
融合中文字形和字义的字向量表示方法
2021-11-23 14:47唐善成张镤月王瀚博
科学技术与工程 2021年32期
唐善成, 张 雪, 张镤月, 王瀚博, 陈 明
(西安科技大学通信与信息工程学院, 西安 710054)
字词向量表示是自然语言处理[1]的基础,在表音文字领域,如英文,需用词向量表示文本;在表义文字领域,如中文,由于每个字具有特定语义(与英文中的字母不同)[2-3],可以用字向量、词向量表示文本[4-6]。Mikolov等[7]提出了Word2Vec;Pennington等[8]提出了GloVe在词向量表示方面取得了较大的进展。Word2Vec 的原理是用一个词预测前后词,或者用前后词预测当前词,然后利用语言模型来判断输入的样本是否符合自然语言规则。GloVe结合了潜在语义分析(latent semantic analysis,LSA)和Word2Vec的思想,使用语料库的全局统计特征和局部的上下文特征。
以上方法适用于英文,而中文较英文有独特特性。汉字起源于象形文字,字形蕴含着丰富的语义信息[9-10]。中文字向量表示方法相关研究有:Su等[11]利用字形学习汉字的表现形式,验证了字形特征能够增强汉字的表示;谢海闻等[12]提出了一种基于胶囊神经网络的汉字字形表征模型,将汉字拆分为部件并进行识别并生成表征向量,选出部分部件组成向量用于字形的表征;Meng等[13]将汉字作为图像,利用Tianzige-卷积神经网络(convolutional neural networks,CNN) 模型提取汉字语义,性能得到提升;蔡子龙等[14]提出了汉字字形融合方法,用部分替代法和辅助学习法从字形位图中提取汉字的字形特征;Wang等[15]提取汉字局部结构特征,整合词根挖掘的隐式信息,增强了嵌入语义。
以上方法借鉴了英文词向量表示方法,所需训练数据集较庞大,字向量质量稳定性差[16],没有考虑汉字整体字形结构所蕴含的语义信息,没有利用字典包含的稳定字义信息。为了克服现有方法的不足,首先利用中文字形自编码器生成字形向量,然后融入汉字字义得到字义向量,提出融合中文字形和字义的字向量表示方法GnM2Vec(glyph and meaning to vector),有效解决了传统字向量表示方法存在的问题。
1 融合中文字形和字义的字向量表示 方法
1.1 字向量表示方法研究路线
研究路线如图1所示。字向量表示方法的输入是繁体字字形图像,经字形自编码器的编码器部分处理得到的字形向量来初步表示相应汉字;然后,基于字形向量表示每条字义中的每个汉字得到基于字形向量的字义向量,通过字义自编码器的编码器部分处理得到融合字形和字义的字向量表示。

图1 字向量方法研究路线Fig.1 Research route of character vector method
基于卷积自编码器构建字形自编码器和字义自编码器。卷积自编码器由两部分组成:编码器和解码器,以字形自编码器为例阐述其工作原理。输入为(96,96,1)维的字形图像,编码器的编码过程为
z(l)=Cov[a(l-1),w(l),b(l)]
(1)
h(l)=ReLu[z(l)]
(2)
a(l)=MaxPooling[h(l)]
(3)
式中:w(l)和b(l)分别为编码器的第l层权重和偏置项;Cov(·)为卷积操作;z(l)为第l层编码后的结果;h(l)为z(l)经过ReLU激活函数计算后的结果;MaxPooling表示进行池化操作,且保留最大值;a(l)为经过h(l)池化后的结果,也是l层最后的输出。
假设编码器有p层,字形自编码器解码器的解码过程为
z(p+l)=DCov[a(p+l-1)]
(4)
h(p+l)=ReLu[z(p+l)]
(5)
a(p+l)=UpSampling[h(p+l)]
(6)
式中:DCov(·)为反卷积操作;z(p+l)为第p+l层解码后的结果;h(p+l)为z(p+l)经过ReLU激活函数计算后的结果;UpSampling表示进行上采样操作;(p+l)为h(p+l)经过上采样后的结果;激活函数ReLU表达式为

(7)
经过n(字形自编码器中,令n=3)次卷积反卷积操作以后,经Sigmoid函数计算的结果即为解码器输出,此时输出为(96,96,1)维重构后的字形图像。激活函数Sigmoid公式为
(8)
1.2 字形自编码器
1.2.1 字形自编码器模型工作过程
字形自编码器模型工作过程包含训练阶段和字形向量生成阶段,如图2所示。在训练阶段,首先将每张汉字字形图像经过缩放、灰度化、归一化处理为96×96的灰度图,然后字形自编码器模型基于已处理好的图像进行训练。在字形向量生成阶段,基于已训练的字形自编码器的编码器部分将字形图像映射到潜在空间表示,最终得到每个字512维的字形向量。

图2 字形自编码器工作过程Fig.2 Glyphautoencoder working process
1.2.2 字形自编码器模型网络结构
卷积层、池化层和下采样层的padding设置为“same”;优化器为“Adam”;学习率为0.001,损失函数为“binary_crossentropy”。具体网络结构如表1所示。

表1 字形自编码器模型网络结构Table 1 Glyph autoencoder Network Structure
1.2.3 字形自编码器所生成向量的近邻字计算
为验证初步取得的字形向量的效果,随机抽取了10个汉字,分析字形向量间的余弦距离得出与目标汉字相似度最高的10个汉字;汉字近邻字计算结果如表2所示,基于字形的字向量表示可以很好地将字形相似的汉字聚在一起,在一定情况下,可以捕捉到字义相似的字,如“讲”与其近邻字“读”“诵”“议”。

表2 汉字近邻字计算结果Table 2 Calculation results of nearest neighbor characters of Chinese
1.3 字义自编码器
1.3.1 字义数据分析处理
每个汉字字义条数、每条字义字数不完全相同,分别对汉字字义条数、字义字数进行了统计,如表3、表4所示。由统计结果可知,字义条数在16条之内的汉字共有3 574字,约占全部汉字个数的99.6%,字义字数在16字之内的字义共有11 802条,约占全部字义条数的91.7%。为了平衡计算量和字义覆盖度,每个汉字至多取16条字义,每条字义至多取16个字。

表3 字义条数统计结果Table 3 Statistical results of the number of characters semantics

表4 字义字数统计结Table 4 Statistical results of character semantics
1.3.2 字义自编码器工作过程
字义自编码器工作过程与字形自编码器类似。在训练阶段,加入汉字字义,并用字形向量表示字义中的每个汉字,经字义自编码器训练,得到字义自编码器模型。在字义向量生成阶段,载入已训练的字义自编码器的编码器模型,经模型计算得到融合字形和字义的字向量。融合字形和字义的字向量生成过程如下。
(1)将常用字的每条字义表示为(16,512)维原始字义矩阵。字义中的每个字用已训练的512维字形向量表示,字义长度不足16字的用0补全,超过16字的只截取前16字。
(2)用字义自编码器将每个(16,512)维字义矩阵映射为512维压缩字义向量。
(3)选取常用字的16条字义,每条字义映射为512维字义向量,字义个数不足16的用0补全,超过16条的只截取前16条,表示为(16,512)维压缩字义矩阵。
(4)用字义自编码器将(16,512)维压缩字义矩阵映射为512维字向量,生成蕴含字形与字义信息的字向量。
如“讲”的融合字形字义的字向量生成过程如图3所示。

图3 融合字形与字义的字向量Fig.3 Character vector fusing glyph and character semantics
2 实验与分析
2.1 实验数据集
字向量训练数据集主要分为:中文维基百科公开数据、3 587个汉字的繁体字图像、3 587个汉字所对应的12 867条基本字义;汉字繁体字字形来源于汉文学网在线新华字典站;汉字基本解释来源于新华字典电子版数据库。
实验中训练Word2Vec、GloVe的数据集来源于中文维基百科公开的1.75 G数据集,经处理最终得到1 G数据集[17],汉字字数约有2.1×108。窗口大小为5,字频最小值为1,字向量维度为512维,其中Word2Vec字向量使用CBOW模型训练得到。最近邻字计算字频来源于国家文字工作委员会在线现代汉语2×107字语料库的字频数据。命名实体识别任务实验采用微软亚洲研究院(MRAS)所发布的命名实体识别语料,包含训练集约222×104字、测试集约17×104字。中文分词实验中采用NLPCC-2016所公布的中文分词数据集,包含训练集约7×105字、测试集约7×105字。短文本语义相似度计算实验数据为ChineseSTS数据集,分为训练集27 490条以及测试集5 105条,每一条数据包含两个句子及其相似度,相似度由低到高分为5个等级。
2.2 最近邻字计算
实验选取国家语委在线现代汉语语料库中3个高频字和3个低频字,分别通过Word2Vec、GloVe和GnM2Vec方法计算这些字的最近邻字,结果如表5所示。由此,可以得到如下结论。
(1)Word2Vec、GloVe依赖于训练数据集,稳定性差。在以下6个字的近邻字计算结果中,Word2Vec、GloVe虽然可以找到与“一”“人”“贰”的近义字,但若扩大近邻字范围,其近义程度有所降低;并且Word2Vec、GloVe几乎不能找到与“上”“橄”“蹋”字具有相似意义的字,低频字向量表示质量较差。而GnM2Vec则得益于加入中文字形和字义,即使扩大近邻字范围,也可以在较少的数据集中找到与目标字具有相似字义的字,稳定性更好。
(2)Word2Vec、GloVe更注重于上下文语义关联性,捕获中文近义字效果较差。以“人”字为例,Word2Vec、GloVe更多捕获的是与“人”出现在相同上下文环境的字,例如出现“妇”“族”等字。所提方法由于融合了汉字字义信息,得到“人”的近邻字更加具有字义相似性,即近邻字和目标字是同义字。GnM2Vec能够更好地表达字义相似性。

表5 近邻字计算实验结果Table 5 Experimental results of nearest neighbor character calculation
2.3 命名实体识别
采用Huang等[18]提出的双向长短期记忆网络-条件随机场(bi-directional long short term memory-conditional random field,BiLSTM-CRF)模型作为测评模型来对比不同字向量表示方法生成的字向量在命名实体识别中的效果,为了测试字典语义对字向量质量的贡献度,做了消融实验,即基于字形字向量(glyph to vector,G2Vec)完成命名实体识别实验。评测指标是按照命名实体边界来计算测试集的准确率、召回率、F1值。
对比Word2Vec、GloVe、G2Vec 、GnM2Vec生成的字向量在命名实体识别中的效果,结果如表6所示。通过分析,本文方法GnM2Vec生成的字向量在命名实体识别实验中较Word2Vec在测试集上准确率、F1值分别提高了2.44、2.25;较GloVe分别提高了0.38、0.05;较G2Vec分别提高了0.47、0.3。
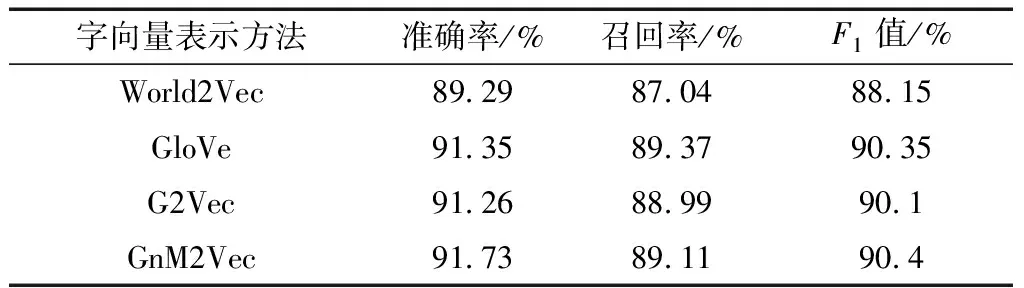
表6 命名实体识别任务中的实验结果Table 6 Experimental results in named entity recognition task
2.4 中文分词
中文分词实验使用Huang等[18]提出的BiLSTM-CRF模型作为测评模型来对比不同字向量表示方法所产生字向量在中文分词任务中的效果,并做了消融实验,评测指标为分词边界的准确率、召回率和F1值。
对比了Word2Vec、GloVe、G2Vec 、GnM2Vec、产生的字向量在中文分词中的效果,具体结果如表7所示。分析可知,GnM2Vec较Word2Vec在测试集上准确率、F1值分别提高了0.52、0.3,较GloVe分别提高了0.18、0.14;较G2Vec分别提高了0.71、0.33。
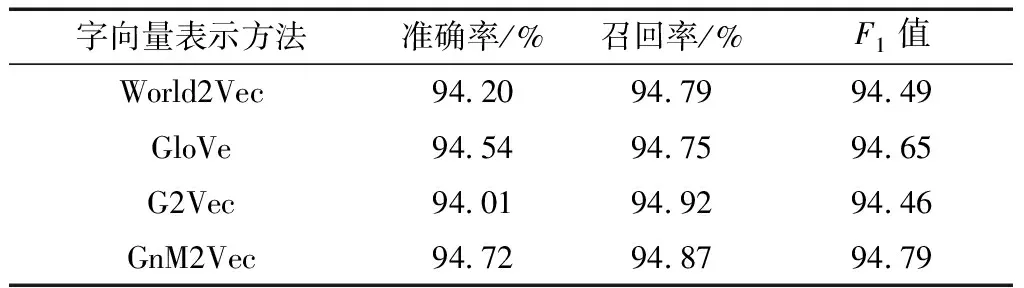
表7 中文分词任务中实验结果Table 7 Experimental results in Chinese word segmentation task
2.5 短文本语义相似度计算
对比了Word2Vec、GloVe、GnM2Vec、等字向量在CNN[19]、长短期记忆网络(long short-term memory,LSTM)[20]、Self-Attention[21]不同模型中短文本语义相似度的效果。评测指标为F1值。
表8为不同模型和向量在测试集上的F1值,可以看出,在CNN、Self-Attention和LSTM模型中,GnM2Vec较word2vec的F1值分别提高3.57、3.62、2.53;较GloVe的F1值分别提高了1.85、3.62、0.5。对F1值求均值,较Word2vec、GloVe分别提高了3.24、1.99。
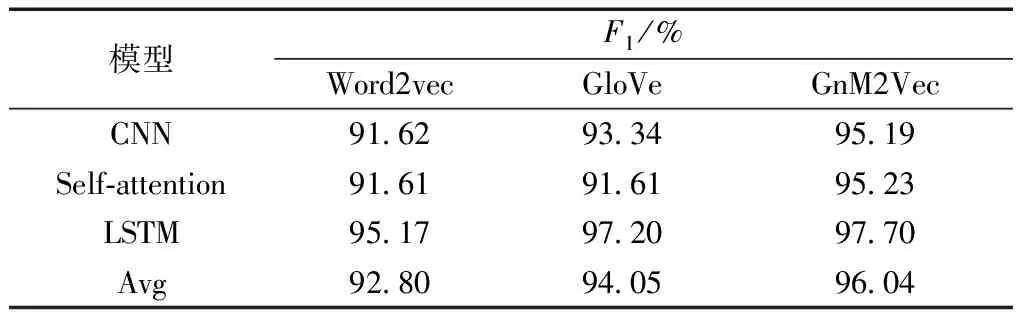
表8 短文本语义相似度计算实验结果Table 8 Experimental results of short-text similarity calculation
3 结论
提出了一种融合中文字形和字义的字向量表示方法。该方法通过字形自编码器自动提取汉字字形特征得到字形向量表示,采用字义自编码器进一步进行语义映射,生成融合字形和字义的字向量,得出以下结论。
(1)所提方法依赖稳定的字形字义数据集,有效解决了传统字向量表示方法存在的过度依赖大数据集的问题。
(2)从汉字整体结构角度出发利用字形结构所蕴含的语义信息和字典所包含的专业知识生成字向量。近邻字计算实验结果表明,所提方法表示质量更稳定。
(3)通过中文命名实体识别、中文分词和短文本语义相似度计算实验对所提的字向量表示方法进行了测评,结果显示所提方法整体上好于现有方法。
目前,字义自编码器在训练阶段无法提取所有字义信息,有效信息损失较大,在未来研究中将尝试注意力等模型降低字义信息损失,进一步提升字向量质量。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
锻压装备与制造技术(2021年5期)2021-11-13
汉字汉语研究(2021年2期)2021-08-30
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
汉字汉语研究(2019年4期)2019-03-04
家教世界·创新阅读(2018年7期)2018-11-20
小学生学习指导(低年级)(2018年5期)2018-04-24
小学生学习指导(低年级)(2018年5期)2018-04-24
小学阅读指南·低年级版(2016年5期)2016-05-14
