
机械产品专利知识的提取和应用*
2021-08-23 10:12董文斌战洪飞余军合
机械制造 2021年8期
□ 董文斌 □ 战洪飞 □ 余军合 □ 王 瑞
宁波大学 机械工程与力学学院 浙江宁波 315211
1 研究背景
企业机械产品设计过程中,专利文献占有很重要的地位。然而,目前专利申请数量日趋庞大,产品设计人员需要花费大量时间阅读和分析专利文献。随着专利数据的大幅增加,仅依靠人工查阅的方式获取专利知识与信息越来越显得力不从心。对此,笔者构建了辅助设计人员进行研发设计的专利知识抽取方法与系统,实现对专利知识的自动提取,构建专利知识图谱,产品设计专利知识推送等功能。
关于从专利文本中提取知识的研究一直是热点,不同学者对专利知识提取的认识和方法都不尽相同。Park等[1]提出基于主谓宾结构的专利情报系统,将从专利文本中提取到的主谓宾结构作为相关的专利知识,并基于此构建专利地图和专利网络。陈忆群等[2]采用支持向量机自动抽取出专利文本中的关键词,由此挖掘专利知识。An等[3]提出一种基于介词语义分析网络确定专利关键词之间类型的方法,通过确定介词定义技术术语之间的关系,来描述专利的技术内容。郭洁[4]为了获取林业机械专利中的功能结构知识,提出将闭合加权频繁模式与林业机械领域同义词典相结合的方法,通过试验验证了这一方法的稳定性和可靠性。盛卿[5]针对机电产品专利提出了“任务流”模型,用于提取和重用创新原理知识。于丽娅等[6]研究了机电产品专利设计知识的特点,通过识别专利文献中的动名词短语来获取创新专利设计知识。吴正[7]通过文本挖掘手段,从具有相同或相似特征的专利中提取了实现功能和解决问题的关键性术语,并基于此绘制专利地图来进一步分析,辅助创新。马建红等[8]从创新设计角度出发,采用基于组合特征和最大熵分类器的方法对目标功能、作用原理、位置特征等创新知识进行抽取,这是一种统计机器学习的专利知识抽取方法。张盘龙[9]在构建专利知识图谱的过程中,通过分词、主题分类等方法,同时应用改进的基于图的排序算法,提取专利中的关键词,作为承载专利知识的实体。薛驰等[10]将专利作用结构知识提取分为技术对象和技术关系两类提取,采用最大熵原理和专利术语词典识别的方法提取技术对象,采用建立组成类动词库识别核心动词的方法提取技术关系,最终实现专利作用结构知识的提取。
以往学者对专利知识的提取通常以关键词或术语的形式来代表专利知识,提取对创新研发有启发作用的知识不全面。笔者在参考总结前人文献的基础上,针对专利文献中蕴含的有助于创新设计的知识进行分析,构建专利知识结构模型,在实体识别和实体关系抽取两项任务中引入深度学习神经网络模型,克服传统方法的缺点,最终实现专利知识的有效提取。
2 专利知识提取服务框架
随着专利数量的日趋庞大,有关人员需要花费大量时间阅读和分析专利文献,获取专利中蕴藏的设计知识,这与如今快节奏时代的高效率目标存在矛盾。因此,需要有一种方法,能使计算机自动提取专利中的知识。笔者基于润桐、soopat等专利检索网站中的中文专利文献,研究从摘要等非结构化数据中提取与产品设计相关的功效、原理、结构知识的方法,并对专利文献进行知识建模,分为摘要、说明书等专利内容和公开号、申请人等专利属性,从专利内容中提取结构、原理、功能知识。基于深度学习相关算法模型,实现实体识别和实体关系抽取两大任务,进而完成专利知识的提取。
专利知识提取服务框架如图1所示。
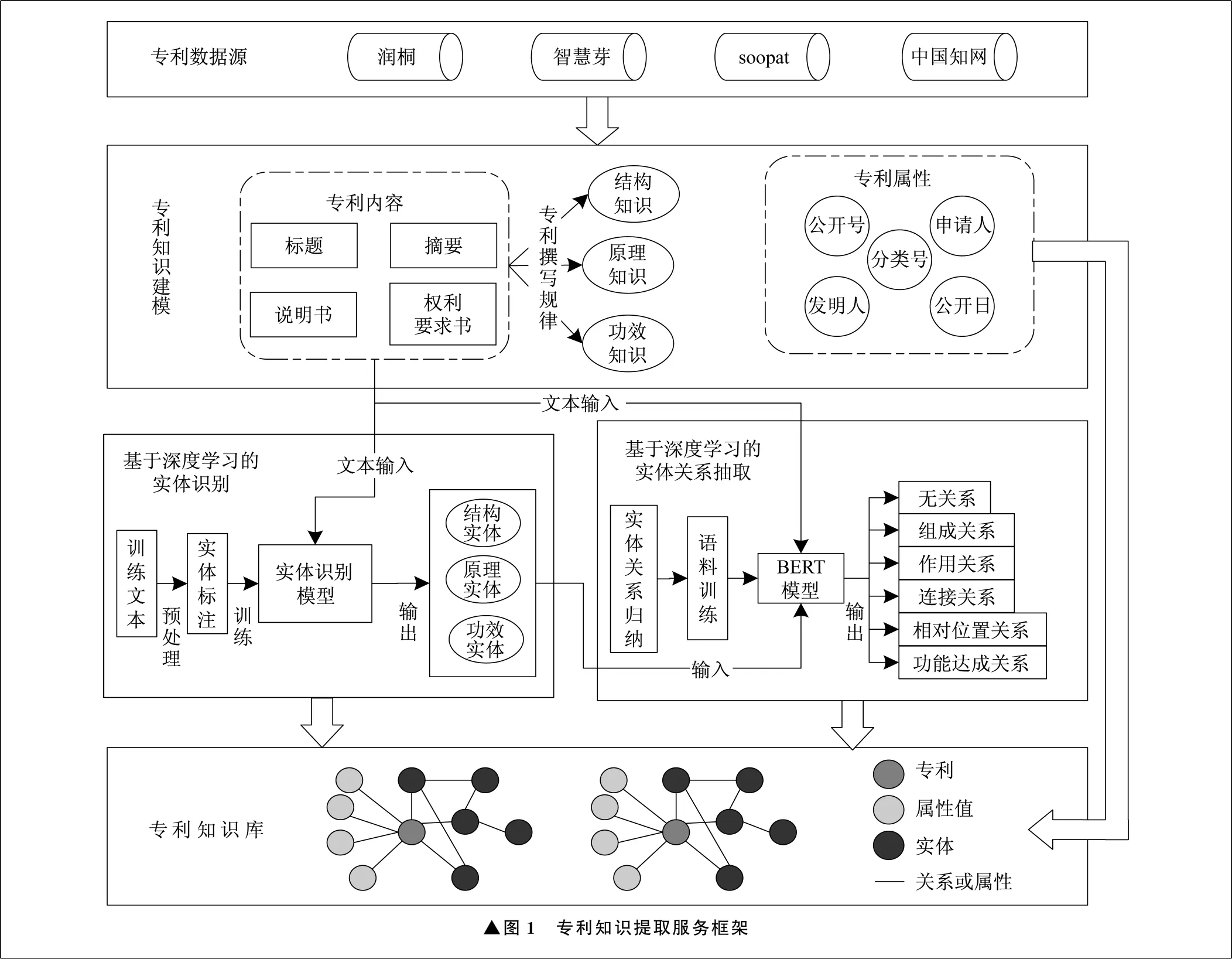
▲图1 专利知识提取服务框架
专利数据源主要选择润桐、智慧芽、中国知网等常用专利检索网站,并从中获取专利数据。在专利知识建模部分,主要根据专利文献的撰写规律归纳出专利中蕴含的功效、原理、结构三类知识,并分析其特征。在基于深度学习的实体识别模块中,通过算法模型对专利领域实体进行识别。在实体关系抽取部分,使用BERT语言预训练模型,通过分类原理进行实体间关系的识别。基于抽取出的实体和实体关系,以实体-关系-实体的形式表示专利知识,并与专利属性一同存入专利知识库。
3 基于深度学习的专利知识提取
笔者主要通过解决识别专利文本中承载知识的实体和抽取实体之间关系的两项任务来完成专利知识的提取。通过对专利文本中的知识结构进行建模,分析专利中的实体类型及实体关系,引入深度学习算法模型,使计算机能够自动识别实体和抽取实体关系。采用深度学习方法,克服了采用传统自然语言处理方法提取文本特征不能很好地表征文档语义、语法,容易丢失有用信息的缺陷。应用深度学习方法,还可以获取更优良的文本特征。
3.1 专利知识建模
笔者主要针对机械产品的发明和实用新型类专利进行研究。发明和实用新型类专利文献中包括公开号、申请人等描述专利属性的信息,在导出或提取后通常是可以直接储存和应用的结构化数据。标题、摘要、权利要求书等是具体描述专利内容的文本,其中蕴含着最主要的专利知识。标题表述产品或产品组件名称。摘要是对专利全文的概括性描述,主要涉及功效、结构、原理等内容。权利要求书对所需法律保护的结构进行具体说明。说明书对产品设计的背景、功效、结构、原理等进行具体描述。
专利说明书的内容虽然具体,但是过于烦琐冗杂,权利要求书只描述产品的结构,摘要则在很大程度上保留专利涉及的主要知识,而且容易获取。基于此,笔者选择摘要来提取专利中的相关知识。专利的功效知识包含专利所能达到的功能效果,反映产品设计的需求和目的,如降低噪声、延长使用寿命等。原理知识指达到专利所述功效的步骤或方法,如红外感应、紫外线杀菌等。结构知识描述产品的结构组件、结构组件的零部件,以及它们之间的关系。笔者通过对专利文献进行分析,将其中的知识表示为实体-关系-实体或实体-属性-属性值,并以节点-边-节点的形式构建专利知识结构模型,如图2所示。此模型包含了专利的基本属性、结构、原理、功效实体,结构与结构之间的相对关系,如连接关系、作用关系等,以及原理与功效之间存在的实现关系。

▲图2 专利知识结构模型
3.2 实体识别
对机械产品专利知识结构分析建模后,需要对模型中提到的实体和实体之间的关系进行识别抽取。实体识别指从专利文本中识别出表示功能、结构、原理等知识的领域实体,如从专利文本“本实用新型提供一种电动牙刷,包括刷头、刷柄和刷柄座”中识别电动牙刷、刷头、刷柄、刷柄座等表示结构知识的系统和零部件名,作为结构实体。笔者引入双向长短期记忆神经网络模型和条件随机场模型[11],通过序列标注的方式对专利领域实体进行识别。用双向长短期记忆神经网络模型和条件随机场模型实现实体识别时,按照实体特征采用标签标注一部分数据,模型经训练学习实体的特征后不断调整参数,使训练后的模型针对专利文本能自动计算出对应的标签序列,结合标签找出实体。为提升模型的实体识别性能,笔者在模型上游任务中引入BERT语言预训练模型进行预训练词向量。
(1) 确定专利文本的领域实体类型。专利文本的领域实体包括三部分:① 零部件名;② 形状构造,如电机、齿轮、凹槽等结构实体;③ 描述实现功效的功效实体,如清洁效率、寿命等。通常在发明专利中会涉及原理知识,可以提取描述原理的术语作为原理实体,如紫外线杀菌、太阳能充电等。
专利中的实体类型见表1。

表1 专利中实体类型
(2) 训练数据语料标注。将获取到的专利文本以“。”和“;”为分隔符,按句进行分割,并随机选择一部分作为训练语料进行标注。标注过程中,使用开始-中间-其它标注方法进行标注,将每个字符标注为B-X、I-X或O,语料标注见表2。B-X表示词语或短语的第一个字符,而且该词语或短语属于X类型,是FUNC、STRU、PRIN三种中的一种。表2中,原理实体“红外感应”的“红”字标注为B-PRIN。I-X表示字符属于X类型词语或短语第一个字符之后的字符,如“红外感应”的“外”“感”“应”都标注为I-PRIN。用O标注不属于任何类型的字符,如表2中“通”“过”“方”“式”等。

表2 语料标注
(3) 预训练词向量。BERT语言预训练模型预训练的词向量融合了句子中的语义特征,有更好的泛化能力[12]。笔者将BERT语言预训练模型训练的词向量输入到下游任务,来提高实体识别的效果,BERT语言预训练模型结构如图3所示。BERT语言预训练模型的输入初始词向量w1、w2、…、wn经三重向量嵌入融合了词的归属句子、位置等信息,输出预训练后的词向量T1、T2、…、Tn。模型中的亮点机制是掩语模型,类似于完形填空,先随机遮盖住句子中的部分词,通常为15%,再应用上下文来预测遮住的词。

▲图3 BERT语言预训练模型结构
(1)
式中:Pi,yi为第i个位置归一化后输出标签序列中标签yi的概率;Ayi-1,yi为从标签yi-1到标签yi的转移概率。

▲图4 专利领域实体识别模型
(5) 对实体识别结果进行评估。通过准确率C、召回率R、综合评价指标F三个指标对各类实体识别的结果进行评估[13]。准确率C为正确识别出的实体数与识别出的实体总数的比值,召回率R为正确识别出的实体数与训练集中的实体总数的比值,综合评价指标F为:
(2)
3.3 专利领域实体关系抽取
通过前文介绍的实体识别模型识别出专利摘要文本中的各类实体后,需要对识别出的实体之间的关系进行识别抽取。实体关系抽取任务的目标是预测两个实体在句子中的语义关系,如给定文本序列“电动牙刷包括手柄和刷头”,给定实体“电动牙刷”和“刷头”,目标是预测出两个实体之间的关系为组成关系。实体关系的抽取在自然语言处理领域内实质上属于文本的多分类,笔者依然采用BERT语言预训练模型来完成实体关系抽取任务。
总结专利文本中实体关系的类型,并定义编号,见表3。组成关系指一个组件包含若干部件或零件,代表词有“包括”“设有”等。相对位置关系描述零部件之间的位置关系,如A位于B之上、A嵌于B之内等。作用关系描述零部件之间的动态关系,如A带动B等。连接关系描述零件之间的连接配合关系,如A与B相连接等。功能达成关系描述通过技术方案实现功效的关系,如通过A实现B功能等。
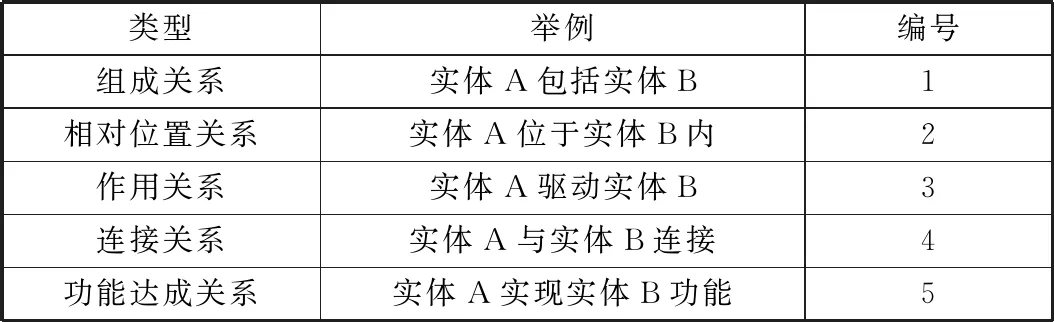
表3 专利文本中实体关系类型


▲图5 实体关系抽取架构
文本序列经过BERT语言预训练模型后,得到实体的隐藏向量Ht。对每个实体的所有隐藏向量进行求平均,添加激活函数后连接全连接层。实体的最终隐藏向量H′1、H′2和第一个标记[cls]的最终隐藏向量H′0分别为:
(3)
(4)
H′0=W0(tanhH0)+b0
(5)
式中:W0、W1、W2为权重矩阵,大小为BERT语言预训练模型隐藏层的大小,W1=W2;b0、b1、b2为偏置向量,b1=b2;h、j为实体A在句子中的开始和结束位置;k、m为实体B在句子中的开始和结束位置。
h″=W3[concat(H′0,H′1,H′2)]+b3
(6)
p=softmaxh″
(7)
式中:h″为综合向量;W3为综合权重矩阵;b3为综合偏置向量;p为输出概率;concat为组合函数;softmax为归一化函数。
4 专利知识服务系统
笔者基于构建的机械产品专利知识图谱设计了相关的专利知识服务系统。设计人员输入需求,根据知识图谱的最短路径查询,自动输出相对应的知识节点,并通过余弦相似度计算相关的知识节点进行推送。这一系统的目标是通过获取专利知识构建专利知识图谱,给予设计人员恰当的知识推送,辅助进行产品创新设计。这一系统能够实现专利知识的自动提取,专利知识图谱的构建和可视化,专利知识的快速精准查询,创新设计知识的推送,系统功能模块框架如图6所示。根据上述专利知识抽取研究,设计了专利知识服务系统的知识抽取模块,主要子模块有实体标注、实体识别、实体关系抽取等。系统整体运行框架采用浏览器/服务器模式,基于开放源代码的网络应用框架,使用Python语言作为主要业务和界面开发语言,图数据库采用Neo4j数据库,整体在Eclipse软件集成开发环境中进行。
5 实例分析
5.1 实例概况
笔者选择电动牙刷的专利作为试验数据,分别从润桐、智慧芽等专利数据库中获取。在输入关键词“电动牙刷”“智能牙刷”“声波牙刷”等后,筛选从2011年到2020年的数据,并剔除失效专利。编写爬虫程序获取专利共3 840篇,获取信息包括题目、摘要、申请日、公开日、申请人等。对数据进行预处理,以“。”“;”等为分隔符对摘要文本进行分句处理。
5.2 专利摘要文本实体识别
为了使模型能自动学习实体特征,需要对一部分摘要文本进行人工语料标注。笔者从获取的3 840篇专利摘要中随机选择384篇进行语料标注,并以8∶2的比例划分为训练集和测试集。在讨论完标注标准后,由三位硕士研究生分别独立完成语料标注任务。
将标注后的语料经实体识别模型训练,得到实体识别结果,见表4。实体识别结果各项数据都较为理想,其中结构实体和功效实体的识别效果要明显优于原理实体,这是因为结构知识和功效知识在专利文本中通常以比较规范和明确的语言来表述,所以识别的结果相比原理实体较好。原理知识的表述通常比较复杂,而且在专利中描述原理的语句不多,导致训练样本中原理实体相对较少,得到的结果也较差。

表4 实体识别结果

▲图6 专利知识服务系统功能模块框架
由数据回归到文本,从实际识别出实体的效果来看,结构实体和功效实体识别的泛化能力较好,能识别出训练集中未标注的实体,如标注“清洁”可以识别出“清洁卫生”“洁净”等未遇到过但语义类似的词。原理实体的识别效果不如结构实体和功效实体,因为专利中表述原理的语句较少,而且有些隐藏在其它句子中。应用所述方法识别专利领域实体的效果见表5,由此验证了专利领域三类实体识别的结果。

表5 专利领域实体识别效果
通过向训练后的模型输入一段摘要文本来展示实体识别的结果,采用专利CN209422143U“一种红外感应充电健美电动牙刷”来具体展示,实体识别界面如图7所示。

▲图7 实体识别界面
5.3 专利摘要文本实体关系抽取
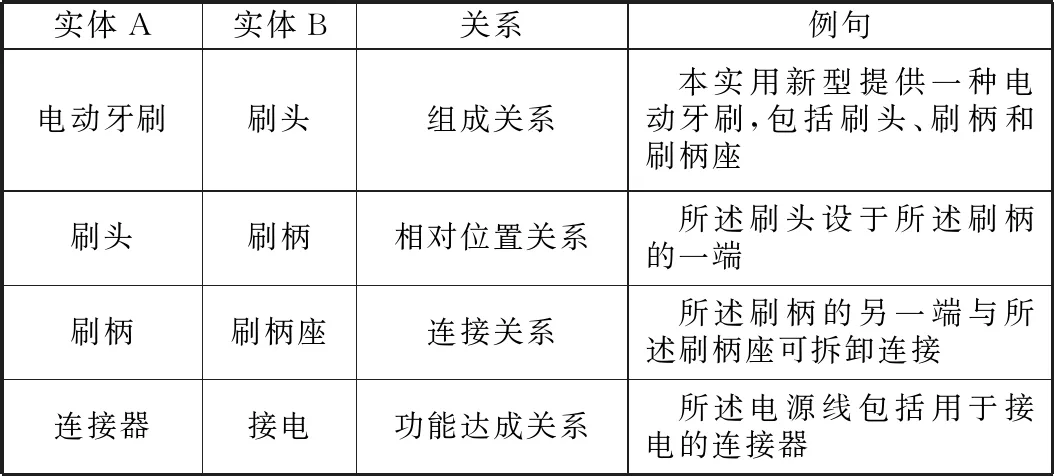
表6 部分专利实体关系样本
经BERT语言预训练模型训练后实体关系抽取结果见表7。表7表明,模型在专利实体关系抽取方面有不错的效果,其中作用关系和连接关系效果相对较差,原因是两者的语义特点较为接近,如句子“所述刷柄的另一端与所述刷柄座可拆卸连接”中实体“刷柄”和“刷柄座”两者既有连接关系又有作用关系,而经模型预测的结果为作用关系。组成关系、功能达成关系、相对位置关系在文本中表达规范,有明显的线索词,而且语义特点分明,所以取得了较为理想的结果。

表7 实体关系抽取结果
从摘要中抽取几个包含两个实体的句子,使用训练后的模型抽取实体关系,实体关系抽取测试结果见表8。实体关系抽取界面如图8所示。

表8 实体关系抽取测试结果

▲图8 实体关系抽取界面
对抽取出的实体与实体关系进行整合,形成实体-关系-实体的形式表示专利知识,存入专利知识库,并以节点-边-节点的图谱形式进行可视化。专利知识图谱如图9所示。

▲图9 专利知识图谱
5.4 专利知识推送服务
笔者设计的专利知识服务系统能很好地满足设计者的知识需求。通过输入需要了解的内容,系统会自动查询和推送相关知识及相关专利。如设计电动牙刷时,设计人员想要查阅能够达到防水这一功效的相关知识,只需要在系统创新知识推荐板块的文本框中输入“防水”,并点击查询,系统即会自动推送实现防水功效的相关结构或原理,包括硅胶密封圈、防水槽、防水电池、防水介质等内容。创新知识推送界面如图10所示。

▲图10 创新知识推送界面
6 结束语
笔者根据专利文献的特点,构建了专利知识结构模型,将专利知识提取的任务分为实体识别和实体关系抽取,并且基于深度学习的方法进行了抽取,并构建了产品专利知识图谱,设计了辅助产品创新设计的专利知识服务系统,取得了不错的效果。当然,笔者使用的方法仍有许多不足之处,如实体标注标准属于最简单的标注标准,可以使用划分更细的标注标准来提升识别结果的准确率。另外,实体识别和实体关系抽取是分开的,属于流水线式工作,实体识别中的误差可能会传入实体关系抽取,从而使抽取结果的整体误差增大,后期将考虑采用联合抽取的方法进行实体识别和实体关系抽取。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
保健医苑(2020年1期)2020-07-27
中国外汇(2019年18期)2019-11-25
数学物理学报(2019年1期)2019-03-21
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
中学生数理化(高中版.高二数学)(2017年1期)2017-04-16
高师理科学刊(2016年8期)2016-06-15
