
融入学习者模型在线学习资源协同过滤推荐方法
2021-11-27 00:48刘芳田枫李欣林琳
智能系统学报 2021年6期
刘芳,田枫,李欣,林琳
(1.东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318;2.讷河市第一中学,黑龙江 讷河 161300)
近年来,随着互联网技术高速发展,在线教育平台的使用越来越被学习者所接受,尤其新型冠状病毒爆发之后,线上学习是在不能正常进行线下学习的情况下优选的学习模式。数据表明,截至2020 年12 月,我国在线教育用户规模达3.42亿,占网民整体的34.6%。该项数据在2020 年3 月时达到高峰,为4.23 亿,占比数据为46.8%[1]。面对巨大的在线学习需求,在线教育机构提供免费在线课程,共享在线教学资源,在线教育行业呈现爆发式增长趋势。然而随着在线学习平台的广泛使用,在线学习资源的数量也急剧增长,在数量庞大的在线学习资源中,学习者很难快速定位自己需要的资源,导致“信息迷航”。
信息推荐是解决用户从海量对象中迅速有效地筛选出符合自己偏好特征的对象的方法[2]。目前,信息推荐技术被广泛应用于诸多领域。将信息推荐技术应用到在线教育,实现在线教育过程中学习资源的个性化推荐是解决“信息迷航”问题的一个有效途径。协同过滤算法是目前信息推荐技术的主流算法,该算法的相关研究工作大多集中在相似度计算和用户对资源评分的优化上[3]。在相似度计算方面,Wang 等[4]提出了基于Kullback-Leibler 散度的项目相似度计算方法来改进相似度计算,提高推荐准确率;Jiang 等[5]提出了基于Quasi-norm 的用户相似度计算方法,来提高推荐精度;Mu 等[6]提出了一种改进的Pearson 相关系数的方法改进相似度计算从而改善推荐结果。他们都是通过提高用户相似性的度量来提高信息推荐的质量。但是协同过滤在应用到学习资源个性化推荐方面,仅靠提高相似度很难提高推荐质量,将学习者这一学习资源推荐的主体与信息资源推荐的用户相对比,学习者的学习风格、偏好、背景、认知水平等个性化特征更为复杂,学习者的复杂特征对在线学习资源推荐质量影响较大,国内外诸多研究人员对学习者展开研究。Wang等[7]设计了自适应的推荐模型,该模型研究了学习者的兴趣偏好特征,并以学习者和学习资源的相关性为依据,挖掘基于本体的学习资源的语义关系;Segal 等[8]将社会选择特征融入传统的协同过滤算法,提出了Edu Rank 算法,该算法可适应个性化教学;Zhang 等[9]提出基于本体的语义关系模型,并将协同过滤算法与改模型融合;Aleksandra 等[10]提出采用聚类方法的学习者学习风格模型,并改进矩阵分解方法进行推荐。
学习者是在线学习的参与者,学习资源推荐的个性化程度,直接决定着学习者的学习效果,因此在推荐时不仅要考虑相似度的计算方法的改进,更要研究学习者的个性化特征。个性化的学习者模型的构建是学者们研究的重点[11-13],但大多研究都较集中在学习者行为数据分析、学习资源特征分析、语义特征分析等单一方面,缺乏对学习者整体特征的综合分析和学习者多维度特征的个性化研究。本文以在线学习平台中的学习者真实数据为依托,以学习者为中心,提出融合学习者多维度模型的在线学习资源协同过滤推荐方法,优化在线教学学习效果,进一步提高在线教育的个性化程度。
1 多维度学习者模型构建
学习者是在线学习的主体,具有静态和动态的个性化特征,学习者模型用于描述学习者特征,该模型的构建是提高在线学习资源推荐性能,优化推荐精度,实现个性化推荐的核心。在构建学习者模型时首选要确定学习者的个性化特征,本文依据CELTS-11 学习者信息模型规范[14],以学习风格理论[15]和教育目标分类理论[16]为指导,将学习者特征分为静态特征和动态特征两个部分,其中,静态特征包括学习者基本信息、学习风格和静态兴趣偏好,动态特征包括认知水平和动态兴趣偏好。静态特征是学习者的初始特征,在整个学习过程中不能随着学习深入而发生变化,不能表示学习者的个性化特征程度,但作为基本特征可以解决初始用户在推荐过程中存在的冷启动问题。动态特征是指随着学习行为的发生,学习者的一些隐含特征逐渐显现,如学习认知状态和对某些资源的学习评价等都会随着时间发生变化,因此动态特征是构建学习者模型的重点。学习者的静态和动态数据通过采集层进行数据采集,在数据层完成信息归类,数据分析层将归类好的信息进行进一步数据挖掘,为表示层的学习风格、认知水平、静态和动态兴趣偏好特征提供数据基础。学习者模型构建过程如图1所示。

图1 学习者模型构建过程Fig.1 Building process of learner model
1.1 数据采集
学习者的初始静态数据和动态行为数据是构建学习者模型的数据基础。通过学习者注册时所填写的问卷、量表等获取学习者模型的基本信息、学习风格以及静态的兴趣偏好等特征信息;通过调取学习平台的章节知识点测评数据和各类学习者行为数据获取学习者的认知水平和动态兴趣偏好特征。通过数据采集层实现基础数据的获取与收集,为下一步的归类分析挖掘以及特征表示做基础。
1.2 学习风格的特征表示
学习风格的概念是1954 年由美国赛伦首次提出的,它是反应学习者生理、心理等需要的概念,学习风格的研究为学习者模型的个性化要求提供了依据[17]。以Felder-Silverman 风格模型为基础,以所罗门学习风格量表(index of learning style questionnaire,ILSQ)[18]为手段,将学习者的学习风格从感知、输入、处理和理解4 个维度进行量化,在数据采集层每一个学习者都要填写学习风格调查量表,将获取的ILSQ 量表结果送入数据层和分析层,在表示层构建学习风格特征。
学习风格特征量化的具体流程如下:
1)以四元组

2)学习者填写ILSQ 量表时,共44 道题,每题包含两个选项A 和B,答题结果的值定义为Pj,其中j表示题号;
3)根据Pj的结果筛选处理,分类累加,最后的累加结果用a和b表示;
4)对a和b值的大小进行判断,如果a>b,则Vi=(a−b)a;如果a 5)学习风格特征的测试结果四元组LS则为学习者的学习风格特征量化结果。 学习者的兴趣偏好特征分为静态兴趣偏好特征和动态兴趣偏好特征。将数据集中的学习资源通过部分人工标注,再将剩余的资源通过相似度计算、最近邻排序等方法,实现自动标注,最后通过人工查询相关反馈机制进行校核,保证学习资源特征表示的准确性。以学习资源特征构成的规范化标签集合为选项,构建静态兴趣偏好问卷,在数据采集层每一个学习者都要填写静态兴趣偏好问卷,将获取的结果送入数据层和分析层,在表示层构建静态兴趣偏好特征。 学习者的学习过程是一个动态变化的过程,学习过程中各种操作都会产生相应的行为信息,该信息反映了当前学习者的兴趣偏好,本文将随着时间变化产生的兴趣偏好称为动态兴趣偏好[19],具体的量化过程如下: 1)学习者行为分类及权重计算 学习者行为主要分为5 类,即浏览行为、收藏行为、分享行为、下载行为以及评价行为,不同的行为所代表的学习者的隐含偏好程度是不同的[20],这里引入权重来表示不同的学习行为的贡献程度。权重的确定方法有很多种,专家评测或者经验主义权重具有一定的主观性,本文采用熵权法确定权重[21]学习者行为分类、权重分布及本文最后采用的权重数值,如表1 所示,其中wi表示第i个行为所占的权重分配。 表1 学习者行为分类及权重分布Table 1 Learner behavior classification and weight distribution 2)学习者−学习资源评分矩阵构建 依据学习行为及其所占的权重分配构建学习者−资源评分矩阵Pm×n,该矩阵可作为学习者对学习资源的评价依据,Pm×n为 Pm×n矩阵中的每个值都表示学习者um对资源in的行为权重,如果su i=0,那么说明学习者uj并未对ik产生任何行为,如果矩阵元素全为0,则说明学习者uj并没有开始学习。 3)学习资源−学习标签矩阵构建 为了建立学习者与学习资源标签的直接关联关系,首先构建学习资源标签矩阵来表征学习资源的特征: Qn×l矩阵中的元素rjk表示资源ij是否拥有标签tk,rjk=1 表示标签tk标注了资源ij;rjk=0 表示未被标注,因此矩阵Qn×l是一个由0 和1 构成的矩阵。 依据学习者−学习资源评分矩阵Pm×n和学习者−学习资源标签矩阵Qn×l构建学习者−标签矩阵Tm×l: 4)学习者动态兴趣偏好行为特征表示 学习者的不同行为操作在学习资源上累积可以用动态兴趣偏好矩阵Tm×l来表示,学习者对资源的偏好程度体现着学习者之间的差异,这一差异在表征学习者的行为特征属性时是一个渐增函数,其计算公式为 式中:guk(1 ≤k≤l)是学习者兴趣偏好在学习资源上的累加值,是学习者u在关联资源的标签tk上不断累加的行为之和;v是学习者平均兴趣偏好值;λ是学习者行为累加和的最小值,用来消除不同学习者间兴趣偏好偏差。 5)时间因素调整动态兴趣偏好特征的偏移 学习者的兴趣偏好特征会随着学习的深入产生偏移,动态兴趣偏好特征的调整包括各类行为的特征表示和时间因素,行为特征采用上述的渐增函数,而时间因素表征了学习者基于时间参数的特征,采用时间衰减函数来进行计算[22]。学习者的动态兴趣偏好特征时间因素的计算公式为 式中:tnow为当前时间;表示学习者u被标签tk标注的时间集合里的最近值;超参数θ∈[0,1]可以影响时间因素对动态兴趣特征的计算,二者表现为负相关。 将行为特征和时间权重特征进行综合,得到学习者的动态兴趣偏好特征,即 学习者的认知水平特征描述的是学习者在学习某个知识点之后,对该知识点对应的试题进行测试,获取的对该知识点的掌握程度。 以“布鲁姆教育目标分类理论”为依据,知识点对应的学习资源的学习目标被分为6 个等级(如图2),这6 个等级代表着不同学习者对核心知识点掌握程度,即认知水平。在学习过程中,采集层的章节知识测试数据代表了绩效信息,通过分析章节知识点和试题测试成绩,获取认识水平特征,由于该项指标分为6 个等级,不同的学习者会有不同的整体认知水平,同一个学习者不同时期对于不同的知识点也会有不同的水平状态,因此认知水平体现着学习者的个性化特征。学习者的认知水平特征表达式为 图2 学习资源知识点掌握程度的表示方法Fig.2 Representation method of learning resources knowledge points master degree 式中:ki表示第i个知识点;li表示对第i个知识点的掌握程度,即认知水平,n是学已学过的知识点数量。 协同过滤是信息推荐技术中经典的推荐方法[23-26],本文采用协同过滤作为在线学习资源推荐的基本算法,实现基本的推荐,在基本推荐的基础上融合学习者模型的多维度特征,进行精准推荐。 经典协同过滤技术的推荐过程分成3 个部分:1)收集学习者对学习资源的评分,构建学习者-学习资源评分矩阵;2)学习者-学习资源评分矩阵隐含着学习者对学习资源的兴趣偏好,因此可以通过相似度计算求出与被推荐的学习者具有相似兴趣偏好的学习者集合,构成K近邻学习者集合;3)计算K近邻学习者集合中每个学习者对学习资源的评分,产生被推荐学习者对学习资源的预测评分,按照评分进行排序,产生学习资源推荐集合,在该集合中筛选出没有被被推荐学习者学习过的Top-N 个资源,这Top-N 个资源就是最后的推荐结果。 冷启动问题是推荐系统的共性问题,它指的是在面对刚刚进入推荐系统的新学习者时,由于行为数据较少,因此系统无法获取初始学习者的隐含偏好信息,本文构建的学习者模型的静态特征可以较好地解决冷启动问题。在数据采集层通过问卷、量表等方式获取学习者的学习风格以及静态的兴趣偏好等特征信息,通过加权融合计算学习者静态综合特征相似度,按相似度排序构成K近邻学习者集合,根据K近邻学习者的学习资源列表完成初始学习者的推荐。 1)静态兴趣偏好特征相似度计算 学习者un的初始兴趣偏好标签个数为q,学习者um的初始兴趣偏好标签个数为p,学习者un和um之间含相同标签数目为k,相似度计算公式为 2)学习风格特征相似度计算 学习风格包括4 个维度,不同维度的分数值表示为S={s1,s2,s3,s4},将S值标准化之后,利用欧几里得距离公式计算学习风格距离,其计算公式为 um和un的学习风格相似度计算公式为 3)静态综合特征相似度计算 将学习风格特征相似度和静态兴趣偏好特征相似度加权融合形成学习者静态综合特征相似度,超参数α∈[0,1]可以影响学习风格和静态兴趣偏好的影响程度,α的具体数值通过实验统计数据的经验获得,静态综合相似度计算公式为 为丰富推荐结果的多样性,提高推荐结果的准确性,在融合静态特征推荐的基础上,引入学习资源-学习标签矩阵,结合基础协同过滤算法中用到的学习者-学习资源评分矩阵,构建学习者-学习标签矩阵,更新动态兴趣偏好特征。通过分析章节知识点和试题测试成绩,获取认识水平特征,通过计算融合动态兴趣偏好特征和认知水平特征的相似度,得到融合学习者动态特征的K近邻学习者集合,由K近邻集合得到推荐资源列表的过程与基于协同过滤的方法一致。 1)融合行为特征和时间权重特征的兴趣偏好相似度计算 以学习者对学习资源的评分来描述学习者的兴趣偏好特征是不全面不准确的,在构建学习者模型动态兴趣偏好特征时,融入各类学习行为,再对这些行为加权计算,构建融合行为加权的学习者-学习资源评分矩阵,从而构建学习者-学习标签矩阵,再融合时间因素,表示学习者动态兴趣偏好特征随着学习行为的持续和时间的深入产生的偏移问题。 融合行为特征和时间特征的兴趣偏好特征向量表示为Fu={Fut1,Fut2,···,Futj},学习者um和un之间的相似性可以通过皮尔逊相关系数进行计算,即 式中:Tmn由学习者um和un的兴趣偏好标签的交集构成的标签集合;Fm,ti和Fn,ti分别表示学习者um和un对标签ti的兴趣特征值;分别表示学习者um和un对集合中所有标签的平均兴趣值。计算学习者的兴趣特征值相似度,并按相似度的高低进行排序,构建出与目标学习者兴趣特征最为相似的近邻学习者集合U={u1,u2,···,um,···,uk},这里k为超参数,具体数值通过经验或实验验证给出。 2)融合认知水平特征的相似度计算 将学习者um在已学习过的知识点上的认知水平的集合表示为L(um)={L(um)=(k1um,h1um),(k2um,h2um),···,(kjum,hjum)}。其中,kjum表示学习者um掌握的第j个知识点;hjum表示对第j个知识点的学习者um的掌握程度,即认知水平。使用余弦相似度计算公式计算学习者的认知水平相似度,构建出与目标学习者认知水平特征最为相似的近邻学习者集合,学习者um和un的认知水平相似度计算公式为 3)学习者动态综合特征相似度计算 将2 种动态特征相似度加权,计算出学习者的动态综合特征相似度。设置参数 β调整融合比例,具体计算公式为 以超星为在线学习资源推荐研究依托平台,《C 程序设计》课程的学习资料为学习资源,东北石油大学《C 程序设计》学习者2020 年3 月到2020 年7 月时间段的学生的真实学习行为为数据开展实验,数据集中主要有3 类文件:1)学习者特征中的静态数据文件,包括学生基本信息、学习风格信息和学习兴趣信息;2)学习者特征中的动态数据文件,包括知识点测评信息,学习资源浏览、收藏、下载、评价和分享行为数据;3)带有标签信息的学习资源数据。原始数据经过数据预处理后,共计数据20547 条,学生849 人,学习资源19876 个,其中静态数据8567 条,动态数据11980 条。将数据集按照4∶1 的比例分为训练集和测试集进行模型的训练和测试。 准确率、召回率、F1是常用的用于评价推荐性能的评价标准。准确率是系统推荐给学习者的资源与学习者在测试集上感兴趣的资源的交集和系统推荐给学习者的资源的比率,即 召回率是系统推荐给学习者的资源和学习者在测试集上感兴趣的资源的交集与学习者在测试集上感兴趣的资源的比率,即 式中:R(u)表示推荐产生的学习资源;T(u)表示学习者在测试集上关注的学习资源。随着学习资源推荐个数的增多,准确率会有所下降,但是召回率有所上升。对测试集所有学习者的上述度量求均值计算平均准确率AP 和平均召回率AR,引入F1值度量整体推荐方法的性能,F1值越大,表示该推荐方法性能越好,F1值计算公式为 本文构建的学习者模型包括静态特征和动态特征,其中,静态特征包括静态兴趣偏好特征和静态学习风格特征;动态特征包括动态兴趣偏好特征和动态认知水平特征。从验证融合学习者特征算法有效性角度出发,首先基于学习者对学习资源的评分矩阵,实现了基于经典协同过滤的推荐。在此基础上融合各项动静态特征,本文的经典协同过滤算法采用文献[2]中的通过构建“用户-项目”评分矩阵计算用户相似度,匹配近邻用户进行推荐的方法。 1)融合学习者静态特征实验分析 基于协同过滤方法,融合学习者静态特征,在学习资源推荐个数为5、10、15、20、25、30、35 时的准确率、召回率和F1值比较如图3 所示。通过实验结果可知,对比于只依靠学习者对学习资源评分矩阵的经典协同过滤推荐,融合了学习者模型的单项的静态特征会提高整体推荐的性能,但是单项实验并不会得出哪个特征对推荐结果的影响更大,而且多项特征的融合效果也不会通过单项实验得到,因此多项特征的融合参数如何选择也是要解决的问题。 图3 融合学习者各项静态特征的推荐性能Fig.3 Recommended performance of integrating learners’various static characteristics 实验中涉及学习资源推荐个数k的实验参数和静态兴趣偏好特征与静态学习风格特征相融合的权重系数α。实验过程中,先定义推荐的学习资源个数为5 个,再对融合参数α取值从0.1~1 的推荐结果计算准确率和召回率的F1值,如图4 所示。当α取值为0.6 时F1值最高(见图4),因此在后续测试结果中令α=0.6,再通过实验测试对比分析融合静态兴趣偏好特征和静态学习风格特征在不同学习资源推荐个数情况下的准确率和召回率。 图4 静态特征融合参数选择比较Fig.4 Static feature fusion parameter selection comparison 2)融合学习者动态特征实验分析 学习者动态特征融合包括学习者动态变化的认知水平和学习者对学习资源持续性的学习体现出的动态兴趣偏好特征。通过多次实验对比分析准确率、召回率和F1值,将时间参数θ、动态特征融合参数β调到最优值,最终在θ=0.2,β=0.7 时,推荐结果最准确。 3)综合对比分析 综合对比分析基于协同过滤的推荐、融合学习者静态特征的推荐和融合学习者动态特征的推荐,从准确率、召回率和F1值3 个角度进行分析,实验数据如图5~7 所示。 图5 不同推荐方法的准确率比较Fig.5 Accuracy comparison of different recommended methods 图6 不同推荐方法的召回率比较Fig.6 Recall rate comparison of different recommended methods 图7 不同推荐方法F1 值比较Fig.7 F1 value comparison of different recommended methods 通过综合对比分析,得出结论:动态特征方面,融合行为特征和时间特征的动态兴趣偏好特征对最后推荐结果影响相对较大;静态特征方面,学习者的兴趣偏好特征要比学习者学习风格特征影响大。整体上,融合学习者动态特征的推荐性能优于融合学习者静态特征的推荐和基于协同过滤的推荐。 目前在线教育学习平台中存在海量学习资源,然而提供的服务个性化程度却不高,针对在线学习过程中的“信息迷航”问题,本文以在线学习平台中的学习资源数据和学习者数据为采集层的基础数据,通过数据分析和挖掘,构建了多维度的个性化学习者模型。该学习者模型包括学习者静态特征和学习者动态特征,静态特征包括学习风格特征和静态兴趣偏好特征,动态特征包括认知水平特征和动态兴趣偏好特征。采用协同过滤作为在线学习资源的基础方法,将学习者静态特征和动态特征分别融入协同过滤的推荐方法中,通过实验得到的数据证实,本文构建的学习者模型,以及基于该模型构建的学习资源推荐方法提高了在线学习资源协同过滤推荐的性能。该方法对于满足个性化学习的需求、提高在线学习的学习效果具有重要意义。1.3 兴趣偏好的特征表示







1.4 认知水平的特征表示

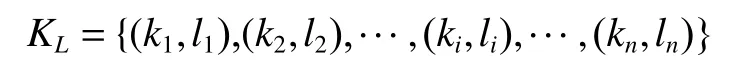
2 融合学习者模型的协同过滤改进
2.1 基于协同过滤的在线学习资源推荐
2.2 融合学习者静态特征的协同过滤推荐改进




2.3 融合学习者动态特征的协同过滤推荐改进
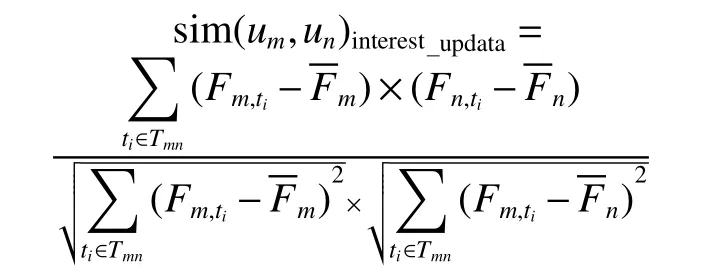


3 实验结果与分析
3.1 实验数据集
3.2 评价标准

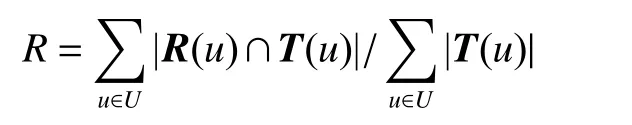
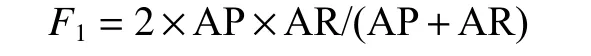
3.3 实验结果与分析





4 结束语
猜你喜欢
卫星应用(2022年7期)2022-09-05
卫星应用(2022年3期)2022-05-23
卫星应用(2022年1期)2022-03-09
云南画报(2021年8期)2021-11-13
学生天地(2020年15期)2020-08-25
意林·少年版(2020年2期)2020-02-18
环球慈善(2019年6期)2019-09-25
海外华文教育(2016年4期)2017-01-20
成人教育(2015年7期)2015-12-21
电子设计工程(2015年15期)2015-02-27
