
基于数据驱动的高校毕业生就业率预测研究
2021-03-08 02:33刘小杰
现代电子技术 2021年5期
刘小杰
(宿迁学院,江苏 宿迁 223800)
0 引 言
对于一所高校来说,毕业生就业是一个最为关键的问题,如何让毕业生找到更好的工作,对于学生的培养和管理具有重要的意义[1⁃3]。为了更好地实现毕业生就业,大多数高校均建立了高校毕业生就业信息管理系统,产生了许多有价值的高校毕业生就业数据,通过这些数据对高校毕业生就业率进行预测具有重要的价值[4]。
由于高校的重视,投入了大量的人力和财力对高校毕业生就业率预测问题进行研究。当前有许多高校毕业生就业率预测方法[5⁃7],主要有基于人工神经网络的高校毕业生就业率预测方法、基于支持向量机的高校毕业生就业率预测方法,它们均是通过对高校毕业生就业率历史数据进行分析,找到高校毕业生就业率变化规律,但是在实际应用中,均存在许多不足,如人工神经网络是一种传统的机器学习算法,基于大数据定理,要求高校毕业生就业率历史数据多,才能得到较好的高校毕业生就业率预测结果。当历史数据比较少时,高校毕业生就业率预测误差极大,并且预测结果不稳定,可信度比较低[8⁃10];支持向量机虽然没有大数据的要求,但是其参数直接影响高校毕业生就业率预测效果。当前主要采用经验法和遗传算法确定支持向量机的参数,但不管是经验法还是遗传算法,均无法获得支持向量机的全局最优参数,使得高校毕业生就业率预测精度有待提高[11⁃13]。
为了提高高校毕业生就业率预测精度,针对高校毕业生就业率预测方法存在的不足,提出基于数据驱动的高校毕业生就业率预测方法,并在Matlab 2018 平台上与其他方法进行高校毕业生就业率预测对比测试,验证了本文设计方法的高校毕业生就业率预测结果的优越性。
1 基于数据驱动的高校毕业生就业率预测方法
1.1 高校毕业生就业率预测数学模型
高校毕业生就业信息管理系统中保存了大量的高校毕业生就业率历史数据,对高校毕业生就业率历史数据进行挖掘,提取高校毕业生的就业率变化,可对高校毕业生就业进行指导。高校毕业生就业率预测原理为:根据历史数据,采用一定的方法建立高校毕业生就业率预测模型,对将来的高校毕业生就业率发展态势进行分析与预测;为了提升高校毕业生就业率预测精度,建模方法的选择十分关键,本文采用支持向量机。
高校毕业生就业率预测的数学模型可以描述为:

式中:x1,x2,…,xn表示高校毕业生就业率历史数据集合;y表示预测结果;f()表示高校毕业生就业率变化规律拟合函数。
1.2 支持向量机
支持向量机是一种现代统计理论的人工智能学习算法,对于一个问题的训练样本集合{(xi,yi)},i=1,2,…,n,n表示训练样本的数量,xi表示问题的输入,yi表示问题的期望输出,机器学习算法通过学习可以建立该问题的估计模型,该模型可以拟合输入和输出之间的关系。假设x和y的联合概率分布为F(x,y),预测函数集为{f(x,w)},那么其最小的期望风险为:

式中G(y,f(x,w))表示f(x,w)对y估计时所造成的损失。
在实际应用中,F(x,y)不易获得,使得R(w)不能直接进行计算,根据大数定律,利用n个样本上损失的平均值近似替代R(w),则有:
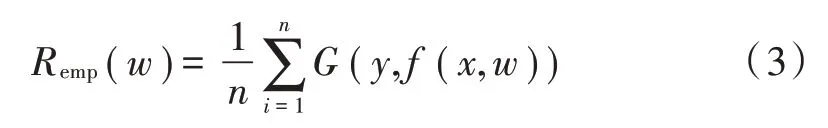
对于训练样本集合{(xi,yi)},i=1,2,…,n,引入松弛变量ξ= ( )ξ1,ξ2,…,ξn,支持向量机可以表示为一个线性约束的二次优化问题,具体为:

式中C为惩罚参数。
通过引入拉格朗日函数,求取鞍点,可以得到:

式中α表示拉格朗日乘子。
式(5)的约束条件为:


式中k(xi,x)定义如下:
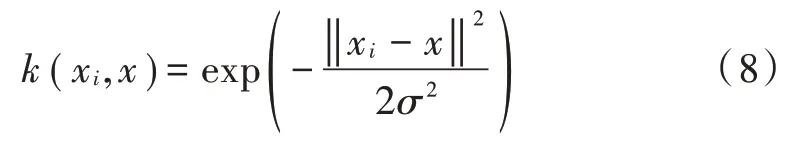
式中σ为核宽度。
参数σ和C对支持向量机预测性能有重要影响,为此选择蚁群算法对σ和C进行优化,确定最优的σ和C。
1.3 蚁群算法
第t个时刻,路径(i,j)上的信息素浓度和启发式信息值分别为τij(t)和ηij(t),蚁群算法是一种模拟蚂蚁行为的启发式算法,第i只蚂蚁由节点i到j的转移概率为:

蚂蚁完成一次完整的路径搜索后,路径上的信息素需要更新,具体方式如下:
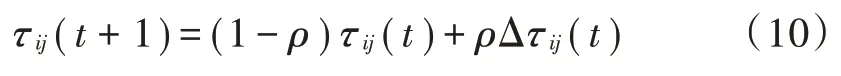
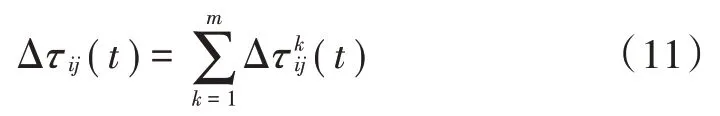
1.4 数据驱动的高校毕业生就业率预测原理
基于数据驱动的高校毕业生就业率预测原理为:首先采集高校毕业生就业率的历史数据,并对数据进行预处理,建立高校毕业生就业率预测的训练样本,然后采用蚁群算法优化支持向量机的参数,对高校毕业生就业率训练样本进行学习,建立高校毕业生就业率预测模型,最后对未来高校毕业生就业率进行预测,并输出结果,具体工作原理如图1 所示。
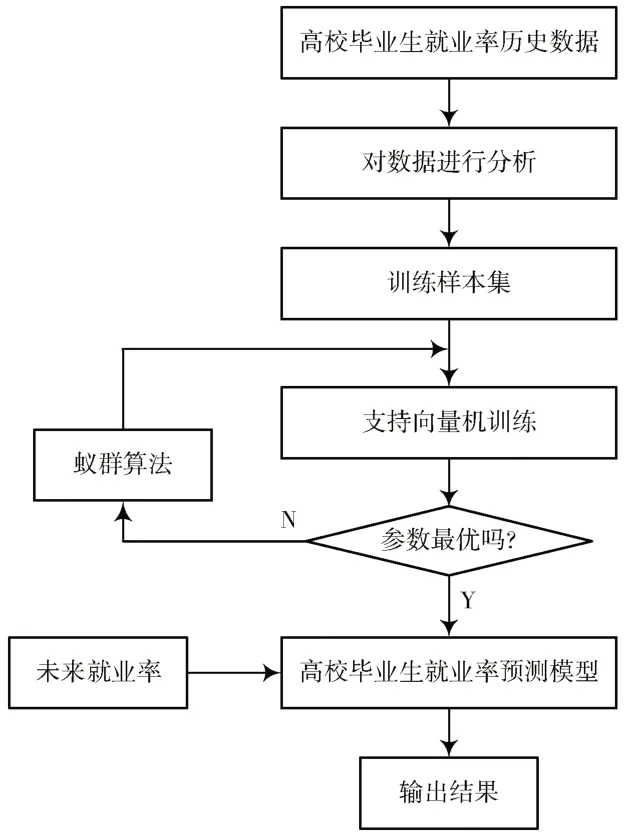
图1 数据驱动的高校毕业生就业率预测流程
2 高校毕业生就业率预测的仿真测试与分析
2.1 仿真测试实验环境的具体设置
为了分析数据驱动的高校毕业生就业率预测方法的有效性,采用具体仿真实验对其进行测试与分析,仿真测试环境的具体设置如表1 所示。
为了分析数据驱动的高校毕业生就业率预测模型的优越性,在仿真测试环境条件下,选择当前典型的高校毕业生就业率预测方法进行对比测试,具体设置如下:
1)凭经验随机确定支持向量机参数的高校毕业生就业率预测方法,简称为SVM。
2)遗传算法优化支持向量机参数的高校毕业生就业率预测方法,简称为GA⁃SVM。
2.2 测试对象
为了使高校毕业生就业率预测方法具有通用性,对所有类型的高校,选择每一类不同数量的高校毕业生就业率数据作为测试对象,具体样本数据如表2 所示。

表1 高校毕业生就业率预测仿真实验环境
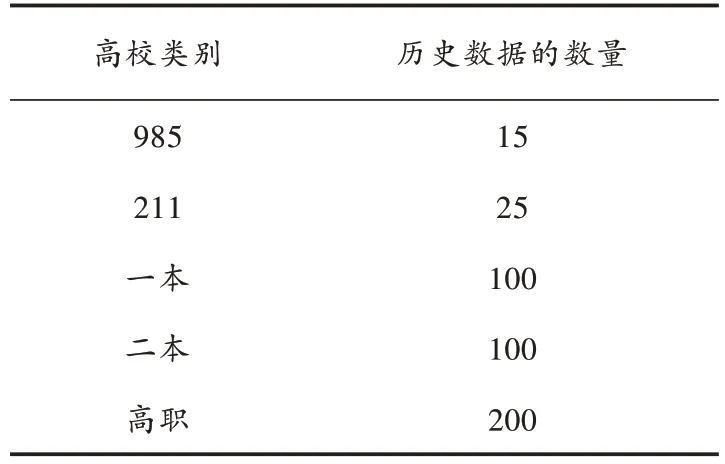
表2 高校毕业生就业率预测建模的数据
2.3 预测方法的参数确定
采用经验法、遗传算法、蚁群算法分别确定支持向量机参数,具体如表3 所示。从表3 可以看出,不同的算法得到不同的支持向量机参数,因此它们对高校毕业生就业率预测结果具有不同的影响。

表3 不同方法的支持向量机参数
2.4 实验结果与分析
支持向量机采用表3 的参数,对于每一类高校的数据,随机选择2 3 作为训练样本进行学习,建立高校毕业生就业率预测模型,并对剩下的1 3 进行测试,统计它们的高校毕业生就业率预测精度和误差,结果分别如图2 和图3 所示。对图2 和图3 的高校毕业生就业率预测结果分析,可知:
1)SVM 的高校毕业生就业率预测精度和误差分别为82.77%和17.23%,高校毕业生就业率预测误差超过了实际应用的要求,无法应用于实际的高校毕业生就业管理中。
2)GA⁃SVM 的高校毕业生就业率预测精度和误差分别为90.42%和9.58%,要明显优于SVM 的高校毕业生就业率预测结果,这是由于GA⁃SVM 引入了遗传算法对支持向量机的参数进行优化,而SVM 采用经验方式确定,可见GA⁃SVM 能够更好地对高校毕业生就业率的变化趋势进行预测,获得了更优的高校毕业生就业率预测结果。
3)本文方法的高校毕业生就业率预测精度和误差分别为94.30%和6.70%,在所有方法中,本文方法的高校毕业生就业率预测精度最高,大幅度减少了高校毕业生就业率预测误差,这表明蚁群算法获得了更好的支持向量机参数,建立了更优的高校毕业生就业率预测模型,克服了当前高校毕业生就业率预测方法的弊端,具有十分明显的优越性。

图2 不同方法的高校毕业生就业率预测精度

图3 不同方法的高校毕业生就业率预测误差
2.5 高校毕业生就业率预测效率对比
不同方法的高校毕业生就业率训练和测试时间具体如表4 所示。从表4 可以看出:
1)对于每一种方法,高校毕业生就业率预测训练时间均要多于测试时间,这是因为在高校毕业生就业率预测模型的训练过程中,需要不断对高校毕业生就业率预测的参数进行优化,因此消耗的时间较多,而本文方法测试仅采用已经构建好的模型对高校毕业生就业率测试样本的值进行估计,消耗时间相对较少。
2)在所有高校毕业生就业率预测模型中,SVM 的高校毕业生就业率预测总时间最长,预测效率最低,这是因为支持向量机采用结构风险最优化原则进行学习,每增加一个训练样本,就要重新训练一次,这样使得高校毕业生就业率预测的计算时间复杂度比较高。
3)GA⁃SVM 的高校毕业生就业率预测总时间要少于SVM,这是因为其采用遗传算法模拟生物界的进化理论可以找到较优的支持向量机参数,减少了高校毕业生就业率预测建模的训练时间。
4)本文方法的高校毕业生就业率预测建模效率最高,加快了高校毕业生就业率预测速度,这是因为蚁群算法可以更快找到最优的支持向量机参数,改善了高校毕业生就业率预测效率。
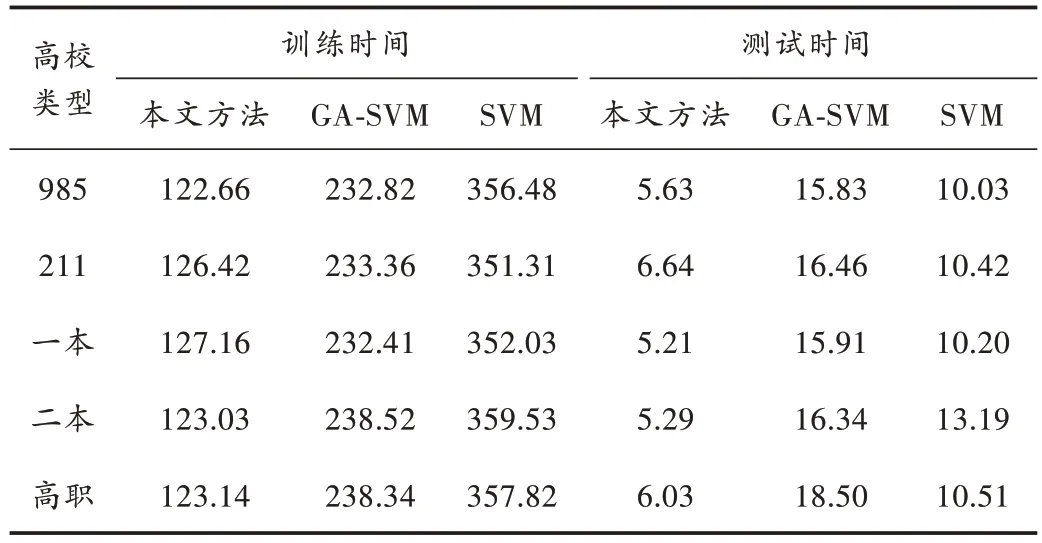
表4 不同方法的高校毕业生就业率预测建模时间 ms
3 结 语
高校毕业生就业率对高校学生的培养起着指导性作用,当前所有高校均关注高校毕业生就业率的情况,因此高校毕业生就业率直接影响到高校的招生,为了提高高校毕业生就业率预测精度,本文提出了基于数据驱动的高校毕业生就业率预测方法。首先采集大量的高校毕业生就业率历史数据,通过引入数据挖掘技术⁃支持向量机对高校毕业生就业率变化规律进行挖掘,并针对支持向量机在高校毕业生就业率预测过程的参数优化问题,引入了蚁群算法对支持向量机的参数进行优化,具体的高校毕业生就业率预测实例结果表明,本文方法不仅使得高校毕业生就业率预测误差更小,而且高校毕业生就业率预测建模的时间也更短,高校毕业生就业率预测的整体结果均优于其他对比预测方法,解决了当前高校毕业生就业率预测的缺陷,预测结果可以为高校招生就业管理部门提供有价值的参考意见,同时为复杂多变的高校毕业生就业率预测建模提供了一种新的研究思路。
猜你喜欢
疯狂英语·读写版(2023年5期)2023-06-01
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
意林(2020年15期)2020-08-28
意林·全彩Color(2019年7期)2019-08-13
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
创业家(2015年4期)2015-02-27
新闻前哨(2014年11期)2014-12-25
职业技术教育(2014年9期)2014-07-08
