
基于CT影像组学模型鉴别诊断小细胞肺癌与非小细胞肺癌
2021-08-12 09:20黄志成叶钉利胡乔治赵瑞坤
中国介入影像与治疗学 2021年8期
黄志成,叶钉利,胡乔治,郑 君,赵瑞坤
(吉林省肿瘤医院放射科,吉林 长春 130021)
肺癌是临床常见呼吸系统恶性肿瘤[1],多起源于肺上皮细胞[2],按照组织病理学分型可分为小细胞肺癌(small cell lung cancer, SCLC)和非小细胞肺癌(non-small cell lung cancer, NSCLC)。SCLC约占肺癌总数的15%[3],是最具侵袭性的肺癌亚型,生长迅速、较早转移、易复发、预后差,患者5年生存率不足7%[4],临床治疗常以化学治疗(简称化疗)为主[5]。NSCLC约占肺癌总数的85%,与SCLC相比,生长相对缓慢,扩散、转移亦相对较晚;手术是对早期NSCLC的最优干预方式[6]。准确鉴别SCLC与NSCLC有助于临床合理制定治疗方案。影像组学借助计算机软件,采用特征提取方法从医学影像数据中挖掘多维度定量特征,并以统计学和机器学习方法筛选最有价值的纹理特征用以训练机器学习模型,以此鉴别诊断疾病[7]。本研究观察基于CT的影像组学模型鉴别诊断SCLC与NSCLC的价值。
1 资料与方法
1.1 一般资料 回顾性分析2018年2月—2020年2月1 524例于吉林省肿瘤医院接受手术治疗(穿刺活检术、胸腔镜手术或开胸手术)的肺癌患者,男681例,女843例,年龄28~88岁,平均(62.2±9.7)岁。纳入标准:①术前接受胸部CT平扫检查;②经活检病理或术后病理确诊为NSCLC或SCLC;③病灶长径1~5 cm。排除标准:①其他系统恶性肿瘤;②CT图像有明显金属或运动伪影。
1 524例中,SCLC患者526例(SCLC组),男243例,女283例,年龄32~85岁,平均(62.6±9.4)岁;NSCLC患者998例(NSCLC组),男438例,女560例,年龄28~88岁,平均(62.1±9.9)岁,其中肺腺癌498例、肺鳞癌500例。
1.2 仪器与方法 采用GE Lightspeed 16排CT机。嘱患者仰卧,头先进,双臂上举,深吸气后屏气接受肺部扫描。扫描参数:层厚5 mm、层间距5 mm、管电压120 kV、管电流215 mA、转速27.5 mm/rot、螺距1.375∶1,重建矩阵512×512。
1.3 提取影像组学特征与机器学习 由2名具有3年以上胸部CT诊断经验的主治医师在不知晓患者信息和临床资料的情况下阅片,意见不一致时,由1名从业20年以上的影像科副主任医师进行最终判断。于纵隔窗区分肿瘤、坏死及空洞区域,以肺窗图像进一步确定肿瘤边界;肺内存在多个病灶时,选取穿刺活检或手术切除病灶作为分析目标。采用MaZda(Version 4.6)软件在病灶最大层面图像中沿肿瘤边缘手动勾画ROI(图1),避开坏死和空洞区域,边界不清或遇淋巴结融合等情况时通过CT值确定病灶边界。提取病灶纹理特征参数,采用Z-Score标准化算法对数据进行标准化处理。而后对影像组学特征行Correlation相关性分析,截断值设定为0.7,根据自变量与自变量的相关系数r进行筛选,如多个自变量的r均>0.7,则保留1个自变量,以剔除冗余数据并保留特征值差异明显的组学特征。在此基础上以最小绝对收缩和选择算子(least absolute shrinkage and selection operator, LASSO)算法[8]进一步处理(图2),筛选出最佳影像组学特征,用以构建预测模型。
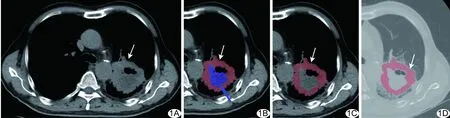
图1 患者男,67岁,肺鳞癌 A.病灶最大层面纵隔窗CT图像; B.根据CT值将病灶分为肿瘤区域(红色)、坏死区域(蓝色)和空洞区域(黑色); C.纵隔窗CT图像示ROI; D.肺窗CT图像示ROI (箭示ROI)
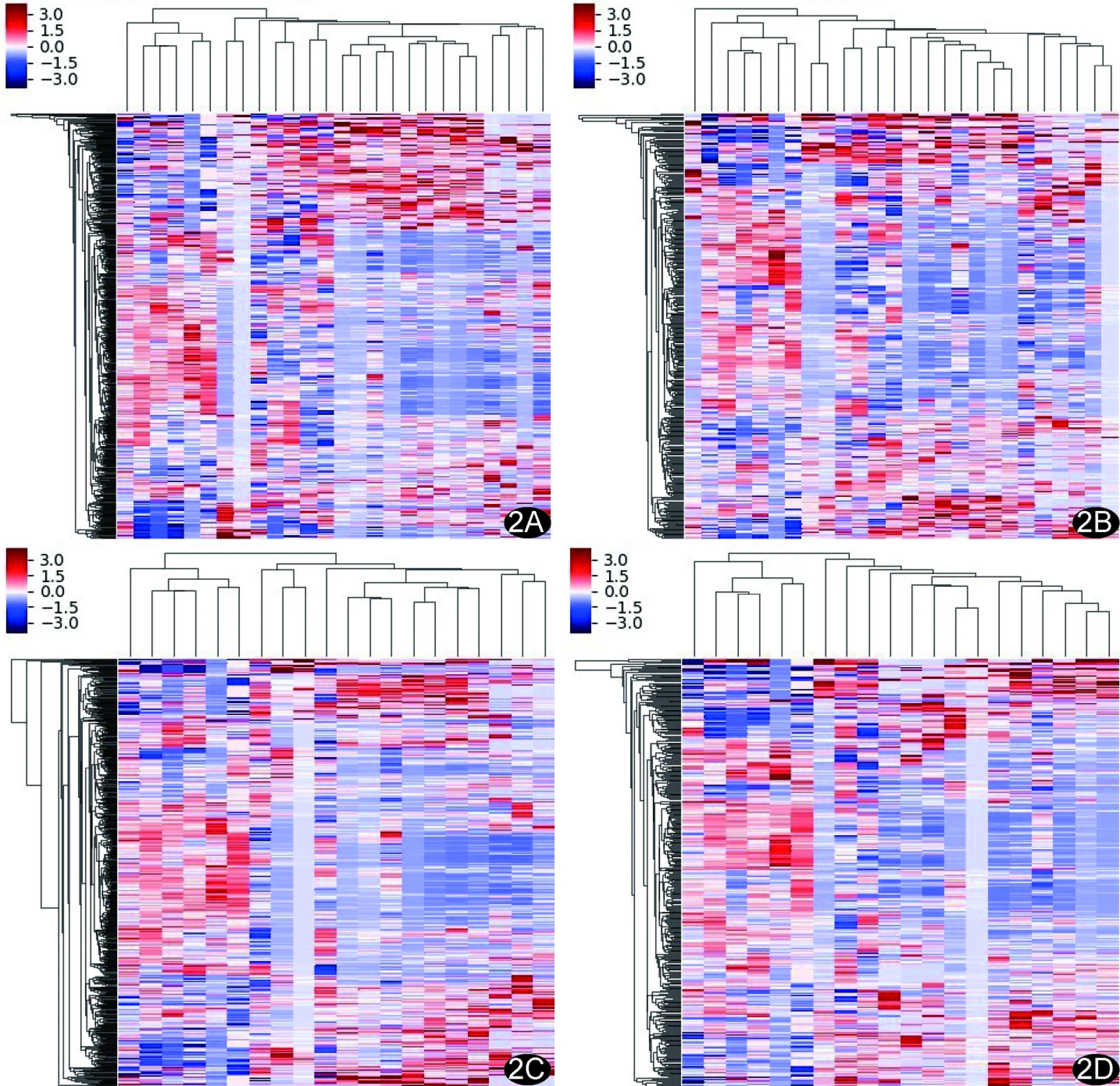
图2 Correlation模型、LASSO模型在训练集和验证集中的热图 A.Correlation模型在训练集中的热图; B.Correlation模型在验证集中的热图; C.LASSO模型在训练集中的热图; D.LASSO模型在验证集中的热图
以7∶3比例将数据分为训练集和验证集。在模型训练阶段分别采用7种机器学习模型对数据进行处理,包括Logistic回归、随机森林(random forest, RF)、贝叶斯算法(Naive Bayes, NB)、决策树(decision tree, DT)、卷积神经网络(convolutional neural network, CNN)、邻近算法(K-nearest neighbor, KNN)和支持向量机(support vector machine, SVM)模型;以验证集测试结果作为机器学习分类器的性能指标,根据准确率选择最佳分类器模型。
1.4 统计学分析 采用SPSS 25.0统计分析软件。计量资料以±s表示,计数资料以频数表示。采用χ2检验比较组间患者性别差异,以独立样本t检验比较组间年龄差异。P<0.05为差异有统计学意义。
2 结果
SCLC组与NSCLC组患者性别(χ2=0.74、P=0.39)、年龄(t=0.97,P=0.33)差异均无统计学意义。对每个病灶提取306个纹理特征参数,最终筛选出20个组间差异明显的影像组学特征(表1),并以之构建预测模型。
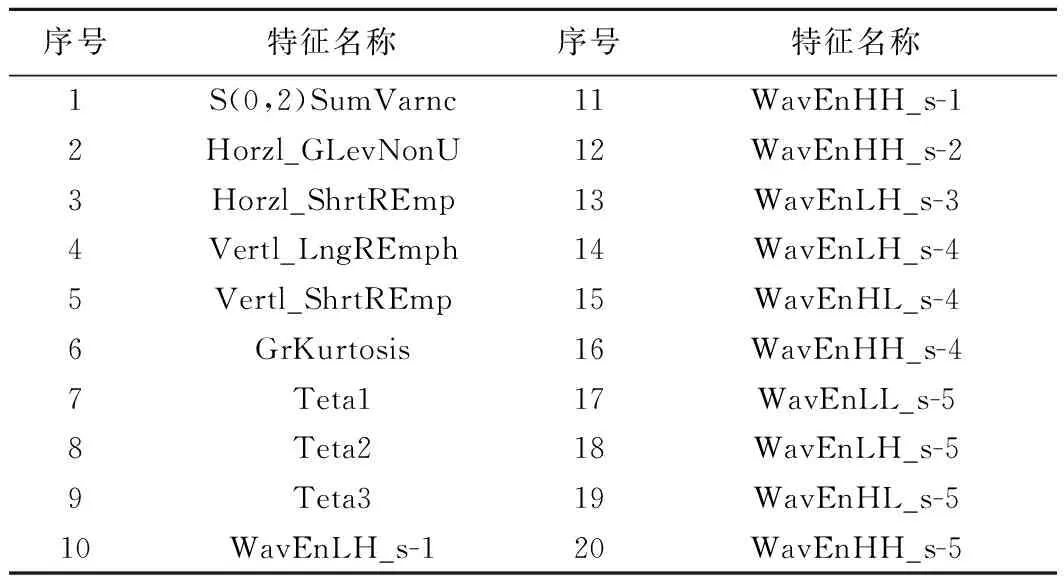
表1 用于构建机器学习模型的20个影像组学特征
模型训练结果显示,KNN模型鉴别诊断SCLC与NSCLC的准确率最高(图3),为最佳分类器模型;其在训练集的AUC为0.88、准确率81.34%、特异度97.00%、敏感度51.63%,在验证集的AUC为0.82、准确率78.82%、特异度95.00%、敏感度48.10%,见图4。

图3 各分类器模型对验证集的分类准确率 图4 KNN模型预测病理分型的ROC曲线 A.训练集; B.验证集
3 讨论
根据2015版WHO肺癌组织学分类标准[9],肺癌分为9种类型, SCLC为发病早、生长快、易转移、预后差的一种特殊类型肺癌,明显区别于其他类型。对于SCLC,手术治疗和局部放射治疗难以发挥关键性作用,细胞毒性化疗为主要治疗方法;对NSCLC则以手术联合全身化疗和/或局部放疗为主要干预方式。治疗前准确区分SCLC与NSCLC,有助于临床医师制定更有效的干预措施,以达到最佳治疗效果。
既往研究[10]报道,SCLC与NSCLC的平扫CT影像学表现存在重叠,而能谱CT对二者的鉴别价值亦有限[11],导致单纯依据CT图像很难准确预测SCLC与NSCLC。影像组学可无创预测病灶组织学分类,为临床决策提供依据。CHEN等[12]对69例肺癌的CT平扫图像进行影像组学分析,结果显示基于CT平扫图像的影像组学模型可有效鉴别SCLC与NSCLC。梁伟等[13]分析131例肺癌的CT平扫图像,发现基于CT平扫图像的影像组学模型对SCLC与NSCLC有较好的鉴别能力。徐圆等[14]基于100例肺癌的CT增强图像建立的影像组学模型可有效鉴别SCLC与NSCLC。郭炎兵等[15]分析145例肺癌的MR T2WI,并建立基于T2WI的影像组学模型,其鉴别SCLC与NSCLC的效能亦较高。
本研究在上述研究基础上扩大样本量,并进一步扩展机器学习模型范围,基于1 524例肺癌的CT平扫图像,通过提取特征的方式对每个病灶获得量化后的306个纹理特征,再以相关性分析和LASSO算法筛选出SCLC与NSCLC组间差异最明显的20个影像组学特征用于机器学习模型训练。在模型训练阶段采用7种机器学习模型,以尽可能多地纳入目前常用机器学习分类算法,结果显示KNN模型的准确率最高,其在验证组的AUC和准确率分别为0.82和78.82%。
KNN是数据挖掘分类算法之一,主要依靠待定样本周围有限的邻近确定样本,而非依靠判别类域的方法来确定所属类别,故对类域交叉或重叠较多的待定样本集而言较其他方法更具优势。本研究中SCLC和NSCLC数据集在类域方面存在较多交叉重叠,这可能是KNN算法诊断效能优于其他诊断模型的原因。但KNN算法亦存在不足,当样本数量不平衡时,输入一个新样本可使该样本的K个邻近确定样本中的大容量类样本占据多数,导致判断结果出现偏差。本研究中SCLC与NSCLC的样本数量不平衡,NSCLC样本居多,可能导致KNN算法预测新的SCLC样本时因邻近K个样本中NSCLC数量占多数而误判为NSCLC,此点可能是KNN模型在训练集和验证集中敏感度均不够高的主要原因。
本研究的局限性:①为回顾性分析,选取样本均为术后病例,可能存在选择性偏倚;②系单中心研究,可能导致结果缺乏拓展性;③未纳入年龄和性别之外的其他临床信息和影像学征象,有待完善。
综上所述,基于CT影像组学结合机器学习算法建立的诊断模型能鉴别SCLC与NSCLC,以KNN模型的效能更优。
猜你喜欢
中国临床医学影像杂志(2022年2期)2022-05-25
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
国际口腔医学杂志(2019年3期)2019-05-31
中国交通信息化(2018年5期)2018-08-21
天然产物研究与开发(2018年2期)2018-04-04
癌变·畸变·突变(2016年3期)2016-02-27
医学研究杂志(2015年12期)2015-06-10
医学研究杂志(2015年11期)2015-06-10
