
基于深度学习的核磁共振图像智能分割算法研究
2021-10-27 05:57马啸天李书芳
中国传媒大学学报(自然科学版) 2021年3期
马啸天,李书芳
(北京邮电大学信息与通信工程学院,先进信息网络北京实验室,网络体系构建与融合北京市重点实验室,北京 100876)
1 引言
基于深度学习方法的核磁共振图像(Magnetic Resonance Image,MRI)分割是图像分割研究领域中的研究热点,在医学领域具有重要的应用价值。心脏是人体最重要的器官之一,是循环系统中的主要器官,为血液流动提供动力。心血管疾病(Cardiovascular Disease,CVD)具有高患病率、高致残率和高死亡率的特点,已经成为人类最普遍的死亡原因[1]。心脏功能分析在临床心脏病学中对患者管理、疾病诊断、风险评估和治疗决策发挥着重要作用。可以通过定量评估心室容积、卒中体积、射血分数和心肌质量等临床参数,对心脏功能进行分析。这些参数的计算前提是对左心室、右心室和心肌轮廓的精确分割。目前临床上评价心脏功能的影像技术中,心脏磁共振成像(Cardiac Magnetic Resonance Imaging,CMRI)技术良好的时间和空间分辨率使其具备同时显示心脏结构和功能的能力,加之其不存在辐射损害,这种集形态、功能及细胞生物学检查为一体的无创性检查已发展为心脏病诊断和鉴别诊断的理想方法,被认为是判断心脏结构和功能的“金标准”[2]。因此心脏MRI 分割已成为一个医学影像分析的热点问题。
通常,放射科医生通过手动绘制包含分割目标结构的轮廓线,从周围的组织器官中划定目标区域。由于医学影像本身的复杂性以及对结果极高精确度的要求,目前医学影像的分析工作主要由有经验的医生完成,自动化的分割与诊断由于不能满足临床需要,只能作为辅助补充。然而放射科医生人工分析所需的工作量大、耗费时间长,且受不同的放射科医生各自主观的经验、所处环境、工作状态等影响,其结果也因人而异,对同一区域的勾画结果不能百分之百复现。随着医疗数字化的推进,利用各种设备采集到的医学图像数量也快速增长,这些更增加了医生的工作量。在现有的医学影像分割技术中,深度学习方法体现出了明显的优势。
将深度学习技术用于计算机辅助诊断中不仅可以提高诊断精度和效率,还能有效缓解医疗资源紧张,为医生减轻压力,降低对专家经验的依赖,提升基层诊疗水平。然而在医学影像分割任务中,也面临着诸多挑战:由于扫描成本、患者隐私以及高人工标注成本等问题,使得用于训练深度学习模型的数据规模十分有限;医学图像的输入维度高,通常为体积数据,数据量大;需要分割的目标体积较小,对精度的要求更高;不同的分割目标差异性较大,缺少可迁移到医疗影像分割任务上的通用预训练模型等。心脏MRI 自身的特点,例如左心室腔内亮度不均匀,与其他器官亮度信号相似,心脏病引起心室心肌形状畸形,以及心尖和基底切片图像的复杂性等等,也给心脏MRI 的分割任务带来诸多困难。
基于上述问题,本文提供了基于深度学习的心脏MRI 分割方法。通过感兴趣区域检测及深度学习网络技术,对心脏MRI 图像与医生手动分割的真值标注数据进行训练,实现对心脏MRI 图像左右心室和心肌的准确、自动分割。使用了多种数据增强手段进行实验数据集的人为扩充。Jaccard 系数,Dice重叠系数和豪斯多夫距离(Hausdorff Distance,HD)作为分割效果的客观评估指标[3]。与现有的几种方法相比,我们的方法取得了优秀的结果。
2 相关工作
2.1 分割挑战与数据集
过去几年来,心脏MRI 的左心室、右心室的心内膜和心外膜分割是该领域的研究重点,为了推进先进的医学方法也已经组织了一些半自动/全自动的心脏分割挑战,这些挑战通常提供由专家标注的真实的数据集,并提供一组评估指标来对各种方法进行评价,如2009年和2011年的左心室分割挑战[4,5],2012年的右心室分割挑战[6]和2015年的Kaggle 第二届年度数据科学碗挑战赛,2017年MICCAI 的自动心脏诊断挑战ACDC[7]等。
本文我们使用ACDC 数据集。数据集由150位不同患者的心脏MRI 组成,包括100个训练样本和50个测试样本,每个训练样本包含舒张末期(End of Diastole,ED)和收缩末期(End of Systole,ES)的左心室、右心室以及心肌(心外膜轮廓)的专家手动分割标注结果。每位患者的MRI 数据包含28-40 帧从左心室底部到顶部的整个心动周期的一系列短轴图像切片。每个切片的空间分辨率平均为235-263个体素。
2.2 心脏MRI 分割
Petitjean 和Dacher(2011)[8]对先前的左心室分割方法进行了全面的阐述,包括多级Otsu 阈值、可变形模型和水平集、图形切割、基于知识的方法(如主动和外观形状模型)和基于Atlas 的方法。这些方法在小基准左心室数据集上取得了一定的成功,但它们的鲁棒性差、准确性低,且泛化能力有限。2015年Kaggle 挑战赛的结果表明,性能最高的方法依赖于深度学习技术,尤其是全卷积网络[9]和U-Net[10]。Avendi 等人(2015)[11]将机器学习的最新进展(例如堆叠自动编码器和卷积神经网络)与可变形模型相结合,使左心室心内膜分割的结果达到了新的水平。2016年,P.V.Tran[12]首次使用全卷积神经网络同时分割出左心室和右心室的内外膜。2018年,Nasresfahani 等[13]首先提取出感兴趣区域(Region of Interest,ROI),在此基础上采用全卷积神经网络,提高了分割精度,同时提高了模型的鲁棒性。
3 方法
本文提出的心脏MRI 分割方法由数据预处理与分割两部分组成。
3.1 预处理
预处理步骤包括对心脏MRI 数据的感兴趣区域检测、数据标准化、数据增强。
3.1.1ROI 检测
ROI 检测的步骤包括使用标准差滤波器进行滤波,找到心动周期图像序列中像素强度随时间变化强烈的区域,然后使用Canny 边缘检测[14]和霍夫变换技术[15]找到包含心脏的感兴趣区域。
Canny 边缘检测算法由多个步骤构成:
(1)图像平滑。采用高斯平滑滤波来去除图像中的噪声。在图像边缘检测过程中,图像的边缘和噪声难以区分,仅凭边缘检测算法不能完全消除噪声对边缘检测过程和结果的影响,因此需要对原始图像进行预处理。图像预处理中的常见滤波方法有均值滤波、中值滤波和高斯滤波。相较于均值滤波和中值滤波,高斯滤波在对图像进行平滑滤波时能很好地保留图像中的灰度分布情况。令f(x,y)为输入数据,fs(x,y) 为经过高斯卷积平滑后的图像,G(x,y)表示高斯函数,表达式如下:
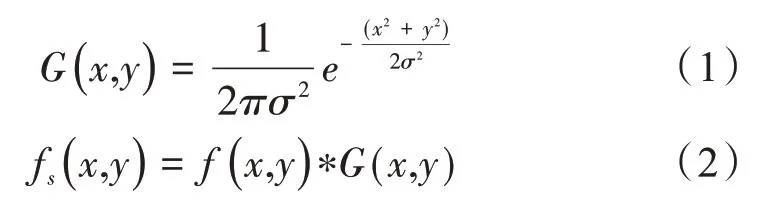
(2)计算图像梯度强度和方向。Canny 算法的基本思想是寻找一幅图像中灰度强度变化最强的位置,即梯度方向。平滑后的图像中的每个像素点的梯度由Sobel 算子来计算。首先运用如下的卷积阵列Sx和Sy分别求得原始图像A沿水平(x)和垂直(y)方向的梯度Gx和Gy:
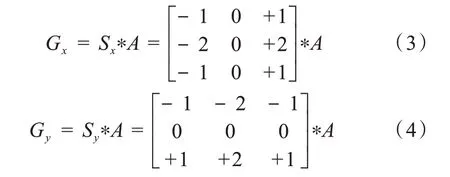
然后利用下列公式求得每一个像素点的梯度幅值:

在变化剧烈的地方(边界处)将获得较大的梯度度量值G,然而这些边界通常非常粗,难以标定边界的真正位置,为了标定边界,还需要梯度的方向信息:
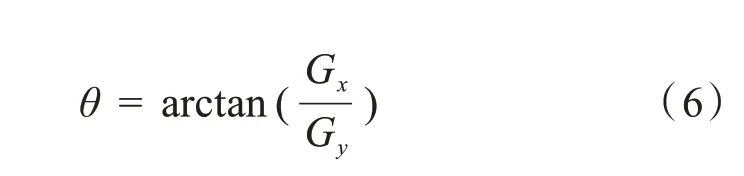
(3)应用非极大值抑制(Non-Maximum Suppression)技术来消除边缘误检。对每个像素点将其梯度方向近似为(0°,45°,90°,135°,180°,225°,270°,315°)中的一个,比较该像素点和其正负梯度方向的两个像素点的梯度强度,如果该像素点梯度强度最大则保留,将其视为边缘,否则抑制。经过这样的处理后会保留一条边界处最亮的一条细线,图像的边缘明显变细。但是这些细线部分可能是噪声或其他原因造成的局部极大值。
(4)应用双阈值来决定可能的边缘。Canny 算法中应用了双阈值的技术,即设定一个阈值上界T1和阈值下届T2,如果图像中的像素点梯度值超过T1,称为强边缘,小于T1大于T2的称为弱边缘,小于T2的不是边缘。通过设置足够高的T1,强边缘像素点的梯度足够大(变化足够剧烈),强边缘必然是边缘点。为了判断弱边缘是边缘还是噪声,当弱边缘的周围8邻域有强边缘像素存在时,就将该弱边缘点保留为边缘像素,以此来实现对强边缘的补充,若没有,则去除。Canny 建议高阈值与低阈值T1:T2之比为2:1。
对于霍夫变换,霍夫变换的原理是运用两个坐标空间之间的变换,利用点和线的对偶性,将一个空间中具有相同形状的直线或曲线映射到另一个坐标空间中的一个点上形成峰值,从而把检测任意形状的问题转化为统计峰值问题。
以圆形霍夫变换(Circular Hough Transform,CHT)为例,霍夫变换首先提取图像的边缘,然后利用圆的方程将边缘图像中的每个点映射到另一个三维空间中去,这个三维空间称为霍夫空间。霍夫空间的前两个维度表示待检测的圆的圆心坐标,第三个维度表示待检测的圆的半径。边缘图像中的每个点在霍夫空间中都被映射为一个圆锥面,同一个圆上的点在霍夫空间中的映射会相交于一点,该点对应的坐标就是待检测的圆的参数。
二维空间中的圆的方程用下式表示:

圆上任意一点的(xi,yi)被映射到三维参数空间a-b-r中的一个曲面上,该曲面方程用下式表示:
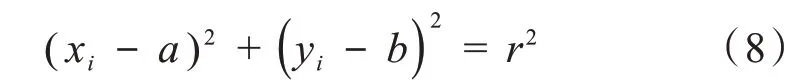
将圆上的每个点都进行以上的映射过程。假如每一个点对应的圆锥面都相交于点()a0,b0,r0上,则所有的点都在这三个参数所确定的圆上,这个圆就是要检测的圆。
本文在Canny 边缘检测的基础上,使用霍夫变换进行圆环的检测来进行ROI 检测,找到左心室区域的中心。
3.1.2数据标准化
由于采集设备和条件的不同,不同患者之间的心脏MRI 图像可能由于明暗、对比度等原因,出现尺度不一的问题。而神经网络学习的本质上就是为了学习输入数据的分布,如果训练数据和测试数据的分布差异过大,会大大降低模型的泛化能力。为了解决这个问题,通常需要对输入数据进行标准化处理。
将采集到的心脏短轴MRI 数据转化为像素灰度均值为0,方差为1 的标准化数据;使用Z-score 标准化方法[16]对图像数据的像素强度进行标准化,

其中X为切片图像像素,μ为图像像素均值,σ为图像像素标准差。经过标准化处理后的图像像素值分布符合标准正态分布,均值为0,方差为1。
3.1.3数据增强
由于扫描成本、患者隐私、高质量的图像标注获取困难等原因,大量基于深度学习的医学图像研究面临可用数据集少、训练数据量不足的问题。小样本数据集往往不足以支撑深度神经网络训练,常出现模型在训练样本上表现很好但在测试数据集上泛化效果不佳的过拟合现象。为了解决训练数据量不足的问题,本文采用数据增强技术来人为地增加数据集,以防止模型过拟合。常见的数据增强方法有缩放、翻转、旋转、裁剪、平移等几何变换方法和添加噪声、模糊、颜色变换、擦除、填充等颜色变换方法。本文采用的数据增强方法包括-5~5 度的随机角度旋转,-5~5 mm 的随机平移,-0.2~0.2 倍数的随机缩放比例,添加零均值的标准差为0.01 的高斯噪声,以及使用B 样条插值进行弹性形变。
3.2 心脏MRI 分割
3.2.1网络结构
本文提出的分割网络结构基于Jégou 等人2017年提出的语义分割架构[17]进行改进,改进后的网络结构如图1 所示。网络结构类似U-Net 的典型的语义分割结构,包括下采样和上采样两个部分,由7个密集连接块[18],3个过渡层上采样,3个过渡层下采样组成。在下采样路径中,密集连接块的输入与输出通过特征通道进行拼接。在上采样路径中,通过特征图元素级相加,与对应的下采样路径中的特征图进行融合,其中改进的跳跃连接使用线性投影操作来匹配对应的特征通道数。
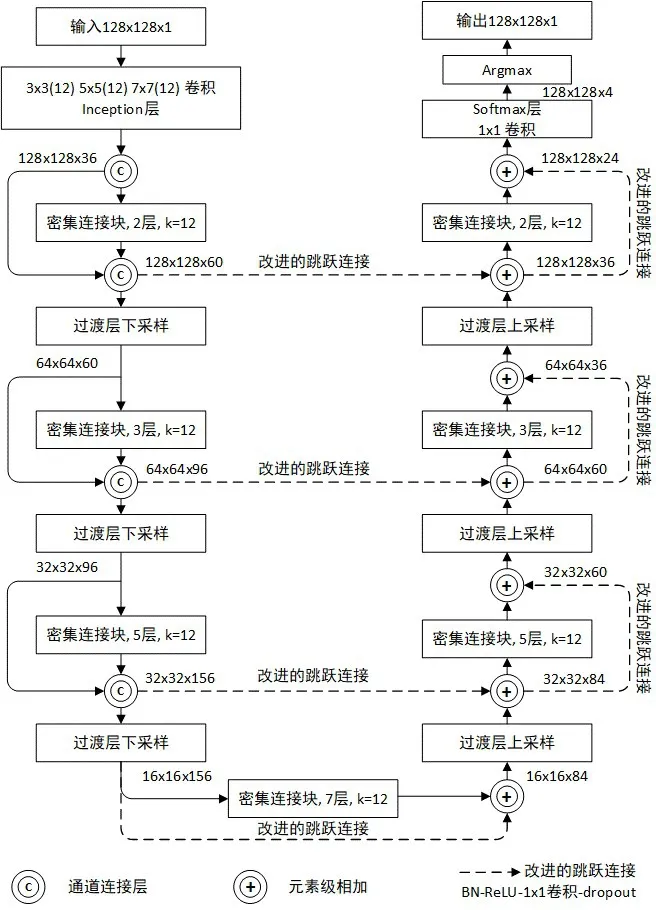
图1 网络结构
在输入128×128×1 的图像后,首先通过改进的Inception 模块[19]获得图像的多尺度特征。其中原始的Inception 模块由步长为2 的最大池化操作和卷积核大小分别为1×1、3×3、5×5 的卷积操作组成,改进后的Inception 模块由3×3、5×5 和7×7 大小卷积核的卷积操作组成,去除了最大池化操作,并引入了更大的7×7 卷积核的卷积操作,扩大了模型的感受野,有利于大目标区域的检测,并减少与目标相似的假阳性区域的误判。
下采样部分类似于DenseNet[18]的结构,在上采样部分通过转置卷积、密集连接和改进的跳跃连接[10],使下采样的结果恢复到原始输入的空间分辨率。改进的跳跃连接由批次归一化(Batch Normalization,BN)、ReLU 激活函数、1×1 卷积操作和dropout 组成,使得下采样和上采样过程中不同维度的特征通道通过投影操作相匹配,实现了跨通道的特征信息交互。使用元素级相加进行拼接,与直接的特征通道拼接相比,减少了参数量和内存占用。
最后将上采样得到的特征图与1×1 卷积层和softmax 层相结合,使用Argmax 生成分割的最终结果图。
3.2.2损失函数
在心脏MRI中,心脏相关结构对应的像素为前景像素,心室周围组织器官对应的像素为背景像素。在整个心脏MRI 中,绝大部分的像素都属于背景像素,因此网络预测的结果可能会更偏向于背景类像素,如果不给前景像素设置足够的权重,会导致网络训练倾向于给背景类像素更高的权重,造成大量像素的错误分类。在医学图像中,这种严重的类不平衡问题通常由损失函数解决,例如Dice 损失[20]和加权交叉熵损失[21]等。
交叉熵损失通过计算预测的输出类和目标类之间的体素误差概率来度量所有体素的累积误差。假设y是真实的概率分布,是预测的概率分布,即神经网络的输出,则交叉熵函数的公式定义为:

其中yi表示样本i的指示变量,如果样本i的预测类别与该样本的类别相同则值为1,否则为0;表示样本i类别的预测概率。
如果有N个训练样本,则整个样本的平均交叉熵为:
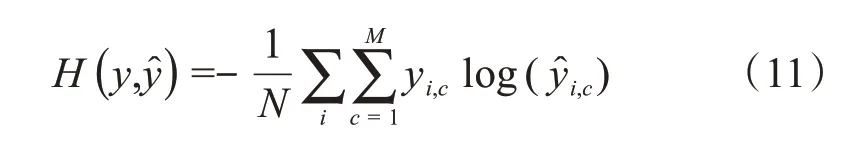
其中M表示类别的数量;yi,c表示样本i的指示变量,如果样本i的预测类别与该样本的类别相同则值为1,否则值为0;表示观测样本i属于类别c的预测概率。
考虑单独使用交叉熵损失无法解决这种出现的类不平衡问题,本文设计加权方案用于加权交叉熵损失的计算。
从手工分割真实标注图像生成权重图,用于加权交叉熵损失公式在每个体素处计算的损失。加权交叉熵损失LW由下式计算:
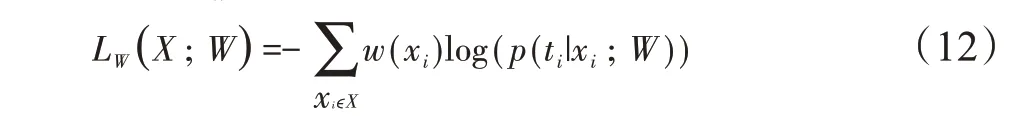
其中,W=(w1,w2,…,wl)为可学习权重的集合,wl为与深度学习网络第l层对应的权重矩阵,X为训练样本,ti为体素xiϵX对应的目标类标签,w(xi)为在每个体素xi处估计的权重,p(ti|xi;W)表示网络最后输出层的对体素xi的概率预测。
V-net[20]提出了图像分割领域中另一个常用的损失函数Dice-loss。Dice 损失函数是根据dice 系数设计的。V-net中的损失函数为:
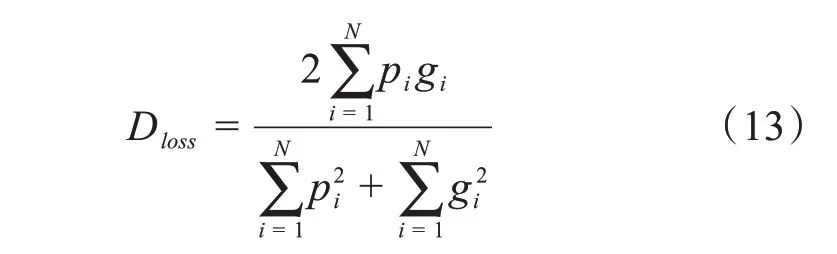
其中pi是第i个像素值预测的结果,gi是其真实值,1 代表目标,0 代表背景。Dloss的取值在0 到1 之间,越接近1表示预测的结果越接近真实值。
最终损失函数使用加权交叉熵和Dice 系数的组合,并使用L2正则化,形式如下式所示:

其中,λ、γ和η是单个损失的权重参数,||∙||为L2范数,||W||2为L2 正则化项,其权重参数设置为η=5× 10−4。
4 实验结果与分析
4.1 实验设置
本文网络基于Python 3.6 和Tensorflow 1.12 实现。实验均在服务器的单个Nvidia Geforce GTX 1080ti GPU卡上进行。网络训练使用ADAM优化器,学习率设置为0.001,损失函数由式(14)确定。数据集使用MICCAI 在2017年提出的ACDC 数据集,共150例不同患者的心脏短轴电影序列MRI 图像数据,其中包含有左心室、右心室以及心肌(心外膜轮廓)的专家手动分割标注的病例100例。网络训练批次由16幅预处理后的128×128 的二维MRI 图像组成,设置训练epoch 为250。每个epoch 后,在验证集上对模型进行评估,确保最终选择的用于测试集评估的最佳模型在验证集上具有最佳的分割评估效果。
4.2 实验结果分析
读取原始心脏MRI数据,经过包含ROI检测的预处理步骤后,得到结果如图2 所示,其中(a)为原始心脏MRI数据输入,(b)为经过ROI检测后,以左心室为中心绘制了包含整个左心室的ROI灰色掩膜。

图2 ROI检测结果
经过图像数据标准化和数据增强处理后,根据ROI 检测得到的ROI 区域中心和区域半径,将图像数据裁剪为以ROI 中心即左心室为中心的128×128大小的块,作为深度学习分割网络的输入。与将每张切片空间分辨率平均为235-263个体素的原始心脏MRI 切片数据直接作为输入相比,使用相同的模型训练占用的GPU 显存大小从10GB 以上下降为不到6GB。
ROI 检测分割结果如图3 所示,图3 中(a)为输入图像,(b)为经过ROI裁剪后的128×128大小的图像。
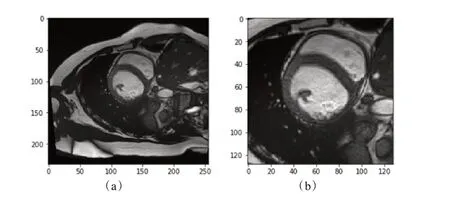
图3 ROI检测分割结果
将经过预处理后的图像数据输入深度学习分割网络训练250个epoch 后,将训练得到的模型应用到测试集上得到分割结果。以一例患者心脏ED 时的分割结果为例,如图4 所示,图中(a)为患者心脏ED 时的原始MRI,(b)为ED 时的专家手动分割标注,(c)为ED 时的网络分割结果,(b)和(c)中白色为左心室区域,浅灰色为心肌区域,深灰色为右心室区域。可以观察到本文所提出方法分割结果与专家手动标注结果非常接近,准确分割了左心室、右心室和心肌。

图4 患者分割结果
本文采用Jaccard 系数,Dice 重叠系数和豪斯多夫距离来评估测试数据分割效果,它们在医学图像处理的评估上已经得到标准化。
Jaccard 系数又称为Jaccard 相似系数,用于比较样本集之间的相似性与差异性,Jaccard 系数值越大,样本相似度越高。Jaccard 系数定义如下式,其中P和G分别为预测和真实标签轮廓所包围的像素集:
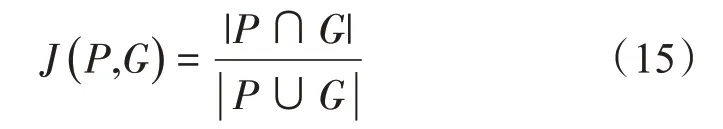
Dice 系数基本上衡量了预测的标签与真实值的相似程度,Dice系数取值为0到1之间,越高的Dice系数表示分割的性能越好。Dice系数定义如下式:
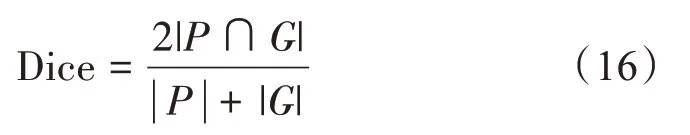
豪斯多夫距离是描述两个点集之间距离的一种度量,度量了两个点集间的最大不匹配程度,高豪斯多夫距离表示两个点集不紧密匹配。豪斯多夫距离定义如下式:

其中p和g分别为点集P和G中的点,d(p,g)为两点间的欧几里得距离,||∙||为L2范数。
本文分割模型训练使用的损失函数由式(14)确定,式中λ、γ和η均设置为1。与使用其他损失函数训练作对比,对分割结果分别使用Dice 重叠系数、HD、Jaccard 系数进行评估,结果见表1、表2 和表3,其中CE 表示交叉熵损失函数,Dice 表示Dice 损失函数,SwCE 表示加权交叉熵损失函数,L2 表示L2 正则化,ED 和ES 分别表示心脏心动周期的舒张末期和收缩末期。表中数值为平均值,括号内为标准差。

表1 不同损失函数分割结果评价(Dice系数)
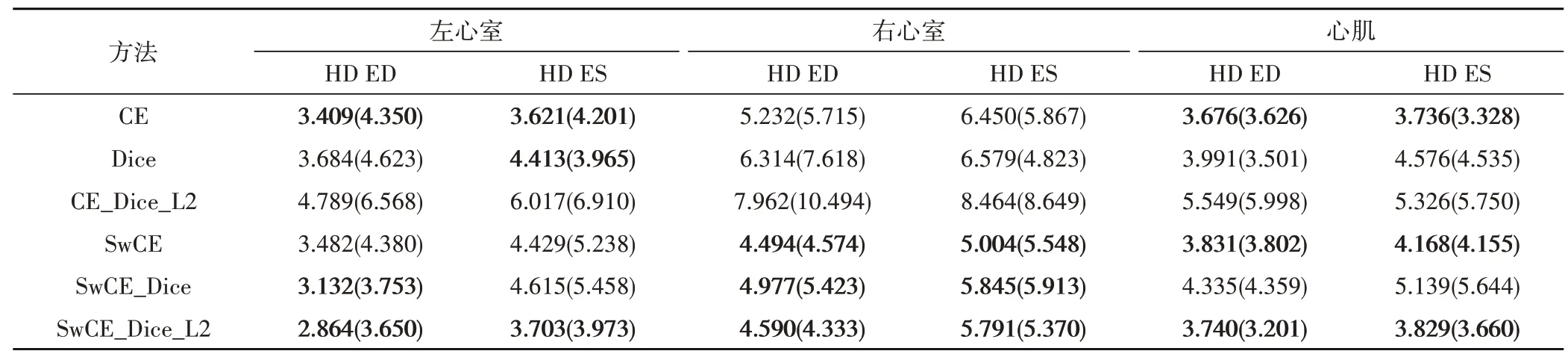
表2 不同损失函数分割结果评价(HD)
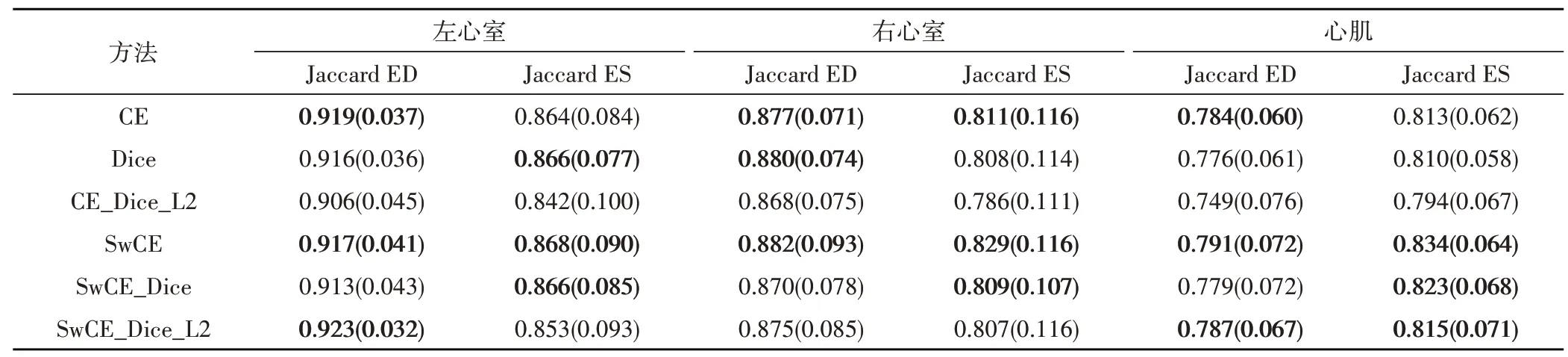
表3 不同损失函数分割结果评价(Jaccard系数)
将分割结果评估前三用粗体显示,可以看到本文提出的加权交叉熵损失函数SwCE 有显著的优越性,在左心室、右心室和心肌上的分割结果评估均获得领先,证明本文提出的加权方案可以更好的解决医学图像中的类不平衡问题。
使用由式(14)确定的SwCE、Dice、L2 正则化相结合的损失函数的分割结果,在豪斯多夫距离上取得了最优的评价,表明分割的整体效果接近专家手动标注结果,在心脏的基底和心尖也没有出现偏差过大的误判,分割模型的鲁棒性要比单独使用Sw-CE 损失函数更好。
我们比较了本文提出的模型与2017年ACDC 挑战前三名的模型,在50例测试集上的分割结果评估对比如表4和表5所示。结果表明本文提出的方法与挑战前三名获得了相近的结果,并且在HD 这一评估指标上结果优秀,表明与专家手动标注结果更接近,误判区更少,在心脏的基底和心尖切片处的分割效果更稳定,模型的鲁棒性更好。

表5 与其他模型对比(HD)
5 结论
本文提出了一种基于深度神经网络的心脏MRI自动分割方法。提出的心脏MRI 分割方法由预处理和分割两部分组成。预处理步骤包含了使用Canny边缘检测和霍夫变换等方法的感兴趣区域检测、数据标准化、数据增强等,能够减少模型训练占用的内存大小以及非目标域信息带来的干扰,改善训练数据不足时分割模型的性能。预处理后,我们对检测到的ROI 进行心脏结构的自动分割,提出的分割模型基于Jégou 等人2017年提出的语义分割架构进行改进,模型的训练使用提出的加权交叉熵、Dice 系数和L2 正则化组合的损失函数。我们在ACDC 数据集上实验了我们的方法,并与其他人作对比,实验结果表明,我们的方法的分割结果接近专家手动分割结果,在客观评价指标上获得了优秀的表现,且该方法具有更好的鲁棒性。
猜你喜欢
昆明医科大学学报(2021年4期)2021-07-23
小天使·二年级语数英综合(2019年10期)2019-11-08
科学养生(2018年6期)2018-10-15
通信产业报(2016年44期)2017-03-13
共产党员(辽宁)(2015年2期)2015-12-06
医学研究杂志(2015年12期)2015-06-10
读者·校园版(2015年19期)2015-05-14
中国社区医师(2009年18期)2009-10-26
雕塑(1999年2期)1999-06-28
雕塑(1996年2期)1996-07-13
