
基于改进ReliefF与k-means算法的良恶性肺结节分类模型
2021-03-21 05:11朱英亮仇旭阳
小型微型计算机系统 2021年3期
朱英亮,仇旭阳,徐 磊
(上海理工大学 光电信息与计算机工程学院, 上海 200093)
1 引 言
如今,肺癌已严重威胁人类的身体健康,在中国,肺癌在发病率和死亡率方面在城市人群里居于第一位.由于肺癌早期症状不明显,容易发生误诊.在诊断不明而进行手术切除的结节中约有一半是良性.因此,进行早期地准确诊断并给出合理的治疗方案具有非常重大的意义.CT作为无创辅助诊断的一种重要手段,由于其非介入性、高分辨率等特点,在临床上被广泛使用.
肺癌在初期表现为结节症状,利用计算机辅助技术协助专家对肺部CT图像进行分析成为临床上的主要应用.
目前利用图像分析技术来辅助医生进行良恶性肺结节的诊断已在临床上得到了广泛的应用,也是当前医学图像分析领域的热门研究课题之一,很多学者提出了不同的算法模型进行良恶性肺结节的分类.Sangamithraa等人[1]利用灰度共生矩阵提取肺部结节的纹理特征,然后利用反向传播网络(BPN)完成良恶性肺结节的分类.Hien等人[2]提出了一种基于图像小细胞集的灰度密度分布特征提取算法,利用该算法提取肺部的灰度密度特征,最后用随机森林进行结节的分类. Akram Sheeraz等人[3]提出了一种基于混合特征的支持向量机(SVM)肺结节检测和良恶性分类系统.但是该方法易受阈值的影响.Duan[4]提出用高斯混合模型(GMM)将提取的结节特征分组,再利用Relief和前向选择算法找局部最优特征,最后用最优路径森林进行结节分类,达到平均89.8%的识别率.Yang[5]提出了一种新型的多判别生成对抗网络模型,该模型与编码器相结合,用于肺结节的良性和恶性分类,识别率达到了95.32%,但是运行时间过长以及网络复杂.Xie[6]等人一种基于多视角知识的协同(MV-KBC)深度学习模型,基于ResNet-50网络进行训练,恶性结节的识别率达到了95.7%,但是网络足够复杂,需求的数据集大,训练极为耗时,要求的硬件性能过高.
近些年来,在传统算法中灰度共生矩阵(GLCM)被各种研究表明是模式识别的有力基础,利用GLCM计算出的纹理属性有助于理解图像内容的细节,GLCM的使用比主成分分析法(PCA)具有更高的准确率[7].Raju[8]等人使用了一种高效的与GLCM属性相关的模糊C均值(FCM)分割算法,用于在超声肾图像中对肾囊肿和肿瘤进行分类.IUW Mulyono[9]等人利用灰度共生矩阵(GLCM)从parijoto水果中提取纹理特征,然后使用K最近邻(KNN)方法对它们进行分类.Swati Jayade[10]等人提出利用GLCM提取皮肤癌变区域的图像特征,将这些特征作为SVM分类器的输入来进行分类.Huang[11]等人利用灰度共生矩阵提取海洋涡旋的纹理特征进行海洋涡旋识别.Zhou[12]利用灰度共生矩阵提取肺部CT图像的9种纹理特征.但是良恶性肺小结节纹理区别主要在边缘[13].因此本文利用灰度-梯度共生矩阵(GGCM)提取肺部CT图像的14种纹理特征,并改进了灰度-梯度共生矩阵中提取边缘的算子.在此基础上,本文重点提出了一种基于新的距离度量的ReliefF算法使得重要特征能够让同类样本聚合,不同类样本分离,并且消除了样本差异化及数量的影响,进而计算出对应的纹理特征的权重值,最后将权值应用到改进的k-means算法中构建结节分类模型.本文所选数据集为LIDC,其中共有1018个研究实例.本文从中选取128个实例,这些实例统计共有452个肺结节(包括247个恶性结节,205个良性结节,根据XML文件获取结节良恶性信息).LIDC数据库中都有一个XML注释文件用来保存肺结节的主要特征信息,包含结节的恶性程度(良恶性结节),大结节(直径≥3mm)的轮廓坐标,小结节(直径<3mm)的中心点坐标等.从247个恶性结节中随机选取180个,205个良性结节中随机选取150个作为训练集,剩下的良恶性结节作为测试集.本文采用准确率和平均准确率两种指标来衡量提出算法对良恶性肺结节分类的准确性和有效性.
2 方 法
本文提出的方法主要包括以下4个步骤,并且算法流程图如图1所示.
1)运用中值滤波去除噪声和直方图均衡化对CT图像进行增强;
2)提取CT图像中肺结节区域;
3)运用改进的灰度-梯度共生矩阵提取肺结节ROI区域的纹理特征;

图1 本文算法流程图Fig.1 Algorithm flow chart
4)用改进的ReliefF和改进的k-means算法对纹理特征权重聚类,构建结节分类模型.
2.1 预处理
本文运用中值滤波和直方图均衡算法对CT图像进行滤波和增强.并对CT图像进行256级灰度转换,而后进行16级灰度压缩,图2为处理后的CT图像及其直方图.
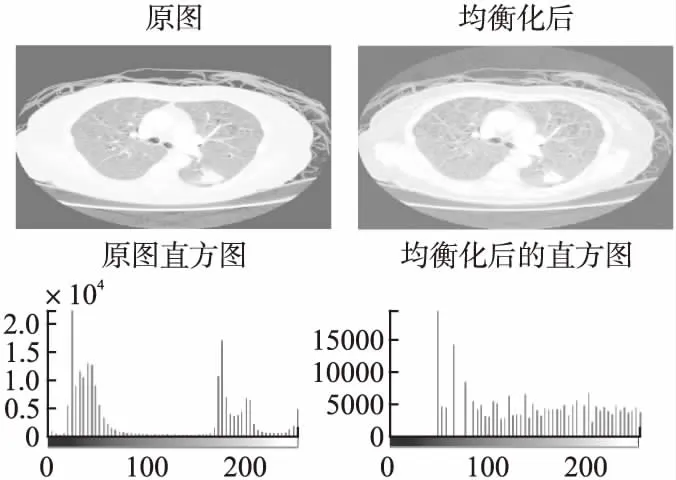
图2 预处理后的CT图像及其直方图Fig.2 Preprocessed CT images and their histograms
2.2 提取肺结节区域
本文所选用的肺结节CT图像数据的ROI(region of interest)区域是LIDC/IDRI数据库中已经划分好的,由4个放射学专家进行手动划分,并将ROI区域位置信息保存在XML文件中,XML文件包含了切片CT原始数据的所有信息,将XML中ROI区域信息读出后对肺结节进行分割,为后面的灰度-梯度共生矩阵提取肺结节特征做准备.如图3所示,白色的线所示区域即肺结节区域.
2.3 灰度-梯度共生矩阵的改进及纹理特征提取
对图像进行分类和识别最重要的就是对图像特征进行提取,然后选取相关性强的特征进行分类.图像的特征形式包括颜色、形状、纹理及空间关系等,利用纹理特征进行疾病的分析已在临床上得到了广泛的应用,是用于疾病诊断的重要辅助手段.其中利用灰度共生矩阵(GLCM)提取图像的纹理特征在特征分类中得到了较为广泛的应用,但是仅仅利用灰度共生矩阵来提取肺结节的纹理特性是不够的.因为良恶性小结节的纹理特性主要区别是边缘,因此灰度-梯度共生矩阵(GGCM)成为了一种更好的选择,但是其一般的做法是利用边缘算子例如Sobel和Canny等进行提取边缘来获取梯度信息,但是Sobel和Canny等算子容易造成边缘信息缺失.本文针对这一缺陷,提出了一种边缘检测算子,可以有效避免结节边缘信息的泄露,更好地提取纹理特性来进行良恶性结节的识别.假设图像为f,边缘检测算子(式(1))为:
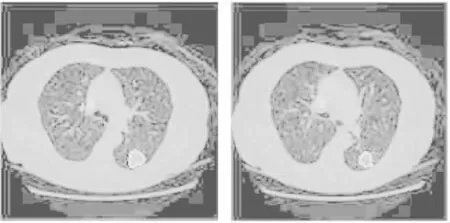
图3 CT图像中肺结节的ROI区域Fig.3 ROI of pulmonary nodules in CT images
(1)
其中Gσ是高斯核,σ为标准差,本文实验中φ=2.如图4所示为本文改进边缘检测算法应用在肺部CT图像上的效果.图4左侧为Sobel算子的检测结果,肺结节边缘发生泄漏;右侧为本文提出算法的检测结果,结节边缘信息完整.这能够让灰度-梯度共生矩阵提取更完整的结节边缘信息,得到更全面的纹理特征.本文利用改进的灰度-梯度共生矩阵提取肺结节区域的小梯度优势、大梯度优势、灰度分布不均匀性、梯度分布不均匀性、能量、灰度平均和梯度平均等14个相关的纹理特征,并且按照测试样本与训练样本3:1的比例,随机选择部分数据作为测试样本,分别用灰度-梯度共生矩阵提取

图4 CT图像边缘检测算法对比Fig.4 CT image edge detection algorithm comparison
14个相应的特征纹理数据,然后将这些进行平均化处理得到相应的良性和恶性结节的14个纹理特征数据的对比图,如图5所示.从图中可以看到,灰度-梯度共生矩阵提取的纹理特征中有些特征例如灰度差、小梯度优势、相关性等特征就能很好区分良恶性肺结节(由于改进了边缘检测算子,因此梯度信息可以很好区分良恶性结节),而有些例如灰度平均、梯度平均等纹理特征就不能很好区分良恶性结节,因此需要在这14个纹理特征空间中剔除无关(区分效果不明显)的特征量,缩小特征空间.
2.4 特征选择算法及其改进
利用图像的特征进行分类或者检测时,需要将提取出来的特征进行一定程度上的冗余特征的去除.因为无关特征不仅会加大运算量和时间,而且会干扰分类的正确性.因此,如何从提取的众多特征中找出相关性最大的特征成为利用纹理特征进行结节分类的关键性的一步.由于Relief系列算法简单高效,使其得到了广泛的应用.并且没有数据类型的限制,

图5 良恶性结节纹理特征对比Fig.5 Comparison of texture characteristics of benign and malignant nodules Average feature weight curve
根据特征和类别之间的相关性的大小来给相应的特征分配不同大小的权重,并且将权重小于某个阈值的特征剔除,达到选取特征的目的,但是它只能处理两类别的数据.Kononenko[14]将Relief算法做了改进,使得能够处理多类别问题,即ReliefF算法.每次从训练集中随机选择一个样本R,从该样本的同类和不同类中各选择k个最近邻样本,然后根据式(2)计算特征I的特征权重:
(2)
式中,diff(I,Ri,Hj) 和diff(I,Ri,Mj(C)) 为两样本在特征I上的欧式距离,用来表征两样本的相似程度,因此ReliefF算法的核心思想主要是让重要的特征(分配的权重系数尽可能大)使得同类样本尽可能靠近,不同类的样本尽可能远离,达到更好地分类效果.
Huang[15]提出特征选择的准确度与训练集样本的数量是呈正相关的.在实际情况中,不同特征所对应的样本数量是不一样的,并不是均匀分布的.并且每次算法运行时选中的样本点都不相同,因此属性权值必会波动,也就是需要考虑样本间的差异.因此本文提出改进的ReliefF算法.
假设一个训练样本集含有N个类别,则特征I的特征权重计算式为:


(3)
式(3)为本文改进的算法.其中Ldist的计算公式为:
(4)
在式(4)中,uc为与样本R同类别样本的中心,uj为与R不同类别的样本中心,实验中δs=0.5,δd=1.5.本文用新的距离计算方法取代欧式距离的计算方法,式(4)中第1项能使同一类别的样本尽可能靠近,第2项能使不同样本尽可能相离,这样使得相关性强的特征能有效地进行分类.与此同时为了消除ReliefF算法中样本数量对特征权值的影响,在计算特征权重时,考虑类别数N和样本数Aj以及不同类的最近邻样本M,使得特征权重评价更加均衡.
为了消除其他特征分量的噪声干扰,对样本Ri在更新特征I的权值时,近邻样本的选择以该维特征分量上的距离为准则,那么样本间的距离可表示为式(5):
(5)
通过以上分析可知,本文改进的ReliefF算法使得特征权重分配更加均衡,新的距离计算公式使得重要特征能让同类样本更加聚合,不同类样本相互分离,达到了更好的分类效果.另外本文综合考虑样本数量不均匀所带来的权重值计算的缺陷,同时也减小了不相关特征的噪声影响,使近邻样本的选择更准确.
本文实验数据来自UCI机器学习数据库,选取数据类型为威斯康星州乳腺癌数据集(Breast Cancer Wisconsin (Original) Data Set),此数据集有699个样本,每条数据有11个属性,但是可以用于提取的只有9个特征.在训练集上用ReliefF、Zhou[12]提出的W-ReliefF和本文算法进行特征选择的对比实验.根据式(4)随机选取k个近邻样本,由于随机k值的不同将导致不同的特征权重,因此本文采取平均值的方法,将3个算法各运行10次,最后取10次权重结果的平均值作为最后的特征权重系数.各个属性权重的大小分布如图6所示.由图6所示,ReliefF算法的平均特征权值从大到小为1>6>3>8>7>5>2>9>4,W-ReliefF算法的平均特征权值从大到小为1>7>5>8>3>9>6>2>4,本文改进算法的平均特征权值从大到小为1>8>5>7>9>3>6>2>4.从图6可以明显看出属性9的平均权值在3种方法当中变化小.因此选定属性9作为权重阈值的边界,因此可以明显得到W-ReliefF在ReliefF的基础上将属性6剔除了,而本文算法在W-ReliefF的基础上将属性3剔除了,因此本文提出的算法进一步压缩了属性空间,而且剔除了倾向于占大多数的良性样本的属性3和6,保留了重要的属性特征.

图6 平均特征权值曲线图Fig.6 Average feature weight curve
为了进一步验证本文提出的改进的ReliefF算法的有效性,从UCI数据库中随机选取8个用于分类并且类别数不少于2的样本作为训练集进行实验.表1为所选的训练集的信息.
由于训练集样本中各类别的样本数量分布不一样,可以用表1的不平衡度来进行描述,可表示为式(6):

(6)
其中分子表明各个类别最大样本数与最小样本数之差(Nc为每个类别包含的样本数),分母表明每个类别的平均样本数(n为样本总数,N为类别总数).式(6)表明各个类别最大与最小样本数占每个类别具有的样本数的比例之差,可以反应类别数据的分布情况.在数据集上分别运行ReliefF、W-ReliefF和本文改进的算法各20次,然后求出每个属性平均权重系数,进行比较后,选出有效的属性.最后运用k-means算法对特征选择后的有效属性进行分类,求出分类准确率,结果如表2所示,图7为特征选择结果.

表1 所选训练集概况Table 1 Overview of the selected training set

表2 特征选择前后的分类准确率比较Table 2 Comparison of classification accuracy before and after feature selection
由图7可知,本文算法会使得数据集特征空间减小,去除相关性小的特征,并且效果比W-ReliefF和ReliefF算法好.表2中给出经过两种算法进行特选择后再利用k-means分类的准确率对比,带有“↑”符号的,表示准确率上升明显,“↓”符号的表示准确率有所降低.数据表明利用本文算法进行特征选择后,识别准确率明显提高的有6组数据,比其他算法的识别准确率都要高.本文改进的ReliefF算法比W-ReliefF算法效果更好,原因是本算法不仅考虑了样本中各类别数的不均衡度,平衡了各特征权重系数的分配.而且在此基础上利用重要的特征能使得同类样本聚集,不同样本尽可能分开的特性,重新设计了距离选择公式.并且改进了近邻样本选择的标准,更好地去除了冗余特征,使得识别的准确率更高.

图7 特征选择结果图Fig.7 Feature selection result graph
2.5 聚类算法k-means及其改进
聚类算法是将一堆数据按照它们各自的特性分为几个类别,它是一种无监督学习,使得同一类别中的数据相似性尽可能大,不同类别中的数据差异性尽可能大.k-means算法因其效率高、原理简单,实现容易等得到了广泛的应用.由于聚类算法是根据特征间的相似度来划分的,因此,一般将内部特征间差异的相似度作为一个很重要的衡量指标,一般定义样本点到数据中心点之间的距离的方法来描述数据之间的差异性[16].
k-means算法是基于欧式距离,该算法的核心公式为:
(7)

k-means算法的优点是效率高并且易于实现,但是也有一些的不足之处:
1)k-means算法以k为参数,需要事先人为设定好k值,也就是类别的个数,而k值的选定是难以估计的.然而本文研究的主要是良恶性结节的二分类问题,k值可以预先设定为k=2,因此可以忽略k值设定的影响.
2)k-means算法在聚类过程中,采用欧式距离来描述样本之间的相似度,这种描述方式是假设样本数据各个维度对于相似度的衡量作用是相同的,即没有考虑样本数据属性之间的差异.重新计算每个类的质心(即为聚类中心),重复这样的过程,直到质心不再改变,最后确定了每个样本的所属类别.因此算法的缺点是对类别规模差异太大的数据效果不好,并且对噪声和离群点十分敏感,对于不同权重系数的特征属性不能有效区分.因此本文对k-means算法做出对应的改进策略,使其更准确地进行良恶性结节的分类.
针对k-means算法的缺点,本文利用改进的ReliefF算法缩减样本数据的特征空间,并赋予特征相应的不同权重值.并将不同大小的特征权重引入k-means算法中,此时的k-means算法改变了数据各个维度对于相似度的衡量作用,可以很好的消除噪点和离群点的影响.另外本文引入改进ReliefF算法中的距离法则,同类样本尽可能靠近,不同样本尽可能分开的思想,因此本文改进的k-means算法(式(8))为:
(8)
权重在聚类过程中实现等值聚类起着至关重要的作用,且改进的k-means算法中的wi是一个非负数,是由本文改进的ReliefF算法得到的各纹理特征对应的权值wi.
在模式识别的过程中,分类就是将具有相同特性的样本归为一类,而具有另外共性的归为另一类.在医学图像的辅助诊断系统中,分类器可以用于病人病情决策.本文利用改进的ReliefF算法与改进k-means算法结合起来构建良恶性结节的分类器.
3 实验结果与讨论
对于提取的纹理特征利用改进的ReliefF算法计算特征权重,将权重大小进行比较分析,运行程序20次,统计结果如图8所示.由图8可知,灰度差、相关性、小梯度优势等特征的权重最大,权重大的特征是最主要的影响因素,从多次计算规律来看,不同的特征有不同的重要程度,因此有着不同大小的特征权重,选取多个特征的组合进行实验分析,本文将特征按照1-14进行编号.
本文利用改进的ReliefF算法对特征赋予权重的高低进行从大到小排序,并且选择相应的权重数据,再利用改进的 k-means算法进行聚类分析,实验结果如表3所示.

表3 应用不同属性组合分类成功率Table 3 Success rate of classification by applying different combinations of attributes
从表3的实验结果可以看出,选择特征权重最大的8个属性(灰度差、梯度差、能量、小梯度优势、相关性、灰度熵、混合熵、逆差矩)用于结节分类,分类的正确率是最高的,同时实验结果表明特征权重小的属性会增加特征空间的维度,影响分类的精度.因此利用灰度-梯度共生矩阵提取出的纹理特征可作为良恶性结节分类的选择特征.在此基础上,本文将最大的8个纹理特征权重加入到改进的k-means算法中去,构建一个结合了改进ReliefF以及改进的k-means算法的良恶性结节分类器.本文提出的良恶性结节分类器是基于纹理特征进行识别的,实验结果如表4所示.

表4 肺结节分类准确率Table 4 Classification accuracy of pulmonary noclules
由表4可以看出,根据纹理特征可以进行良恶性肺结节的识别,实验结果表明:本文提出的算法对于恶性结节识别率高,良性结节识别率良好,并且改进的ReliefF和k-means算法均有效,准确率都有一定提升.如表5所示,本文将提出的算法与其他算法的识别率进行了比较,从比较结果中发现本文提出的算法相比其他传统算法较优,使得良性结节的识别率有了一定的提升.但相对于文献[6]提出的多视角知识的协同(Multi-View Knowledge-Based Collaborative)深度学习模型存在差距,原因是此方法ResNet-50网络来提取结节的外观、体素和形状特性,然后再利用基于知识的协作(Knowledge-Based Collaborative)子模型进行分类.网络深度深,模型复杂度高. 文献[5]提出多将判别生成对抗网络模型与编码器相结合,用于肺结节的良性和恶性分类的算法也比本文识别率优,但是网络复杂,训练耗时.这些对于本文有进一步启发,下一步工作可以利用深度学习的网络提取肺结节不同视角的特征,再与编码器相结合,最后利用本文改进的方法进行分类.

表5 几种算法的比较Table 5 Comparison of several algorithms

图8 改进ReliefF算法计算20次属性的权重分布误差棒图Fig.8 Improved ReliefF algorithm calculates the error bar graph of weight distribution of 20 attributes
4 结 论
本文对肺部CT图像首先利用改进了边缘检测算子的灰度-梯度共生矩阵提取了14种纹理特征参数,然后通过改进的ReliefF算法使得分类作用大的特征将同类样本聚合,不同类样本分开,并且降低特征空间的维度.最后本文对k-means算法的距离度量进行改进,引入同类样本聚合、不同类样本分开的距离度量准则,将重要特征的权重引入到此算法中进行良恶性肺结节的分类.本文构建了从提取纹理特征到冗余特征去除再到分类的算法模型.并且在实验测试集上通过大量实验以及识别率对比得出不同纹理特征对于分类的贡献效果各不相同,纹理特征空间存在冗余特征,需要通过一定手段进行特征空间的压缩,本文实验发现灰度梯度共生矩阵提取的纹理特征中灰度差、梯度差、能量、小梯度优势、相关性等8个重要特征的组合可以得到最好的分类结果,本文算法可以达到良性结节83.46%,恶性结节95.02%的识别率.
猜你喜欢
兵器装备工程学报(2022年8期)2022-09-13
集装箱化(2021年1期)2021-04-12
中国信息技术教育(2020年2期)2020-02-02
保健与生活(2019年7期)2019-07-31
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
小资CHIC!ELEGANCE(2018年33期)2018-11-08
西部资源(2018年1期)2018-11-01
Coco薇(2017年8期)2017-08-03
中学生数理化·高三版(2016年9期)2016-05-14
