
基于相似系数的海温中长期统计预报方法研究
2021-09-13 09:41苑福利
海洋学研究 2021年1期
李 科,苑福利,刘 厂
(1.中国人民解放军 海军研究院,天津 300061;2. 哈尔滨工程大学 智能科学与工程学院,黑龙江 哈尔滨 150001)
0 引言
21世纪被称为海洋的世纪,海洋和人类生活的各方面息息相关,由此凸显出海洋的重要性。海洋的特性及变化可以通过海温的分布及演变规律进行反映,同时,海温演变所引发的各类海洋现象对于海洋经济发展、海上油气资源开发、海洋环境安全保障以及军事活动有至关重要的影响[1]。因此,对海温的准确、快速预报对于国家政治、经济和国防安全等都具有重要意义。
近代以来,世界各国都开展了海温分析预报研究和业务化运行等相关工作。20世纪60年代初,我国逐渐开始进行海温的分析预报研究工作,包括最初的近海海域的海表温度统计预报方法研究,到后来基于站点观测海表温度分析预报方法以及基于卫星观测海表温度的二维空间场分析预报研究[2]。同时,随着科学技术的不断进步和社会经济的发展,对海温的预报也提出了新要求,相应的预报方法研究也呈现多样化的趋势。
海温分析预报的方法主要包含以下三类:经验预报方法、数值预报方法和统计预报方法[3]。其中,经验预报方法主要取决于人的主观因素,客观性较差。数值预报方法存在计算资源需求量大、对初始条件敏感以及受物理时效性限制等缺点。统计预报方法作为数据驱动方法,能够弥补数值预报对计算资源需求量大、预报时效短的缺点;同时由于数值预报方法逐渐逼近可预报性上限,统计预报方法作为数值预报方法的补充手段,其必要性日益凸显。近年来,随着观测技术的不断进步和再分析数据的不断发展,统计预报方法的预报精度有了极大的提升。因此,本文选取统计分析预报作为海温中长期预报的方法。
相似预报作为统计分析预报中简单易实现的方法,是依据相似的大气-海洋形势或者相似的因子场能够产生相似的大气-海洋动力过程,并因此出现相似的大气-海洋现象的客观物理规律,通过计算相似性判据,从大量历史样本中找出相似度高的若干组样本数据,将其预报时期大气-海洋演变结果作为大气-海洋预报结论。相似预报相比于非线性方法具有建模简单、计算量较小的特点,因此在大气-海洋预报中具有广泛的应用场景,是该领域进行快速准确预报的重要方法[4]。1991年,TOTH[5]对比了多种相似预报模型对海面高度的预报能力,证明采用平均绝对误差(MAE)作为相似判据比皮尔逊相关系数更加准确。1995年,ZORITA et al[6]将大尺度气象变化与局部的预报量相联系,将相似方法应用到了降尺度中。2001年,任福民 等[7]采用相似预报对ENSO的重要指标——NINO 3区海温指数进行预报,证明相似预报较持续性预报在预报效果上有明显的提高且对于转折事件具有较好的预报能力。2003年,FERNNDEZ et al[8]提出了将典型相关分析和相似方法相结合的降尺度方法。2006年,HAMILL et al[9]研究了不同相似预报方法对模型结果的订正效果。
尽管基于相似性判据的预报方法在大气-海洋领域的气温、海表高度等预报中已经有了深入的研究,且取得了较好的进展[10-12],但相似预报方法在海温的中长期时间序列预报方面的相关研究比较欠缺[13-14]。因此,本文在长时间海洋观测资料的基础上,构建了基于相似系数的统计预报模型来实现海温中长期预报的相关研究。本文首先运用统计分析方法对长时间的海温资料进行特征分析;之后采用相似系数作为相似性判据构建海温的相似预报模型;最后利用偏差订正方法对相似预报模型的预报结果进行订正,以实现海温时间序列的快速、准确的中长期预报。
1 数据和方法
1.1 数据
本文所使用的海温数据集是由国家海洋信息中心提供的西北太平洋海域再分析产品(CORA v1.0)。CORA数据集的空间范围为10°S-52°N,99°E-150°E。空间格网分辨率为1/2°~1/8°变网格;时间范围为1958年1月1日至2017年12月31日共59 a,时间分辨率为1 d。该数据产品采用的气象驱动场为NCEP(National Centers for Environmental Prediction)气象再分析场,选用的海洋模式为普林斯顿广义坐标系统海洋模式。采用多重网格三维变分海洋数据同化方法,以便有效提取多源海洋数据中的多尺度时空信息,实现现场温盐观测、卫星遥感测温和测高资料等海洋观测资料的同化[15]。
1.2 相似预报方法
相似预报方法是一种经典的统计预报方法,在天气预报中得到了广泛的应用。相比于统计回归分析,相似预报方法的模型更易于构建[16-18]。相似预报方法基本思路是:根据预设的相似准则,通过相似性分析从历史样本数据中寻找出与待预报样本数据的主要特征最为相似的样本,并把历史样本数据的相似性分析结果作为依据,从而实现待预报样本数据的相似预报。大气和海洋学中通用的相似判据有海明距离(Hamming Distance)、相似系数(Similarity Coefficient)和相似离度 (Similar Disparity) 三种[19]。
1.2.1 海明距离
假设以Hij表示两个不同样本数据间的海明距离,则其公式为
(1)
式中:i、j为不同样本数据,m为样本数据的个数,x为每个样本数据的数值,k为样本数据序号。海明距离Hij的取值范围为[0,N),N由样本差值决定。海明距离Hij越接近0,表示不同样本数据间相似性越高;Hij越接近1,相似性越低[20]。此外,欧式距离Oij如下式所示
(2)
由式(1)和式(2)可知,海明距离和欧氏距离具有相同的性质,但是,海明距离反映的是不同样本数据值之间的差异情况,即空间距离,海明距离无法对不同样本数据间相似性的形状差异进行分析。
1.2.2 相似系数
假设以Rij代表样本间的相似系数,其公式为
(3)
式中:i、j为不同样本数据,x为每个样本数据的数值,m为样本数据的个数,k为样本数据的序号。相似系数Rij的值域为[0,1],当Rij越接近1表示不同样本间的相似度越高,越接近0表示不同样本间的相似度越低[4,21]。
1.2.3 相似离度
相似离度是可以反映不同样本之间“形”和“值”的差距的统计量,假设X为样本集,X=(X1,X2…,Xn), 其中Xi=(xi1,xi2,…,xid),则不同样本数据间的相似离度Cij为
(4)
式中,用dk表示不同样本之间的第k个因子差,即
(5)
(6)
dk=xik-xjk
(7)
(8)
式中:m为样本中的因子数量,Dij为值系数;Sij为形系数;Eij为不同样本数据之间差值之和的均值[4,22]。
1.2.4 相似判据选取
为更准确地比较海明距离、相似系数和相似离度三种相似判据的相似特性优劣,选取4组不同的样本数据进行相似性分析[23]。其中,每组样本数据包含5个因子,如下表1所示。

表1 3种相似性判据对比分析Tab.1 Comparative analysis of the three similarity criterions
将所选取的4组不同的样本数据绘制成折线图(图1)。由图1可知,样本数据1和样本数据2、3、4之间存在一定的相似度,样本数据1和2之间的相似度较高。但是从表1中可知,样本数据1和样本数据2、3、4之间的海明距离相等,这与图形结果相矛盾,说明海明距离无法反映不同样本数据之间的形状差异程度。同时,样本数据1和样本数据2、3、4的均值均为6,相似离度均为2.40。这与图形结果相矛盾,说明相似离度也无法作为不同样本数据之间相似度的衡量标准。此外,样本数据1和样本数据2、3、4之间的相似系数分别为0.52、0.30和 0.14,这与图1所示一致,说明相似系数可以作为不同样本数据之间相似度的衡量标准。进一步分析,样本1和样本3、4之间的相似系数差别较大,但是样本1和样本3、4之间的平均绝对误差接近,因此相似系数对数值差异具有一定的分辨能力但无法达到预期。

图1 不同相似性判据的相似性比较示意图Fig.1 Schematic diagram of similarity comparisonfor different similarity criterion
综上分析,相比于其他2种相似性判据,相似系数是同时可以分辨出不同数据样本之间的“值”和“形”差异的相似性判据,但是对样本之间“值”的差异分辨能力不足,需要额外加入偏差量值作为“值”判据的补充。因此本文选择将偏差和相似系数结合,构造新的相似系数,并将新的相似系数作为不同数据样本之间相似性的判断标准。
1.3 预报结果评估方法
基于相似系数构建统计分析预报模型,并通过该模型进行海温的中长期预报得到预报结果后,需要针对预报模型的预报性能进行评估检验。在海洋学中,通常采用平均绝对误差、均方根误差以及相关系数对统计分析预报模型的性能进行评估检验[23-24]。
平均绝对误差(Mean Absolute Error,MAE)是观测值Xi和预测值Yi之间误差的绝对值的算术平均值,所有样本数据差异在平均值上的权重都相等,可以表征出模型预测结果中误差的分布情况。MAE的计算公式为
(9)
均方根误差(Root Mean Square Error,RMSE)是观测值Xi和预测值Yi之间残差的标准差,能够很好地反映出样本数据的离散程度。RMSE的计算公式为
(10)
相关系数(Correlation coefficient, 常用R表示)为反映观测值Xi和预测值Yi之间相关关系的统计性指标,该指标可以定性地描述不同样本数据之间相关性的具体关系及方向,但无法对不同样本数据之间相关的具体程度进行定量确切的描述[25]。R的计算公式为
(11)

2 相似预报模型
2.1 相似预报模型构建
基于相似系数的相似性判据能够较好地反映出不同样本数据间“形”和“值”的差异,本文将已加入偏差的相似系数作为不同样本数据之间的相似性判据,构建海温的单点时间序列相似预报模型。模型构建的基本步骤如下:(1)依据待预报时间及预报时长等参数,选取单个空间格点待预报时间对应的时间序列海温样本数据作为基准样本数据,将基准样本数据与再分析数据集历史样本数据中的同类型样本数据进行相似性判别,依据加入偏差的相似系数的计算结果对各个历史样本进行重新排序得到新历史样本数据集XX=(XX1,XX2,…,XXn),作为模型的预报因子;(2)将计算结果中对应的相似系数集合SC(M)作为预报模型的权重值;(3)计算各个历史样本数据与基准样本数据之间的偏差集合E(M)以及E(M)和SC(M)加权集合平均值;(4)综合上述计算结果,可以得到基于相似系数的海温单点时间序列相似预报模型:
(12)
式中:SSTd表示待预报时段内第d天海温的预报值,M表示选择相似年份的数量,xmd表示第m个相似年份样本中第d天海温的观测值。
基于相似系数的海温单点时间序列相似预报模型流程如图2所示。待预报海域中其他点的海温也可以采用上述模型得到海温的中长期预报结果。

图2 基于相似系数的海温单点时间序列相似预报模型流程图Fig.2 Flow chart of the similarity forecast modelbased on similarity coefficient for a single-pointtime series of SST
本文选取1981—2015年的CORA再分析数据为历史样本数据,2016年的CORA再分析数据作为待预报样本数据,基于上述方法构建基于相似系数的海温单点时间序列相似预报模型。
2.2 预报数据偏差订正
根据上述式(8)分析可知,历史样本数据与待预报样本数据之间存在偏差Eij,因此在进行模型预报之前需要将历史样本数据减去偏差值Eij,以便于实现模型的偏差订正。具体做法如下:定义偏差Eij为待预报年份中指定时间段内数据的算术平均值减去各个历史年份对应数据的算术平均值[26],将计算得到的偏差Eij按照对应相似系数降序排列的方式进行重组以得到偏差序列集合E,E表示第i个历史样本数据偏差,与XXi相对应。按相似系数大小降序排列将历史样本数据分别进行加权集合平均从而得到预报数据。
为进一步解释基于相似系数的海温单点时间序列相似预报模型的预报及偏差订正过程,以研究海域空间点(17.25°N,115.25°E)为研究对象,基于2016年1月1日至2016年1月9日的待预报数据及历史样本数据计算相似系数,进一步实现1月10日温度数据的预报。经过相似系数的计算、排序,结果如表2 所示。

表2 历史样本数据和待预报数据之间的相似系数计算结果排序Tab.2 Sorting of similarity coefficient calculation results between historical sample data and data to be forecasted
分析表2可知,在选择的历史样本数据中,1997年、1987年、2002年、2007年、1988年的历史样本数据与待预报数据的相似系数最高,因此选取这5组历史样本数据进行待预报数据的海表温度预报,在此基础上进行偏差订正得到的海温预报值为24.85 °C,海温观测值为24.15 °C,误差为0.065 °C,预报结果优于气候态的相关结果。
2.3 预报结果
通过上述基于相似系数的海温单点时间序列相似预报模型的建立及预报误差订正等相关计算分析,得到2016年的待预报数据的预报结果,并选取1月、4月、7月、10月作为各个季节的代表月份,基于观测数据对上述所建立的海温单点时间序列相似预报模型的预报能力进行分析验证。
本文以ARIMA模型和气候态预报作为对比方案,采用平均绝对误差、均方根误差和相关系数作为重要指标来评估海温的预报性能。其中,ARIMA模型是指将非平稳时间序列转化为平稳时间序列,然后将待预报变量仅对其滞后值以及随机误差项的当前值和滞后值进行回归建模所得到的预报值;气候态预报指以累年日平均值作为下一年的预报值。
为了进一步详细展示模型预报值与观测值之间的变化趋势,在所选研究海域中随机选择3个空间点(10.375°N,113.875°E)、(17.125°N,113.875°E)和(22.625°N,113.875°E)作为研究对象,将3个空间点在1月、4月、7月、10月的预报值、观测值和气候态值进行比较分析,验证海温单点时间序列相似预报模型的预报能力。
2.3.1 冬季预报结果分析
选取2016年冬季(即1月)的相似系数预报值、ARIMA预报值、气候态预报值和观测值之间的平均绝对误差、均方根误差和相关系数进行分析验证,结果如表3和图3所示。

表3 冬季预报结果MAE、RMSE和R对比表Tab.3 Comparison of MAE, RMSE and R for winter forecast results

图3 冬季不同模型预报值与观测值的对比图Fig.3 Comparison of forecast values among different model and observation values in winter
由表3和图3可知,3个空间点在2016年冬季的相似系数预报值比气候态预报值更接近于观测值,且相似系数预报的预报值与观测值之间的相关系数大于ARIMA预报、气候态预报的预报值与观测值之间的相关系数;预报值与观测值之间的均方根误差和平均绝对误差也均小于ARIMA预报、气候态预报结果,证明该相似系数预报模型在冬季预报实验中具有较ARIMA预报和气候态预报方法更优的预报能力。
2.3.2 春季预报结果分析
选取2016年春季(即4月)的相似系数预报值、ARIMA预报值、气候态预报值和观测值之间的平均绝对误差、均方根误差和相关系数进行分析验证,结果如表4和图4所示。

表4 春季预报结果MAE、RMSE和R对比表Tab.4 Comparison of MAE, RMSE and R for spring forecast results

图4 春季不同模型预报值与观测值的对比图Fig.4 Comparison of forecast values among different models and observation values in spring
由表4和图4可知,3个空间点在2016年春季的相似系数预报和气候态预报的相关系数接近,且大于ARIMA预报的相关系数。空间点(10.375°N,113.875°E)的相似系数预报和ARIMA预报的均方根误差和平均绝对误差均显著小于气候态结果;空间点(17.125°N,113.875°E)的相似系数预报的均方根误差和平均绝对误差均略小于气候态结果且显著小于ARIMA预报结果;空间点(22.625°N,113.875°E)的相似系数预报的均方根误差和平均绝对误差均略大于气候态结果,但小于ARIMA预报结果;此外,3个空间点的相似系数预报结果比气候态预报和ARIMA预报结果均更接近于观测值,证明该相似系数预报模型在春季预报实验中具有较ARIMA预报和气候态预报方法更优的预报能力。
2.3.3 夏季预报结果分析
选取2016年夏季(即7月)的相似系数预报值、ARIMA预报值、气候态预报值和观测值之间的平均绝对误差、均方根误差和相关系数进行分析验证,结果如表5和图5所示。

表5 夏季预报结果MAE、RMSE和R对比表Tab.5 Comparison of MAE, RMSE and R for summer forecast results

图5 夏季不同模型预报值与观测值的对比图Fig.5 Comparison of forecast values among different models and observation values in summer
由表5和图5可知,3个空间点在2016年夏季的相似系数预报值比气候态预报值更接近于观测值,且相似系数预报的预报值与观测值之间的相关系数大于ARIMA预报、气候态预报的预报值与观测值之间的相关系数;预报值与观测值之间的均方根误差和平均绝对误差也均显著小于ARIMA预报、气候态预报结果,证明该相似预报模型在夏季预报实验中具有较ARIMA 预报和气候态预报方法更优的预报能力。
2.3.4 秋季预报结果分析
选取2016年秋季(即10月)的相似系数预报值、ARIMA预报值、气候态预报值和观测值之间的平均绝对误差、均方根误差和相关系数进行分析验证,结果如表6和图6所示。
由表6和图6可知,3个空间点2016年秋季的相似系数预报值比气候态预报值更接近于观测值,相似系数预报的预报值与观测值之间的相关系数和ARIMA 预报、气候态预报的预报值与观测值之间的相关系数相差不大;相似系数预报的预报值与观测值之间的均方根误差和平均绝对误差绝大部分小于ARIMA 预报、气候态预报结果,证明该相似预报模型在秋季预报实验中具有较ARIMA预报和气候态预报方法更优的预报能力。

表6 秋季预报结果MAE、RMSE和R对比表Tab.6 Comparison of MAE, RMSE and R for autumn forecast results

图6 秋季不同模型预报值与观测值的对比图Fig.6 Comparison of forecast values among different models and observation values in autumn
2.3.5 区域预报结果分析
上述内容中,仅在研究海域随机选取3个空间点进行单点时间序列的相似预报实验,由于空间点的选取存在一定偶然性,造成预报结果验证的相关论证不够完整。因此在上述单点验证的基础上,选取整个海域为研究对象,由单点预报拓展到区域海表温度预报。研究区域共计 4 000个空间网格点,去除陆地后有效的空间网格点数为 3 478个。对每个点分别进行基于相似系数方法的海温预报和基于气候态方法的海温预报,将得到的3 478个空间网格点的预报结果进行统计,得到不同季节、不同评估标准下满足要求的空间点的个数如表7所示。

表7 不同季节、不同评估标准下满足要求的空间点个数对比表Tab.7 Comparison of the number of space points meeting the requirements at different season and under different evaluation criteria 个
由表7可知,以春季预报结果为例,基于相似系数方法的预报结果中,相关系数大于0.8的空间网格点为3 107个,均方根误差小于1 ℃的空间网格点为3 385个,均方根误差小于0.5 ℃的空间网格点为 1 893个,平均绝对误差小于1 ℃的空间网格点为 3 386个,平均绝对误差小于0.5 ℃的空间网格点为 1 715个;基于气候态方法的预报结果中,相关系数大于0.8的空间网格点为2 720个,均方根误差小于1 ℃的空间网格点为1 502个,均方根误差小于0.5 ℃的空间网格点为207个,平均绝对误差小于1 ℃的空间网格点为2 067个,平均绝对误差小于 0.5 ℃ 的空间网格点为419个。上述实验结果证明,在春季预报实验中,相同的指标下,基于相似系数方法的空间点个数显著多于气候态方法,其他3个季节的预报实验也有类似的结果,因此证明,基于相似系数方法的海温中长期预报方法优于基于气候态分析的方法。
为进一步研究相似预报结果的空间形态分布,选取整个海域为研究对象,展示不同模型的SST预报场和真实结果之间的对比(图7)。
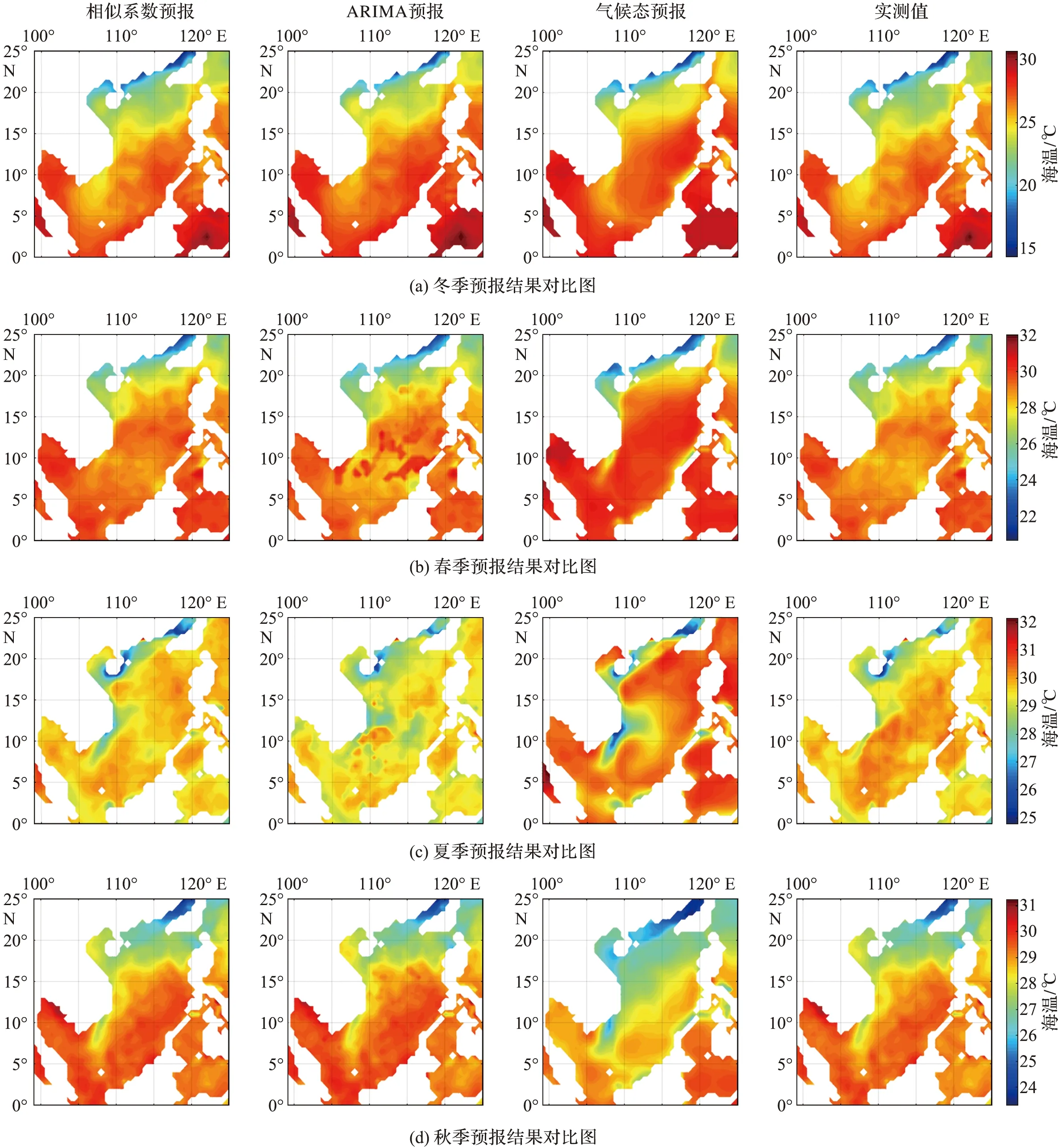
图7 相似系数预报、ARIMA预报、气候态预报和观测值在不同季节预报结果的对比Fig.7 Comparison among similarity coefficient forecasts, ARIMA forecasts, climatologyforecasts and observations at different seasons
由图可知,在4个季节的预报实验中,相比于其他2种方法,相似系数预报结果的空间分布都更加接近于实测值的空间分布。因此证明,基于相似系数方法的海温中长期预报方法优于ARIMA预报方法和气候态预报方法。
3 小结
本文在数理统计分析研究的基础之上,计算分析了3种相似性判据,得出了相似系数作为相似性判据可以更好地分析不同海温数据样本之间相似性的结论,并将相似系数分析方法从气象领域引入到海温的中长期预报应用中,提出基于相似系数的海温单点时间序列相似预报模型,并且分析验证了不同季节对模型预报能力的影响,证明了该相似预报模型在海温中长期预报中的适用性,为海温预报提供了新思路。
猜你喜欢
大气科学学报(2022年2期)2022-05-12
环境技术(2022年1期)2022-03-21
区域治理(2021年1期)2021-06-15
飞天(2019年6期)2019-07-08
军事文摘(2018年24期)2018-12-26
上海航天(2017年4期)2017-09-14
中国化妆品(2017年12期)2017-06-27
太空探索(2016年7期)2016-07-10
太空探索(2015年8期)2015-07-18
新高考·高二数学(2015年2期)2015-05-27
