
基于防御蒸馏和联邦学习的安全深度神经网络研究
2021-06-05 12:32肖林声钱慎一
湖北民族大学学报(自然科学版) 2021年2期
肖林声,钱慎一
(郑州轻工业大学 计算机与通信工程学院,郑州 450002)
深度学习已经被证明在很多的机器学习任务中表现出色,这些深度神经网络(DNN)可以从大量的样本中训练出高精度的模型,然后以极高的准确率对新的样本进行分类,因此DNN被大量的用于各种环境和任务中[1-3].而在当今的世界中,深度学习和人工智能技术发展遇到了两个主要的挑战,一个是在的大多数的行业中,数据以数据孤岛的形式存在;另一个是训练人工智能模型需要大量的数据,而将数据的不当收集将使得数据的隐私和安全难以得到保护[4].为了解决以上问题,谷歌最早提出了联邦学习的概念[5-7].他们的主要想法是基于分布在多个设备上的数据来构建机器学习模型,并同时防止用户的隐私泄露.
除此之外,最近关于机器学习和安全领域的研究也表明,攻击者可以通过让大多数的包括DNN在内的机器学习模型,使用精心设计的输入来迫使其输出攻击者所选择的输出.攻击者精心设计的样本被称为对抗样本,对抗样本的设计算法仅引入了尽可能少量的扰动,使得对抗样本和正常样本难以区分.图1展示了普通样本和对抗样本的区别.
图1中,图像(a)被训练完成的DNN正确分类为数字“8”,而图像(b)则是对抗样本设计算法从正确的图像中生成的并被分类为错误的数字“4”.深度学习被广泛用于车辆的自动驾驶中,基于DNN的系统用于识别道路上的标识和车辆[8],若干扰这些系统的输入,例如轻微的改变车身导致对于行驶的车辆识别失败,则会无法使得汽车停下来,最终酿成事故.即使在联邦学习的条件下,所训练的DNN模型依旧容易受到对抗攻击的威胁.因此,设计DNN系统时必须要考虑对抗样本的问题,但是目前的对策非常少,过去的工作考虑了构建针对对抗样本的防御的问题,但是它们的不足之处在于,它们需要对DNN的架构进行修改,或者仅仅对部分对抗样本有效[9-10].

(a) (b)图1 对抗样本和正常样本的差别Fig.1 The difference between adversarial samples and normal samples
为了解决目前DNN所面临的问题,本文使用了联邦学习和防御蒸馏[11]的技术来对抗攻击者进行的对抗攻击并保护用户的隐私,并使用了稀疏三元(STC)法减小用户与服务器之间的通信开销,设计了安全的深度神经网络.主要贡献包括以下方面:① 本文所使用的防御蒸馏的方法使得对抗攻击的对抗样本的制作成功率从95.9%降低到了0.45%.② 通过在真实数据集上的验证,文中的方案在保证了模型预测准确性和安全性的同时,将通信开销减少到了原来的1%~10%.
1 理论基础
主要介绍深度神经网络(DNN)、防御蒸馏、联邦学习和STC稀疏三元理论.
1.1 深度神经网络
深度神经网络是一种成熟的机器学习技术,在其中组合了许多的参数函数,使得输入的样本的表示更加简单[12].实际上来说,一个DNN由几个连续的神经元层组成,最后形成一个输出层,这些层可以看作是输入数据的连续表示[13].深度神经网络的结构如图2所示.
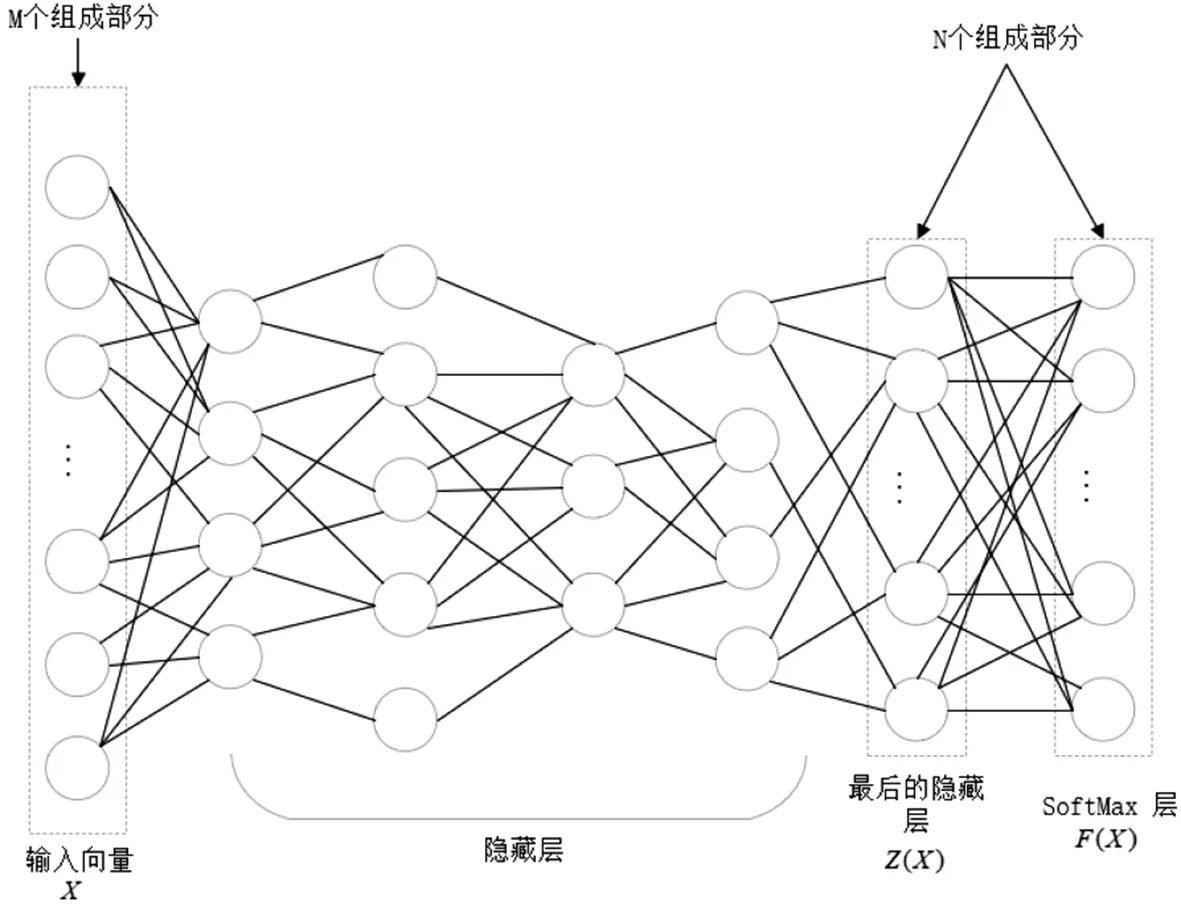
图2 深度神经网络Fig.2 Deep neural network
输入层的多维输入向量X,其中的每一个神经元都对应上文所提到的参数函数,构成层的神经元被建模为将激活函数应用于其输入的基本计算单元.并且神经网络通过一组向量加权的链接来连接各层,这些权重向量也称为网络参数θF.在训练的过程中,θF中数值的权重向量将会被评估.在这个过程中,DNN中会输入大量的训练样本(x,y)∈(X,Y),通过一系列的训练过程计算DNN输出层的预测误差,以及相应的权重参数的梯度[14],再使用计算出的梯度值更新现有的权重参数,以此来提高网络的整体精度.该训练方式被称为反向传播,由预先设定的超参数来控制,这些超参数对于模型是否收敛至关重要,最重要的超参数为学习率,它控制着使用梯度更新权重的速度.
一旦网络被训练,整个网络的体系结构,连同它的参数θF将被认为是一个分类函数F,在测试的过程中,训练完成的网络将被用于测试数据X并且得到预测输出F(X),训练过程中所得到的权重包含了使得DNN可以正确预测和分类新数据的知识.在之前额工作中已经证明了DNN部署在对抗环境中时,必须考虑DNN的一些漏洞,即对抗样本是针对DNN的人工产物,在DNN完成训练之后,攻击者可以利用生成的对抗样本进行攻击.通过将精心设计的扰动δX加入到正常样本X中,从而激发DNN的特定行为,将样本分配到攻击者所选择的类中.注意,攻击者所设计并添加的样本扰动δX必须足够小,允许样本被正常的处理而不被发现,以此来达到对抗攻击的目的,对抗样本的生成过程如图3所示.
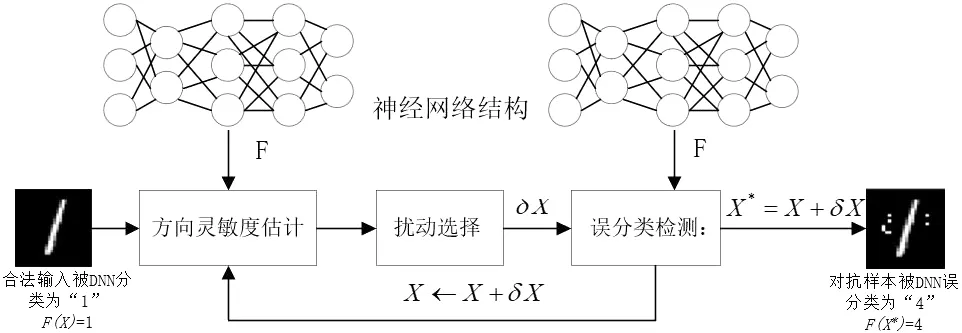
图3 对抗样本生成过程Fig.3 Adversarial sample generation process
1.2 联邦学习
联邦学习的结构如图4所示.
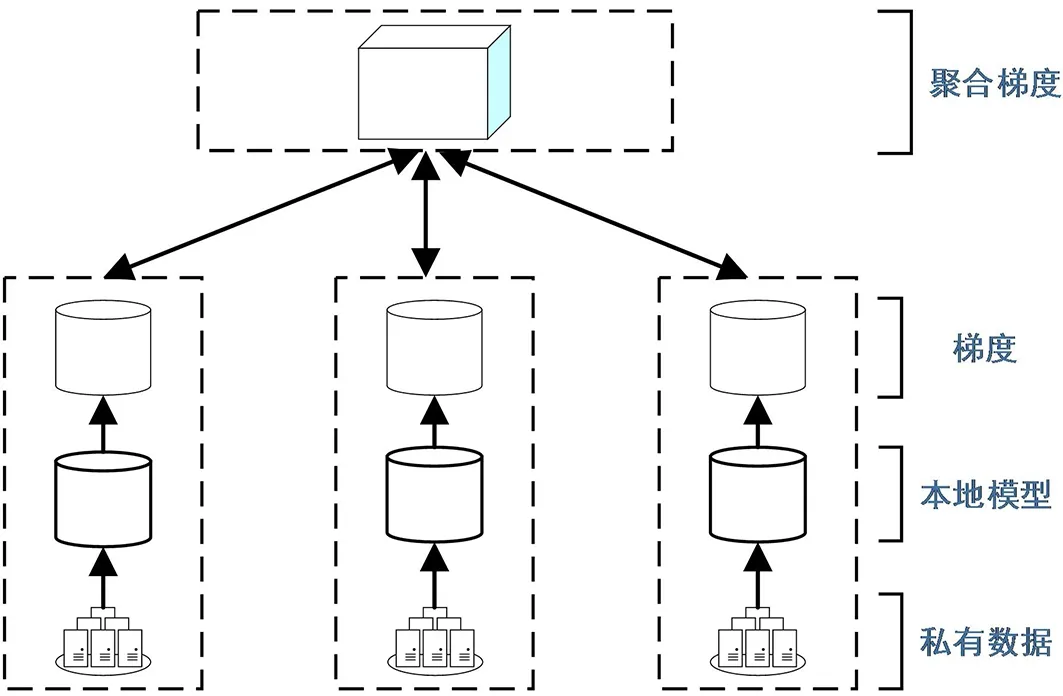
图4 联邦学习系统结构Fig.4 Federal learning system structure
模型训练过程如下.
1) 基于私有数据集,用户Ci在本地训练θ,得到梯度向量gi:
gi=Train(θ,Di) .
(1)
2) 服务器S接收从用户上传的梯度向量gi.
3) 在服务器S中,所有将获得的梯度向量聚合:
(2)
4) 计算完成后,得到聚合梯度向量gS,并将其返回给所有m,用户使用聚合梯度来更新本地模型:
(3)
其中,α是学习率.
在一轮训练完成后,用户需要检测本地模型的准确率是否达到了要求,如果满足了要求则停止训练并输出训练好的模型,如果没有达到要求则继续迭代,进行下一轮的训练,直到达到要求为止.
1.3 STC算法
联邦学习中,用户在每次训练完成后,均需要将训练得到的梯度全部传输给服务器,在需要的梯度参数较多的系统中,将会占用大量的通信资源,这将会成为系统性能的瓶颈.在本文中,参考了Aij等[15]提出的Top-K梯度选择方案和Felix Sattler等[16]提出的Top-K梯度选择方案的扩展——STC稀疏三元算法,如图5所示.之所以选择STC稀疏三元算法,是因为相比于Top-K梯度选择算法,STC根据稀疏度选择梯度后,将选择出的梯度进行量化处理,当稀疏化和非零元素的量化结合将获得更好的减小通信开销的效果.
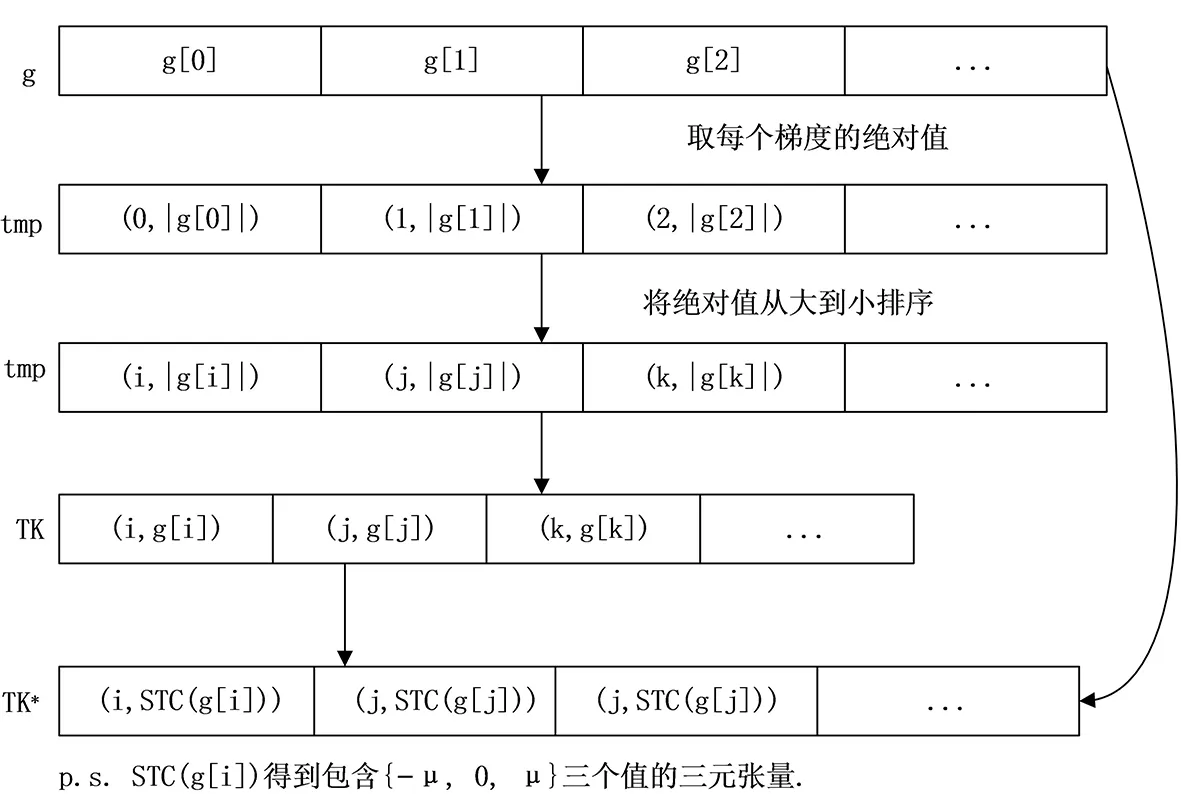
图5 稀疏三元压缩算法(STC)Fig.5 Sparse ternary compression
具体来说,每次用户C计算得到梯度g后,首先将梯度向量中的每个元素g[j]的绝对值并将取完绝对值的g[j]进行排序,将排序完成的梯度绝对值的最大的K个梯度提取出.然后将这选择出的K个梯度值量化为三元张量后,上传到服务器S.
图5中TK代表用Top-K方案取出的绝对值最大的K个梯度值.而tmp中存储的是梯度的索引和梯度的绝对值,将梯度的索引和梯度的绝对值排序后选择出绝对值最大的K个梯度值,在稀疏化的同时对稀疏化后的目标向量进行量化,在STC算法的作用下,TK∈Rn最终会生成三元张量TK*∈{-μ,0,μ}n.
在文献[15]中,先使用Top-K算法取出相应的梯度绝对值最大的K个梯度,然后再将其梯度值量化成为包含{-μ,0,μ},作者用实验证明了,三元化对收敛速度没有影响,甚至会提高训练模型的精度,表明了对数据稀疏化和量化的结合相比于单纯使用Top-K算法来对数据进行稀疏化操作更好地利用了通信资源,而且效率更高,并且作者还不只将STC用在从用户将梯度上传到服务器的情况,同时也将STC用到了用户从服务器下载的情况上,进一步减小了通信开销.
1.4 防御蒸馏
蒸馏是一个训练的程序,最初设计出来是为了使用从不同的DNN中迁移来的知识来训练目标DNN.Ba等[17]最早提出了这个概念,而Hinton等[18]则将蒸馏正式引入.通过蒸馏技术将知识进行转移是为了将知识从大的架构转移到较小的架构中来减少DNN的计算复杂度,这项技术有助于深度学习在计算资源有限的设备,例如智能手机中进行部署,这些设备无法使用强大的GPU进行计算.Nicolas Papernot等[11]则提供了一种新的蒸馏变体,从DNN中提取知识来提高其自身对于对抗样本的鲁棒性,而不是在不同的架构中进行知识迁移.
Hinton等[18]提出了神经网络蒸馏模型,由于蒸馏最早出现的目的是降低DNN的规模,使其可以在运算能力较差的设备上部署,因此需要有一个DNN在原始数据集中训练,将训练得到的蒸馏标签输入到第二个DNN的数据集中,第一个DNN为了实现蒸馏,首先使用原始数据在一个输出层为softmax层的神经网络上进行训练,softmax层仅仅接收最后一层隐藏层的输出Z(x),并将其归一化为概率向量F(x),也就是DNN的输出,为数据集中的每一个标签类分配一个概率.在softmax层中,概率向量F(x)的计算为:
(4)
其中的N为类的数量,并且T为蒸馏温度并且该参数在softmax层中共享.由式(4)可知,softmax温度越高,生成的概率越相近,即T→∞时概率趋近于1/N,而温度越小则生成的概率越离散,即输出的概率向量中有一个概率会趋近于1而其他的则趋近于0.
防御蒸馏与Hinton等[18]提出的原始的蒸馏方法不同之处在于防御蒸馏保持相同的网络架构来训练原始网络和蒸馏网络.防御蒸馏的框架如图6所示.
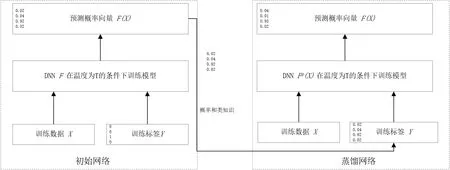
图6 防御蒸馏结构图Fig.6 Defense distillation structure diagram
防御蒸馏的训练过程概述如下.
1) 防御蒸馏算法的输入是一个带有样本标签的样本集合X.特别的,令x∈X作为样本,将Y(x)来表示样本的离散标签,也称为硬标签.Y(x)是一个指示向量,其中唯一的非零元素代表了样本所对应的正确的类的索引,例如(0,1,0,0,…,0).
2) 使用给定的训练集{X,Y(X)},然后在温度T的条件下训练以softmax层为输出层的深度神经网络F,输出的F(x)为标签的概率向量.更确切地说,如果深度神经网络拥有参数θF,然后在输入为X的条件下输出的概率分布为F(X)=p(.|X,θF),对于标签集中的所有的标签Y,所分配的概率为p(Y|X,θF).为了简化符号表示,文中使用Fi(X)来表示在输入为X并且有参数θF的条件下类i的概率.
3) 重新形成一个新的样本集{X,F(X)}来代替{X,Y(X)},即使用代表了网络F的在每个类上的概率的软标签F(X)来代替样本X的硬标签Y(X).
4) 使用新的样本集{X,F(X)},训练另一个DNN模型Fd,该模型和第一个DNN模型F结构相同,并且温度T也相同.这个新的DNN模型Fd被称为蒸馏模型.
使用软标签的好处在于,与硬标签相比,在概率向量中包含了类之间的相对差别和关联等额外的知识,使用类的相关信息来训练模型,也可以有效地防止过拟合,有效增强了模型的泛化能力.
2 方案设计
基于联邦学习和防御蒸馏,针对DNN中所面临的挑战,提出了安全且通信开销较小的训练协议πDNFL,可以有效的抵御测试过程中攻击者通过对抗样本对训练完成的模型发动的对抗攻击.
在协议中,文中的目标是在对抗攻击中保护DNN模型的预测准确度以及在模型训练的过程中保护用户的隐私数据的安全.但是由于训练DNN需要大量的数据,传统的训练方式是将用户的数据汇总到一起来进行模型的训练,这使得一些攻击者会通过访问服务器,使得用户数据泄露,因此,本文在协议中使用联邦学习,使得训练DNN时可以在一定程度上保护用户的隐私.协议的流程如图7所示.
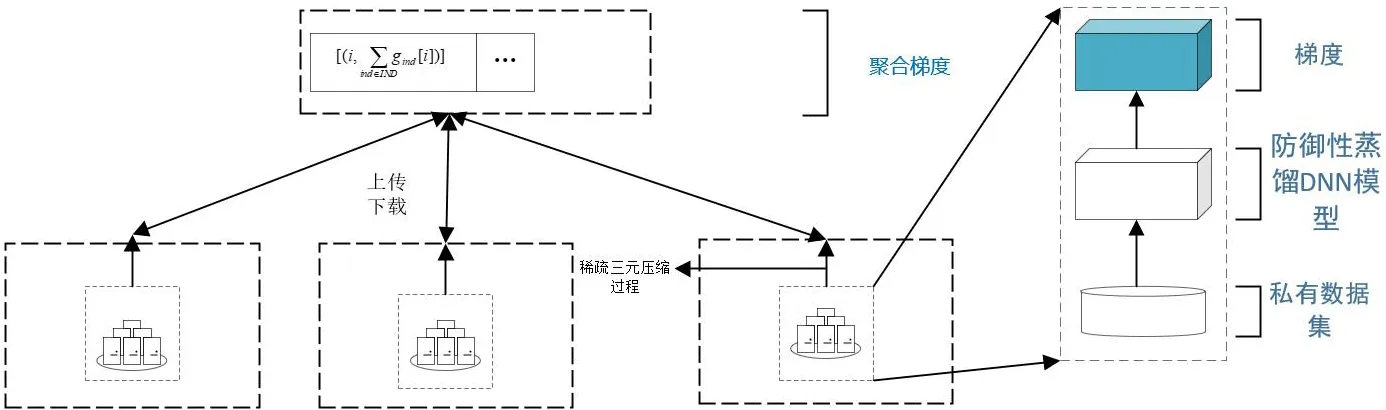
图7 协议πDNFLFig.7 The illustration of protocol πDNFL
算法1 协议πDNFL.
输入:用户的私人数据Di、以及需要训练的防御蒸馏模型θ.
输出:训练完成的模型θ.
步骤1 服务器和用户之间建立安全的传输信道;
步骤2 用户在各自本地生成随机数;
步骤3 用户使用本地数据训练防御蒸馏模型,计算梯度;
步骤4 用户使用STC稀疏三元法,选择出梯度元素并将其量化,并计算残差Ri;
步骤5 将量化完成的梯度以及对应的索引信息传送到服务器中,并在服务器按照索引信息将量化梯度聚合,并在服务器中计算残差R;
步骤6 服务器将聚合完成的梯度和对应的索引信息传送回参与用户;
步骤7 用户更新本地模型;
步骤8 检查所训练模型的性能,若所训练的模型准确率达到要求则停止训练,否则跳转到步骤3开始下一轮训练.
在完成训练后,研究防御蒸馏对于模型灵敏度的影响.对于DNN来说,模型灵敏度越高,则越容易被对抗攻击威胁.而在温度T越高的情况下,对抗样本就越难生成,这也是为何高温使得蒸馏模型Fd更稳定的原因,这是由于蒸馏降低了模型对于输入微小变化的敏感度.使用雅可比矩阵来量化模型对于输入的敏感度,于是计算得到温度为T时的模型F的雅可比行列式(i,j)的表达式为:
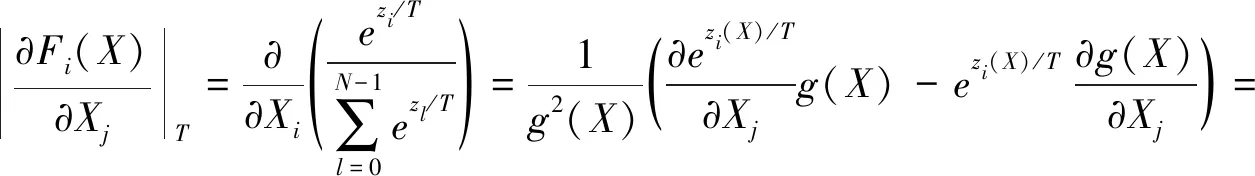
(5)
这里将zi(X)写为zi,由式(5)可知,提升softmax层的温度可以系统的降低在防御蒸馏训练时模型对于输入的微小变化的灵敏度.在测试时,将温度T降低为1,因为这样操作不会影响在训练时得到的模型参数,因此通过高温而得到的低灵敏度在测试时就可以观察到,而在测试时改变温度只会使得类的概率向量更加离散而不会改变相对顺序,防御蒸馏模型可以降低对抗样本的生成梯度,从而降低了模型对于输入变化的敏感性,并且增强了模型的鲁棒性[11].
3 实验与结果
在手写体数字识别MNIST上的基于卷积神经网络(CNN)的深度神经网络上进行试验,其中深度神经网络的结构如表1所示.其中的参数选择:Learning Rate:0.1;Momentum:0.5;Dropout Rate(Fully Connected Layers):0.5;Batch Size:128;Epochs:50.其中MNIST数据集由Training Set Images、Training Set Labels、Test Set Images和Test Set Labels这四部分组成,其中将Training Set Images和Training Set Labels的数量设定为60 000,而Test Set Images和Test Set Labels为10 000.
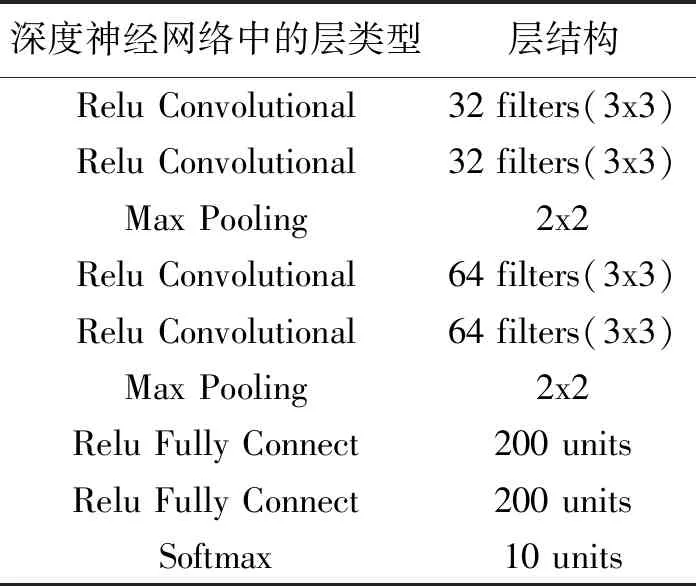
表1 深度神经网络的结构Tab.1 The structure of a deep neural network
实验环境部署在 Inter Xeon E5-2620和8根16G DDR4内存条共128 G内存的服务器上,并在服务器的局域网内模拟了2个参数服务器和10个客户端,基于Python3实现本文所提出的基于防御蒸馏和联邦学习.在实验中,每一次迭代都会使得参与者和服务器交互计算1次,完成梯度的聚合运算.
分别从准确率、训练的通信开销和对抗样本的攻击成功率三方面来分析文中所提出的方案.
3.1 模型的准确率
衡量模型性能一个很重要的标准就是模型的准确率,通过测量准确率的变化,表明本文方案对于模型性能的影响是可以接受的,这一部分首先测量了原始DNN和仅使用联邦学习和稀疏三元方法的DNN两种情况.图8分别给出了两种情况下在训练过程中的准确率的变化情况,其中本文所使用的STC中的梯度选择的参数为1%、5%和10%.
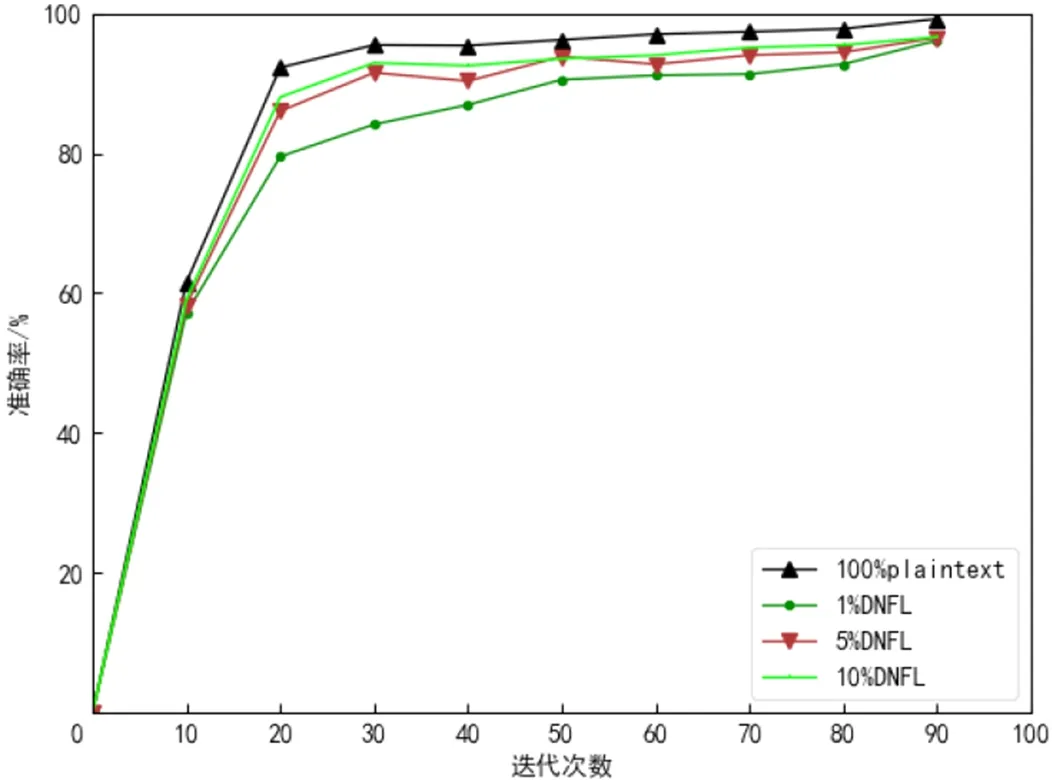
图8 准确率变化Fig.8 The accuracy change
可以看到,在使用联邦学习和不同的梯度选择参数的条件下,模型训练的收敛速度基本一致,并且模型的准确率虽略有降低但是在可以接受的范围内.接下来在模型中使用防御蒸馏,其中防御蒸馏中softmax层的温度T取{1,2,5,10,20,30,50,100}.如图9所示,经过训练可以发现,温度对于模型性能的影响是有限的.

图9 温度对于模型性能的影响Fig.9 The effect of temperature on model performance
3.2 通信开销
在本文所提出的协议中,需要将参与用户的训练梯度传输到服务器中,因此,通信开销大是研究者必须面临的问题,因此为了通信性能的提升,本文使用了STC稀疏三元法与联邦学习算法结合提出了高效的解决方案.
在实验中,将STC选择的比率选择为1%、5%和10%,并分别在不使用STC的plaintext以及协议πDNFL条件下,在一次迭代过程中的通信开销.结果如表2所示.
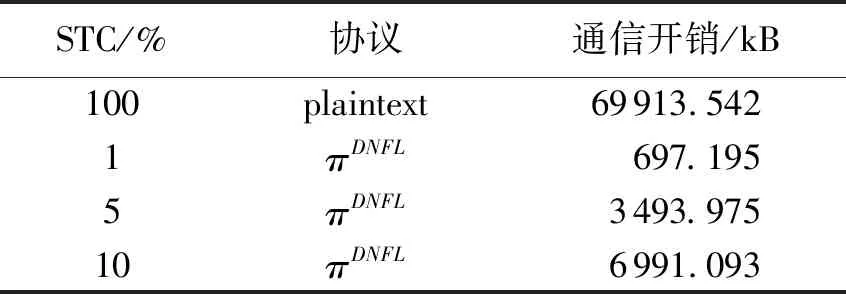
表2 一次迭代训练中的通信开销Tab.2 Communication overhead in an iterative training
实验结果表明,相比于不使用梯度选择算法的plaintext,该协议使用的STC稀疏三元法可以极大地优化通信开销,由3.1节可得,稀疏度在该范围内选择不会对模型的性能造成太大的影响,因此可以看到,将STC的稀疏度从10%降为1%,通信开销减少了大约9.02倍,很好地优化了通信性能.
3.3 对抗攻击的成功率
在本节中,需要在测试集中生成对抗样本,因此通过将输入特征的4.02%进行失真[19]的方法在测试集中生成9 000个对抗样本,该方法在没有使用蒸馏的情况下成功率可以达到95.89%.然后将测试集中的样本输入协议πDNFL中进行预测,同时不断的改变温度T的值,分别观察在不同的温度下,对抗样本攻击的成功率的大小.实验中将温度T的值取为{1,2,5,10,20,30,40,50,100},图10展示了与温度有关的对抗样本成功率.
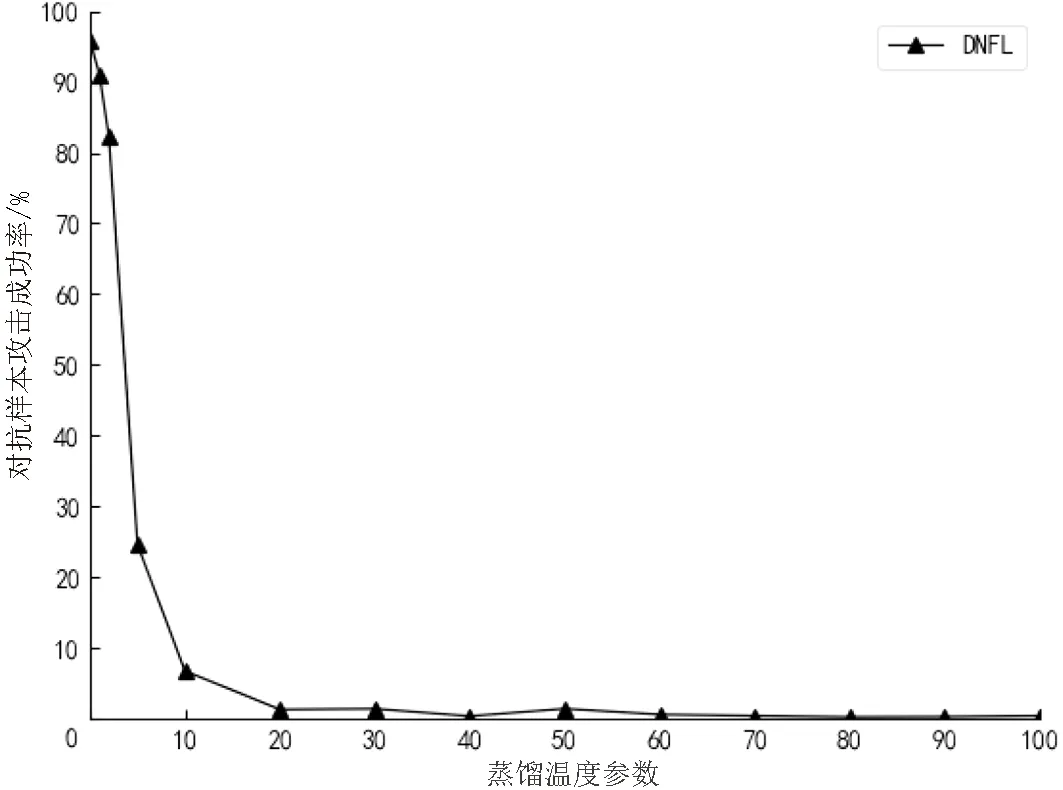
图10 温度对于对抗样本成功率的影响Fig.10 The effect of temperature on the success rate of adversarial samples
由图10中的数据可以看到,随着温度的上升,对抗攻击的成功率从95.89%下降到了0.45%,因此提高温度可以有效地抵御对抗样本的攻击.
4 结语
DNN是一中优秀的深度学习模型,但是其却容易受到对抗攻击和隐私泄露的威胁,而这个问题则在当今的生活中显得尤为重要.本文将防御蒸馏、联邦学习和稀疏三元法相结合,在保证DNN可以抵御对抗攻击和隐私泄露问题的同时,也使得通信效率有了很大的提升.由于除了DNN之外,其他的很多机器学习模型依旧受到对抗攻击的威胁,但是防御蒸馏却只能使用在DNN模型中,接下来笔者将探索更好的对抗攻击的应对方法,并使这些拥有更好的泛化能力.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
网络安全和信息化(2020年9期)2020-12-31
网络安全和信息化(2020年7期)2020-08-07
网络安全和信息化(2019年8期)2019-08-28
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
电子制作(2018年1期)2018-04-04
北京航空航天大学学报(2017年12期)2017-04-23
网络空间安全(2016年3期)2016-06-15
