
基于时间序列模型和情感分析的情感趋势预测
2021-11-01 13:26孙嘉琪王晓晔温显斌
计算机工程与设计 2021年10期
孙嘉琪,王晓晔+,杨 鹏,温显斌,高 赞,于 青
(1.天津理工大学 计算机科学与工程学院,天津 300384; 2.天津理工大学 天津市智能计算及软件新技术重点实验室,天津 300384; 3.齐鲁工业大学 山东省计算中心,山东 济南 250014)
0 引 言
随着网络社交媒体的发展,大众更倾向于在诸如微博、论坛这些媒体上来发表针对某话题或事件的看法。这些评论一般内容精练,观点明确,因此以往的情感分析方法主要都是根据对评论文本特征进行挖掘,从而对情感极性进行判断。然而,现如今社交平台上的评论都是跟随事件发展实时发表的,其蕴含的情感随时间的推移发生改变。这种改变在一定程度上是对某一事件未来走向的反映。因此,挖掘这些评论中蕴含的情感观点,分析并预测大众情感走势在下一时间段的变化过程就十分必要。以股市论坛为例,投资者针对当天股市趋势实时地发表个人的观点,其所蕴涵的投资者情绪也是在时刻变化的,对其情感趋势进行预测在一定程度上也是在帮助投资者了解未来股市发展。时间序列模型是当前进行趋势预测的较好方法,能够刻画时间序列的未来走势。因此,为了有效利用评论数据的实时性来进行情感趋势的预测,本文提出将时间序列模型与情感分析相结合,对投资者情感值时间序列进行建模分析,充分体现了深度学习注重特征学习的优势与时间序列分析方法对趋势预测的有效性。
1 相关工作
挖掘情感观点,即情感分析,是人们对实体、事件及其属性的意见、评价和情绪的计算研究[1],是当前自然语言处理重要任务之一,目前,发展较快的研究方法是基于深度学习的方法。文献[2]介绍了运用CNN(convolutio-nal neural network)进行文本分类的方法,提出通过标记好的数据训练出卷积神经网络从而达到预测数据类别的效果。文献[3]提出了用LSTM(long-short term memory)网络对文本进行情感分类,重点关注词语间的关系。在更复杂的情感分析任务中,文献[4]为了充分利用短文本的情感特征信息,提出一种结合卷积神经网络和词语情感序列特征的情感分析模型。针对各具有特点的语料,上述这些方法可以完成不同文本的情感分类任务。但单纯的情感分析方法仅局限于对情感所属的类别进行判断,很难对于未来情感走势的变化进行预测。
时序情感趋势预测的提出是为了探究情感趋势在下一阶段的走向,对情感分析的实时性进行研究。文献[5]采用传统时间序列模型进行情感走势的追踪,利用Twitter收集到的数据,以机器学习的方法检测情感变化并探究其变化原因。文献[6]结合微博的情感时序变化提出了一种实时的非参数化的热点主题检测方法,通过微博情感极性分析及其强度变化来计算情感时序分布,构建复合模型,以此检测微博热点主题。
在股票市场这一领域,已经有研究融合社交媒介数据,借助于情感分析对投资者情绪与股票市场关系进行探究。文献[7]介绍了用朴素贝叶斯和支持向量机的方法提取投资者情绪信息,并据此预测股票价值。文献[8]根据Twitter用户情感数据,采取监督的机器学习方法得出Twitter公众情绪与公司股票走势具有相关性的结论。文献[9]提出一种构建股票论坛关注度指标的方法,结合股票评级数据,得出股票交易量受到情绪一致性影响的结论。这些研究在一定程度上都验证了行为金融学中投资者的情绪会随股市行情发生改变,也会对市场造成影响的理论。但是对于情绪数据的实时性关注的不够,时序情感数据的时效性和有序性没能有效应用于对投资者情感趋势预测上,同时,情感分析方法大部分采用基于情感词典和机器学习的方法,而金融领域尚未形成权威的情感词典,机器学习的方法容易忽略数据相关性,特征工程需要耗费大量人工精力去调整研究。
针对上述问题,本文提出一种基于时间序列分析的情感趋势预测方法。收集股市论坛评论数据并人工标注,同时为确保数据量满足深度学习模型的需要采用数据扩增方法,选择深度学习模型对评论数据进行情感分析,提出ARIMA-GARCH(auto regressive integrated moving average-generalized auto regressive conditionally heteroscedastic)时间序列模型对情感趋势进行预测。
2 基于BERT-BLSTM的情感分析
2.1 短文本向量化
经过预处理后的短文本需要向量化表示才能作为分类模型的输入。目前大部分的文本分类任务中,词向量转化模型都采取的是Word2vec模型,但是,其不能通过上下文进行一词多义的区分。为了改进这一问题,本文选择用BERT(bidirectional encoder representations from transformers)模型[10]来进行文本向量化表示。
BERT的重要部分是基于双向Transformer编码器实现的,其模型结构如图1所示。它可以学习每个单词前后两边的信息,获得更好的向量表示。根据上下文的不同,会输出不同的向量。

图1 BERT模型结构[10]
本文使用BERT模型输出的是字符级别的向量,即输入短文本的每个字符对应一个向量表示,直接将字符级向量作为特征输入BLSTM(bidirectional long short-term me-mory)模型。
2.2 算法结构
为了能同时考虑短文本上下文语义信息,充分提取短文本包含的所有特征,本文构建双向长短时记忆网络进行情感分类。其算法结构如图2所示。

图2 BERT-BLSTM算法结构

前向传播层的计算公式如下
后向传播层的计算公式如下
将两者合并到得到输出可以得到Ht,如下式所示
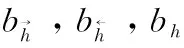

3 基于时间序列模型的情感趋势预测
3.1 时序情感值构造
本文使用时间序列模型进行情感趋势的预测需要利用历史情感值,这里采用基于Antweiler和Frank提出的看涨指数的计算方法[11]构建情感值,来反映在某时间跨度上情感的走势,对情感信息进行整合。这种看涨指数BI的计算方法整合了看涨评论及看跌评论,是一种较好的衡量投资者情绪的指标。计算公式如式(1)所示
(1)

3.2 基于ARIMA-GARCH的情感趋势预测模型
首先对ARIMA和GARCH时间序列模型进行简单介绍。对于平稳的时间序列,可以采用阶数为p和q的自回归移动平均模型,但现实情况是,不会存在理想化的完全的平稳时间序列,针对非平稳和非季节性数据,需要进行差分操作,即选择ARIMA(p,d,q)模型,ARIMA模型是根据已有观察数据的特点从而对下一时间段的数据进行预测的[12],令yt和εt分别为时间段t内的观测值和随机误差,μ为模型均值,φ1,φ2,…,φp是阶数为p的自回归参数,θ1,θ2,…,θq是阶数为q模型的移动平均参数,d是差分的阶数。一般情况下,ARIMA(p,d,q)可以用式(2)表示
φp(L)(1-L)d(yt-μ)=θq(L)εt
(2)

本文所构建的情感值时间序列并不平稳,因此,选择ARIMA模型更为适用。
由于情感趋势预测模型可能存在残差项,因此需要检验残差项的异方差效应并建立GARCH模型。单独的ARIMA模型无法对残差项异方性检验,从而会导致出现模型精度不高、重要信息缺失的问题。而GARCH模型的建立,能够有效解决这些问题,对情感值变化的随机性进行考虑。
GARCH模型本质上就是针对时间序列的波动率进行建模的,是由Bollerslev最早提出的。它从ARCH模型变形而来。对于单变量序列,令其均值方程用式(3)表示为
yt=μt+at
(3)
其中,μt表示yt的条件均值,at为时间t时的残差且at=σtεt,此时εt~iidN(0,1)。
当满足
(4)

本文将ARIMA和GARCH混合,主要是分两个阶段,在第一阶段,用ARIMA模型对情感值时间序列数据进行建模,得到其残差部分。在第二阶段,判断其残差部分是否存在异方差效应。若不存在异方差效应,直接选择ARIMA作为预测模型;存在异方差效应,用GARCH对残差进行建模,与ARIMA建模部分结合输出。将构造的情感值时间序列作为ARIMA-GARCH模型的输入,其过程如图3所示。

图3 ARIMA-GARCH模型结构
4 实 验
4.1 数据集
4.1.1 数据集描述
本文创建上证指数评论数据集,数据来源于东方财富网上证指数(SSCI)吧,东方财富网是中国访问量最大,影响力最大的财经证券门户网站之一,为用户提供交流学习的机会,该股吧允许投资者根据当天大盘情况24小时随时发表观点,在每天的任意时刻都有投资者发表评论。因此股吧评论带有时间属性。
本文收集从2019年8月8至2019年8月28日的股票论坛评论数据近13 000条构成数据集,手动将评论数据的标记为3种情绪,0代表看跌情绪(bear),1代表看涨情绪(bull),2表示中立情绪(neutral),同时将数据集分为训练集、验证集和测试集。训练集的各类投资者情绪数据分布如图4所示,可以看出不同情感极性的评论数量是显著不同的。

图4 各类情感极性评论每日数量分布
另外,以两周为例,每日评论总数统计如图5所示,可以看出周一及周五的评论数在一周内最多。这可能与股市工作日有关,周六日为股市休市时间,周一可能会出现集中式的观点表达。而周五是可以做投资交易的最后一天,那么在当天投资者可能会给出更多的意见,为周五的决策建议。
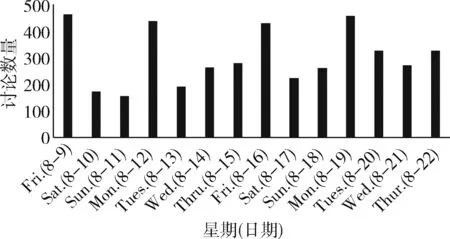
图5 14天内每日评论总数统计
4.1.2 数据扩增
为满足深度学习对于数据量的要求,这里采取EDA数据扩增方法。首先对EDA(easy data augmentation)进行一下简单介绍,EDA由4个操作组成:同义词替换、随机插入、随机交换和随机删除[13]。下面对这4种操作进行描述。
同义词替换[13]:在句子中随机抽取除停用词以外的词语,用随机选择的同义词对抽取出的单词进行同义词替换。在本文中,使用哈工大的同义词词林作为同义词选择的词典,哈工大同义词词林是中文中现今相对最为完整的同义词词林。
随机插入[13]:在不考虑停用词的情况下,随机抽取一个词语,然后在该词的同义词集合中随机选择一个,插入原句的随机位置。
随机交换[13]:随机选择句子中的两个词语进行位置交换,这个过程可以重复多次。
随机删除[13]:对句子中的单词按照概率α进行随机删除。
根据文献[13]提出的这一数据扩增方法,已经验证针对类似本文大小的数据量进行扩增数据量对于分类任务的准确率有所提高,并且选取对每条数据中概率为α=0.1的词语进行上述操作时,效果最好。因此,本文也采取α=0.1的方法对数据量进行扩充。经过数据扩增之后,训练数据集大小扩充到接近100 000条。
4.2 情感分析
4.2.1 数据预处理
本文的预处理过程主要包括以下几个部分。本文所用数据为论坛用户的评论短文本,其中不乏一些特殊符号和空白,所以需要对文本进行清洗,去除特殊符号和空白;根据停用词词库去除无实际意义的停用词;本文研究的主要是不超过200字符的短文本,因此将部分过长文本过滤掉,包含对研究毫无意义的内容的评论也选择过滤掉。
4.2.2 实验设置
为了更好评价所提出算法的性能,设置CNN和CNN-LSTM[14]对照实验组,同时为了衡量词向量嵌入方法对分类效果的影响,与Word2vec词嵌入方法作对比。其中Word2vec词向量维数为300维,向量均由 Skip-gram 算法训练得到。本文使用的BERT预训练模型是Google提供的BERT-Base模型,网络结构一共12层,隐藏层有768维,采用12头模式,学习率5e-5。对照实验组设置如下:
(1)Word2vec+CNN:将经过Word2vec训练得到的词向量,使用卷积神经网络对数据进行特征提取,并使用Softmax分类器进行情感分类,计算该训练样本属于某类的概率;
(2)Word2vec+CNN-LSTM:以词向量为输入,经过CNN层,提取特征值,将其输入LSTM层,以文本特征词与前后序列的形式学习上下语义,输出一个向量。将所得向量经过Dropout层及全连接层处理,最后采用Softmax分类器判定情感类别;
(3)Word2vec+BLSTM:以词向量为输入,使用 BLSTM 进行训练,将提取的特征向量采用Softmax分类器判定情感类别;
(4)BERT+CNN:采用BERT预训练模型获得字符级向量作为输入,其余设置与第(1)组相同;
(5)BERT+CNN-LSTM:采用BERT预训练模型获得字符级向量作为输入,其余设置与第(2)组相同;
(6)BERT+BLSTM:采用BERT预训练模型获得字符级向量作为输入,其余设置与第(3)组相同。
4.2.3 评价指标
本节研究的内容属于分类问题,用于评估模型性能的指标为精确率、召回率及F1值。在这里我们取其精确率均值precision-m、召回率均值recall-m以及F1均值F1-macro。具体如下式表示
(5)
(6)
(7)
(8)
(9)
(10)
其中,i是情感极性的标签,N是情感极性类别的数量,TP、FN、FP、TN的含义见表1。

表1 准确率
4.2.4 实验结果及讨论
本文设置的各对比实验的结果见表2。对比实验(1)与实验(4),实验(2)与实验(5),实验(3)与实验(6),可以看出,针对同种分类模型,利用BERT预训练模型进行文本向量化的方法比利用Word2vec词嵌入模型进行词向量转换的方法在准确性、召回率、F1值上都有明显提升,平均提升0.06;同时,对比实验(4),实验(5),实验(6),可以看出,BLSTM模型的分类效果最好,准确率达到0.73,CNN-LSTM次之,CNN在这3种模型中分类效果最差,我们可以将此现象归因于CNN对文本全局特征的学习能力不强。对比实验(3)与实验(6),基于BERT字符级向量的 BLSTM 算法相较基于Word2vec词向量的BLSTM算法具有更好的细节信息拟合能力,能够提取更多的文本字符所蕴含的细节特征。因此,综上,基于BERT-BLSTM的情感分析方法的性能在这一数据集上表现更为出色,准确率、召回率分别达到0.73和0.75。

表2 对比实验结果
4.3 情感趋势预测
基于BERT-BLSTM情感分析方法,可以对评论数据进行自动情感分类。本文根据所得的情感分类结果,结合3.1节中提到的情感值计算方法,计算固定时间单位内的情感值。这里所选定的情感值计算的时间跨度为12 h,将计算得出的情感值时间序列数据作为ARIMA-GARCH模型的输入,从而预测未来情感趋势。
4.3.1 模型参数确定
首先采取ADF(augmented dickey-fuller)检验方法对将构造的情感值时间序列进行平稳性检验,它是一种常见的判断时间序列平稳性的方法[15,16]。ADF检验的原假设是存在单位根即序列是非平稳的,检验统计量是同时小于1%,5%,10%水平下的数字就可以显著地拒绝原假设,即判断序列平稳。检验结果见表3,其中检验统计量为-3.07,大于置信度1%水平下的值,则判断所构造的时间序列不平稳。因此需要进行差分操作,即需要确定ARIMA(p,d,q)中的参数d。在进行一阶差分后,对时间序列进行平稳性检验,检验结果见表4,其中检验统计量为-6.38,小于置信度1%,5%,10%水平下的值,则判断一阶差分后的情感值时间序列平稳,即d=1。

表3 原始情感值时间序列后的ADF检验

表4 情感值时间序列一阶差分后的ADF检验
本文采用对序列自相关性ACF、偏自相关性PACF图的分析,得出p,q的取值。图6为一阶平稳序列ACF、PACF图,可以看出,其中ACF在滞后5期,PACF在滞后4期出现较大衰减,因此判断p,q范围分别为5~7和4~6,根据对均方根误差值的比较,确定预测效果最好的p,q取值。

图6 一阶平稳序列ACF、PACF
接下来需要对残差部分进行异方差性效应的检验,采用LM检验法,得到0.9956,显著不为 0,表明存在异方差效应,则需要建立GARCH(r,s)模型。通过对图7中残差序列ACF、PAC F的分析得到r=1,s=1,由以上建立 ARIMA(p,d,q)-GARCH(1,1)。
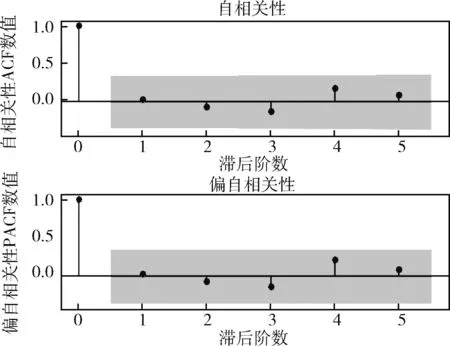
图7 残差序列ACF、PACF

(11)
ARIMA(p,d,q)-GARCH(1,1)采用不同p,d,q取值时的预测误差见表5。由表5可以看出,当p=6,d=1,q=5时,预测效果最好,其均方根误差的值最小。相比其它几组值,误差最多降低了0.12,均方根误差达到了0.692。同时可以看出,当p,q增加一定量值时,预测误差会有所下降,但是,并不是都取其可取范围内的最大值时,预测效果就最好,预测误差可能反而会增加。因此,确定预测模型为ARIMA(6,1,5)-GARCH(1,1)。

表5 ARIMA(p,d,q)-GARCH(1,1)不同p,d,q取值时的预测误差
4.3.2 实验结果讨论
如图8所示,在ARIMA(6,0,5)-GARCH(1,1)模型下,将情感值预测结果与实际情感值对比,并且对未来8个时间段的情感值进行预测。为了能够更加形象地展现此ARIMA-GARCH模型在预测情感趋势上的效果,我们选取传统时间序列模型ARIMA(6,0,5)进行情感值预测作为对比。可以看出,ARIMA-GARCH模型的预测精准度相较于ARIMA模型更高,对原始数据拟合效果较好,个别预测值与实际完全拟合。从图9来看,股市大盘指数的涨跌幅与投资者情感趋势存在相关关系,走势存在相似之处,具有一定的参考价值。但二者并不完全相同,很大程度上是由于股市的不确定性、政府政策及当前经济形势都会影响股市发展。

图8 ARIMA-GARCH模型拟合及预测效果

图9 股市的涨跌幅度与当日预测情感值对比
5 结束语
在本文中,将时间序列模型与情感分析相结合,用BERT-BLSTM对股市论坛评论数据进行情感分类,构建情感值时间序列,提出ARIMA-GARCH时间序列模型对情感值时间序列进行建模分析。在情感分类中,通过与其它几种文本分类模型实验结果的对比,表明采取BERT模型对文本向量化并且采用BLSTM进行文本分类的方法能获得更好的分类效果。同时,本文提出的基于ARIMA-GARCH对情感趋势预测的方法简单直接,可以直观地展现情感值的发展趋势,投资者情感趋势预测结果较好,预测值与真实值的拟合效果也在预期范围之内。结合真实股市涨跌幅数据进行比较,情感走势既是对股市发展的侧面反映,也在一定程度上对行为金融学观点进行验证。在未来的工作中,可以尝试对某一特定领域的股票进行研究,也可以尝试对其他国家股票市场发展与其投资者情绪之间关系进行研究。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
新高考·高一数学(2022年3期)2022-04-28
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
