
一种用于图形渲染的高性能SpMV专用加速器结构
2021-03-22 01:38邓军勇马青青
小型微型计算机系统 2021年3期
邓军勇,马青青
(西安邮电大学 电子工程学院,西安 710121)
1 引 言
稀疏矩阵向量乘法(Sparse Matrix-Vector multiplication,SpMV)在科学计算中有广泛应用[1],例如图形渲染中涉及的几何变换、投影变换、视口变换等需要大量的稀疏矩阵向量运算.目前,图形渲染中的SpMV运算仍存在并行度较差,资源占用较多,访问开销较大的问题.因此,如何实现SpMV高性能计算成为了图形处理器设计中的关键性问题之一.
目前的SpMV优化方法有很多,Liu等[2]在CSR(Compressed Sparse Row)格式的基础上提出了CSR5格式,对于只有数十次迭代的求解器之类的实际应用,CSR5格式由于格式转换的开销较低而更加实用.Merrill等[3]提出了一种“基于合并”的CSR格式并行方法,此方法可提供高性能,而无需格式转换或扩充,而且基本上不受行长异质性的影响.Grigoras等[4]设计了一种非零压缩算法,该算法可以减少冗余非零值,从而在不降低计算效率的情况下利用备用FPGA资源来克服基于FPGA的SpMV实现中的存储器带宽限制.Han等[5]提出了一种高效节能推理引擎(EIE),EIE以CSC(Compressed Sparse Column)的变体格式按列存储稀疏矩阵使运算变得简单,但是,其预处理开销较大,且由于每个PE在特定列中可能具有不同数量的非零元素,因此,此运算过程可能会遇到负载不平衡的情况.
杨等[6]在现有的BRC(Blocked Row-Column)数据结构基础上提出了BRCP(Blocked Row-Column Plus)存储格式,采用了不同的二维分块策略,根据稀疏矩阵的特性自适应地调节分块参数,实现了SpMV在GPU上的并行性.程等[7]提出一种稀疏矩阵的存储格式HEC(Hybrid ELL and CSR),该存储格式由ELL(ELLPACK)与CSR格式混合而成,可提高稀疏矩阵的存储效率,减少SpMV的运算时间.邓等[8]提出一种用于图计算的稀疏矩阵压缩方法,每个稀疏列经预处理电路独立压缩成CSCI格式,其中包括列标识数据对和非零元素数据对,此压缩方法可以提高图计算的并行性和能效.Xie等[9]提出一种称为CVR(Compressed Vectorization-oriented sparse Row) 的SpMV表示形式,CVR可以同时处理输入矩阵中的多行以提高缓存效率,此方法对SpMV的稀疏性和不规则性不敏感,有较小的预处理开销,具有更低的缓存未命中率,同时CVR的控制较复杂,相关控制参数超过30个.
针对SpMV高性能计算,现有的研究优化方法都从一定程度上解决了资源占用较多,并行度较差的问题.但是,由于预处理开销、访问开销较大和数据相关性,要做到同时兼顾并行度和资源占用率还是有一定难度的.于是,本文充分利用数据的并行性,基于矩阵列向量的线性组合,设计了一种用于图形渲染的高性能SpMV专用加速器结构,并将传统矩阵运算结构、EIE运算结构与本文所设计的运算结构做对比,以测试其应用于图形渲染的变换操作时的优化效果.
2 研究背景
2.1 图形渲染中的变换操作
图形渲染中包含了大量的变换操作,如几何变换、投影变换、视口变换等[10].几何变换通常指模型变换或视图变换(二者合称模型视图变换),完成场景对象由模型坐标系向视觉坐标系的转换.几何变换包括平移、旋转、缩放变换,假设顶点坐标为p=(px,py,pz,1),则平移变换过程如式(1)所示:
p′=T(t)·pT=(px+tx,py+ty,pz+tz,1)
(1)
由公式(1)可以看出平移变换矩阵如式(2)所示:
(2)
旋转变换根据坐标轴不同分为绕x轴、y轴、z轴的旋转,假设旋转角度为φ,则绕x轴的旋转变换矩阵如式(3)所示.
(3)
缩放变换矩阵如式(4)所示,当某个参数大于1.0,则沿对应的坐标轴拉伸物体;小于1.0,则收缩物体.
(4)
根据投影中心与投影平面之间距离的不同,投影可分为透视投影和正射投影.其中透视投影变换可看作是两个基本变换,即世界坐标系到视点坐标系的变换和视点坐标系到屏幕坐标系的变换[11],透视投影变换矩阵如式(5)所示:
(5)
视口是指经过几何变换后的物体显示于屏幕窗口内的指定区域,在图形渲染流程中经视口变换可以得到窗口坐标,窗口坐标显示了屏幕中的像素相对于窗口左下角的位置[10],视口变换矩阵如式(6)所示:
(6)
不管是几何变换还是投影变换和视口变换,其核心计算都是SpMV,而图形渲染中存在着大量的几何变换、投影变换和视口变换等,但由于SpMV运算时数据之间存在的相关性和不规则的内存访问引发的内存开销,使其性能大大降低.因此,SpMV性能的优化,将成为图形渲染性能优化的关键.
2.2 现有矩阵向量运算结构
现有的矩阵向量运算结构有很多,如前文中提到的CSR5、CVR、EIE等,本文将选择传统矩阵向量运算结构和EIE运算结构与本文所设计的运算结构做对比,以测试其优化效果.
2.2.1 传统矩阵向量运算结构
对于传统的矩阵向量乘法,其运算方式如式(7)所示,矩阵的每一行分别与向量做乘法和加法运算,得到最终的结果向量.该算法都是串行计算,效率很低,本文在此算法的基础上,寻找到了一些在计算时没有相关性的数据,使算法能够并行运算,从而提高矩阵向量运算的效率.
(7)
2.2.2 EIE运算结构
压缩稀疏行(CSR)是存储稀疏矩阵的最常用格式[12],与其类似的还有压缩稀疏列(CSC)格式.文献[5]中提出的一种高效节能推理引擎(EIE)对压缩的网络模型进行推理,并通过权重共享来加速稀疏矩阵向量乘法.EIE以压缩稀疏列(CSC)的变体格式存储编码稀疏权重矩阵W,通过在多个处理元素(PE)上交织矩阵W的行来并行化矩阵矢量计算,每个PE都有自己的v,x和p数组.此结构通过扫描矢量a来找到非零值aj并将aj及其索引j广播到所有PE,然后每个PE将aj乘以其对应Wj中的非零元素,并在累加器中累加各部分的和,最后输出激活向量b的每个元素.表1显示了EIE中PE0对应的CSC表示形式

表1 PE0对应的CSC表示形式Table 1 CSC representation of PE0
.
以CSC格式按列存储稀疏矩阵使运算变得简单,只需将每个非零激活值乘以其对应列中的所有非零元素即可.但是,其预处理开销较大,且由于每个PE在特定列中可能具有不同数量的非零元素,因此,此运算过程可能会遇到负载不平衡的情况.
3 基于矩阵列向量线性组合的加速器结构
本文基于线性代数关于矩阵列向量的线性组合思想,提出了一种用于图形渲染的高性能SpMV专用加速器结构.该结构充分利用数据的并行性,提升了矩阵向量相乘的运算速度,由于图形渲染中存在大量的SpMV运算,因此该结构将会使图形渲染的效率大大提高.
3.1 算法思想
并行计算可以提高SpMV的运算效率,想要实现并行计算就要挖掘矩阵向量运算过程中存在的数据并行性,即运算可以同时进行而不存在数据相关.矩阵向量相乘的数学运算方式——矩阵列向量的线性组合为此提供了思路,其运算方式如式(8)所示:矩阵M可以分为4个列向量,向量v中的每一个元素与其对应列相乘,最后相乘的结果再相加得出最后的结果向量.此算法充分利用了数据的并行性,使大量的乘法和加法操作可以同时进行,也可以减少数据的不规则访问.
(8)
3.2 加速器结构
图1是根据矩阵列向量的线性组合思想所设计的SpMV专用加速器结构,主要包括控制器、乘法器、加法器和寄存器.A0、A1、A2、A3寄存器分别存储4×4矩阵A的4列,B0、B1、B2、B3寄存器分别存储4×1向量B的4个元素,控制器每隔一拍向寄存器组传输矩阵A的一列和向量B的一个元素,对应的列和元素相乘得出中间向量,分别寄存在T0、T1、T2、T3寄存器中,4个中间向量两两相加分别寄存在S0和S1寄存器中,S0和S1中向量相加即得出最终的结果向量.

图1 矩阵列向量的线性组合运算结构图Fig.1 Structure of linear combination of matrix column vectors
此加速器使矩阵的4列能够并行计算,整体采用流水线结构,能够大幅度提升矩阵向量运算的速度,并且每一列只和向量中的一个元素进行运算,大大减少了向量中元素的访问量和访问不规则问题.
3.3 算法应用
本设计不仅实现了基于矩阵列向量线性组合的加速器结构,还将传统矩阵向量运算结构和EIE运算结构用verilog实现,并且这3种运算结构都采用4×4的矩阵规格和4×1的向量规格,便于比较.由2.1节我们可以知道图形渲染中变换操作的核心计算是SpMV,提升SpMV的运算性能对于提升图形渲染的运算性能具有很大的意义.因此,我们将几何变换中的平移、旋转、缩放变换及投影变换和视口变换的矩阵格式都应用于上述3种运算结构,矩阵格式如式(2)-式(6)所示,以比较在面对不同的矩阵格式时,哪一种运算结构的性能更佳.
4 实验结果及分析
4.1 验证策略
为验证运算结构的正确性,本文使用modelsim仿真工具对用verilog实现的3种运算结构及其在3种图形渲染变换操作上的应用算法进行基本功能验证,查看经3种变换操作得到的视觉坐标、屏幕坐标、窗口坐标是否正确.为验证运算结构的性能,本文使用Xilinx公司的综合工具ISE,在XC6VLX550T开发板上进行综合,查看3种运算结构及其应用在3种变换操作时的运算性能和资源占用情况等.
4.2 实验结果
不管是哪一种运算结构都存在大量的乘法和加法运算,因此,乘法和加法必然成为了运算过程中的瓶颈.为优化运算结构的性能,运算中的乘法和加法操作都调用乘法器和加法器IP核来实现.经modelsim仿真验证,本文设计的SpMV专用加速器结构在输入数据后经过16个时钟周期,输出了正确的坐标向量,传统运算结构和EIE运算结构分别经过15和22个时钟周期得到正确的坐标向量,将3种运算结构应用于3种图形渲染变换操作后也都得出了正确的坐标向量.
4.3 性能分析
将本文提出的SpMV专用加速器结构与传统运算结构和文献[5]中的EIE运算结构都用verilog实现,综合后得出的速度和资源占用情况对比如表2所示.可以看出,在相同的

表2 3种运算结构的速度和资源占用情况对比Table 2 Comparison of speed and resource occupation of three computing structures
FPGA上,本文设计的基于矩阵列向量线性组合的加速器结构与传统运算结构相比,速度能够提高28%,资源占用率减少约48%;与文献[5]中的EIE运算结构相比,速度能够提高37%,资源占用率减少约18%.
实现了上述3种运算结构后,将几何变换中的平移、旋转、缩放变换及投影变换和视口变换的矩阵格式都应用于3种运算结构,经仿真验证功能正确后进行综合,3种几何变换的应用经ISE综合后的速度和资源占用情况分别如表3、表4、表5所示,投影变换和视口变换的应用经ISE综合后的速度和资源占用情况分别如表6、表7所示.

表3 应用于旋转变换的速度和资源占用情况对比Table 3 Comparison of speed and resource occupation applied to rotation transformation

表4 应用于缩放变换的速度和资源占用情况对比Table 4 Comparison of speed and resource occupation applied to scaling transformation

表5 应用于平移变换的速度和资源占用情况对比Table 5 Comparison of speed and resource occupation applied to translation transformation
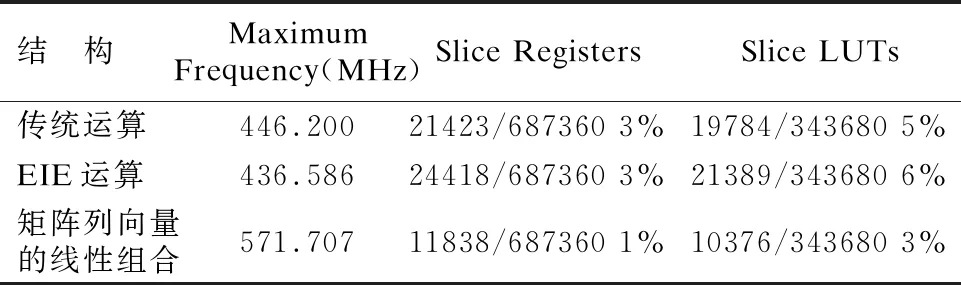
表6 应用于投影变换的速度和资源占用情况对比Table 6 Comparison of speed and resource occupation applied to projection transformation

表7 应用于视口变换的速度和资源占用情况对比Table 7 Comparison of speed and resource occupation applied to viewport transformation
从表中可以看出,应用于图形渲染的变换操作后,本文设计的基于矩阵列向量线性组合的加速器结构与传统运算结构相比,速度依旧能够提高28%,与文献[5]中的EIE运算结构相比,速度平均能够提高30%.应用于旋转变换后,本文设计的基于矩阵列向量线性组合的加速器结构与传统运算结构相比,资源占用率减少约46%,与EIE运算结构相比,资源占用率减少约60%;应用于缩放变换后,本文设计的基于矩阵列向量线性组合的加速器结构与传统运算结构和EIE运算结构相比,资源占用率分别减少约43%、52%;应用于平移变换后,资源占用率分别减少约47%、58%;应用于投影变换后,资源占用率分别减少约48%、52%;应用于视口变换后,资源占用率分别减少约46%、58%.
由此可以看出,不管是哪一种变换的应用,本文设计的SpMV专用加速器结构在运算时的速度和资源占用都优于传统运算结构和EIE运算结构.
5 结 语
本文针对图形渲染中SpMV计算量大,并行度较差,资源占用较多,访问开销较大的问题,从硬件实现角度出发,充分挖掘了数据的并行性,运用线性代数关于矩阵列向量的线性组合思想,设计了一种用于图形渲染的高性能SpMV专用加速器结构.此加速器整体采用流水线结构,使大量的乘法和加法操作可以同时进行,大幅度提升了矩阵向量运算的速度,也可以减少数据的不规则访问.实验结果表明,与传统矩阵运算结构、文献[5]中的EIE运算结构相比,本文设计的加速器结构在应用于图形渲染的变换操作时运算速度较快,资源占用率较低,在用于图形渲染的高性能SpMV运算方面具有一定的优势.
猜你喜欢
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
现代仪器与医疗(2022年3期)2022-08-12
新高考·高一数学(2022年3期)2022-04-28
读与写·教育教学版(2017年10期)2017-11-10
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
