
聚类分析在X波段双偏振雷达相态识别中的应用
2021-06-23 08:51李宗飞李祥海陈凯华冯亮
气象科技 2021年3期
李宗飞 李祥海 陈凯华 冯亮
(1 天津市气象信息中心,天津 300000; 2 中国科学院大气物理研究所云降水物理与强风暴重点实验室,北京 100029)
引言
随着我国电子硬件和计算机软件技术的发展,新一代多普勒天气雷达正在向双偏振天气雷达升级。双偏振天气雷达不仅包含反射率因子(ZH)、径向速度(V)、谱宽(W),还包括了差分反射率(ZDR)、相关系数(ρhv)、差传播相移(ΦDP)、差传播相移率(KDP)等差分信息。双偏振天气雷达在冰雹、暴雨等灾害性天气监测预警中起到了重要作用[1],能更好地计算降水量、雨滴谱等信息[2],并且可以进行水凝物相态识别,对于分析降水的物理过程有着重要意义。
双偏振天气雷达在相态识别方面表现较好,1993年Straka和Zrnic提出的布尔判决逻辑进行水凝物分类[3],由于观测噪声以及雷达参数之间的不完全排斥,所以该方法并不能完全分类降水相态。通过建立概率模型的方法也可以进行相态识别,需要统计相应的概率密度函数,并且需要先验知识,实现较为困难[4]。模糊逻辑算法是目前较为常用的相态识别方法,模糊逻辑算法最早由Zadeh(1965)提出,曹俊武(2005)、何宇翔(2010)、刘亚男(2012)等先后使用该方法实现降水粒子的相态识别,模糊逻辑算法进行相态识别首先需要建立成员函数,成员函数是指不同水凝物粒子的雷达参数取值范围的函数,又称为隶属函数,成员函数的优劣直接决定了相态识别效果[5-7]。
成员函数的建立有通过散射模拟获得,也有根据观测以及前人经验进行修改得到,然而由于不同雷达接收机灵敏度、动态范围、噪声系数等差异[8],该方法得到的成员函数对不同雷达的识别效果存在差异,尤其是当雷达参数存在系统性偏差时,如双偏振雷达水平和垂直通道增益和灵敏度不同,导致差分反射率存在系统性偏差,此时常用的成员函数与实际雷达观测数据存在差异,不利于进行相态识别[9]。为了得到更合适的成员函数,可使用雷达和机载粒子谱仪联合观测,然后调整相应的的成员函数,该方法实验难度较大,且观测成本较高。针对此类情况,本文提出使用聚类分析的方法对水凝物粒子进行分类,然后根据聚类中心判断降水相态。
因为雷达老化出现系统性偏差是一个渐变过程,不能及时对雷达进行定标或系统性补偿,该过程中采用模糊逻辑算法进行相态识别将存在一定的误差,所以本文使用聚类分析的方法完成相态识别,然后统计不同相态粒子的雷达参数概率分布特征,计算相应的概率分布函数,对该函数进行归一化处理并构建成员函数,可用于模糊逻辑算法进行相态识别。因为该函数通过统计得到,所以不受系统偏差影响,更适合于该雷达使用。
1 资料来源
使用数据来自于中国科学院大气物理研究所的车载X波段双偏振雷达,型号为714XDP-A,观测地点为北京市顺义区,经纬度分别为116°40′48″E,40°10′48″N,雷达工作频率9.370 GHz,距离分辨率150 m/250 m,最大探测距离150 km。该雷达工作年限较长,存在器件老化现象,其反射率ZH和差分反射率ZDR存在系统偏差,相关系数ρhv在信噪比较低时其相关性变差,为估计降水和相态识别增加了难度。
使用了2015年7月和2016年9月发生在北京的降雹过程资料,雷达扫描方式为垂直扫描(RHI),用于相态识别的数据包括ZH、ZDR、KDP和ρhv。其中反射率ZH和差分反射率ZDR存在较大的降水衰减,所以本文使用了KDP综合分类法进行衰减订正[10]。另外,为了减少数据中的噪声,提高数据可用性,本文对以上四种数据进行平滑处理。
2 聚类分析识别相态原理
2.1 聚类分析
聚类分析是一种群分析手段,是对样品或指标进行多元统计的方法[11]。K-均值聚类方法通过计算样本之间的距离进行分类,可以将样本或指标看成n维空间上的点,例如样本x1={x11x12x13},和x2={x21x22x23},在三维空上的欧氏距离d为
(1)
K-均值聚类方法由如下4个步骤完成:


j≠i},i=1,2,…,k
(2)

最终的各个聚点是每个分类的重心,具有各分类的鲜明特征,而且每个聚点之间有较大的欧氏距离,是区分各个分类的标志性数据。另外,由于初始聚点为随机数据,受算法自身的局限性影响,聚类分析可能会陷入局部稳定的状态,不能进行充分的分类,需要重复计算,才能得到最佳结果。此为K均值聚类分析方法的自身局限性,本人通过软件重复分类,选择充分分类的结果做为最终分类,利用计算机可重复计算和不断迭代的特点弥补算法的不足,表明该算法可以进一步的优化。
2.2 相态识别原理
不同相态水凝物在双偏振雷达参数上的表现是识别相态的基础,例如冰雹的反射率通常在35~50 dBz之间,差传播相移率在-3~1 °/km,差分反射率在-3~0 dB之间,相关系数在0.94~0.98范围之间,所以,能够利用不同水凝物在雷达参数上的表现不同进行相态识别[12]。模糊逻辑算法进行相态识别是在此基础上建立成员函数对雷达参数进行模糊化,然后按照一定规则进行数据合成,最后进行退模糊化和识别相态。
根据不同水凝物雷达参数特征的表现,表明各水凝物的雷达参数存在欧氏距离,所以能够使用聚类分析算法对不同相态的水凝物进行区分。能够反映水凝物相态的雷达参数包括反射率因子ZH(dBz),差分反射率因子ZDR(dB),差传播相移率KDP(°/km)以及相关系数ρhv(无量纲)。首先,将相同位置的4个雷达参数构成一个样本(ZH,ZDR,KDP,ρhv),然后对一定范围的所有样本进行聚类分析,最后对分类结果的聚类中心进行相态判断,因为聚点与聚点之间有较大的欧氏距离,边界清晰,所以很容易根据不同相态的降水特征进行判别。
聚类分析完成相态识别后,可一进步统计水凝物的雷达参数概率分布特征,并对其进行函数拟合,从而建立不同水凝物的成员函数,作为该雷达专有的成员函数,可用于模糊逻辑算法进行相态识别。
3 聚类分析相态识别实例
3.1 资料预处理
由于在强降水过程中X波段雷达存在较大的降水衰减,所以首先需要对雷达反射率及差分反射率进行衰减订正,本文使用KDP综合分类法进行衰减订正,该方法分别对ZH和KDP进行分类,然后采用自适应算法计算不同分类中的衰减系数,并制定了衰减系数表格,最后使用表格数据计算衰减率,并进行反射率和差分反射率的衰减订正[10]。
聚类分析是按照各样本之间的欧氏距离进行分类的,为了解决不同参数在欧氏距离计算时的公平问题,需要对所有参数进行归一化,例如反射率因子取值范围在-5~70 dBz之间,而相关系数取值范围在0~1之间,如果不进行归一化,那相关系数对于距离的影响要远远小于反射率因子,不能充分发挥相关系数的作用。固态降水识别主要依赖相位数据,为提高相位参数的权重,可以对KDP和ρhv乘以大于1的系数,增加该参数的权重。另外,受接收机灵敏度和噪声系数限制,当回波较弱时双偏振雷达的偏振参数误差较大,如KDP和ρhv,所以需要剔除反射率小于5 dBz的回波,然后进行相态识别。
3.2 相态识别实现
图1为2016年9月7日18:48(北京时)冰雹降水的垂直扫描过程,所处方位角为212°,图1a反射率和图1b差分反射率均进行了降水衰减订正,回波强度在对流中心处得到一定恢复,但对流中心后方因电磁波无法穿透出现空洞,并且在回波边缘处由于信噪比较低ZDR、KDP和ρhv均出现异常值,如ρhv在50 km后因小于0.7超出色标范围而无法显示。
图1中可以看出云团顶高达到12 km,并且垂直3 km处可明显看到零度层亮带,距离雷达32 km处为对流中心,最强回波达到60 dBz左右。图中显示零度层亮带以下反射率小于30 dBz, 差分反射率小于1.5 dB,差传播相移率在0°/km左右,相关系统在0.98左右,表明该区域为小到中雨量级。在对流中心处反射率35~60 dBz之间,差分反射率从-3~3 dB之间,差传播相移率从0~8 °/km,相关系统在0.88~0.96之间,且对流中心延伸到10 km高度,表明此处为强降雨和冰雹区域。零度层亮带一般为融雪,其上多为雪和冰晶[13]。在近地面对流中心的后方区域,受降水衰减影响反射率为0~5 dBz。图中反射率和差分反射率均已进行衰减订正,但差分反射仍存在小于-3 dB的数据,超出色标显示范围,该区域差传播相移率和相关系数信噪比较低,且有些数据低于色标显示范围,不进行相态识别。

图1 2016年9月7日18:48北京X波段双偏振雷达垂直剖面(方位212°):(a)订正后反射率,(b)订正后差分反射率,(c)差传播相移率,(d)相关系数
在不考虑温度分布的情况下,对雷达4种参数进行聚类分析,使其充分分类,得到7个分类,聚类中心分别为小雨(含中雨){17.42 dBz,-0.18 dB,-0.99°/km,0.970}、大雨{36.49 dBz,0.64 dB,2.04°/km,0.951}、雹{36.81 dBz,-1.47 dB,-0.83°/km,0.963}、雨夹雹{47.97 dBz,1.53 dB,7.50°/km,0.923}、雪或冰晶{11.90 dBz,-1.02 dB,-1.26°/km,0.977}、霰{21.48 dBz,-1.28 dB,-1.130°/km,0.979}、未知{7.84 dBz,-1.18 dB,-1.84°/km,0.778}。图2中深灰色为未知相态,主要因为该区域反射率、差分反射率存在较大衰减,并且因为信噪比变差所以水平和垂直方向回波的相关性变差,导致雷达参数不能用于相态识别。从图2中看出在对流中心近地面位置主要是大雨、雹和雨夹雹,对流中心的高空为雹,外围为霰。零度层亮带识别为大雨和霰(此处无法正确分类),零度层亮带上方统一识别成雪(或有冰晶存在),该区域的错误识别皆因聚类分析算法自身局限性导致,不能对所有水凝物进行完全分类,考虑引入温度数据有可能解决该类问题,但由于对流性降水温度分布较为复杂,所以留待后续研究解决。
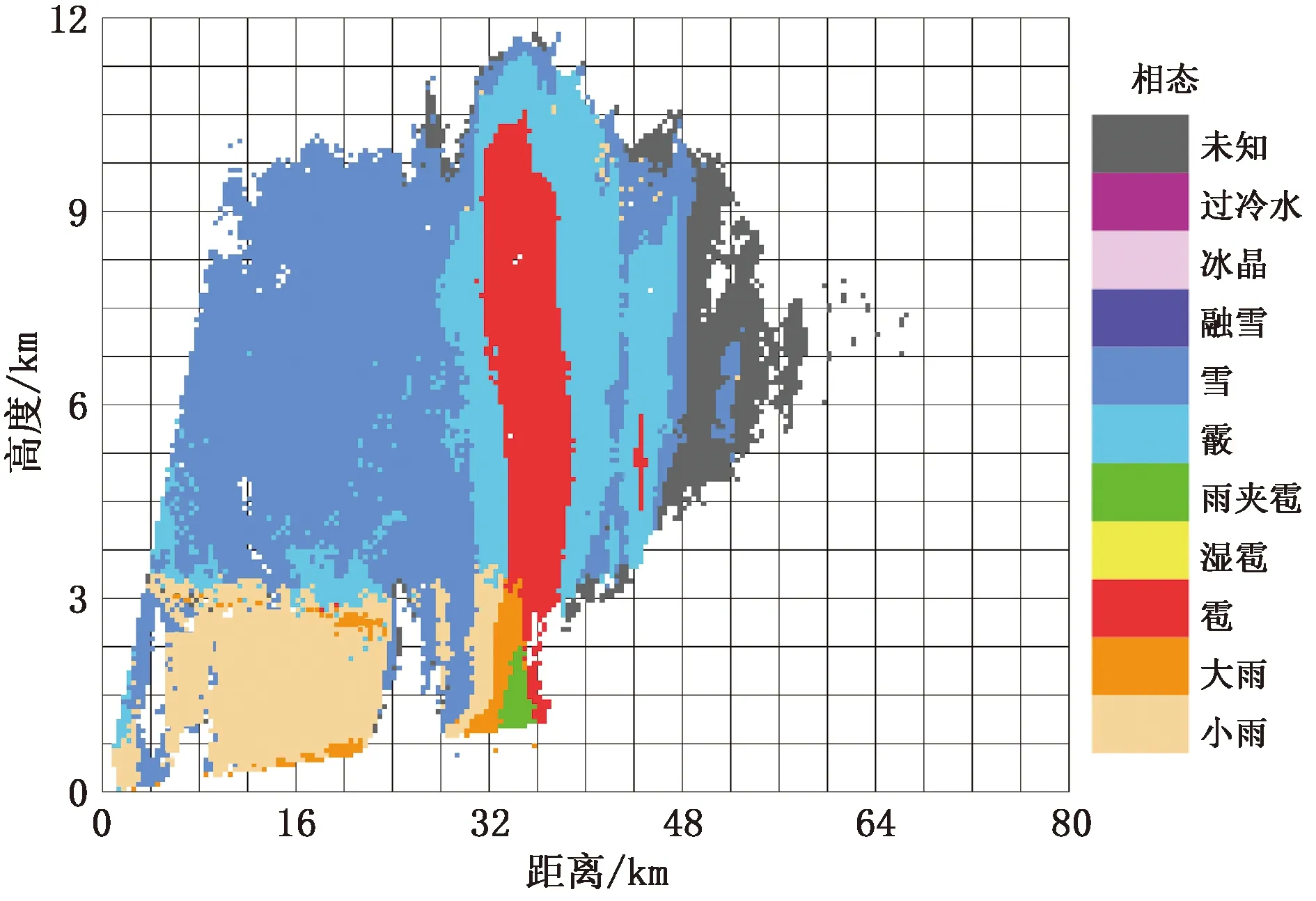
图2 2016年9月7日18:48北京X双偏振雷达相态识别
图3为2015年7月29日22:57(北京时)观测数据,该数据为冰雹过程的垂直扫描数据,方位角为190°。图3中分别为订正后的反射率,订正后差分反射率,差传播相移率和相关系数,图中显示本过程为强对流过程,对流高度达到12 km以上,最大强度为50 dBz。数据在水平方向的64 km之后因电磁波无法穿透而完全衰减。图中在水平方向60~64 km处对流高度及强度均为最大区域,是该过程的对流中心,该区域的差分反射率和相关系数均表现出冰雹特征。图中反射率和差分反射率均已进行降雨衰减订正,差分反射率低于-3 dB的区域未能显示,不进行相态识别。

图3 2015年7月29日22:57北京X波段双偏振雷达垂直剖面(方位190°):(a)订正后反射率,(b)订正后差分反射率,(c)差传播相移率,(d)相关系数
图4为相态识别结果,聚类算法对各降水相态分类中心为小雨(含中雨){14.15 dBz,-0.13 dB,-1.14°/km,0.968}、大雨{35.17 dBz,0.9 dB,1.04°/km,0.976}、雹{38.02dBz,-1.22dB,-0.91°/km,0.956}、雨夹雹{41.76 dBz,0.74 dB,3.47°/km,0.942}、雪或冰晶{13.16 dBz,-1.23 dB,-1.20°/km,0.943}、霰{25.99 dBz,-1.01 dB,-0.93°/km,0.969}、未知{11.59 dBz,-0.42 dB,1.1°/km,0.794}。从分类结果可以看出对流中心位置5 km以上主要为冰雹,5 km以下主要为雨夹雹,而水平方向64 km以外存在因为信号衰减而无法观测的冰雹区域。在5 km以上对流中心两侧主要为霰粒子,最外围是雪或冰晶,其下方为降雨。图中可以看出在降水回波边缘位置,依然存在因回波信噪比较差而无法识别的未知降水类型。

图4 2015年7月29日22:57北京X双偏振雷达相态识别
聚类中心即为该相态粒子雷达参数的平均值,表明该相态粒子的平均特征,从数据上看与以往经验数据略有差异,各类水凝物雷达参数均值偏低,表明雷达可能存在老化现象,回波接收功率及回波相关性变差。
3.3 统计参数特征
本文按照以上方法对冰雹过程的多次RHI扫描进行相态识别,并将雷达各类参数根据水凝物进行分类,然后统计各参数的概率密度分布,并进行归一化, 最后得到属于该雷达在本次过程的相态识别成员函数,可进一步用于模糊逻辑算法进行相态识别,图5、图6给出了2015年和2016年的大雨和冰雹的统计数据。
图5为2016年9月7日的大雨和冰雹雷达参数的概率分布情况,从图中可以看出,本次降水的冰雹和大雨反射率较为接近,主要分布在25~45 dBz之间,差分反射率和差传播相移率有较大差异,其中冰雹的差分反射率和差传播相移率主要为负值,而大雨为正值,两者相关系数主要分布在0.97以上,差别不大。该统计显示了该过程中冰雹及大雨的参数分布差异。
图6为2015年7月29日的大雨和冰雹雷达参数的概率分布特征,与图5相比本次过程的反射率、差分反射率和差传播相移率的中心位置均小于图6,表明该过程弱于2016年的过程。从两次过程反映出冰雹的差分反射率和差传播相移率小于大雨过程,并且其分布范围较窄。
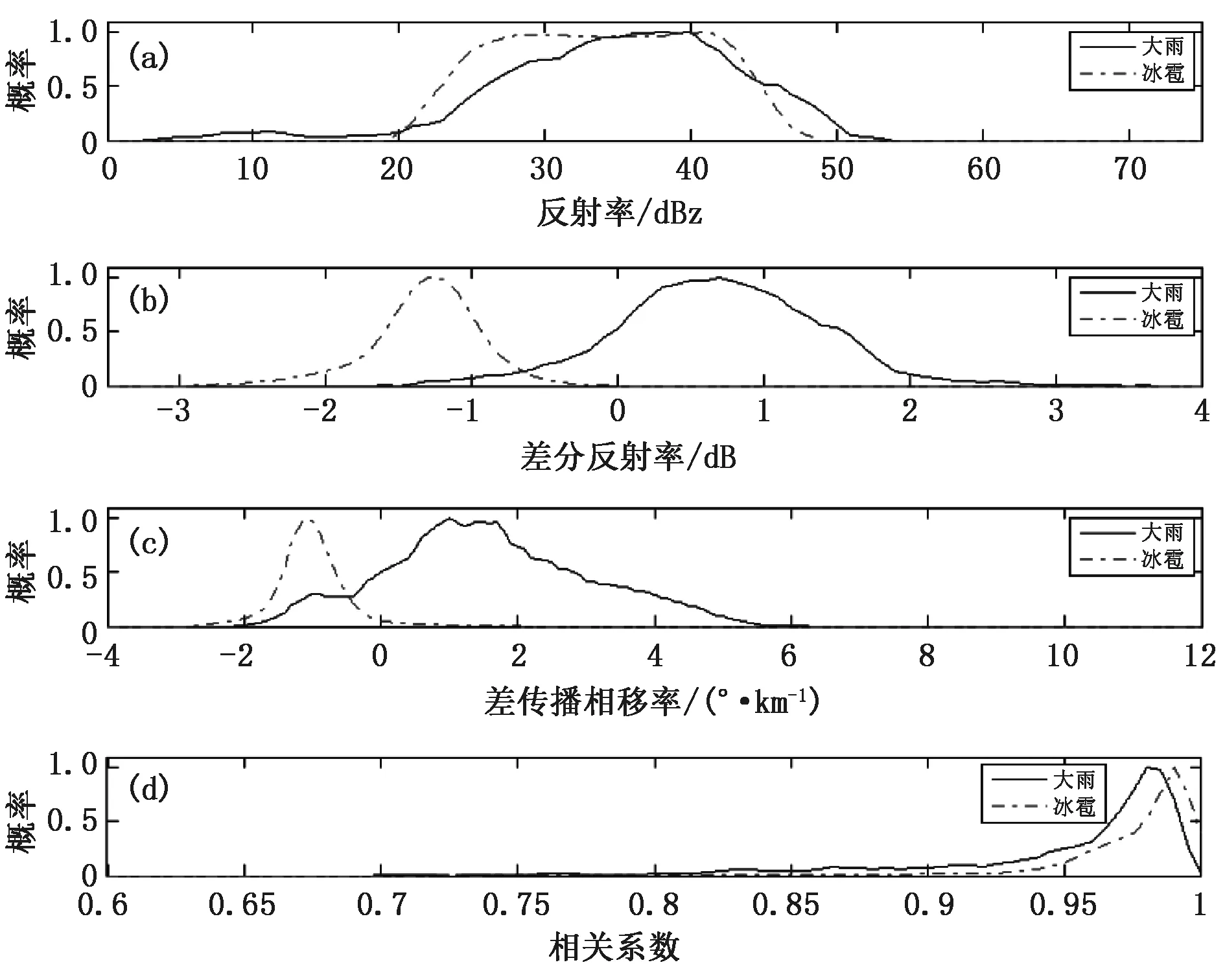
图5 2016年9月7日过程大雨和冰雹雷达参数概率分布(a)反射率,(b)差分反射率,(c)差传播相移率,(d)相关系数

图6 2015年7月29日过程大雨和冰雹雷达参数据概率分布(a)反射率,(b)差分反射率,(c)差传播相移率,(d)相关系数
经与刘亚男2012年使用模糊逻辑算法相比[7],雷达参数的分布特征存在一定的差异,首先是反射率和差分反射率明显偏弱,其中冯亮在2018年论文中提到该雷达差分反射率需要一定的补偿[9],表明该雷达确实存在老化现象。另外,差传播相移率分布宽度窄于模糊逻辑算法中给出的成员函数,表明在单次过程中的参数分布包含于平均特征分布中,考虑增加更多降水个例,可能会趋于一致。
从图5、图6数据可以看出,在本次过程中,冰雹与大雨的差分反射率和差传播相移率的分布特征有较大的差异,以此分布曲线拟合成员函数,在模糊逻辑算法中将明确分辨出两种降水类型,所以使用聚类分析方法构造成员函数用于模糊逻辑算法是可行的。
4 结论与讨论
K-均值聚类分析方法在双偏振雷达相态识别中应用效果较好,该方法区别于传统算法,是对大数据算法的一种典型应用,弥补了传统算法在相态识别中对先验数据的依赖,如模糊逻辑算法完全依赖于成员函数。但该算法同样存在自身的局限性,如在计算时存在局部稳定状态,需要重复聚类才能解决。该问题可采用其他聚类分析方法,择优处理。另外,该方法是在当前大数据应用环境下的一种尝试,是模糊逻辑算法的一种补充方案。
经聚类分析进行相态识别后的数据,可分别进行概率分布统计,完成成员函数的构建,通过该方法构建的成员函数更为适合该雷达进行水凝物分类,并且不受雷达系统误差的影响。因为不同降水类型的数据分布特征不一致,所以需要对多类型降水进行完全统计,才能构建合理的各成员函数。
温度分布在相态识别中起着重要作用,在不考虑温度的情况下,在雷达参数上无法识别融雪与霰和雨、雪和冰晶等的区别,因为它们的雷达参数不存在排斥,所以加入温度信息是利用雷达参数进行相态识别的重要手段。
猜你喜欢
数学杂志(2022年5期)2022-12-02
冶金能源(2022年5期)2022-10-14
湘潭大学自然科学学报(2022年2期)2022-07-28
——缺陷度的算法研究
条码与信息系统(2022年3期)2022-07-05
汽车电器(2022年6期)2022-07-02
祝您健康·文摘版(2022年5期)2022-05-09
成都信息工程大学学报(2021年5期)2021-12-30
新世纪智能(数学备考)(2021年5期)2021-07-28
汽车文摘(2018年2期)2018-11-27
环球时报(2017-07-19)2017-07-19
