
基于语义依存关系的汉语复句关系词自动识别*
2021-09-15 08:35杨进才
计算机与数字工程 2021年8期
杨进才 郑 雷 胡 泉
(华中师范大学计算机学院 武汉 430079)
1 引言
在中文信息处理领域,单句处理已经成熟,而复句处理还有很大的空间[1~2]。复句是由两个和两个以上的分句组成,而关系词是连接两个分句的标志[3~4]。关系词的正确识别是分析有标复句关系的前提,对复句的处理有着重要的意义。
关系词在各个复句中出现的搭配、形式、词性都不尽相同,在一些的句子中充当关系词,而在另外句子中可能不充当关系词。这种不确定性给复句关系词的识别带来困难。关系词是复句格式的组成形式,复句格式一旦形成,就会对复句语义进行反制约[3]。如“虽然/但是”充当关系词时,其所对应的两个分句之间的语义关系必然是转折关系。关系词识别不正确时,复句的语义也会出现错误,如例1所示。
例句1:医务人员一面检查,一面问诊(《长江日报》1990年07月25日01版次)。

图1 例句1语义依存分析图
在例句1中,准关系词“一面/一面”充当关系词,表示两个分句是并列关系。例1的语义依存分析将“一面/一面”的词性标注为d(副词),语义依存关系都是Mann(方式角色),且两个分句之间是eSucc(顺承关系)。关系词以及分句间的关系标注错误,错误原因在于未能正确识别“一面/一面”关系词搭配,仅仅是按照“检查”和“问诊”这两个v(动词)之间的语义关系来判断分句之间为顺承关系。
2 相关研究
关系词的自动识别方法分为两种,基于规则的方法和基于机器学习的方法。
基于规则的识别方法通过人工对语料库中的关系词以及在句子中出现的特征进行归纳总结,将提取约束条件表示成规则录入规则库。再根据规则库中的规则去匹配复句特征分析器的分析结果,以此来判断准关系词是否充当关系词。其优势在于直接利用了语言学家总结的规律,识别的准确率相对较高,其缺点是过度依赖人工挖掘的规则;因人工归纳的规则的不全面与准确而导致识别率相对降低,且人工总结规则需要消耗大量人力。贾遂民[6]通过分析汉语复句语料库总结出用于关系词识别的12种特征,以这些特征建立规则的约束条件,再对规则进行匹配进而识别关系词。杨进才[12]等总结出关系词出现在句子中的依存句法特征,采用规则的方法进行复句关系词识别。
基于机器学习的方法使用模型有决策树[13],贝叶斯网络和支持向量机[14]。模型的效果取决于训练的语料库的选取,当训练语料库和测试的模型越相似,结果就越好。相比较基于规则的方法,该方法优点是不需要人工的总结规则,利用机器自动识别,其识别率较高,但是准确率较低。李艳翠[13]中从清华汉语树库中抽取带功能标记和不带功能标记的自动句法树的句法、词法、位置特征,并利用决策树的方法进行复句关系词的识别。
目前,无论是基于规则的还是基于机器学习方法的识别,都只使用到了字面特征或者语法特征,并没有使用到语义层次的上的特征[5~12]。本文所采用的是哈工大LTP-Cloud[17]平台对语料库进行语义依存分析,从分析结果中提取关系词的语义依存特征,再利用随机森林模型对关系词进行识别。
利用LTP-Cloud对例句2进行语义依存分析的结果如图2所示。

图2 例句2语义依存分析图
例句2:虽然目前面临着困难,但是大家有信心克服(《长江日报》1991年05月03日01版次)。
例句2中关系词为“虽然/但是”,其语义依存分析图表明“虽然/但是”在句中词性均标注为mConj(连词标记),分句之间的语义依存关系为eResu(结果关系)。虽然例1、例2的语义依存树中没有标识出关系词,分句间的关系语义依存关系类型也不完全正确,但语义依存关系反映了分句之间的语义关系,反过来为判别准关系词是否充当关系词提供重要的依据。
语义依存分析是建立依存理论基础上[15],可以不受句子表层句法结构的约束,直接获取句子所表达的语义信息。分析句子词之间的语义关联,并以依存结构来呈现。与语法依存结构不同的是语义依存分析不只关注句子的主要动词,而是整个句子。语义依存关系更加深刻地描叙了词与词和句子与句子之间的信息,这更利于复句关系词的自动识别。
3 复句关系词特征提取与表示
本文数据来自于华中师范大学语言与语言教育研究中心开发的汉语复句语料库CCCS(the Corpus of Chinese Compound Sentences),该语料库是专门面向汉语复句关系词研究的语料库,共收录有标复句658447条。利用哈尔滨工业大学的LTP平台对语料库中的复句进行语义依存分析,构建语义依存树库。
通过对语义依存树库中大量复句语料的分析和总结,将关系词提取的特征归纳为以下几类。
1)关系词的词性
在语义依存树库中,共有28种词性。根据语料库关系词的统计可得,关系词在复句中的词性为连词、副词、动词、介词占总数的97.89%。
2)关系词的支配词的词性
在语义依存树中,每一个关系词最多只能有一个父节点,该父节点即为关系词的支配词。如例句1中分别列举了含有“一面/一面”搭配的例句,其词性标注为d(副词),支配词分别为“检查”,“不足”,词性都为v(动词)。
3)关系词支配其它词的词性
语义依存树中,非叶子节点都会有自己的支配词。根据语义依存语法分析,复句关系词在语义依存树中一般为叶子节点。所以如果准关系词支配了其它词,且词性不为wp(标点符号),该准关系词不充当关系词。
4)关系词左右词的词性
在复句中关系词左右词的词性,若为空,则用Null表示。
5)关系词所在复句的位置
以逗号为分割点,将复句划分成为若干分句,提取关系词所在分句的位置。
6)关系词在分句中的位置
本文只考虑关系词在某个分句中最左边、中间、最右边的情况。关系词左端无词右端有词表示为-1,右端无词左端有词表示为1,左右两端都有词表示为0,左右两端都无词表示为-2。
7)关系词之间层次距离
一个关系词按照句子中词的顺序从左或从右的方向开始匹配另外的一个关系词,在这个过程中所隔的词数为搭配距离[4]。在依存树中,则用“依存距离”来表示搭配距离。语义依存树是建立在依存句法树的基础上扩展的树[16],所以依存句法中的“依存距离”概念在语义依存树依旧有效。其指的是支配词和从属词之间的距离。当两个关系词所代表的叶子节点同时向上搜索,找到相同的父节点所经过节点的数值之差即为层次距离,即为两个关系词在依存树中的层次距离。
例3:不是占有她,而是送她回家(《长江日报》1982年07月07日04版次)。
由图3可知,关系词“不是”和“而是”到根节点“占有”的层次距离分别是1和2,其层次距离差为2-1=1,故“不是”和“而是”的层次距离为1。
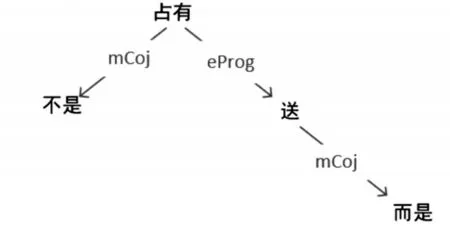
图3 例句3中“不是/而是”语义依存关系
8)关系词与支配词之间的语义依存关系
在LTP处理后的语义依存树中,共有71种语义依存关系[17]。每个词和其支配词之间都只有一种语义依存关系,但在复句中的关系词由于语义依存树的不同可能存在多种依存关系。准关系词在复句中是否充当关系词,会改变其和支配词之间的依存关系,因此准关系词与支配词之间的语义依存关系,可以作为判定准关系词是否为关系词的重要依据。
例4:这二者既有统一的一面,又有矛盾的一面(《人民日报》1980年11月13日)。
例4中有两对准关系词,其中“即/又”充当关系词,“一面/一面”是伪关系词。从图4中可知“即/又”和其支配词之间的都是mConj(连词标记),充当关系词。而“一面/一面”不充当关系词,搭配依存于“统一/矛盾”,语义依存关系为Feat(描写角色),在句子充当了角色,故是不充当关系词。

图4 例句4中语义依存树
9)关系词之间的语义依存事件关系的差集
在语义依存树中71种语义依存关系被分为三类,分别是主要语义角色,每一种语义角色对应存在一个嵌套关系和反关系;事件关系,描述两个事件间的关系;语义依附标记,标记说话者语气等依附性信息[17]。其中事件关系都是以“e”开头的语义依存关系,它很好地刻画不同分句之间的关系,当准关系词之间的语义关系和其所在分句之间的事件关系相同时,则可为准关系词的判断带来一定的帮助。
本文定义的语义依存树中,关系词之间的语义依存事件关系的差集为从关系词所在依存树的节点出发,向上遍历直至根节点,同时建立两个数组A、B存储对应的关系词遍历途中所有的语义事件关系(以“e”开头);然后对A,B数组中的元素做差集;最后将A,B数组中的元素分别取出来,同数组元素以“+”连接,不同数组元素以“/”连接。设A,B数组经过差集后的数组元素分别为A1,A2和B1,B2,B3,可表示为“A1+A2/B1+B2+B3”。具体实例如例4和例5所示。
例5:他们想革新,又怕革新,想突破,又怕突破(《长江日报》1985年10月25日04版次)。
例6:城周虽仅二、三里,但依山负险,异常坚固(《长江日报》1986年04月08日04版次)。
例5中“又/又”充当关系词,由图5可知关系词到根节点的语义依存关系,依次为“mConj,eProg(递进关系)”和“mFreq(频率标记),eResu(结果关系),eResu,eProg”,筛选出事件关系后为“eProg”和“eResu,eResu,eProg”,故例6的语义依存事件关系的差集为“eResu,eResu”,表示为“/eResu+eResu”。图6同理可得,“虽/但”充当关系词,其到根节点“城周”的语义依存关系分别为“mConj,eCoo(并列关系)”和“mConj,eAdvt(转折关系)”,筛选出事件关系后为“eCoo”和“eAdvt”,故例6的关系词“又/又”的语义依存事件关系的差集为“eCoo,eAdvt”,表示为“eCoo/eAdvt”。

图5 例句5中语义依存树
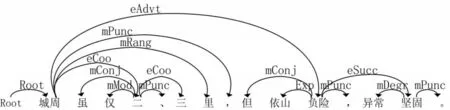
图6 例句6中语义依存树
单个关系词提取特征的方式和上述提取方式相同。其中,涉及到两个关系词之间的特征,在单关系词中是以关系词和根节点特征表示。如:例3中双关系词“不是”和“而是”的层次距离为1。那么单关系词“不是”层次距离为1,“而是”的层次距离为2。同理例6中,“又/又”关系词之间的语义依存事件关系的差集是“eCoo/eAdvt”,那么其中第一个关系词“又”和第二个关系词“又”的语义依存事件关系的差集分别是“eCoo”,“eAdvt”。
4 随机森林模型构建
关系词的自动识别,可以转化为准关系词的分类的问题。随机森林的分类原理是在数据集N中有放回地随机抽取n(n≤N)个数据生成新的训练样本集合,然后在n个样本集中的M个特征随机选取m(m≤M)个特征,生成n个分类树组成随机森林,测试数据的分类结果是根据分类树投票多少而定[18]。
分类树是按照基尼指数来选取特征,以该特征作为分类属性进行节点分类。假设有M个类别,样本点属于第K类的概率为Pk,其概率分布的gini指数如式(1)所示。
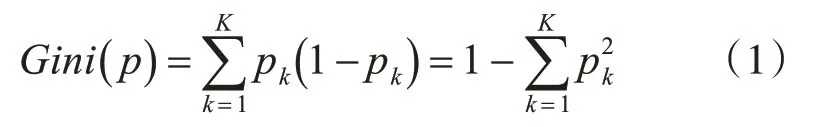
如果样本集合D以某个特征A被分割为D1,D2两个部分,那么在选择特征A的条件下,集合D的Gini指数的定义为
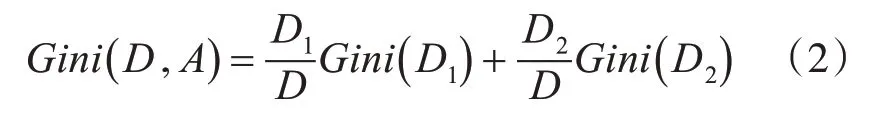
Gini(D,A)表示当以特征A作为分割属性时,对数据集D分割后的不确定性。Gini指数的值越小,分类的正确率就越高。
4.1 随机森林模型改进
由于关系词提取特征比较多,且每个特征对应的属性值也比较多。这可能会导致随机森林决策树过度生长,泛化能力变差。故本文的决策不以单个离散的特征属性作为节点分裂的依据,而是以特征属性的范围进行节点分裂。改进后的决策流程如下。
Step1:首先对提取的特征进行数值化,并对数值化后的特征进行缩放。
Step2:根据基尼指数选取最佳的特征属性的范围,作为当前树的根节点,并分裂成两个节点,其中一个满足根节点的特征范围,另一个不满足特征范围。
Step3:将分裂后的节点作为当前根节点。转到Step2的操作,直到不满足节点分类条件。
Step4:按照Step2和Step3步骤构建随机森林。
随机森林生成的决策树数量大,决策树很大,图7仅显示一颗决策树的一部分。
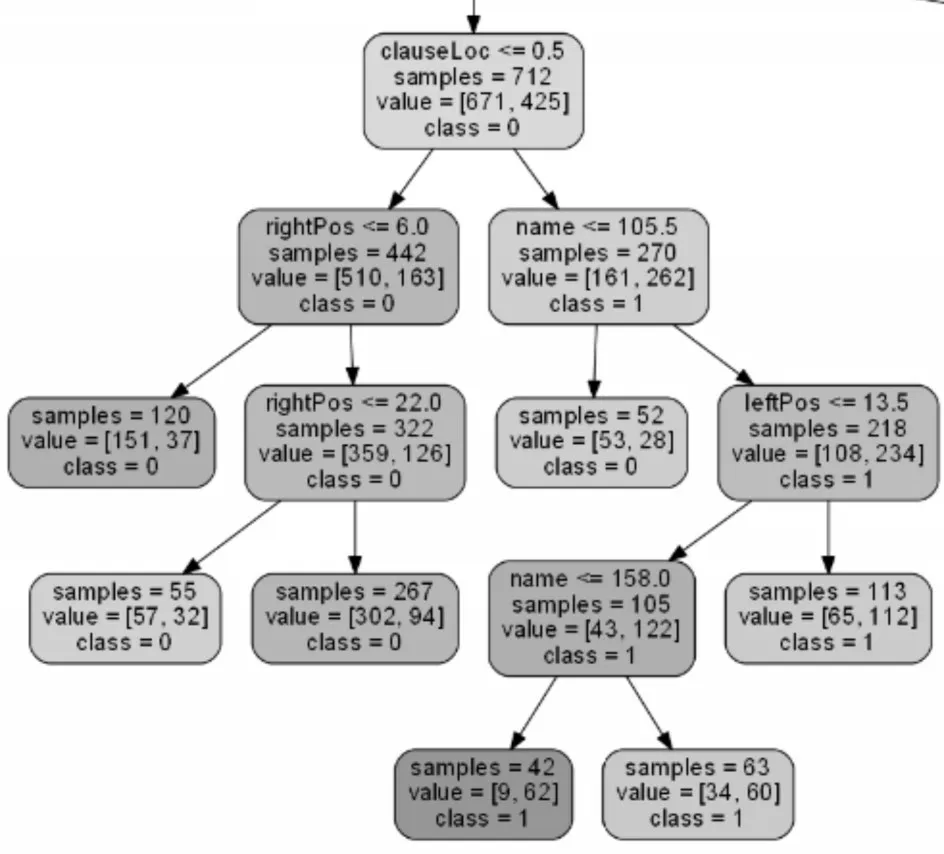
图7 决策树的一部分
4.2 复句关系词自动标识过程
先通过LTP对CCCS汉语复句语料库中的复句进行语义依存解析,提取基于依存关系的复句关系词特征,并将特征向量化,通过本文改进的随机森林算法,构建复句的关系词自动识别模型。为了验证我们模型的有效性,将这些特征数据的4/5用作训练集,剩下的用作测试集来验证模型的合理性。同时也平衡训练集中不同类别的数量,使结果中是关系词和不是关系词提取的特征数量基本保持一致。具体流程如图8所示。
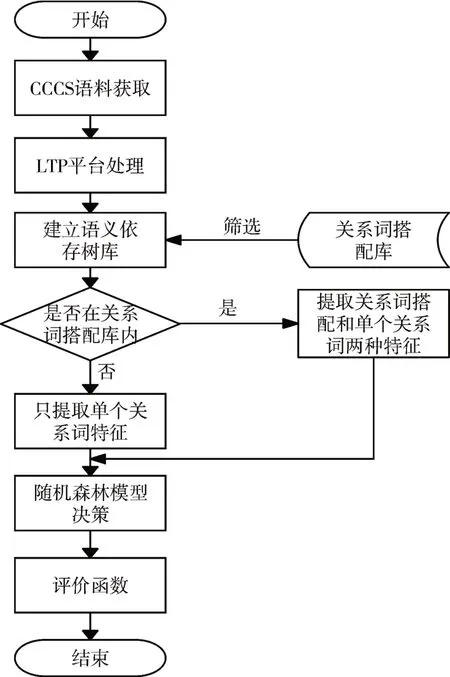
图8 复句关系词自动识别流程图
例7:既直观,又朦胧(《长江日报》1998年09月02日14版次)。
首先将句子经过LTP处理得到语义依存树[[0,“既”,“c”,1,“mConj”],[1,“直 观”,“a”,-1,“Root”],[2,“,”,“wp”,1,“mPunc”],[3,“又”,“d”,4,“mConj”],[4,“朦胧”,“a”,1,“eCoo”],[5,“。”,“wp”,4,“mPunc”]]。其中“既”和“又”为准关系词,且二者也在关系词搭配库中,分别以该句中的单个准关系词和两个准关系词共同作为关系词搭配词来提取特征。提取的特征如表1所示。
将表1提取到的两种特征依次输入随机森林中进行决策,对于单个关系词提取的特征经过决策后的结果:“即”,“又”分别充当关系词的概率为95.12%,85.36%。而关系词搭配提取的特征决策结果:“即,又”共同充当关系词的概率为90.12%。两者都超过50%,故“即,又”充当关系词。

表1 从依存树中提取的特征
5 实验结果分析
本文对复句关系词CCCS数据进行筛选,共得到538190条数据,经过LTP平台处理后,提取单个关系词语义依存特征共1749962条,两个关系词语义依存特征1413573条,平均每条复句可以提取3.25条单关系词特征,2.63条双关系词特征。以50000条复句为一组,取其中10组,分别将单关系词特征和双关系词特征都放入随机森林进行分类。为了试验结果的可靠性和可读性,本文每组数据都经过10次随机森林模型决策,并将其所有结果取平均值,以百分号来表示。其实验详细结果如表2所示。

表2 实验结果简化分析
表2显示单双关系词提取特征后的平均的正确率分别为92.32%和91.13%。其中随机森林中的袋外得分可以有效表示该模型的泛化能力,袋外得分越高则泛化能力越好。单双关系词的袋外得分都达到90%以上,具有不错的泛化能力。同时单关系词识别的结果在不同评价标准下都略好于双关系词,这说明本文的方法更适用于单关系词提取的特征。由于单关系词提取特征与复句中分句的多少无关,故本文的方法适用于所有有标分句类型。同时在随机森林模型中,统计每个特征的重要度,结果如表3所示。
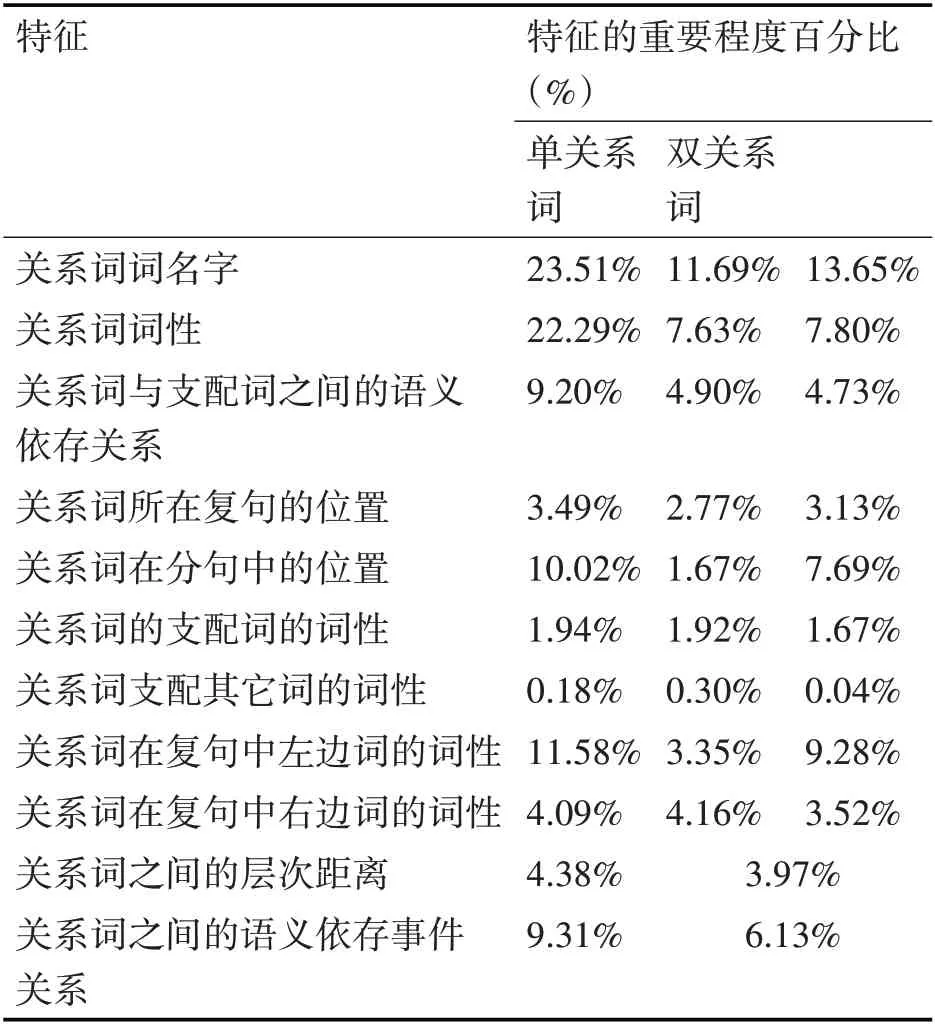
表3 特征的重要度
在表3中,双关系词有两栏,左边表示的是第一个关系词对应的特征,右边表示第二个关系词对应的特征。从表中可知单关系词有11个特征,双关系词有20个特征。无论是使用单关系词还是双关系词提取的特征,词名的特征重要度最高,关系词的词性其次。而关系词与支配词之间的语义依存关系,在单关系词中重要度达到了9.2%,在双关系词中重要度为4.9%+4.73%=10.36%,同时本文的关系词之间的语义依存事件关系特征重要度也达到了9.31%和6.13%。关系词一般不支配其他词,词性一般都为Null,不具备区分能力,故关系词支配其它词的词性的重要程度最低。由此可见,从语义依存关系的角度,使用随机森林方法分析关系词搭配是有效的。
本文的方法与相关的方法如表4所示。

表4 相关工作的比较
文献[12]是利用依存语法中的依存关系,来分析汉语复句中关系词搭配的依存关系,从中总结出约束条件,并把约束条件形成依存关系规则加入规则库中,运用字面特征与语法特征相结合的规则识别汉语复句关系词。文献[13]是根据清华汉语树库的标注方法,利用规则从中提取复句关系词并标注其类别,然后分别抽取带功能标记和不带功能标记的自动句法树的句法、词法、位置特征,进行复句关系词的识别。本文为了统一比较,此处只比较不带功能标记作为识别对象。文献[14]根据复句关系词字面关系和关系词搭配方面进行特征的提取,利用贝叶斯模型对特征集合进行训练和测试,将结果转化为规则库,然后根据规则库进行关系词自动识别。本文的方法比基于决策树模型的方法正确率要高,证明了使用语义依存特征进行关系词识别的可行性。同时本文的正确率比后两个方法低,但优点是不需要人工归纳规则,随着对复句的语义依存识别的准确率上升,关系词识别的正确率必定会有所提升。
6 结语
本文对复句语料库CCCS进行语义依存分析建立依存树库,提取语义依存特征,将对关系词的自动识别从利用字面特征与句法特征提升到语义特征层面。通过随机森林模型进行分类,即保证了该方法的泛化性,又不需要人工的总结规则,节省人力物力。实验结果也证明了该方法的可行性。
本文关系词识别的特征依旧是人工提取,下一步研究将使用神经网络自动提取特征,进行关系词的自动识别。
猜你喜欢
成都理工大学学报·社会科学版(2022年1期)2022-05-26
外语学刊(2021年1期)2021-11-04
时代人物(2019年14期)2019-11-21
新生代(2019年3期)2019-10-19
师道·教研(2017年11期)2017-12-10
小天使·一年级语数英综合(2016年4期)2016-11-19
小天使·一年级语数英综合(2016年8期)2016-05-14
小天使·一年级语数英综合(2016年6期)2016-05-14
小天使·一年级语数英综合(2015年10期)2015-10-14
改革与开放(2010年6期)2010-06-04
