
近邻同步聚类模型与指数衰减加权同步聚类模型的比较与分析
2021-03-23 07:17陈新泉周灵晶戴家树
安徽工程大学学报 2021年1期
陈新泉,周灵晶,戴家树,周 祺
(1.安徽工程大学 计算机与信息学院,安徽 芜湖 241000;2.安徽工程大学 教育工会,安徽 芜湖 241000)
作为统计学中多元统计分析方法的一种重要技术,聚类分析试图发现未知数据中的内在结构或分布规律。在机器学习中,聚类被称为无监督学习,指的是试图发现无标记数据中的内在分布结构,让划分后的簇表现出数据的自然结构特点。聚类可以让缺乏先验信息的数据集获得其内在的分布结构(聚类的数目、大小、分布位置及空间结构等信息),进而为半监督学习、监督学习、数据压缩等一些后续操作提供一定的辅助信息。通常,同一聚类中的数据应该比不同聚类间的数据更为相似,不同聚类间的数据应该具有较大的差异。聚类在许多领域都有应用,如:心理学和其他社会科学、生物学、统计学、模式识别、信息检索、机器学习和数据挖掘。
聚类分析属于一个交叉研究领域,它融合了多个学科的方法和技术。Qlan Wei-ning等从多个角度分析了现有的许多聚类算法,给出了一些优缺点比较分析结果。Johannes Grabmeier等从数据挖掘的角度(如相似度的定义、相关的优化标准等)分析了许多聚类算法。Arabie和Hubert的专著是早期聚类分析领域的一本很有价值的参考文献。Jain等对一些经典聚类算法进行了很好地比较与分析,这是聚类分析领域早期一篇经典的综述文献。2000年后,Rui Xu等和Anil K.Jain对聚类算法分别做了较为全新的综述分析。
传统的聚类算法一般可分为基于划分的聚类方法、层次聚类方法、密度聚类方法、网格聚类方法、模型聚类方法、图聚类方法等。近年来,量子聚类方法、谱聚类方法、粒度聚类方法、概率图聚类方法、同步聚类方法等也流行起来。
Böhm等于2010年第一次将自然界中普通存在的同步现象引入聚类分析领域,在国际顶级会议KDD(Knowledge Discovery and Data Mining)上发表了第一篇同步聚类算法论文。这篇开拓性论文首先将Kuramoto模型进行了适当地推广,得到可应用于聚类算法中的扩展Kuramoto模型,提出了(Synchronization clustering,Sync)聚类算法。接着作者还将最小描述长度原理应用于Sync算法中,提出了一种参数的自动优化方法。基于同步模型的聚类算法可以缓解聚类分析和噪声检测在传统数据上的某些难题,它具有动态性、局部性及多尺度分析等特性,可以在一定程度上解决大规模数据的聚类分析所面临的困难。自此之后,新型的基于同步模型的聚类算法形成了一个研究热潮。
自Sync算法发表后,吸引了一些研究人员的注意。近几年,邵俊明等从多个角度研究基于同步模型的数据挖掘方法,发表了多篇高水平论文。例如,文献[10]提出了一种新颖的孤立点检测算法。文献[11]提出了一种新颖有效的高效子空间聚类算法(arbitrarily ORiented Synchronized Clusters,ORSC)。文献[12]提出了一种基于同步模型和最小描述长度原理的新颖的动态层次聚类算法(hierarchical Synchronization clustering,hSync),文献[13]提出了一种可以发现复杂图的内在模式的新颖的图聚类算法(Robust Synchronization-based Graph Clustering,RSGC)。文献[14]提出了一种用于检测概念漂移的基于原型学习的数据流挖掘算法。黄健斌等在文献[8]的基础上,提出了一种层次型的同步聚类算法(Synchronization-based Hierarchical Clustering,SHC)。2017年,陈新泉找到了另外一种更为有效的同步聚类模型—Vicsek模型的线性版本。在将这种Vicsek模型的线性版本应用到聚类中后,发表了基于该模型的ESynC(Effective Synchronization Clustering)算法。杭文龙等基于重力学中的中心力优化方法,提出了一种局部同步聚类算法(Gravitational Synchronization clustering,G-Sync)。陈新泉在文献[8]的基础上,提出了基于三种空间索引结构的快速同步聚类算法(Fast Synchronization Clustering,FSynC)。FSynC算法中的两种参数型方法在某些情况下可得到O(dnlogn)的时间代价。这几篇较新的同步聚类论文分别从不同的角度拓展了同步聚类算法的研究。
1 基本概念
设数据集S
={x
,x
,…,x
()}分布在d
维有序属性空间(A
×A
×…×A
)的某个有限区域内。为更好地描述研究算法,先给出几个基本定义。定义
1数据集
S
中的点x
()(i
=1,…,n
)的δ
近邻点集δ
(x
())定义为:δ
(x
())={x
|0<dis
(x
,x
())≤δ
,x
∈S
,x
≠x
()}。(1)
式中,dis
(x
,x
())为S
中的两个不同点x
和x
()的相异性度量,δ
是一个预先设定的阈值参数。定义1的实质意义是:δ
(x
())是从中选取与点x
()相距不超过δ
“距离”的其他点所构成的集合。定义
2应用到聚类中的扩展的Kuramoto模型定义为:
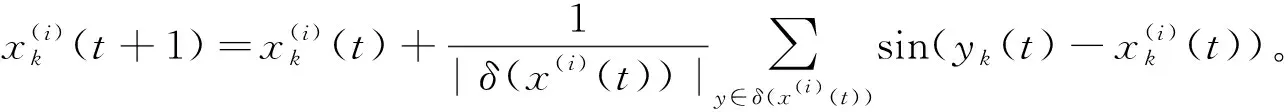
(2)
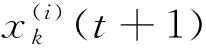
定义
316应用到聚类中的Vicsek
简化模型定义为:
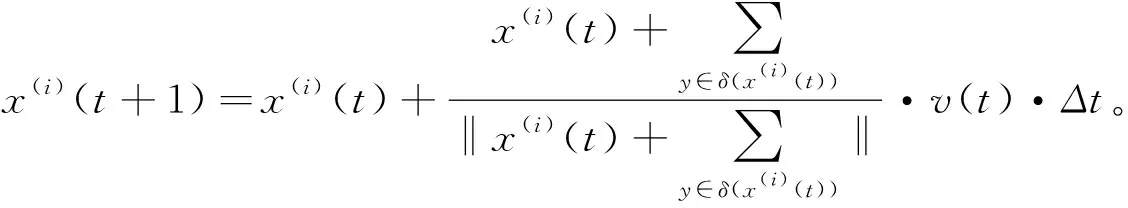
(3)
式中,x
()(t
+1)表示点x
()在第t
个同步后的更新位置;v
(t
)表示第t
个同步时的移动速度;v
(t
)·Δt
表示第t
个同步的移动路径长度。在一些基于Vicsek模型的多agent系统中,v
(t
)是个常量。通过一些仿真实验的观察,当v
(t
)是常量时,基于式(3)的Vicsek模型的原始版本不能很好地应用到聚类中,所以将Vicsek模型的另外一种有效版本应用到聚类中。

(4)
式中,x
()(t
+1)表示点x
()在第t
个同步后的更新位置。式(4)与Mean Shift聚类算法中的下一个搜索位置的计算公式相似。从中我们可以看出,点x
()的更新位置就是点x
()及它的δ
近邻点集δ
(x
())的均值位置。式(4)还可以被改写为: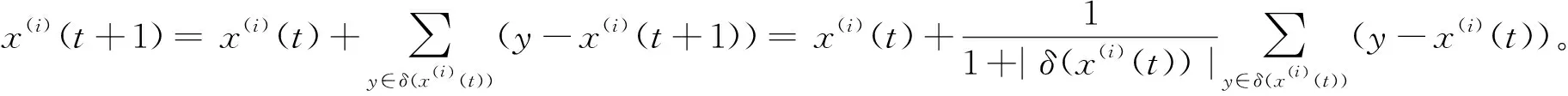
(5)
式(5)与式(2)在外形方面有点相似,但它们有着本质的区别。我们可以看到,式(2)所表示的更新模型是非线性的,而式(4)与式(5)的更新模型是线性的。
基于万有引力定律和物理学中普遍存在的指数衰减规律,我们提出下面的三种指数衰减加权同步模型。前两种模型是在全局范围内进行迭代计算,后一种是在δ
近邻范围内进行迭代计算。定义
5应用到聚类中的第一种指数衰减加权同步模型定义为:
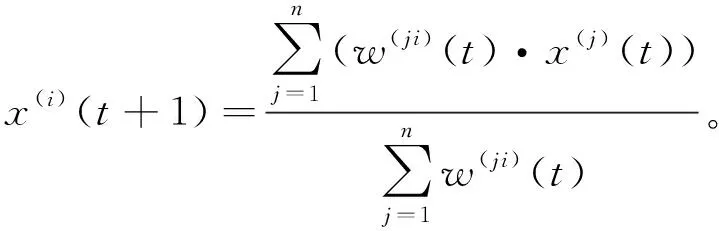
(6)
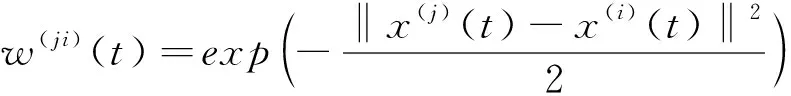
定义
6应用到聚类中的第二种指数衰减加权同步模型定义为:
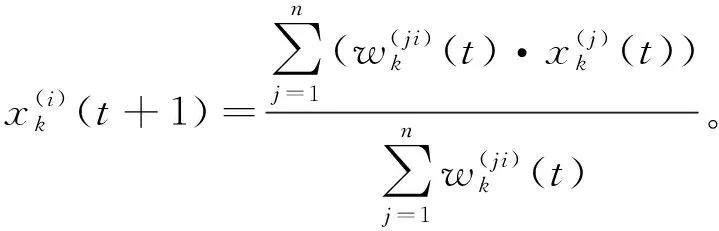
(7)

定义
7应用到聚类中的
δ
近邻指数衰减加权同步模型定义为:

(8)
定义
8 数据集S
={x
,x
,…,x
()}在经历了T
步的同步聚类后稳定下来,表示为S
(T
)={x
(T
),…,x
()(T
)}。设从S
(T
)可获得K
个聚类和K
个孤立点,K
=K
+K
。S
(T
)的聚类稳定点集记为C
={c
,…,c
()},其中c
()是第j
个聚类区域的稳定标记位置。如果x
()(T
)满足式(9),则点x
()判为属于第j
个聚类区域。dis
(c
(),x
()(T
))<ε
。(9)
式(9)中的参数ε
与算法中的迭代退出阈值参数ε
相同,是一个非常小的实数。如果第j
个聚类区域包含了n
个数据点,则这n
个数据点在原始数据集S
={x
,…,x
()}中的均值位置m
()与第j
个聚类稳定点位置c
()之间的距离表示为dis
(c
(),m
()),则K
个聚类区域的稳定位置与K
个聚类区域的均值位置差异值定义为: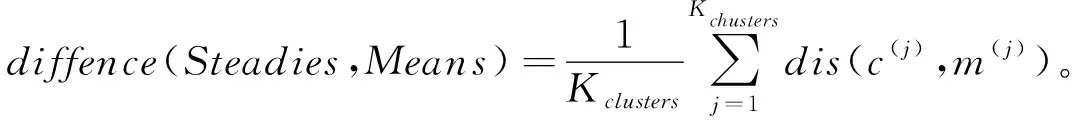
(10)
显然,式(10)所表示的这个指标可度量同步聚类后聚类区域的稳定位置与均值位置的平均差异。
定义
9互信息(Mutual Information,MI)。根据香农信息论,两个离散随机变量
X
和Y
的互信息定义为: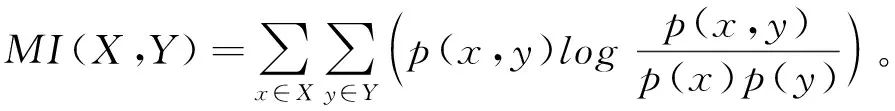
(11)
式中,p
(x
,y
)是两个随机变量X
和Y
的联合概率密度分布函数,p
(x
)是随机变量X
的边缘概率密度分布函数,p
(y
)亦然。定义
10 正规化互信息(Normalized Mutual Information,NMI)。两个聚类结果X
和Y
的正规化互信息定义为: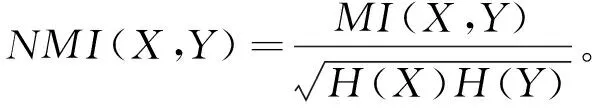
(12)
式中,MI
(X
,Y
)是两个聚类结果X
和Y
的互信息,H
(X
)是聚类结果X
的信息熵,H
(Y
)亦然。定义
11调整互信息(Adjusted Mutual Information,AMI)。两个聚类结果
X
和Y
的调整互信息定义为:
(13)
式中,MI
(X
,Y
),H
(X
),H
(Y
)的含义与上面相同,E
{MI
(X
,Y
)}是两个聚类结果X
和Y
的互信息的数学期望。定义
12调整变信息(Adjusted Variation Information,AVI)。两个聚类结果
X
和Y
的调整变信息定义为:
(14)
式中,MI
(X
,Y
),H
(X
),H
(Y
),E
{MI
(X
,Y
)}的含义与上面相同。当聚类结果X
和Y
完全一致时,NMI
,AMI
和AVI
取值为1。当聚类结果X
和Y
的互信息等于它们的期望时,AMI
和AVI
取值为0;当聚类结果X
和Y
的分布相互独立时,NMI
取值为0。2 基于同步模型的聚类算法
Böhm等提出的Sync算法,Chen提出的ESynC算法是2.1节中基于近邻同步模型的聚类算法的两个典型代表,基于指数衰减加权同步模型的聚类算法将在2.2节中予以介绍。
2.1 基于近邻同步模型的聚类算法
基于近邻同步模型的聚类算法是一种在δ
近邻范围内进行动态同步迭代的聚类算法框架,具体表述如下:算法1:基于近邻同步模型的聚类算法
输入:数据点集S
={x
,…,x
()},距离相异性度量dis
(·,·),近邻阈值参数δ
,迭代退出阈值参数ε
;输出:数据点集S
的聚类结果,可以采用数据点的聚类归属标记数组FinCluResult
[1…n
];1:迭代步t
初始化为0,即:t
←0;2:fori
=1,2,…,n
do;3:x
()(t
)←x
()4:end for
5:while(S
(t
)={x
(t
),x
(t
),…,x
()(t
)}仍在同步移动中)do6: fori
=1,2,…,n
do7: 根据式(1)为数据点x
()构造它的δ
近邻点集δ
(x
());8: 根据定义2,或定义3,或定义4,或定义7计算x
()(t
)同步后的更新值x
()(t
+1);9: end for

mse
(S
(t
),S
(t
+1))<ε
)then12: 这个动态的同步聚类过程收敛了,可以从while循环中退出来;
13: else
14: 迭代步t
增加一步,即:t
++,然后进入下一次while循环;15: end if
16:end while
17:将退出while循环的t
值赋给同步总次数T
,此时可得到数据点集S
同步后的收敛结果集S
(T
)={x
(T
),x
(T
),…,x
()(T
)};18:在S
(T
)中,那些代表一些数据点的稳定位置可看作是聚类中心,那些只代表一个或几个点的稳定位置可看作是孤立点的最终同步位置。根据S
(T
)={x
(T
),x
(T
),…,x
()(T
)}很容易得到一个由若干个稳定点或孤立点构成的自然聚类簇,从而构造出FinCluResult
[1..n
]。备注:在算法1的第8步中,如果采用定义2来计算x
()(t
)同步后的更新值x
()(t
+1),就是Böhm等提出的Sync算法;如果采用定义4来计算x
()(t
)同步后的更新值x
()(t
+1),就是Chen提出的ESynC算法;定义3的同步模型在文献[16]中已有几个对照实验;如果采用定义7来计算x
()(t
)同步后的更新值x
()(t
+1),则会得到一种同步聚类算法。2.2 基于指数衰减加权同步模型的聚类算法
基于指数衰减加权同步模型是一种在全局范围内进行动态同步迭代的聚类算法框架,具体表述如下:
算法2:基于指数衰减加权同步模型的聚类算法
输入:数据点集S
={x
,…,x
()},距离相异性度量dis
(·,·),迭代退出阈值参数ε
;输出:数据点集S
的聚类结果,可以采用数据点的聚类归属标记数组FinCluResult
[1..n
];1:迭代步t
初始化为0,即:t
←0;2:fori
=1,2,…,n
do3:x
()(t
)←x
();4:end for
5:while(S
(t
)={x
(t
),x
(t
),…,x
()(t
)}仍在同步移动中)do6: fori
=1,2,…,n
do7: 根据定义5,或定义6计算x
()(t
)同步后的更新值x
()(t
+1);8: end for
mse
(S
(t
),S
(t
+1))<ε
)then11: 这个动态的同步聚类过程收敛了,可以从while循环中退出来;
12:else
13: 迭代步t
增加一步,即:t
++,然后进入下一次while循环;14: end if
15:end while
16:将退出while循环的t
值赋给同步总次数T
,此时可得到数据点集S
同步后的收敛结果集S
(T
)={x
(T
),x
(T
),…,x
()(T
)};17:在S
(T
)中,那些代表一些数据点的稳定位置可看作是聚类中心,那些只代表一个或几个点的稳定位置可看作是孤立点的最终同步位置。根据S
(T
)={x
(T
),x
(T
),…,x
()(T
)}很容易得到一个由若干个稳定点或孤立点构成的自然聚类簇,从而构造出FinCluResult
[1..n
]。备注:在算法2的第7步中,如果采用定义5来计算x
()(t
)同步后的更新值x
()(t
+1),会得到一种同步聚类算法;如果采用定义6来计算x
()(t
)同步后的更新值x
()(t
+1),则会得到另外一种同步聚类算法。2.3 算法的复杂度分析
(1)算法1的复杂度分析。在算法1中,步1只需要O
(1)的时间代价,步2到步4需要O
(n
)的时间代价。步5需要O
(T
)的时间代价。在步7中,如果采用简单的全范围蛮力判断方法,为数据点x
()(i
=1,…,n
)构造它的δ
近邻点集δ
(x
())需要Time
=O
(dn
)。当数据集的维数较小时,通过为数据点集构造空间索引结构的方法,可以取得O
(d
logn
)的时间代价。在步8中,计算x
()(t
)(i
=1,…,n
)同步后的更新值x
()(t
+1)需要Time
=O
(d
·|δ
(x
())|)。所以步6到步10最多需要O
(dn
)的时间代价。步10需要O
(dn
)的时间代价。步11到步15只需要O
(1)的时间代价。步17只需要O
(1)的时间代价。步18需要O
(dnK
)的时间代价,其中K
是聚类数和孤立点数之和,一般有K
≪n
。根据Böhm等和我们的分析,算法1未采用空间索引结构时的时间代价为Time
=O
(Tdn
);算法1在低维数据集中,采用有效的空间索引结构时的时间代价为Time
=O
(Tdn
logn
)。(2)算法2的复杂度分析。算法2中的步1,步2到步4,步5的时间代价与算法1相同。在步6到步8中,使用定义5来计算w
()(t
)(i
,j
=1,…,n
)需要Time
=O
(d
),计算x
()(t
)(i
=1,…,n
)同步后的更新值x
()(t
+1)需要Time
=O
(dn
);使用定义6来计算w
()(t
)(i
,j
=1,…,n
;k
=1,…,d
)需要Time
=O
(1),计算x
()(t
)(i
=1,…,n
;k
=1,…,d
)同步后的更新值x
()(t
+1)需要Time
=O
(n
)。所以步6到步8需要O
(dn
)的时间代价。步9需要O
(dn
)的时间代价。步10到步14只需要O
(1)的时间代价。步16只需要O
(1)的时间代价。步17需要O
(dnK
)的时间代价,其中K
是聚类数和孤立点数之和,一般有K
≪n
。根据上面的分析,算法2的时间代价为Time
=O
(Tdn
)。2.4 参数的优化确定
算法1和算法2中的迭代退出阈值参数ε
仅影响着同步迭代的次数及聚类精度,一般可设置在[0.01,0.000 001]范围内。在所有实验中,均设置为ε
=0.000 01。算法1的近邻阈值参数δ
可以影响数据集的聚类结果。参数δ
的优化设置原则是:如果两个数据点的相异性度量小于δ
,那么可以认为这两个点应该在同一个聚类中。在文献[8]中,参数δ
可以通过MDL原理来优化确定。根据文献[16]中的定理1和性质1,很容易选择确定参数δ
的一个合适值。验中的参数δ
就是根据这个方法确定的。通过大量的仿真实验发现,在多数具有明显聚类结构的数据集中,参数δ
都具有一个比较宽泛的有效值范围。在文献[23]中,给出了如下两种估计参数δ
有效值的方法。(1)第一种估计参数δ
有效值的方法由式(15)表示:MstEdgeInCluster
≤δ
<DisDifferentClusters
。(15)
式(15)中,MstEdgeInCluster
是聚类簇的所有最小生成树(每个聚类有一个将该聚类所有点连接在一起的最小生成树)中的最大边;DisDifferentClusters
是不同聚类中的两个点的最小相异性度量。(2)第二种估计参数δ
有效值的方法是一个基于数据集S
(或它的一个样本)的最小生成树而设计的一个算法。具体步骤如下:①首先从数据集S
中构造出一个最小生成树MST
。②接着对该MST
的所有边进行升序排列。设排序后的边集表示为ES
(MST
(S
))={e
,e
,…,e
-1},这里e
≤e
≤…≤e
-1。③在ES
(MST
(S
))中,搜索具有最大差值的两个相邻边。这样,估计参数δ
有效值的另外一个公式可表示为: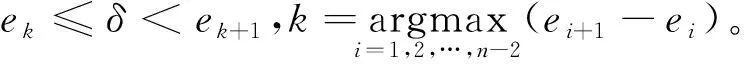
(16)
式(16)中,e
和e
+1是ES
(MST
(S
))中具有最大差值的两个相邻边。3 仿真实验
3.1 仿真实验设计

表1 仿真实验数据集的描述(a 4类2维实值型人工数据集的描述)

表1 仿真实验数据集的描述(b 8个UCI数据集的描述[24])
相关实验均在Intel(R)Celeron(R)CPU 3855U 1.6 GHz上进行,配备8 G内存,在Windows 7的Visual C++6.0开发环境下采用C语言和C++语言混合编程进行仿真实验验证。
为比较这些同步聚类模型的聚类结果和时间效率的差异,采用表1中描述的4类人工数据集和8个UCI数据集做一些仿真实验。表1a给出了4类人工数据集的基本描述信息,它们是由两个函数根据设定的参数在区域[0,600]×[0,600]内生成的2维数据。这两个函数的C语言代码在文献[16]的附加材料附录2中给出。表1b是8个UCI数据集的简单描述。
这里采用多个不同类型的数据集对基于六种同步模型的聚类算法(分别基于定义2、定义3、定义4、定义5、定义6和定义7构造的同步聚类算法)在时间代价(单位为s)、同步迭代次数、聚类区域的稳定位置与均值位置的差异值和聚类质量(采用3个基于信息论的度量指标AMI/AVI/NMI)上进行适当的比较,观察分析这六种同步聚类模型的聚类有效性差异。同步聚类算法中的迭代退出阈值参数ε均设置为0.000 01。在算法1中,基于定义2、定义3、定义4和定义7的同步聚类模型,根据文献[16]的方法为近邻阈值参数δ选择一个合适值。
3.2 六种同步模型的动态聚类过程示例与比较
图1采用的数据集选自表1a中的DS1类,数据点数目为400,具有5个比较明显的聚类区域。在几个同步聚类模型的算法中,参数δ
设置为30,参数ε
设置为0.000 01,最大迭代次数设置为50,定义3中的v
(t
)·Δt
设置为0.1。图1a~图1e给出了六种同步聚类模型在这个数据集上的同步聚类过程演变轨迹,用NC(Number of Clusters)记录着聚类数目,t
记录着迭代的轮次。通过比较定义2、定义3、定义4、定义5、定义6和定义7可以看出,除了定义2是非线性的同步聚类模型,其他几个定义都是线性的同步聚类模型。从图1中可知,除了基于定义4的同步聚类模型外,其他几个同步聚类模型都不能获得良好的局部聚类效果。
3.3 人工数据集的仿真实验结果
表2是基于六种同步模型的聚类算法在4个人工数据集(表1a中的4类人工数据集,数据点数目设置为1 000。第1个数据集具有5个比较明显的聚类区域,无噪声点;第2个数据集具有4个比较明显的聚类区域,含3个噪声点;第3个数据集具有6个比较明显的聚类区域,无噪声点;第4个数据集具有5个比较明显的聚类区域,含15个噪声点)上的实验结果比较。在表2中,数据点数目n及算法所需设置的参数δ的具体值附在数据集后的括号内。表2的实验不设置最大迭代次数,参数ε
设置为0.000 01,定义3中的v
(t
)·Δt
设置为0.1。3个指标AMI/AVI/NMI的取值基本上可以反映出聚类质量(采用人工观察到的聚类区域或孤立点来设置基准聚类标号)的好坏。式(10)所表示的差异值指标反映出同步聚类后聚类区域的稳定点集与平均点集之间的平均差异。时间和迭代次数反映出聚类速度。3.4 UCI数据集的仿真实验结果
基于六种同步模型的聚类算法在8个UCI数据集上的实验结果比较如表3所示。由表3可见,算法所需设置的参数δ
的具体值附在数据集后的括号内。表3的实验不设置最大迭代次数,参数ε
设置为0.000 01,定义3中的v
(t
)·Δt
设置为0.1。3个指标AMI/AVI/NMI的取值基本上可以反映出聚类纯度(采用数据集本身的类别号来设置基准聚类标号)的好坏。式(10)所表示的差异值指标反映出同步聚类后聚类区域的稳定点集与平均点集之间的平均差异。时间和迭代次数反映出聚类速度。




图1 基于定义2、定义3、定义4、定义5、定义6和定义7的同步聚类模型的动态聚类过程比较
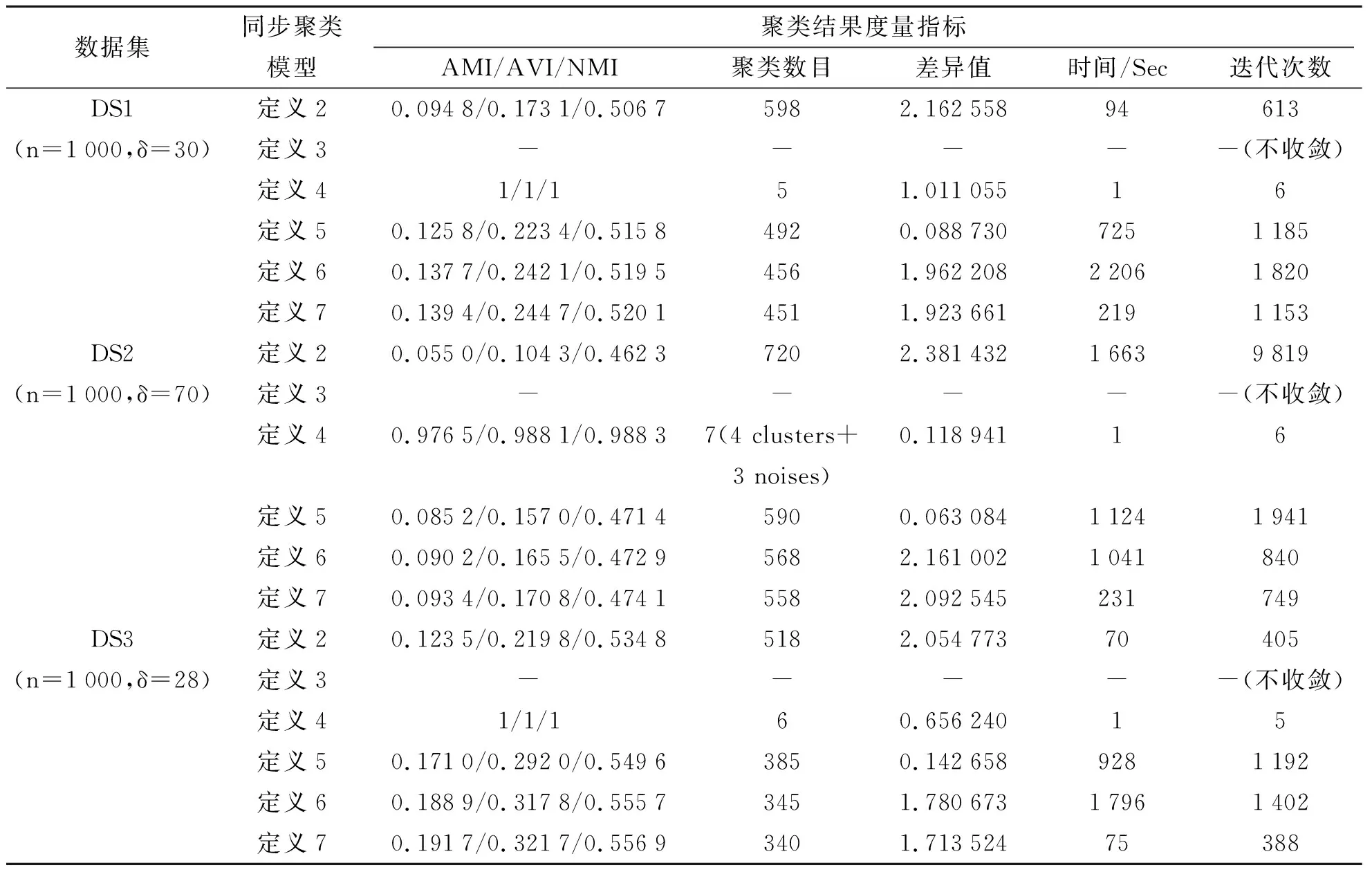
表2 人工数据集的实验结果

续表2
3.5 实验结果分析及结论
从图1的实验结果可以看出,基于定义4的同步聚类算法的聚类效果最好,其他几种同步聚类模型虽然具有一定的同步效果,但它们的聚类结果不能很好地反映出数据集的聚类结构。从表2的实验结果可以看出,基于定义4的同步聚类算法的聚类质量总体上最优,聚类速度最快。从表3的实验结果可以看出,基于定义4的同步聚类算法的聚类质量总体上最优。通过比较表2和表3还可以看出,有的UCI数据集使用几个同步聚类模型进行聚类时,或者运行时间过长,难以在有效时间范围内达到迭代的终止条件,或者只经历一次迭代就满足迭代终止条件而退出循环。基于定义5的同步聚类算法的差异值指标通常都取得了最小值,但最终的聚类数目和AMI/AVI/NMI值并不理想,这是因为这个模型的同步幅度小,未获得良好的聚类效果。基于定义2和定义3的同步聚类算法在多数情况下长时间都不能正常地迭代退出同步聚类过程,说明相邻两次迭代的均方误差一直都较大,不能进入同步稳定阶段。
基于定义4的同步聚类算法在迭代次数、聚类效果方面总体上表现最好。这种基于近邻范围内的均值位置更新式(即基于定义4)的迭代同步模型在聚类分析领域非常有效,其聚类效果远优于基于定义2的同步聚类模型(即文献[8]首次提出的扩展Kuramoto同步聚类模型)、基于定义3的同步聚类模型和研究提出的另外三种同步聚类模型(分别基于定义5、定义6和定义7)。研究提出的三种同步聚类模型虽然是基于万有引力定律和指数衰减规律而提出来的,但在聚类上的应用效果总体上不如基于Vicsek模型的线性版本(即基于定义4)。
另外,我们还观察到,AMI和AVI指标能较好地度量聚类质量,而NMI指标有时偏好于聚类结果中簇数目较多的情况。具体来说就是,当聚类结果与基准聚类不一致时,簇数目较多的聚类结果的NMI值远远大于簇数目较少的聚类结果。例如,Glass数据集有210个数据点,当把每个点当作一个单聚类(即孤立点)时,其NMI值为0.530 6,大于对应6个聚类和29个孤立点时的NMI值0.454 0。

表3 8个UCI数据集的实验结果(a 前4个UCI数据集的实验结果)

续表3a

表3 8个UCI数据集的实验结果(b 后4个UCI数据集的实验结果)
4 结束语
在聚类分析领域,常见的同步模型有扩展的Kuramoto模型,基于Vicsek模型的线性版本,基于第二个线性版本的Vicsek模型,万有引力同步模型等。扩展的Kuramoto模型采用一种非线性的动态同步迭代公式来计算每一个迭代步骤的新位置,而基于Vicsek模型的线性版本采用一种线性的动态同步迭代公式来计算每一个迭代步骤的新位置,基于第二个线性版本的Vicsek模型采用一种加权的线性同步迭代公式来计算每一个迭代步骤的新位置。从研究及文献[16]和文献[25]的一些仿真实验可以看出,后两种同步模型更适合应用到聚类分析中。
KMeans和FCM(Fussy C-Means)等基于划分的聚类算法速度快、应用广,但需要事先设定正确的聚类数目,而且多适合于球状类聚类结构的数据集。同步聚类算法具有在多个尺度、多个层次上探测出数据集的聚类结构,易于发现孤立点等优点。在Sync算法、ESynC算法和SSynC(Shrinking Synchronization Clustering)算法中,参数δ的有效取值范围一般都比较宽泛。但没有使用空间索引结构的同步聚类算法需要O(Tdn2)的时间复杂度。近年来流行的谱聚类算法是一种建立在谱图理论上,将聚类问题转化为图的最优分割问题,可以在特征空间上进行聚类的方法。但谱聚类算法仍难以避免如下几个缺点,如聚类结果的好坏依赖于数据集相似度矩阵的构造,聚类数目需要人工设定,最大特征向量集的选择影响着最终的聚类结果,需要O
(n
)的时间和空间复杂度等。下一步,我们将对谱聚类算法与同步聚类算法做一些比较分析研究,尝试综合它们的优点设计出更为优秀的聚类算法。还可以采用MapReduce框架来实现并行版本的MLSynC方法,并将该方法应用到位置数据的时空分析中。最后,从理论上证明这些同步聚类模型的迭代收敛性,并将ESynC算法应用到文本聚类和Web日志分析中也是未来可以尝试的工作。
猜你喜欢
幼儿教育·父母孩子版(2022年4期)2022-05-08
汽车实用技术(2022年4期)2022-03-07
VOGUE服饰与美容(2020年9期)2020-09-02
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
语文世界(初中版)(2018年10期)2018-11-06
语文世界(初中版)(2017年5期)2017-06-22
作文与考试·初中版(2017年12期)2017-04-19
电子技术与软件工程(2016年23期)2017-03-06
作文大王·中高年级(2008年12期)2008-12-19
海外英语(2006年11期)2006-11-30
