
融合手部骨架灰度图的深度神经网络静态手势识别∗
2021-05-15 06:59章东平束元周志洪
传感技术学报 2021年2期
章东平束 元周志洪
(1.中国计量大学信息工程学院,浙江省电磁波信息技术与计量检测重点实验室,浙江 杭州310018;2.上海市信息安全综合管理技术研究重点实验室,上海200240)
近年来,手势识别受到了很多学者的广泛关注[1-5],但基于机器视觉的手势识别,尤其是在无约束环境下通过手部动作来控制智能机器[6]方面,仍然是一项具有挑战性的任务。 在无约束环境下进行手势识别时涉及的挑战主要包括:手势的自由度值较大[7]、自我遮挡、手部定位不准确和背景环境复杂等方面。 基于上述众多因素的影响,无约束环境下手势识别算法的综合性能普遍不高,尤其是识别准确率方面,具有较大的提升空间。
手势识别基于运动状态可分为静态手势识别和动态手势识别。 静态手势,是指每一种静态形式的手部姿势都分别表示某种特定的意义,即一张图片代表一个手势。 动态手势是在一定的时间段内,由一组静态手部姿势形成的一个更为复杂的手势来表示某种特定的意义,即一段视频代表一个手势。
基于传统方法的手势识别算法主要有:一种贝叶斯视觉注意模型[8]在检测和识别静态手势时,将选择性注意模型引入,且模拟了人体大脑视觉皮层的部分功能,然后使用支持向量机(SVM)分类器对手势进行分类,该方法在NUSHP-II 手势数据集上的准确率为94.36%;一种有效结合机器学习模型与模板匹配的方法[9],在作者的数据集上获得了99.75%的基本手势识别率以及100%的复杂手势识别率;一组深度混合分类器[10],用于以自我为中心的手势识别,在NUSHP-II 数据集的识别精度为97.72%;一种朴素贝叶斯分类器系统[11],在基于静态手势的协作机器人方面表现良好,其结果在不同的工作环境、距离、角度、不同大小的人等条件下产生了较好的鲁棒性;一种融合表面肌电和加速度传感信息的识别方法[12],对四路表面肌电与三轴加速度信号进行数据采集,通过支持向量机完成分类,在作者的数据集上达到了91.2%的识别率。
基于神经网络的动态手势识别算法主要有:文献[13]提出了一种ResNet-10 轻型CNN 架构用于手势检测,提出了一种D-CNN ResNeXt-101 模型来对手势进行分类,在EgoGesture 数据集和NVIDIA Dynamic Hand Gesture 数据集进行了手势分类测试,准确度分别为94.04%和83.82%;一种融合了Masked Res-C3D 网络和骨架LSTM 模型[14],并提出了一种通过权重融合层融合异常结果和分类模型缺陷的方案,用于RGB-D 视频中的异常手势识别,在IsoGD 数据集上识别率为68.42%。
基于神经网络的静态手势识别算法主要有:一种使用CNN 的手势识别[15],其背景减少技术用于去除建议手部区域的敏感背景,并获得了95.96%的平均识别率;一种基于R-CNN 的手势识别[16]产生了识别精度为99.4%,但平均一张图像的识别计算时间为40 s,这在计算上是较为昂贵的;一种使用Faster R-CNN 对象检测器为协作机器人建立的智能手势识别[17],在作者自己的数据集上测试的平均准确度为91.94%,且平均一张图像的识别计算时间为230 ms;一种通过迁移学习利用两个天线的阻抗变化和深度卷积神经网络对频谱图图像对手势进行分类[18],该方法在作者自己的数据集上准确度达到94.6%;一种带有CPF 的Faster R-CNN 对象检测器来找到RGB 图像中手的准确位置[19],在Gloves 数据集上进行了测试,平均精度为95.51%。
为解决在无约束环境下静态手势识别准确率不高的问题,本文提出了一种融合手部骨架灰度图的深度神经网络。 首先,构建了一种基于手部关键点及其相关性的手部骨架灰度图作为网络输入。 当训练网络时仅输入RGB 图像,因图像中的手容易受到无约束环境下灯光、自身手指间的遮挡以及背景颜色,尤其是自身肤色等方面的影响,导致网络仅依靠通过RGB 图像获得的纹理,颜色和轮廓等特征信息无法实现更精准的手部检测定位,从而进一步的导致静态手势识别在无约束环境下手部定位不准确且准确率不高的情况;而在输入RGB 图像的基础上同时输入手部骨骼灰度图,并将两者以增加通道的形式进行特征融合后,通过手部关键点及其相互间的连接信息增强手部图像特征,增大手势的类间差异,同时降低无约束环境对手势识别的影响,以提高手部识别的准确率。 其次,在网络结构方面,以yolov3[20]神经网络作为主干网络,将残差模块中的卷积替换为扩展卷积,通过增大卷积视野的方式来提高对手势占画面比较大情况下的准确率。 然后,在手部骨架灰度图和RGB 图像特征融合后,通过SE 模块学习通道之间的相关性,自动学习每个特征通道的重要程度,对每个通道上的特征进行缩放,以增强两张图像之间的特征融合。 最后,采用RReLU激活函数来代替Leaky ReLU 激活函数,以提升网络的鲁棒性,从而降低无约束环境对静态手势识别的影响。
1 网络结构
一种融合手部骨架灰度图的深度神经网络如图1 所示:以yolov3 神经网络为主干网络,首先通过RGB 图像经openpose 提取的手部数据来构建手部骨架灰度图,并连同RGB 图像一起输入到网络中;其次在多尺度模块前以增加通道的形式将RGB 图像的特征与手部骨架灰度图进行特征融合,并一个通过SE 模块学习通道之间的相关性,对每个通道上的特征进行缩放;然后将残差模块中的1∗1 的卷积改成膨胀系数为2 的扩展卷积,3∗3 的卷积改成膨胀系数为3 的扩展卷积;最后将激活函数由Leaky ReLU 函数改为RReLU 函数。
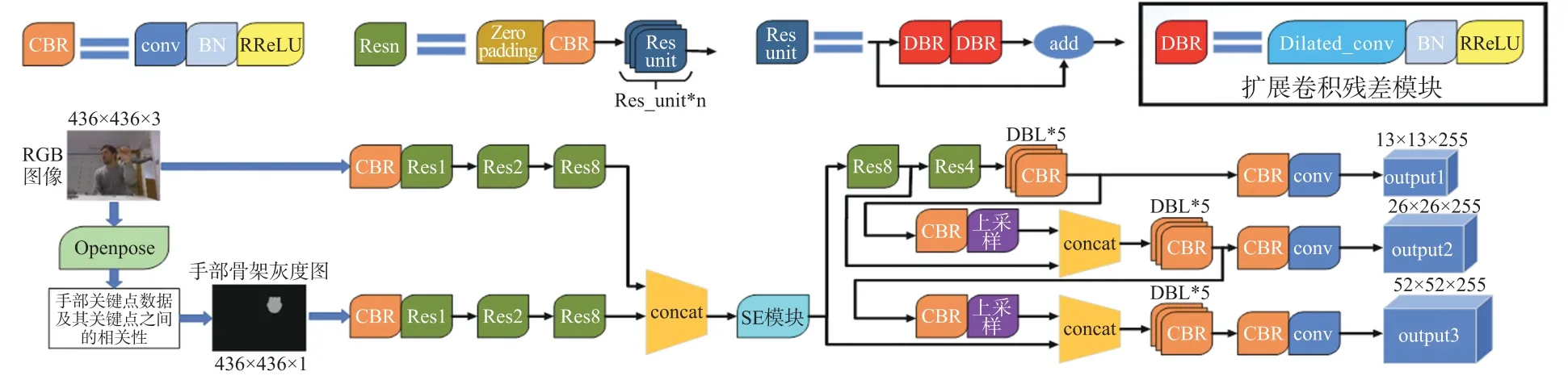
图1 融合手部骨架灰度图的深度神经网络
2 手部骨架灰度图构建
2.1 基于openpose 获取手部骨架信息
卡内基梅隆大学在2017 年CVPR 会议上提出一种提取手部关键点的开源代码[21], 简称openpose。 手部关键点名称如表1 所示,手部骨架示意图如图2 所示,表1 中的序号分别对应图2 中的关键点序号。 该算法的原理主要是利用立体几何,以多视图作为监督信号源,生成一致的手部关键点标签,引导训练手部关键点检测器,输出手部21个关键点归一化后的二维坐标值及其对应的得分。

图2 手部骨架图

表1 openpose 手部关键点名称
2.2 手部骨架灰度图构建
提出的一种基于手部关键点信息和关键点之间相关性的手部骨架灰度图,如图3 所示,是在openpose 输出的基础上,将归一化后21 个手部关键点位置坐标值(x,y)及其对应关键点得分的输出文件进行如下计算和处理所得。

图3 部分手势的GHS 图像
首先,按照原图的像素级宽高进行还原,以便在原图像上定位。 然后以关键点为圆心,r个像素点为半径画圆,所得的圆内所有像素点的灰度值,均为关键点得分乘以255。 最后,关键点之间的关联性表现在以上述圆的直径为宽,关键点之间欧式距离为长,构成的长方形内所有像素点的灰度值为两个关键点的平均得分乘以255。 手部骨架灰度图的其他像素点的灰度值均置为0。 上述计算如式(1)~式(3)所示:
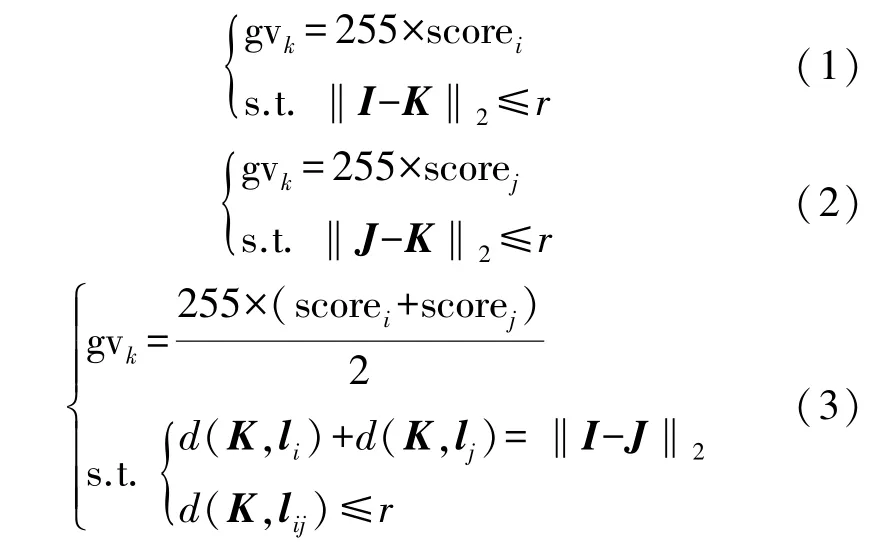
式中:gv 表示灰度值,k表示第k个像素点,score 表示关键点得分,i和j分别表示第i和j个关键点,I、J和K分别表示对应关键点在原图像上的坐标值(x,y),I-K2表示求两个坐标点之间的欧式距离;d(K,li)表示求点K到直线li之间的距离,lij表示过点I和J的直线,li表示过点I且与直线lij垂直的直线,lj表示过点J且与直线lij垂直的直线。
2 SE 模块
SE 模块[22]是2018 年由来自Momenta 的高级研发工程师胡杰及其所在WMW 团队在CVPR 会议上提出的,模块的网络结构如图4 所示,其中e 是一个缩放参数,目的是为了减少通道数从而降低计算量。 该模块的组成有3 个部分,分别是Squeeze 操作、Excitation 操作和Scale 操作。

图4 SE 模块网络结构
Squeeze 操作如式(4)所示,利用全局的池化,将大小为C×H×W的输入特征综合为C×1×1 的特征描述,其中C为通道数,H和W分别为图像的高宽。

Excitation 操作如式(5)所示,先利用一个全连接层操作将W1和zc相乘,其中W1的维度是(C/r)×C,再经过一个ReLU 层,输出的维度不变;然后再将结果和W2相乘,且和W2相乘也是一个全连接层的过程,W2的维度是C×(C/r),因此输出的维度就是1×1×C;最后再经过sigmoid 函数,得到s。
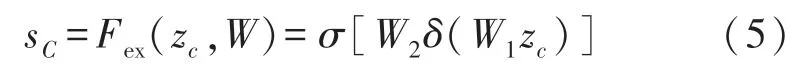
式中:δ和σ分别表示第一次全连接操作和第二次全连接操作。
Scale 操作如式(6)所示,即把uc矩阵中的每个值都乘以sc,其中uc是一个二维矩阵特征图,sc是权重系数,YC表示结合了权重之后SE 模块的最终输出。
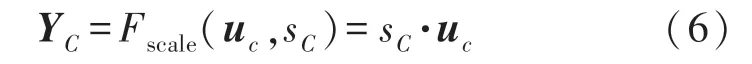
3 改进yolov3 原激活函数
3.1 Leaky ReLU 激活函数
Yolov3 中使用的激活函数是Leaky ReLU 激活函数,作用在于对网络的上一层节点输出做非线性转换,同时解决神经网络的梯度消失问题。 相较于ReLU 激活函数,Leaky ReLU 是给所有负值赋予一个非零斜率,其计算如式(7)所示:

式中:xi表示函数输入,yi表示函数输出,ai表示一个在(0,1)区间内的一个固定参数。 由于在训练过程中ai是固定不变的,从而限制了网络在无约束环境下的鲁棒性。
3.2 RReLU 激活函数
RReLU 激活函数,是在Leaky ReLU 激活函数的基础上,将负值的斜率在训练中变为随机的值,即ai是从一个均匀的分布中随机抽取的数值,但在测试环节就会固定下来。 RReLU 激活函数如式(8)所示:

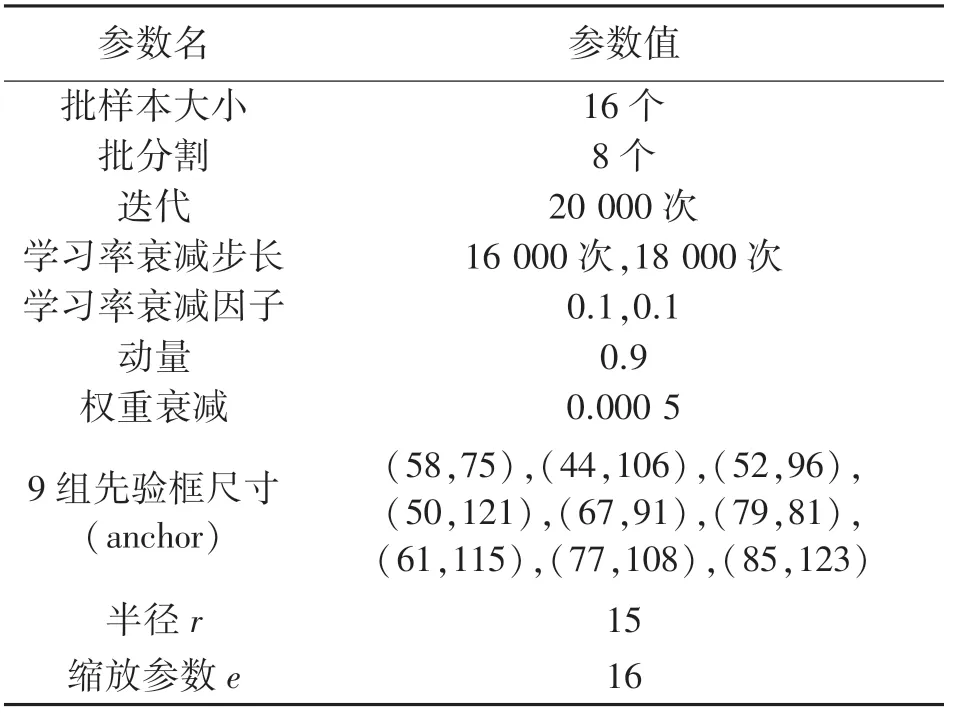
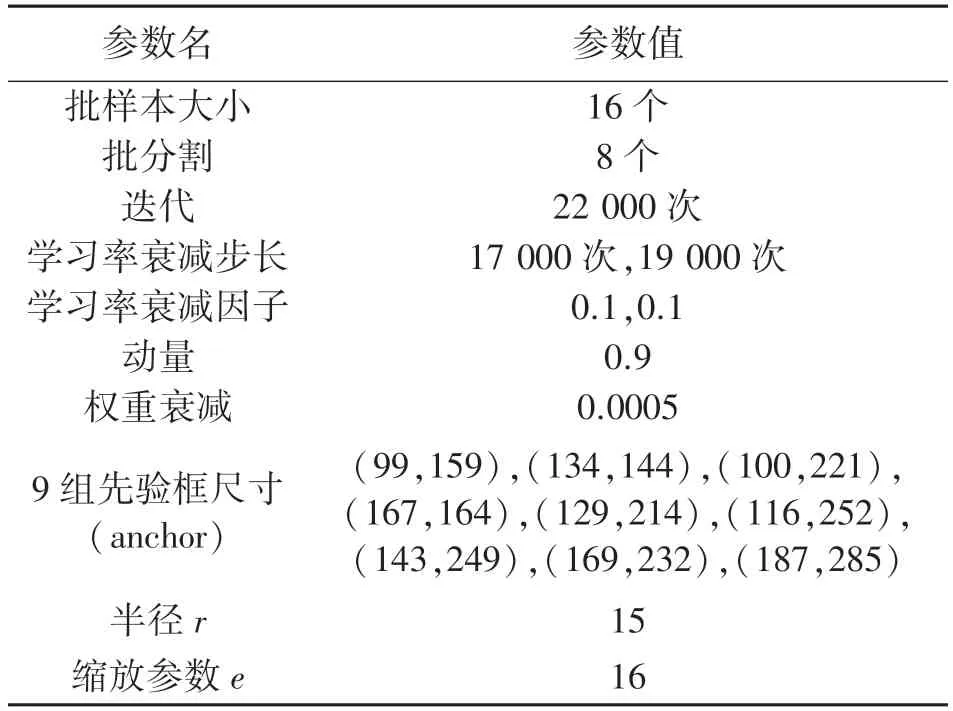
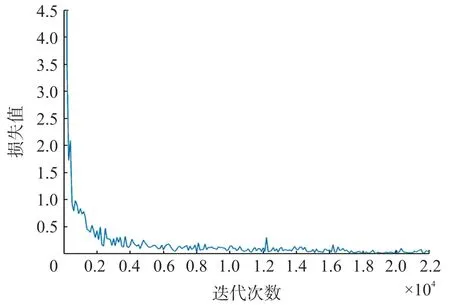
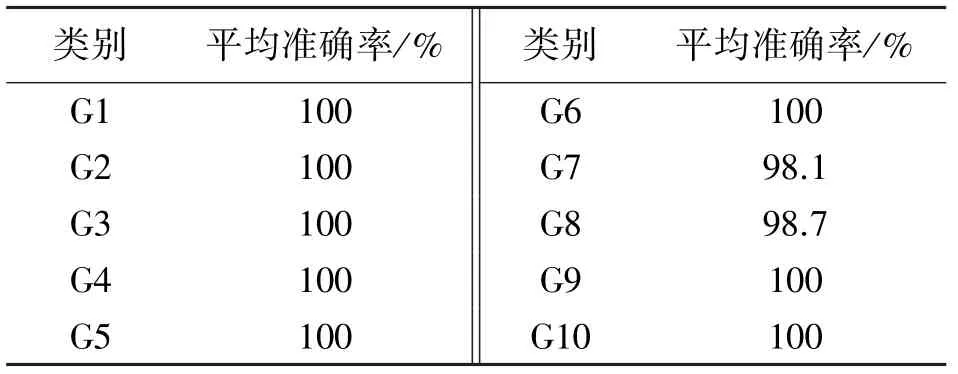
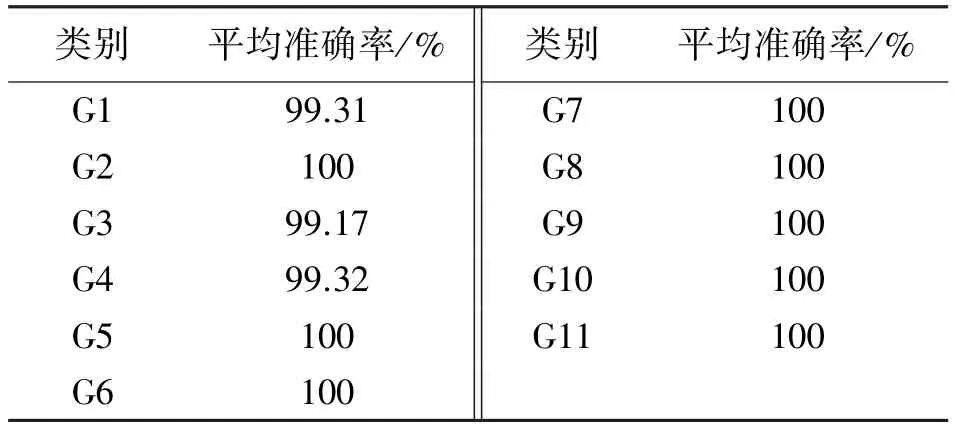
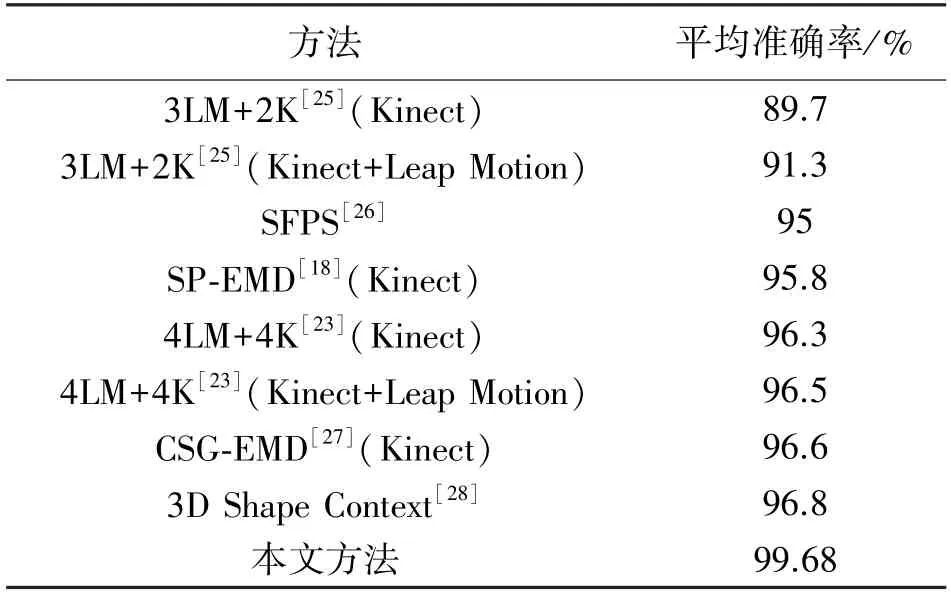
式中:ai∈U(l,u),l Yolov3 网络引入了FPN 结构,同时它的检测层由三级特征层的融合,直接将浅层网络所得的特征与深度卷积后的特征进行融合,这样的结构解决了其他部分网络(例如SSD 模型)最后一层自动筛掉小物体的问题,提高了小物体的识别能力,从而提高了在手部占画面比较小情况下的手势识别精度。 且Yolov3 网络模型的识别速度达到了较高的实时水平,而本文因手部骨架灰度图的提取需要一定时间,所以以Yolov3 为主干网络后可一定程度上保证了本文提出的手势识别网络模型的识别速度。 4.1.1 Microsoft Kinect & Leap Motion 数据集 Microsoft Kinect & Leap Motion 数据集[23]包含RGB 数据、深度数据和Leap Motion 数据。 该数据集包含由14 个不同的人分别做10 种不同的手势,并且每个人对每个手势重复做10 次,总共有1 400个不同的数据样本。 对应10 个手势的RGB 图像图5所示,例如拳头,“Yes”、数字以及小拇指等。 图5 Microsoft Kinect & Leap Motion 数据集RGB 手势图像示意图 4.1.2 Creative Senz3D 数据集 Creative Senz3D 数 据 集[24]是 通 过 Creative Senz3D 相机获取的。 该数据集包含4 个不同的人执行的11 个不同的手势,同时每个人将每个手势分别重复30 次,总共进行了1 320 次采集。 对应11个手势的RGB 图像图6 所示,例如拳头,数字1 至5 等。 图6 Creative Senz3D 数据集RGB 手势图像示意图 所有的训练和测试均在台式电脑上进行,电脑的主要配置为Intel(R)Core(TM)i5-8400 CPU @2.80 GHz、6GB 的GPU NVIDIA GeForce GTX 1060显卡和8GB 的运行内存。 程序在Windows10 系统下运行,同时调用并行计算架构(CUDA)、英伟达神经网络库(Cudnn)、开源计算机视觉库(OPENCV)。模型训练时使用官网提供预训练权重文件来初始化本文的网络权重参数,以便训练时加快模型的收敛速度。 在yolov3 中,由于适合的先验尺寸将会直接影响到静态手势识别时的速度以及目标框在定位时的精度,因此对所有训练样本数据集上标注出的边界框数据采用K-means 聚类来获得最优的9 组先验框尺寸。 具体训练参数值如表2 和表3 所示。 其中,参数半径r用于构建手部骨架灰度图,缩放参数e用于SE 模块的通道数缩放。 表2 Microsoft Kinect & Leap Motion 数据集的训练参数设置 表3 Creative Senz3D 数据集的训练参数设置 图7 Microsoft Kinect & Leap Motion数据集训练时损失曲线图 在Microsoft Kinect & Leap Motion 数据集上,最终模型共训练20 000 次,耗时29 h。 训练模型时,从14 个人中随机抽取10 个人作为训练数据,即训练数据集共1 000 张RGB 图片和1 000 张对应的手部骨架灰度图,剩余的4 个人的400 张RGB 图像和400 张对应的手部骨架灰度图作为测试数据集。 在训练过程中,通过绘制模型损失曲线观察训练动态过程,其对应的损失值变化曲线如图7 所示。 可看出:模型在前期迭代中损失值缩减迅速,模型快速拟合;当迭代训练4 000 次后,损失值下降放缓;当迭代至20 000次时,损失值收敛至0.010 3,结束训练在Creative Senz3D 数据集上,最终模型共训练22 000 次,耗时25 h,训练模型时,按照不同的手势执行人采用留一法将数据分为训练数据集和测试数据集。 训练数据集由3 个人共990 张RGB 图片和990 张对应的手部骨架灰度图,剩余的1 个人的330 张RGB 图像和330 张对应的手部骨架灰度图作为测试数据集。 在训练过程中,通过绘制模型损失曲线观察训练动态过程,其对应的损失值变化曲线如图8 所示。 可看出:模型在前期迭代中损失值快速缩减,模型快速拟合;当迭代训练4 400 次后,损失值下降放缓;当迭代至22 000 次时,损失值收敛至0.021 5,结束训练。 图8 Creative Senz3D 数据集训练时损失曲线图 本文提出的一种融合手部骨架灰度图的深度神经网络,每一步改进分别在Microsoft Kinect & Leap Motion 数据集上测试结果如表4 所示,在Creative Senz3D 数据集上测试结果如表5 所示。 该网络算法在Microsoft Kinect & Leap Motion数据集上每一类的准确率情况,具体如表6 所示,其中除G7 和G8 的准确率分别为98.1%和98.7%,其他类别准确率均达到了100%。 在Creative Senz3D数据集上每一类的准确率情况,具体如表7 所示,其中除G1、G3 和G4 的准确率分别为99.31%、99.17%和99.32%,其他类别准确率均达到了100%。 表4 每一步改进在Microsoft Kinect & Leap Motion数据集上的测试结果 表5 每一步改进在Creative Senz3D 数据集上测试结果 表6 Microsoft Kinect & Leap Motion 数据集上10 类的测试结果 表7 Creative Senz3D 数据集上11 类的测试结果 不同的手势识别方法以及yolov3 在Microsoft Kinect & Leap Motion 数据集上测试结果如表8 所示。 通过对比可以清晰的看出,本文提出的方法比其他方法在平均准确率上至少提高了2.88%,且基于GHS 图像和RGB 图像的手势识别速度为26 fps。 表8 不同算法在Microsoft Kinect & Leap Motion数据集上的测试结果 不同的手势识别方法以及yolov3 在Creative Senz3D 数据集上测试结果如表9 所示。 通过对比可以清晰的看出,本文提出的方法比其他方法在平均准确率上至少提高了0.2%,且基于GHS 图像和RGB 图像的手势识别速度为31 fps。 表9 不同算法在Creative Senz3D 数据集上的测试结果 通过上述实验结果表格的对比,说明无约束环境下静态手势在识别过程中,使用手部关键点及其相互关联性构建手部骨架灰度图,以yolov3 为主干网络,添加扩展卷积残差模块和SE 模块,并用RReLU 函数作为激活函数的方法在识别准确率上有着较大的提升。 该方法在Microsoft Kinect & Leap Motion 数据集和Creative Senz3D 数据集上均进行了测试对比实验,相比其他静态手势识别方法,本文提出的识别方法在这两个无约束环境下的静态手势数据集有着优秀的表现。 在Microsoft Kinect & Leap Motion 数据集和Creative Senz3D 数据集上准确率均达到了最高,分别为99.68%和99.8%,且基于GHS 图像和RGB 图像的手势识别速度分别为26 fps 和31 fps。 手势识别在空间定位方面依旧有着不小问题。如今的手势识别算法距离理想的空间定位能力,即得到手部的精准位置还有着不小的差距,而其也正是未来人机交互的重要基础。 同时,本文提出的解决方法仍未能完全解决对应的挑战和难点,尤其在网络延迟和实时性方面依旧有着较大的提升空间。3.3 Yolov3 为主干网络
4 实验
4.1 实验数据集介绍


4.2 实验参数设置

4.3 在Microsoft Kinect & Leap Motion 数据集和Creative Senz3D 数据集上实验结果分析



5 结论
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
红领巾·萌芽(2019年9期)2019-10-09
小学科学(学生版)(2018年12期)2018-12-19
数学物理学报(2017年5期)2017-11-23
小学阅读指南·低年级版(2017年6期)2017-06-12
中国卫生(2014年2期)2014-11-12
语文知识(2014年7期)2014-02-28
