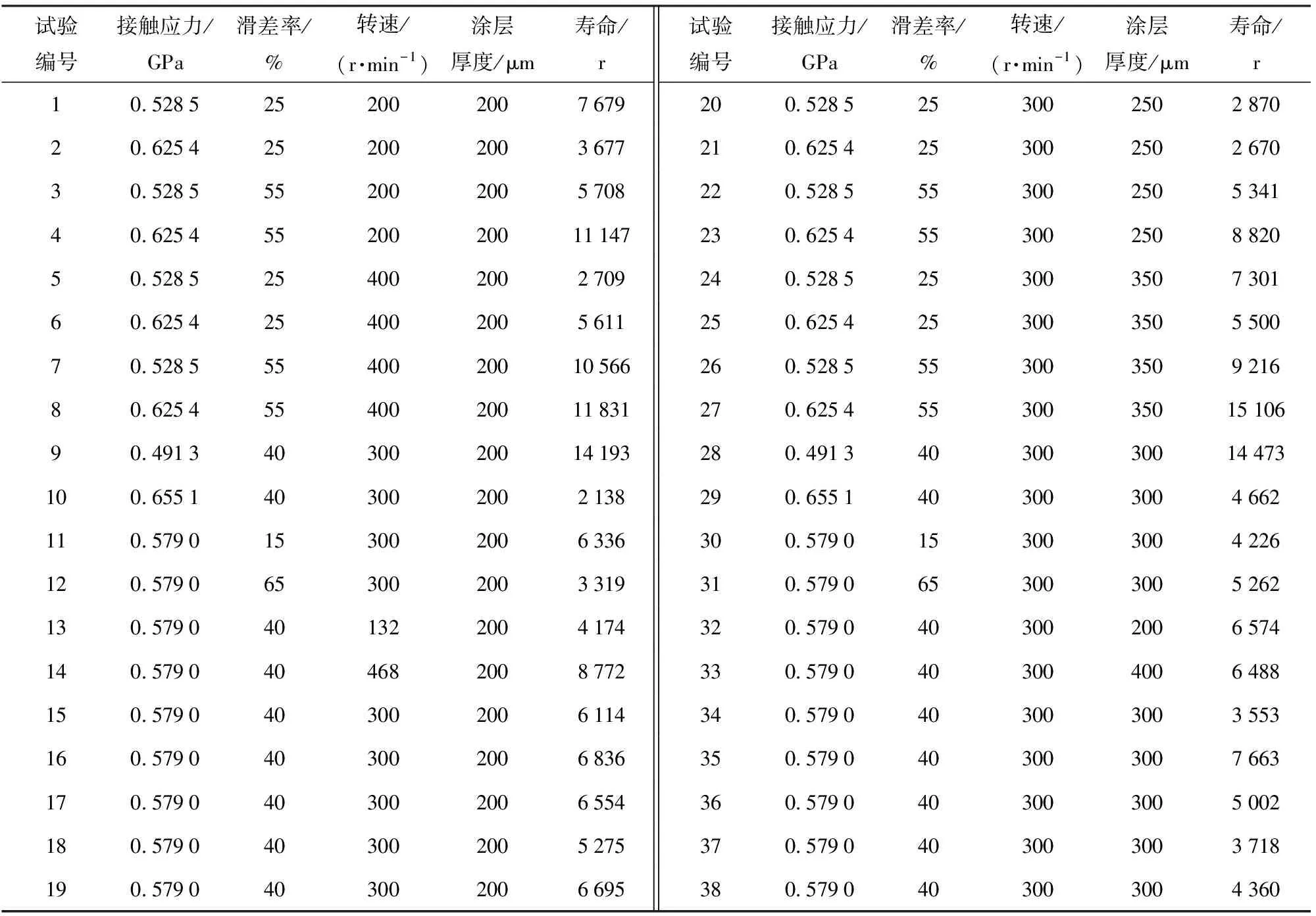
表2 AT40涂层接触疲劳试验参数及结果Tab.2 Contact fatigue test parameters and test results of AT40 coating
图4给出了表2中寿命数据经Weibull变换[28],并在直角坐标系下绘制的接触疲劳寿命Weibull概率纸图(WPP图)[29]。由图4可知,采用中心复合设计获取的寿命数据服从两参数Weibull分布。
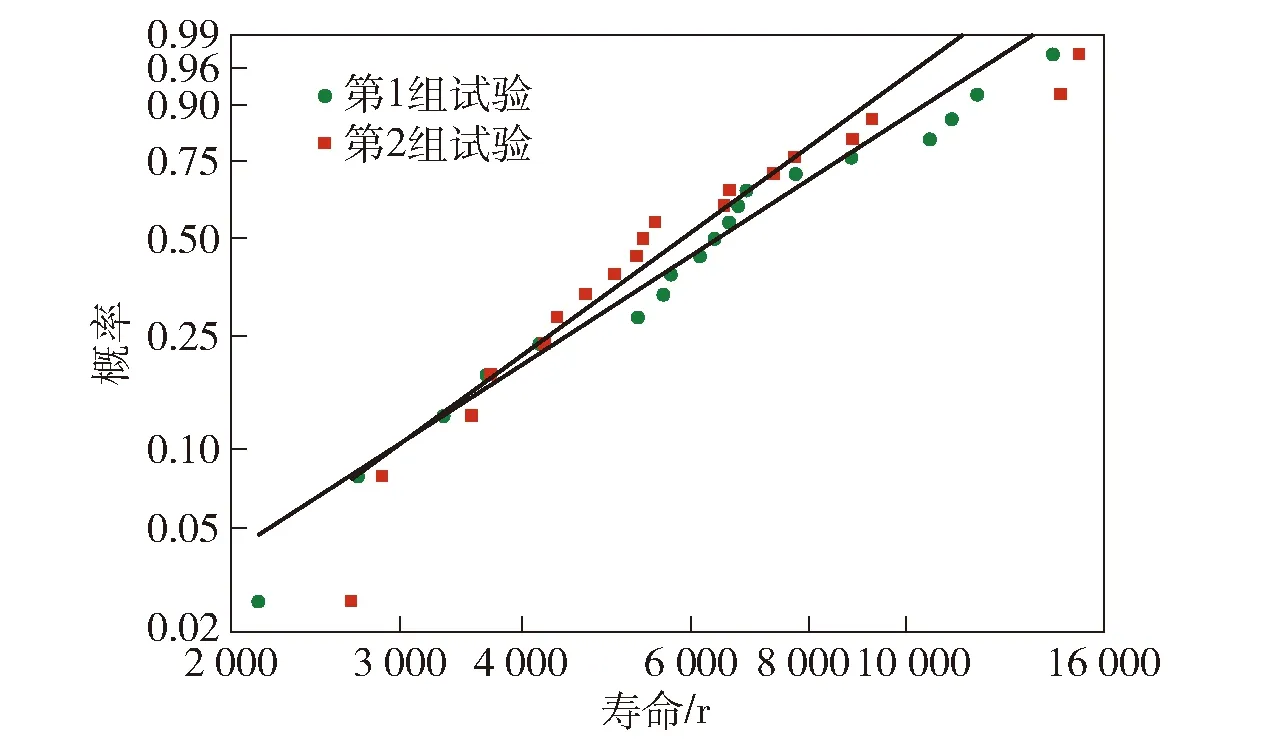
图4 中心复合设计下接触疲劳寿命WPP图Fig.4 WPP graph of contact fatigue life with central composite design
第1组试验及第2组试验在中心点进行5次重复试验,其余各试验点只进行1次试验。由于热喷涂层的伴随性结构缺陷[30]及在服役中损伤的不确定性,使得失效数据具有随机性和分散性等特征,需要对采用中心复合设计法获取的寿命数据的可靠性进行检验。
在直角坐标系下绘制图5所示中心点的正态概率图,可知中心点大致沿直线分布。同时,采用Kolmogorov-Smirnov检验[31](K-S检验)对中心点进行正态性检验,检验结果如表3所示。对于第1组试验及第2组试验,检验的显著性值分别为0.890和0.981. 图5和表3表明,第1组试验和第2组试验的中心点均具有正态性。
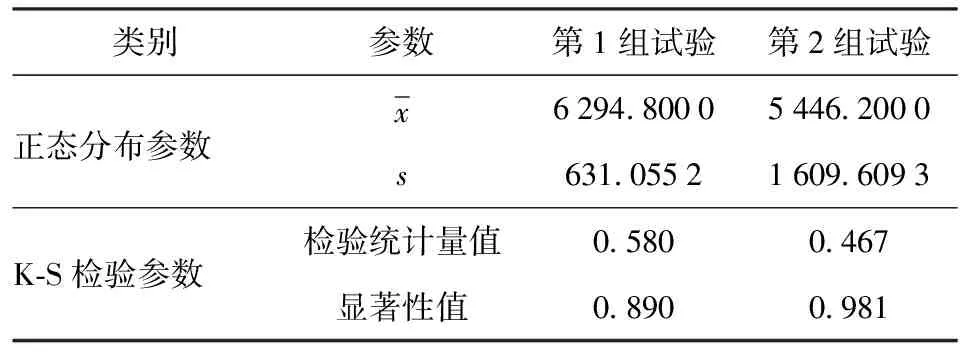
表3 中心点的正态性检验Tab.3 Normality test of center points
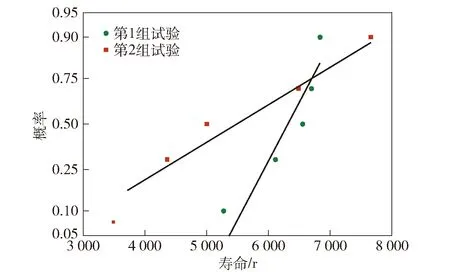
图5 中心点正态概率图Fig.5 Normal probability graph of center points
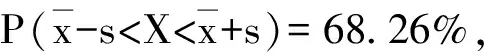
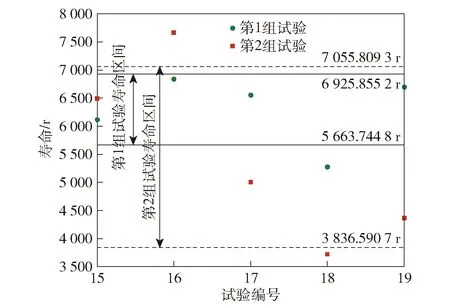
图6 疲劳寿命数据正态分布的3σ准则示意图Fig.6 3σ criterion diagram of normal distribution of fatigue life
2.2 失效形貌特征
第1组试验和第2组试验中,失效模式主要为分层失效和表面磨损,所占比例如图7所示。图8所示为典型的表面磨损失效形貌。由图8可见,微点蚀较为严重,在整个涂层宽度范围内已形成大面积的浅层材料去除。图9所示为AT40涂层发生分层失效的典型表面形貌。由图9可见发生分层失效的AT40涂层表面微观形貌具有如下特征:1)分层失效是损伤累积的结果,分层区域约为宽度面积的30%~100%;2)分层失效的涂层边缘较为陡峭,且分层失效贯穿涂层的一侧,较为严重时分层区域沿宽度方向贯穿涂层;3)分层失效位置为涂层与基体结合的界面处,分层区域的金属基体已经完全裸露,裸露的位置为喷砂处理后的基体部分,无明显的犁削和黏着特征;4)在涂层未完全分层去除处,呈现出典型的具有疲劳裂纹扩展特征的海滩条带形貌,涂层表面出现了较为明显的宏观材料去除。
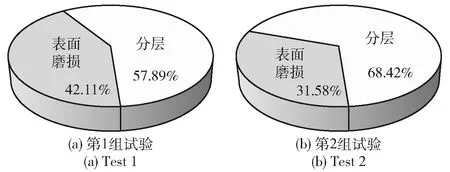
图7 AT40涂层接触疲劳失效模式比例Fig.7 Contact fatigue failure mode proportion of AT40 coating

图8 典型表面磨损形貌Fig.8 Typical surface wear morphology

图9 分层失效典型形貌图Fig.9 Typic morphology of delamination failure surface
2.3 SVM回归分析
2.3.1 SVM原理
Vapnik提出的SVM理论[7]是基于统计学习理论发展起来的一种新型机器学习算法,对小样本适用性较强,尤其当训练集有限时得到的决策规则,对独立的检验集仍能得到较小的误差。这种方法不涉及概率测度和大数定律,基本避免了从归纳到演绎的过程,具有结构风险最小、可以逼近任意函数且保证全局最优等特点。将ε不敏感损失函数[8]引入,并用于解决数据的拟合与回归问题,得到了SVM预测理论,即支持向量回归机(SVR)。SVR预测的基本思想是,对于给定的训练集{(xi,Yi),i=1,2,…,n},其中xi∈Rn为输入值,n为样本数,Yi∈R为预测值,寻找Rn上的实值函数f(x),拟合输入和输出之间的关系。
2.3.2 接触疲劳寿命的SVM回归模型拟合
2.3.2.1 寿命数据的标准化
由于接触应力、滑差率、转速、涂层厚度的物理意义和量纲不同,使得各自取值的范围差别较大,在SVR训练中易出现稳定性较差的现象,从而导致泛化能力差。通过标准化处理可以提高训练的稳定性和泛化性,使接触应力、滑差率、转速、涂层厚度4个变量在训练中地位相同。
对Yi进行标准化,记为Y′i,公式如下:
(2)
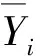
2.3.2.2 寿命数据的划分
为处理方便,将除去测试样本后的试验数据组成的集合称为训练集,训练样本由训练集中选取的元素构成。为保证模型的预测精度,训练集的组成要具有一定代表性,选取的训练样本既要具有一定的稳定性,其样本数又要满足建模需要。观察表2可知,编号为1、2、7~21、24、26~38的试验中,接触应力、转速、滑差率和涂层厚度4个可控制因素的取值水平涵盖了试验中的所有值,具有一定代表性,可将试验1、2、7~21、24、26~38的数据组成训练集。由于试验点15~19及34~38为重复试验,故对重复试验点取算术平均值,作为相同试验条件下的试验数据。于是训练样本共包含23个寿命数据。
由于黄金分割法[32]作为一种优先法,是一种数学上的比例关系,具有严格的比例性、和谐性,训练样本的个数应至少等于训练集中元素个数的0.618倍,即训练样本数应大于等于14.214,而样本数应为正整数,故取为15.又由于信息熵的大小体现了信源发消息的随机性的大小,即信息熵大则意味着随机性大,信息熵小则意味着随机性也小[33]。于是,可采用信息熵的大小来体现训练样本的稳定性[34],并进一步确定训练样本。
对于已知的一个概率向量(p1,p2,…,pN0),称
(3)
为信息熵。
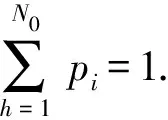
(4)

(5)
经计算,可得样本数自15开始,不同样本数的训练样本信息熵如表4和图10所示。

表4 不同训练样本数的信息熵Tab.4 Information entropies of different training samples
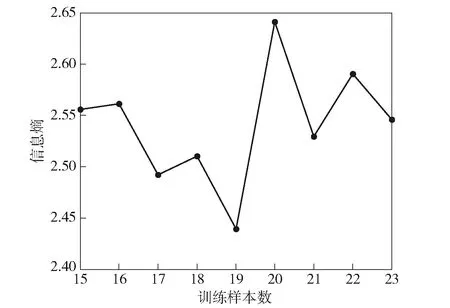
图10 训练样本数与信息熵的关系图Fig.10 Relational diagram of training samples and information entropy
2.3.2.3 SVR寿命预测模型
SVR主要包括线性和非线性两类,非线性SVR通过定义满足Mercer条件的核函数K(xi,xj),将训练数据映射到一个高维特征空间F,然后在F中进行线性回归。常用的核函数有多项式核函数、高斯径向基核函数和多层感知核函数等。
SVM算法步骤如下:
步骤1给定训练集{(xi,Yi),i=1,2,…,n},xi∈Rn,Yi∈R,i=1,…,n.
步骤2选择适当的正数ε和C,选择核函数K(xi,xj)。
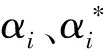
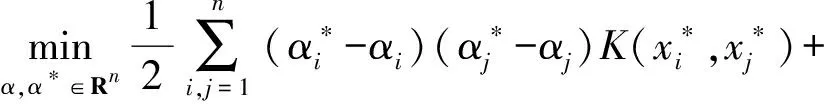
步骤4构造回归估计函数
由表4和图10可知,训练样本含有19个数据。依据表2可知,训练样本包含试验编号为1、2、7、10~19、20~21、24、26、29、30~38的试验数据。其中,对重复试验点15~19和34~38取算术平均值。将试验编号为3~6、22~23、25的数据作为测试样本,其中对重复试验点34~38取算术平均值。设u、v、x为向量,γ、e、d为待定参数,分别选择多项式核函数K(u,v)=(γuTv+e)d和高斯径向基核函数K(x,xT)=exp (-γ·‖x-x′‖2)。采用列举法得到如下预测结果:对于多项式核函数,取惩罚参数C=0.5、γ=91、d=1时模型的预测效果较好;对于高斯径向基核函数,取惩罚参数C=10、ε=0.01、γ=0.001时模型的预测效果较好。预测结果如表5所示,SVM回归模型的平方相关系数R2和均方根误差RMSE如表6所示。
2.3.3 精确度和可靠性
预测模型的可靠性可通过残差正态性进行讨论。采用K-S检验方法对表5中预测模型的残差进行非参数假设检验,给定显著性水平同上。检验结果如表7所示。
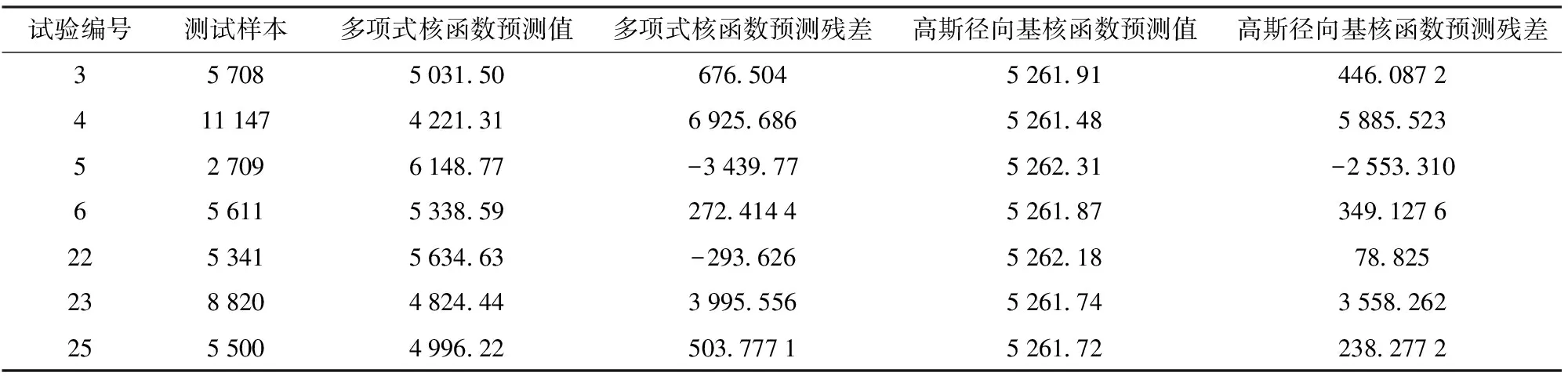
表5 SVM回归预测值Tab.5 Predicted values of support vector machine regression

表6 SVM回归模型的相关系数和均方根误差Tab.6 R2 and RMSE of support vector machineregression medel
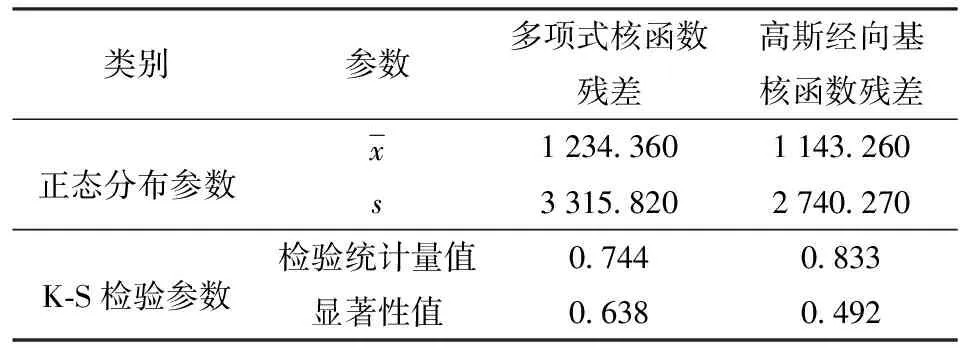
表7 残差的正态性检验Tab.7 Normality test of residuals
由表7可见,K-S检验的显著性值均大于0.05,故可以认为残差具有正态性,表明SVR模型的预测结果是合理的。然而,观察表6可知,虽然高斯径向基核函数下的回归模型均方根误差优于多项式核函数下的回归模型。但是,多项式核函数下回归模型的平方相关系数R2优于高斯径向基核函数下的回归模型。且由图11可见采用高斯径向基核函数的预测模型各预测值之间几乎没有差异,表明在小样本情况下,采用高斯径向基核函数的预测模型其残差的随机性较差,采用多项式核函数的模型其预测效果要优于高斯径向基核函数。
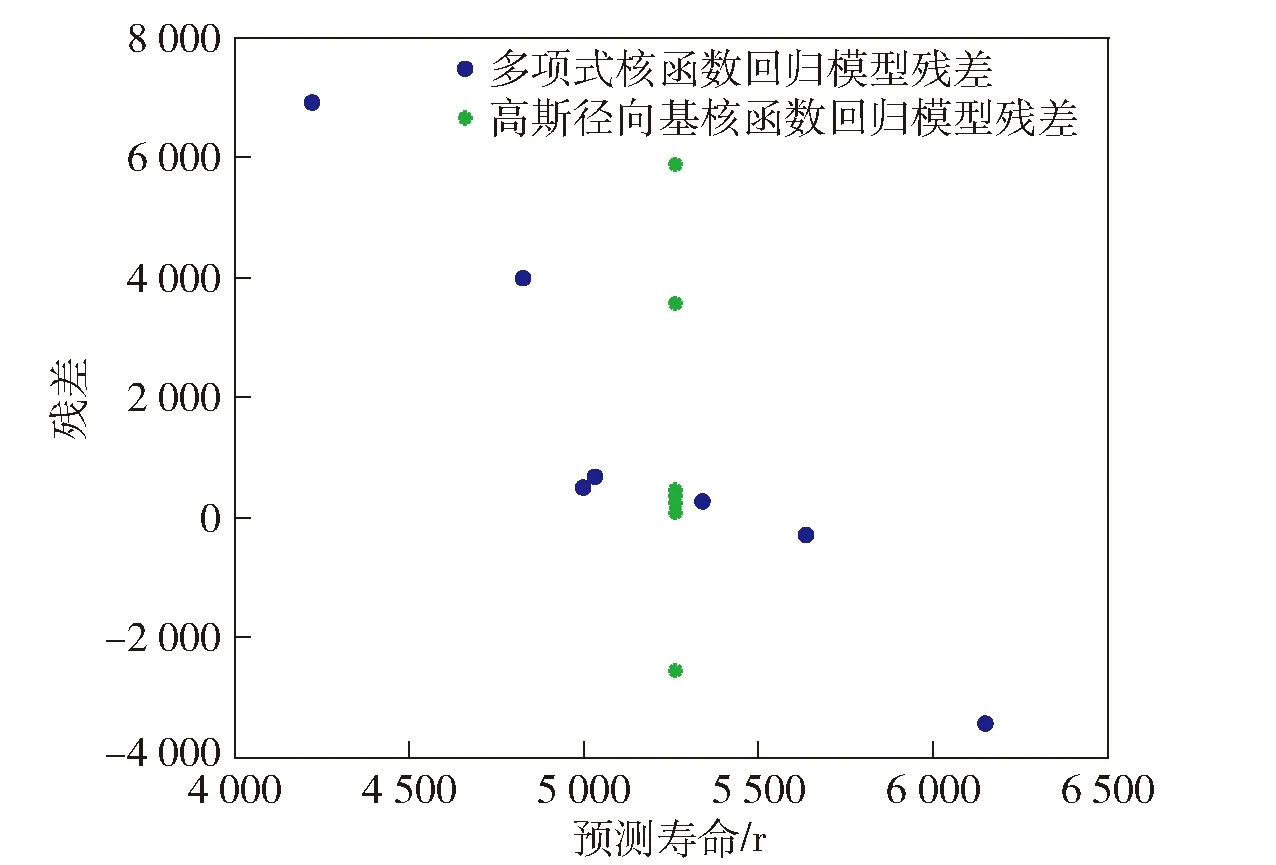
图11 残差图Fig.11 Residual plot
3 结论
本文采用超音速等离子喷涂技术,在相同喷涂参数下得到了相同喷涂厚度的AT40涂层。采用砂轮磨削方式制备了满足中心复合设计试验方案所要求的涂层厚度。在中心复合设计方案下获取了喷涂层受接触应力、滑差率、转速和涂层厚度作用的多因素接触疲劳寿命数据,并采用SEM观察了涂层失效形貌,同时建立了SVR模型。所得主要结论如下:
1)多因素影响下AT40涂层的接触疲劳失效模式主要为分层失效和表面磨损。表面磨损失效表现为较严重的微点蚀。分层失效表现为损伤累积的结果,涂层边缘较为陡峭,且分层失效贯穿涂层的一侧,而较严重时分层区域沿宽度方向贯穿涂层;分层失效位置为涂层与基体结合的界面处,分层区域的金属基体已经完全裸露,裸露的位置为喷砂处理后的基体部分,无明显的犁削和黏着特征;在涂层未完全分层去除处,呈现出典型的具有疲劳裂纹扩展特征的海滩条带形貌,涂层表面出现了较明显的宏观材料去除。
2)多因素影响下AT40涂层的接触疲劳寿命数据服从Weibull分布,正态分布的3σ准则检验结果表明,采用中心复合设计方案得到的多因素接触疲劳寿命数据具有可靠性和稳定性。
3)黄金分割法和信息熵理论相结合的方法,可将寿命数据分成训练集和测试集,为建立可靠的SVR模型奠定基础。进一步,残差分析结果表明残差具有正态性,表明SVR模型的预测结果是合理的。
4)在小样本下,多项式核函数下的SVR预测模型优于高斯径向基核函数下的SVR预测模型。
猜你喜欢
材料研究与应用(2022年2期)2022-05-23
建材发展导向(2022年6期)2022-04-18
昆明医科大学学报(2022年2期)2022-03-29
包装学报(2022年1期)2022-03-24
表面技术(2022年2期)2022-03-03
科技创新与应用(2020年6期)2020-02-29
中华诗词(2019年8期)2020-01-06
环球时报(2017-03-22)2017-03-22
现代电子技术(2016年23期)2017-01-12
