
一种结合域自适应的图像语义分割算法
2021-10-20 10:59高宏力
机械设计与制造 2021年10期
毛 威,高宏力
(西南交通大学机械工程学院,四川 成都610031)
1 引言
语义分割是视觉研究的核心问题,相关实际应用如自动驾驶[1]、故障诊断[2-3]、车辆检测[4]对其需求不断增长。语义分割的目标是为图像的每个像素分配语义标签。现有基于深度神经网络的图像语义分割方法的训练需要大量标记数据,这些数据的收集和标记成本高昂,这很大程度上限制了此类方法的实际应用。为解决此问题,这里使用成本较低的计算机生成并标记的逼真的合成数据训练深度网络。但真实图像与合成图像在分布域上存在的差异会降低模型性能,因此这里使用一种对抗学习方法来实现域自适应,以解决上述问题。
又由于语义分割输出空间包含空间信息和局部信息(如空间布局和局部环境)。且即使在不同域的输入图像外观迥异的情况下,语义分割输出仍可能存在许多相似性。因此,这里采用在输出空间上进行像素级域自适应的方法。在此基础上,这里于不同级别的输出空间构建多级域自适应网络以提升模型性能。
具体来说,这里采用的域自适应方法是基于卷积神经网络的端到端算法。在输入空间上,通过对抗学习实现源域与目标域所预测的标签分布的近似。基于对抗生成网络[5],这里使用的模型由两部分组成,一部分是语义分割模型用以预测分割结果,另一部分是判别器网络用以判断其输入是源自目标域还是源域的语义分割输出。对抗学习的目标是利用损失函数,使语义分割模型能够欺骗判别器,进而使源图像与目标图像在输出空间生成相似分布。
2 算法综述
2.1 模型概述
概括地说,这里所使用的模型主要由两部分组成,分别是用于语义分割的网络G与判别器Di。其中当使用多级对抗学习时,i表示判别器所在的级别。将合成图像集视为来自源域,用{}Is表示,相对的真实图像集来自目标域,表示为{It}。两个图像集都∈RH×W×3,且只有源域图像已被标记。
具体的方法是首先通过使用源域图像训练G以优化该网络。再将目标图像集输入优化后的G,预测It的语义分割输出Pt。然后根据对抗生成网络的原理,将两种预测输出作为判别器的输入,目的是判别输入是否出自源域或目标域。由于任务的目标是使源图像与目标图像的语义分割预测相互近似,通过对目标域的预测计算对抗学习损失,经由Di向G的网络梯度传播,促进G在目标域生成与源域预测更相似的分割分布。
2.2 输出空间自适应
尽管分割输出位于低维空间,但其仍包含如场景布局等在内的丰富信息。即使源域与目标域的图像不同,它们的分割输出仍可能具有程度很高的空间和局部相似性。因此,在输出空间上进行域自适应是更合适的选择。这里利用这一特点,结合对抗学习方法来改进图像的域自适应方法。
根据所提出的模型,这里使用构成模型的两个网络的损失函数构建域自适应方法的目标函数:

式中:Lseg-源域图像输入语义分割网络的损失,使用交叉熵损失函数;Ladv-使目标域图像的预测分割输出近似于源域的输出分布产生的对抗损失;λadv-平衡两种损失的权值。
2.3 单级对抗学习
结合WassersteinGAN(W-GAN)[6]来定义判别器目标函数与对抗损失函数。WGAN与原始GAN算法的不同之处包括基于Wasserstein距离确定损失函数,且不使用log对数函数等。WGAN相较于原始GAN的优点体现于确保了GAN训练的稳定性,降低对抗学习训练的难度。
给定语义分割输出为P=G(I)∈RH×W×C,其中C表示类别数目。将P输入判别器D,通过训练判别器的参数最大化源域与目标域图像分割输出的绝对差异。其损失函数可表示为:
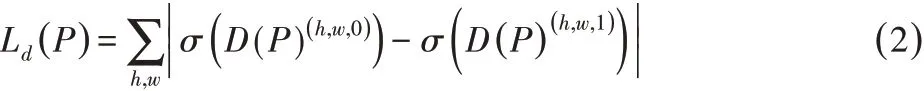
对于分割网络的训练,这里使用源域图像的交叉熵损失定义分割损失:
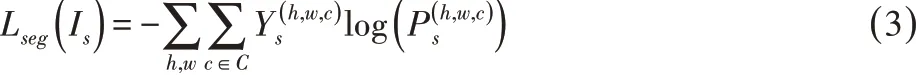
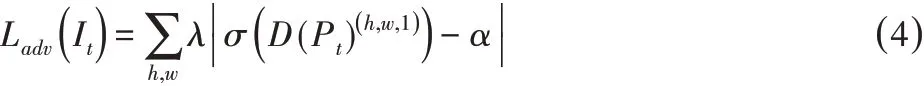
利用该损失函数训练分割网络,并通过促进Pt分布与Ps近似,最大化判别器将目标域的预测结果误判为源域结果的概率。
2.4 多级对抗学习
与预测结果不同,由于距离输出较远,在输出空间应用单级对抗学习时,低阶特征所产生的改变不能达到要求。根据为语义分割算法添加附加损失函数的方法[8],这里于单级对抗学习模型基础上,在低阶特征空间增加另外的对抗模块构成多级对抗学习模型,以提高自适应方法。这样便可将分割网络的训练目标函数扩展为:
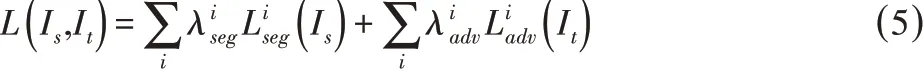
式中:i-对抗模型所在级别。注意到在输入各判别器进行对抗学习之前,分割输出是在各特征空间中产生的。因此与的形式仍和单级对抗学习中的相同。然后根据训练对抗学习所常用的min-max准则,对式(5)进行优化:

训练优化的最终目标是最小化源域图像在G的分割损失,同时使目标域预测被判断为源域预测的概率最大。
2.5 网络结构与训练
为保证G的分割结果符合需求,采用以在ImageNet上预训练的ResNet-101[9]为基础的DeepLab-v2[10]的残差网络变体作为语义分割G的基本模型。参照近期语义分割工作的方法[10][11],这里将最后两个卷积层的步幅改为1,并移除了最后的全连接层。为了扩大感受野,在conv4与conv5层使用孔卷积方法[10],且步幅分别为2和4。在网络最后,分类器使用孔空间金字塔池化(ASPP)[10]方法,并添加一个上采样层使生成的softmax输出的尺寸与输入图像相同。
判别器的结构与[12]相似,但为保存空间信息,只使用全卷积层。具体的,网络由五个卷积层构成,使用步幅为2的4×4卷积核,每层的通道数分别为{64,128,256,512,1}。这里不使用批归一化层,而以小批训练,且在除最后层外的每一卷积层后都连接一个leaky ReLU层,并在最后的卷积层添加一个上采样层以将输出缩放至与输入相同的尺寸。
根据上述分割网络与判别器即可构建单级自适应模型。更进一步,这里从conv4层提取特征图,并以ASPP模块作为附加分类器,之后再连接用于对抗学习的判别器,这样就生成了单级的自适应模块。如此在不同卷积层应用该方法就能构建出多级自适应模型,而出于对效率与精度的权衡,这里只使用两级自适应模型。网络结构与域自适应模块结构分别如图1、图2所示。
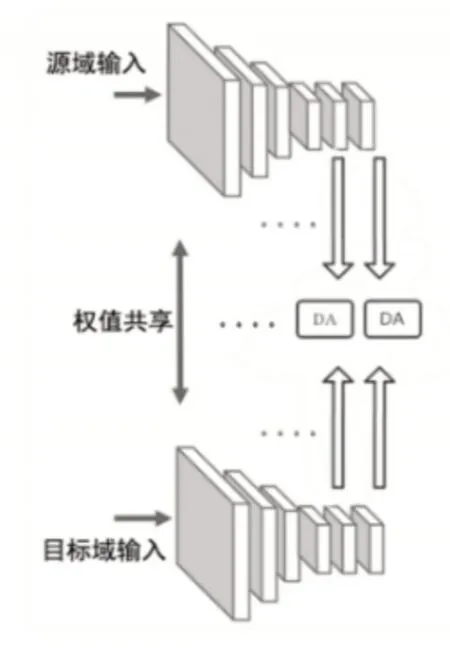
图1 网络结构,其中DA表示域自适应模块Fig.1 Network Architecture,Domain Adaptation Module(DA)
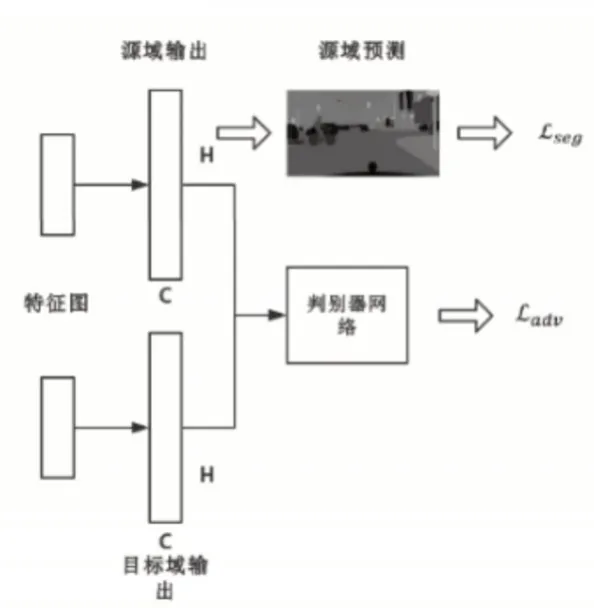
图2 (DA)域自适应模块,包含判别器网络Fig.2(DA)Domain Adaptation Module
这里通过联合训练分割网络与判别器的方法来有效训练提出的模型。在每一训练批次中,源域图像Is首先被输入进分割网络以优化式(3)中的Lseg,并生成输出Ps。紧接着,分割网络对目标域图像It的输出Pt将与Ps共同被用于判别器,进而实现对式(2)中Ld的优化。最后再计算式(4)中的Ladv,以促进Pt与Ps分布的近似。对于多级模型的训练,只需在每个自适应模块中重复相同的步骤。为训练分割网络,这里采用随机梯度下降优化(SGD)算法,其中权值衰减、动量等参数被设置为10-4和0.9,且初始学习率设为2.5×10-4并以指数为0.9进行多项式衰减。又由于WGAN训练方法的特性,这里不选择基于动量的优化方法,而使用随机梯度下降优化算法训练判别器,并设学习率为10-4。这里在GPU计算机上,使用PyTorch库实现所用网络。
3 实验验证
GTA5数据集是计算机合成图像数据集,图像总数为24966,且图像分辨率为1912×1052,包含19个类别。在训练过程中,这里先使用整个GTA5数据集训练模型,再将CityScapes的训练数据集的2975个图像数据应用于该模型。当测试模型时,使用CityScapes的含有500个图像的验证集评估模型性能。所有的实验都使用IoU测度评估结果。如图3所示为实验实例结果。

图3 实验实例结果Fig.3 Experiment Result
表1 的内容是这里所使用方法的结果与其他域自适应方法的比较。对于使用基于VGG-16结构的方法,这里采用与之相同的基本网络结构训练所提出的单级自适应模型,以准确评估比较不同方法。从表1可看出,这里所用方法取得了相对不错的结果。并且与这里方法不同,其他方法皆拥有特征自适应模块,而结果则表明在输出空间实现自适应的方法是更合适的选择。
利用高性能的模型作为基准与用自适应方法改进过的模型进行比较也是理解自适应方法重要性的手段。因此,这里在基于ResNet-101的网络的基础上训练自适应模型。表1中表现了基准模型只使用源域图像训练且不结合自适应方法与不同自适应模型的结果比较。另外,监督模型与自适应模型间的差异的缩小程度也是评价自适应方法的重要因素。因此,这里使用CityScapes数据集的标记真值训练得到监督模型,作为参照结果。通过表2的比较结果可发现,基于VGG-16网络的模型与参照结果的差异更大,因此基于ResNet网络的方法更为适用。
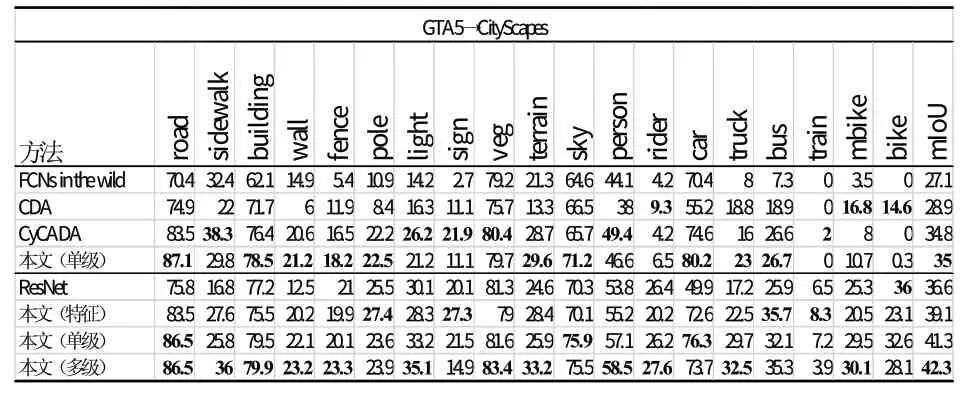
表1 基于VGG-16的方法及基于ResNet-101的方法实验结果Tab.1 Experiment Result Based on VGG-16 and ResNet-101
在训练优化分割网络G时,确保分割损失与对抗损失的权值的相对平衡非常重要。基于单级自适应模型,这里通过比较改变λadv所取得的不同结果寻找合适的λadv值。实验结果表明较大的λadv值可能致使网络传播错误的梯度,所以这里选取0.001作为λadv值。同样在单级自适应模型的基础上,这里比较了基于特征的域自适应与在输出空间上的域自适应方法的结果,其中基于特征的方法使用判别器判别不同域的图像的特征。可以看到在输出空间的自适应方法的优点体现在两点:一是其实验结果更好;二是在特征空间的自适应对λadv参数的改变更为敏感,这增加了训练的难度。对于多级对抗学习的训练,位于高阶输出空间的模块的参数设置与单级对抗学习的参数相同(即0.001)。而由于低阶输出用于分割预测的信息较少,故这里赋予其分割与对抗损失较小的权值(即
总结来说,由表3的实验结果可看到,相较于基于特征的自适应方法,在输出空间上的自适应方法结果更好,并对参数改变更不敏感,从而降低了训练的难度,所以这里选用在输出空间的自适应方法。通过表1的实验结果可看到这里所用域自适应方法取得了与其他一些方法相比较较为良好的结果准确度。表2通过对不同自适应模型与监督模型的精度差的比较可以看到这里所使用的基于ResNet的多级自适应方法对精度提高的作用更为显著。
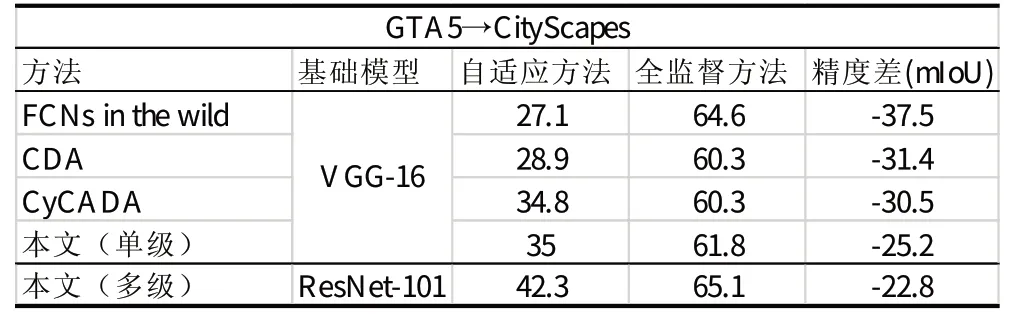
表2 自适应模型与监督模型的精度差Tab.2 mIoU of Adaptation Model and Supervised Model
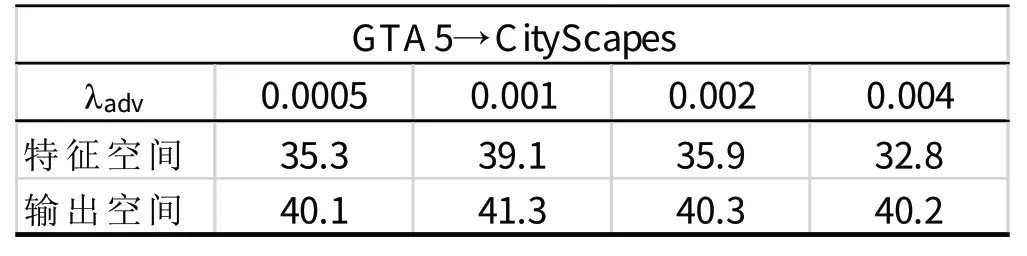
表3 不同空间的域自适应方法对λadv参数改变的敏感度Tab.3 Sensitivity for Domain Adaptation Method to λadv in Different Space
4 结束语
这里采用域自适应方法将通过合成图像训练的模型应用于真实图像的语义分割,以解决大量有标记真实图像获取成本高昂的问题,其中域自适应方法通过在输出空间上的对抗学习实现。根据WGAN对对抗学习损失函数进行了改进。另外,还通过构建多级对抗学习网络来利用不同级别特征信息以提升模型性能。实验结果表明这里所提出方法相较于其他方法取得较好的结果。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
计算机技术与发展(2020年11期)2020-12-04
开放教育研究(2020年2期)2020-03-31
今日农业(2019年15期)2019-01-03
现代语文(2016年21期)2016-05-25
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
电子与信息学报(2015年12期)2015-08-17
读者·校园版(2015年19期)2015-05-14
大连民族大学学报(2015年2期)2015-02-27
外语学刊(2011年1期)2011-01-22
