
基于趋势符号聚合近似的卫星时序数据分类方法
2021-03-26 04:01阮辉刘雷胡晓光
北京航空航天大学学报 2021年2期
阮辉,刘雷,胡晓光,*
(1.北京航空航天大学 自动化科学与电气工程学院,北京100083; 2.北京机电工程研究所,北京100074)
时间序列是按照时间排序的一组随机变量,其通常是在相等间隔的时间段内依照给定的采样率对某种潜在过程进行观测的结果[1]。在卫星的测控管理过程中,会产生大量的遥测数据,它们以时间序列的形式存储在数据库中。而运行状态监测系统传感器产生的监测数据通过遥测系统传输至地面控制中心,此类数据是地面判断在轨卫星运行和健康状态的唯一依据[2]。同时,这些海量的时间序列蕴含可用于卫星故障诊断的规律和知识。通过数据挖掘,可以提取卫星各器件的信息,发现异常、关联、模式、趋势等知识。有效掌握和利用这些信息规律对卫星异常检测和关联分析、故障诊断、监测预警,对卫星测管管理与决策活动,如改进卫星设计、提高测试及监测自动化等工作具有特别重要的意义[3-7]。
此外,在 金 融[8]、天 气 观 察[9]、生 物 医 学 测量[10]领域同样大量产生此类型的数据。因此,在过去几十年中,时间序列数据挖掘的研究在开发新算法和改进可用算法以满足当前需求方面一直非常活跃。
由于原始时间序列具有高维、高音量和大量噪声的特征,计算机要对原始时间序列进行分类面临许多挑战。
现有的分类算法可以分为2类,即基于形状的分类算法和基于结构的分类算法。
基于形状的分类算法以最近邻(One-Nearest-Neighbor,1-NN)分类器作为基础,时序数据的表示方法则为欧氏距离(Euclidean Distance,ED)[11]和动态时间规整(Dynamic Time Warping,DTW)[12]。
在短时间序列数据集上,1-NN DTW 已被证明是具有高度代表性和竞争力的分类器。基于形状的技术的不足之处在于:当使用噪声或包含特征子结构的长数据对数据进行分类时,它们显示的性能很差。
基于结构的技术有2个步骤。首先,这些方法包括离散傅里叶变换(Discrete Fourier Transform,DFT)[13],可索引分段线性逼近[14]用于提取特征向量;然后,采用经典数据挖掘算法(如决策树),支持向量机被用来做分类任务。
目前,符号化方法也被广泛使用。因为它具有简单、可读性、高效率之外,还可以使用其他领域的算法,如信息检索或文本处理等。其中,Lin等[15]提出的符号聚合近似(Symbolic Aggregate Approximation,SAX)方法是时下流行的符号化表示方法。SAX基于分段总体逼近(Piecewise Aggregate Approximation,PAA)方法[16],并假定PAA值遵循高斯分布。SAX根据高斯曲线下的等大小区域离散化PAA值,从而产生断点,后采用计算开销小的低边界计算准确的距离。
模式 袋 模 型(Bag-of-Patterns,BOP)[17]提 取子结构作为时间序列的高级特征,将这些子结构转化为SAX,并采用ED作为度量距离进行相似性度量的相关应用,如分类、聚类等。BOP方法不考虑子结构之间的顺序,只是将时间序列看成是一些SAX字符串出现概率的集合,每个SAX字符串是相互独立的,类似于直方图的统计表示。
但SAX表示的质量取决于PAA系数,即时间序列分割的段数,用于量化的符号数量(字母大小数)和高斯假设。同时,SAX中的符号是根据每个分段的均值绘制的,不能表示分段的趋势。
为此,一些文献尝试解决SAX的这些问题。Pham等[18]通过引入对时间序列截的长度和字母大小起作用的自适应断点矢量来缓解高斯假设。但是,通过使用聚类方法引入预处理阶段,就失去了SAX的简单性。为描述SAX的趋势信息,文献[19]中提出的扩展符号聚合近似(Extended SAX,ESAX)将PAA段的符号最小值和最大值与相关的SAX符号以及它们的出现顺序相关联。这定义了一个抽象形状,可以在时间序列检索中提供更好的结果。但是,ESAX 表示的大小是SAX表示的大小的3倍。从效率的角度来看,笔者没有将文献[19]的方法与相同大小的SAX表示进行比较。文献[20]提出的基于趋势的符号聚合逼近(Trend-based Symbolic Aggregate approXimation,TSAX),在每个分段中添加了2个趋势指标,TSAX可以区分2个不同趋势之间的差异,但仍不能反映同一趋势中的差异。另外,TSAX表示的大小与ESAX相同,是SAX的3倍。
提高分类算法准确率、减少运算时间是数据符号化表示的主要目标。本文提出一种改进的符号表示——趋势符号聚合近似(Trend Symbolic Aggregate Approximation,TrSAX),集成SAX与最小二乘法,用以描述时间序列的均值和斜率,在不增加运算时间的情况下,进一步提高了分类的准确率。
1 卫星时序数据
1.1 卫星遥测数据来源
根据任务的不同,一颗卫星所含分系统略有差别,但通常包括热控分系统、姿轨控分系统、星务管理分系统、电源分系统、推进分系统、结构分系统、测控分系统、总体电路分系统等。
为监测各分系统的工作状态,设计时在各分系统中设置了大量的测试传感器,采集测试信息传递到地面,形成卫星遥测数据。
1.2 卫星遥测数据特点
卫星的测试数据一般分为数字量和模拟量。数字量可细分为独立数字量、关联数字量和状态数字量。模拟量可细分为恒定模拟量、区间模拟量和趋势变化模拟量。其中,数字量主要为指令、计数和状态等,模拟量主要为电流、电压、角度、温度、压力等。此外,由于卫星是按照轨道周期运行,卫星遥测数据存在周期性。
综上,不同卫星不同分系统的具体遥测数据需要在进行充分分析、数据预处理之后,进行分类、聚类、异常检测等相关研究。
1.3 真实卫星遥测数据分析
文献[21]中对“风云三号”卫星遥测数据进行了分析,其中含133个测试参量,时间跨度为500天。并对3种具有周期特性的测试序列(电流、角度、转速)为对象进行了详细研究。
由于卫星遥测数据具有明显的周期性,通过对遥测数据的每个周期进行分析,可知卫星在该周期之内的运行状态是否正常。
首先,需要对遥测数据进行分段,具体根据卫星工作方式进行分段,根据幅角测试参量的测试值为0~360不断循环,具有周期性,且周期分隔点明确。同时,幅角测试值能够反映出卫星轨道的运行位置,因此,将测试值由360跳变到0的点作为幅角突变点进行分段。对于因数据缺失而不完整的序列,在实验中进行剔除,确保各分段子序列完整。
如图1~图3所示,以角度测试时间序列的幅角突变点为标识进行分段,将每段序列进行叠加绘图。样本数据样本选用的是3种遥测数据测试序列的前4 000个有效样本点,每个周期的数据点为86,样本数据包含47个周期。图中显示各个分段子序列之间的耦合度高,分段合理。

图1 卫星某角度测试时间序列分段叠加结果Fig.1 Satellite angle test time series segmentation merging results

图2 卫星某转速测试时间序列分段叠加结果Fig.2 Satellite rotation speed test time series segmentation merging results

图3 卫星某电流测试时间序列分段叠加结果Fig.3 Satellite electric current test time series segmentation merging results
图中分段子序列具有以下特点:
1)各子序列整体变化趋势相同,局部有细小差别,波形不完全重合。
2)测试子序列波动趋势不同,有的较为平滑如图2所示,有的较为激烈如图3所示。
2 相关定义
2.1 时间序列
时间序列数据[15]是指将使用同一统计指标的数值按照时间先后顺序排列而成的数列:

式中:时间序列T的长度为n。
2.2 截
使用滑动窗口函数[17],将时间序列T=(t1,t2,…,tn)分为固定长度为ω的多个截Si;ω=(ti,ti+1,…,ti+ω-1)。

式中:时间序列T分成n-ω+1个截。

2.3 段
截Si;ω=(ti,ti+1,…,ti+ω-1)被分成m个等长的段,表 示 为 集 合{sj,j=1,2,…,m},sj={t(j-1)×L+l,l=1,2,…,L},L=floor(ω/m),floor函数为向下取整函数。
图4为显示了时间序列划分的示意图。长度为512的时间序列样本被分为449个截,每个截被等分为4段。

图4 时间序列划分示意图Fig.4 Schematic diagram of time series division
3 符号化表示
3.1 段平均值
段sj={t(j-1)×L+l,l=1,2,…,L}的平均值¯sj计算如下:

表1列出了字母数为3~9的断点,断点字母符号的范围为3~5。使用φ-1个断点将分布空间划分为φ个等概率区域。N(0,1)高斯曲线下的B=β1,β2,…,βi的断点间面积等于1/φ。

表1 字母数为3~9的断点查找表Table 1 Look up table from breakpoints with alphabet sizes from 3 to 5

图5 φ=3和φ=4时,各平均值和小写字母之间的对应关系Fig.5 Corresponding relationship between average values and lower-case letters for φ=3 and φ=4
3.2 段斜率值
SAX忽略了时间序列段中对于分析时间序列分类和相似性至关重要的趋势信息这一重要特征。为了描述趋势信息,本文使用最小二乘法来计算每个时间序列的斜率值。

式中:L=floor(ω/m),为一个截中段的个数;j表示第j个段。
采用0°和±45°三个角度的斜率作为角度间隔值将角度空间(-90°,90°)划分为5个非重叠间隔,如图6所示,将计算出的斜率用大写字母表示,该字母对应于它们的驻留区域。通过这种方法,将角度空间(-90°,90°)转换为5个大写字母,代表5种情况:速降(A)、缓降(B)、水平(C)、缓增(D)和速增(E)。
每段用2个符号表示,大写字母表示斜率值,小写字母表示平均值。将计算出的大写字母和小写字母组合起来代表每个时间序列截。这些为每个时间截组成的大小字母串,称为趋势符号聚合近似(TrSAX)表示。图7为长度64的时间序列截的TrSAX字母串,对于φ=4,截的TrSAX字为AcAaDaEa。

图6 角度间隔和字母的对映关系Fig.6 Angle interval and corresponding letters

图7 趋势符号聚合近似(TrSAX)表示示意图Fig.7 Schematic diagram of trend symbolic aggregate approximation(TrSAX)representation
4 TrSAX词袋
与BOP方法类似,本文提取时间序列中的截作为子序列,并将其转换为TrSAX词,则一条时间序列可转为一个TrSAX词袋(Bag-of-TrSAX,BOTS)。
4.1 BOTS参数设定
BOTS有4个参数,分别为截长度ω和3个用于表示截的TrSAX参数,即字母符号数φ、该截中段的数量m和大写字母数γ。
4.2 BOTS工作流程
1)使用4.1节的TrSAX参数,为数据集建立一个大小为s=(γφ)m的TrSAX“词汇表”。
2)使用滑动窗口函数,将长度为n的原始时间序列T转换为n-ω+1个固定大小的截。
3)将这些时间序列截进行(0,1)标准化。
4)将时间截转换为TrSAX字。
5)时间序列T转换成为一个TrSAX字袋。
如果时间序列没有噪声或尖峰,是平滑的,则许多连续的截将转换为相同的TrSAX字。若对所有这些出现的TrSAX单词进行计数,则计数过多。
为此,为了防止这种情况,本文使用数据规约[17],仅统计重复出现的TrSAX词中第一个,并忽略所有重复项,直到新词出现。数据规约如下所示,首次出现的TrSAX词标粗。
假设获得如下TrSAX字符串S:

数据规约之后,字符串S迭代为S′:

然后,构造直方图H以计算出现在字符串S′中的TrSAX单词的数量。
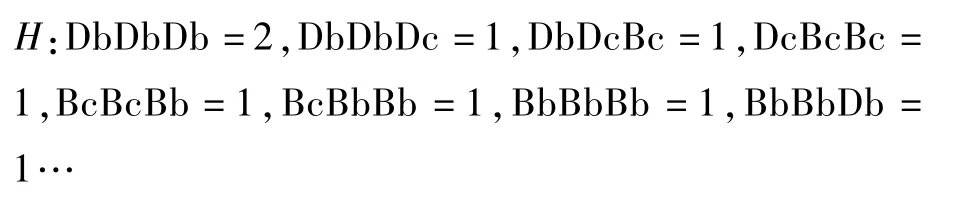
在每个时间序列获得直方图H之后,建立TrSAX字矩阵M,其中每一行对应于时间序列数据,每一列对应于TrSAX字。表2给出了一个时间序列的BOTS表示形式的虚拟示例。
对于获得的矩阵M,时间序列相似性度量为两行中列的累加平方值的平方根。给定矩阵Mm×n,Ri=[mi1,mi2,…,min]和 Rj=[mj1,mi2,…,mjn]为矩阵的第i行和第j行。

表2 时间序列的BOTS表示形式的虚拟示例Table 2 Visual example of BOTS representation for time series
两者从时间序列Ti和Tj转换而来,由BOTS表示,BOTS距离定义为

式中:

5 实验分析
5.1 实验数据集
目前的卫星遥测数据各周期内的正常模式、异常模式、故障模式均没有明确资料可参考,因而选用具有卫星遥测参数数据类似特性的公开数据集进行验证。从UCR公开数据集中筛选出与卫星遥测数据中的角度序列类似的SonyAIBORobot-Surface数据集,与卫星遥测数据中的转速序列类似的Fish数据集,与卫星遥测数据中的电流序列类似的FaceFour数据集进行实验验证,3个时间序列数据集的信息如表3所示。

表3 时间序列数据集详细信息Table 3 Details on time series datasets
5.2 参数训练
每个数据集包含一个训练集和一个测试集。采用训练集训练参数。如4.1节所述,BOTS分类器需要4个参数。
首先,使用网格搜索方法结合交叉验证从训练集中训练了这些参数。使用固定的大写字母数γ=5和字母符号数φ=4。对于段的数量m,本文选择{3,4,5}。对于截长度ω,都从16开始,每次加倍,直到小于或等于n/2。训练算法如下所示。
训练阶段的目的是找到一组参数值,使得训练的分类准确率最大。如果2组参数具有相同的分类准确率,则选择较小的参数。在训练阶段的最后,获得了训练数据集的最佳参数值集合{γ,φ,m,ω},可直接用在测试集上进行分类。
算法1BOTS分类算法。
From sk.learn.model_selection import cross_val_score
colLengh=len(trainInput[0])
end=int(math.log(colLengh/2,2))
windowList=list(map(int,np.logspace(4,end,end-3,base=2))) #截长度从16开始,每次加倍,直到小于或等于n/2
wordList=[3,4,5] #段的数量
tmpErrorRate,optimalWindow,optimalWord=1,None,None
for window in windowList:
for word in wordList:
testErrorRates=
cross_val_score(trainAndPredict(window,word,train Input,trainLabels,testInput,testLabels),X_trainval,Y_trainval,cv=5) #5折交叉验证
testErrorRate = testErrorRates.mean() #取平均数
logRecord.append([window,word,testErrorRate])
tmpErrorRate,optimalWindow,optimalWord=testErrorRate,window,word #得到最优的截长度、段的数量
5.3 TrSAX各项参数的影响
所有的参数值集合在测试集上运行实验,分类错误率结果及运行时间如图8和图9所示。
如图8所示,段的数量m从3增加到4,分类错误率随着截长的变化,出现非线性的变化。但是当m值为5时,分类错误率明显增加。m的值对分类错误率有影响,但没有一定规律。通常,对于本文中的大多数数据集的实验,值为3或4效果很好。

图8 三个数据集的分类错误率结果Fig.8 Classification Error rate results for three datasets

图9 三个数据集的运行时间结果Fig.9 Running time results for three datasets
如图9所示,段的数量m对运行时间的影响有2个规则。首先,m从3增加到5,运行时间明显增加。原因是TrSAX词汇量为s=20m,随m的增加呈指数增长,并且与运行时间成正相关。另外,在m相同的情况下,运行时间随截长的增加而减少,并且当字典大小较大时,这种情况更加明显。这是因为词汇量大且稀疏,并且截长ω的增加减少了映射单词的数量,同时减小了所获得的矩阵M 的大小,从而减少了运行时间。
5.4 对比算法及实验结果
由于本文方法旨在通过增加趋势信息来提高SAX的分类准确率。因此,将与1-NN SAX(或BOP)进行比较。另外,选择了ESAX和TSAX作为比较算法。如引言所述,基于ED和DTW 建立的1-NN分类器在短时间序列上具有很高的代表性和竞争力。因此,将本文提出的BOTS与这5种算法进行比较,如表4所示。
通过对3个数据集进行预定义分类的实验,验证了BOTS的有效性。实验结果显示,BOTS分类算法在3个数据集中分类错误率都是最低,表现最佳。在平均排名方面,基本顺序是BOTS>1-NN TSAX>1-NN SAX>1-NN DTW >1-NN ED>1-NN ESAX。

表4 不同表示算法的分类结果Table 4 Classification results of different representation algorithms
在所选择的3个数据集中,1-NN DTW 和1-NN ED表现较好,略低于1-NN SAX,优于1-NN ESAX。而BOTS和1-NN TSAX 表现优于1-NN SAX,而1-NN ESAX表现排名最差,为第6。说明趋势信息对降低分类错误率影响明显,对SAX增加合适的趋势信息可以明显降低分类错误率,而不合理的趋势信息则会明显增加分类错误率。
与SAX相比,TrSAX的优点在于:它可以通过每个段的趋势特征描述具有相同均值但趋势不同或趋势方向相同,但斜率有差异的某些模式(如缓增或速增)来提高分类的准确性。另外,对于某种时间序列,趋势信息对于专家而言非常重要,并且许多决策是通过趋势分析确定的。
TrSAX也有一些缺点:它仅是通过0°和±45°3个角度间隔值简单地将趋势特征区分为速增、缓增、水平、缓降和速降5个状态,这对于一些数据集有用。对于一些特殊的数据集,不同的角度间隔会使得分类准确率不同。如何合理确定角度间隔值的问题仍未解决。
6 结 论
1)本文提出了一种基于趋势符号聚合近似的时间序列表示方法TrSAX,可以将原始时间序列转换为矩阵结构,该矩阵结构可以使用最小二乘法结合SAX表示来描述每个时间序列段的平均值和斜率值。
2)对文献[21]中的“风云三号”卫星遥测数据进行了分析,得出角度序列、转速序列、电流序列3种遥测数据具有明显的周期性,以角度测试时间序列的幅角突变点为标识进行分段,进行叠加绘图,可以得到耦合度较高的周期曲线。在UCR公共数据集中筛选出与角度序列、转速序列、电流序列类似的3个数据集进行了实验验证。
3)通过实验分析段的数量m,截长度ω的各种值对BOTS分类性能的影响。期望较大m和较小的ω来描述原始时间序列的尽可能多的细节,并为时间序列分类带来更好的结果。但是,实验结果证明这一期望没有实现。随着m的增加或ω的减少,分类错误率不会持续下降。为了确定m和ω的最佳组合,需要在提供的训练数据集上进行训练。此外,m对分类错误率更敏感,并且m比ω具有更大的影响。对于大多数数据集,m等于3或4可以产生令人满意的结果。
4)对比实验结果显示,与卫星遥测参数中角度序列、转速序列、电流序列类似的3个公开数据集中,BOTS分类错误率明显低于其他5种分类方法,对未来卫星模拟量遥测参数的分类提供了一种新的思路。
在未来的研究中,将研究参数m 和ω的设置,以加速和简化参数的确定,同时需要对角度间隔值进行进一步的优化。此外,还将探索基于TrSAX的其他任务,如聚类以及相关性分析等。
猜你喜欢
山西教育·招考(2021年8期)2021-12-17
计算机测量与控制(2021年9期)2021-10-08
语数外学习·高中版上旬(2020年5期)2020-09-10
新课程·上旬(2019年1期)2019-03-18
新高考·高三数学(2017年4期)2017-07-10
教师·中(2017年3期)2017-04-20
理科考试研究·高中(2016年10期)2017-01-17
试题与研究·教学论坛(2016年27期)2016-08-11
企业文化·中旬刊(2015年10期)2016-03-09
教学研究与管理(2014年4期)2014-05-16
