
基于形态流的石油钻井水流异常检测
2021-07-02 08:55李衍志
计算机应用 2021年6期
李衍志,范 勇,高 琳
(西南科技大学计算机科学与技术学院,四川绵阳 621010)
(∗通信作者电子邮箱17828100385@163.com)
0 引言
石油是生产汽油、煤油、柴油等化学物质的重要原料,同时其副产物也是有着广泛的用途[1]。发掘石油原料的同时也伴随着大量的具有污染性的气体来到地面。为了保护环境、保障安全生产,必须对超过排放标准的气体进行无害化处理。这些污染性气体中威胁性最大的就是硫化氢(H2S),其含量高、无色无味且含有剧毒、不溶于水,不能溶解在钻进排水管道的水流中[2]。由于这些污染气体大多不溶于水或者只有部分能溶于水,且井内气体含量越高内部气压就越高,井内气压变化,排水管道口的水流形态就会变化。污染气体含量越高水流形态变化越明显。异常样本从当前帧和上一帧的对比可以看到,图像中水流的量明显变大,水流的形态变化也很明显;正常的样本从前后两帧的对比可以看出,虽然形态和水流量上都有一定的变化,但是变化不大。从异常样本和正常样本的对比来看,正常样本和异常样本形态上都有变化,但是异常样本的形态变化更为剧烈。现在生产过程中都是人工在后台监测水流的变化情况,但是人工监测存在视觉疲劳和一个人难以同时监测多个点的问题,因此很难避免造成监测不到位和人力资源浪费的问题。基于人工智能技术,使用计算机代替人工监测是其解决方法。目前在机器视觉领域关于监测石油钻井水流形态变化是否异常的研究较少,该项研究主要存在以下两大难点:1)水流数据表示方面,水流的形态是不固定的,普通的特征提取方式难以同时表述水流形态在空间和时间上的变化过程;2)水流异常的表现形式也不固定,无法一一列举所有的情况,这也就给异常检测和判别带来了困难。
针对水流数据表示方面的问题,在以往的其他视频异常数据检测任务中常用的是轨迹特征和光流特征。其中,轨迹特征计算复杂且耗费计算资源,因此光流是众多研究者常用的方法,文献[3-4]等都对光流进行了研究。一方面,虽然现有计算资源已经比较强大,但是在实际应用中,有些计算需要在前端完成,前端配置一般不高,所以从算法上进行优化是其解决方法。另一方面,光流特征虽然在一定情况下具有优越性,但是其要求所描述的物体运动缓慢、一定时间内形态基本不变,所以光流不适用于水流异常数据检测。其他的诸如纹理特征、颜色特征、尺度不变特征变换(Scale Invariant Feature Transform,SIFT)特征等都只能对单幅图像提取特征,不能描述水流在时间轴上的变化。所以需要一种针对水流的新特征提取方法,该方法需要同时从二维空间和时间两个维度描述水流的变化过程。
在水流的异常数据检测判别方面,以往关于视频的异常事件检测的方法可以分为全监督的方法和非全监督的方法两个大类。非全监督的方法可以分为基于重建的方法、基于预测的方法和基于生成对抗网络的方法。全监督的方法在使用时需要预先列举所有的异常情况[5-7],然而水流的异常是偶然发生的,具有不确定性,不能完全列举所有的异常情况,所以全监督的方法不具有实际应用价值。非全监督的方法中:基于重建的方法,重建过程计算复杂,时间复杂度高[8-9],不能满足水流数据实时检测的需求;基于预测的方法根据预测值与真实值之间的差异来判别异常[10],但是水流形态几乎每一帧都在变化,因此要想学习到一个预测模型很困难;基于生成对抗网络的方法[11-13],首先通过对抗训练学习到正常水流数据的某种表示模式,测试时再根据当前水流数据帧是否符合这种表示模式来判是否异常。目前为止在异常视频数据检测公共数据集中性能表现最好的是文献[11]的方法,但是该方法生成器采用的是全卷积网络(Fully Convolutional Network,FCN)结构,没有充分利用到融合层的数据信息。
综上所述,针对目前将人工智能技术应用到石油钻井水流异常检测上的研究较少,以及视频异常事件检测相关研究存在缺陷不能直接应用在石油管道水流异常监测上的问题,本文提出了一种基于形态流的石油钻井水流异常检测算法。在水流数据表示和特征提取方面,该算法为了克服光流存在的缺陷结合实际水流形态的变化提出了形态流;在异常检测算法层面,为了提高异常检测精度对现有的GANomaly 算法[1]进行了改进。实验结果表明,本文算法在水流异常检测任务中,检测精度达到95%,在时间效率上也能满足实际的需求。改进后的异常检测网络在公共数据集上也取得了优于同类算法的精度,当异常类别为1 时检测精度相较最好的GANomaly算法提升了19个百分点。
1 水流异常检测流程
水流异常检测流程如图1 所示,需要注意的是在该应用中,水流分割仅仅是作为异常检测方法中特征提取的预处理步骤,是整体方法的一部分;同时,对图像进行分割然后再进一步提取形态流特征是训练阶段和测试阶段共有的部分。如图1 所示,在训练阶段需要通过学习得到两个映射:一个是形态流特征重建映射x→f1()x;另一个是重建结果和对应的形态流特征在进行L2 距离最小化学习时得到的最小化映射f3(x)。两个模型预训练好之后,将正常数据依次输入两个模型,然后根据最后输出的L2距离建立高斯模型。高斯模型用于表示正常数据的L2距离的最小化结果分布,高斯模型的阈值则结合异常样本和正常样本共同确定。在测试阶段,提取完形态流特征之后,首先将形态流特征输入重建模型得到重建结果;然后,将重建结果和对应的形态流特征同时输入最小化模型得到输出的L2 距离值;最后将该距离值输入高斯模型,当高斯模型输出的概率值小于高斯模型的阈值时判定该数据帧异常。
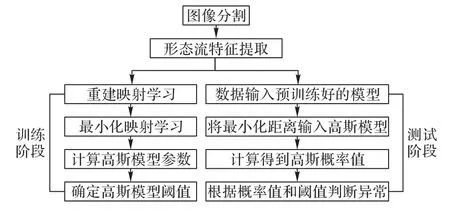
图1 水流异常检测流程Fig.1 Flow chart of abnormal water flow detection
2 形态流特征提取
2.1 水流分割
特征提取是水流异常检测任务中的重要一环,一种好的特征表示方法能决定最终检测结果的好坏。形态流特征提取的第1 步就是对图像中感兴趣的区域进行提取,即分割出图像中的水流。作分割的目的是为了克服如图2 所示水流数据样本中背景和噪声的干扰,只保留对水流异常检测有用的信息。

图2 水流数据样本Fig.2 Water flow data samples
水流的分割不同于普通物体例如熊、桌子、板凳这类有固定形态物体的分割,因为水流是没有固定形态的;同时它也不同于火焰的分割,火焰的颜色基本都是暗红色或者黄中透红,而水流受到水中介质的影响颜色是不固定的。因此,水流的分割不能简单地通过HSV(Hue,Saturation,Value)、RGB(Red,Green,Blue)等颜色空间来实现,也不能根据物体形态的特有属性来实现。深度学习的出现解决了场景和模式兼容的问题。需要同时考虑到模型不能太过简单影响分割效果,也不能太过复杂有了效果没有时间效率,例如deeplab[14]、AdaptSegNet(Adaption of Semantic Segmentation)[15]、区分特征网络(Discriminative Feature Network,DFN)[16]等算法时间效率就不高。综合各种因素最后选择了U-Net 神经网络[17]来作水流分割。
U-Net 原有研究使用交叉熵作为损失函数不能真实地表述生成数据与标签图像之间的对应重合关系。因此,本文中使用了图像分割领域更为常用的Dice 作为损失函数,Dice coefficient 可以评估两个样本的相似性,用于衡量两个样本的重叠程度,比交叉熵作为图像分割的损失函数更合适。训练过程中Dice损失函数定义如下:

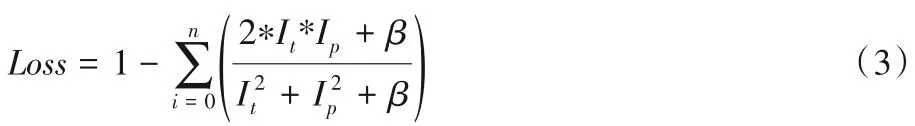
式中:Ip表示训练过程中神经网络的输出图像;It表示对应的标签;Loss表示损失;i,j表示像素点的坐标位置。式(3)中,i=0,n表示参与计算的图像数量,β表示一个非0 常数。因为在实际情况中偶然会发生突然喷射后短暂的一两个数据帧中无水流,即可能存在Ip和It同时为零的情况,所以为了保证训练的继续进行,必须加上一个非零常量β,保证分母部分不为零。通过多次实验可知,β取值为1×10-5时可以取得良好的分割效果。从式(3)也可以看出,当标签和实际的预测值越接近时损失越小。样本的水流分割结果如图3所示。

图3 不同样本的水流分割结果Fig.3 Water flow segmentation results of different samples
2.2 形态流特征提取
目前,常用于视频异常检测的人工设计特征有纹理特征、颜色特征、光流特征、轨迹特征等。因为光流可以从时间域和空间域两个层面来准确刻画视频图像随时间的变化,相较于颜色特征和纹理特征等包含了更丰富的信息,所以现在的研究中普遍都采用了光流作为输入。本文也首先考虑了使用光流作为输入的特征,相邻两个数据帧原图和光流特征图像分别如图4、图5所示。

图4 两个相邻数据帧Fig.4 Two adjacent data frames

图5 光流计算结果Fig.5 Optical flow calculation result
如图5 所示,光流特征的计算结果很混乱,并不能看出水流在时间轴上的变化,也不能看出水流的空间形态。这是由光流特征本身的计算条件所限制的,即光流计算时假设了计算目标运动时缓慢的时间是短暂的,物体形变不大[3-4,18],但是水流形态时时刻刻都在发生变化,且变化程度相对较大。因此需要新的特征表示方法(形态流)来描述水流形态的变化。因为本文是通过水流形态在时间轴上的变化来表示视频中水流的变化,所以取名为形态流。
形态流特征的提取,也借鉴了光流描述视频数据变化的思路。形态流特征和光流一样都是从时间域和空间域两个层面来描述视频数据变化。不同之处在于,形态流特征考虑了人工进行异常数据判断过程,从水流形态的变化上来刻画数据。形态流特征提取的依据在于工业生产中专业人员根据监控视频中水流形态的变化过程来判别水流是否异常,而水流的形态体现在图像中就是目标区域(水流区域)像素点的位置分布。一个视频序列的形态流特征提取流程如下:设原有的视频序列为I0,I1,…,In,则经过分割后的视频图像序列为-I0,其中I0表示第一帧,In表示最后一帧。虽然水流的形态是不固定的,在短时间内也会发生形态上的变化,但是在短时间内的同一场景下正常的水流数据形态变化并不剧烈。也就是说,在正常数据中相邻的两个数据帧,形态变化较大,但是在分割后的数据上相邻两帧之间对应位置上还是有很大一部分像素点是重合的。所以如果是正常的水流数据,经过分割后相邻两个数据帧相异部分较少,而在包含异常数据帧的数据中相邻两帧之间的相异部分则很大,这也为从时间轴上描述水流形态的变化提供了基础。
数据除了在时间维度上有形态变化的信息之外,其自身也包含了丰富的形态信息。为了充分利用时域和空间域信息,首先对水流数据进行分割去除背景得到感兴趣的水流形态区域;然后,从第一帧开始获取两相邻数据帧,对两帧图像按位求异或就可以得到两个图像形态在时域上的变化信息。在空间维度上,本文直接使用分割后得到的水流数据来描述水流形态,因此在求取异或之后将当前的数据帧拼接在右侧。直接拼接在右侧不采用梯形、三角形等方式拼接是为了保证图像中水流形态不产生变化。按照上述方法,逐帧计算,直到视频数据的最后一帧。形态流特征如图6所示。
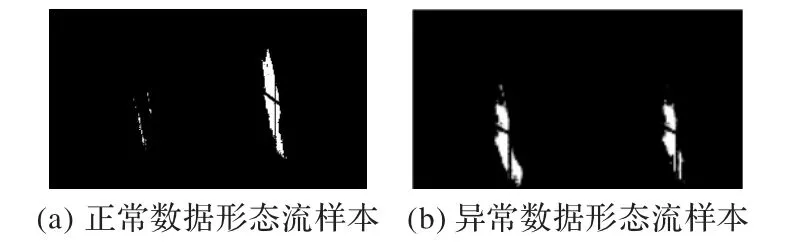
图6 形态流样本Fig.6 Samples of shape flow
如图6 所示,单个样本中,从左往右看,形态流特征图左半部分代表数据在时间轴上的变化,右半部分代表当前水流形态。由上述描述可知,左半部分由相邻两个数据帧之间求取异或得到,同时正常数据相邻两帧之间存在许多重合的像素点,因此正常数据左半部分只有少量相异的像素点(图中白色部分),异常数据左半部分相异的像素点相对较多。
3 水流异常检测神经网络模型
本文中水流异常检测的神经网包括三个部分的神经网络:生成器、判别器和分辨网络。在训练阶段需要同时用到上述的三个网络,而在实际使用和预测阶段则只需要用到生成器和分辨网络两个部分。在实验中,通过生成对抗网络(Generative Adversarial Network,GAN)的方法进行训练,生成器部分为重建网络,负责学习正常数据形态流的重建表示f1(x);判别器负责判别生成数据的真伪;分辨网络则是学习生成器生成数据和原始输入数据之间的L2 距离最小化表示f3(x)。其潜在的原理是f1(x)和f3(x)都是通过对正常数据的学习得到的,因此它只适用于正常数据。在测试时如果遇到异常数据,生成器部分的重建网络得到重建数据就会跟原来的数据产生较大的误差,分辨网络就会输出一个较大的值。测试时如果遇到的是正常数据,那么数据的重建质量就会很高,分辨网络也会相应输出一个很小的值。因此判别数据是否异常就可以直接根据分辨网络输出的数据大小来判定。判别器学习到的映射f2(x),则是为了保证生成器的重建质量,因为生成器重建的效果越好,异常的判别就会越准确。整体的水流异常检测神经网络结构如图7 所示,归一化层(Batch Normalization,BN)是残差结构的一部分。
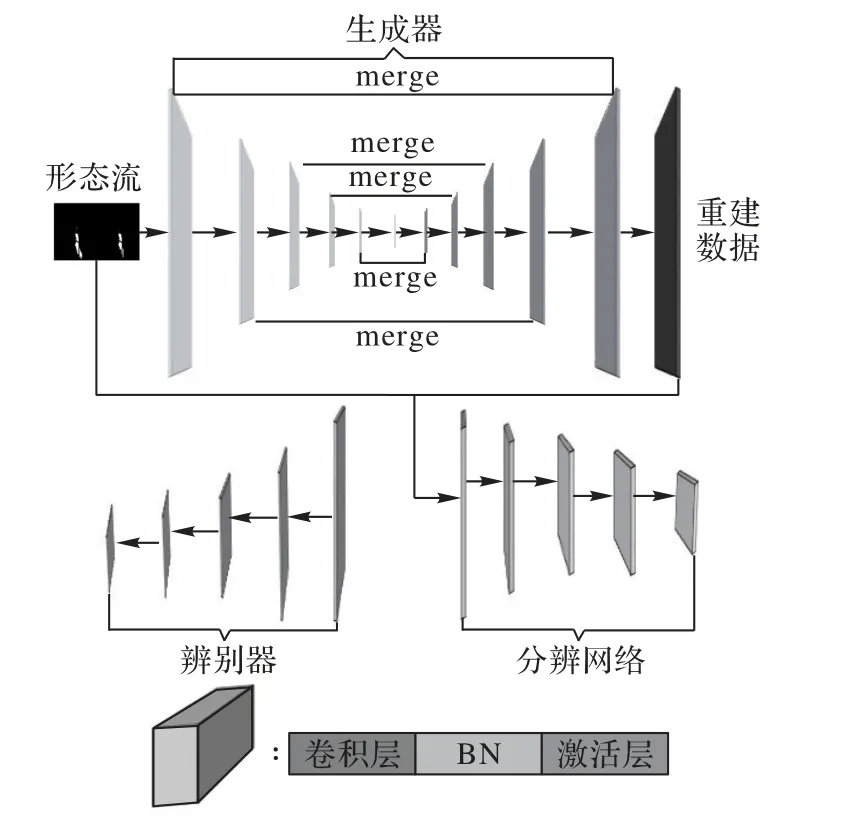
图7 水流异常检测神经网络结构Fig.7 Structure of neural network for water flow anomaly detection
3.1 生成器
生成器用于重建输入的形态流特征,它的重建数据与前文所述的基于重建的方法[8]有本质上的区别。基于重建的方法,是对整个视频数据进行学习,从而构建重建字典,字典中的内容是学习到的特征。本文的重建网络则是通过对形态流的特征进行学习得到重建映射f1(x)。
GANomaly 神经网络的生成器采用的是全卷积神经网络[19]的结构。FCN的神经网络只有使用下采样的编码模块和使用上采样的解码模块两种模块,而没有如图8 所示的融合层(merge),因此不能学习到图像更深层次的潜在特征。使用普通的卷积网络,存在梯度消失和弥散的问题,因此网络结构层数不能太深,这一点也限制了FCN 对数据特征的提取能力。本文将神经网络改为残差网络的模式,可以加深网络的层数,进一步加强生成器对数据潜在特征的提取能力[20]。从文献[10]中可知,充分利用融合模块可以提取到图像的深层次信息,学习到更强的重建映射。如图8 所示,本文在增加融合层(merge)的基础上,将原始的卷积层改为了残差块。每一个残差块由一个卷积层、一个BN[21]层以及激活层构成。
对于重建网络的损失函数,目前大多是将特征匹配损失应用在异常检测中[22]。由文献[23]可知,特征匹配减少,GAN训练就会不稳定。因此本文根据特征匹配的原则来定义损失函数。实际计算中首先令f为一个函数,该函数是判别器的中间层输出,然后计算输入x和生成器的输出G(x)之间的L2距离,具体如式(4)所示。
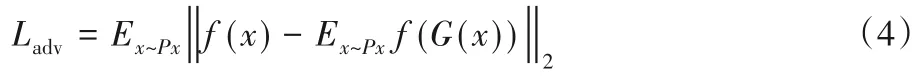
式中:Px为数据分布;Ladv代表生成器的损失。
3.2 分辨网络
分辨网络在训练过程中,最小化生成器生成的数据G(x)和原始输入数据x(形态流)之间的L2 距离。本文算法与GANomaly的不同之处在于,原分辨网络与生成器的编码部分拥有相同的结构,而本文中不要求两者相同。改进的原因在于要保证GAN 训练过程比较稳定,生成器网络层数就不能设计得太深,否则会出现梯度不稳定的问题[21]。因此GANomaly原有的分辨网络层数不深,也就导致了网络的分辨能力不强。本文的分辨网络与生成器编码部分不同,为了提高分辨网络的分辨能力加深了网络的层数。同时,残差网络将梯度变化由原来的乘法运算优化为加法运算,能够解决神经网络训练过程中梯度不稳定的问题,因此本文中使用了残差网络的结构来加深网络的深度。设形态流的数据分布为Px,则改进后的神经网络损失函数如式(5)所示。
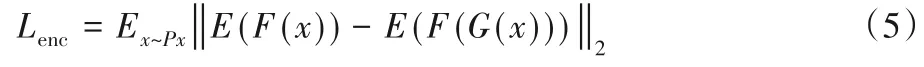
式中:F(x)为形态数据输入分辨网络得到的特征;F(G(x))为生成器的输出G(x)输入分辨网络得到的特征。
3.3 判别器
判别器是生成对抗网络的重要组成部分,负责判别生成器生成数据的真伪。即:生成器负责生成重建数据,判别器则负责判别生成的数据与原来的数据是否一致,并将判别的结果返回给生成器,以便监督生成器生成和原图更加一致的数据。在损失函数方面,直接使用了文献[24-25]的损失函数,如式(6)所示。

其中x、G(x)代表不同输入数据。
3.4 数据训练与异常检测
训练时,首先将形态流特征输入生成器中进行数据重建,然后由判别器判别真伪;然后,同时将形态流和判别器输出送到分辨网络中进行训练。训练过程中使用的损失函数为上述三个部分神经网络损失函数的结合,其具体表达式如式(7)所示。

训练阶段只用到了正常数据的原因有两个:其一是异常偶有发生且不是固定的,因此难以完全列举:其二是本文中训练网络是为了得到f1(x)和f3(x)两个映射,最终是根据是否偏离正常数据的高斯模型来判定是否异常。
在进行异常检测时,需要提前训练好分割网络、生成器以及分辨网络。首先,需要将原始的视频数据送入分割网络分割出水流;然后,再按照前文所述的步骤提取形态流特征x;接着,将数据输入生成器中得到重建结果G(x);最后,将x输入分辨网络获取输出的距离值,并将距离值输入建立好的高斯模型得到输出异常的概率值,当输出的概率p<ε(高斯模型的阈值)时判定该数据异常,当输出的概率值p≥ε时判定数据为正常数据。相较于GANomaly 中直接通过输出的距离阈值来判别是否异常,本文算法更具有统计意义,高斯模型的计算式如式(8)所示。
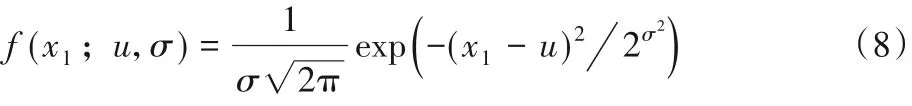
式中:x1代表输入的距离值;σ代表统计的方差;u代表统计的均值。
高斯模型的阈值ε通过多次计算F1得分得到,其计算式如式(9)所示。

式中:真正例(True Positive,TP)代表异常样本被检测为异常;假正例(False Positive,FP)代表正常的样本被检测为异常;假负例(False Negative,FN)代表异常样本被检测为正常样本。从上述计算式可以看出,FP和FN两者越接近于0,F1得分越高,即误检和漏检越少,F1值越接近于1。在选择阈值ε时,通过多次随机设定ε的值然后计算其F1得分,最终选取得分最高的值。
4 实验与结果分析
根据实验数据的不同可以将实验分为两个大类:一类是本文实地采集和制作的相关数据集上的实验;另一类是在公共数据集上的实验。在实体采集和制作的数据集上的实验包括:1)水流分割实验、形态流的验证实验;2)针对水流异常数据点检测的实验。由于目前没有水流异常检测的相关研究,所以也没有相关水流公共数据集。所以本文为了验证改进后的GANomaly 算法,在异常数据检测的公共数据集上对改进后的算法和其他相关算法进行了对比实验。实验使用的平台为Linux 服务器(Linux 8.0),内存为1 TB,训练和测试都使用了两块显存为12 GB 的Titan v 图形处理器(Graphics Processing Unit,GPU)。
4.1 评价指标
评价指标中常用的方法是通过概率值来评价一个模型的好坏,其中最常用的是精度(Precision,P),计算方法如式(10)所示。
2018年9月28日,是孔子诞辰2569周年的日子。在这个特殊的日子里,为弘扬传统文化,践行“用中和思想,做德能教育”的办学理念,培养德能兼修、知行合一的中和英才,山西省孝义市中和路小学全体师生相聚操场举行“祭先师孔圣、承尊师传统、育得能英才”为主题的纪念孔子诞辰2569周年暨新生开笔典礼活动(以下简称祭孔活动)。孝义市教育局政教科科长杨淑琴,山西九五新国学学院常务院长、山西家长学校讲师团高级讲师吕菊花,山西日报《青少年日记》杂志社编辑杨晓雪参加祭孔典礼。

4.2 实体采集和制作的数据集上的实验
4.2.1 数据集介绍
实体采集和制作的数据集是通过在石油工厂实地采集获得,异常的样本也是有长期工作经验的专家挑选出来的,专家们判别一个片段是否异常的依据是水流在时间轴上变化的剧烈程度。如图2 所示,数据的左上角还有采集时间。用于实验验证的数据集共包含7 个场景,其中50 000 张训练数据、2 000张测试数据。训练数据全部是正常样本,测试数据中包含1 000张正常数据和1 000张异常数据。正常的数据样本片段如图8 所示,异常图像相较于正常图像的前后两帧数据之间的变化较大,具体如图9所示。

图8 正常样本Fig.8 Normal samples

图9 异常样本Fig.9 Abnormal samples
4.2.2 水流分割实验
特征提取是异常检测的重要内容,水流分割是特征提取的重要一环。本文中通过U-Net 来进行水流分割,常用评判分割结果好坏的指标是交并比(Intersection Over Union,IOU)。为了确定式(3)中β的取值,本文在U-Net 上进行了多次实验,实验结果如表1所示。
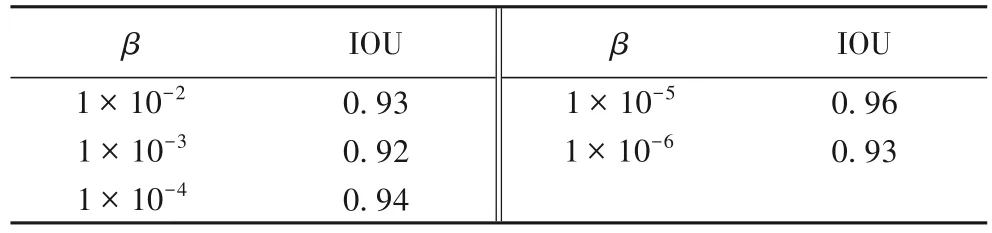
表1 U-Net中不同β值下的IOU对比结果Tab.1 Comparison results of IOU at different β values in U-Net
如表1 所示,β取值为1×10-5时可以获得更好的分割效果。β取值为1×10-5时,样本图像和分割结果如图3所示。
4.2.3 形态流特征验证实验
该实验用于验证形态流特征是否有效,参与对比的特征为原图、分割图像、光流、形态流。将上述4 种特征分别作为输入在相同的模型中进行训练和测试,然后取多次实验的平均值作为最后结果,以此来验证形态流特征在水流异常检测任务中的优越性。GANomaly 和本文算法都使用上述四种特征作为输入进行了实验验证,本文算法的实验结果如表2 所示,GANomaly上的实验结果如表3所示。

表2 本文算法采用不同特征作为输入的检测精度对比 单位:%Tab.2 Detection precision comparison of proposed algorithm with different features as input unit:%

表3 GANomaly采用不同特征作为输入的检测精度对比 单位:%Tab.3 Detection precision comparison of GANomaly with different features as input unit:%
如表2~3 所示,无论是在GANomaly 上还是本文算法上,新提出的形态流相较于其他三种特征都取得了更好的效果。光流特征由于其自身条件的限制,不适用于水流数据的特征提取,因此取得了最差的结果。原始数据和分割后的数据相比,原始数据存在更多背景噪声的影响,所以它的精度相较分割后的数据较低;同时由于原始数据和分割后的数据不能体现水流数据形态在时间轴上的变化,而形态流同时具备时间域的变化信息和本身的空间信息,所以在水流数据的异常检测上取得了更好的效果。
从表2~3 的对比可以看出,本文算法在四种特征上相较于原始的GANomaly 检测精度皆有提升。由此可见,本文所提出的形态流特征,能够适用于水流异常检测,相较于其他特征有更好的性能表现。
4.2.4 水流异常检测实验
为了验证本文算法在水流异常检测任务中的优越性能,在水流数据集中将本文算法与其他的相关异常检测算法进行了对比验证。为了得到最好的训练结果,实验中对学习率等参数进行了多次的调整和训练,由于这不是本文的研究重点所以没有过多地介绍。每次训练迭代200 次后精度不再提升即停止训练。由于GAN 训练的不稳定性,所以在之前多次训练的情况下取最优结果的参数,又进行了五次的训练,并取平均值作为最终结果。本文算法最终选取的学习率为0.000 01,batchsize 设置为64,输入的图像大小为最低高清图像标准720×1280。参与对比的算法包括本文改进的算法、GANomaly[11]、EGBAD(Efficient GAN-Based Anomaly Detection)[12]、AnoGAN(Anomaly Detection with Generative Adversarial Network)[13]和孤立森林[26],这五种算法的检测精度如表4所示。
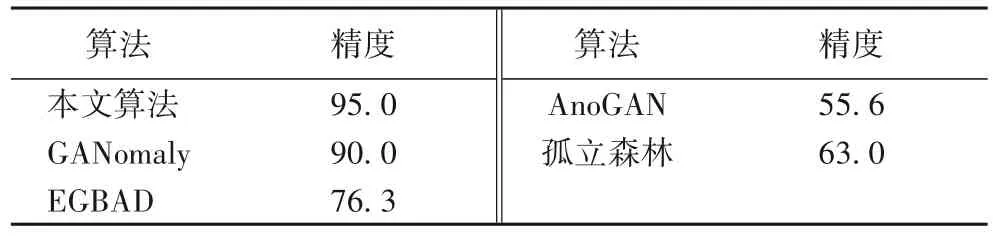
表4 不同算法的水流异常检测精度对比 单位:%Tab.4 Comparison of water flow anomaly detection precision of different algorithms unit:%
从表4 中可以看出,本文所提算法的检测精度明显高于EGBAD[12]、AnoGAN[13]、孤立森林这几种算法,其检测精度达到了95.0%,相较于GANomaly 算法提升了5 个百分点。时间效率方面,同时使用两块Titan v 的GPU 时,可以达到每秒18 帧的检测速度。本文算法能适用于如图10 所示的不同场景,也能克服如图10(d)所示的雾气干扰,孤立森林和EGBAD[12]、AnoGAN[13]等算法 在实验 中均不 能检测到如图10(d)所示的带有雾气的异常数据帧。

图10 检测到的异常片段Fig.10 Anomalies detected
4.3 公共数据集上的实验
4.3.1 常用公共数据集介绍
异常事件检测常用公共数据集是mnist 和cifar10。这两个数据集原本是用来作为图像分类的数据,但是由于异常检测也可以看作二分类问题,即将数据视为正常和异常两个类别,所以不少研究者也用它们来做异常数据检测的研究[11-13]。在使用这两个数据集时,由于进行的是无监督训练,异常数据是不参与训练过程的,所以在训练之前需要将异常的类别选择好。例如,本文将0 定义为异常类型,那么0 就不参与训练只参与测试,1~9参与训练。
4.3.2 公共数据集上不同算法对比
该部分的实验设计是为了验证本文算法的通用性,即本文改进后的神经网络是否可以适用于不同的数据集,同时也可以从侧面说明为何本文算法在水流异常检测中性能表现突出。在mnist数据集和cifar10数据集上进行验证,参与对比的算法有GANomaly[11]、EGBAD[12]、AnoGAN[13],结果如图11所示。
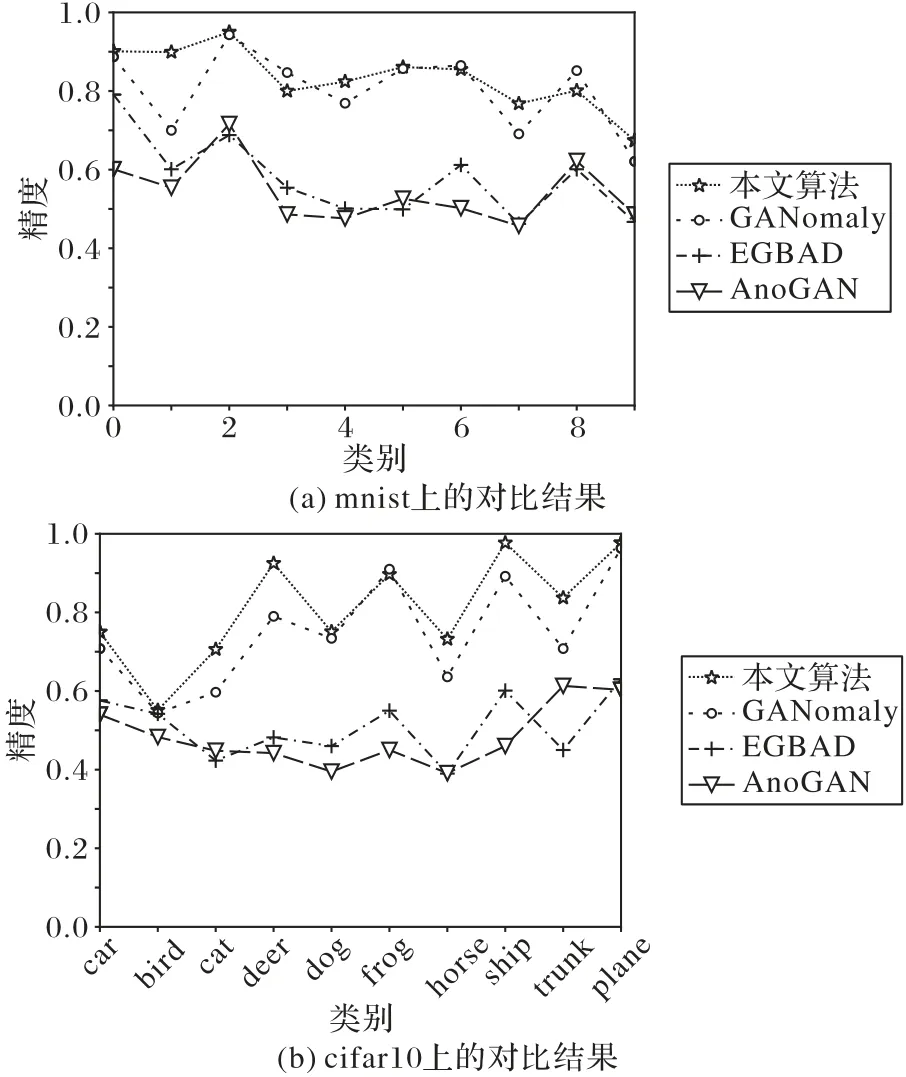
图11 公共数据集上不同算法的对比结果Fig.11 Comparison results of different algorithms on public datasets
相较于用于对比的三个算法中表现最佳的GANomaly 算法,本文所提算法生成器和分辨网络都改为残差网络结构,网络深度增加了2 倍,同时加入了特征融合层使得网络的特征提取和分辨能力大幅提高。实验过程中神经网络学习率设置为0.000 1,batchsize 设置为64,输入图像的大小设置为640×640。
如图11 所示,两个数据集共20 个类别中有8 个类别本文改进后的算法与GANomaly 算法持平,10 个类别的精度高于原来的算法,只有在mnist 数据集中3 和8 这两个类别精度低于GANomaly算法。类别3和8上,本文算法相对于GANomaly算法低了5 个百分点左右,其可能的原因在于3 和8 的右侧很像,本文的神经网络可能对于具有左右两部分相似的数据不友好。这一点可以从1 和7 侧面印证,从上往下看1 和7 具有一定相似性,所以原来的GANomaly 区分不出来,而本文改进后的神经网络学习到了数字左侧和右侧的内容,而1和7从左往右看差别比较大,所以在类别1和7上改进后的算法检测精度提升了10 个百分点以上。EGBAD[25]、AnoGAN[1]这两个算法的精度相较于GANomaly 和本文改进的算法在所有类别上的精度都较低。
5 结语
本文从实际出发,通过对水流的异常检测解决了石油生成过程中的污染气体监测问题。由于异常偶有发生且表现形式不固定,无法列举所有异常情况,所以异常数据的获取困难。为解决这个问题,本文采用了无监督学习的方法,在网络模型训练过程中模型通过正常数据隐式地获取和学习异常。水流异常检测任务中本文算法精度可以达到95.0%,利用两块Titan v的GPU同时计算可以达到18 frame/s的处理速度,满足实际需求。在算法层面提出了形态流特征,能准确刻画水流形态的快速变化。在mnist 数据集中异常类别设置为1 时,本文算法检测精度达到了90.1%,相较于GANomaly 提高了19 个百分点。本文改进的神经网络算法在公共数据集中有50%的类别优于原始算法,40%和原始算法持平,但是依然存在10%的类别低于原始算法。由实验分析可知,本文的神经网络可能对左右对称的数据不友好,但是由于缺乏类似的样本和数据因此无法进行进一步的实验和改进。同时本文只根据前后两帧的形态变化来提取特征,下一步可以考虑结合连续多帧的形态变化来提升精度。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
文苑(2020年6期)2020-06-22
作文周刊·小学四年级版(2019年16期)2019-06-12
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
火花(2016年7期)2016-02-27
读者(2015年9期)2015-05-04
西南学林(2011年0期)2011-11-12
