
基于残差神经网络的烟丝类型识别方法的建立
2021-05-26 10:22周明珠刘德祥王宏强李晓辉
烟草科技 2021年5期
钟 宇,周明珠,徐 燕,刘德祥,王宏强,董 浩*,3,4,禹 舰,李晓辉,杨 进,邢 军
1.新疆维吾尔自治区烟草质量监督检测站,乌鲁木齐经济技术开发区天柱山街55号 830026 2.国家烟草质量监督检验中心,郑州高新技术产业开发区翠竹街6号 450001 3.中国科学院合肥物质科学研究院 安徽光学精密机械研究所 光电子技术研究中心,合肥市蜀山湖路350号 230031 4.中国科学技术大学,合肥市金寨路96号 230026
1 材料与方法
1.1材料
从一批未掺配烟丝中随机取梗丝、叶丝、膨胀叶丝和再造烟叶丝各100根。
1.2图像采集与处理
使用500万像素工业相机和35 mm焦距工业镜头(德国Basler acA1920-40gm GigE相机和配套镜头),采集4种类型烟丝各100个样本的图像,单个图像大小为2 592像素×1 944像素。
图像处理、模型建立、数值计算代码均采用python语言;残差卷积神经网络构建采用开源的tensorflow-gpu 1.13.2,keras2.1.5;图 片 处 理 采 用opencv 4.3.0.36;数据集的组织、分割以及模型评价指标计算采用numpy 1.17.4,pandas 1.0.5,sklearn 0.23.1;图像处理单元(Graphic Processing Unit,GPU)采用NVIDIA GeForce RTX2060。
1.3 模型构建
1.3.1 数据集构建
通过opencv将样本缩放至256像素×256像素,以减小样本内存。将处理后样本的80%作为训练集进行模型训练,20%作为测试集用以验证模型表现。训练集和测试集的样本分布见表1。

表1 训练集和测试集样本数量分布Tab.1 Sample quantity distribution of training set and test set (张)

图1 梗丝样本图像Fig.1 Image of cut stem sample
为有效降低模型“过拟合”风险,采用水平/竖直方向平移、水平/竖直方向翻转、随机旋转、随机缩放、错切变换等方式对数据集进行增强[15]。图1为原数据集中梗丝的一个样本图像,图2为梗丝图像经不同方式变换后的增强图像。经算法处理后,原数据集从400张增强至7 832张,增强后的训练集和测试集样本数量分布见表2。

图2 梗丝样本经数据增强后图像Fig.2 Images of cut stem samples after image enhancement

表2 数据增强后训练集和测试集样本数量分布Tab.2 Sample quantity distribution of training set and test set after image enhancement (张)
1.3.2 分类模型构建
基于残差神经网络结构构建了烟丝类型分类模型,输入层为224像素×224像素、3通道的张量。为防止模型“过拟合”,网络中多处增加了批归一化层[16],激活层均采用ReLU激活函数[17]。各模型层及输入图像张量在网络前向传播计算时,张量形状变化情况见表3。其中,恒等映射模块及卷积模块结构见图3。
1.1.1 患者入选标准 ①首发或复发急性心力衰竭/慢性心力衰竭急性发作期心功能NYHA分级:Ⅲ~Ⅳ级;②休克诊断根据《实用内科学》第十四版标准[1];同时符合以上2项。本研究经本院伦理委员会论证同意开展,所有入组患者均签署知情同意书。
样本经输出层被计算为长度为4的张量,利用公式(1)计算该样本属于某分类的概率值。

式中:pi,j—样本i预测为某分类(j)的概率;Zi,j—样本i对应的神经网络输出张量。
得到概率值后,再利用公式(2)计算该迭代次的损失值。

式中:yi,j—样本i的真实标签值,长度为4的张量,j处为1,其余处为0;pi,j—样本i预测为某分类(j)的概率;m—样本数。
模型在优化算法的作用下,逐次迭代更新神经网络权值以降低损失值,直至达到指定迭代次数后停止训练。
2 结果与分析
2.1 加载权值对模型的影响
在样本量或训练资源较少的情况下,训练出较优的网络权值需要较多的迭代次数。基于此,迁移学习领域的研究工作近年来取得较大进展[18-20],通过迁移已有的知识来解决目标领域中仅有少量有标签样本数据甚至无标签样本数据的学习问题。其过程是将已完成训练的模型权值全部或部分载入到当前模型中,再根据实际问题全部或部分训练模型的权值,可以有效提高模型的训练效率。何凯明等[14]在ImageNet数据集上使用残差神经网络训练网络权值,实现了top-1分类准确率75.3%,top-5分类准确率92.2%,并发布了Resnet50的神经网络权值。基于本文方法所构建的模型中,特征提取模块迁移了Resnet50权值,全连接层模块各层权值的初始值由随机初始化的方式进行赋值,在模型训练时,只更新全连接层模块的权值,特征提取模块各层权值不更新。对于是否加载迁移的权值,模型在训练集和测试集上的表现见图4。可见,加载权值的模型训练时损失值下降较快,下降曲线较为平滑。在相同迭代次数下,训练完成时损失值较低,在测试集上的表现相同。加载权值的模型训练集和测试集的准确率差异不大,且均比不加载权值的模型高,说明模型的泛化能力和准确率均较高。

表3 残差神经网络结构Tab.3 Structure of residual neural network

图3 残差神经网络中恒等映射及卷积模块结构图Fig.3 Structure of identity mapping module and convolution module in residual neural network

图4 加载权值对模型的影响Fig.4 Influence of weight loading on model
2.2 优化算法和学习率对模型的影响
优化算法是通过改善训练方式使损失值最小化。在训练神经网络权值时,梯度下降是一种最常用的算法,利用公式(3)对神经网络的权值进行更新。
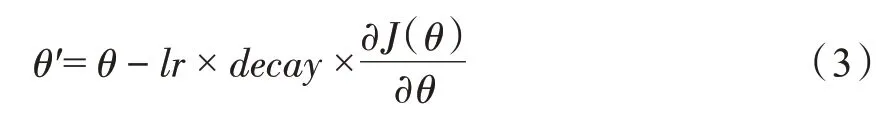
式中:J(θ)—损失函数;θ′—待更新的权值;θ—当前权值;lr—学习率(learning rate);decay—学习率衰减因子,随着迭代次数增加,动态修改学习率。
Ashia C.Wilson等[21]探讨了不同优化算法在CIFAR-10数据集训练集及测试集上的不同表现。通过对比自适应估计(Adaptive Moment Estimation,Adam)算法及随机梯度下降(Stochastic Gradient Descent,SGD)算法在不同学习率下的训练及测试过程可以发现,随着迭代次数增加,模型会逐步接近较优值,此时较大的学习率不利于模型收敛。因此,在模型训练过程中,在学习率中加入一个衰减因子,能够使学习率随着迭代次数的增加而逐步减小。
学习率对模型表现有显著影响[22]。不同算法对学习率的适应能力不同,但都表现出相同的规律。当学习率较大时,模型训练速度快,损失值较快达到最低值且准确率较快上升至最高值,但模型在测试集上表现出较强的波动性,这是因为模型权值在较优值附近“振荡”,无法收敛,随迭代次数增加,在衰减因子的作用下学习率逐步降低并最终完成模型训练;当学习率较小时,模型损失值下降和准确率上升均较为缓慢,在有限次迭代后,模型能力较低,未被完全训练好。因此,较大和较小的学习率均存在不足,通过对学习率进行网格筛选,确定Adam算法较优学习率为2×10-5(0.000 02),SGD算法较优学习率为2×10-4(0.000 2)。
利用公式(4)~公式(7)计算准确率、召回率、f1分数、加权平均值4项指标,并以此评估模型表现。模型经过200次迭代后,在训练集上,Adam和SGD算法在较优学习率下的表现见表4。可见,SGD算法的准确率、召回率、f1分数的加权平均值均为99.92%,略高于Adam算法(99.76%),但差异并不显著。

式中:Pi—某分类的准确率,%;TPi—某分类预测正确的样品数量,张;Ki—预测为某分类的样品数量,张。


表4 模型在训练集上的表现Tab.4 Performance of model on training set
式中:Ri—某分类的召回率,%;TPi—某分类预测正确的样品数量,张;Ni—某分类的总样品数量,张。

式中:f1i—某分类的f1分数,%;Pi—某分类的准确率,%;Ri—某分类的召回率,%。

式中:avg_weight—某指标基于样品数的加权平均值;f—某指标;Ni—某分类的总样品数量,张。
2.3 模型评估
模型在测试集、原数据集测试集上的表现与卷积神经网络[9]的表现对比见表5和表6。测试集任一类型烟丝残差神经网络分类准确率最低为96.72%,高于卷积神经网络(58.02%)。其中,叶丝的准确率略低,叶丝、膨胀叶丝的召回率较低,说明叶丝和膨胀叶丝相互误认的概率较大,加权平均准确率为98.05%,高于卷积神经网络(60.20%);原数据集测试集任一类型烟丝的分类准确率最低均达到94.74%,高于卷积神经网络(80.95%),加权平均准确率为97.62%,高于卷积神经网络(84.95%)。此外,测试集模型f1分数加权平均值为98.04%,训练集为99.76%,两者差异不大,说明模型的泛化能力较强。

表5 模型在测试集上的表现Tab.5 Performance of model on test set

表6 模型在原数据集测试集上的表现Tab.6 Performance of model on test set of original data
模型在测试集上的测试结果(表5)表明,识别错误和未被识别的样本数约占2%,主要有两种情况:一是模型未能区分出膨胀叶丝和叶丝,这是由于在宏观尺度上,两者的特征差异不明显,尤其是少部分叶丝膨胀后没有显著变化,从而难以区分;二是部分样本图像来源于同一原始样本数据或图像增强,模型对其中一个原始图像如果不能正确判断,则其增强后的图像也会出现误判。因此,要提高模型识别准确率,一方面是增加训练的样本类型和数量,另一方面是提高图像的质量,在训练集中引入不同方式的增强图像。
3 结论
为实现烟丝类型的准确识别,利用各类烟丝图像特征差异,以残差神经网络为基础建立了识别模型,并对模型的识别准确率、召回率、优化算法等进行了研究,结果表明:①基于残差神经网络的烟丝类型识别方法具有较高的准确率和召回率,模型测试集准确率和召回率均高于96%,可以有效识别烟丝类型。②模型的训练集与测试集表现差异较小,模型具有较强的泛化能力。③预训练权值、优化算法及学习率等超参数对于模型具有较大影响,通过加载预训练权值可提升模型训练速度;优化算法对模型表现影响较小,但不同算法的学习率不同,学习率应处于相对适中水平,较高学习率会增加模型收敛难度,较低学习率会降低模型训练效率。④基于残差神经网络的烟丝类型识别方法相比基于卷积神经网络的识别方法具有更高的识别率、泛化能力及鲁棒性。未来将进一步研究烟丝在线收集以及在工业图像采集条件下的数据集构建和提高模型识别准确率等问题,实现烟丝类型的实时分析。
猜你喜欢
南方农业(2022年13期)2022-08-03
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
数学年刊A辑(中文版)(2020年2期)2020-07-25
烟草科技(2020年3期)2020-05-19
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
江西农业学报(2019年6期)2019-06-26
消费导刊(2018年8期)2018-05-25
自动化学报(2017年7期)2017-04-18
