
基于Spark 的分布式网络日志处理系统的设计与实现
2021-06-25 06:44芦成刚王桂荣
科学技术创新 2021年15期
芦成刚 王桂荣
(延边大学工学院,吉林 延吉133002)
当今社会中大量数据的出现使数据分析领域的地位变得越来越重要。在当今的大数据领域,Spark 作为大数据通用计算平台,不但活跃,而且热门与高效[1]。为了给用户提供更好的体验,有必要分析网络日志。网络日志非常庞大,传统的日志分析方式已经很难满足人们的需要,有必要利用新的技术架构进行分析。本文介绍一种以Hadoop 分布式文件系统(HDFS)为存储结构,基于Spark 相关技术,利用Flume 的高扩展性和高可靠性,将日志进行分布式存储并离线分析处理的日志分析处理系统[2]。
1 系统整体配置
1.1 虚拟机环境安装
在本地电脑上安装一台虚拟机,在该虚拟机上克隆出三台主机,安装cent os 系统。每台主机安装Hadoop 存储系统,其中,一台为主机(Master),两台为从机(Slave),构成模拟分布式存储系统。Spark 可以独立安装使用,也可以和Hadoop 一起安装使用。
1.2 Spark 平台搭建
1.2.1 Scala 环境安装
1.2.1.1 Master 机器
Step1: 下载Scala 安装包,解压到/opt 目录下;
Step2: 修改Scala 安装包目录所属用户和用户组;
Step3: 找到环境变量文件.bashrc , 点击打开后进行编辑,添加一些其它选项,设置它的Scala_home 为解压目录下的安装包,设置它的path 环境变量为安装包下的bin 文件;
Step4: 验证Scala 安装。
1.2.1.2 Slave 机器
Slave 机的安装步骤和Master 机器安装步骤是一样的,根据前面Master 机器的安装步骤来安装就可以。
1.2.2 Spark 安装
1.2.2.1 Master 机器安装步骤如下:
Step1:在/opt 目录中,下载Spark 安装包并将其解压;
Step2:找到Spark 安装包的目录,重新设置用户与用户组;
Step3: 找到环境变量文件.bashrc , 打开进行编辑,添加Spark 的环境信息,设置SPARK_HOME 属性,使其指向/opt 目录下的spark 安装软件,修改它的Path 环境变量,使其指向SPARK 的bin 文件和sbin 文件;
Step4: 对Spark 进行配置。找到Spark 安装位置并进入到conf 目录,找到Spark-env.sh.template 文件,将其拷贝到Spark-env.sh。用文本编辑器打开Spark-env.sh 并将其编辑,添加相关配置信息,主要是配置相关环境变量,例如:
JAVA_HOME:指定Java 安装路径,指向安装文件;SCALA_HOME:指定Scala 安装路径,指向它的安装版本;SPARK_MASTER_IP:指定Spark 集群 中的Master 节点的IP 地址;
SPARK_WORKER_MEMORY:指定的是Worker 节点能够分配给Executors 的最大内存大小;
HADOOP_CONF_DIR:指定Hadoop 集群配置文件目录。
最后,找到Slaves.template 文件并将其拷贝到Slaves,在里面编辑内容为:
Master
Slave01
Slave02
即Master 既是Master 节点又是Worker 节点。
1.2.2.2 Slave 机器
这里Slave 机的安装步骤和Master 机器安装步骤相同,根据前面Master 机器的安装步骤来安装就可以。
2 系统整体分析
2.1 需求分析
日志是计算机系统中非常广泛的概念,任何程序都可以输出日志。日志源设备的类型多样,型号复杂,需要对日志信息进行初步的规范化处理[3]。本设计基本使用的是Web 日志,Web 日志里包括由各种Web 服务器生成的用户访问日志和Web 应用程序输出的日志。在Web 日志中,每个日志可以很直观的表达用户的访问行为。接下来这个是一条完整的日志:
117.35.88.11-- [10/Nov/2016:00:01:02 +0800] "GET/article/ajaxcourserecommends?id=124
HTTP/1.1" 200 2345 "www.imooc.com" "http://www.imooc.com/code/1852" - "Mozilla/5.0 (Windows NT 6.1; WOW64)
此日志可以获取大量信息,例如访问者IP、访问时间、访问过的网页和访问者。Web 日志中有大量消息是人们感兴趣的,例如,不同网站的不同类型页面浏览量,独立IP 的数量等。可以通过Web 日志计算关键字查询的频率和用户检索的用户查询的数量,并用于构建广告点击魔术并分析用户行为特征[4]。
2.2 系统体系结构
该平台按结构分为三个模块:日志收集模块、日志分发模块、日志分析模块。
日志收集模块:Flume 通过收集和处理Web 日志数据,可以将其导入进HDFS,Flume 收集数据的具体过程为:
2.2.1 检查Flume 配置文件,该文件在$FLUME_ HOME/conf目录下。
2.2.2 检查配置代理,监视在指定文件夹中是否有新文件的更改。如果出现新文件,就执行下一步,并且继续监视文件夹中的文件更改情况。
2.2.3 如果有新文件,查看新文件出现的内容并解析。
2.2.4 往通道中写入,如果成功,则将文件标记为已完成或将文件删除,如果写入不成功,则重新读取文件内容并解析。
2.2.5 传输数据到channel 中,并将数据写入HDFS 存储。
日志存储模块:本系统使用HDFS 进行数据存储,通过使用Flume,文件会以三秒的间隔自动上传到HDFS,用于三个节点。日志数据存储模块的数据存储过程如下:
Step1: 在客户端,调用create () 函数,创建文件DistributedFileSystem。
Step2:对元数据进行封装,此功能用FileStaus 类完成。
Step3:调用元数据节点,此功能用FileSystem 类完成。
Step4: 元数据节点有重要的作用,首先确定原文件是否存在,如果不存在,就重新调用create(),创建新文件,如果存在,就面向客户端创建新文件。
Step5: 客户端用于写数据,FSDOutputStream 则负责将数据分成块,写入数据队列。
Step6:FSDOutputStream 保存确认队列,用以确认数据块是否发送,等待数据节点通知,数据是否成功写入和存储,如果成功存储则结束。
日志分析模块:日志分析模块主要组成部分为日志数据清理,日志数据特征提取,日志数据功能正规化与日志数据特征分析等[5]。日志数据清理模块中,理想情况下,Web 日志数据集中的每条记录都已完成。但实际上会有一些嘈杂且不完整的数据残留。丢失数据的原因大概就是因为,不愿意发布的数据或者是手动输入时一时疏忽,导致了一些数据的丢失。在Web 日志数据集中,如果一条记录的属性被标记为空或“_”,那么该记录被认为具有缺失值,并不是一条完整的数据[6]。
3 实验结果
收集到的数据应先对其进行清洗操作,之后需要解析访问的日志,使用Sparksql 解析访问日志。通过Spark 对离线日志进行分析,统计最受欢迎的topn 的视频访问次数。统计结果如图1所示。
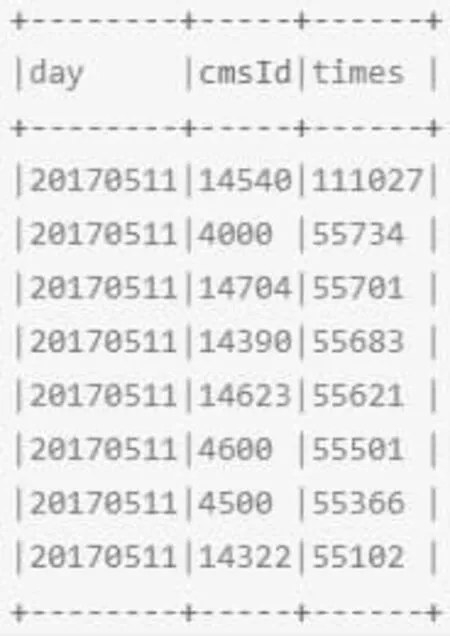
图1 最受欢迎的topn 的视频访问次数
将统计结果写入Mysql 中,这个过程是从底层往上层封装的。编写Mysql 的连接工具类,步骤如下:
Step1:创建数据库表;
Step2:在pom.xml 文件中添加JDBC 依赖包;
Step3:和表结构对应的课程访问次数实体类;
Step4:调用DAO 实现统计结果写入Mysql;
Step5:执行程序后,查看验证数据库结果。如图2 所示。
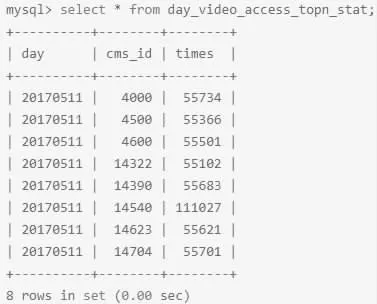
图2 将结果写入Mysql
由实验结果可知,该系统能够较好的实现Web 日志的分析,可以为网站决策者提供必要的参考依据。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
火力与指挥控制(2020年1期)2020-03-27
World Journal of Diabetes(2019年3期)2019-04-16
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
