
基于GA_BP神经网络的地铁车站深基坑变形预测研究
2021-04-30 03:33
四川水泥 2021年5期
(河南科技大学应用工程学院,河南 三门峡 472000)
0 引言
地铁车站深基坑工程由于开挖工期长、施工难度大、地质条件和周边环境复杂、施工过程中各种不确定的因素多等特点,致使地铁车站深基坑工程施工具有很高的风险性,为了保证工程施工顺利实施,开展变形监测和预测工作具有重要的意义。近年来,诸多学者运用时间序列、灰色系统、ARMA模型、BP 神经网络等多种方法进行基坑监测数据的处理及预测。BP 神经网络在非线性映射、自适应学习、输入输出灵活等方面具有优良性能,因而被广泛应用于基坑变形预测。但通过研究发现,BP 神经网络在应用过程中出现收敛速度慢、容易陷入局部极小值、隐含层神经元不确定等不足,而导致预测结果不理想。基于此,本文以郑州市地铁5 号线某车站深基坑变形监测实测数据为基础,利用GA 遗传算法在全局寻优上的强大搜索能力,优化BP神经网络,避免预测过程陷入局部极小,通过工程实证分析,表明GA_BP组合预测模型能够有效提高预测精度。
1 变形预测BP 神经网络
1.1 变形预测BP 神经网络模型简介
变形预测BP 神经网络是一种人工神经网络的误差逆向传播训练算法[1],其学习过程由信号的正向传播和误差的反向传播两个过程构成,正向传播时,在输入层输入样本数据,经过隐含层处理后,传向输出层,若输出层的实际输出与变形监测实际值不符时,则转向误差反向传播阶段,将输出误差通过隐含层向输入层传播,并将误差分摊给各层的神经元,获取各层神经元的误差信号,作为修正各个神经元权值的重要依据[2]。BP 神经网络的拓扑结构如图1所示。
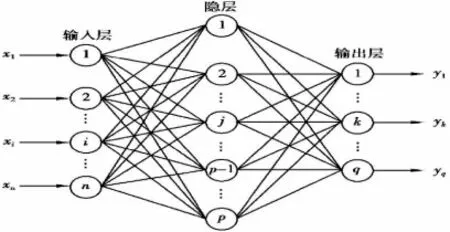
图1 BP 神经网络拓扑结构图
1.2 BP 神经网络预测模型的缺陷
BP 神经网络预测模型算法决定了误差函数存在多个局部极小值,不同的网络初始权值直接决定了BP 神经算法在收敛于局部最小值还是全局最小值,则会产生不同的预测结果。因此,为了得到理想的预测结果,必须通过计算来确定收敛于全局极小值的网络初始权值,遗传算法优化BP 神经网络能够解决初始权值选取问题。
2 基于遗传算法的GA-BP 神经网络
遗传算法主要基于Darwin 的进化论和Mendel 的遗传学说,Darwin 的进化论的核心观点是适者生存,Mendel 的遗传学说的主要观点是基因遗传原理Mendel 的遗传学说[3]。它从一组随机产生的初始解开始训练、优化,通过对遗传序列的选择、交叉以及变异筛选,保留下来适应度好的个体,新的群体不仅继承了上一代的优点,又使得新的群体优于上一代,如此反复循环,最后收敛于最适应环境的某个个体上,既得到了问题的最优解[1][4]。遗传算法的实施流程图如图2所示。
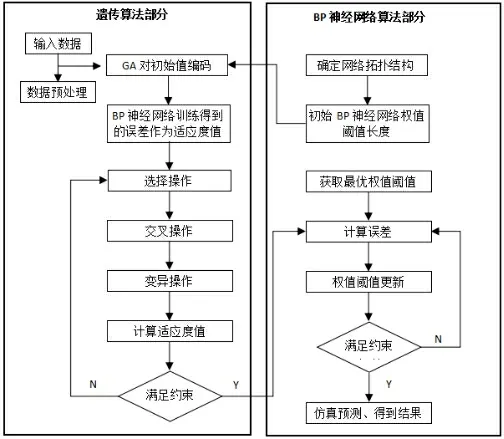
图2 遗传算法的实施流程图
3 工程案例
3.1 工程概况
郑州地铁5 号线某车站结构型式为地下三层三跨箱型框架结构,岛式车站,站台宽13m,有效站台长度140m,车站外包总长170.2m,标准段外包总宽22.3m。车站顶板覆土4.0m,主体结构标准段基坑深24.0m,宽22.3m;盾构井段基坑深25.7m,宽26.5m。拟建工程场地属于A 区地貌,车站在开挖过程中不可避免会对周围地层、地下管线、建(构)筑物等造成影响,为了保证施工期间道路畅通,周边环境安全稳定以及工程结构自身安全,必须对监测数据进行预测,指导施工和改进设计方案。
3.2 模型建立
取地面沉降监测点DBC-9-3 2016年3月4日到2016年7月22日的累计变形监测数据作为训练样本,建立深基坑地表沉降经遗传算法优化的BP神经网络模型,并运用该模型对DBC-9-3监测点7月29日、8月5日、8月12日的累计变形量进行预测。首先利用遗传算法优化BP算法程序寻找全局最优解,确定最优的初始权值和阈值,然后利用选取的训练样本训练该神经网络,达到预设的约束条件后,利用该模型进行预测。输入值为前三期累计变形量、隐含层节点数设为5、输出值为第四期累计变形量,以此类推,迭代次数设为200。计算结果如表1所示。
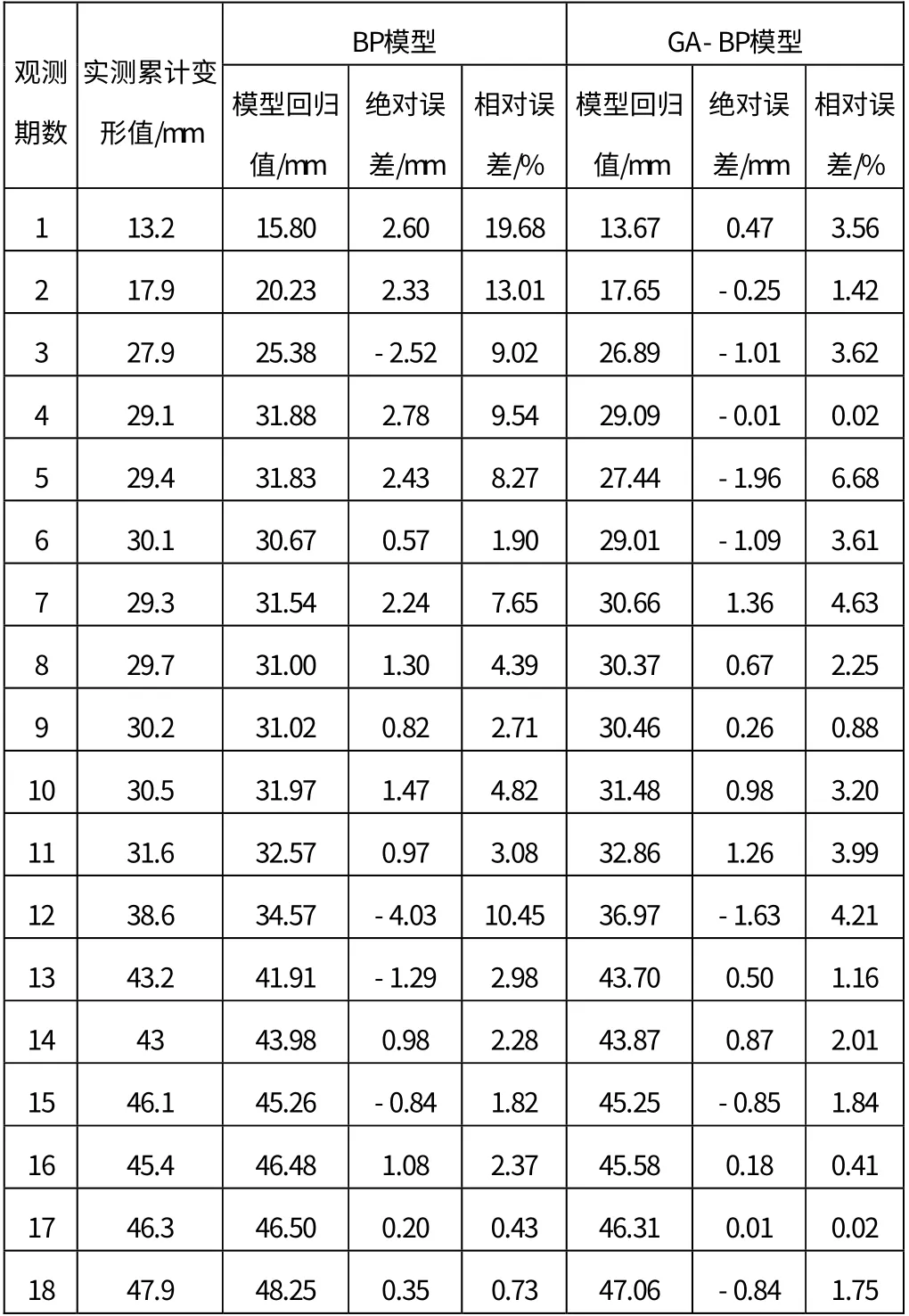
表1 GA-BP模型与BP模型回归值对比
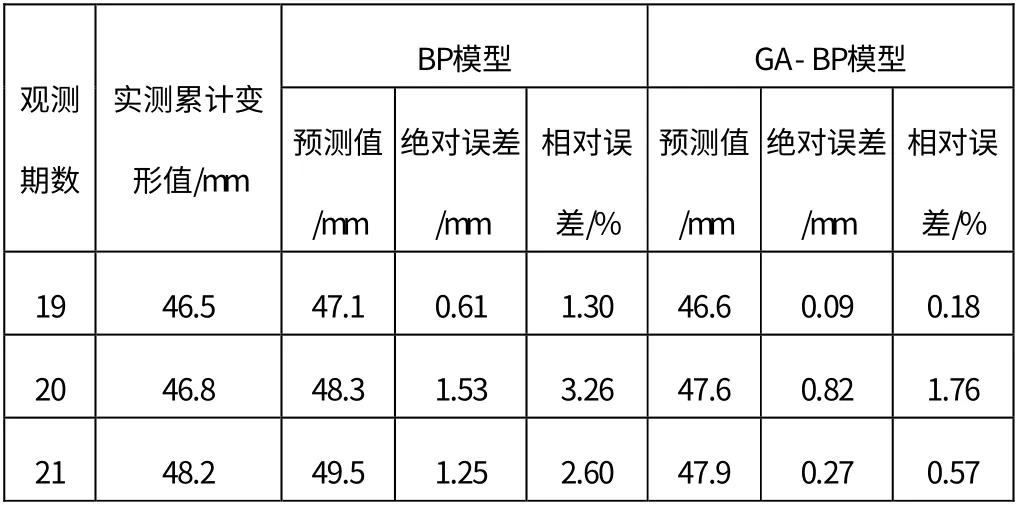
表2 GA-BP模型与BP模型预测对比
3.3 结果分析
通过表1、表2可以看出,BP 神经网络模型模拟最大绝对误差值为-4.03mm,最大相对误差为19.68%,模拟值相对误差平均值为5.84%,相关系数R2为0.9690,模型预测最大绝对误差为1.53mm,最大相对误差为3.26%;GA-BP 模型模拟最大绝对误差值为-1.96,最大相对误差为6.68%,相关系数R2为0.9902,模型预测最大绝对误差为0.82mm,最大相对误差为1.76%。从上述数据可以看出,GA-BP 神经网络模型能够有效提高预测精度。
4 结论
(1)采用经过遗传算法优化的BP 神经网络模型来预测地铁车站深基坑施工周边地表沉降值,误差小,收敛速度快,证明该模型与方法分析此类时间序列数据有较好的适用性和准确性。
(2)GA-BP 模型精度很大程度上依靠训练样本的数量,训练样本越多,预测精度就越高,应该及时将新的监测信息添加到训练样本中,及时更新模型以便得到更好的预测效果。
猜你喜欢
高技术通讯(2022年7期)2022-09-28
成都信息工程大学学报(2022年3期)2022-07-21
汽车工程(2021年12期)2021-03-08
科技创新与应用(2020年6期)2020-02-29
电子制作(2019年24期)2019-02-23
计算机与数字工程(2018年5期)2018-05-29
计算机测量与控制(2018年3期)2018-03-27
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
