
基于时间特征的可疑资金交易识别研究
2021-09-09 07:36丁晓
现代计算机 2021年19期
丁晓
(中南财经政法大学信息与安全工程学院,武汉 430073)
0 引言
随着经济发展,洗钱犯罪活动也呈现扩大趋势,如果不进行打击,将会对国家和社会造成严重危害。金融机构、特定非金融机构及相关监管部门都有发现、打击这类行为的迫切需求。但是相关数据具有体量大的特征,手工方法已经无法甄别,需要用计算机技术进行分析。
洗钱活动中,部分犯罪分子的资金转移手法有一定规律性。交易时间作为资金交易数据中的一个基本特征,能反映该涉案人员的交易习惯、交易周期等。本文研究以资金交易的时间特征为研究对象,以聚类分析为辅助手段,进行可疑资金交易模式识别研究,并以“靶心模式”这种行为模式的识别为例,设计了详细识别算法。这个算法是无监督学习算法,不需要先验数据,简化了算法的应用。这个算法也是办案人员经验、知识的固化,保证了算法的正确性,而且算法在实际案件侦查中取得了好的成绩。
1 相关研究
在反洗钱领域,分析算法大体可以分为五大类:
(1)洗钱类型分析,是基于已经发现的案例进行检测。Bhattacharyya等人使用支持向量机进行信用卡欺诈检测[1];Luo X使用频繁项模式算法检测账户之间的可疑交易[2];Paula E等使用了深度学习方法[3]。
(2)链接关系分析,找出账户间的实质关系。Dreewski等人使用社交网络分析法进行账号间关系分析,每个账户作为图的一个顶点,具备介数中心度、接近中心度、权威度等属性,还借助社交网络技术,试图分析各个账户在洗钱犯罪中的角色[4];Colladon AF等人试图从网络中发现可疑交易[5]。Jin Y等人使用分层模型根据资金流动的方向对账户进行分层,简化大规模网络,还利用熵权法对各账户主体进行评价,分析各主体在洗钱网络中的重要性[6]。
(3)行为模型。Demetis DS使用EM聚类算法,进行聚类,根据客户的历史数据建立概率密度函数,再据此判断新数据是否可疑,但是它假设的用户交易数据满足高斯分布不一定成立[7]。
(4)风险评估。Larik和Haider改进了欧式自适应谐振理论,消除了基于距离聚类和基于密度聚类的弱点,计算出平衡集群,将正常行为模式和稍微偏离正常行为模式的数据划分到同一个集群,且能通过AICAF索引将两者区分开,当客户数据差异较大时效果较好[8];Vikas J等人使用了基于位图索引的决策树算法评估风险因数,特别之处在于构造决策树的方法,效率很高[9]。
(5)异常检测。异常检测是识别、发现每个账户不同寻常的交易。Raza等将贝叶斯网络和聚类技术结合,先使用模糊C-means聚类算法对客户交易数据进行划分,接着在每个聚类上构造动态贝叶斯网络,使用后验概率分布进行预测[10];Andrew Elliott等人将交易数据构造为有向带权图,综合使用了网络比较分析、社区划分、频谱分析和统计方法,提取出140多个特征,接着将这些特征聚合,最后采用随机森林进行正常、异常的划分[11]。
和上述工作都不同,本文研究是对办案人员经验、知识总结、提炼后,以算法形式实现对人类知识的固定。
2 基于时间特征的可疑资金交易识别算法
2.1 可疑资金交易行为模式分析
通常来说,洗钱过程可以分为处置阶段、培植阶段、融合阶段[12]。处置阶段将非法取得的资金投入洗钱系统;培植阶段通过多种、多账户、多层的金融交易来将非法取得的资金与其来源分离开来;融合阶段将“合法化”后的资金集中起来使用。通过这三个阶段来达到掩盖资金的非法来源和真实所有权的洗钱目的。洗钱案件一般涉及的金额较大,涉案人员为了规避相关部门的自动审查,往往会采取拆分的方式对资金进行多次转移,但交易数额均在报告阈值之内。即便如此,这些行为也会呈现出一定的行为特征。
洗钱活动中资金交易行为模式有很多,本文以一种“靶心模式”为例展开研究。账户所有人若在短时间内有一笔大额资金转入,随后又以多笔小额资金的形式进行转出,这种“一进多出”的交易行为模式,本文将其称作“靶心模式”。除此之外,资金转入、转出的时间间隔不长,具有快进快出的特点;作为中转账户,操作人有收取手续费的行为,转出总金额和转入总金额的比例在一定范围之内;这种转账工具账户具有突发性,每次资金转移行为的前后时间段,往往没有其他资金进出行为。在资金融合阶段,存在类似的但是方向相反的行为模式。
本文以“靶心模式”为例进行探究,提出了一种基于时间特征的可疑资金交易识别算法,目的是识别出呈现“靶心模式”的可疑资金交易。
2.2 基本概念
定义1,交易资金序列。对于序列集X={(d,m,t)│d∈D,m∈R,t∈T},D={′转入′,转出′},R为实数集合,T为离散的交易时间集合,则称序列集X为某账户的交易资金序列。令c=|X|,设p∈X,q∈X,若p≠q,则p(t)≠q(t)。
定义2,转入交易资金序列。交易资金序列I,I⊆X,I={(d,m,t)│d=′ 转入′,m∈R,t∈T},则称交易资金序列为某账户的转入交易资金序列。令m=|I|。
定义3,转出交易资金序列。交易资金序列O,O⊆X,O={(d,m,t)│d=′ 转出′,m∈R,t∈T},则称交易资金序列为某账户的转出交易资金序列。令n=|O|。
2.3 算法框架
“靶心模式”的突发性行为特点,导致了可以采用时间聚类的方法对交易资金序列进行自动划分,然后再结合其他交易特征进行可疑交易的提取和识别。
如果突发性不明显,可能会使得多次资金转移数据混合在一起,导致行为特征不明显,进而降低算法的准确性。
考虑到在“靶心模式”下,每次资金转移行为的转入和转出存在时间上的先后关系,故不对整个交易资金序列进行时间聚类,而是分别对转入交易资金序列和转出交易资金序列进行聚类,这样有利于降低突发性不明显带来的问题;然后根据时间特征,把每个转出聚类簇和转入聚类簇进行对应,汇集成一次资金转移行为的交易簇;再针对交易簇数据进行“靶心模式”行为特征匹配,判断该次资金转移行为是否为可疑交易。
“靶心模式”的可疑交易资金的识别算法框架如图1所示。
(1)对数据进行预处理,转换为交易资金序列;
(2)将交易资金序列按照资金流动方向划分为转入交易资金序列和转出交易资金序列;
(3)分别对转入交易资金序列和转出交易资金序列进行时间聚类,在适当排除噪声、调整聚类方法的参数后,保证两次聚类得到的簇数目一致;
(4)对每一个转入交易资金序列的聚类簇Ca,在转出交易资金序列的聚类簇中寻找一个聚类簇Cb,使得Cb簇中心的交易时间大于Ca簇中心的交易时间,且差值在预设区间内;将Ca、Cb合并为交易簇Ct;
(5)计算每个交易簇中转出总金额和转入总金额的比值,如果不在预设区间,则为不平衡账户,不符合“靶心模式”行为特征;
(6)计算每个交易簇中转出总笔数与转入总笔数的比值;如果不在预设区间,则视为不符合“靶心模式”行为特征;
(7)通过(5)和(6)检测的交易簇数据,就是具备“靶心模式”行为特征的可疑交易数据。
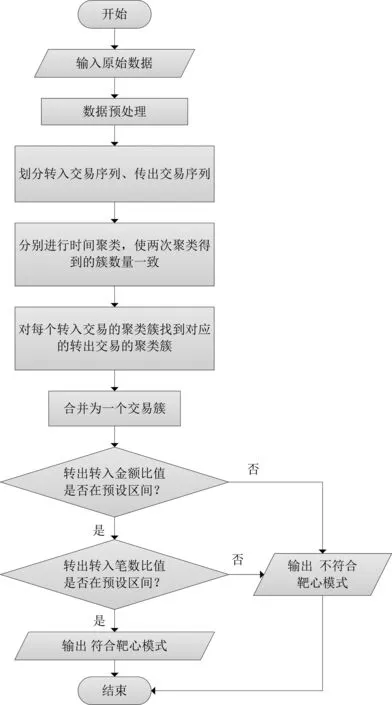
图1 算法流程图
2.4 聚类算法的选取
聚类方法可以按照算法思想分为四类:基于划分、基于密度、基于层次、基于网格。常见的聚类算法有:K均值算法(K-means),基于密度的聚类算法(DBSCAN)、凝聚层次聚类,它们分别对应于基于划分、基于密度、基于层级的聚类算法。
不同的聚类算法在不同的数据集上的表现存在差异,依据数据集的特点选择合适的聚类算法是十分必要的。K-means作为聚类算法中使用最为广泛的算法,其优点是理解简单、容易实现、时间复杂度低,缺点是对噪声和离群值敏感、不适用于结果是非凸形分布的数据、需要给定聚类簇数。DBSCAN的优点是无须预先给定聚类的簇数、可以识别任意形状的数据、可以识别噪声,缺点是不适用于密度不均匀的数据。层级聚类的优点是无须预先给定聚类的簇数,可以发现类的层次关系,缺点是计算复杂度高,容易聚成链状。
在本文研究的“靶心模式”行为特征的交易资金序列,不存在层次关系;转入交易资金序列的特点是交易笔数少,单笔交易金额大,交易时间分散;转出交易资金序列的特点是交易笔数多,单笔交易金额相对转入一般不大,交易时间密集且不一定均匀。考虑到转入交易资金序列中的交易笔数少,即样本点不多,噪声对聚类的影响较大,故使用DBSCAN对转入交易资金序列进行时间聚类。由于转出交易资金序列中交易笔数多,即样本点多,噪声对整体聚类影响不明显,且存在交易时间分布密度不均匀的情况,故使用K-means对转出交易资金序列进行时间聚类。
2.5 算法设计
在识别具备“靶心模式”行为特征的可疑资金交易时,设X为某涉案账户A的交易资金序列,设集合中元素数量为c,故有X={x1,x2,…,xc-1,xc}。
(1)按照资金流动方向,交易资金序列X划分为转入交易资金序列I和转出交易资金序列O,它们各自的交易笔数分别为m和n。则有转入集合I={i1,i2,…,im-1,im},转出集合O={o1,o2,…,on-1,on},c=m+n。
(2)抽取转入交易资金序列I和转出交易资金序列O的时间集合,转入时间集合表示为TI={t1,t2,…,tm},转出时间集合可以表示为TO={t1,t2,…,tn}。
(3)使用K-means算法对转出时间集合TO进行聚类,k从2开始,多轮聚类,取使轮廓系数最大的k值为最终簇数量。
(4)使用DBSCAN算法对转入时间集合TI进行聚类,调整DBSCAN算法中的的参数,包括邻域距离eps和邻域最小样本个数MinPts,排除噪声点后保证聚类得到的簇数量与上一步骤中的k值相同。如果无法得到k个簇,算法终止。
(5)将转入时间集合的聚类结果按照聚类中心升序排序后,定义每个转入时间簇为TI1,TI2,…,TIk,TI=TI1∪…∪TIk;同样,将每个转出时间簇定义为TO1,TO2,…,TOk,TO=TO1∪…∪TOk。
(6)对转入时间簇TIi,找到晚于且最接近于其聚类中心的转出时间簇TOj,且两个聚类中心的时间差小于阈值γ;TIi∪TOj构成一个交易时间簇。在交易资金序列X中按照交易时间查找对应元素,形成对映的交易簇。
(7)给定阈值δ,计算每个交易簇中转入总金额MI、转出总金额MO,若MO/MI>δ,则认为该交易簇的交易行为不符合扣手续费的特征,不符合“靶心模式”。
(8)给定阈值σ,计算每个交易簇中转入总笔数FI、转出总笔数FO,若FO/FI>σ时,则认为该交易簇的交易行为模式符合“靶心模式”,该交易簇中全部交易为“靶心模式”下的可疑资金交易。
在交易资金序列的定义中,已经约束了某账户的每笔交易具有时间唯一性,保证了在步骤(6)中,能够正确地从交易资金序列X中按照时间找到对应元素。
3 实验设计及结果
3.1 数据准备
根据某可疑账户的数据,设计了具有相同行为特点的模拟数据。模拟数据的时间跨度从2017年4月到2017年12月,包含2358条交易数据,有129条转入交易数据,2229条转出交易数据,转入资金总计约4470万元,转出资金总计约3870万元。每个数据项包含交易时间、金额、交易方向和交易对手ID四项内容,其中交易时间为时间戳格式。
接着清洗数据。删除小额交易数据,这往往是正常的消费数据;删除交易对手是自己的数据,这是自己对倒行为,不是本文要分析的内容,排除后可以减少干扰。每个数据项保留交易时间、金额和交易方向三项内容,按照交易方向,将数据划分为转出交易资金序列和转入交易资金序列。最终得到2316条数据。
将清洗后的交易数据进行按月时间-频次可视化后,发现交易频次比较高的集中在2017年5月和2017年7月两个月份,2017年5月有数据260条,转入4条,转入金额238万元,转出256条,转出金额295万元,2017年7月有数据258条,转入8条,转入金额489万元,转出250条,转出金额458万元;其余月份频次低,转入、转出间隔较远,明显不符合“靶心模式”的行为特征,所以选取2017年5月与2017年7月两个月的交易数据进行分析。
3.2 实验过程及分析
使用Python3,调用sklearn.cluster中的K-means方法对转出交易资金序列的时间进行聚类,不断调整参数,绘制轮廓系数随k值变化的曲线,选取效果最佳的k值;调用sklearn.cluster中的DBSCAN方法对转入交易资金序列的时间进行聚类,依据确定的k值,对DBSCAN进行调参。统计聚类结果中每个交易簇的各项指标,观察指标是否符合阈值规定的区间。按照簇中心时间相近、方向对应原则,合并得到多个交易簇。对每一个交易簇进行“靶心模式”识别。
对2017年5月的转出交易资金序列,根据交易时间,k的取值从1到50变化,依次进行K-means聚类;根据每次聚类得到的轮廓系数,画出变化曲线,如图2所示。当k=3时轮廓系数最大,为0.995,所以最终确定簇数量k为3。
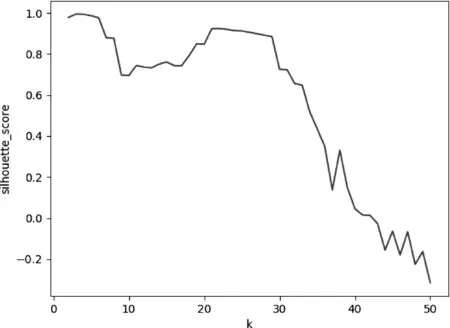
图2 轮廓系数随k值变化曲线
对转入交易资金序列,根据交易时间使用DBSCAN进行聚类。计算[元素个数/k]=1,所以令参数MinPts=1;对交易时间排序后计算差分,得到差分序列,以各差分值为邻域距离参数eps,逐次聚类,取聚类数量为3时的结果为最终结果。
根据聚类结果,将转入交易资金序列划分为3个子序列,每个子序列根据交易时间分别画出箱线图,如图3(a)所示,横坐标代表各聚类中心点的时间顺序,纵坐标为交易时间。同样根据聚类结果,将转出交易资金序列划分为3个子序列,每个子序列根据交易时间分别画出箱线图,如图3(b)所示,横坐标代表各聚类中心点的时间顺序,纵坐标为交易时间。
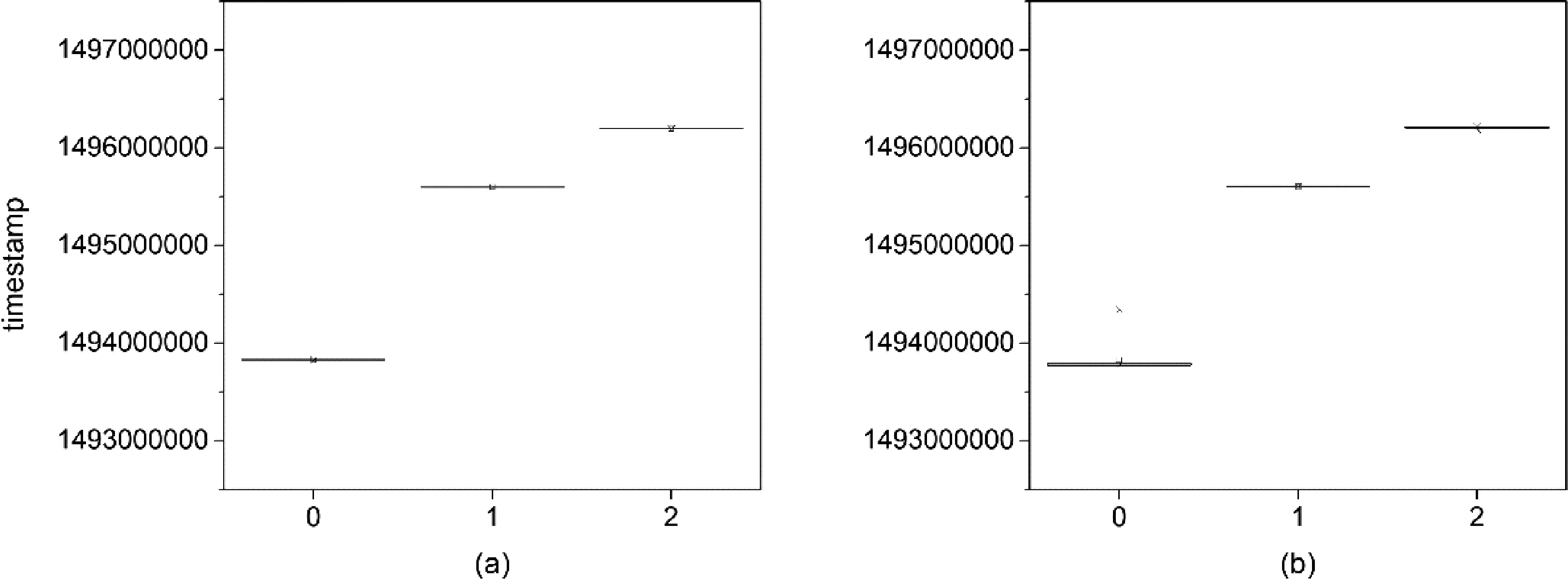
图3 2017年5月交易数据分簇箱线图
箱线图可以反映出每个簇中交易时间的分布情况,具体体现在极大值、极小值、中位数和两个四分位数上。当以上几个值相当接近或完全重合时,箱型图的形状趋近于一条直线。可以看出,2017年5月发生的交易在基于时间特征进行聚类后,每个簇的交易时间十分紧密,每个箱型图的形状趋近于一条直线,且与其他的簇分布位置相隔一段距离,这也反映出聚类的轮廓系数很高。还可以看出,对转入时间集合和转出时间集合聚类后得到的簇分布位置非常一致。
同样的方法,在对2017年7月交易资金序列进行计算后,转出资金序列数据聚类数为2,转入资金序列在聚类时候存在噪声,所以多了一个噪声簇。删除噪声簇后所画箱线图如图4所示。
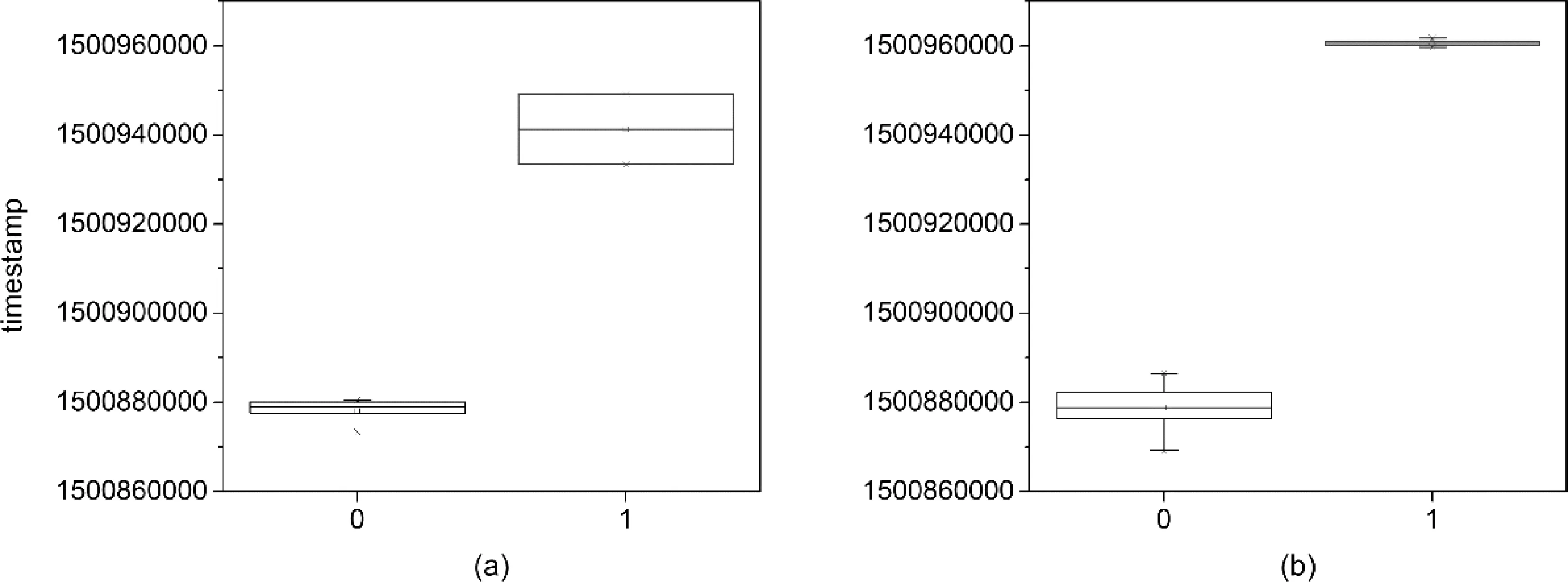
图4 2017年7月交易交易数据分簇箱线图
根据办案干警经验,取δ=1.05,σ=100,即“靶心模式”模式要求转出总金额与转入总金额相差在百分之五以内,每笔转入要对应100笔以上的转出。两个月的交易数据,分别按聚类簇计算,结果如表1和表2所示。

表1 5月数据实验结果

表2 7月数据实验结果
表1中,0号交易簇,两个比值都不在阈值之内,2号交易簇,虽然转出总金额与转入总金额基本平衡,但转出交易笔数不符合“靶心模式”的特点,只有1号交易簇满足设定的阈值,可以判定为“靶心模式”的可疑资金交易。
表2中,0号交易簇虽然转入转出总金额基本平衡,但是转入转出笔数不满足“靶心模式”的特点。1号交易簇满足设定的阈值,可以判定为“靶心模式”的可疑资金交易。
4 结语
本文算法实现了对可疑交易资金的识别,但是这些交易行为是否就一定是违法行为,单纯从交易资金数据上是无法给出准确结论的。本文研究定位于先找出可疑的资金数据,进而提供侦查方向。本文算法已经在经济犯罪案件侦查中得到应用,算法能够在海量资金数据中找到可疑的账户和人员,为案件侦查提供了方向,办案部门据此展开进一步侦查,已经侦破了多起案件。
猜你喜欢
阅读(高年级)(2022年6期)2022-06-17
汽车实用技术(2022年4期)2022-03-07
初中生世界·七年级(2021年2期)2021-03-12
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
阅读与作文(英语初中版)(2019年8期)2019-08-27
娃娃乐园·3-7岁综合智能(2017年8期)2018-02-01
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
电子技术与软件工程(2016年23期)2017-03-06
