
基于Python 的文本数据增强系统设计与实现
2021-07-30 08:15韩会珍刘立波
宁夏工程技术 2021年2期
韩会珍,刘立波
(宁夏大学 信息工程学院,宁夏 银川 750021)
近年来,人工智能正逐渐改变着世界,而自然语言处理已成为计算机科学与人工智能领域内一个重要方向,在各个行业应用越来越广泛[1—2]。随着深度学习的出现和计算能力的提升,自然语言处理中情感分析和主题分类等文本分类任务都取得了很高的准确性,但高性能往往取决于训练数据的大小和质量[3],文本数据的收集往往是十分困难的,文本增强技术的出现很好地解决了这类问题。
在实际的文本数据收集中,正常文本与敏感文本的数量很容易失衡,但又要求训练出的模型能够召回较为全面的敏感文本[4—6]。这就需要文本“数据增强”,来扩展敏感文本数量,让数据更丰富。传统文本数据增强方法中,同义词替换(SR)方法是对文本中的一些词语进行替换来完成数据增强,方式实现较为简单,但生成的文本与原文本相似度太高。采用VAEHD 文本生成模型可以学习文本中的潜在性解释,生成具有特定情感属性的文本[7]。但是该模型实现过程较为繁琐,且需要额外的数据。本文采用一种简单文本增强(EDA)方法,不需要额外的数据,而且同义词替换、随机交换、随机插入、随机删除4 种方式的结合能更好地扩充语义,实现起来也较为简单。因此,依据实际需求,首先对文本进行预处理,以处理乱码、换行符冗余等问题,然后再利用EDA 方法进行文本数据增强。采用Python 语言结合Flask 框架设计实现了Web 网页版单文本和批量文本数据增强系统[8—12],对于处理少样本场景下样本不均衡性、数据量不足易导致模型过拟合有较好的应用价值。
1 文本数据收集
该系统开发和测试均采用实验室构建的枸杞虫害文本描述数据集,包含大青叶蝉、负泥虫、木虱等17种常见枸杞虫害。由于该数据集的文本描述的是人工撰写,耗时耗力,搜集到各类枸杞虫害的描述信息有限,因此在构建数据集时,有的虫害种类文本描述数量过少,有的虫害种类文本描述数量较多,造成了数据集的样本不均衡,且枸杞虫害数据集文本总量只有1 670,对模型训练来说数据量不足,所以选取该数据集作为该文本数据增强系统的训练和测试数据。
2 系统设计思路
2.1 功能模块设计
基于Python 设计的文本数据增强系统,以实验构建的样本不均衡且数据量不足的枸杞虫害文本描述数据集进行数据增强,前端界面用Flask 框架结合Python 语言响应处理实现Web 网页交互[13]。该系统主要分为预处理模块、单文本数据增强模块、批量文本数据增强模块。具体功能模块见图1。
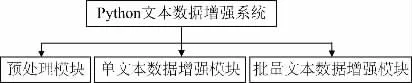
图1 文本数据增强系统功能模块
2.2 系统流程设计
文本数据增强系统流程图见图2。

图2 文本数据增强流程图
该系统流程设计主要包含:①文本数据预处理;②单文本或批量文本数据增强;③设置文本原路径和增强后文本路径;④EDA 中各增强方式比例设置;⑤保存增强后生成的文本。
文本数据增强是对文本数据进行扩充。该系统采用改进的EDA 文本数据增强技术,其文本数据增强4 种方式含义见表1。

表1 文本数据增强4 种方式含义
3 系统实现
3.1 功能实现
该系统主要采用实验室构建的少样本枸杞虫害文本描述数据集进行文本预处理及数据增强操作。
3.1.1 文本预处理实现 由于撰写文本时,编码格式不同,操作方式有误,可能会导致文本中出现中英文夹杂、乱码、换行符冗余等文本不规范问题,通过文本预处理技术实现文本的规范化很有必要。
本文通过hanzi API 实现了对中文文本字符的替换和删除,并通过re 正则表达式解决了删除空行、乱码等问题,实现了文本数据的规范化。
3.1.2 文本数据增强实现 针对单文本和批量文本的数据增强,首先通过os.path.isfile(filename)函数判断要增强的是单个文本还是批量文本。对单个文本直接进行数据增强;而批量文本则先利用函数os.listdir(filename)获取输入文件夹路径下的所有文本文件,再用循环语句分别对单个文本进行数据增强。批量处理可以选择输入包含100,200,500 等多个文本的文件夹,系统会根据获取路径对文本进行增强操作。
在数据增强过程中,首先,获取需要增强的文本原路径和增强后的保存路径;然后,通过stop words list 过滤掉一些出现过于频繁但实际意义不大的词来对文本进行清理,利用EDA 技术中synonym_replacement()函 数、random_deletion()函数、random_swap()函数、random_insertion()函数,分别对文本数据进行同义词替换、随机删除、随机交换、随机插入来增强文本数据;其次,设置num_aug 参数确定要生成文本的数量,即文本数据增强倍数,设置4 种数据增强方式的参数值范围为0~1;最后,将增强后的文本数据写入保存路径下的新建文件夹。
3.2 关键技术
Python 语言是近年来人工智能编程方向潮流的计算机编程语言。Flask 是一个轻量级的Web 框架,简单易上手,灵活小巧。Flask 中的route 路径及各种封装函数,使用方便快捷,能快速高效地开发该系统。
该系统采用Python 为主要开发工具,Flask 框架进行Web 端界面布局设计,搭建系统环境。之后通过Flask 框架将HTML 页面保存的表单数据提交到Python 后台进行响应处理,完成数据增强操作。
环境搭建所需注意:①安装nltk 自然语言处理工具包pip install -U nltk;②下载WordNet,将压缩包放入C:UsersPublic.DESKTOPPUC4DFJAppDataRoaming ltk_datacorpora,并解压在该文件夹内。
4 系统测试
4.1 系统界面
该系统以Flask 框架结合HTML 设计编写简单的Web 操作界面,采用实验室构建的枸杞虫害文本描述数据集进行文本数据增强。该系统界面包含文本预处理页面和文本数据增强页面,分别见图3 和图4。
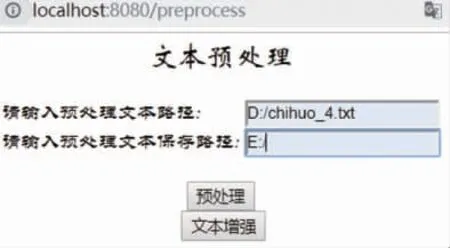
图3 文本预处理界面

图4 文本数据增强界面
图4 中生成数量表示一个原句子生成多少个新句子,即单个文本数据增强4 倍,生成后文本数量共5 句。同义替换比例、随机插入比例、随机交换比例、随机删除比例设置参数值为0.1。
4.2 文本数据增强实现界面
该系统测试时,分别对单个文本和批量文本进行数据增强操作。原始单文本和增强后的文本效果见图5 和图6。图5 是格式不规范的单个文本,图6是5 倍增强后生成的文本。

图5 单个原文本界面

图6 单文本增强后的界面
批量原文本和增强后的文本见图7 和图8。图7 是原文件夹里的所有文本,图8 是5 倍增强后生成的所有的文本。
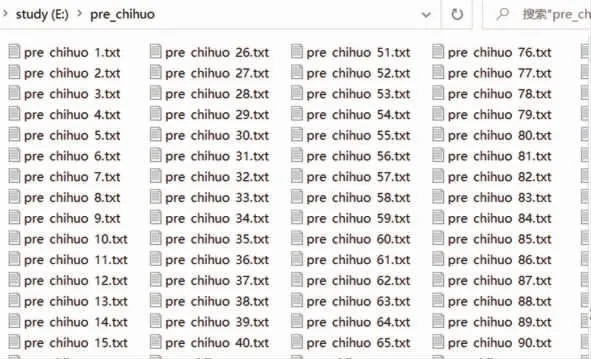
图7 批量原文本的界面
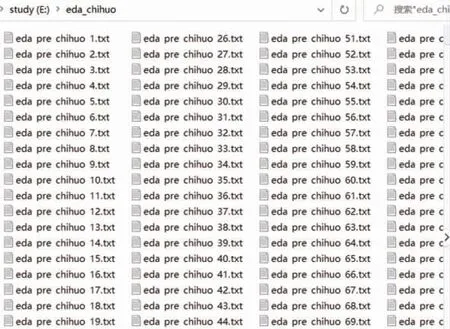
图8 批量文本增强后的界面
4.3 文本增强效果分析
为体现该文本数据增强系统的鲁棒性及有效性,该实验采用枸杞虫害文本描述数据集进行不同训练集、不同增强倍数的分类准确率测试,对文本数据增强效果的鲁棒性和效率进行分析研究。
(1)文本数据增强效果。该实验分别选取了枸杞虫害文本描述数据集200、500、1 000、Full Data(枸杞虫害文本描述总数,共1 670 个文本描述)不同训练集大小的文本数据,在增强倍数分别为1 倍、2倍、4 倍、8 倍、16 倍、32 倍的条件下进行数据增强,并将增强后的文本数据作为训练集输入到TextCNN 模型进行文本分类识别,结果见图9。

图9 不同训练集分类效果评价图
对于小数量数据集,过拟合的可能性更大,所以生成许多增广的句子会大大提高性能。对于较大的训练集,每个原始句子增加过多的增广句子是没有帮助的,因为当有大量真实数据可用时,模型倾向于适当地进行归纳。基于这些结果,由图9 可以得出表2 的结果。

表2 推荐的文本增强倍数
由图9 可以看出,利用该系统进行不同训练集规模数据增强后得到的枸杞虫害文本描述在4 倍数据增强时分类效果最好,准确率达到了85.3%。
(2)实验方法的增强效果。该实验对枸杞虫害文本描述数据集中500 个文本,分别采用SR、VAEHD、本文EDA 方法进行16 倍数据增强,并对增强后的数据采用TextCNN 分类模型进行分类识别,评价指标采用准确率和时间,结果见表3。

表3 不同数据增强方式文本分类结果对比
由表3 可知,该系统采用的EDA 数据增强方法比SR 和VAEHD 方法在文本分类实验中的准确率分别提高了11.1%和3.7%,且文本数据增强时间分别减少了0.129 s 和0.065 s,说明该系统采用的方法比传统数据增强方法效果更好。
(3)系统的效率。为了验证该系统文本数据增强的快速性和高效性,对数据集中100 个、500 个文本分别进行5 倍、10 倍批量文本增强,并统计增强后文本总数量和增强所用时间,实验结果见表4。
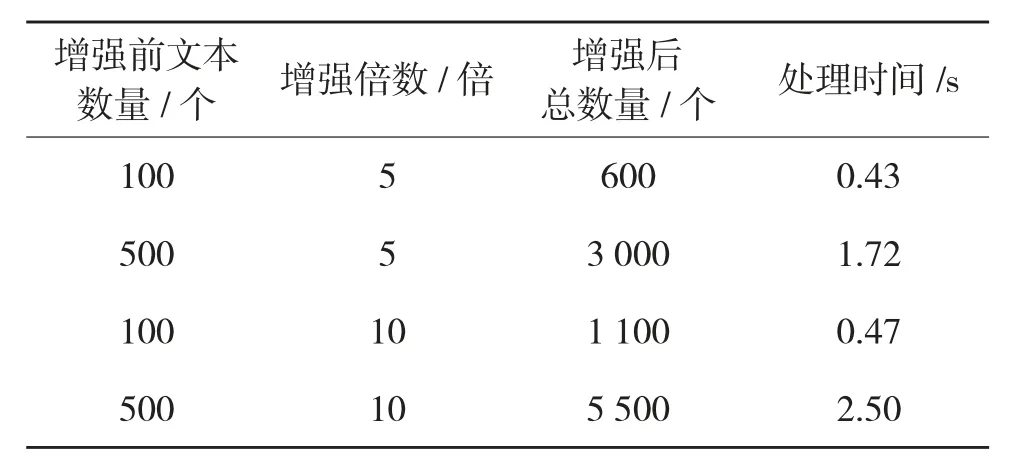
表4 批量文本数据增强效果
由表4 可知,该系统能在0.47 s 和2.50 s 内分别完成对100 个、500 个文本的批处理数据增强,说明该系统能快速高效地完成批量文本数据增强。
根据以上实验结果可以看出,该系统不仅可以高效地进行单文本增强,还能实现批量文本增强操作。增强后的文本数据在文本分类实验中也取得了较好的准确率。实验采用枸杞虫害文本描述数据集进行文本数据增强,对该数据集进行4 倍数据增强,增强后的文本数量达到8 350,解决了样本不均衡问题,完成了对枸杞虫害文本描述数据集的数据扩充。
5 结论
本文基于Python 文本数据增强系统实现了对文本数据的扩充增强,并完成了单文本数据增强和批量文本数据增强的功能。对解决小样本场景下样本数量不足容易导致模型过拟合、样本间不均衡的问题十分有效,而且可根据数据增强中的同义词替换、随机交换、随机删除、随机插入进行文本局部调整。该系统完成了枸杞虫害文本描述数据集的文本数据增强,解决了该数据集的样本不均衡、数据量不足的问题。实验结果表明,实验采用的枸杞虫害文本描述数据集在4 倍数据增强时分类效果最好,准确率达到了85.3%。相比传统的SR 方法以及VAEHD方法,本文采用的EDA 方法在500 个文本16 倍数据增强条件下,文本分类准确率提高了11.1%和3.7%。此外,该系统能在0.47 s 内和2.50 s 内分别完成对100 个、500 个文本10 倍的批处理数据增强,表明该系统的快速高效性。
该系统采用Web 操作界面,简单易懂,但存在一些不足。目前该系统只能对txt 文本进行操作,且存在字符长度限制问题,但对传统文本数据集是一个简单实用的系统。下一步工作将会继续改进和完善系统功能,提高系统的兼容性,优化系统的长文本功能,进一步提高文本数据增强的水平。
猜你喜欢
现代园艺(2022年5期)2022-11-19
现代园艺(2022年3期)2022-11-18
学与玩(2022年2期)2022-05-03
建材发展导向(2021年15期)2021-11-05
云南画报(2021年6期)2021-07-28
科学家(2021年24期)2021-04-25
四川蚕业(2021年2期)2021-03-09
绿色中国(2019年13期)2019-11-26
海峡姐妹(2019年5期)2019-06-18
世界热带农业信息(2016年2期)2016-03-11
