
基于LightGBM算法的基站小区智慧节能研究
2021-09-09 07:36李飞裴明丽周源林雪勤
现代计算机 2021年19期
李飞,裴明丽,周源,林雪勤
(安徽科大国创云网科技有限公司,合肥 230088)
0 引言
伴随着通信业务的多样化和泛在化,使得通信网络能耗快速增长。无线通信网络能耗主要来源于通信基站,为了保证通信行业的正常、高效运行,运营商投入的通信基站数量越来越多、范围越来越广,其耗电量也随之增加,甚至成倍增长[1]。这不仅给企业带来更多的经济压力,同时也污染了人类的生存环境,而且存在大量的能源浪费。因此,节能降耗一直是通信行业长期关注并研究的课题而且是节能减排的重点工作[2]。
有数据统计显示,基站站点能耗费用(电费)占到网络运营成本的16%之多,为优化成本结构和促进社会效益,针对基站站点的节能减排已成运营商的一大努力目标。基站节能主要从两个方面入手,一方面是优化基站的硬件结构,硬件厂家研发各种节能的硬件产品[3];另一方面是优化基站的运行控制,应用人工智能技术,基于历史运行数据,预测基站的业务量承载低谷,触发载波关断等节能策略,减少设备运行时间,实现节能[4-5]。
1 LightGBM算法介绍
微软亚洲研究院在2016年公开了一款基于决策树算法的提升框架LightGBM (Light Gradient Boosting Machine)[6-7],它是一种快速、高效、开源框架,支持分布式、高效率的并行训练,被广泛应用于回归、分类、排序等多种机器学习应用领域。
1.1 LightGBM相关理论基础
(1)梯度提升(Gradient Boosting)
它是由一系列子模型的线性组合来完成学习任务的,可划分为两种基本类型:Gradient Boosting和AdaBoost。其中LightGBM属于Gradient Boosting[8-9]。梯度提升的主要思想是一次性迭代变量,迭代过程中,逐一增加子模型,并且保证损失函数不断减小。假设fi(x)为子模型,复合模型为:
Fm(x)=∂0f0(x)+∂1f1(x)+…+∂mfm(x)
损失函数为L[Fm(x)],Y,每一次加入新的子模型后,使得损失函数不断朝着信息含量次高的变量的梯度减小:
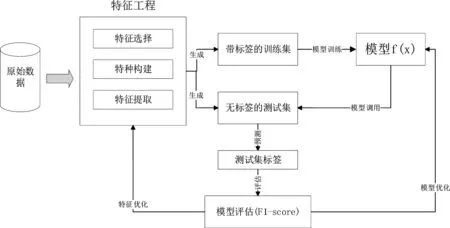
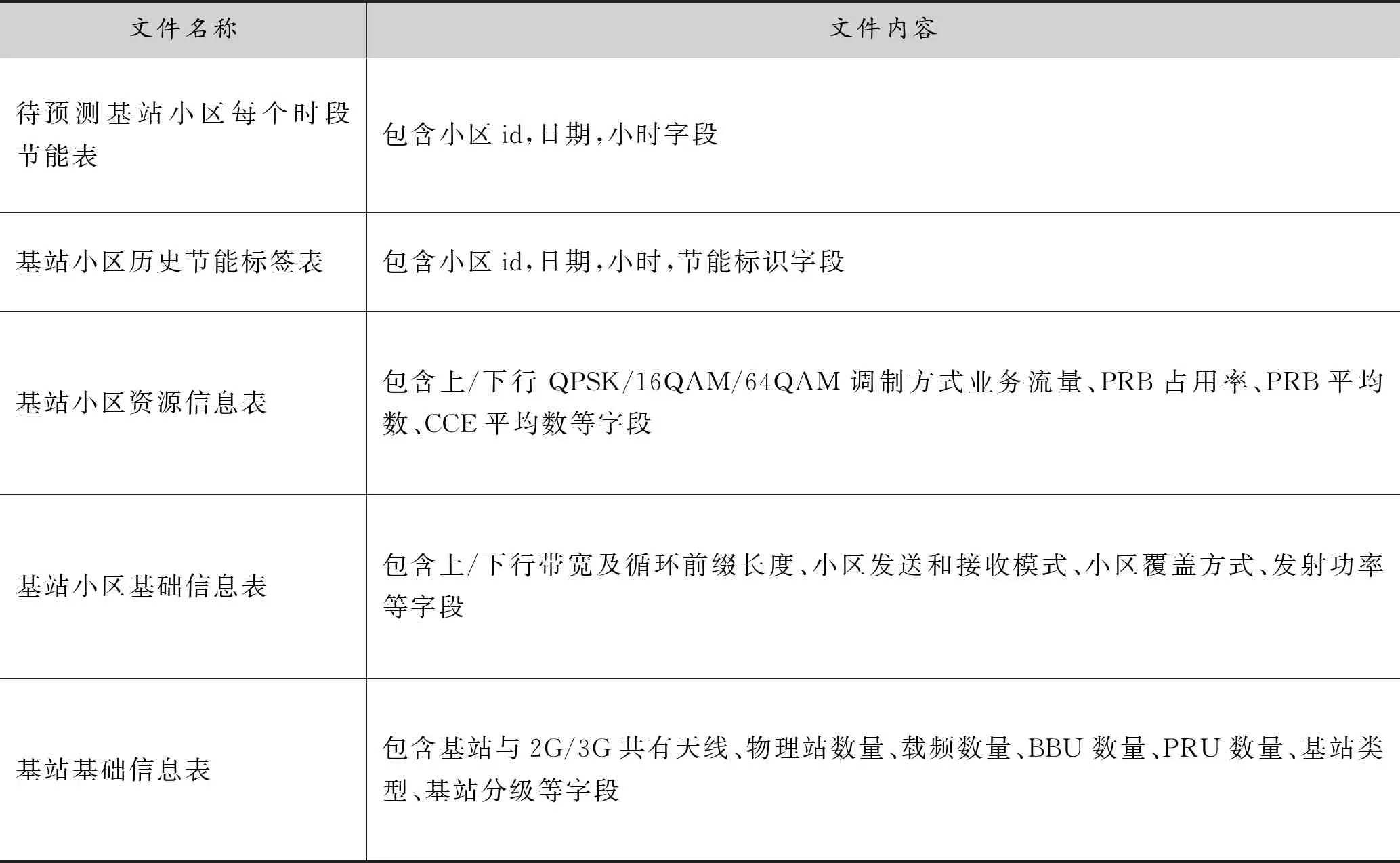
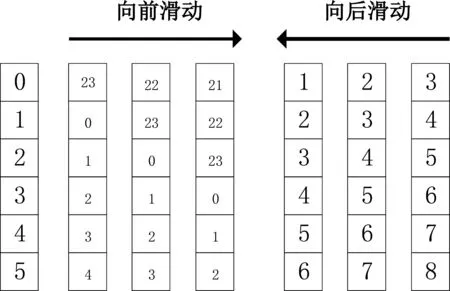
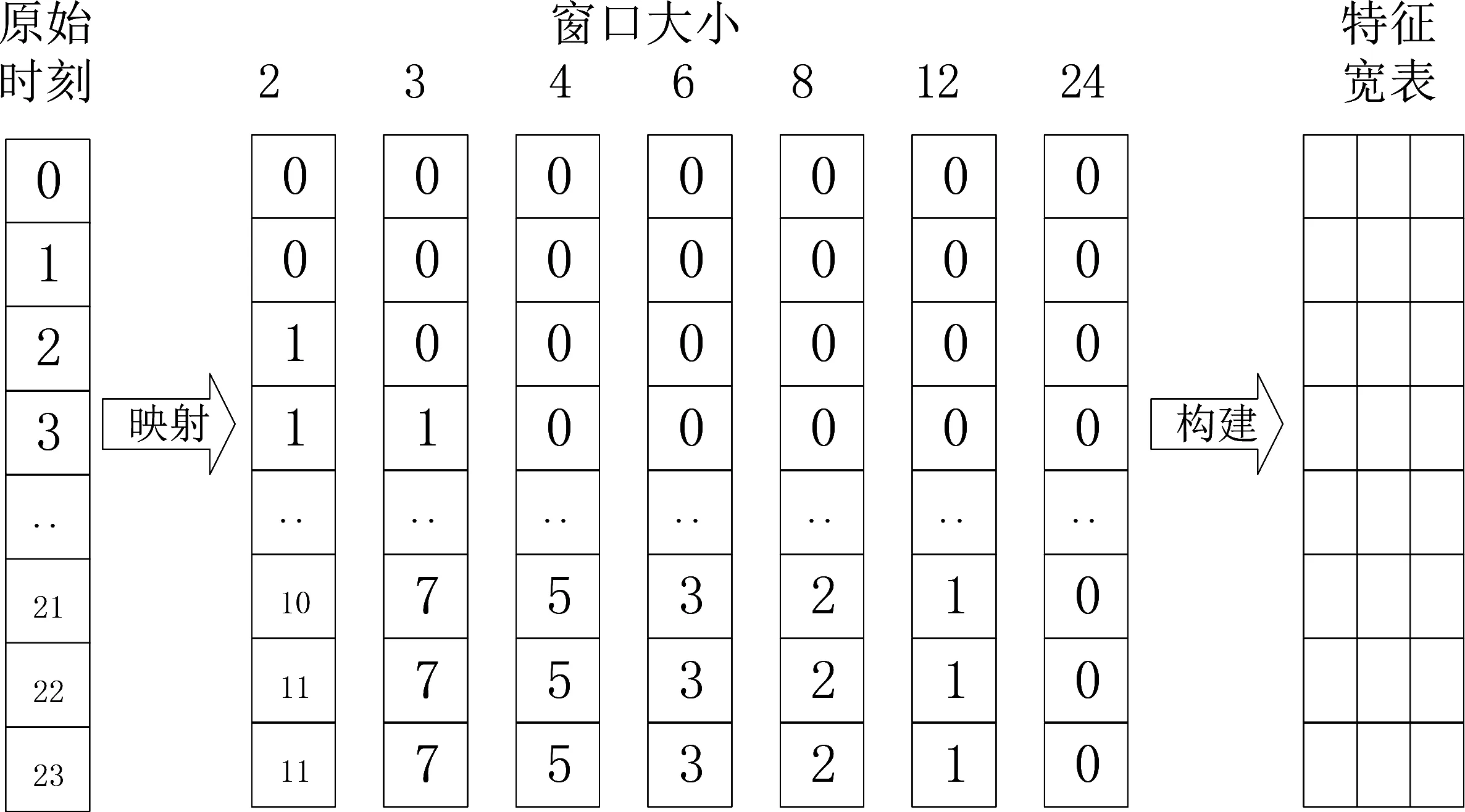
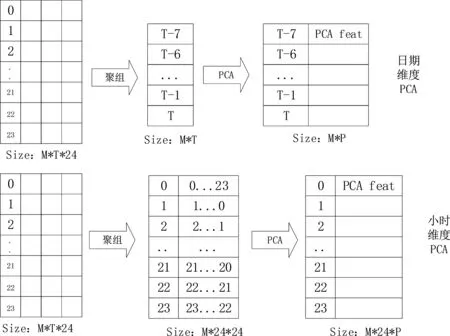
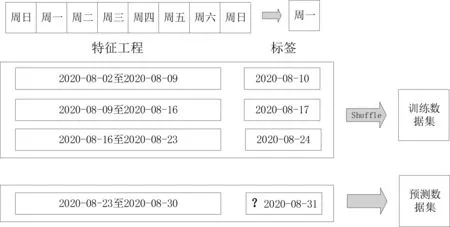
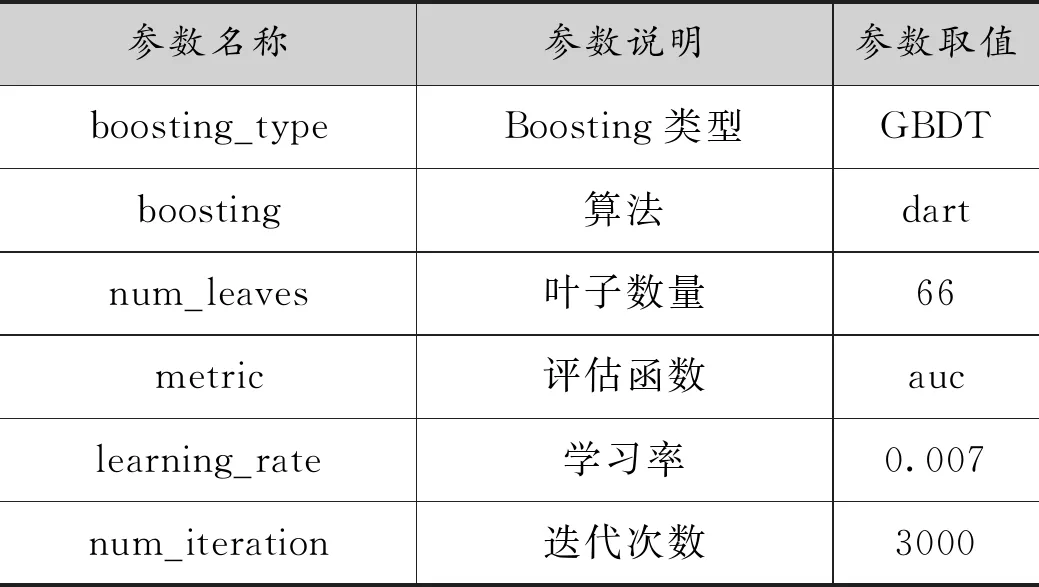
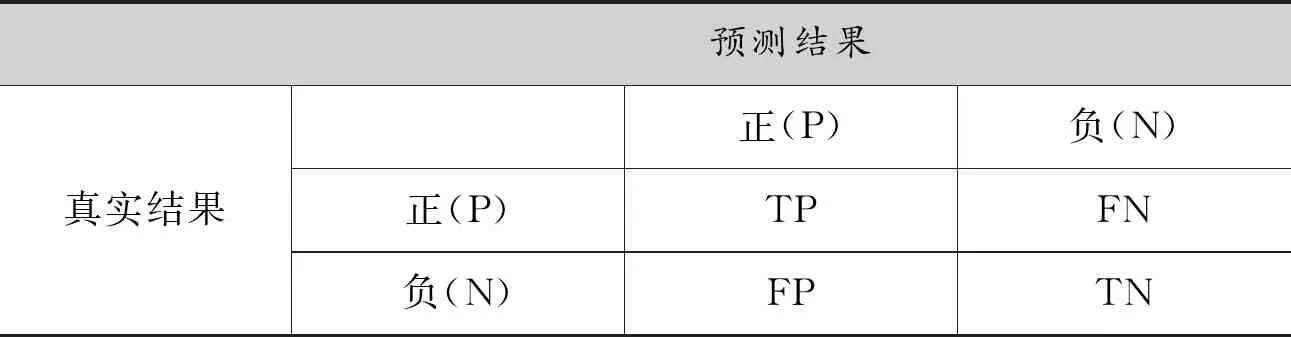
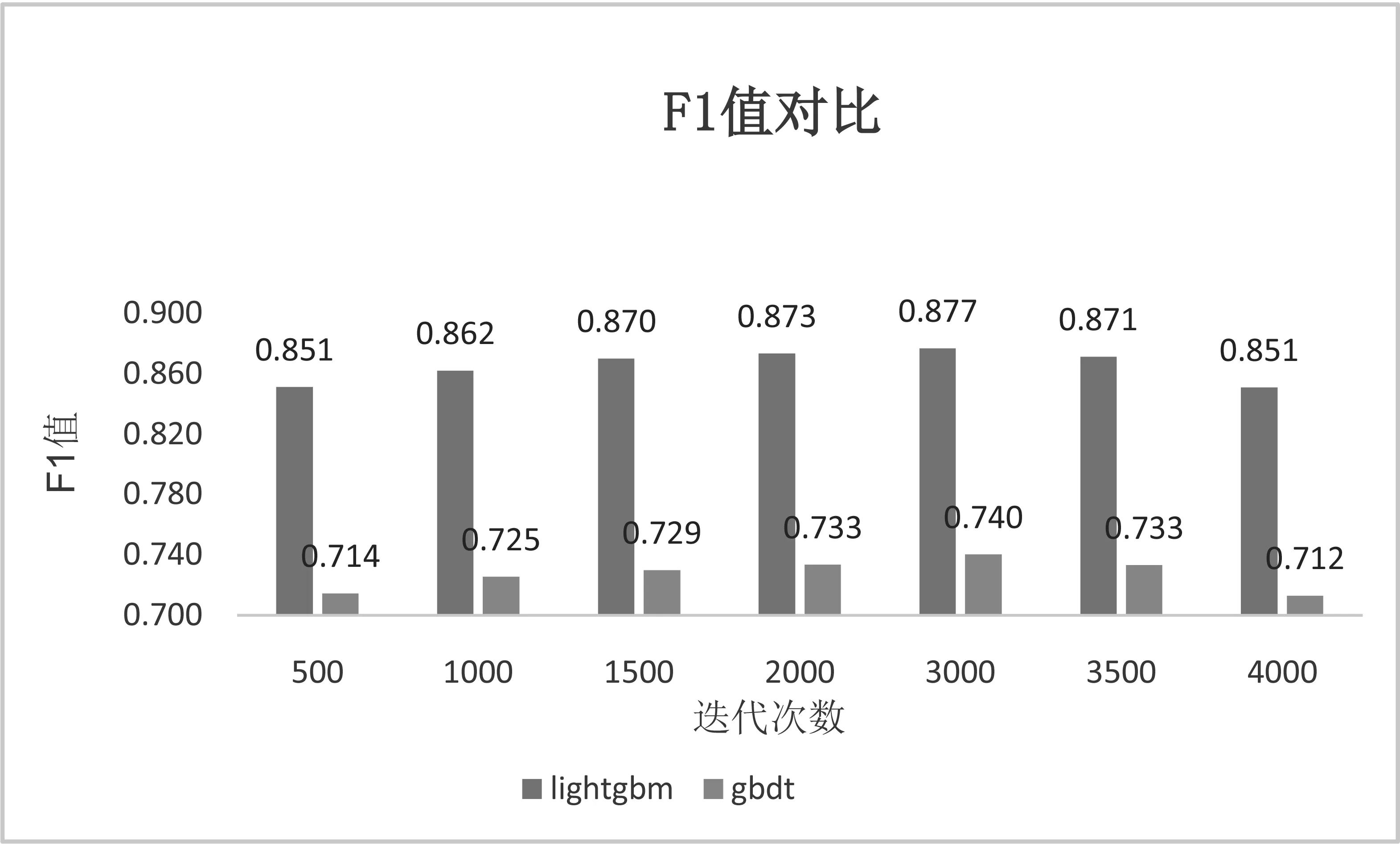
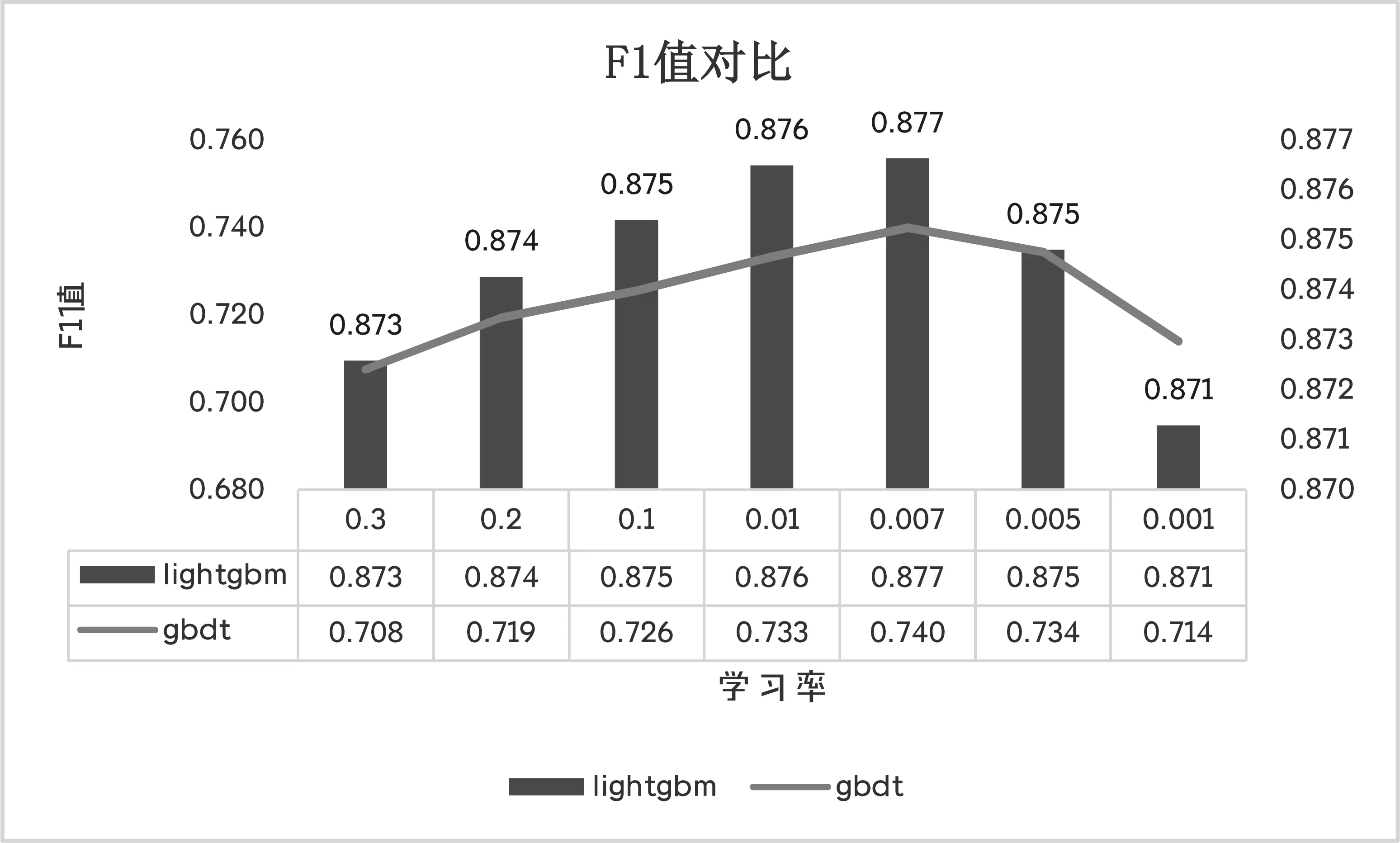
L[Fm(x),Y] (2)梯度提升决策树(Gradient Boosting Decision Tree) GDBT是一种迭代的决策树算法[10],该算法由多棵决策树组成,所有树的结论累加起来做最终结果。在机器学习领域中,它是一个经久不衰的模型,简称GBDT,即: GBDT=Gradient Boosting+Decision Tree GBDT具有Gradient Boosting和Decision Tree的功能特性,其主要优点是训练效果好、不易过拟合且泛化能力较强。近些年,GBDT在行业中被广泛关注和使用,通常用于诸如点击率预测和搜索排名之类的机器学习模型任务。GBDT还是各种数据挖掘比赛中的致命武器。 LightGBM是对GBDT的一种高效实现,主要用于解决GBDT在大规模数据处理上遇到的问题。采用带深度限制的Leaf-wise的叶子生长策略[11],其计算代价小,且避免了过拟合。为了减小存储成本和计算成本,LightGBM选择了基于Histogram的决策树算法。此外LightGBM直接支持类别特征处理,使其性能得到较好的提升。LightGBM主要通过以下几个参数实现算法控制与优化: (1)num_leaves:每棵树的叶子数量; (2)num_iteration:迭代次数; (3)learning_rate:学习率; (4)max_depth:最大学习深度,主要作用是防止过拟合; (5)min_data:一片叶子中数据的最小数量,也可以防止过拟合; (6)feature_fraction:选择特征与总特征数的比值,取值范围介于0、1之间,如果feature_fraction值小于0,那么LightGBM在每一次迭代时会随机选择部分特征。feature_fraction不仅控制选择总特征数的比例,且能够加快训练速度,同时防止过拟合。 (7)bagging_faction:选择数据与总数据量的比值。取值范围也介于0、1之间,与feature_fraction类似,能够加快训练速度,同时防止过拟合,但是随机并且不重复选择的是相应比例的观测,必须要将其设置成大于0的比例。 为了预测基站小区在将来一天的各个时间段(时间粒度为1个小时)是否可以节能,本文通过特征工程构建,将时间序列问题[12]转换成分类预测问题,采用机器学习算法中的LightGBM算法进行建模,训练有监督的基站小区节能预测模型。整个建模流程框架如图1所示。 图1 模型流程框架图 本次建模使用的数据来源于2020AIIA杯人工智能5G网络应用大赛,主办方提供了5个可用的数据文件,文件名称及其文件内容如表1所示。 表1 数据文件及其内容描述 特征工程[13]主要是把原始数据转化为模型可以训练的数据集,经过特征工程得到的数据可以决定机器学习的上限,会直接影响到模型的预测性能,在机器学习过程中占有举足轻重的地位。本文特征工程一般包括以下三个部分,分别是特征选择、特征构建、特征提取。 (1)特征选择 特征选择是删除冗余或者不相关的特征,使得有效特征个数减少并减少模型训练时间,从而提高模型训练的精确度。 基站小区基础信息表和基站基础信息表反映了基站小区和基站基本信息,这些基本信息不回随着日期的变化而变化,因此删除了两个表中的日期pm_date字段并进行去重。另外基站小区基础信息表中存在单一值域的字段,如所属扇区编号related_sectorid、PLMN标识的列表plmnidlist等字段,删除这些仅有单一值的类别字段,并对其进行独热编码操作。 (2)特征构建 特征构建是指通过研究原始数据样本,结合机器学习专业知识及建模经验,思考问题的数据结构和潜在形式,人工构造出新的特征,并且这些新构造的特征能够提高模型训练的效果,同时具有一定的工程意义。 根据提供的基站小区每个时段节能表可知,本文建模的目标是预测基站小区未来一天内每个时间段(时间粒度为1小时)的节能标识。但是基站小区资源信息表主要描述了每个基站小区的每15分钟的资源使用情况的汇总数据,都是量化的指标,因而针对基站小区资源信息表,构建基站小区每天每个小时的各项资源指标的均值,然后在其基础上进一步构建基站小区每个小时的均值、中位数、最大值、最小值、总和以及方差等六项指标,以此来标识基站小区在每个小时各项指标的稳定性特征。并将待预测日期的前1天、前2天、前3天的各项资源指标作为基站小区每个小时的前序特征加入特征宽表,标识其近期资源特征情况。此外,进一步分析各项指标之间的关系后,可进一步构建业务量占比、业务量总和等其他特征。 分析基站小区的历史节能标签数据,可构建基站小区在每个时刻的节能次数、节能比率等特征,并可将前一天、前两天、前三天同时刻的节能标签作为基站小区每个小时的前序特征。考虑节能的时序特征,针对构建得到的基站小区每个时刻的节能比率特征,对时间进行前后滑动,可得到前后3个时刻的环比节能特征,如图2所示。 图2 基于时间窗口滑动的特征构建示意图 (3)特征提取 特征提取是一个将机器学习算法不能识别出来的原始数据转变成可以识别到数据特征的过程。本文采用两种方法进行特征取,分别基于PCA方法[14]和基于时间窗口映射。基于时间窗口映射是指定义不同大小的映射窗口,将原始时间映射到相应的窗口区间,再基于映射后的时间块构建相应的基站小区节能比率、平均节能次数等特征,如图3所示。 图3 基于时间窗口映射特征提取示意图 基于PCA方法指的是分别从日期维度和小时维度出发后构建各基站小区的节能比率,再使用PCA方法进行特征提取,如图4所示,其中M代表基站小区数, T代表提取周期内天数,P表示降维后的维数。 图4 基于PCA方法特征提取示意图 基于上述的特征工程操作,可以基于一定周期的基站小区历史数据可以完成数据宽表的构建,为了实现对未来一天各基站小区各时刻(小时)的节能标识进行预测,传统的做法是使用待预测前一天(N-1)的节能标识作为标签,第N-1天之前的M天历史数据构建特征,得到训练数据集,再使用第N天之前的M天历史数据构建特征得到测试数据集,这种做法可在数据周期样本较少的时候完成模型的构建与节能标签预测,即M最小等于1,最少需要两天的历史数据。 但是当样本周期较多时,该方法则不能充分挖掘时间周期性的特征,从而限制了模型准确率的提升。因此本文提出了一种同周期的数据集特征构建方法,同周期是指预测的日期如果属于周一,那么训练数据集的标签也都取周一的样本数据,然后都基于标签日期的前M天历史数据构建特征,该方法构建的训练集和预测集,样本的特征和样本的标签都是同一个时期,保证了数据的分布一致性,在实验中也发现能够明显提升模型的准确率。同周期数据集构建如图5所示,待预测的样本是2020-08-31,该日期属于周一,那么确定三个周一(2020-08-10/2020-08-17/2020-08-24)作为标签,取待预测标签的前M(M=8)天历史数据,应用特征工程的操作构建数据集宽表,合并同周期的训练数据并打乱后得到最终的训练数据集,待预测历史数据集构建的特征宽表作为测试数据集,至此完成了训练数据集和测试数据的构建。 图5 基于同周期法的数据集构建示意图 本文研究了2种最常用的机器学习算法GBDT和LightGBM的区别和特点,通过对预测精度和复杂度的比较,最终整个模型的核心算法采用LightGBM,并使用Python语言编程实现数据处理和模型训练过程。其中,LightGBM参数设置如表2所示。 表2 模型参数设置表 由于对基站小区节能预测模型的研究是一个二分类任务,因而采用F1-score作为本次建模的模型评估指标。为了说明该指标的计算方式,引入混淆矩阵表,如表3所示。 表3 混淆矩阵 真阳例(TP):样本本身是正样本,预测结果也是正样本; 真阴例(TN):样本本身是负样本,预测结果也是负样本; 假阳例(FP):样本本身是负样本,预测结果是正样本; 假阴例(FN):样本本身是正样本,预测结果为负样本; 精确度(Precision):表示预测结果中正样本中真实标签也是正样本所占的比率,计算公式如下: 召回率(Recall):表示真实结果为正样本中预测结果为正样本所占的比率,其计算公式如下: F1-score:精确度与召回率的调和平均数,其计算公式如下: (1)同学习率、不同迭代次数时不同模型F1值对比 图6 同学习率、不同迭代次数时不同模型F1值对比 图6展示了在学习率相同、迭代次数不同时不同模型下F1值的对比情况,其中,横坐标表示迭代次数,纵坐标表示F1值。从图中可以得出,随着迭代次数的不断增加,LightGBM和GBDT算法的F1值呈现出先增后减的趋势,并且在迭代次数为3000时,两个算法都达到各自的最优值,另外,可以看出在同样的迭代次数下,LightGBM的训练效果始终优于GBDT算法,其平均预测精度比GBDT高出19%。 (2)同迭代次数、不同学习率时不同模型F1值对比 图7展示了同迭代次数、不同学习率时不同模型的F1值对比情况,其中,横坐标表示学习率,纵坐标表示F1值。该图反映了随着学习率的不断递减,LightGBM和GBDT算法的F1值也呈现出先增后减的趋势,并且在学习率为0.007时,F1值最大,两个算法都达到各自的最优效果,另外在同样的学习率下,LightGBM模型下训练结果RMSE值始终优于GBDT,其平均预测精度比GBDT高出20.7%。 图7 同迭代次数、不同学习率时不同模型F1值对比 本文提供了一种采用机器学习算法LightGBM预测基站小区节能的新思路,从多个角度构建了丰富的特征工程,并对比了LightGBM和GBDT算法在模型预测准确率的差异,通过以上实验结果表明,该算法效果显著。对于本文实验的优化方向,主要从以下几个方面进行优化。 (1)将研究CatBoost[15]、TabNet[16]等先进算法并进行模型融合,进一步提高模型的预测精度; (2)将结合分布式训练机制[17],提升模型的推理速度,加速模型的落地应用。1.2 LightGBM应用
2 一种基站小区节能的预测方法
2.1 数据收集与预处理
2.2 特征工程
2.3 数据集构建
2.4 模型训练与评估
2.5 实验结果与分析
3 结语
猜你喜欢
中国新通信(2022年4期)2022-04-23
作文周刊·小学一年级版(2021年36期)2021-01-14
阅读与作文(小学高年级版)(2020年8期)2020-09-12
恋爱婚姻家庭·青春(2019年9期)2019-12-10
恋爱婚姻家庭(2019年26期)2019-09-14
文萃报·周二版(2019年32期)2019-09-10
数学学习与研究(2017年3期)2017-03-09
计算技术与自动化(2014年1期)2014-12-12
中学生数理化·七年级数学人教版(2014年6期)2014-09-18
移动通信(2011年13期)2011-11-13
