
基于激光雷达与毫米波雷达融合的车辆目标检测算法
2021-07-14 08:13刘明亮蔡英凤
江苏大学学报(自然科学版) 2021年4期
王 海,刘明亮,蔡英凤,陈 龙
(1.江苏大学 汽车与交通工程学院,江苏 镇江 212013;2.镇江市江苏大学工程技术研究院,江苏 镇江 212013;3.江苏大学 汽车工程研究院,江苏 镇江 212013)
无人驾驶主要由环境感知、路径规划和决策控制等部分组成.环境感知提供的信息越准确对后续步骤越有利,环境感知的主要任务是识别无人车周边障碍物信息,目标检测是其重要组成部分,对无人车自主行驶至关重要.
目前无人车目标检测所使用的传感器主要包括摄像机、激光雷达、毫米波雷达和超声波雷达等.每种类型传感器都有各自优缺点,摄像头传感器成本较低,可以获得目标的形状与色彩.随着计算机视觉技术的发展,将卷积神经网络(convolutional neural networks,CNN)应用在图像检测上已经较为普遍,且检测效果显著,比如YOLO(you only look once)[1]、SSD(single shot multibox detector)[2]、Fast R-CNN(fast region-CNN)系列[3],与此同时,将基于卷积神经网络的检测算法应用于工程实践也取得了较好的效果[4].然而,由于摄像头缺少深度信息,且受外界光照条件影响较大,上述方法仅可以得到目标的2D检测框,无法探测目标距离信息.激光雷达的引入可以弥补深度信息的缺失,激光雷达具有可以获得距离信息和目标形状、探测距离较远、受外界条件影响较小等优点.因此,基于激光雷达点云的目标检测算法也一直是研究热点.常用的传统检测算法是基于原始点云建立栅格地图并去除地面点[5],对障碍物点云进行栅格聚类之后使用基于几何形状的目标识别分类,但该方法受限于无人车周围环境,当出现灌木丛、地面崎岖不平时,会出现较大误检.伴随着深度学习的不断发展,卷积神经网络也广泛应用于三维点云数据上,比如ZHOU Y.等[6]建立体素网络结构,将点云划分为三维体素再进行特征提取,但此方法需要较高的计算量,且点云是稀疏三维数据,其中存在较多无效空间点.QI C.R.等[7-8]依据点云的无序性和变换不变性的特征设计网络模型,网络以点云为输入并输出点云类别标签,然而该网络仅能处理局部小规模点云,难以在自动驾驶等大规模点云场景上应用.
目前,多传感器融合的目标检测算法渐渐增多,譬如基于相机与激光雷达的检测方案,具有代表性的如F-PointNet[9],该方法设计了视锥体,主体流程首先通过图像检测方法获取目标2D检测框;之后通过传感器标定,将2D检测框投影至点云生成视锥体;最后通过PointNet[7-8〗网络生成精确目标边界框.但该方法检测结果依赖于第1步2D检测框的生成.CHEN X.Z.等[10]提出1个多视角的3D目标识别网络,将点云的俯视图和前视图与摄像头信息作为网络输入融合多视角特征完成目标检测,但该方法输入信息较多,会造成网络运行速度较慢、实时性较差.笔者提出将毫米波雷达和激光雷达数据融合的算法,首先将点云的高度信息做下采样处理并加入点云强度信息,常见的特征提取网络由于不断下采样导致车辆的有效信息不断减少,因此引入特征金字塔结构将高层特征图与低层特征图相结合,丰富最终特征层信息;之后根据毫米波雷达数据生成的预瞄框提供目标感兴趣区域实现目标快速定位;最后使用多任务分类回归网络实现目标检测.在Nuscenes数据集上进行训练及验证,同时将模型移入实车平台进行验证.
1 多传感器融合算法设计
激光雷达数据每帧大约有130万个点,巨大的数据量为无人车描述周边场景提供了帮助,通过感知算法可有效提取无人车周边障碍物类型和距离信息,然而对巨大数据量的处理成为一个难题.针对上述问题,一种做法是使用体素化形成3D体素网格,但3维卷积计算代价昂贵,且激光雷达点云数据非常稀疏,以至于大多数体素网格单元都是空值,增加了网络不必要的计算量.另一种做法是将三维点云降为二维数据,通常将点云的x轴和反射强度转化为颜色通道生成点云的前视图,但此方法易丢失度量信息,且无法解决目标遮挡问题.本研究通过将点云转化为鸟瞰图(bird′s eye view,BEV)视角,解决目标遮挡问题,且保留车辆目标特征信息;之后通过特征提取网络和毫米波雷达数据生成的预瞄框提取目标感兴趣区域;再由多任务分类回归网络确定目标精确位置.
1.1 模型设计
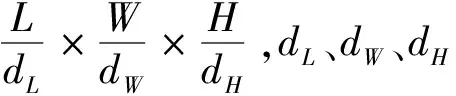
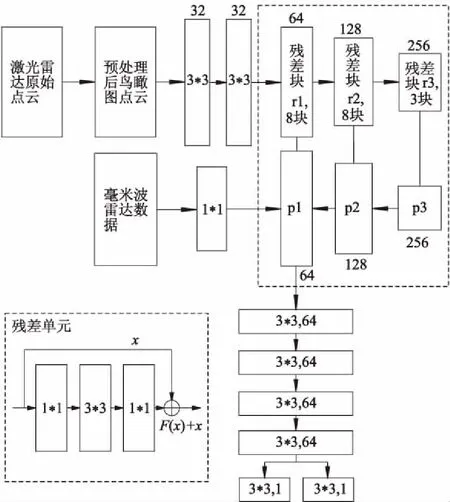
图1 模型网络结构图
1.2 特征提取网络
1.2.1残差块
目前在深度学习领域,特征提取一般会采用直线型的CNN网络,譬如VGG-Net[11],GoogleNet[12],AlexNet[13]等等,这种直线型网络描述图像的能力随着卷积层数的增加而增加,但同时更深层的网络也会导致准确度出现饱和甚至下降现象,本研究使用ResNet[11]作为特征提取网络可以规避这一缺陷.
为避免因为不断堆叠的卷积层导致深层网络学习的特征出现退化,ResNet加入残差单元,即当输入x期望特征输出H(x)变为H(x)=F(x)+x,具体网络连接方式如图1所示.使用3个残差块组成特征提取网络,每个残差块内各包含3、8、8个残差单元,并且在残差学习单元的每层卷积使用量纲一化处理让训练数据有相同分布以加快模型的收敛速度.
1.2.2特征金字塔网络
通过残差卷积块提取的各层特征图大小不一,低层特征图语义信息较少,但目标位置较为精确;高层特征图语义信息多,但目标位置较为模糊.因此,引入特征金字塔[2]结构,通过将高层的特征层与低层相结合的方式,既避免了检测对象像素过小,也丰富了特征图的表达能力.
特征金字塔网络通过自左向右、自右向左和纵向连接的方法将特征图进行融合,以此获得1个可以准确描述目标位置,且语义信息较为丰富的融合特征图.自左向右的过程就是卷积网络的前向传播部分,在特征提取过程产生的特征图命名为r1、r2、r3.对右端的r3,进行卷积核为3*3、步长为1的卷积运算后得到特征金字塔的1层网络结构p3,之后采用上采样并通过纵向连接将原先的自左向右生成的特征图进行相加操作,即p3的上采样结果与对r2进行卷积为1*1、步长为1的卷积操作后的结果相加,然后进行卷积核为3*3、步长为1的卷积运算得到特征金字塔的第2层网络结构p2,依次类推得到p1.建立多尺度的特征图使金字塔每一层均可用于不同尺寸的目标检测.
1.3 预瞄框生成
利用毫米波雷达检测到的目标生成感兴趣区域,并为目标对象提供精确的深度和速度信息.由于激光点云每1帧检测范围内并不都是有效的检测区域,在BEV视角下存在较多无效检测区域,如果整体放入网络会造成网络速度下降,且一些无效点如路边灌木丛会造成误检,通过使用毫米波雷达数据可有效去除一些潜在噪点,加快网络运行速度.此外加入雷达数据也使得网络的输入更加多样性,获得更高的精度和可靠性.
通过激光雷达与毫米波雷达的坐标转换,可以粗略定位毫米波雷达探测对象在激光雷达坐标系下的大致位置,之后将数据点转为包围框形成感兴趣区域.采用LIU W.等[2]的方法设计包围框,对于每个雷达检测点生成不同尺寸和长宽比的包围框,设定的预瞄框大小对应真实世界的长度为3 m,预瞄框的长宽尺寸比例分别为1 ∶1、1 ∶2、2 ∶1,如图2所示.
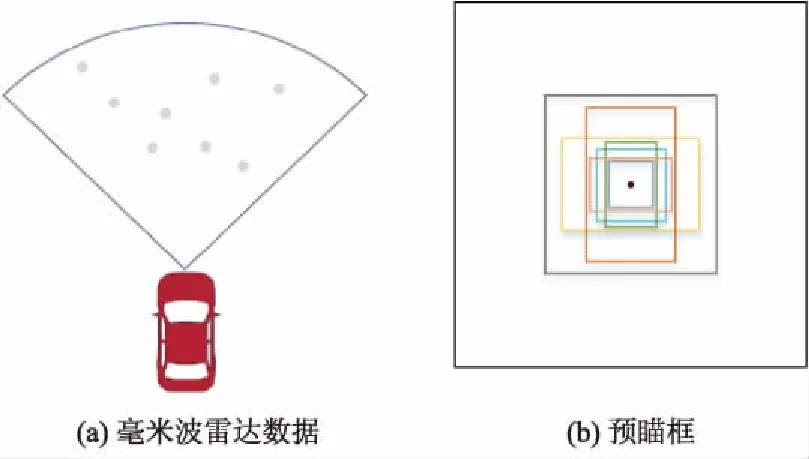
图2 毫米波雷达数据及预瞄框设置
1.4 多任务网络与损失函数设计
多任务网络主要由对象分类和方向定位组成.对象分类部分输出1通道特征图,方向定位任务分支输出6通道特征图,在多任务网络中,使用共享权重的方法降低网络参数数量.
在分类任务上仅预测车辆一类标签,类似于1个二分类问题.使用sigmoid激活函数计算分类的概率,并传递到损失函数计算损失值.在分类任务上设定网络的阈值为50%,即当预测框与真值框的交并比(IOU)大于50%时设定为正标签,小于50%时选取所有预测框与真值框交并比IOU最大值为正标签,其余为负标签.
由于检测目标相对较小,训练时易出现正负样本分布不均的情况,无法进一步提升网络精度.针对样本分布不均问题通过在交叉燏损失前加入参数α,交叉熵损失函数为
(1)
式中:pi为样本i预测为正的概率值;yi为样本i的标签,1为正标签,0为负标签.
然而α的引入不能解决难易样本的不平衡,在实际情况中大多数目标框都是易分样本,易分样本数量相对太多,最终会主导总损失函数.因此引入focal-loss损失函数[14]平衡难易样本,具体方式是对正样本损失函数加入(1-pi)ε,当p=0.9、ε=2时,正样本损失衰减了100倍,以此减小了样本分布不均问题.focal-loss函数为
(2)
假设回归网络预测的每个2D检测框用(xc,yc,w,l,θ)表示,如图3所示,其中:θ为偏转角,在[-π,π]之间;(xc,yc)为框的中心点c的坐标;w、l分别为框的宽度和长度尺寸.在计算部分,偏转角θ用cosθ、sinθ表示,通过计算BEV视角坐标系下的真值框与预测的2D检测框的差值获得dx、dy、dw、dl、dθ.
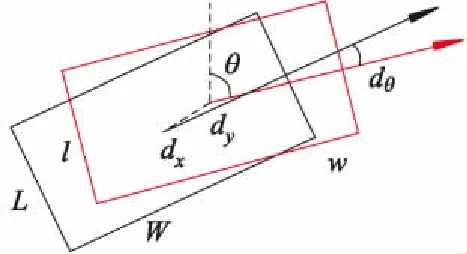
图3 2D检测框示意图
将SmoothL1损失函数用于2D检测框回归,回归参数(dx、dy、dw、dl、dθ)中dx、dy、dθ如图3所示,SmoothL1损失函数为
(3)
式中:xd为预测框与真值框之间的数值差值.
最终多任务网络的损失函数为
F=Ffocal-loss+FSmoothL1.
(4)
2 模型训练
2.1 数据集
训练使用的数据集为Nuscenes数据集.Nuscenes是1个自动驾驶数据集,具有较为完整的传感器套件的数据集,包含雷达、摄像机、激光雷达和GPS(global positioning system)共计12个传感器的数据集.Nuscenes检测类别共有23个类别,本研究仅对车辆类别检测,所以单独提取车辆类别进行网络的训练及验证.Nuscenes的数据集中的毫米波雷达共有5个,分别为前雷达、左前雷达、右前雷达、左后雷达和右后雷达,激光雷达仅有1个安装在车顶部.使用前雷达和车顶激光雷达数据组成本次模型训练数据集,共计2.3万个样本,按8 ∶2的比例对数据集进行划分,分别用于训练和测试.Nuscenes数据集示例1、2分别如图4、5所示.

图4 Nuscenes数据集示例1

图5 Nuscenes数据集示例2
2.2 训练过程与结果分析
试验平台主要参数如下:处理器为Inter(R)core(TM)i5-8600K,主频为3.60 GHz;内存为64 GB;显卡为NVIDIA GeForce GTX1080Ti.迭代训练40个训练周期,训练样本数为6个,初始学习率为0.001,每2 千次迭代以指数衰减,衰减指数为0.8.
将本算法与其他算法检测结果进行对比,结果如表1所示.其中:C1为单独使用激光雷达点云目标检测算法;C2为单独使用相机检测算法;C3为毫米波雷达与激光雷达融合的目标检测算法;AP为车辆类别的检测精度;AP50为IOU阈值设定在50%时的车辆类别的检测精度;AP75为IOU阈值设定在75%时的车辆类别的检测精度.

表1 本算法与其他算法检测结果对比
从表1可以看出:基于毫米波雷达与激光雷达融合的目标检测算法在运行时间上较单一的激光雷达检测算法有所增加,但仍能满足自动驾驶的实时性要求,由于毫米波雷达数据的加入,在IOU设置为50%时,检测精度上与单一相机算法相比提升1.9%,与激光雷达算法相比提升3.3%,检测精度可达60.5%,每帧点云检测耗时为35 ms.
根据距离划分了不同的检测范围,在IOU为50%的情况下以平均精度为评价指标,对本算法与单一传感器算法做了比较,结果如表2所示.其中:d1为检测距离0~20 m;d2为检测距离20~50 m;d3为检测距离50~80 m.
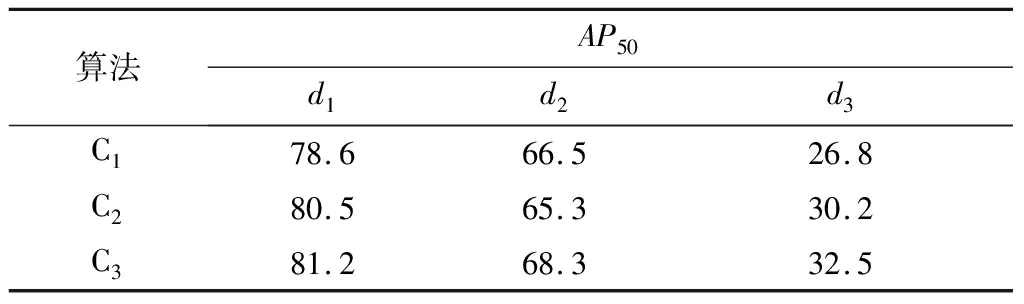
表2 不同检测距离下的检测精度对比 %
从表2可以看出:本算法在远距离范围(50~80 m)内比单一激光雷达检测算法提升5.7%,比单一相机检测算法提升2.3%.
部分试验场景的检测效果如图6-8所示.

图6 场景1的检测效果图

图7 场景2的检测效果图

图8 场景3的检测效果图
3 实车试验
将上面设计的检测算法移植入实车平台,实车试验和激光雷达安装平台如图9所示.

图9 实车试验和激光雷达安装平台
实车平台配置如下:工控机(显卡2080Ti);速腾P3激光雷达系统;德尔福毫米波雷达系统.
3.1 实车检测结果
实车软件平台为ROS系统(kinetic版本),算法语言为python.ROS系统的核心是一个分布式、低耦合的通讯机制,具有底层通信架构完善、模块化管理灵活和生态系统庞大的特点.将车辆检测模型移植入ROS系统,将底层激光雷达和毫米波雷达程序发布的消息传入自定义程序节点,再根据车辆检测模块对数据进行推理,最终实时发布检测结果,并通过ROS系统的可视化组件RVIZ可视化检测结果,最终检测效果如图10所示.其中,白色为标定后的毫米波雷达数据.由于毫米波雷达视场角较小,故对于超出视场角的障碍物仍使用单一激光雷达检测算法检测.
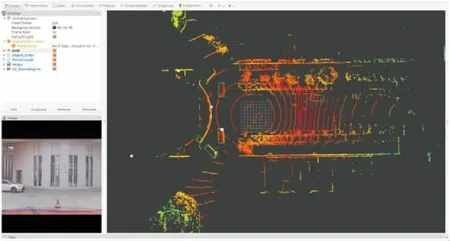
图10 检测效果图
4 结 论
提出了一种毫米波雷达与激光雷达融合的目标检测算法,该方法将庞大的激光雷达点云数据转化为鸟瞰图形式,设计了改进的特征金字塔结构,其结合了低层特征图目标定位准确和高层特征图语义信息丰富的优势,加入毫米波雷达数据点完成对目标的感兴趣区域提取;最后使用分类回归网络将感兴趣区域特征细粒化为2D目标框完成检测任务.在离线数据集和实车试验上,该网络在保证检测精度的前提下,检测速度可满足智能驾驶车辆对实时性的要求,具有实用价值.
猜你喜欢
北京测绘(2022年5期)2022-11-22
汽车实用技术(2022年19期)2022-10-19
北京航空航天大学学报(2021年9期)2021-11-02
内燃机与配件(2021年11期)2021-09-10
汽车观察(2021年8期)2021-09-01
内燃机与配件(2020年20期)2020-09-10
电子制作(2019年11期)2019-07-04
中国交通信息化(2019年1期)2019-03-26
电子制作(2018年16期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
