
中国工业碳排放达峰预测及控制因素研究
——基于BP-LSTM神经网络模型的实证分析
2021-11-08 09:52胡剑波杨苑翰
贵州社会科学 2021年9期
胡剑波 赵 魁,2 杨苑翰
(1.贵州财经大学,贵州 贵阳 550025;2.贵州师范大学,贵州 贵阳 550025;3.悉尼大学,澳大利亚 悉尼 2000)
一、引言
工业革命以来,人类活动冲击了原有碳循环系统中碳源(碳排放)和碳汇(碳吸收)的平衡,化石能源的使用导致大气中二氧化碳浓度不断上升,引发了温室效应和全球气候变暖。按照政府间气候变化专门委员会(IPCC)的预测,到2100年全球平均温度将比工业革命之前的水平高1.5~4.8度,如果不采取应对措施,按照现有趋势,气候变化对人类社会经济的冲击将日益严重。气候问题具有超大时空尺度的外部性,需要全球协同应对。2017年,29个国家签署《碳中和联盟声明》,承诺在21世纪中叶实现零碳排放;2019年9月,在联合国峰会上有66个国家承诺实现碳中和愿景;2020年5月,全球449个城市参与了由联合国气候专家提出的零碳竞赛;截至2021年1月,有127个国家承诺在21世纪中叶实现碳中和愿景。[1]目前,不丹、苏里南等国家已实现碳中和目标,英国、瑞典、法国、新西兰等国已将碳中和目标写入法律。
碳达峰、碳中和将给人类社会带来长远的收益。碳达峰是指某个地区或行业年度二氧化碳排放量达到历史最高值,然后经历平台期进入持续下降的过程,是二氧化碳排放量由增转降的历史拐点,标志着碳排放与经济发展实现脱钩,达峰目标包括达峰年份和峰值。碳中和是指某个地区在一段时期内(一般指一年)人为活动直接和间接排放的二氧化碳,与其通过植树造林等吸收的二氧化碳相互抵消,实现二氧化碳“净零排放”。碳达峰与碳中和紧密相连,前者是后者的基础和前提,达峰时间的早晚和峰值的高低直接影响碳中和实现的时长和实现的难度;而后者是对前者的紧约束,要求碳达峰行动方案必须要在实现碳中和的引领下制定。[2]2020年9月,习近平总书记在第七十五届联合国大会一般性辩论上的讲话中提出“中国将提高国家自主贡献力度,采取更加有力的政策和措施,力争于2030年前二氧化碳排放达到峰值,努力争取2060年前实现碳中和”,并在12月气候雄心峰会上进一步宣布了我国国家自主贡献的四项新举措。习近平总书记强调,实现碳达峰、碳中和是一场广泛而深刻的经济社会系统性变革,要把碳达峰、碳中和纳入生态文明建设整体布局。碳达峰目标与碳中和愿景,彰显了中国积极应对气候变化、走绿色低碳发展道路的坚定决心,体现了中国主动承担应对气候变化国际责任、推动构建人类命运共同体的责任担当,为全球气候治理进程注入了强大的政治推动力,受到国际社会高度赞誉,是中国为应对全球气候变化作出的新的重大贡献。
改革开放以来,我国经济社会持续快速发展,经济实力、科技实力、综合国力不断迈向新台阶,在经济社会快速发展的同时,我国加快推进绿色低碳转型、积极参与全球气候治理,取得了显著成效,但我国产业结构、能源结构转型任务仍然任重道远。据世界银行(World Bank,WB)数据显示,中国是世界上工业门类最齐全的国家,有220多种工业品产量居全球第一。但由于工业化起步晚、行业覆盖面广,当前,仍有很多高能耗、高排放和低附加值的工业行业,以致于工业碳排放达峰成为全国碳达峰的关键所在。在三次产业的碳排放总量中,第二产业的碳排放量最高;在第二产业内,工业是最大的能源消耗与碳排放部门,对能源结构调整、产业结构优化、技术升级等影响巨大。[3]因此,研究工业碳排放对于碳达峰目标和碳中和愿景有着积极且重要的意义。
国家统计局数据显示,2000—2020年我国能源消费总量逐年增加,从2000年的14.70亿吨标准煤上升到2020年的49.80亿吨标准煤,年均增长6.29%。工业行业(包括3大门类,即采矿业,制造业,电力、热力、燃气及水生产和供应业,下面简称为“电力业”)能源消费占比从2000年的70.09%,经过略微的上升之后于2007年达到峰值72.51%,随后虽然有所下降,但截至2019年其占比仍然高达66.16%(见图1)。由此可见,工业碳排放达峰是全国碳达峰工作中极其重要的组成部分。

图1 2000~2019年中国工业与其他行业能源消费量对比
鉴于我国整体实现碳排放达峰目标不足10年,达成碳中和愿景有将近40年,前者是后者实现的基础;加之在预测研究中年限越久远,其精度越差。因此本文将重点解决的问题聚焦在预测工业能否于2030年前实现碳达峰,以及调控哪些因素可促使目标的顺利实现。
二、文献综述
国内外学者关于工业行业碳排放和碳达峰的相关研究主要集中在以下两个方面:一是关于工业碳排放影响因素的研究,二是关于碳达峰的预测模型及其情景分析。
在关于工业碳排放的影响因素分析中,其变动主要受到规模、结构、技术和环境规制等因素影响。郭朝先等证明碳排放量与工业产业规模的关联最为明显[4],林伯强和蒋竺均发现工业能源强度对二氧化碳排放量有显著影响[5],苏永乐等更进一步,认为能源强度对碳排放量的抑制作用最强,其次是产业结构,最后是能源结构。[6]结构方面,中国东中西部地区结构不平衡,[7]工业高排放产业规模大,国际分工与出口产业科技含量不足,[8]都制约着工业碳排放达峰的尽早到达。技术和环境规制则是降低碳排放量的有效方式,发展绿色金融[9]、提升工业产业附加值[10]、发展碳捕获、利用与封存(CUUS)技术[11],建立碳税及碳交易市场[12],均能缓解工业碳排放量。此外,大自然在碳减排过程中扮演着重要的角色,森林生态系统可以吸收人类排放总碳量的48.7%[13],海洋可以吸收约30%。[14]
在关于碳达峰的预测模型与情景分析中,当前主要有LMDI分解模型、Kaya恒等式、STIRPAT模型及BP神经网络等。Paul最先提出LMDI因素分解法,即保持其他因素变量不变的条件下,分别对各变量微分,从而求出各因素变化对目标量的影响;[15]由于易于计算和便于理解,其被广泛应用于能源环境经济领域的分解分析和研究。[16]国内一般将LMDI分解法[17]、以及改进的LMDI分解法[18]同情景预测结合起来对工业碳排放进行研究。Kaya将社会、经济、能源、排放作为温室气体排放的影响因子,此后该恒等式作为IPCC常用的方法。[19][20]Dietz与Rosa为了降低IPAT模型的局限性提出了STIRPAT模型[21],碳排放的影响因素主要分解为人口规模、经济发展水平、技术水平。国内学者对STIRPAT模型进行适当改进后,用于工业碳排放影响因素的相关研究,并取得较为丰富的研究成果。[22][23]然而现实经济社会的发展往往是非线性的,BP神经网络因具有误差反向传播特性,拥有自学习、自组织、自适应能力等优点,学者王艳旭、赵金元等实证显示BP神经网络比多元线性回归模型有更好的预测精度,在工业碳排放量的预测分析中有一定的应用。[24][25]预测的具体过程一般是将不同因素与高、中、低几种情景单独或者组合起来进行情景预测,选择相应的指标如国内生产总值的发展速度,分为高、中、低三种不同的速度下,对未来不同情景下的碳排放达峰进行预测。余碧莹等根据不同情景分析得出全国碳排放量有望于2025年实现达峰,最晚于2030年达峰。[26]蔡博峰等预测中国2027年左右达峰,达峰后经历5~7年平台期。[27]李政等预测电力行业碳排放达峰的时间在不同情景下分别为2023及2029年[28],吴郧等预测发电碳排放量峰值可能出现在40亿~42亿吨。[29]
综上所述,已有文献对工业碳排放及碳达峰问题进行了大量研究,取得了较为丰富的研究成果,但仍然存在如下有待完善之处:第一,缺乏控制性变量的明确阐述及分析。在已有文献中,多数以单因素或多因素复合情景假设进行预测,然而实际经济发展往往是变量间耦合动态发展的,很难按照某一种提前假设的路径发展下去;另一方面,2020年中国全面建成小康社会的实际经验证明,我国有能力通过对某些关键变量的合理控制,从而实现碳达峰目标。简而言之,研究变量控制比情景预测更符合工业碳排放达峰这一课题。第二,缺少神经网络模型的应用。神经网络模型对非线性系统有良好的拟合效果,更适用于工业碳排放达峰的拟合及预测。现在采用神经网络研究碳达峰的文献非常少,研究工业碳排放达峰的更是鲜有涉及。
基于此,本文以STIRPAT模型为基础,合理选择工业碳排放的影响因素,并将其分为宏观调控中能影响工业碳排放达峰的关键因素作为控制变量,其余为非控制变量;在此基础上利用2000—2020年数据构建BP神经网络预测模型;对于2021—2030年的自变量,非控制变量采用LSTM神经网络模型进行预测,控制变量采用逆推法得出,将两类数据代入BP预测模型可对工业碳达峰进行预测,还可对控制变量进行敏感性分析,为中国工业碳排放达峰目标的实现提供一定的参考借鉴。本文的技术路线图参考图2。

图2 技术路线图
三、中国工业碳排放因素分解模型构建
(一)因素分解模型及变量选取
STIRPAT模型是由IPAT模型拓展而来的,可以在模型中引入多个规模、结构和技术相关的独立变量Ι=aPbΑcΤde
(1)
式中:I为环境压力;a为模型系数;b,c,d分别为人口、财富、技术水平的弹性系数;e为模型误差;P为人口数量;A为财富量;T为技术水平。STIRPAT模型在碳排放预测方面的应用往往是将P,A,T这3个变量进行分解或改进。
本文研究的是中国工业碳排放达峰问题,因此对STIRPAT模型的影响因素做了适当改进,具体公式和含义如下:
C=β0Q1β1Q2β2…Q9β9S10β10S11β11…S17β17T18β18T19β19e
(2)
式中,C表示因变量“工业碳排放量(万吨)”;Q表示自变量中的“规模因素”,包括全国年末总人数(万人)、工业增加值(亿元)、工业3大门类城镇单位就业人数(万人)、工业3大门类能源消费总量(万吨标准煤)以及森林蓄积量(亿立方米),小计9个变量;S表示自变量中的“结构因素”,其中,“人口城乡结构”用年末城镇人口比率(%)、“能源结构”用工业3大门类分别占工业能源消费比例(%),“产业结构”用工业3大门类分别占规模以上工业企业主营业务增加值比例(%),“贸易结构”用人民币兑美元汇率(元)分别计量,小计8个变量;T表示自变量中的“技术因素”,其中,“化石能源利用效率”用发电及电站供热总效率(%),“非化石能源消费比重”用一次电力(1)一次电力是指水电、核电、风电以及太阳能发电所发出的电力。及其他能源占一次能源生产总量的比重(%)分别计量,小计2个变量。具体指标及其说明见表1所示。
(二)数据来源与处理
工业在国民经济中属于第二产业,与之并列的是建筑业;工业往下可划分为3大门类,根据最新的2017年国民经济行业分类(GB/T 4754—2017),采矿业涵盖7个大类,制造业涵盖31个大类,电力业涵盖3个大类,共计41个大类(见图3)。

图3 中国产业结构细分图
工业碳排放研究相关数据主要来源于国家统计局网站,限于部分数据的可得性,因此用EPS数据平台作为补充,个别数据如森林蓄积量、工业细分行业增加值等缺失情况,通过DPS数据处理系统V15.10采用指数平滑法进行处理。根据国际能源署(IEA)2018年数据显示,从能源结构看,全球二氧化碳的排放中,煤炭的燃烧和使用贡献了约44%的二氧化碳排放量,石油贡献了约34%,天然气贡献了约21%,其他能源碳排放量占比不到1%。本文因变量工业碳排放量依据中国能源消费数据,即以2000—2020年工业3大门类(包括41个大类)逐年的煤炭、原油及天然气三种能源消费量为基础,采用IPCC方法及相关碳排放系数进行计算,全国三次产业碳排放总量,工业及其内部3大门类产业碳排放量情况如表2所示。
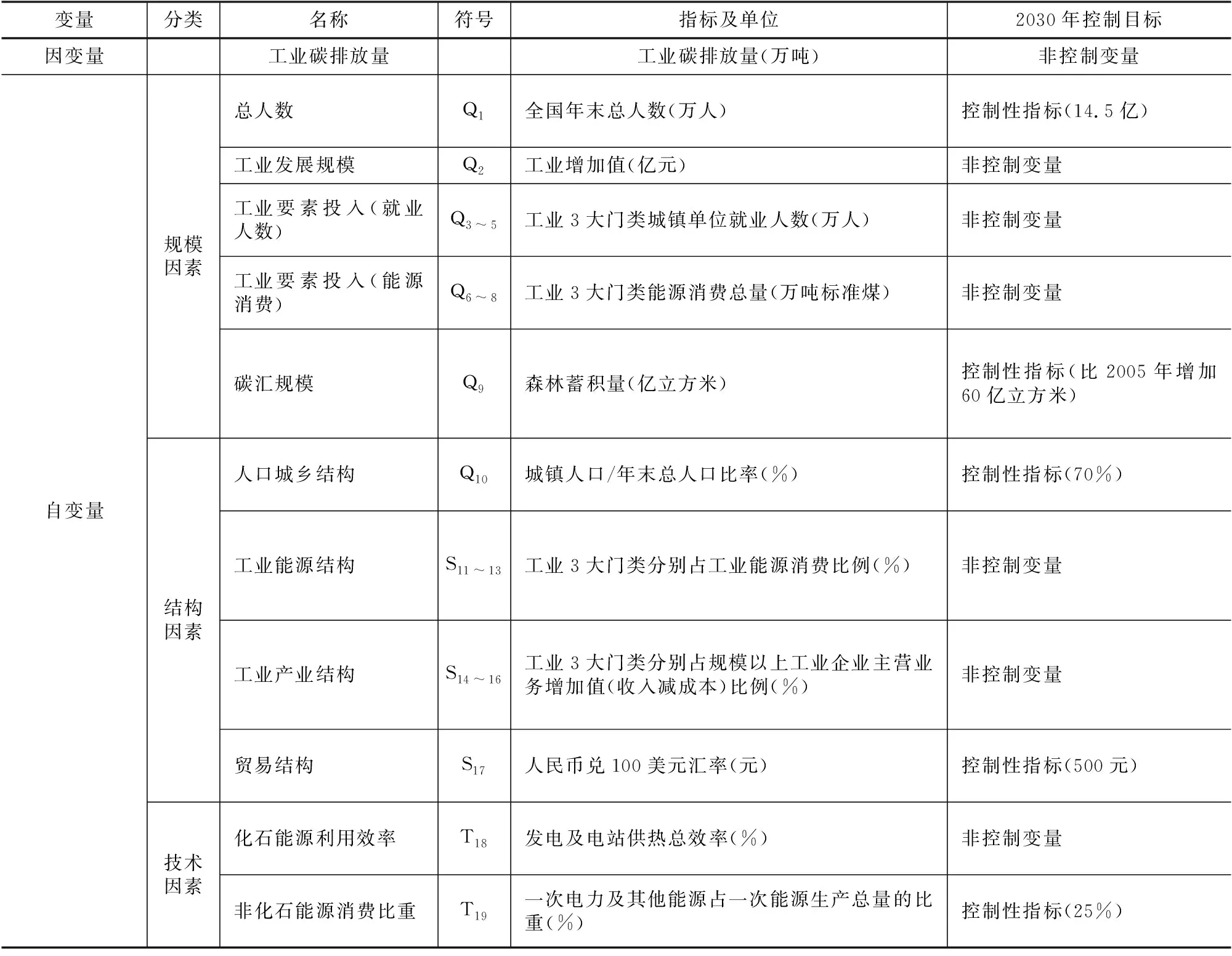
表1 中国工业碳排放量预测模型指标表

表2 2000—2020年中国工业碳排放量 (单位:万吨)
自变量中的全国年末总人口、工业增加值、工业3大门类城镇单位就业人数、工业3大门类能源消费总量、森林蓄积量、人民币兑美元汇率、发电及电站供热总效率、一次电力及其他能源占能源总量的比重可以通过国家统计局网站、能源数据库和工业数据库整理得到;城镇人口比率、工业3大门类能源消费占工业比重可以通过简单的计算得出;相对难的是产业结构变量,由于2003年、2012年和2017年中国工业统计方式有所调整,工业分行业的增加值(3)工业增加值指工业企业在报告期内以货币表现的工业生产活动的最终成果。按照《中国统计年鉴》或《中国工业交通能源50年统计资料汇编》的解释,工业增加值有两种计算方法:一是生产法,计算公式为工业增加值=工业总产值-工业中间投入+应缴增值税;二是收入法,计算公式为工业增加值=固定资产折旧+劳动者报酬+生产税净额+营业盈余。目前,工业统计主要采用生产法计算工业增加值。数据难以获得,本文采用工业分行业规模以上企业主营业务收入减去主营业务成本进行代替,因此,工业结构因素中的产业结构变量用各年工业3大门类主营业务增加值的比例作为自变量。
四、中国工业碳排放达峰的预测及其控制
本文构建BP-LSTM神经网络模型作为计量分析的核心模型,先用BP神经网络训练出符合精度要求的预测模型,然后代入用LSTM神经网络预测的非控制性变量和用2030目标值逆推估算出的控制变量,用于中国工业碳排放达峰的预测及分析。
(一)方法选取
神经网络模型近年来在许多领域发挥了重要作用,主要包含BP(Back Propagation)神经网络,卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)等。BP神经网络于1985年由Rumelhart等人提出的一种多层次反馈型神经网络,1990年Robert Hecht-Nielson证明了一个三层BP网络可以完成任意n维到m维的映射。[30]图4是一个三层BP神经网络模型结构图,输入层节点数为n,隐含层节点数为m,图中Wik(i=1,2,…,n;k=1,2,…,m)为输入层第i节点到隐含层第k节点的权值;Wk(k=1,2,…,m)为隐含层第k个节点到输出层的权值。BP算法主要思想是:输入学习样本,采用最速下降法,通过误差反向传播不断迭代以调整网络权值,使输出向量与期望向量尽量接近;当网络输出层误差平方和小于指定值时训练完成,保存网络的权值及偏差。[31]

图4 三层BP神经网络结构图
LSTM神经网络是长短期记忆神经网络(Long Short-Term Memory,LSTM)的简称,源于Hochreiter、Schmidhuber等人基于RNN循环神经网络所改进的模型,[32]有效地解决了长距离依赖问题。LSTM神经网络模型引入了状态单元(Cell State)与门(Gate)的概念,使得其比RNN网络具有更强的适应性。如图5所示,LSTM模型下,t时刻的信息会与t-1时刻的输出和t-1时刻的记忆单元汇合,通过遗忘门、输入门和输出门三个门控结构进行处理。遗忘门会对上一时刻的信息进行舍弃及保留处理,输入门将当前时刻的有效信息进行存放,输出门对可以作为下一时刻输入的信息进行处理。[33]

图5 LSTM神经网络原理图
(二)碳达峰BP神经网络预测模型
本文采用BP神经网络进行碳达峰预测模型的构建。BP神经网络模型采用3层网络结构,输入层节点数19个,隐藏层节点数8个,输出层节点数1个。训练函数采用TRAIN_RPROP,误差函数用ERRORFUNC_LINEAR,终止函数用STOPFUNC_MSE,隐含层激励函数用SIGMOID_SYMMETRIC,输出层激励函数用SIGMOID_SYMMETRIC。经过1684次迭代训练,均方误差(MSE)为61802.29,均方根误差(RMSE)为248.60,平均绝对误差(MAE)为168.75,平均绝对百分比误差(MAPE)为0.03%,预测模型通过有效性检验,达到精度要求。从表3可见,本模型预测值与原值误差除了2000年为0.22%,其余绝对值均在0.13%以下,精度能够满足预测要求。

表3 2000—2020年中国工业碳排放量BP模型预测及原值对比表
(三)变量LSTM预测及估算
在工业碳排放量预测模型指标表(表1)中,最右边一列标注出了控制性指标及非控制性指标。对于控制性指标,其含义是指可以通过一定的宏观政策引导、环境规制等政策性方式,对相应指标进行管控,以便能顺利实现碳达峰目标。对于非控制性指标,则更多受到过去数据和市场的影响,将会按照一定的惯性向前发展,因此宜采用适当的模型进行预测。对时间序列变量进行预测的模型有很多,根据时间序列预测模型的优缺点,以及本文非控制变量数据资料的特征,结合已有的研究文献,LSTM长短期记忆神经网络因有更好的预测精度而用于本文对非控制性自变量的预测。
1.非控制变量预测
本文基于2000—2020年时间序列数据,通过构建LSTM预测模型对影响工业碳排放量的非控制性变量进行设定,并对未来10年的数值分别预测。2021—2030年各个非控制变量预测结果简述如下:(1)规模以上企业工业增加值在未来10年,保持缓慢下降趋势,从2021年的31.32万亿下降到2030年的31.06万亿。(2)城镇单位就业人数中,采矿业和电力业人数保持单调下降,制造业人数先从2757万人逐步下降到2025年的最低值1640万人,随着中国加强重视制造业、以及产业升级等因素,预计制造业就业人数会有一个回弹趋势,到2030年达到2105万人。(3)能源消费方面,采矿业基本保持不变;制造业能源消费保持持续上升的趋势,从2021年的28亿吨标准煤到2030年的30.33亿吨标准煤,上涨8.30%;电力业的能源同样保持上涨趋势,上涨的幅度为4.30%。(4)工业能源结构方面,分行业能源消费占工业总消费的比重上,采矿业占比基本保持不变;制造业的能源消费占比持续上升,从84.97%上升到2030年86.02%,占比上涨1.05%;电力业的能源消费占比上涨较为轻微,为0.32%。(5)工业产业结构中,采矿业规模以上企业主营业务增加值的占比比例从2.97%上升到2030年3.03%,仅仅增加0.6%;制造业规模以上企业主营业务增加值占比从89.57%轻微上涨到89.97%,上涨0.4%;电力业上涨为0.09%。(6)发电及供热总效率从47.00%上升到48.97%。通过LSTM模型预测的各变量数据及趋势(见表4),符合相关文献对未来的预期。(7)横向对比工业3大门类能源消费和主营业务增加值的占比发现,采矿业能源消费占比基本保持约6%,主营业务增加值保持在约3.00%;制造业能消费占比和主营业务增加值占比相差不大;电力业的能源消费约11%,主营业务增加值的占比约为5%;可见采矿业与电力业的单位GDP能耗有较大改进空间。

表4 2021—2030年非控制变量LSTM模型预测结果表
2.控制变量估算
中国工业碳排放达峰的控制性变量如表1所示,具体指标解释如下。一个国家碳排放达到峰值常常意味着城市化和工业化的成熟;已达峰国家如日本(91%)、巴西(85.5%)的城市化率一般都超过了70%。[34]国家人口发展规划(2016-2030年)预计中国2030年总人数在14.5亿左右。[35]2020年12月12日,习近平主席在气候雄心峰会上提出,到2030年,中国碳排放强度比2005年下降65%以上,非化石能源占一次能源消费比重将达到25%左右,森林蓄积量将比2005年增加60亿立方米。[36]自2005年中国实行“浮动汇率制度”以来,人民币兑换美元的汇率从“8”开始,进入“6”时代迄今已13年;人民币进入“5”时代是迟早之事。[37]汇率变动对贸易结构乃至工业结构将会产生重大影响。
控制变量的估算分为两步。第一步,2030年各控制变量达到的数值分别为:全国年末总人数14.5亿人,城镇人口比率达70%,森林蓄积量197亿立方米,人民币汇率为500元(兑100美元),非化石能源消费占25%。第二步:以2020年年度数据为起始,采用平均递增法估算出2021—2030年的逐年数据。
(四)中国工业碳排放达峰预测与控制因素对比分析
1.中国工业碳排放达峰预测
将上述非控制变量LSTM预测数据和控制变量逐年递推估算数据,带入建好的BP神经网络可以得出未来10年中国工业二氧化碳排放量如图6所示。

图6 2021~2030年中国工业碳排放量趋势图
未来10年,工业二氧化碳排放量呈“W型”波动,从2021年的102.52亿吨,逐年下降到2023年达到一个相对最低值102.29亿吨,随后逐步上升到2026年达到最大值103.18亿吨;随后轻微下降到2028年为102.99亿吨的波谷,后又微弱上升到2030年的103.11亿吨。由此可见,在控制变量均匀达成的条件下,非控制变量按照内在规律发展的推动下,工业碳排放峰值将于2026年达到,但在接下来4年存在一定波动,整体保持在相对高位水平。
2.控制因素影响对比分析
将2两类预测数据进行对比分析可得出不同控制因素作用的差异。第一类数据是5个控制变量均按照2030年目标逆推得出的数据带入模型,得到全部控制因素变动下的逐年预测值;另一类数据是分别将单个控制变量保持不变,其余4个变量按照前述数据得出的预测值。用两组数据的差值表示该控制变量对工业碳排放量的影响情况,分为绝对值差异和相对差异。从展示绝对数值的表5及相对差异比例的图7可见,5个控制变量对工业碳排放量的影响是不同的。首先,从方向上来看,年末总人数、城镇化率、森林蓄积量三者与工业碳排放量是同向增长的;人民币兑美元升值(汇率时间序列数据降低)、非化石能源占比提高,跟工业碳排放量的增加方向是相反的。其次,从大小来看,非化石能源占比的增加,对工业碳排放量的抑制作用最明显,有0.45%—1.23%的作用;其次是人民币兑美元的汇率变动,即人民币升值,对未来10年工业碳排放量有0.33%—0.81%的抑制作用;人口数量、城镇化率和森林蓄积量对工业碳排放量的影响效果,整体偏小,在0.13%以内。再次,具体原因分析。非化石能源占比的提升和人民币升值,对于工业碳排放达峰有着最为明显的影响。究其原因,非化石能源占比的提高,意味着零碳排放能源占比增加,从能源结构上做出重大调整,因此对工业碳排放达峰带来深刻而明显的影响,与已有研究方向较为一致。另外一个影响因素是人民币汇率,随着中国国力的不断增强,人民币资产不断升值和人民币国际化的需求,使得人民币升值的趋势愈发明显;升值不仅影响中国工业出口结构进而影响工业产业结构,还能显而易见地影响到以美元计价的碳排放强度及其他指标,对碳排放强度等指标值能产生近似同等比例的效果。例如,碳排放强度=碳排放量/GDP,假设人民币从600元人民币兑100美元,升值到500元人民币兑100美元,会使得以美元计价的GDP上升约20%;当中国碳排放总量不变的条件下,单位美元GDP的碳排放强度会相应下降约20%。

表5 2021—2030年控制变量对中国工业碳排放量影响对比表 (单位:亿吨)
五、结论与政策含义
(一)主要结论
针对中国工业碳排放达峰问题,本文采用STIRPAT模型将影响因素分为规模、结构和技术三类,选取了19个相关自变量,进一步归类为控制性变量和非控制性变量,通过BP-LSTM神经网络模型计算,得到如下研究结论:(1)中国工业碳排放量将在2026年达到峰值103.18亿吨,且在随后4年以“W型”轻微波动。(2)在2021—2030年期间,LSTM预测的非控制因素显示规模以上企业工业增加值呈轻微下降趋势;制造业人数先下降后回弹,能源消费量持续上升,增幅为8.30%,其主营业务增加值占比从89.57%轻微上涨到89.97%;发电及供热总效率预计从47.00%上升到48.97%;制造业能消费占比和主营业务增加值占比相差不大,采矿业与电力业的单位GDP能耗仍有较明显的改进空间。(3)控制性因素的对比分析显示,非化石能源占比的提升和人民币升值,对于工业碳排放达峰和碳减排有着最为明显的影响;人口数量、城镇化率和森林蓄积量对工业碳排放量的影响效果整体偏小。
(二)对策建议
根据中国工业碳排放达峰控制变量的对比分析结果及碳达峰情况,下面从影响较大的2个控制变量及宏观动态的角度提出如下对策建议。第一,重点推动能源结构优化及区域能源分配。本文实证结果显示,非化石能源占比的增加,即工业能源结构中扩大低碳、无碳能源的占比将对工业碳排放达峰有最明显的影响。国家应该促进传统化石能源向清洁能源的快速转变,着力解决时空分布不平衡问题,保证输出的稳定。在风、光、水资源丰富地区,加大能源基地建设,以此向工业发达地区输送能源;同时加强储能技术和智能电网调控技术的发展,协调推进供需两端的同步发展。第二,通过汇率政策推动工业产业结构优化。未来工业碳排放达峰过程中,国家汇率管控应与产业升级联动,做到相互促进。我国提出构建以国内大循环为主体,国内国际双循环相互促进的新发展格局。要求保持汇率缓慢升值,保持工业各行业的基本稳定,积极推动高新技术产业发展。中国是世界上工业增加值最大的国家,工业品出口历来占比较大;人民币升值会给中低端制造业出口带来严重打击,解决之道只能是不断提高产品附加值,提升产业结构中高科技的比重;积极应对、主动出击,持续推动工业产业升级。第三,动态优化、逐步落实工业达峰控制策略。中国对世界承诺2030年前实现碳达峰,工业是重要组成部分,需要确保在2030年前实现。国家宏观政策中,应重视对关键控制变量的政策引导和监督,制定政策时应动态调整并优化,分年、分行业逐步落实工业碳排放达峰控制策略,确保2030年底前实现碳达峰并适度缩短平台期。
猜你喜欢
区域治理(2022年40期)2022-11-27
新疆钢铁(2021年1期)2021-10-14
中华环境(2021年9期)2021-10-14
建材发展导向(2021年14期)2021-08-23
煤气与热力(2021年6期)2021-07-28
中国经济周刊(2021年10期)2021-06-06
中国人口·资源与环境(2020年10期)2020-12-23
高师理科学刊(2020年2期)2020-11-26
人物画报(2019年4期)2019-10-26
中国医药指南(2019年25期)2019-10-22
