
基于《伤寒论》的命名实体识别研究*
2021-09-15 08:36王菁薇骆嘉伟晏峻峰
计算机与数字工程 2021年8期
王菁薇 肖 莉 骆嘉伟 晏峻峰
(1.湖南中医药大学信息科学与工程学院 长沙 410208)(2.湖南中医药大学中医学院 长沙 410208)(3.湖南大学信息科学与工程学院 长沙 410082)
1 引言
《伤寒论》是东汉末年张仲景所著汉医经典著作,是一部阐述外感病治疗规律的专著,其以非结构化形式储藏着丰富可靠的知识[1]。由于古籍中喜用虚词、指代词,相较于现代自然语言处理,中医药古籍的处理更具有挑战性。中医药古籍命名实体识别是指根据具体古籍的内容,从中识别出关键信息的过程,涉及疾病、证候、症状、方药等中医类信息。近些年,从最初基于规则和字典的方法到现在的深度学习方法,命名实体识别技术在医学领域取得了一些进展,但中医药领域相关的命名实体识别模型较少,用于中医药古籍的模型更是微乎其微[2]。高佳奕等[3]对名老中医临床肺癌医案进行序列标记,利用条件随机场构建中医临床信息抽取模型,抽取结果符合中医辨证理论,能有效实现中医临床医案症状命名实体识别。祝锡永等[4]改进并构建了用于医疗领域的中文命名实体识别模型——CTD-BLSTM模型。高佳奕等[5]尝试使用多种命名实体抽取模型对中医肺癌数据集上进行实验。肖瑞等[6]针对部分名老中医医案著作构Bi LSTM-CRF模型,识别的准确率达到97.23%。以上学者的研究证明了构建中医药古籍命名实体识别模型的可行性。本研究尝试将预训练模型ALBERT应用于中医药古籍,基于《伤寒论》进行实验,并与BERT模型训练结果进行对比,为深度挖掘张仲景《伤寒杂病论》及其他中医药古籍提供参考[7]。
2 资料与方法
2.1 数据来源
数据来自宋版《伤寒论》[8]。
2.2 数据预处理
考虑到《伤寒论》条文描述中,包含“太阳病”等疾病特征、“太阳中风”等证候特征、“恶寒”等症状特征、“桂枝汤”等处方特征、“桂枝”等药物特征[9]。本研究根据以上实体特征,将《伤寒论》中实体划分为疾病、证候、症状、处方、药物五类不同标签,与其无关的信息划分为非命名实体组成部分。疾病、证候、症状、处方、药物分别记作disease、syndrome、symptom、prescription、medicine,非命名实体组成部分记作O。利用BIO标注法进行标注,具体方法见表1。如《伤寒论》条文第十二条可以标注为“太/B-syndrome阳/I-syndrome中/I-syndrome风/I-syndrome,/O阳/B-symptom浮/I-symptom而/O阴/Bsymptom弱/I-symptom,/O阳/B-symptom浮/I-symptom者/O,/O热/B-symptom自/I-symptom发/I-symptom;/O阴/B-symptom弱/I-symptom者/O,/O汗/Bsymptom自/I-symptom出/I-symptom,/O啬/B-symptom啬/I-symptom恶/I-symptom寒/I-symptom,/O淅/B-symptom淅/I-symptom恶/I-symptom风/Isymptom,翕/B-symptom翕/I-symptom发/I-symptom热/I-symptom,/O鼻/B-symptom鸣/I-symptom干/B-symptom呕/I-symptom者/O,/O桂/B-prescription枝/I-prescription汤/I-prescription主/O之/O”。

表1 命名实体标注方法
2.3《伤寒论》命名实体识别模型构建
常见的命名实体识别模型结构,如图1所示,一般包括将输入的文字生成向量的Embedding层、捕捉输入的双向语义依赖的特征提取层以及给标签添加一些限制确保结果有效性的输出标注层。本研究选取Bi LSTM模型[10]作为特征提取层、CRF模 型[11]作 为 输 出 标 注 层,分 别 以word2vec、BERT-wwm以及ALBERT作为Embedding层构建了BiLSTM-CRF模型、BERT-BiLSTM-CRF模型及ALBERT-BiLSTM-CRF模型。

图1 命名实体识别模型结构
双向长短时记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)由前向长短时记忆网络(LSTM)和后向长短时记忆网络(LSTM)组成。对于任一时刻t的输出,前向LSTM记录了t时刻以及t时刻之前的信息,后向LSTM记录了t时刻以及t时刻之后的信息。相较于长短记忆网络(LSTM)模型,BiLSTM模型结合了输入序列前向和后向的信息,在自然语言处理的应用中,考虑到“上文”的同时,考虑到了“下文”的信息。条件随机场(Conditional Random Fields,CRF)可以考虑到已经标注好的数据的相邻标记信息,避免得到不合语法的标签序列,如在一个句子中,疾病的起始词后不应接症状的中间词。
BERT[12]是2018年Google提出的预训练模型,采用了MLM随机屏蔽掉部分token,然后预测被屏蔽掉的token。2020年Yiming Cui等[13]考虑到传统NLP中的中文分词,将全词Mask应用在中文中,发布了BERT-wwm(Whole Word Masking)。在BERT的基础上,ALBERT[14]对词嵌入参数进行因式分解,成功将嵌入层的参数缩小为原来的1/8;对隐藏层间参数进行共享,使隐藏层参数量变为原来的1/12或者1/24;同时提出了一种新的训练任务——句子间顺序预测,给模型两个句子,让模型去预测这两个句子的前后顺序,使模型能学到更多句子间的语义关系。
3 实验结果与分析
3.1 实验设置及评价指标
为了验证ALBERT-BiLSTM-CRF模型的有效性,将其分别与BiLSTM-CRF模型、BERT-Bi LSTM-CRF模型进行了比较。
本研究使用多分类任务中的常用评估指标——精确率(precision,P)、召回率(recall,R)以及精确率和召回率的调和平均(F1-score),评估各模型在《伤寒论》命名实体识别任务中的性能[15]。此外,为了保证实验结果的可靠性,对训练数据进行随机打乱处理,并采用五折交叉验证对样本集进行划分。每个模型均独立训练五次,然后将其平均值作为最终的预测结果。
3.2 实验结果
为了验证ALBERT-BiLSTM-CRF模型在中医古籍实体识别中的有效性,利用随机打乱标注好的《伤寒论》对各模型进行性能评估,结果如图2~4所示。
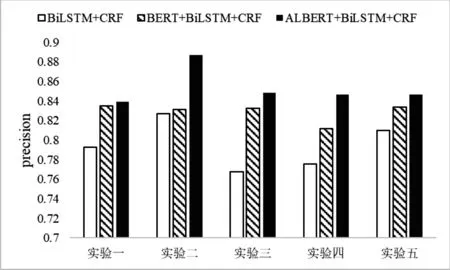
图2 各模型实验结果—P

图3 各模型实验结果—R

图4 各模型实验结果—F1-score
从实验结果可以看出,结合BERT、ALBERT等预训练模型识别效果优于BiLSTM-CRF模型,按照F1-score值对各模型的性能进行排序,结果如下:ALBERT-BILSTM-CRF>BERT-BILSTM-CRF>Bi LSTM-CRF。结果表明蕴含语义关系得到的嵌入向量有助于使中医药古籍实体识别效果的提升;而ALBERT虽然在BERT的基础上大大削减了模型参数量,但其提出了句子间顺序预测任务,使得Al-BERT-BiLSTM-CRF模型在实验中的效果优于BERT-BiLSTM-CRF模型。
4 结语
本研究应用ALBERT-BiLSTM-CRF模型进行中医药古籍命名实体识别,对《伤寒论》进行实验。结果显示,相较于传统的BiLSTM-CRF模型,预训练模型对命名实体识别任务的效果有较大的提升;相较BERT模型,优化后的ALBERT模型更适用于《伤寒论》的命名实体识别任务。中医药古籍是历代医家在临床实践中总结得到的智慧结晶,提高命名实体识别技术在中医药古籍中的识别效果,对传承中医药古籍具有重大意义。本研究采用的数据集较小,各类实体分布不均衡,症状实体间存在表达的多样性,缺乏对古文中指代词的处理。今后研究将进一步增加数据集,结合实体链接、融合对齐以及语义理解等方法,提高模型对中医药古籍中命名实体的识别效果。
猜你喜欢
基层中医药(2022年5期)2022-10-24
布达拉(2020年3期)2020-04-13
出版人(2019年11期)2019-12-19
世界中医药(2018年7期)2018-09-10
中西医结合心血管病电子杂志(2016年23期)2017-03-03
中国民族民间医药·下半月(2016年10期)2016-12-13
中国中医药图书情报(2015年5期)2015-11-05
图书馆界(2013年6期)2013-03-11
图书馆界(2013年3期)2013-03-11
浙江中医杂志(2004年2期)2004-09-14
