
基于词聚类CNN和Bi-LSTM的汉语复句关系识别方法*
2021-09-15 08:35孙凯丽邓沌华
计算机与数字工程 2021年8期
孙凯丽 李 源 邓沌华 李 妙 李 洋
(1.华中师范大学计算机学院 武汉 430079)(2.华中师范大学语言与语言教育研究中心 武汉 430079)
1 引言
汉语复句是衔接小句与篇章的重要单位,在汉语句法中占有重要地位。汉语言研究中,若要取得“句处理”的重大进展,则汉语复句的句法语义自动判定问题便成为了主要的研究内容[1]。复句是由两个或以上的分句构成,汉语言中近2/3的句子是复句。因此,对汉语句子的研究实则是对复句的研究。复句的关系识别是汉语言应用中语义自动分析的关键,是自然语言理解的基础研究问题。复句关系识别的主要任务是研究复句句间的逻辑语义关系,正确的判断逻辑关系意味着能够有效地理解复句。因此,该课题的研究有利于提升篇章分析[2]、自动问答[3]、信息抽取[4]等系统的性能,并推动多种自然语言处理任务的发展。
复句根据关系标记标示能力的强弱分为充盈态有标复句和非充盈态有标复句。如例1所示,复句中存在关系标记“除了…还…”,由该关系标记可以明确地标示例1属于并列关系复句,因此,像这样的复句称为充盈态有标复句。例2复句中由于关系标记的缺失,此时若判定复句语义关系,就不能仅仅通过关系标记来进行标示,而需结合句子具体的语义来分析,这样的复句称为非充盈态有标复句。如在例2中,a)、b)两复句虽含有相同的关系标记“万一”,但通过具体的语义分析后判定a)为因果关系复句,b)为转折关系复句。所以,在非充盈态有标复句中若要正确地识别语义关系,需要充分考虑复句的语义、语境、句法等特征信息,而不是仅仅单纯地依靠关系标记来确定。
例1除了在第二师范教国文,还在育德中学讲国故。(梁斌《红旗谱》)
例2a)万一造成全厂断水,会带来不敢想象的灾难!(蒋杏《写在雪地上的悼词》)
b)听从郭芙的注意,万一事发,师母须怪不到他。(金庸《神雕侠侣》)
本文所研究的内容主要是针对非充盈态二句式复句进行关系识别,使用的语料为邢福义等[5]在2005年发布的汉语复句语料库(the Corpus of Chinese Compound Sentence,CCCS)[23]和 周 强 等[6]在2004年发布的清华汉语树库(Tsinghua Chinese Treebank,TCT)。其中CCCS语料库共收录658447条有标复句,语料来源以《人民日报》和《长江日报》为主。TCT语料库则是从大规模经过基本信息标注的汉语平衡语料库中抽取而来,具有100万汉字规模的语料文本,句子总量达到44136条,复句数量为24444条。
基于CCCS和TCT语料库,本文提出了一种基于词聚类算法的卷积神经网络(CNN)与双向长短时记忆(Bi-LSTM)网络相结合的联合模型架构,并引入融合词向量的方法解决非充盈态二句式复句关系识别的任务。本文所提出的联合模型架构能够充分利用CNN与Bi-LSTM网络结构的优势,在提取文本局部语义特征的同时又获得了文本整体的语义信息以及长距离的语义依赖特征。其中,本文模型中是对原始的CNN进行改进,将池化层替换为Bi-LSTM网络层,目的是在提取文本内局部语义特征的基础上,减少池化操作所带来的语义信息的丢失。另外,本文在最初阶段使用基于K-means的词聚类算法,实现对复句词向量的聚类建模,充分挖掘复句中单词间的语义相似特征信息,增强网络结构的学习能力。整体而言,本文采用局部语义特征与全局语义特征相互结合相互补充的思想,对复句向量矩阵联合建模,最终实现复句关系类别的正确判定。经过验证,本文所提模型取得了较好的识别性能,对比杨进才[11]等的最好识别方法有着明显的性能提升,准确率提升约3.4%。
2 相关工作
汉语复句的关系识别主要通过分析复句语义、语境,即上文文本信息来判断复句所表述的语义关系倾向。自2001年由邢福义[7]提出的复句三分系统,根据分句间的逻辑语义关系将复句分为因果、并列、转折三大类。在这之后,许多专家学者展开了对复句关系自动判别的研究,并取得了一些显著的成果。复句关系识别技术大致可以分为基于规则的方法和基于统计模型的方法,又或是两者的结合。周文翠等[8]选取复句主语、谓语等相关语法特征,并根据《知网》将特征进行量化,最后使用支持向量机(SVM)训练模型,实现并列复句的自动判别。Huang等[9]利用决策树算法提取句子的词性、长度、关系标记等特征,从而识别汉语句子的因果、并列关系。李艳翠等[10]基于已标注的清华汉语树库,结合规则与句法树的相关特征采用最大熵、决策树和贝叶斯的方法进行关系词与关系类别的判别研究。杨进才等[11]将非充盈态二句式复句作为研究对象,结合关系标记搭配理论以及句间的语义信息,提出了一种基于语义相关度算法的关系类别自动判别方法。目前,越来越多基于深度学习的方法被广泛地应用到自然语言处理任务中。该方法相较于传统模型能够大幅度地减少特征工程的工作量,并在节省人工的同时,提升模型的效果。具体主要表现在语言建模中,如Kim[12]首次将CNN运用到句子分类任务中取得了较好的效果,同时给出了模型的几种变体。Zeng等[13]提出了一种基于CNN的模型方法,同时加入单词位置特征、名词词汇特征等实现关系分类。Cai等[14]将CNN与LSTM进行结合形成一种新的模型架构BRCNN,以此获取双向文本语义信息,解决了句子级别的关系分类问题。然而,在汉语复句相关研究中,深度学习方法还尚未有实现的先例,本文将结合深度学习方法与复句句法特征展开对关系类别的自动标识研究。
3 基于词聚类的CNN和Bi-LSTM结合的模型方法
为了实现复句关系类别自动判定的任务,本文提出了基于词聚类的卷积神经网络和双向长短时记忆相结合的网络架构,模型结构如图1所示。该模型主要由两部分组成,底层是传统的K-means聚类模型结构,上层是经改进的卷积神经网络结构。本模型的整体流程:首先使用词嵌入模型对输入的文本句子进行编码,转换为由词向量组成的句子表示。之后,经过K-means聚类算法对句子单词进行建模,获得单词间的词义相似特征。然后,将句子表示与词义相似特征进行拼接输入经改进的CNN模型中,提取句子的局部语义特征,同时通过Bi-LSTM网络层又获得双向语义依赖特征。最终,通过全连接分类层完成复句关系类别的标识。
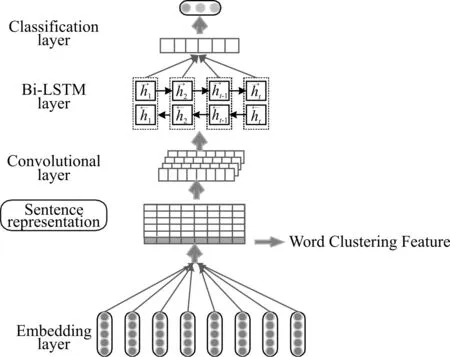
图1 基于词聚类CNN与Bi-LSTM结合的模型结构
3.1 输入和编码层
模型最初阶段,首先要做的是将复句中单词转换为机器可识别的实数向量。本文采用的是由Word2Vec词嵌入模型训练得到的词向量表示。另外,本文使用语言技术云平台LTP[24]对汉语复句进行分词,得到词序列[x1,x2,…,xn],其中n为句子长度。单词向量xi∈R1×d,d表示词向量的维度,由单词向量组成的句子表示为x1:n∈Rn×d,如式(1)所示,其中⊕为连接操作。
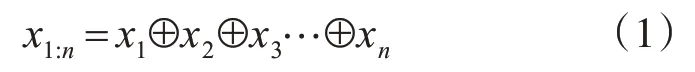
3.2 K-means词聚类层
给定文本句子数据集为D,含有文本S{s1,s2,…,sm},其中每个文本句子si中由n个单词组成,如式(1)中的x1:n。数据集D中文本S所包含句子的单词总量记为N,K-means算法实现将N个单词对象自动归聚到K个簇C1,…,CK中,其中Ci⊂D且Ci∩Cj=Ø。该算法实现了簇内对象高相似性和簇间对象的低相似性[15]目的。
K-means算法过程如下。
1)簇的个数K值初始化为K=N*1%;
2)从D中随机选择K个对象作为初始簇的质心点ci,i∈[1,k];
3)计算D中单词对象x与每个质心点ci之间的欧氏距离d ist(x,ci),将x分配到欧氏距离最近的簇ci中,即最相似的簇;
4)更新簇质心点,即重新计算每个簇中对象的均值点;
5)Repeat,untilD中簇的质心ci不再改变。
词向量本身蕴含丰富的语义信息以及上下文信息,本文利用K-means算法独有的簇内高相似性特点对单词向量进行建模,深层次的挖掘单词间的语义相似特征。同时,采用簇内替换的方法对该特征进行表示,即文本句子si中的单词替换为各单词所在簇的质心向量,重组句子形成句内单词相似特征表示s′i,以此来增强神经网络的学习能力。
3.3 卷积层
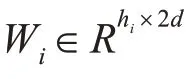


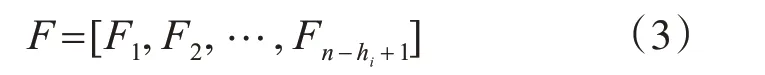
3.4 Bi-LSTM网络层
循环神经网络(RNN)是对前馈神经网络的改进,是一种能够较好地处理序列数据的链式网络结构,但是RNN在训练过程中随着文本序列长度的增加会带来梯度爆炸和梯度消失的问题[16~17]。为了解决该问题,Hochreiter等[18]提出了长短时记忆(LSTM)网络,它的特点在于引入了记忆单元(memory cell)来控制整个数据流的传输。在每个t时刻,其输入向量不仅有当前时刻单词xt∈Rd,还有前一时刻隐藏层状态ht-1。具体计算如下:
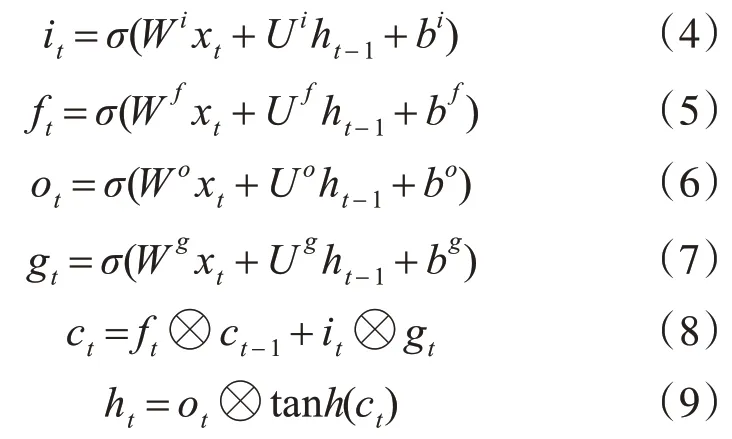
其中,σ是一个sigmoid函数,⊗表示元素相乘操作。tanh是一个非线性激活函数。it、ft、ot在这里分别是指输入门,遗忘门和输出门。在最初时刻t=1时,ho和c0被初始化为零向量,ht是t时刻以及之前时刻所存储的所有有用信息的隐状态向量表示。
LSTM网络的优点是能够获得当前时刻和之前时刻所有单元的信息,其缺点是无法获得当前时刻之后的所有单元信息,因此双向长短时记忆(Bi-LSTM)网络便应运而生,它是对LSTM的进一步改进,即分别用前向和后向的LSTM来获取过去和将来所包含的隐藏信息,由这两部分信息组成最终的输出信息,如式(10):

通过该Bi-LSTM层实现了捕获语义的长期依赖关系特征,以此提高模型的性能。
3.5 语义关系识别层
该层为最后的语义关系识别层,实则是带有Softmax函数的全连接层,根据以上卷积层与Bi-LSTM网络层获得的复句特征表示,作为全连接层的输入,这里记作Xf。具体计算如下所示:
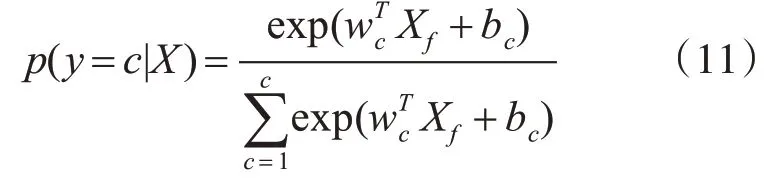
式中:假设关系类别有c类。wc,和bc分别是权重矩阵和偏置项,是随机生成的可训练参数。
4 实验结果与分析
4.1 实验数据集
本文实验采用的数据集为汉语复句语料库和清华汉语树库。汉语复句语料库CCCS是一个针对汉语复句研究的专用语料库,它主要由华中师范大学语言与语言教育研究中心开发。该语料库共包含有标复句658447条,收录的语句主要来源于《人民日报》和《长江日报》。清华汉语树库TCT是从大规模的经过基本信息标注的汉语平衡语料库中抽取而来,是一个具有100万汉字规模的语料文本。其中,句子总量达到44136条,复句数量为24444条。该树库中,不同文体语料分布情况为文学37.25%,学术4.64%,新闻25.83%,应用32.28%。
实验中数据样本将复句的关系类别分为因果关系类别,并列关系类别和转折关系类别。CCCS语料库中,我们在本实验中共选取13215条非充盈态二句式复句做为实验样本集,其中有3224条因果关系复句,7960条并列关系复句,2031条转折关系复句。在TCT语料库中由于语料文本有限,我们共使用8577条非充盈态复句样本,其中包含2112条因果关系复句,5309条并列关系复句,1156条转折关系复句。表1展示了实验中数据集的划分。
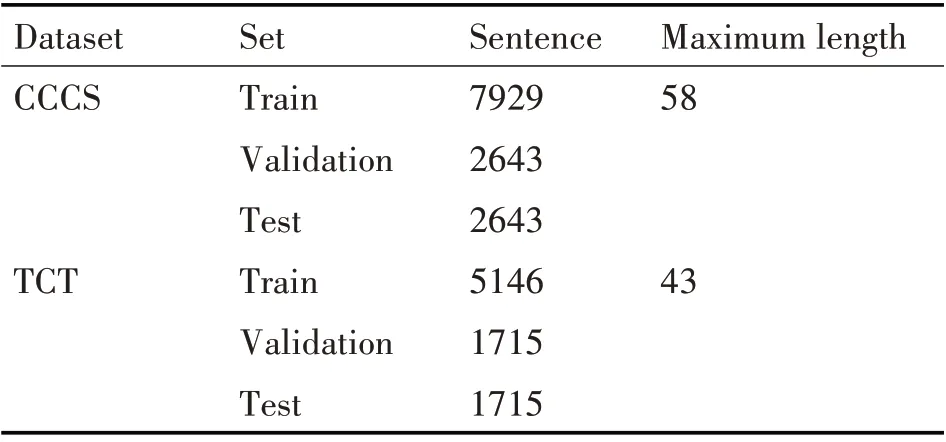
表1 实验数据统计
4.2 实验模型参数设置
本文使用Word2Vec[19]预训练的词向量,维度设置为300。另外,由于卷积神经网络需要固定长度的句子作为输入,因此分别统计两个数据集中最长复句所含的单词数作为固定输入长度,句子长度不足的采用随机均匀分布函数填充为[-0.25,0.25]的随机向量值。实验中采用dropout策略防止过拟合现象发生,设置值为0.5。同时实验的目标函数中又加入L2正则化项来提高模型的性能,并采用反向传播算法(Back Propagation)[20]以及随机梯度下降(SGD)优化算法[21]对目标函数进行优化。Bi-LSTM网络层的隐含层维度设置为256维。实验过程中使用网格搜索的方法调整模型最佳的参数值,并且通过每1000个epoch验证一次模型的表现力,主要参数值具体如表2所示。
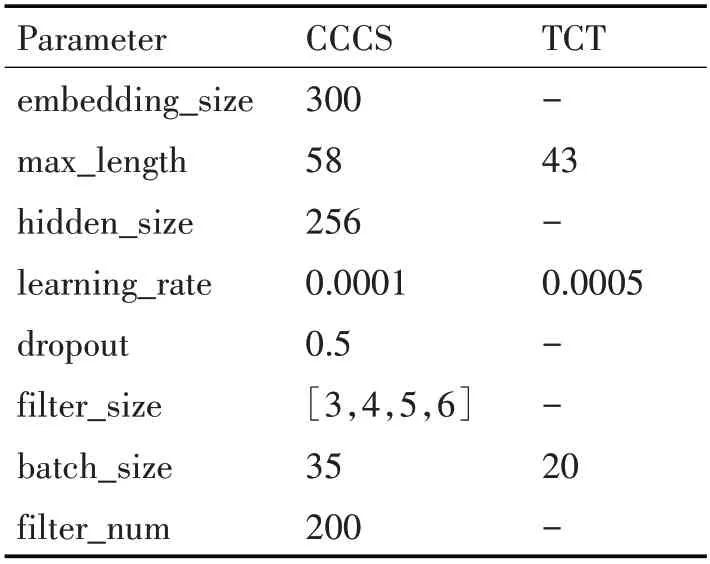
表2 模型超参数设定
4.3 实验对比分析
本文采用正确率作为模型的评价指标。它是广泛应用于信息检索和统计分类领域的度量值,用来评估模型结果的质量。同时,为了检验本文所提模型BCCNN的性能,实验中设置了两个基准系统:1)机器学习模型方法SVM[8],该模型使用复句主语、谓语再加上时间副词、方位词等相关特征,借助《知网》将特征量化,最终实现复句关系分类。2)最大熵模型[22],该方法根据依存句法树中句子的成分特征以及依赖关系特征,并且加入单词对特征进行建模实现句间关系的识别。3)统计学习方法语义相关度算法[11],该方法利用复句核心词跨度、词频以及关系词搭配距离进行计算复句语义相关度,判别复句的关系类别。表3展示了使用深度学习方法的本文所提模型与以上基准模型性能的比较。为了验证所提方法的可行性,同时在TCT数据集中进行相同的实验。
经实验验证,本文所提出的方法在非充盈态二句式复句上的关系类别自动标识正确率达到了92.4%和90.7。实验结果对比分析如表3所示。
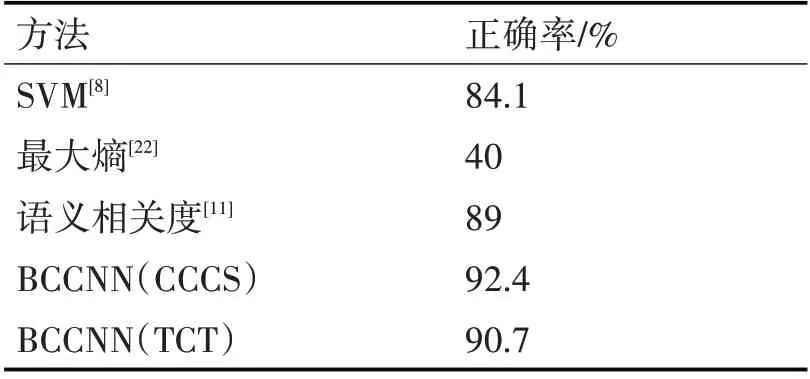
表3 实验对比结果
其中,传统机器学习模型SVM识别方法仅能识别并列与非并列复句的关系类别。而基于最大熵的句间关系识别方法的正确率较低,不能满足实际应用中的需求。
本文所提模型BCCNN与目前效果最好的基于语义相关度识别方法相比,其正确率提高了1.7%~3.4%,并且模型的可拓展性也有所提升,它可以引入不同复杂度的神经网络结构,较语义相关度识别方法更加适应当下自然语言中高维度、大数据等特点的计算环境。
5 结语
本文在复句语义关系识别任务上采用局部语义特征与全局语义特征相互结合相互补充的方法,提出了一种针对二句式非充盈态有标复句的基于词聚类的CNN与Bi-LSTM相结合的识别方法。该方法同时考虑了句间自身所蕴含的语义信息、上下文信息和单词间的语义相似信息以及局部特征信息,而且还考虑了复句内部的长距离语义依赖特征信息,这些特征信息促进了复句关系类别的识别。在复句关系识别任务中,复句的句间语义、语境以及句法等特征信息对于该任务是尤为重要的。在本文所提模型中仅考虑了词语间的相似性特征,对于句间的语义相似性,结构特性等未考虑,同时也只是针对二句式非充盈态有标复句展开研究。对于无关系标记的复句关系类别的识别,以及进一步对神经网络模型的再次改进,提高识别正确率是本文下一步的研究工作。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
成都理工大学学报·社会科学版(2022年1期)2022-05-26
外语学刊(2021年1期)2021-11-04
时代人物(2019年14期)2019-11-21
新生代(2019年3期)2019-10-19
师道·教研(2017年11期)2017-12-10
长江学术(2015年1期)2015-02-27
改革与开放(2010年6期)2010-06-04
安徽理工大学学报·自然科学版(2008年1期)2008-06-25
