
一种半监督学习的代码自动生成性能评估方法
2021-03-22 01:39张晓江
小型微型计算机系统 2021年3期
张晓江,姜 瑛
(昆明理工大学 云南计算机技术应用重点实验室, 昆明 650500) (昆明理工大学 信息工程与自动化学院, 昆明 650500)
1 引 言
如何有效地提高软件开发的效率和质量,是软件工程领域关心的核心问题.一直以来,许多研究者都通过改善软件开发方法和运用技术手段来提高软件开发的自动化水平.其中,代码自动生成技术指利用某些技术自动地生成软件源代码,达到根据程序员的需求自动编程的目的.代码自动生成技术被认为是提高软件开发自动化程度和质量的重要方法,受到学术界和工业界的广泛关注.
以 GitHub 和 Stack Overflow 为代表的开源网站和开源社区的发展,给研究人员提供了大量高质量的源代码.这些代码中隐含着许多知识,将这些知识用于软件开发中,使得大规模代码的学习成为可能.通过使计算机理解源代码中的语义信息和结构信息,并借助计算能力的增长和深度神经网络,代码补全、基于功能描述的代码自动生成、基于输入输出的代码自动生成等成为当前的研究热点[1].
目前,代码自动生成技术的部分研究已应用到实际开发中,依据某种代码生成方法实现的代码自动生成工具通常以插件的形式嵌入到集成开发环境中.例如,IntelliJ IDEA、Eclipse、PyCharm等集成开发环境都支持嵌入的代码自动生成插件,以帮助程序员提高开发效率.在应用代码自动生成工具编程的过程中,需要程序员和代码自动生成工具相互配合来完成编码工作.代码自动生成工具根据程序员的输入及当前代码语义环境生成代码,生成的代码出现在IDE(Integrated Development Environment)的代码推荐框中,程序员根据需要在代码推荐框中进行代码选择.此外,程序员也可能对选择的生成代码进行修改、删除等操作.
代码自动生成技术的目的是为了提高软件的开发效率.而在代码自动生成过程中,程序员的开发效率很大程度上是由代码自动生成的性能来决定的.代码自动生成的性能指代码自动生成过程中所占用的时间空间以及代码自动生成的规模和效率.通过对代码自动生成的性能评估,可以对比不同模型生成代码的质量,分析影响生成代码性能的因素.目前代码自动生成的相关研究越来越多,但是很多研究者只是针对代码生成模型进行不断改进,忽略了代码自动生成过程中由程序员和代码自动生成工具相互作用而产生的性能问题.实际上,代码自动生成的性能取决于代码自动生成工具以及程序员的行为.
本文通过分析程序员行为与代码自动生成工具行为的交互特征,结合半监督学习方法与深度神经网络提出了一种代码自动生成性能评估方法,并且分析了代码自动生成过程中性能类别与程序员行为以及代码自动生成工具行为之间的关系.
2 相关工作
在现有研究中,用来评估代码自动生成性能的指标主要包括Precision(精确率)、Recall(召回率)、MRR(Mean Reciprocal Rank)、F-Measure[2].如果代码自动生成工具推荐的是排序后的K个结果,可以使用Top-K的Precision、Recall、MRR、F-Measure对代码自动生成性能进行评估.
1)Precision:又称查准率,指代码自动生成工具正确推荐的代码数目占代码自动生成工具推荐代码总数的比例,计算如公式(1)所示:
(1)
式(1)中,Actual_code(i)代表第i次程序员真实需要的推荐代码,Recom_code(i)代表第i次代码自动生成工具推荐的代码.
2)Recall:又称查全率,定义为代码自动生成工具正确推荐代码数目与程序员真实需要的推荐代码总数之间的比例.
(2)
式(2)中的各变量含义同式(1).
3)MRR:体现代码自动生成工具推荐代码结果的优劣情况,靠前的结果较优,评分越高.第1个推荐代码成功推荐,则分数为1;第2个推荐代码成功推荐则分数为0.5;第n个推荐成功分数为1/n;若没有推荐成功分数为0.计算如公式(3)所示:
(3)
式(3)中,K为代码自动生成次数,rank(i)为第i次正确推荐代码所在推荐列表中的位置.
4)F-Measure:是Precision和Recall的加权调和平均.
(4)
在代码自动生成性能评估中,通常将Precision和Recall视为同等重要,所以将式(4)中的β设为1,就是最常见的F1-Measure.
在基于机器学习的代码自动生成的研究过程中,Hindle A等人[3]将传统的N-Gram模型应用到代码自动生成的研究中,使用语言模型N-Gram进行代码预测,实验通过MRR评估代码自动生成的性能,MRR评估指标为51.88%.Hellendoorn VJ等人[4]在语言模型的基础上加入“缓存”机制来维护程序的局部信息,通过对比循环神经网络与带有“缓存”机制的N-Gram,发现代码的局部性特征对于token的预测有极大的帮助,使用循环神经网络进行代码预测时MRR评估指标为67.5%,而带有“缓存”机制的N-Gram模型MRR评估指标为69.3%.
Nguyen TT等人[5]引入了一种统计语言模型SLAMC(A Novel Statistical Semantic Language Model For Source Code),在语言模型的基础上加入“缓存”机制来维护程序的局部信息.实验结果表明,加入“缓存”机制的模型捕获了源代码中的局部规律,实验使用Top-K的Precision对模型生成代码准确性进行评估,Precision在Top-1中达到64.00%、Top-5达到78.20%.Raychev V等人[6]使用N-gram模型与循环神经网络结合,在JavaAPI调用级别进行代码补全,利用N-Gram模型对程序中的API 调用序列建模,从而对API的调用序列进行预测.该研究通过分析Top-K个推荐代码的Precision来评估模型的效果.Tu Z等人[7]同样针对N-Gram模型忽略的程序局部特征,在语言模型中加入了缓存机制,其附加的缓存组件通过捕获软件的局部性,从而改进了N-Gram方法,其中MRR评估指标为54.44%,Top-1中Precision为52.04%,Top-5中Precision为57.45%.Raychev V 等人[8]基于循环神经网络,将程序代码的抽象语法树的序列化结果作为训练数据集,并将网络输出结果区分为终结符的预测和非终结符的预测,该方法在一定程度上运用了存在于抽象语法树中的结构化信息,进一步提升了与生成代码相关的非终结符预测的准确性,该研究使用Top-K个推荐代码的Precision来对模型生成代码性能进行评估.
Allamanis M等人[9]提出了专门为方法命名问题设计的神经概率语言模型的源代码,该模型通过在一个高维连续空间中将名称分配到称为嵌入的位置,以一种具有相似嵌入的名称倾向于在相似的上下文中使用的方式来了解哪些名称在语义上是相似的,并通过F1-Measure评估模型的性能.之后,Allamanis M等人[10]基于图网络学习代码中的结构以及语义特征,利用图模型中的不同边表示代码token之间的结构和语法关系,实验中F1-Measure评估指标为44.0%.
在当前代码自动生成的相关研究中,缺乏针对代码自动生成性能的统一评估方法.部分研究用Precision、Recall、MRR、F-Measure作为评估代码自动生成性能的指标,但这些指标仅基于代码自动生成个数以及生成代码的正确性来进行计算.在实际开发中,代码自动生成的效果不仅仅由代码自动生成工具决定,程序员的行为在其中也起到了较大的作用.现有评估方法忽略了程序员行为在代码自动生成过程中的重要性,只是针对代码自动生成结果进行了评估.此外,由于大部分研究采用不同的评估指标,且各指标之间无法直接转化,难以对各种代码自动生成模型和方法进行对比.因此,针对代码自动生成过程进行性能评估是亟待解决的问题.
本文综合程序员以及代码自动生成工具在代码自动生成过程中的作用,提出了一种基于半监督学习的代码自动生成性能评估方法.通过采集程序员行为与代码自动生成工具行为的相关数据来抽取代码自动生成过程中影响性能的特征,利用半监督学习对代码自动生成过程中的相关特征数据进行聚类分析从而确定性能类别;根据与性能相关的特征数据以及对应的性能类别来训练代码自动生成性能评估模型,从而分析代码自动生成性能、程序员行为与代码自动生成工具行为在代码自动生成过程中对性能的影响程度.
3 针对程序员行为与代码自动生成工具行为相关数据的重要特征提取
代码自动生成的性能包括程序员编程的性能和代码自动生成工具的性能,因此影响代码自动生成过程性能的数据主要包括程序员行为数据和代码自动生成工具行为数据.
3.1 与性能相关的基本特征
在代码自动生成过程中,有时代码自动生成工具生成了符合逻辑的代码,但并不符合程序员的预期,那么这段代码在实际使用中也是性能较差的.因此,与性能相关的基本特征由程序员行为和代码自动生成工具行为共同决定.若能抽取所有与性能相关的特征,则可以分析出代码自动生成过程中的所有性能问题.但是,考虑到性能数据收集过程中产生的程序扰动以及软硬件开销,本文主要关注与性能相关的基本特征.
代码自动生成工具会根据程序员的输入代码自动生成代码,而程序员的输入代码决定着代码自动生成工具生成代码的内容.程序员输入代码的长短可能会导致生成不同的代码,而程序员错误的输入甚至会导致代码自动生成工具生成不相关的代码.所以程序员的输入在很大程度上影响着代码自动生成工具的性能.
代码自动生成工具为程序员更高效的完成编码工作提供了辅助,程序员选中的生成代码代表着实际开发中需要的代码,同时也反映了代码自动生成工具生成代码的正确性.此外,程序员选择生成代码过程中的按键次数可以反映出程序员需要的代码在代码推荐列表中的位置以及代码自动生成工具生成代码的准确率.程序员在选择生成代码之后发生的删除或纠正代码行为表示程序员虽然选择了生成代码,但生成代码需要经过修改才能达到程序员的期望.
程序员当前已经编写好的代码可视为代码上下文,代码自动生成工具会根据代码上下文进行代码自动生成.因此,代码上下文的复杂度以及代码上下文的语义环境决定了代码自动生成的内容,清晰的代码上下文结构更有助于生成高质量的代码.在代码自动生成工具每次向程序员推荐的代码中,程序员是否选择生成代码决定了生成代码是否成功推荐.现有工具在提供代码生成功能时,通常将生成的代码添加到IDE的代码推荐框中,然后程序员根据自己的实际需要选择相应的生成代码.因此,自动生成的代码在代码推荐列表中的位置及生成时间尤为重要,它将直接影响程序员的按键次数以及等待时间,从而进一步影响开发效率.由于编写代码具有很大的灵活性,因而代码自动生成工具生成代码的数量可以为程序员提供多种解决方案.

表1 代码自动生成性能基本特征Table 1 Basic characteristics of automatic code generation performance
综上所述,本文定义了程序员行为、代码自动生成工具行为与代码自动生成性能相关的基本特征,如表1所示.
3.2 与性能相关的复杂特征分析及处理
除了3.1中提出的与性能相关的基本特征,由于代码中存在大量程序员自定义的修饰符,导致代码自动生成工具推荐的代码在语义上符合程序员的需要,但是实际代码并不一定完全与程序员需要的代码相同.所以,程序员的删除行为或生成代码是否被程序员选择等信息并不能完全衡量代码自动生成过程的性能.因此,将程序员选择代码与生成代码之间的语义相似度作为一个与性能相关的重要特征.
为了得到选择代码与生成代码之间的语义相似度,本文用Word2Vec[11]对代码token进行向量化表示.Word2Vec在一个连续空间中为每个词语产生一个对应的分布式向量,可计算词语之间的相似度.本文应用Word2Vec的这一特性来评估代码自动生成工具生成的代码与程序员所需代码之间的相似性.Word2Vec主要包括CBOW(Continuous Bag-of-Words Model)[12]和Skip-Gram[13]两种模式,其中CBOW是从原始语句推测目标词,Skip-Gram是从目标词推测出原始语句,实践表明CBOW对小型语料效果较好,而Skip-Gram在大型语料库中表现更加出色.因此本文使用Skip-Gram模型为代码训练一种分布式的向量表示.
训练词向量之前需要大量分词后的优质代码语料.在构建代码语料的过程中,由于代码文件通常包含大量的自然语言注释,将影响词向量以及代码分词的效果.本文使用抽象语法树(Abstract Syntax Tree,AST)对代码进行解析并进行数据清洗,校验代码语料语法是否规范,并利用AST构建代码词典.
3.2.1 数据清洗
为了避免代码语料中存在的自然语言注释以及语法不规范等问题对词向量的构建产生影响,我们使用AST对代码语料进行解析,通过AST结构的完整性来检查代码语法是否规范.首先将待解析代码初始化为code,将code通过AST解析为T,通过检查T来判断code语法是否规范,若不规范对code进行删除,否则通过遍历T中节点,删除T中注释节点,对T进行AST反向解析,将T输出为Tcode,Tcode即为干净数据.
3.2.2 建立代码词典/分词
在建立代码词典过程中,首先初始化代码词典为L,将Tcode通过AST解析为T,遍历T中所有节点,将所有叶子节点内容添加到L,通过集合对L进行去重.去重后的L即为代码词典,通过L使用正向最大长度匹配对Tcode进行分词.建立代码词典/分词算法如表2所示.

表2 建立代码词典/分词算法Table 2 Building code dictionary/word segmentation algorithm
3.2.3 计算生成代码相似度
使用分词后的代码语料通过Skip-Gram模型训练词向量.由于相似代码具有相似的向量表示,本文通过计算生成代码与程序员预期代码之间的余弦相似度得到选择代码与生成代码之间的语义相似度,使用公式(5)计算生成代码相似度.
(5)
其中A表示程序员预期代码token,Ak表示tokenA的第k维向量;B表示代码自动生成工具生成代码token,Bi为生成的第i个代码,Bik表示tokenBi的第k维向量.通过计算B中生成代码Bi与程序员期望代码A的相似度,可以得到选择代码与生成代码之间的语义相似度,即生成代码相似度.
4 确定性能类别
抽取性能特征有助于确定性能类别.基于3.1中的代码自动生成性能基本特征及3.2中生成代码与选择代码的语义相似度,可以综合考虑程序员行为和代码自动生成工具行为后对性能类别进行划分.如果可以对性能数据进行分类,就能进一步分析性能特征对性能的影响程度.K-means是一种常用的对数据进行无监督聚类的方法[14],但K-means算法在对性能数据进行分类时,可能将一些性能数据明显较差的数据混合到其余类别中.
我们在观察采集到的性能数据时,发现偶尔出现部分特征项为0的数据,而这部分数据大多分布在代码自动生成工具推荐代码个数、程序员选择的生成代码、程序员选择生成代码的按键次数、生成代码语义相似度等特征中.这些数据明显属于性能较差的类别.为了避免在分类过程中将性能特征数据中的程序员行为和代码自动生成工具行为混淆,或将某一种特征弱化,借鉴文献[15]中基于背景知识分类的方法,本文将半监督算法与代码自动生成过程中程序员和代码自动生成工具间的关系相结合,定义相应的约束条件对性能数据进行分类.
4.1 约束
在K-means的背景下,实例约束可以表示哪些实例应该组合或不应该组合在一起的背景知识.因此,本文考虑两种成对的约束关系,即正关联约束和负关联约束.
1)正关联(Must-link)约束指定两个实例必须位于同一个类别中.
2)负关联(Cannot-link)约束指定两个实例不可能位于同一个类别中.
针对性能体现明显较差的数据,通过定义正关联约束,指定该类数据在聚类过程中强制分配到低性能类别中.反之针对性能体现明显较高的数据,则定义为负关联约束,指定该类数据不与低性能数据划分到同一类别中.
4.2 带约束的K-means聚类算法
为了确定性能数据的类别,本文通过一组正负关联约束结合K-means的聚类原则对性能数据进行半监督聚类.首先将性能数据初始化为D,定义一对正关联约束(Con=)和负关联约束(Con≠),根据K-means的聚类原则,首先随机初始化类别中心C,针对D中的性能数据di在满足约束关系的前提下将其就近分配到Cj.以di到Cj的平均距离对Cj进行更新,并对D中的性能数据di在不违反约束关系的前提下就近分配类别,直到Cj不再发生变化,通过评估聚类效果来确定最佳k值.带约束的K-means聚类算法如表3所示.

表3 带约束的K-means聚类算法Table 3 Constrained K-means clustering algorithm
4.3 评 估
虽然带约束的性能聚类一定程度上可以避免错误的分类,但直接决定聚类效果好坏的类别个数是人为定义的.为了使聚类效果达到最佳,我们在确定性能类别数k时,根据带约束的聚类方法分别计算不同k值时性能类别中数据D的误差平方和,如式(6)所示.
(6)
其中,SSE代表所有样本的聚类误差,Ci代表第i个类别,p为Ci中的样本点,mi为Ci的质心(Ci中所有样本的均值).依据SSE的思想[16],可以对k值进行搜索,当SSE下降幅度变小时确定k值.通过以上过程,可以划分性能类别个数,并对每个类别中数据的特征赋予类别实际意义,如果不能很好地解释每个类别,就再考虑次优的划分方法,直至找到能被赋予实际意义的性能类别.性能类别可作为评估代码自动生成性能的一项指标.
5 基于DNN的代码自动生成性能评估
通过第4节的方法可以得到合理的性能类别,有助于对性能特征数据进行标记.为了分析代码自动生成过程中性能类别与程序员行为及代码自动生成工具行为之间的关系,本文设计了一种基于深度神经网络(Deep Neural Networks,DNN)的代码自动生成性能评估模型.该模型根据程序员行为与代码自动生成工具行为特征数据进行性能分类,同时针对每种性能类别分析程序员行为与代码自动生成工具行为的影响程度,以此评估代码自动生成的性能.基于DNN的代码自动生成性能评估模型如图1所示.
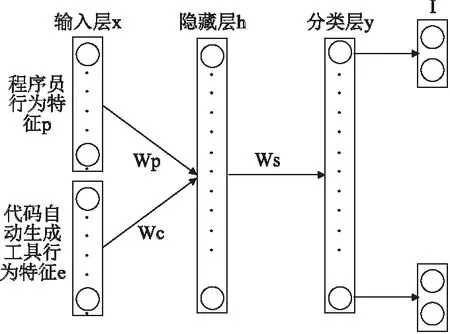
图1 基于DNN的代码自动生成性能评估模型Fig. 1 Performance evaluation model of automatic code generation based on DNN
从程序员行为特征输入层p到隐藏层h的过程记为函数fp,从代码自动生成工具行为特征输入层c到隐藏层h的过程记为函数fc,从隐藏层h到性能分类层y的过程记为函数g,如式(7)、式(8)所示:
h=fp(xp)+fc(xc)=S(Wp+b)+S(Wc+b)
(7)
y=g(h)=S(WTh+d)
(8)
其中S一般取为sigmod函数;Wp为程序员行为特征输入层p与隐藏层之间的权重矩阵,Wc为代码自动生成工具行为特征输入层c与隐藏层之间的权重矩阵;b表示隐藏层的偏置向量,d表示输出层的偏置向量.依据式(7)、式(8)可以得到x所属性能类别y.为方便表示,记θ=(Wp,Wc,WT,b,d).
假设程序员行为特征输入层的样本数据为p={p1,p2,…,pn},代码自动生成工具行为特征输入层的样本数据为c={c1,c2,…,cn},D为包含N个p和c的训练集以及数据对应的性能类别标签,则训练基于DNN的代码自动生成性能评估模型的过程就是利用D对参数θ的训练过程,训练目标是使y和性能类别标签尽可能接近,性能数据分类准确度使用均方误差来描述,其定义为式(9):
(9)
通过以上方法可以得到参数θ.针对未知性能类别的代码生成特征数据x,可以将特征数据分为程序员行为数据xp以及代码自动生成工具行为数据xc两部分输入模型,由于程序员与代码自动生成工具在代码生成过程中有着不同的重要程度,我们在图1中的I层计算了xp与xc对分类结果y的影响程度,即Impact_P和Impact_C.计算方法如式(10)、式(11)所示:
Impact_P=(WTfp(xp)+b)/y
(10)
Impact_C=(WTfc(xc)+d)/y
(11)
其中Impact_P为程序员行为特征p对性能类别y的影响程度,Impact_C为代码自动生成工具行为特征c对性能类别y的影响程度.
通过基于DNN的代码自动生成性能评估模型,可以针对代码自动生成过程中产生的程序员行为数据以及代码自动生成工具行为数据对代码生成性能进行分类,同时分析程序员和代码自动生成工在性能类别中的影响程度.
6 实 验
本文在前期研究中实现了原型工具API4ACGT[17],并利用IntelliJ IDEA的开源插件机制将API4ACGT无缝集成到IntelliJ IDEA中.API4ACGT可以在程序员使用代码自动生成工具进行编码时动态记录程序员的行为信息以及代码生成工具行为信息.
6.1 性能数据及复杂特征提取
我们将API4ACGT(1)https://github.com/xiaojiangzhang安装到多个程序员的IDE中,同时安装了代码生成工具IDEA和AiXCoder.对不同时刻、熟练程度不同的程序员在代码自动生成工具辅助下的编程过程的性能数据进行了采集,数据规模为15000条.部分数据如表4所示.
通过API4ACGT得到性能数据后,首先需对数据进行特征提取,并计算代码自动生成工具生成的代码与程序员需要代码之间的语义相似度.应用3.2中的方法,我们在GitHub开源社区中爬取了40余万个Start大于20的Java代码文件(约11GB),并建立了Java代码语料库,代码词库中的token为77272个.

表5 词向量聚类结果Table 5 Word2Vec clustering results
利用代码词库对Java代码进行分词后,使用Skip-Gram模型训练代码词向量,并在Python3.7环境中使用Gensim提供的Word2Vec模块对分词后的代码语料进行词向量的训练.正如前文所述,AST中的相似节点应该具有相似的表示,为了评估训练的词向量是否达到这个标准,通过K-Means聚类来评估我们训练的词向量.实验中我们将聚类个数设置为48,截取了3个类别中的部分token,结果如表5所示.在类别1中几乎所有符号都与String类型相关,类别2中大多数符号都与循环控制有关,类别3中主要是List的子类或相关方法.这个结果证实了我们的训练是有效的,相似的符号具有相似的向量表示.
根据式(5),对代码自动生成工具所生成的推荐代码与程序员选择的生成代码进行了语义相似度的计算,并将其合并为生成代码语义相似度指标.同时对表4中部分原始数据进行了数值化,代码自动生成工具推荐代码索引按照式(12)进行计算.
(12)
其中n为代码索引位置.生成代码位置越靠后,s值就越小。与代码自动生成过程相关的所有性能特征数值化后如表6所示.

表6 性能特征数值Table 6 Performance feature value
表6中有少量数据存在空值,主要集中在代码自动生成工具生成推荐代码个数、代码自动生成工具是否成功推荐代码、代码自动生成工具推荐代码索引、生成代码语义相似度等特征中.通过分析,出现这种情况的原因主要是由于代码自动生成工具未能为程序员生成代码,所以在程序员选择代码行为或代码自动生成工具相关行为的数据上为空值,可以通过人工判定这种情况属于性能较差的体现.
6.2 性能分类
在应用第4节中的方法标注性能类别时,可以基于人工判定的结果定义相关约束.如果代码自动生成工具推荐代码个数、代码自动生成工具是否成功推荐代码、代码自动生成工具推荐代码索引、生成代码语义相似度的特征值为空或0,则将这类数据强制连接到性能较差的数据类别中;不满足该约束时,该类数据不允许连接到性能较差的类别中.基于这种约束,我们对数据集进行了聚类,通过计算不同k值与SSE值确定最优的性能类别个数,结果如图2所示.
在性能类别数等于3时SSE下降幅度为1413.9,性能类别数等于4时SSE下降幅度为642.47,下降幅度明显变缓慢.可见,将性能数据划分为高、中、低3个类别是合理的.因此,本文设定类别数为3.通过对数据集进行聚类及标注,聚类结果如图3所示.

图2 SSE 计算结果Fig.2 SSE statistics
在图3中,负值表示数据相对较小.如图3所示,在性能较低的类别中,代码上下文复杂度较高,而代码自动生成工具生成代码时间较长,成功推荐代码次数较少,同时生成代码与程序员期望代码之间的代码语义相似度较低.程序员行为中删除行为较突出,说明生成代码并不符合程序员的期望.此外,在代码复杂度较高的情况下,代码自动生成工具生成代码数量较少,时间较长,在代码自动生成过程中性能表现较低.

图3 聚类结果Fig.3 Clustering results
6.3 代码自动生成性能评估
应用第5节的性能评估模型,本文在分类后的数据中随机抽取13000条作为训练集,2000条作为测试集,使用隐藏层数为3、隐层节点数为20的网络参数对模型进行训练.在训练阶段为了防止深度学习中常见的拟合性问题,本文在模型训练过程中加入了Dropout正则化处理,最终模型针对测试集性能分类准确率达到98.17%.
为了评估程序员行为与代码自动生成工具行为在代码自动生成过程中各自的影响程度,选择了一批经过复杂特征提取后的数据进行分类,并计算了程序员行为特征与代码自动生成工具行为特征在不同性能类别中的影响程度,用一个三元组
表7中Class为性能类别.可以看出,低性能类别中Impact_P指标明显高于Impact_C.从序号为3、9、10、11、14、16的数据中可以看出,代码自动生成工具推荐代码个数接近0,代码自动生成工具是否成功推荐代码为0,生成代码语义相似度几乎为0,Impact_P均值为0.8352,而Impact_C均值为0.1648,可以看出程序员行为对低性能类别影响程度较高.低性能数据的各项特征可以反映出代码生成工具没有为程序员生成符合期望的代码.在中性能数据中,Impact_P与Impact_C较为接近,程序员行为数据与代码自动生成工具行为数据分布比较均匀.例如序号为1、5、7、12、15的中性能数据,Impact_P与Impact_C均值为0.4849和0.5151.在高性能数据中,Impact_C指标比较突出,Impact_C几乎接近1.此时,代码自动生成工具生成代码的语义相似度最高达到0.8542,生成代码数量也达到最高,同时程序员按键次数依旧保持在1左右,即代码自动生成工具为程序员生成了优质的代码,从而提高了程序员的开发效率.

表7 程序员行为特征与代码自动生成工具行为特征在不同性能类别中的影响程度实验数据Table 7 Experimental data on the influence of behavior characteristics of programmers and automatic code generation tools on different performance categories
上述实验表明,本文的方法可以有效分析代码自动生成过程的性能,并判断程序员行为与代码自动生成工具行为对代码自动生成过程性能的影响程度.
6.4 评估结果分析
为了进一步验证本文所提出的方法,代码自动生成过程中采集的性能数据使用Precision、Recall、MRR、F1-Measure及本文评估方法中的
从表8中可以看出,不同评估指标显示表7中16条代码自动生成记录的性能评估结果为中等.与Precision、Recall相比,F1-Measure、MRR、
在代码自动生成过程中,涉及较多可能影响代码自动生成性能的因素.例如,程序员输入代码会直接影响代码自动生成工具推荐代码内容;程序员选择生成代码之后,可能出现删除代码的行为等.从公式(1)、(2)、(4)可知,Precision、Recall以及F1-Measure只计算了代码自动生成工具推荐代码个数以及正确推荐代码次数,MRR计算了代码自动生成工具正确推荐代码排序结果.本文提出的方法综合考虑了影响代码自动生成性能问题的相关因素,从程序员行为以及代码自动生成工具行为两个方面进行评估.通过选择深度神经网络作为性能评估的基础模型,在代码自动生成性能评估过程中,不仅对性能数据类别进行计算,而且使用深度神经网络中不同神经元之间的权重参数来估计程序员与代码自动生成工具行为数据对性能评估的影响程度,同时也可以利用两种行为对性能的影响程度分析性能问题的瓶颈.

表8 代码自动生成性能评估结果Table 8 Results of code automatic generation based on different performance metrics
7 结束语
本文针对代码自动生成提出了一种性能评估方法,综合考虑了程序员与代码自动生成工具的作用,通过抽取程序员行为与代码自动生成工具行为特征,使用带约束的半监督聚类方法对性能数据进行分类;根据程序员行为特征数据以及代码自动生成数据建立了一种基于DNN的性能评估模型,评估了程序员和代码自动生成工具对代码自动生成性能的影响程度.实验表明,代码自动生成性能表现较高时,代码自动生成工具行为特征权重较大,几乎直接决定了性能类别,同时也说明高性能的代码自动生成在较大程度上简化了程序员的开发行为;而在低性能类别中,程序员的行为特征权重较大,说明低性能的代码自动生成会导致程序员的开发行为在编程中占据较大比重;在中性能类别中,程序员行为特征与代码自动生成工具行为特征的权重较为平衡.
本文所提出的代码自动生成性能评估方法通过分析程序员行为与代码自动生成工具行为的交互特征,可以有效的对生成代码性能进行评估,并可应用于实际软件项目中.但是,目前仅针对程序员行为与代码自动生成工具行为对性能分类影响程度进行了研究,下一步将针对程序员与代码自动生成工具行为中的不同特征对于性能影响程度进行研究,为提高代码自动生成性能提供更多参考.
猜你喜欢
消费电子(2022年7期)2022-10-31
北京航空航天大学学报(2022年8期)2022-08-31
汽车实用技术(2022年4期)2022-03-07
电脑报(2020年48期)2020-12-28
少儿画王(3-6岁)(2020年4期)2020-09-13
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
东方教育(2018年20期)2018-08-22
意林(2017年24期)2018-01-02
三月三(2016年6期)2016-06-21
微型计算机(2009年4期)2009-12-23
