
基于仲裁机制的生成对抗网络改进算法
2021-12-07 10:09谌贵辉刘会康李忠兵彭娇汪少天林瑾瑜
计算机应用 2021年11期
谌贵辉,刘会康,李忠兵,彭娇,汪少天,林瑾瑜
(1.西南石油大学工程学院,四川南充 637001;2.西南石油大学电气信息学院,成都 610500)
0 引言
图像的合成[1]是计算机视觉领域的一个重要的分支。由Goodfellow 等[2]提出的生成对抗网络(Generative Adversarial Network,GAN)极大地推动了这一领域的发展。同时在最近几年,运用卷积神经网络(Convolutional Neural Network,CNN)[3]的监督学习被广泛运用于计算机视觉的各个领域,因此将生成对抗网络与卷积神经网络相结合的网络结构也就应运而生。由Radford 等[4]提出的深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Network,DCGAN)正是将两者结合的产物,该网络模型进一步提升了GAN 的学习能力,提高了所生成图像的质量。随后,针对模型训练不稳定、容易出现模型崩溃的问题,Arjovsky 等[5-6]先后提出了WGAN(Wasserstein GAN)、WGAN-GP(Wasserstein GAN with Gradient Penalty),将Wasserstein 距离[7]的优越性质融入到了GAN 中,彻底解决了GAN 训练不稳定以及模型容易崩溃的问题,确保了生成样本的多样性。Zhang等[8]提出了将注意力机制[9-10]与GAN 融合的SAGAN(Self-Attention GAN),该改进模型可以很好地处理长范围、多层次的依赖,生成更精细更协调的图像。
但上述各个网络大都存在两个问题:即在其对抗训练过程中生成器与鉴别器都是按照固定的顺序进行训练,模型训练不灵活,导致模型从数据集中学习的特征没有得到更有效的运用;同时,其所使用的损失函数在优化过程中缺乏灵活性,致使模型的收敛状态不明确。因此针对这两个问题,本文提出了基于仲裁机制的生成对抗网络改进算法,该算法主要基于DCGAN,引入所提出的仲裁机制:度量分数计算,训练规划。引入仲裁机制的DCGAN 在每一轮对抗训练结束时会将经过训练的生成器输出的合成图像与真实样本导入仲裁器,通过仲裁器计算度量分数,并根据度量分数以及训练规划规则确定下一轮训练的次序。此时网络模型能根据上一轮的训练结果灵活地调整下一轮的训练次序。同时,通过调整模型中鉴别器的网络结构以及Sun 等[11]提出的Circle loss 函数,将改进模型与Circle loss 函数进行了融合,使得改进后的模型收敛状态更明确,所生成图像的效果得到提升。在LSUN(Largescale Scene Understanding)[12]以及CelebA[13]数据集上进行大量对比实验验证了本文算法的有效性。本文的主要工作如下:
1)提出仲裁机制,提高了模型对抗训练的灵活性。
2)将Circle loss 函数融入生成模型,使得优化过程更灵活,收敛状态更明确。
1 生成对抗网络的相关知识
生成对抗网络(GAN)[2]成功地将博弈对抗[14]的理念运用于深度学习领域,从结构上来看,GAN 主要由两个相互对抗竞争的神经网络构成:生成器(Generator)和鉴别器(Discriminator)。这种对抗竞争机制有利于使网络结构学习真实数据分布,并生成可以以假乱真的合成图像。
生成对抗网络中的生成器试图捕捉学习数据集中的真实分布,而鉴别器则在与生成器的不断对抗中提升自己辨别图像真伪的能力。通俗来说,生成器试图生成与训练集的数据分布相似的样本,鉴别器则试图区分生成器所合成的内容和训练集中的原始样本。在一个训练周期内,生成器试图更好地绕过鉴别器的筛查,而鉴别器试图捕获由生成器生成的合成图像,因此这一过程被称为对抗训练,其大致示意图如图1所示。
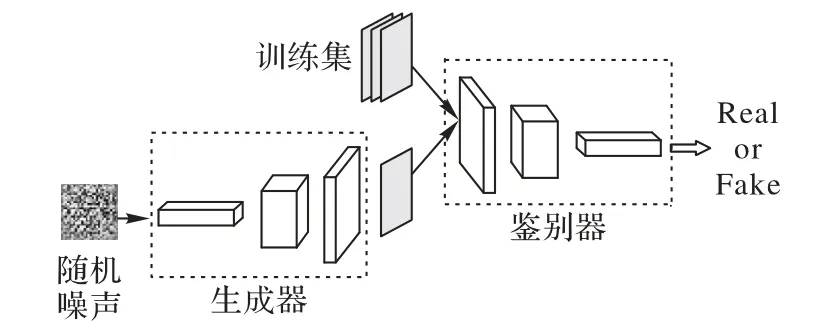
图1 生成对抗网络Fig.1 Generative adversarial network
生成对抗网络(GAN)的目标函数如式(1)所示:
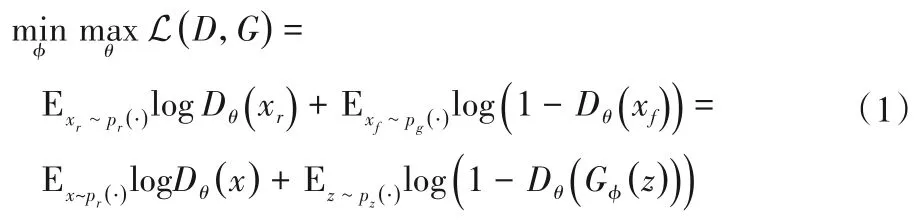
通过图1 可知,生成对抗网络把一组随机噪声导入生成器并根据网络结构参数通过反卷积上采样生成与真实图像xr同样大小的合成图像xf,并将合成图像xf与其标签“0”以及真实图像xr与其标签“1”导入到鉴别器中。根据式(1)可知训练鉴别器的过程中期望最大化目标函数使Dθ(xr)输出的概率值趋近于1,而使Dθ(xf)输出概率值趋近于0,使鉴别器辨别图像真伪的能力得到强化。当对生成器进行训练时期望最小化目标函数,即Dθ(xf)输出概率值趋近于1,使生成器能生成鉴别器无法判别真伪的图像。最后将最大最小目标函数的结果返回给生成对抗网络,并进行下一次对抗训练。
当对抗训练进行到最后时鉴别器对合成图像以及真实图像的输出概率值都接近于0.5。固定生成器,目标函数会在式(2)条件下存在鉴别器最优解。

此时鉴别器将无法判断生成器所生成图像的真伪,生成对抗网络将可以很好地拟合数据集的真实分布,生成可以以假乱真的图像。
2 基于仲裁机制的生成对抗网络
基于仲裁机制的生成对抗网络主要在DCGAN 的基础上引入了所提出的仲裁机制,旨在提升对抗训练过程的灵活性以及网络结构所学习到的数据集特征利用率。引入了仲裁机制的DCGAN 首先会提取网络模型中经过上一轮对抗训练的生成器和鉴别器;然后,将提取的生成器与鉴别器以及度量分数计算模块组合成仲裁机制中的仲裁器;其次,向仲裁器中导入相同批次相同大小的随机噪声以及从数据集中随机提取的真实图像;最后,仲裁器会根据导入的图像计算并输出度量分数,同时将生成器与鉴别器对抗训练的结果反馈给训练规划。
在模型优化上将使用更灵活的Circle loss 函数替换原始模型中的BCE loss 函数,该损失函数能更明确地引导模型收敛。
2.1 仲裁机制
在生成对抗网络的对抗训练过程中生成器与鉴别器总是按照固定的顺序交替进行训练,训练缺乏灵活性的同时从数据集中学习到的特征也无法得到更有效的运用。针对这一问题提出了仲裁机制。仲裁机制主要由两部分组成:1)度量分数计算;2)训练规划。
在每一轮对抗训练结束时,经过训练的生成器、鉴别器与不参与训练的度量分数计算模块会联合计算出度量分数,根据度量分数以及训练规划规则确定下一轮训练的次序,使得模型网络能根据上一轮的训练结果灵活地调整下一轮的训练次序。仲裁机制示意图如图2所示。
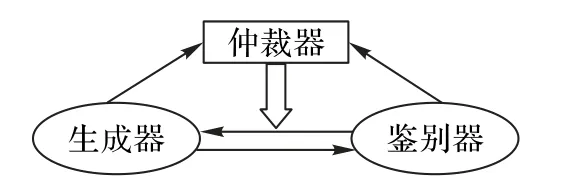
图2 仲裁机制示意图Fig.2 Schematic diagram of arbitration mechanism
2.2 度量分数计算
为适应度量分数计算以及Circle loss 函数输入,对鉴别器结构进行适当调整。鉴别器对每一个样本的输出不再是一个单一的概率值,而是包含32 个元素的概率列向量。此时的鉴别器可以看作自动编码器[15-16]的编码器部分,输出为经过降维的图像潜在特征向量,该潜在特征向量包含图像的大量特征和鉴别器对图像真假的评价,可用于之后的度量分数计算,即度量不同图像分布之间的相关性。同时把一个批次的真实或者合成图像的潜在特征向量看作潜在特征矩阵。
度量分数的计算需要通过仲裁器进行。仲裁器包含有生成器、鉴别器以及度量分数计算模块。其中,生成器与鉴别器为上一轮经过训练的网络结构,需要注意仲裁器只度量上一轮训练的结果,并不会通过反向传播算法更新结构参数。仲裁器计算度量分数大致如式(3)所示。
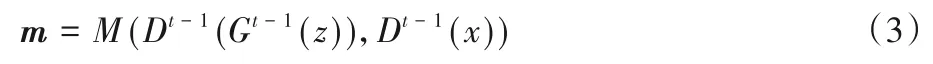
其中:Gt-1和Dt-1为上一轮训练后经过参数更新的生成器与鉴别器;z为随机噪声;x为真实图像;M为度量分数计算模块;m为输出的度量分数向量,包含真实图像与真实图像、真实图像与合成图像、合成图像与合成图像的相似性度量分数。
仲裁器首先从数据集中随机提取一定批次的真实图像x~Pdata(x)以及经过训练的鉴别器,并将真实数据导入鉴别器生成对应批次的真实数据的潜在特征矩阵Real,即Real=D(x)。同时将相应维度的噪声z~Pz(x)导入生成器,将生成器生成的合成图像再次导入鉴别器生成合成图像的潜在特征矩阵Fake,即Fake=D(G(z)),将两矩阵Real、Fake堆叠并计算相应的协方差矩阵cov。
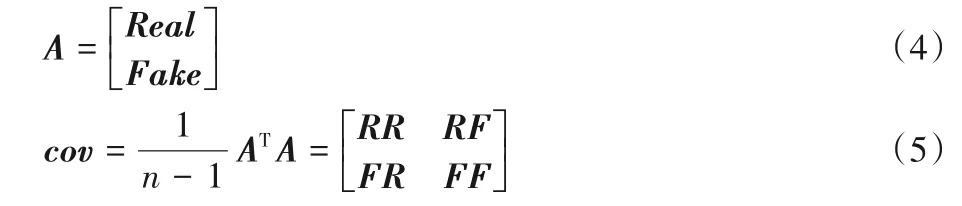
提取出协方差矩阵cov的分块矩阵RR、RF、FR、FF,并计算分块矩阵的特征值的期望,因为计算所得期望为复数,为方便进行比较,取复数在实轴上的投影即实数部分作为相似性度量分数:
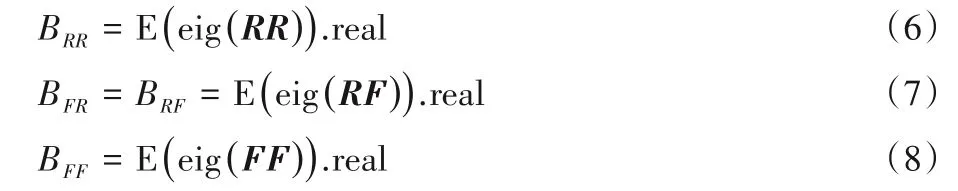
其中:eig(⋅)表示求取矩阵的特征值;(⋅).real 表示求取复数的实部。
通过比较各个相似性度量分数的有效位数可判断对抗训练过程的胜负。经过实验发现初始时RR的相似性分数BRR大于BFR,即真实图像之间分布的相关性大于真实图像与合成图像之间分布的相关性,同时BRR与BFF相近。当侧重训练生成器时BFR会向BRR靠近,侧重训练鉴别器时又会远离BRR,度量分数随训练次序的变化如表1所示。
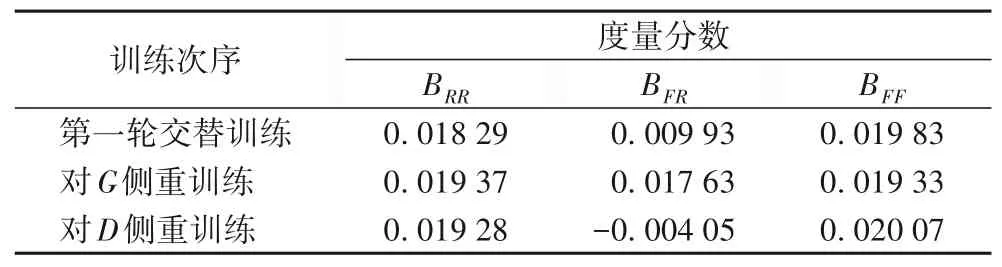
表1 度量分数Tab.1 Measurement score
因为BFR只会接近不会等于或超过BRR,因此当两者的有效位数相同时,则判定为鉴别器无法判别图像真假即生成器获胜;当BFR的有效位数小于BRR时,说明鉴别器能很好地判别图像真假即鉴别器获胜。简言之,通过比较真实图像之间分布的相关性度量分数与真实图像和合成图像之间分布的相关性度量分数的近似程度来判别一轮训练结束后生成器与鉴别器胜负。
2.3 生成器与鉴别器训练次序的规划
初始时,鉴别器与生成器都未经过训练,结构参数都为满足正态分布的随机值。在首次训练时对对抗的两个网络进行交替训练,更新网络结构中的初始化参数,让其学习到一部分数据集分布特征,有利于后续训练中模型状态的收敛。首次训练完后需要经过仲裁器的判别,提取出生成器,导入一个批次相应维度的噪声生成合成图像,同时从数据集中随机抽取相同批次的真实图像。将两者分别导入鉴别器生成对应的潜在特征矩阵。仲裁器会根据潜在特征矩阵计算度量分数,比较真实图像与合成图像分布之间的相关性进而确定生成器与鉴别器在上一轮对抗训练中的胜负。根据胜负按照训练规划规则确定下一轮训练的训练次序。
训练规划的规则即根据上一轮对抗的胜负决定下一轮训练中侧重训练的对象。侧重训练的方式为当鉴别器(D)胜过生成器(G)时即对生成器(G)进行侧重训练,下一训练周期优先对生成器(G)进行训练,然后再训练鉴别器(D),最后再对生成器(G)进行训练,形成一种三明治结构的训练次序。同理,对鉴别器(D)的侧重训练也是如上所述根据胜负交替进行,即根据胜负情况进行GDG或者DGD形式的训练次序,大致情形如图3所示。

图3 训练次序规划Fig.3 Training sequence planning
对抗训练初始阶段生成器与鉴别器会均匀对抗,双方的获胜次数大致相同,但随着训练的继续,生成器会需要更多的侧重训练才能胜过鉴别器,例如鉴别器胜过生成器8 次后生成器才能胜过鉴别器。仲裁的目的在于确保模型能够灵活地对抗训练并充分地利用每一次对抗训练中从数据集中学习到的特征信息,对抗双方一定次数的重复侧重训练有助于提高特征信息利用率。但当无法战胜的次数过多,需要更多侧重训练才能达到目的时,则会产生相反的效果。此时模型生成的样本单一,缺乏多样性,生成器总是趋近于逼近真实分布的某个狭窄区域,因而生成图像的多样性与质量会下降。因此在双方的胜过次数上需要添加一个胜过次数限制,当一方胜过三次即另一方侧重训练了三次后会强制训练获胜方,避免失败方侧重训练过多产生相反效果。
2.4 仲裁器结构
仲裁器包含经上一轮对抗训练后的生成器与鉴别器以及度量分数计算模块,但是结构上不包含损失函数,其作用主要处理上一轮的训练结果并判定生成器与判别器的胜负,输出下一轮对抗训练的次序且不将输出结果反向传播[17-18]。
仲裁器示意图如图4 所示,仲裁器中生成器Gt-1与鉴别器Dt-1为上一轮训练结束后经过参数更新的神经网络。向生成器Gt-1导入一组随机噪声生成一定批次合成图像,并将相同批次的真实图像与合成图像一起导入鉴别器Dt-1,进而生成两个潜在特征矩阵,并最后导入度量分数计算模块计算度量分数,经过判定输出下一轮的训练次序。
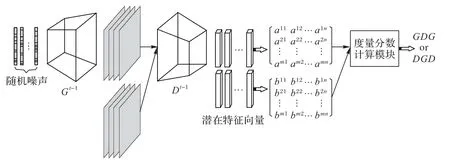
图4 仲裁器结构Fig.4 Arbiter structure
2.5 Circle loss函数
本文使用Circle loss 函数[11]替换了DCGAN 中使用的二分类交叉熵损失(Binary Cross-Entropy loss,BCE loss)[19]函数,该损失函数从相似对的角度出发,旨在最大化类内相似度sp与类间相似度sn,现有的损失函数如triplet loss[20]和softmax plus cross-entropy loss[21]都是将sp与sn嵌入相似对并以减小(sn-sP)为目的。这几种优化方法在灵活性上会有一定欠缺,因为优化方法在每一个单一相似分数上的惩罚力度被限制为相同。事实上当相似分数偏离最优值,网络结构应该对其投入更多注意力,对其重新加权,强调优化程度较低的相似性分数。Circle loss 的名字来源于圆形决策边界,统一了带有类标签以及成对标签的深度特征学习方法。
Circle loss 从式(9)的统一视角出发,并逐步演化过来,更具有一定的普适性。
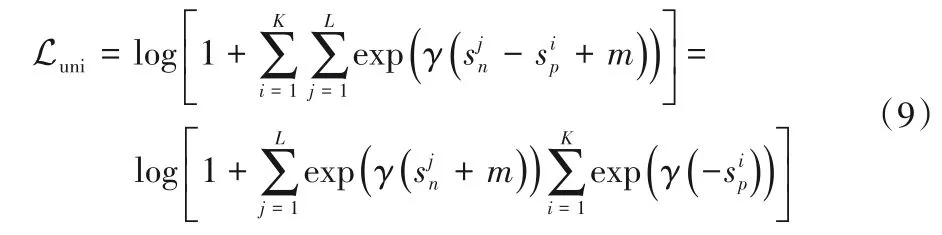
2.5.1 自适应加权
Circle loss 采用了一种自适应加权的方法,这种更灵活的优化策略允许每个相似性分数根据其优化状态去选择优化权重。首先忽略在统一视角下的式(10)的阈值k,转化为如下公式:


2.5.2 添加类内和类间阈值
在以往的损失函数中通过添加一个阈值k去优化(sn-sp),因为sn和-sp是对称的,在sn处添加一个正的k等于在sp处添加一个负的k。在Circle loss 中sn和sp是不对称的,所以其对sn和sp分别需要一个阈值。转换后如式(12)所示:
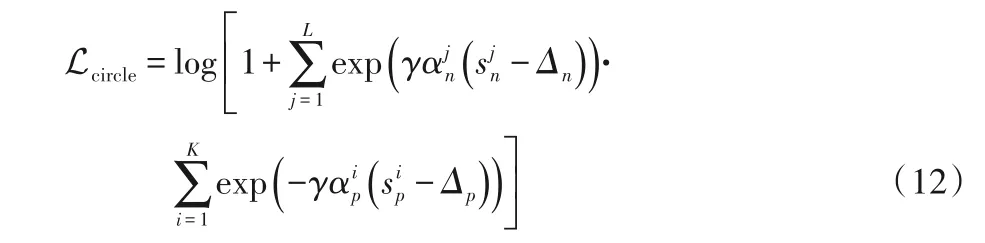
其中Δn和Δp分别为类间和类内的阈值。
本文所提改进模型将Circle loss 函数与生成对抗网络进行了融合,将该损失函数进行适当调整使之适应生成对抗网络真假分类的二分类情况,同时对生成对抗网络鉴别器的网络结构进行了相应优化,使之符合Circle loss 函数的输入要求。融合了Circle loss 的改进算法提高了对抗双方优化过程的灵活度,使模型拥有了更加明确的收敛状态。
3 实验与结果分析
3.1 参数设置及数据集
运行实验的平台为Windows 10,Python 3.7 和Pytorch 框架结合的编译环境,Intel 2.90 GHz CPU 时钟频率,内存为16 GB。
本文采用了两种数据集来验证模型的学习能力以及仲裁机制的有效性,分别为 LSUN(Large-scale Scene UNderstanding)数据集的church 子集以及CelebA 人脸数据集,其中着重训练在建筑物类数据集以及人脸数据集上学习数据集特征并生成图像的能力[23]。实验中所涉及的模型学习率设置为0.0002,总共训练30 epoch,采用Adam 算法进行优化,β1设置为0.5。
3.2 结果分析
为了验证文中所提算法的效果,对所提出的基于仲裁机制的生成对抗网络改进算法进行了多轮实例验证。本文算法主要基于DCGAN 模型,为了验证仲裁机制以及Circle loss 函数对模型效果的提升,依次对DCGAN、DCGAN+CircleLoss、DCGAN+CircleLoss+仲裁(限制)、DCGAN+CircleLoss+仲裁(未限制)这四种组合方式进行了实验,其中“仲裁(限制)”表示在仲裁机制中加入了获胜限制。在基于同一模型进行对比实验的同时,还与其他模型例如WGAN、WGAN-GP、SAGAN等进行了对比。文中主要采用了IS(Inception Score)[24]、FID(Fréchet Inception Distance)[25]两个指标来衡量生成模型的质量以及多样性。其中,IS 越大表明生成图像多样性和质量越好;FID 越小表明两个分布之间越接近,意味着生成图像质量较高、多样性较好。
表2 为实验中逐步改进的算法在CelebA 以及LSUN 数据集上的性能表现情况。首先,对鉴别器网络结构进行调整,由原来的输出单一的概率值调整为输出一组包含32 × 1的概率向量。即用自动编码器的编码器取代原来的鉴别器并用Sigmoid 函数进行激活。最后用Circle loss 函数替换了DCGAN原始算法的二进制交叉熵损失(BCE loss)函数。

表2 不同组合方式的改进算法性能比较Tab.2 Performance comparison of improved algorithms with different combinations
通过表2 中不同算法在两个数据集上的性能指标可以看出,“DCGAN+CircleLoss”组合的算法相较于DCGAN原始算法在人脸数据集以及LSUN 数据集上的效果都有了一定的提升。实验结果表明,经过调整的Circle loss 函数通过在图像真假二分类的类内类间相似度上施加不同的惩罚力度,使相似度根据与自身相适应的优化步伐逼近最优值,能够更明确更灵活地引导改进模型收敛,在相同训练周期内模型所生成的图像具有更好的多样性与质量。
在上述模型的基础上引入仲裁机制。首先,交替训练生成器与鉴别器更新网络结构参数。随后,提取出生成器并导入相应维度噪声生成一定批次的合成图像。同时,从数据集随机提取相同批次的真实图像。并将两者导入仲裁器,仲裁器内的鉴别器部分会将输入图像进行降维并输出潜在特征向量。仲裁器中的度量分数计算模块会将前一部分输出的潜在特征向量组成的潜在特征矩阵进行堆叠并计算协方差矩阵。提取出协方差矩阵内对应的分块矩阵,计算其特征值的期望,将期望的实部作为度量分数进行有效位数比较确定对抗训练胜负。根据胜负按照训练规划规则进行相应的侧重训练直至训练结束。因为存在侧重训练过多而导致模型崩溃[26]的现象并致使生成图像质量变差。为了提高生成模型的稳定性,缓解模型崩溃,在每一轮对抗训练中加入了获胜次数限制,并进行了对比实验。
通过表2 中“DCGAN+CircleLoss+仲裁(未限制)”以及“DCGAN+CircleLoss+仲裁(限制)”组合的算法可知,未加入获胜限制时,仲裁机制在提升模型训练灵活性的同时并未提高生成图像的质量,甚至在两个数据集上的性能指标都比原始模型以及融合Circle loss 函数的模型算法要差,原因为在对抗训练中生成器学习如何生成满足真实分布的图像相较于鉴别器学习鉴别图像真伪更难,所以在对抗训练中生成器需要更多的侧重训练才能胜过鉴别器。当鉴别器获胜次数过多,即生成器进行侧重训练次数过多时,生成器所学习到的图像分布将会趋近于逼近真实分布的某个狭窄区域以求骗过鉴别器。此时生成器所生成图像将趋于单一,缺乏多样性,更不能胜过鉴别器。在对抗训练中加入获胜限制后,鉴别器获胜次数过多时会强制对鉴别器进行侧重训练,此时能及时更新鉴别器参数,使鉴别器的神经网络感受野不再过于关注同一区域,此时生成器学习的分布将会远离之前逼近的真实分布的狭窄区域,更容易逼近图像分布的最优解。实验结果显示,加入获胜限制后改进算法在两个数据集上的结果明显有了改善,并且优于未加入仲裁机制的两种算法,表明了加入获胜限制在提高系统稳定性、缓解模型崩溃上的优点。
综合表2 数据可知,融合了Circle loss 函数以及添加了获胜限制的仲裁机制的改进算法除了在LSUN 数据集上的IS 指标不如DCGAN 原始算法和“DCGAN+CircleLoss”组合的算法外,剩余部分都优于在两个数据集上的其他对比算法,其中相较于DCGAN 原始算法,在LSUN 数据集上的FID 指标下降了1.04%,在CelebA数据集上IS指标提高了4.53%,表明了所提改进算法的有效性以及在生成图像上的优良性能。其中“DCGAN+CircleLoss+仲裁(限制)”组合的算法在LSUN 以及CelebA数据集上所生成的图像如图5~6所示。

图5 改进模型在LSUN数据集上的生成效果Fig.5 Generation effect of improved model on LSUN dataset

图6 改进模型在CelebA数据集上的生成效果Fig.6 Generation effect of improved model on CelebA dataset
在不断改进的模型之间进行对比实验的同时,加入了“DCGAN+CircleLoss+仲裁(限制)”与其他模型之间的对比实验,例如WGAN、WGAN-GP、SAGAN,对比结果如表3 所示。所提算法除了在CelebA 数据集上FID 指标差于WGAN 和WGAN-GP,以及在LSUN 数据集上IS 指标略小于SAGAN,其余部分均优于所对比经典模型,表明了引入Circle loss 函数以及仲裁机制的改进算法能更好地近似原始图像分布。在对抗训练中模型状态的收敛更明确,训练过程相较于原始模型更具有灵活性,能更有效利用训练过程中学习到的图像特征,所生成图像具有更好的多样性以及质量。
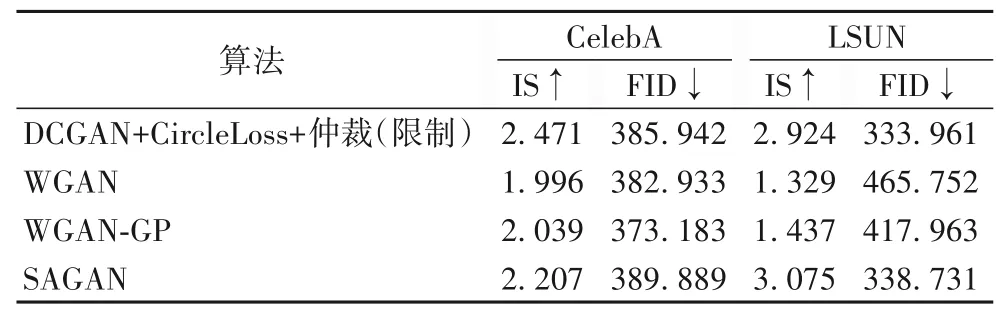
表3 不同模型的对比结果Tab.3 Comparison results of different models
4 结语
针对生成对抗网络中对抗训练缺乏灵活性,所使用优化算法不灵活、收敛状态不明确的问题,本文提出了一种基于仲裁机制的生成对抗网络改进算法。所提算法在建筑类以及人脸数据集上有较好的生成效果,优于DCGAN 原始算法以及WGAN 等经典算法。但是随着对抗训练的进行,添加了获胜限制的模型仍存在对抗训练不灵活的问题。由于生成器对图像真实分布的学习难于鉴别器对图像真伪分辨的学习,导致对生成器的侧重训练会逐渐多于鉴别器,进而造成模型训练的不稳定,添加了获胜限制的模型虽然能缓解这一问题,但最终会导致对抗训练次序的固化。如何在确保不引入获胜限制的模型能够灵活进行对抗训练的同时,提高模型训练的稳定性是今后的研究方向。
猜你喜欢
模式识别与人工智能(2022年9期)2022-10-17
上海文化(文化研究)(2022年3期)2022-06-28
计算机研究与发展(2022年1期)2022-01-19
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国对外贸易(2015年11期)2016-02-22
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
法制与社会(2009年18期)2009-07-08
