
一种提高手机人民币图像真伪识别率的CNN框架*
2021-09-15 08:35郭素珍任明武
计算机与数字工程 2021年8期
郭素珍 任明武
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
随着我国在世界舞台上经济政治实力的快速提高,人民币在国内外流通速度随之加快[1]。人民币鉴伪技术的发展对于保证我国金融安全,维护正常的经济秩序和社会的稳定性都具有重要的现实意义。
目前手机分辨率普遍在2000万像素,更有甚者达到4800万像素,这为利用手机人民币图像鉴伪带来了可能,但是利用手机拍摄的人民币图像难免会有变形、噪声,这使得使用手工提取手机人民币图像特征进行真伪鉴别面临很大的问题。近年来,深度学习在图像检测识别领域取得了令人瞩目的成就,相比传统的人工提取特征的图像处理方法,深度学习通过其网络在训练过程中自己学习参数来对输入图像进行特征提取,然后对输出结果进行判断并识别。现在,卷积神经网络在图像分类[2]等计算机视觉领域的应用广泛。
图像分类是计算机视觉领域的一个经典研究课题,传统的图像分类主要处理语义级图像和实例级图像两大类:前者包括诸如场景识别、对象识别等,其目的是识别不同类别的对象,如猫和狗等;后者则是对不同的个体进行分类,如人脸识别。而细粒度图像分类则位于这两者之间,不同于对象识别等粗粒度的图像分类任务,细粒度图像的类别精度更加细致,类间差异更加细微,往往只能借助于微小的局部差异才能区分出不同的类别[3]。细粒度图像分类任务一直是分类任务中极具挑战性的任务,主要原因就是数据集本身类内差异大,类间差异小的特性[4]。RMB图像的真伪鉴别很明显属于细粒度图像分类的范畴,其真假RMB的差异很小,但是类内差异却比较大。
本文首先介绍在2014年ILSVRC上定位第一,分类第二的经典网络VGG[5]和2015年提出的针对细粒度图像分类任务的双线性卷积神经网络[6]。随后介绍手机人民币图像的红色分量对于人民币鉴伪的重要性。之后介绍一种用于手机人民币图像鉴伪任务的框架,该框架以带有提取红色分量Lambda层的VGG16的block5的输出一分为二为基础构成B-CNN。之后介绍两种模型学习策略,专门用于该框架的模型学习。最后的实验部分,首先对比将单纯的VGG16(不包含顶部的三个全连接层和softmax层)的block3、block4、block5的输出分别接三个层(卷积核大小为1*1、filters=5的卷基层、概率参数为0.5的Dropout层、激活函数为sigmoid的全连接层)之后的人民币真伪鉴别性能;其次对比在以VGG16的block3、block4、clock5的输出为基础构建的B-CNN网络在人民币真伪鉴别性能;继而对比增加了提取人民币红色分量的Lambda层的单纯的VGG16的block3、block4、clock5的输出构建的B-CNN网络在人民币真伪鉴别性能。最后对比两种训练策略对人民币真伪鉴别性能的影响。
2 卷积神经网络
神经网络是机器学习[7]的重要组成部分,也是深度学习的基础。卷积神经网络(Convolutional Neural Network,CNN)[8-9]相较于一般的神经网络最突出的特征就是增加了卷积层和池化层,这相当于在神经网络的线性基础上增加了非线性变化。卷积层拥有的参数共享、局部连接的特性使得传统神经网络采用全连接网络带来的参数量巨大训练消耗资源多的弊端得到改善。
2.1 VGG16
VGG[5]网络模型对卷积神经网络的深度和性能之间的关联进行了多项探索,其网络结构非常简洁,整个网络中全部使用大小为3*3的卷积核和2*2的最大池化核。
VGG16的网络架构如图1所示,VGG16里面包含多个conv->conv->max_pool这类的结构,其卷积参数padding都是same类型、其下采样完全是通过max_pooling完成。其较之前的卷积神经网络最大的闪光点就是卷积层使用更小的filter尺寸和间隔。
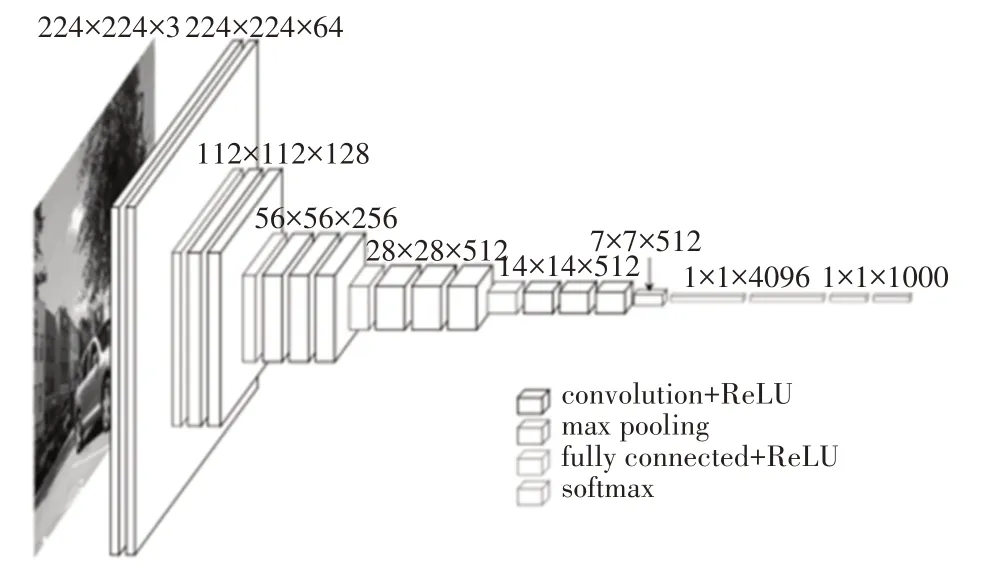
图1 VGG16网络结构图
2.2 B-CNN
细粒度图像分类任务中几种主流方法有强监督的细粒度图像分类、弱监督的细粒度图像分类。强监督的细粒度图像分类是指在模型训练的时候除了使用图像的类别标签外,还使用了标注框等额外的人工标注信息;而弱监督的细粒度图像分类在模型训练时只依赖于类别标签[10]。
Lin等[6]在2015年创造性地提出了双线性卷积神经网络(B-CNN),该模型的网络架构图2所示,其在三个经典数据集上达到了很高的分类精度、能够实现端到端的训练,且属于仅依赖图像的类别标签的弱监督分类算法。B-CNN模型可认为一个网络对物体局部区域进行检测,另外一个网络进行特征提取,两个网络相互协调完成细粒度图像分类过程中的区域检测和特征提取。
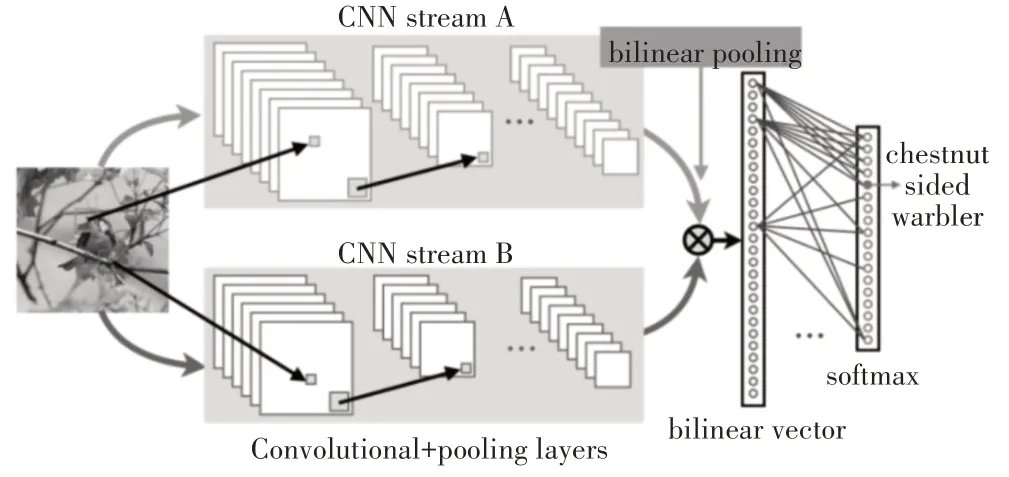
图2 B-CNN网络架构
B-CNN网络由B=(fa,fb,P,C)组成,其中fa,fb代表特征提取函数,对应于图2中的streamA和streamB,P是一个池化函数,C则是分类函数。从图2中可以看出,其实就是用两个卷积神经网络对图像进行特征提取,然后用一个bilinear pooling层将CNN抽取的两组特征进行结合,最后带入softmax层进行分类。此处的bilinear pooling本质上就是对两个CNN的输出进行外积,从而得到双线性特征X,之后将X依次按照式(1)和式(2)进行处理,从而得到图片最终的特征,并用于后续分类。
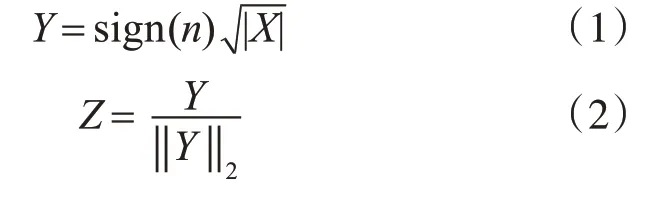
3 手机人民币图像的GLCM纹理特征
本文针对的手机人民币图像指的是用魅族16th手机拍摄的百元人民币的局部特征图像,本人采集的手机人民币图像的12个特征区域均为人民币正面特征,即左上角国徽、左上角国徽右侧祥云、中国人民银行标识下方100字样、包含壹佰圆字样的中间梅花区域、左下角的100字样、毛主席脸部,毛主席耳朵、毛主席耳朵上方头发区域、毛主席耳朵下方衣领区域、毛主席衣领中间扣子、右上角100元字样,右下角盲文区。
纹理分析技术起源于对遥感图像的分析[11],常用的纹理分析技术有统计分析、结构分析、模型分析和频谱分析,而灰度共生矩阵(Gray Level Co-occurrence Matrix,GLCM)是统计分析方法中最关键的方法之一[12]。灰度共生矩阵统计在图像中的指定方向上,像素坐标相距一定间隔的两个灰度像素同时出现的概率,矩阵中的元素代表图像中灰度之间的联合概率密度。灰度共生矩阵G中的元素可以定义为式(3),其中(x,y)代表图像像素的坐标,i,j=0,1,…L-1是图像的灰度级,|.|表示集合中的元素个数,S表示在指定区域中具有特定空间关系的像素对的集合,dx和dy为求取灰度矩阵时选取的步长。

Ulaby等[13]基于GLCM特征,提出熵(Entropy,ENT)、能量(Energy,又称角二阶矩Angular Second Moment,ASM)、惯性矩(又称对比度Contrast,CON)和相关性(又称逆差矩,Inverse Different Moment,IDM)等四种纹理特征,这四种特征的计算公式如下:

本人求取了手机人民币图像的12个特征区域的RGB通道在GLCM的step为1、2、3的情况下的四个方向上的四种纹理特征,其均值如表1所示,求取灰度共生矩阵使用的灰度级别是64。从表中可以看出:在手机人民币的鉴伪任务中,手机人民币图像的红色分量对比蓝绿分量具有其优越性。

表1 手机人民币图像RGB三通道在GLCM步长为1、2、3情况下四个方向上四种纹理特征均值
4 本文方法
本节提出一种针对手机人民币图像局部特征的真伪识别框架,框架是以VGG16和提取图片红色分量的Lambda为基础构建的变种的B-CNN网络。Lin[14]在2017年提出的B-CNN的改进中就已经证实了双线性特征是高度冗余的,可以减小数量级,而不会显著降低精度,但是其并没有摆脱仍然是两路不一样的CNN网络进行特征提取。本人以增加了提取图片红色分量的Lambda层的单路VGG16模拟两路输出,从而构建B-CNN网络。本节提出的网络构造图如图3所示,图中红色框代表提取人民币图片红色分量的Lambda层;绿色框代表VGG16的5个block层;蓝色框代表B-CNN中的Bilinear Pooling层。
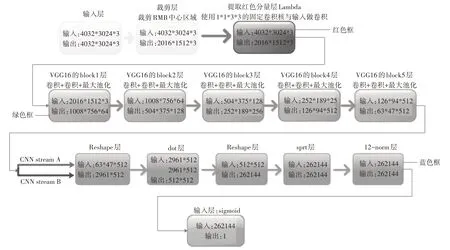
图3 本文提出框架的结构图
4.1 简单组合训练
VGG16模型提出后,在多领域的特征提取上都展示了巨大的优势[15]。因为本人的数据集不足以训练VGG16如此庞大的网络,所以在模型训练时使用了迁移学习的方法,即在训练带有提取手机人民币红色分量的Lambda层的VGG16模型时先载入了VGG16在ImageNet预训练的权重,然后再使用本人构建的手机人民币图像数据集进行进一步的训练。
简单组合训练的具体策略是首先将图3中的蓝色框全部去掉(即去掉了B-CNN的Bilinear Pooling层),以带有提取手机人民币红色分量的Lambda层的VGG16的block5的输出作为图片的特征,以激活函数为softmax的全连接层为输出,利用梯度下降法更新模型参数。当此模型收敛后,再加入Bilinear Pooling层,之后冻结Bilinear Pooling层之前的所有层的权重,再次训练直到模型收敛。
4.2 端到端组合训练
上面提出的简单组合框架训练中,单路VGG16和Bilinear Pooling层在训练期间没有发生直接的关联,即两部分均属于单独训练。本小节在简单组合训练的基础上提出一种端到端组合训练方法。
端到端组合训练的具体策略是直接搭建图3中的模型,训练开始时载入VGG16在ImageNet数据集上预训练的权重,继而使用本人采集的手机人民币图像数据集进行端到端的训练,即VGG16和Bilinear Pooling同时训练权重,训练直到模型收敛。
5 实验验证
本实验使用的数据集为通过魅族16th采集的一百元真假人民币的12个特征区域的图片,图片大小均为4032*3024像素。其中每个特征的真假人民币训练样本各为1200张,验证样本各为300张,测试样本各为300张。实验采用的实验平台是Titan v+python3.6+keras2.2.4。本文提出的两组框架在模型训练时选用相同的训练参数。
本节为了证明本文提出的以带有提取手机人民币图像红色分量的Lambda层的单路VGG16构建的B-CNN网络在手机人民币图片鉴伪任务中的有效性,对比了多种框架和本文提出的框架在手机人民币鉴伪任务中的性能指标,性能指标包含精确率、召回率、准确率、错误率。性能对比结果如表2。

表2 不同模型在测试集上性能指标
本小节对比的特征提取器框架包含:单纯的VGG16的block3、block4、block5的输出、带有提取手机人民币红色分量的VGG16的block3、block4、block5的输出、单纯的VGG16的block3、block4、block5的输出构成的B-CNN的简单组合训练和端到端组合训练、本文提出的带有提取红色分量Lambda层的单路VGG16的block3、block4、block5的输出构建的B-CNN的输出。上述特征提取器的输出均通过激活函数为softmax的全连接层。
观察表2,我们按照在表2中框架顺序依次编号为1~6。最明显地能看到前三个框架以VGG16的Block3的输出作为特征提取器时,训练无法收敛,这是因为简单的block3的输出无法获取真人民币的有效特征,从而导致所有预测都是假人民币,这也是为什么假币的召回率为100%的原因。框架4中依然是使用VGG16的block3的输出,但是其因为使用了Bilinear Pooling层对其输出进行了进一步的非线性化,使得准确率得到飞升。从框架1到框架6,最直观的还是随着block的增多,即非线性层带来的非线性程度的提高,准确率逐步上升。
其次对比三组框架(框架1和框架2,框架3和框架5,框架4和框架6),这三组框架的区别仅仅在于是否有提取手机人民币图像的红色分量的Lambda层,从表格中可以清楚地看出:带有提取红色分量Lambda层的框架在准确率上明显更具有优势,这也很好地验证了手机人民币图像中红色分量确实比其他两个分量携带的有效信息多。
最后对比两组不同训练方法的性能,即框架3和框架4、框架5和框架6。这两组框架的区别仅仅在于训练方法的不同,结果显示:使用端到端组合训练方法可以明显提升识别率。简单组合训练依赖于网络前端VGG16网络对手机人民币图像的特征提取能力,若前端的VGG16无法提取有效信息,那么简单组合训练后期冻结网络前端之后也无法获取有效的用于真伪鉴别的特征。反观端到端组合训练,其VGG16和Bilinear Pooling层同时训练,同步提取特征,使得模型的非线性能力得到提升,也能更好地提取手机人民币用于真伪鉴别的特征
6 结语
本文提出了一种提升手机人民币图像真伪鉴别的深度学习框架,其使用带有提取红色分量的Lambda的VGG16的block5作为前端,使用Bilinear Pooling作为后端,最后使用激活函数为softmax的全连接层作为分类器。本文使用了简单组合训练和端到端组合训练方式获取前文所述框架,并且在实验部分也对比了多种特征提取器对手机人民币图像真伪鉴别的各种性能。现提出几点展望。
1)本文在实验部分证明了该框架可以提高手机人民币的真伪识别率,但是实验所用数据集仅仅是一种手机拍摄获取,不具有普遍性,后期可以针对多款手机(华为、小米等)进行数据集的补充。
2)本文的数据集对于有大量训练参数的网络来说,会存在过拟合的问题,后期应该更多的手机真假人民币图像扩充数据集。
3)本文使用的基础框架是VGG16的block5的输出,在后期可以针对其他特征提取网络(ResNet[16]、DenseNet[17]、Inception[18]等)构建单路BCNN网络模型。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
读者·校园版(2020年19期)2020-09-16
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
英美文学研究论丛(2018年1期)2018-08-16
电机与控制学报(2018年9期)2018-05-14
