
一种基于自动特征学习的陨石坑区域检测算法
2021-06-09 01:15陆婷婷张尧阎岩杨利民杨卫东
北京航空航天大学学报 2021年5期
陆婷婷,张尧,阎岩,杨利民,杨卫东
(1.中国运载火箭技术研究院 研究发展部,北京100176;2.河南工业大学 粮食信息处理与控制教育部重点实验室,郑州450001)
随着各国新一轮深空探测活动的兴起,如何通过自主手段进行着陆器自主导航成为深空探测任务的一个重点研究问题。由于星体表面的陨石坑具有几何形态规则(边缘呈圆形)、特征显著、数量巨大等特点,已经成为深空探测飞行器进行视觉导航所首选的导航路标,大量学者对基于陨石坑视觉导航算法进行了深入研究[1-5]。
如何从导航图像中提取陨石坑区域是实现基于陨石坑视觉导航算法的首要步骤,这里的陨石坑区域是指导航图像中包含且仅包含一个陨石坑的矩形区域。根据检测原理的不同,当前的陨石坑区域检测算法可以分为2类:基于陨石坑形态特征的检测算法和基于监督学习的检测算法。
基于陨石坑形态特征的检测算法主要利用陨石坑固有的形态特性实现陨石坑区域检测。这一类陨石坑区域检测算法的典型代表包括:基于阈值分割和形态学处理的检测算法[6]、基于形态学的检测算法[7]、基于模板匹配的检测算法[8-9]、基于阈值分割和霍夫变换的检测算法[10-11]、基于图像边缘信息和纹理分析的检测算法[12]、基于张量投票的检测算法[13]、基于Canny边缘检测算子和图像光照方向的检测算法[14-18]、基于边缘信息和SIFT特征提取的检测算法[19-20]等。实际上,以上这些典型算法仅适用于图像背景简单并且图像拍摄视角不大的情况,但实际的陨石坑图像中通常包括大量的沟壑、山谷等干扰地质特征,并且拍摄视角多变,因此,以上这些检测算法无法适用于复杂的陨石坑图像。
基于监督学习的检测算法将陨石坑区域检测问题转化为一个典型的二分类问题。这一类算法的研究主要集中在如何构建一个陨石坑区域分类器,典型算法包括:基于Boost及Boost的各种变种算法的分类方法[21-25]、基于贝叶斯分类器和遗传算法的分类方法[26]、基于Fisher分类器的分类方法[27]等。与基于陨石坑形态特征的检测算法相比,基于监督学习的检测算法具有更高的精度,这是因为监督学习方法在进行最终识别之前,已经利用训练数据集学习到了强泛化能力。另外,以上算法在描述陨石坑区域特征时,均使用人工特征,无法随着图像环境的变化而自适应改变,当图像环境发生变化时,这类算法的精度可能会发生恶化。除了以上算法外,最近还有研究学者提出利用卷积神经网络(Convolutional Neural Network,CNN)进行陨石坑区域检测[28-30],但其所设计算法仅能适应导航图像仅包含圆形陨石坑的情况,无法适应于含有椭圆形陨石坑的导航图像。
为了更加精确地实现深空探测导航图像的陨石坑区域检测,本文提出一种基于自动特征学习的陨石坑区域检测算法,该算法属于监督学习方法的一种,其在充分利用图像陨石坑形态特征基础上,通过利用已有数据集自动学习陨石坑区域特征的方式实现陨石坑区域高效检测,并通过大量的仿真实验验证了所提陨石坑区域检测算法的有效性,可满足空间探测飞行器自主导航的需求。
1 陨石坑区域检测算法总体框架
基于自动特征学习的陨石坑区域检测算法总体框架如图1所示,主要包括陨石坑候选区域检测和陨石坑候选区域分类2个基本流程。

图1 陨石坑区域检测算法总体框架Fig.1 Overall framework of crater region detection algorithm
首先,根据图像陨石坑的形态特征,从输入导航图像中提取陨石坑候选区域。一般情况下,图像陨石坑由一对明显的亮暗区域构成,面向太阳光照一侧是亮区域、背向太阳光照的一侧是暗区域,如图2所示。那么,图像陨石坑中的每一对满足某种位置关系的亮暗区域便可能对应一个陨石坑区域,将利用该思想检测陨石坑候选区域。与传统的基于滑窗的检测算法相比,本文候选区域检测算法误检率低,可以有效减小陨石坑候选区域分类算法的计算负担、提高计算效率,同时,不需要指定候选区域的具体尺寸,自适应程度高。

图2 图像陨石坑的光照特征Fig.2 Optical characteristics of imaged crater
然后,对陨石坑候选区域进行分类,得到真实的陨石坑区域。该过程利用特征自动学习的方式提取所有陨石坑候选区域特征,并利用支持向量机(SVM)将这些候选区域分为2类:陨石坑区域和非陨石坑区域,从而实现陨石坑区域检测。
下面分别对陨石坑候选区域提取和陨石坑候选区域分类2个核心环节的具体算法进行详细设计和研究。
2 陨石坑候选区域提取
根据上述分析可知,图像陨石坑具有明显的亮暗区域,这些亮暗区域虽然不具有明确的几何形态,但却属于非常显著和稳定的区域特征,且具有射影不变性。针对以上特点,采用最大稳定极值区域(Maximally Stable Extremal Regions,MSER)[31-32]算法实现图像陨石坑候选区域提取。
通过分析原始MSER算法的基本特点可知,原始MSER算法仅能检测到图像陨石坑的稳定区域,不能识别这些稳定区域的亮暗关系,并且检测到稳定区域之间还具有明显的嵌套包含关系,位于每组嵌套结构中部位置的稳定区域通常是对陨石坑检测意义不大的区域。因此,需要对原始MSER算法进行改进,得到适合于陨石坑亮暗区域检测与匹配的稳定区域检测算法,称这种改进后的MSER算法为Crater MSER。
基于Crater MSER算法的陨石坑候选区域检测算法基本流程图3所示。首先,从输入的导航图像中检测最大稳定极值区域;其次,从最大稳定极值区域中提取出极大稳定区域和极小稳定区域,这些区域能够有效代表陨石坑的亮暗特征;然后,分别对极大稳定区域和极小稳定区域进行面积滤波和形状滤波,排除形状特征异常的稳定区域;最后,通过对滤波后的极大稳定区域和极小稳定区域的亮暗特征进行识别和匹配,实现陨石候选区域检测。

图3 Crater MSER算法的基本流程Fig.3 Basic flowchart of Crater MSER algorithm
2.1 最大稳定极值区域的提取
为了获取能够表征陨石坑亮暗特征和形状特征的稳定区域,先利用原始的MSER算法[31-32]从输入导航图像中提取最大稳定极值区域,其是输入图像中灰度变化最稳定的区域,通常对应着图像陨石坑的亮暗区域,这是由图像陨石坑的灰度特性决定的。
根据MSER算法的基本思想[31-32]可知,基于原始MSER算法提取得到的最大稳定极值区域之间存在着嵌套关系。图4给出了一组最大稳定极值区域提取的实例。对于给定的输入图像,基于原始MSER算法得到6个最大稳定极值区域M1~M6,其中,M3~M6是亮区域,而M1和M2是暗区域,并且这些最大稳定极值区域具有如下的嵌套关系:

式中:Mi∈Mj表示区域Mj完全包含Mi(i=1,2,3,4,5,6;j=1,2,3,4,5,6)。图4中还绘制出了每个稳定区域所对应的同矩椭圆,同一稳定区域及其对应的同矩椭圆以相同的颜色显示。

图4 Crater MSER算法基本流程的真实实例Fig.4 Instances of basic procedure of Crater MSER algorithm
2.2 极大稳定区域和极小稳定区域提取
从所有的最大稳定极值区域中提取出极大稳定区域和极小稳定区域,其中,极大稳定区域是指不被任何其他稳定区域所包含的稳定区域,而极小稳定区域是指不包含任何其他稳定区域的稳定区域。极大稳定区域和极小稳定区域之间存在着一一对应的关系,任何一个极小稳定区域都被其所对应的极大稳定区域所包含,并且这组相对应的极大和极小稳定区域具有相同的亮暗信息。极大稳定区域表征图像陨石坑的形状,其亮暗信息由所对应的极小稳定区域决定,一对亮暗极大稳定区域对应着一个陨石坑候选区域。
给定一组最大稳定极值区域M={Mi}(1≤i≤NM,NM为M中的稳定区域个数),可以利用式(2)所示的判别准则提取极大稳定区域和极小稳定区域:

式中:Imi(Mi)=1表示Mi为极小稳定区域,Imi(Mi)=-1表示Mi为极大稳定区域,而Imi(Mi)=0表示Mi既非极小稳定区域也非极大稳定区域。仍以图4所示图像为例,根据式(1)所示准则可以从输入导航图像的最大稳定极值区域M1~M6中提取出所有的极大稳定区域和极小稳定区域,其中,M1和M3是极小稳定区域,而M2和M6是极大稳定区域,并且极大稳定区域M2和M6分别包含极小稳定区域M1和M3。
2.3 面积滤波及形状滤波
2.2节所提取的极大稳定区域和极小稳定区域具有不同的形状和尺寸,一些比较小的稳定区域属于噪声区域,而一些具有极端形状(如极度扁长)的区域也属于非陨石坑区域,因此,应该对所有的极大和极小稳定区域进行形状滤波和面积滤波,选择TA作为面积滤波的阈值、TS为形状滤波阈值,面积滤波器滤除面积小于TA的所有稳定区域,形状滤波滤除所有满足式(3)的稳定区域:

式中:Ma和Mi分别为与该稳定区域具有相同标准化二阶中心矩的椭圆的长短轴,数值可以按照式(4)计算:
其中:σ11、σ12、σ22为该稳定区域的标准化二阶中心矩的3个组成元素,由式(5)计算得到:

式中:(xi,yi)为当前稳定区域的第i个像素点;N为该稳定区域包含像素点的个数;[μxμy]T为该稳定区域中心点坐标,由式(6)计算得到:

2.4 亮暗区域识别
进行面积滤波和形状滤波之后,识别所有极小稳定区域的亮暗信息,虽然基于阈值分割的技术常被用于解决该问题,但所设定的阈值依赖于图像的质量和光照强度,鲁棒性较差,将基于K均值聚类算法识别极小稳定区域的亮暗信息,以所有极小稳定区域的平均灰度值作为聚类的性能指标,将所有极小稳定区域聚为2类(即K取2),并且具有较大平均灰度值那一类所对应的极小稳定区域为亮区域,而具有较小灰度值的那一类所对应的极小稳定区域为暗区域。K均值聚类是一种典型的非监督分类学习算法,该算法所需要的输入是K的取值及待分类的数据集。K均值聚类算法通过迭代进行簇分配和聚类中心移动2个步骤实现聚类,其中,簇分配的任务是依据所有样本点距离当前簇中心的距离对所有样本点进行分类,簇中心移动的任务是计算当前更新的簇的中心。对于极小稳定区域平均灰度值的K均值聚类问题,其数据集具有图5所示的形式,可以看出,所有的极小稳定区域的灰度值可以被较为清晰地分为2类。

图5 极小稳定区域平均灰度值的一维K均值聚类示意图Fig.5 Schematic diagram of one-dimensional K-means cluster of average gray values of minimal MSER regions
2.5 亮暗区域匹配
得到导航图像中所有极小稳定区域的亮暗信息后,便能够识别出这些极小稳定区域所对应的极大稳定区域的亮暗信息,通过匹配已知亮暗信息的极大稳定区域便可以实现陨石坑候选区域检测,下面分析具体的匹配原理。
给定一对极大稳定区域B和S,B为亮区域,S为暗区域,计算相互之间的投票分,以区域B对区域S的投票分为例。首先,计算区域B对区域S中某一个像素P的投票分:
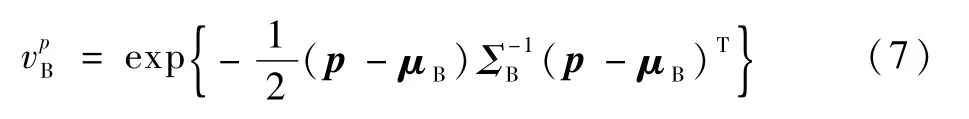
式中:p=[pxpy]T为像素P的位置坐标;μB=[μxμy]T可 以 利 用 式(6)计 算 得 到;ΣB=(σmn)2×2(m,n=1,2)为由式(5)计算得到的区域B的标准化二阶中心矩。那么,区域B对区域S的投票分可由式(8)计算得到:

式中:NS为区域S中所有像素的个数;Pk为区域S中的第k个像素;为区域B对像素Pk的投票分,可由式(7)计算得到。从而,如果区域B和区域S满足以下3条准则,将会被合并。
准则1区域B和区域S之间的距离小于一个与区域B和区域S面积成比例的阈值,该阈值可以设置为2(AB+AS)/π,AB和AS分别为区域B和区域S的面积。
准则2太阳光光照方向lsun与区域S重心指向区域B重心的方向向量lSB之间的夹角为钝角。
准则3区域B对区域S的投票分应该为区域B对所有满足准则1和准则2的暗区域的投票分中的最大值,同样地,区域S对区域B的投票分应该为区域S对所有满足准则1和准则2的亮区域的投票分中的最大值。
基于以上匹配流程,可以获得一系列匹配成功的极大稳定区域对,没有匹配成功的稳定区域为非陨石坑区域,每对匹配成功的极大稳定区域所对应的外接矩形框构成一个陨石坑候选区域。从图4给出的实例可以看到,M2和M6为一对匹配成功的极大稳定区域,包含M2和M6的图像矩形区域即为要提取的陨石坑候选区域。
3 基于自动特征学习的陨石坑候选区域分类
3.1 陨石坑候选区域分类分析
利用陨石坑候选区域提取算法能够从导航图像中检测出一系列陨石坑候选区域,其中有一部分候选区域是真正的陨石坑区域,而另外一部分候选区域是由于星体表面的沟壑、山丘等干扰地质特征造成的误检测陨石坑区域(非陨石坑区域)。因此,为了得到真正的陨石坑区域,需要将陨石坑候选区域分为2类:陨石坑区域和非陨石坑区域。
为了使用分类器对输入图像进行分类,必须从输入图像中提取出能够代表该图像的特征(纹理和边缘等),从而简化分类器的输入,使其在数学上容易处理,同时提高分类精度。实际上,图像的特征可以通过对它的每一个像素点及其邻域内的像素点与一个矩阵(称为卷积核)进行卷积运算得到。当卷积核大小不同或者卷积核元素取值不同时,可以得到不同的图像特征,通常情况下,这里的卷积运算是指以卷积核中的元素为权重、对其所覆盖的图像区域进行加权求和,以该加权和作为该卷积核所覆盖区域中心像素点的特征取值。假设卷积核KE的尺寸为w×h,原始图像为P,那么,输出的新图像P'在像素点(i,j)处的灰度值为

当卷积核KE取值不同时,输出的特征图像之间差别很大。这些手动设置的卷积核为相关图像识别领域专家根据经验选取,所提取出的特征称为人工特征,由于手动设置卷积核一经选取就不再改变,人工特征无法随着输入图像类型不同而自适应改变,对于情况多变的自然场景图像适应性较差。
CNN是一个经典的深度学习模型,其在图像分类[33]、姿 态 估 计[34]、文 本 检 测 识 别[35]等 诸 多领域取得了令人瞩目的成绩。CNN的一个重要特性是能够利用给定的训练数据集对物体特征进行自动学习,从而得到对物体特征最有效的表示。对于一般的分类问题而言[36-37],基于CNN自动学习得到的特征通常能够获得比传统的人工特征(Haar-like特 征[38]、HOG特 征[39]、LBP特 征[40]等)更高的分类精度,并且CNN特征非常适合多变的自然场景图像,能够根据具体的应用场景自适应调整。
为此,将利用CNN实现陨石坑候选区域的特征提取。另外,由于线性SVM是一个经典的分类器模型,并且大量的实际应用问题(步态检测[41]、人脸检测[42]、油罐检测[43]等)已经证明,相比于Logistic回归和Softmax回归,SVM具有更高的分类精度,将结合SVM分类器和CNN对陨石坑候选区域进行分类,最终实现陨石坑区域检测。
3.2 陨石坑候选区域自动特征学习
所设计的用于陨石坑候选区域特征提取的CNN(简称为CraterCNN)结构如图6所示,其包括5个卷积层(C1、C2、C3、C4、C5)和1个尺寸为1 000的全连接层FC6,输出层是一个Softmax分类器,且输出维度为2,输入层是大小为227×227的RGB图像。

图6 CraterCNN网络结构及基于SVM的陨石坑候选区域分类Fig.6 Structure of CraterCNN network and crater candidate region classification based on SVM
在对CraterCNN进行训练时,采用迁移学习的思路实现,即先利用预训练的AlexNet模型[44]对CraterCNN的卷积层C1~C5的权值参数进行初始化设置,并通过随机初始化方式设置CraterCNN的FC6的参数取值,再利用陨石坑数据集对CraterCNN网络进行训练微调。这种做法可以有效地利用AlexNet在ImageNet数据集上学习到的知识对陨石坑候选区域进行分类,防止了由于训练集过小而可能造成过拟合的问题,同时也充分利用了陨石坑数据集自身的特征。
实际上,CraterCNN的第1个全连接层FC6输出的就是网络从输入图像中提取出的1 000维特征。
3.3 陨石坑候选区域分类
利用CraterCNN对陨石坑候选区域进行特征提取,得到1 000维特征向量后,便可以将这1 000维特征送入线性SVM分类器,从而实现对输入陨石坑候选区域的分类。线性SVM的基本思想是:基于训练数据集在样本空间中找到一个能将不同类别样本分割开来的超平面,并且这个划分超平面具有最大的间隔。假设给定的陨石坑候选区域训练数据集为D={(xtrain_1,ytrain_1),…,(xtrain_N,ytrain_N)},ytrain_i∈{0,1}(i=1,2,…,N),xtrain_i为第i个候选区域的d维特征向量,ytrain_i为xtrain_i的类别标签,0表示非陨石坑区域,而1表示陨石坑区域。那么,划分超平面可表示为gTx+b=1,其中,d维向量g为该划分超平面的法向量,b为该划分超平面的位移,b表示了划分超平面与原点的距离,并且定义训练数据集中距离超平面最近的2个非同类样本之间的距离为间隔。那么,具有最大间隔的划分超平面应该是如下优化问题的最优解:

实际上,以上的划分超平面要求训练数据集中所有样本都能够被正确分类,但这样容易导致SVM分类器出现过拟合的情况,因此,一种鲁棒性较强的SVM分类器应该一定程度上允许其在训练数据集上出现一些错分,从而可以通过引入非负松弛变量ξi的方式来实现这个目的。此时,允许在训练数据集上出现一定程度错分的SVM通常被称为软间隔SVM,其是如下优化问题的解:
式中:常数pe衡量了容许SVM分类器在训练数据集上出现错分的程度,pe取值越大,表示要求SVM在训练数据集上出现错分的程度越低,而非负松弛变量ξi表示了样本xtrain_i不满足正确分类约束的程度。采用式(11)所示的软间隔SVM实现对陨石坑候选区域的最终分类。
4 仿真实验
通过仿真实验手段对所提出的基于自动特征学习的陨石坑区域检测算法的有效性和精度进行验证,整个实验过程在具有Windows10操作系统的台式计算机上完成。首先,利用火星表面和月球表面真实陨石坑图像对所提出的陨石坑候选区域提取算法进行验证;其次,利用通用陨石坑数据库对所提出的基于自动特征学习的陨石坑候选区域分类算法进行验证;最后,分别利用仿真陨石坑图像和真实陨石坑图像对所提出的陨石坑区域检测算法进行验证。
4.1 陨石坑候选区域提取仿真实验
分别利用火星表面和月球表面真实图像测试所提出的陨石坑候选区域提取算法的性能,具体的实验结果如图7所示。
图7中,前3行为火星表面图像的陨石坑候选区域提取实验结果,后2行为月球表面图像的陨石坑候选区域提取实验结果,第1列为输入图像,第2列为识别出的极大稳定区域(红色区域为暗极大稳定区域,绿色区域为亮极大稳定区域),第3列为陨石坑候选区域提取结果,其中,红色矩形框为检测到的陨石坑候选区域。可知,所提出的陨石坑候选区域提取算法可以较为精确地提取出输入图像中的陨石坑区域,但由于沟壑、山丘等地质特征的影响,也存在误检测的情况。例如,图7中的前3行所对应的输入陨石坑图像中都存在沟壑,因此,相应的候选区域检测结果中都出现了一个误检测区域,这个误检测区域需要利用后续的陨石坑候选区域分类算法进行筛选。

图7 陨石坑候选区域提取实验结果Fig.7 Experimental results of crater candidate region extraction
4.2 陨石坑候选区域分类仿真实验
4.2.1 数据集选择和性能指标设计
由美国麻省大学波士顿分校KDLab实验室构造的陨石坑数据集h0905_0000[45]是当前陨石坑区域检测研究最通用的训练与测试数据集,许多检测算法都在该数据集上进行了测试,因此,本节实验将使用该数据集测试所提出的基于自动特征学习的陨石坑区域分类算法。
h0905_0000数据集是根据火星快车号携带的高分辨率立体相机拍摄到的火星Xanthe Terra区域全景图h0905_0000制作而成。h0905_0000数据集包括3组数据,如表1所示。这3组数据分别由全景图h0905_0000的西部区域、中部区域、东部区域构建而成,每组数据都由正样本和负样本2类构成,正样本为陨石坑区域(标签为1),负样本为非陨石坑区域(标签为0),整个数据集共包括2 022个正样本和2 888个负样本。

表1 h0905_0000陨石坑数据集分组Table 1 Groups of h0905_0000 crater dataset
由于全景图h0905_0000所对应的火星表面区域的固有地质特征,中部区域地形较西部区域和东部区域复杂,中部区域所对应的数据集的识别难度最大。另外,数据集中的样本尺寸范围从5×5变化到100×100,但均为单通道的灰度图像,在利用CraterCNN对这些数据集进行分类识别时,需要将其统一转换成尺寸为227×227×3的RGB图像。图8给出了该数据集中的一些正负样本示例。

图8 h0905_0000陨石坑数据集中的正负样本示例Fig.8 Positive and negative examples in h0905_0000 crater dataset
为了比较不同算法的精度,利用查准率P、查全率R和F1来评估算法的泛化能力,它们是分类问题中最常用的性能度量,其具体定义和计算方法与文献[1,46]一致。
4.2.2 基于交叉校验数据集的SVM分类器惩罚因子选择
根据3.3节所述,在对CraterCNN提取到的特征进行分类时,使用了具有惩罚因子pe的软间隔SVM分类器,pe表征了SVM分类器对训练数据集出错的容忍程度,对最终的分类器性能影响很大,本组实验将利用交叉校验数据集对SVM分类器的惩罚因子pe进行选择。
首先,在整个h0905_0000数据集的东部区域、中部区域和西部区域分别抽取20%的样本,其中正负样本比例相等(均为10%),将这些来自3个区域的样本构成的数据集作为交叉校验数据集。其次,利用文献[21]所介绍的Haar-like特征提取算子提取这些样本的Haar-like特征,将这些人工特征作为SVM分类器的输入对相应的样本进行分类。这里之所以利用Haar-like特征进行软间隔SVM分类器的惩罚因子pe的选择,是因为已有的陨石坑检测算法[21]已经证实,Haar-like特征是目前比较适合应用于陨石坑检测问题的特征,并且这种特征提取简单、实现方便。
在对某一个惩罚因子进行测试时,将整个交叉校验数据集均等地分为5份,每一次分别选择其中的4份作为训练数据集、另外1份作为测试数据集,如此循环进行5次操作,可以得到当前的惩罚因子对应的5个F1度量值,以这5个F1度量值的均值衡量相应惩罚因子所对应的SVM分类器的分类精度,实验结果如表2所示。可以看到,当惩罚因子pe取值为0.000 1时,SVM分类器在交叉校验数据集上的F1取值最高,因此,对于陨石坑候选区域分类问题而言,SVM分类器的惩罚因子应该设置为0.000 1。

表2 基于交叉校验数据集的软间隔线性SVM分类器惩罚因子选择实验结果Table 2 Experimental results for choosing the penalty factor of linear SVM classifier with soft interval based on cross check dataset
4.2.3 陨石坑候选区域分类算法测试
本组实验利用h0905_0000陨石坑数据集测试所提出的基于自动特征学习的陨石坑区域分类算法(下文将该算法简称为CraterCNN+SVM)。由于h0905_0000陨石坑数据集的3个子集所包含的样本个数都较少(见表1),为了充分高效利用有限数据集验证算法性能,本组实验将采用与选取SVM分类器的惩罚因子实验相同的策略,对于h0905_0000陨石坑数据集的每一个子集,将其均等地分为10份(即10-Fold),如图9所示,依次以其中的9份作为训练集对分类器进行训练,并以另外1份作为测试集计算分类器的查准率P、查全率R和F1,如此循环,那么h0905_0000数据集的每一个子集都将得到10组查准率P、查全率R和F1,以这些度量指标的均值作为分类器在该组数据集上的最终度量指标,这样做的目的是为了削弱不同分组情况引起的训练数据集和测试数据集难度不同而对分类结果造成的影响。

图9 10-Fold训练测试数据集示意图Fig.9 Schematic diagram of 10-Fold training and testing dataset
对CraterCNN+SVM算法进行验证。利用文献[21]方法作为对比方法,该方法是目前在h0905_0000陨石坑数据集上获得最高检测精度的方法,其利用Haar-like人工特征和AdaBoost分类器实现对陨石坑候选区域的分类(下文将该对比方法简称为Haar-like+AdaBoost)。为了比较SVM分类器的性能,实验还将利用Haar-like特征和SVM分类器组合算法实现对陨石坑候选区域的分类(下文将该对比方法简称为Haar-like+SVM),同时,还将利用所提出的CraterCNN提取陨石坑候选区域特征,并分别以Softmax分类器和AdaBoost分类器对CraterCNN网络提取出的特征进行分类,将这2种对比方法简称为CraterCNN+Softmax和CraterCNN+AdaBoost。
所提出的CraterCNN+SVM和4种对比方法(Haar-like+AdaBoost、Haar-like+SVM、CraterCNN+Softmax、CraterCNN+AdaBoost)在h0905_0000数据集3个子集所对应的10-Fold数据集上的查全率R、查准率P和F1的取值如表3所示。可以看到,在3个子集上,CraterCNN+SVM均获得了最高的F1度量取值,同时,除了中部区域的查全率P外,CraterCNN+SVM均获得了最高的查全率P和最高的查准率R,由于中部区域的陨石坑识别难度最大,特征的非线性程度高,线性SVM的查全率较AdaBoost低一些。通过观察CraterCNN+Softmax、CraterCNN+SVM、CraterCNN+AdaBoost在3个10-Fold数据集上的F1取值可以看到,CraterCNN+SVM的F1取值最高。同时,对于Haar-like特征而言,SVM分类器的精度要低于AdaBoost分类器的精度,这是因为陨石坑区域的Haar-like特征的线性可分性较差,所以,线性SVM分类器的性能要稍差于非线性的AdaBoost分类器。另外,由4.2.1节所述,中部区域的陨石坑识别难度最高,因此,各算法在3个区域的F1度量取值最低。

表3 Crater CNN+SVM与其他陨石坑候选区域分类算法对比实验结果Table 3 Contrast experimental results of Crater CNN+SVM algorithm and other crater candidate regions classification algorithms
表4分别给出了CraterCNN特征和Haar-like特征在3组10-Fold测试集上的平均提取时间,以及CraterCNN+SVM和CraterCNN+AdaBoost在这3组数据集上的平均训练时间和平均测试时间。可以看到,在3个数据集上,CraterCNN特征提取时间要明显低于Haar-like特征,同时,Crater-CNN+SVM的平均训练时间和平均测试时间都要低于CraterCNN+AdaBoost。

表4 不同特征提取及不同分类算法的训练和测试在10-Fold数据集上的平均时间Table 4 Mean time of different feature extraction algor ithms and different classification algorithms on 10-Fold training dataset and testing dataset
为了更加形象化地对比CraterCNN提取的特征与Haar-like特征,利用高维特征可视化算法t-SNE分别对h0905_0000数据集的3个子集的所有样本的CraterCNN特征和Haar-like特征进行显示,结果如图10所示。其中,图10(a)~(c)分别是利用CraterCNN对3个数据集的所有样本提取出的特征的二维可视化结果,而图10(d)~(f)分别为这3个数据集中的所有样本的Haar-like特征的二维可视化结果。可知,CraterCNN提取出的特征在3个数据集上的可分性都要优于Haarlike特征,从而再次证明基于CNN的自动学习特征性能远优于人工特征。

图10 基于t-SNE算法的CraterCNN特征和Haar-like特征可视化结果Fig.10 Visualized results of CraterCNN features and Haar-like features based on t-SNE algorithm
4.3 基于仿真陨石坑图像的陨石坑区域检测实验
4.3.1 仿真陨石坑图像数据集
为了有效验证陨石坑区域检测算法,采用仿真方法构建陨石坑图像数据集。首先,利用基于三维解析模型的陨石坑仿真图像生成算法[47]产生10幅陨石坑仿真图像,并分别对每一幅图像进行2次随机射影变换,得到30幅陨石坑仿真图像,这些仿真图像充分模拟了着陆器在着陆过程中可能出现的各种位姿情况。其次,从这些仿真图像中手动选取164个正样本和164个负样本。然后,分别对这些样本进行水平和垂直方向的翻转,得到656个正样本和656个负样本。最后,为了使这些陨石坑样本更加接近真实图像,分别对其进行高斯模糊和运动模糊处理,并添加高斯白噪声,最终得到1 312个正样本和1 312个负样本作为仿真陨石坑图像数据集。图11给出了该数据集中的一些典型样本示例。

图11 陨石坑仿真图像构成的陨石坑区域数据集正负样本示例Fig.11 Positive and negative examples in crater region dataset composed of simulated crater images
4.3.2 陨石坑区域检测算法测试
实验利用基于仿真陨石坑训练数据集得到的CNNCrater+SVM对陨石坑仿真图像进行陨石坑区域检测,并以4.3.1节实验中提到的Haar-like+SVM算法作为对比方法,检测结果如图12所示。图12的第1列给出了基于三维解析模型的陨石坑仿真图像生成算法产生的4幅仿真图像,利用所提出的陨石坑候选区域提取算法从输入的陨石坑图像中提取疑似陨石坑区域,算法得到的陨石坑亮暗区域和候选区域结果如图12第2列和第3列所示,可以看到,所提出的陨石坑候选区域提取算法能够较为精确地从输入的陨石坑图像中提取出陨石坑候选区域。图12第4列和第5列分别为利用CraterCNN+SVM算法和Haar-like+SVM算法得到的陨石坑区域检测结果,这2种算法从每幅陨石坑仿真图像中正确检测到的陨石坑区域个数如表5所示。可以看到,所提出的基于特征自动学习的陨石坑区域检测方法能够正确提取出所有的陨石坑区域,而Haar-like+SVM算法由于使用了人工特征,自适应性较差,对于图12所列出的4幅陨石坑仿真图像,该算法都分别出现了不同程度的错误检测。

图12 基于解析数据的陨石坑仿真图像陨石坑区域检测结果图例Fig.12 Examples of crater region detection experimental results of crater simulation image based on analytical data
另外,表5还给出了所提出的候选区域提取算法、候选区域分类算法以及Haar-like+SVM算法处理图12第1列所示的4幅陨石坑仿真图像的时间。可以看到,基于自动特征学习的陨石坑区域检测算法的大部分时间主要消耗在候选区域提取上。

表5 基于解析数据的陨石坑仿真图像陨石坑候选区域检测结果统计Table 5 Candidate crater region detection experimental results of crater simulation image based on analytical data
4.4 基于真实陨石坑图像的陨石坑区域检测实验
利用真实陨石坑图像对基于自动特征学习的陨石坑区域检测算法(仍然简称为CraterCNN+SVM)进行验证,所使用的测试图像来自于美国麻省大学波士顿分校KDLab实验室在构造陨石坑数据集h0905_0000时所采用的火星表面真实陨石坑图像[45]。由于4.2节中的实验已经针对数据集h0905_0000完成了陨石坑区域分类器CraterCNN+SVM的训练,本组实验将直接利用训练好的分类器,并结合所提出的陨石坑候选区域提取算法,完成对真实陨石坑图像的陨石坑区域检测。与4.3节相同,本组实验仍然选择Haarlike+SVM方法作为对比方法,检测结果如图13所示。
图13第1列给出了来自KDLab实验室的4幅火星表面真实陨石坑图像。利用所提出的陨石坑候选区域提取算法从输入的陨石坑图像中提取疑似陨石坑区域,结果如图13第2列所示。可以看到,所提算法能够较为精确地从输入图像中提取出陨石坑候选区域。CraterCNN+SVM和Haar-like+SVM所提取到的陨石坑区域检测结果如图13第3列和第4列所示,这2种方法从每幅陨石坑仿真图像中正确检测到的陨石坑区域个数如表6所示。可以看到,CraterCNN+SVM能够正确提取出所有的陨石坑区域,而Haar-like+SVM由于使用了人工特征,精度和自适应性较差,对于图13所列出的4幅陨石坑仿真图像,Haar-like+SVM都分别出现了不同程度的错误检测结果。

图13 基于真实陨石坑图像陨石坑区域检测结果图例Fig.13 Examples of crater region detection experimental results based on real crater simulation image

表6 基于真实陨石坑图像的陨石坑候选区域检测结果统计Table 6 Candidate crater region detection experimental results based on real crater image
5 结 论
针对基于陨石坑视觉导航对陨石坑区域检测的需求,提出一种高精度的基于自动特征学习的陨石坑区域检测算法。
1)算法可以实现从导航图像中提取陨石坑区域,为基于陨石坑的视觉导航方式提供必要的导航路标输入。
2)算法有效地利用了图像陨石坑的形态特点,利用改进后的MSER算法实现了陨石坑候选区域检测,有效克服了传统的滑窗检测算法计算负担大、效率低的问题,极大降低了误检率。
3)算法利用自动特征学习的方法实现陨石坑候选区域的分类,实现陨石坑区域检测,检测精度明显高于传统的基于人工特征的陨石坑区域检测算法,在通用火星表面陨石坑数据集上,获得了0.916 4的F1度量值,远高于其他陨石坑区域检测算法。
基于自动特征学习的陨石坑区域检测算法可以为基于陨石坑视觉导航提供陨石坑区域信息,然而,要实现高精度的基于陨石坑视觉导航,还需要对陨石坑区域中的陨石坑环形边缘提取算法进行研究,这将是下一步研究工作的重点。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
小天使·四年级语数英综合(2020年10期)2020-12-16
文萃报·周五版(2020年15期)2020-04-22
阅读与作文(小学高年级版)(2020年3期)2020-03-02
领导决策信息(2018年16期)2018-09-27
软件导刊(2017年4期)2017-06-20
数学学习与研究(2017年3期)2017-03-09
计算技术与自动化(2014年1期)2014-12-12
