
前沿经济理论视野下的数据要素研究进展
2021-12-10 02:45荣健欣王大中
南方经济 2021年11期
荣健欣 王大中
一、引言
数据一般指以“0-1”二进制形式为数字技术搜集、存储、处理、传输的信息。进入21世纪以来,消费互联网及其催生的互联网平台高速发展,产业互联网方兴未艾,人工智能、大数据等新兴数字产业蓬勃推进。数据的处理、传输成本快速降低,数据在制造业数字化转型、电子商务、平台经济等领域中发挥的作用日趋显著,成为产业经济和宏观经济不可忽视的重要投入因素。就数据在当今国民经济中发挥的重要角色,以及经济主体(互联网平台、政府部门等)对数据搜集、处理的巨大投入来看,可以将数据视为一种新兴生产要素。
2019年10月31日,中共十九届中央委员会第四次全体会议通过《中共中央关于坚持和完善中国特色社会主义制度推进国家治理体系和治理能力现代化若干重大问题的决定》。文件提出,“健全劳动、资本、土地、知识、技术、管理、数据等生产要素由市场评价贡献、按贡献决定报酬的机制”。 2020年3月30日,中共中央、国务院发布《关于构建更加完善的要素市场化配置体制机制的意见》,明确提出要加快培育数据要素市场,为进一步发挥数据生产要素的作用指明了方向。党和政府对数据生产要素的重视,充分表明数据对于进入高质量发展阶段的中国经济的重要意义。然而,当前数据要素市场化无论在概念定义、统计度量、价值评估和市场化机制设计等方面都存在一系列实践问题,需要经济学理论提供解决思路。首先,相对于土地、资本、劳动等传统生产要素,数据作为一种生产要素具有一定的特殊性,例如非竞争性(non-rivalry)、规模报酬递增、隐私负外部性等。对数据要素经济价值和要素市场化的讨论离不开对这些特性的分析;其次,数据要素的市场化过程牵涉到数据产权归属、数据交易形式、数据交易机制等诸多前沿议题,需要经济学理论对数据要素化的机制设计和福利效应做出探讨;最后,经济学理论需要探讨数据作为一种生产要素,如何直接贡献于产业市场和宏观经济,并通过统计实证检验和测算数据要素的实际经济贡献。
数据要素的研究呼唤经济理论的创新。本文旨在梳理总结前沿经济理论文献研究数据要素的主要进展。这里所称的“前沿经济理论”,主要涵盖微观经济理论中的机制设计、合约理论、信息设计、行为经济学、产业组织理论,以及宏观经济增长理论中的内生增长理论等领域。这些领域的理论突破为数据要素的福利效应评估、产权归属设定、交易机制设计等重要议题提供了研究工具。当前,对于数据要素研究已有一些优秀的中英文综述(Pei,2020; Bergemann and Bonatti,2019;Carriere-Swallow and Haksar,2019;蔡跃洲、马文君,2021; 徐翔等,2021;熊巧琴,2020),这些综述系统梳理了数据要素研究的主要议题和重要文献。但现有综述由于种种原因,往往对相关数据要素议题的具体研究思路,以及数据要素与经济学前沿理论的贴合点缺乏深入介绍。本文将在这些综述文献的基础上,深入挖掘文献对数据要素相关议题的建模思路,以及与相关经济理论的结合点,从而为数据要素在中国的研究提供新思路。
本文内容组织如下:首先,从隐私负外部性、报酬特征这两方面入手,探讨数据要素相对于传统生产要素的特性;其次,从数据要素的产权归属和交易机制两方面探讨数据要素市场化机制,特别是分四个场景探讨经济学理论中对于数据要素交易机制的研究思路;再次,列举文献探讨数据要素在现实经济中创造经济价值的主要路径,并介绍对数据要素经济价值的重要实证研究成果;最后,从研究方法和中国问题两个角度展望未来的数据要素研究。
二、数据要素特性
这一部分中,我们将讨论数据要素的特性。现有文献已经列举了数据要素的众多特性,例如规模报酬递增、非竞争性、隐私负外部性、超越地理距离的即时传输性等。本文不再详细列举数据要素的一般特性(读者可参考其他文献,如徐翔等,2021),而将集中探讨数据要素的隐私负外部性,以及报酬递增/递减问题。这两大特性深度嵌入数据要素市场化的成本投入和产出收益过程,直接关联数据要素市场化的福利效应,因此对于数据要素的现实政策具有重要意义。此外,隐私负外部性与报酬递增/递减问题牵涉到数据要素的定义和度量,并且和文献所述的数据要素其他特性(例如非竞争性)息息相关。探讨文献对隐私负外部性和报酬递增/递减问题的处理,可以了解经济理论对数据要素的一般处理方法。
(一)隐私负外部性
现实中,不同数据集的信息普遍存在相关性,一个消费者的个人数据可能透露和该消费者有关联的其他消费者的信息。因此,任何消费者与企业“以隐私换补贴”的数据要素市场化交易都面临数据的隐私负外部性问题。但是隐私负外部性的刻画需要完善对数据、隐私本身的度量。这里将介绍几篇文献对于消费者个人数据和隐私负外部性的建模处理。
Ichihashi(2021b)研究了一个企业从消费者手中购买数据的模型。假设有n个消费者,企业从消费者手中购买数据以学习世界状态X∈χ, 每个消费者对于世界状态有一个共同的先验信念分布(common prior)。一次试验μ:χ→Δ(S) 能更新行为主体的信念,<μ>∈Δ(Δ(χ))代表由初始信念和试验μ决定的后验信念。如果<μ>是<μ′>的均值保持展开式(mean preserving spread),则称μ比μ′更有信息含量,表记为μμ′。经济体中数据配置表现为n个试验μ=(μ1,…,μn):χ→Δ(SN)。集合S是信号实现的集合。
为刻画数据隐私外部性,作者定义了数据的替代性和互补性。
数据配置μ是完全替代的,如果∀i∈N,<μ>=<μ-i>。
数据配置μ是完全互补的,如果∀i∈N,<μ-i>=<μø>,μø是无信息含量的试验。
直觉上讲,如果数据配置是完全替代的,则边际的个人数据价值为0,此时厂商光从其他消费者的数据就能推断这个消费者的信息。完全互补的数据配置则是一个消费者的数据的边际价值相当于整个数据集,即缺失了任何一个消费者信息的数据对于企业来说都是无用的。Ichihashi(2021b)用统计试验引致的后验信念分布定义数据配置,并以联合后验信念分布受到单个消费者数据影响的程度定义隐私负外部性。这一路径较为严谨但过于抽象。
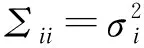
其中S表示包含所有用户的个人数据Si的向量,pi是平台对用户的支付。消费者隐私偏好强度为vi,其总收益为:
即平台总要更准确预测消费者类型,消费者总要避免被准确预测类型。由于存在数据隐私外部性,用户i的总信息泄露为:
这是通过所有用户的信息汇总后,对用户i的类型预测的均方误差(mean square error)的减少值。其中a={a1,…,an}代表所有用户的数据分享决策,ai=1代表用户i出让数据。Sa代表aj=1,即选择分享数据的所有用户j的数据向量。在这一简单的数据市场中,平台决定对用户的补偿pi,用户i决定是否出让数据ai。作者还定义了“单调性”、“子模性”(submodulity)等概念来度量数据隐私外部性。
单调性:两个行动组合a和a′满足a≥a′, 则∀i∈{1,…,n},Ji(a)≥Ji(a′)
经济学含义为:分享信息的用户集合增大后,信息泄露增大。
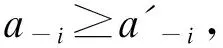
经济学含义为:任何消费者个人透露信息所导致信息泄露的边际增加随着其他消费者透露信息量的增加而减少。
Acemoglu et al.(2021)侧重使用统计指标(类型预测的均方误差)度量消费者信息透露带给其他用户的隐私损失。优点在于度量方法较为客观,缺陷在于隐私损失涉及消费者主观信念,不一定和统计预测的均方误差一致。
Choi et al.(2019)假定消费者使用一个垄断在线平台的服务必须同意出让个人数据。消费者需要权衡出让数据的隐私损失和在线平台的服务。但同时,消费者出让的个人数据也会透露关于用户和非用户(即不同意以出让隐私为代价接受平台服务的消费者)的信息,导致数据隐私外部性。具体来说,假设一个垄断在线平台提供内容服务,一单位连续统的消费者各自对平台内容有随机偏好u,u服从分布函数F。平台可从用户处通过征求同意搜集个人类型θ,θ服从分布函数G,每个消费者承受隐私净损失为λ(θ,m),其中m代表平台服务的消费者量。λ(θ,m)随θ和m递增,代表消费者类型越高,对隐私越敏感;且平台拥有的用户越多,对个体消费者的隐私侵犯越严重(数据隐私外部性)。数据除了对一般用户造成隐私外部性损失,还会造成非用户的隐私损失:对于每个θ类型消费者透露的数据,有α比例会产生非用户的隐私损失。社会计划者或者垄断平台选择门槛类型θE和θN,类型在[0,θE]的消费者由于数据外部性而被动出让隐私,类型在[0,θN]的消费者主动出售数据。即搜集的总数据为:
Choi et al.(2019)使用外生设定的函数来定义和度量隐私外部性和隐私损失。能较为灵活地适用于互联网平台服务换隐私的经济场景。但可能存在函数形式设定的随意性。
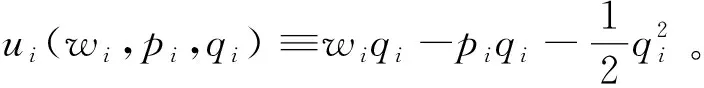
在上游数据市场,数据商在需求冲击实现前从个体消费者手中购买关于需求信息的数据,并把个体数据加总或混淆后售予产品厂商。数据商可以对消费者有效承诺搜集个人信息的精度。具体来说,如果消费者i出售数据,数据商根据承诺能够得到关于他支付意愿的一个私有信号:

其中aj代表消费者j是否出售数据的决策;数据商可以承诺+j的精度,即“混淆”原始数据以照顾消费者的隐私需求;数据商也可以调整αij这一参数以“加总”不同消费者的信息。同样,数据商对下游产品厂商也能出售进一步加总和混淆加工后的原始数据。记数据商搜集消费者数据的政策wi→si为信息结构S:RN→ΔRN。
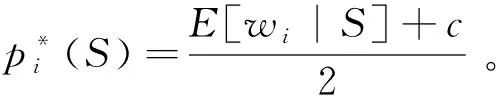
易知此时消费者的个人数据存在负外部性:即使一个消费者不透露自身数据,只要其他消费者透露了数据,则该消费者也要承担个人隐私泄露的损失:Ui(ø,S-i)-Ui(ø)<0。
Bergemann et al.(2021a)的隐私负外部性度量聚焦于泄露隐私引发价格歧视对消费者福利的客观伤害,是产业组织领域度量隐私负外部性的适当路径。综上所述,现有文献对于隐私负外部性的处理直接关联于所关心的具体场景和隐私的度量方式。采用纯粹统计方法度量的隐私(例如Ichihashi(2021)的后验信念分布函数的二阶随机占优性)较为客观,但难以刻画隐私泄露对消费者的主观损失。在产业市场,可以通过客观的价格歧视引致的消费者福利损失度量隐私负外部性。在其他领域,往往需要通过其他方式(例如问卷调查)度量数据要素的隐私负外部性。但文献中也指出了“隐私悖论”(Privacy Paradox, 即问卷中表示更关心隐私的消费者现实中乐于分享数据,见Acquisti et al.(2016)以及Athey et al.(2017))的存在。因此,适用广泛,客观,同时符合消费者主观偏好和实际行为的隐私负外部性度量仍需探索。
(二)报酬递增抑或递减?
传统生产要素(例如资本、劳动)经常被纳入Cobb-Douglas生产函数,以描述其规模报酬不变或边际报酬递减的特征。数据要素是否呈现边际报酬递减或规模报酬不变的特征?如果不是,其决定特征为何?这是文献尚在争论的问题。
1.数据要素的边际报酬
Varian(2018)讨论了人工智能行业的数据要素边际报酬。他认为机器学习中的数据要素,和传统生产要素一样,呈现边际报酬递减。用直观的图像展示,Varian(2018)显示机器学习随着训练图片的增加,平均识别准确率的增速递减。也有实证文献检验了数据投入的边际报酬。Bajari et al.(2020)使用亚马逊周度零售价格数据检验数据量对零售价格预测系统的预测准确度的影响。作者发现数据跨度越长,系统价格预测越准确,尽管存在边际收益递减。同时,横向数据规模越大(即同时期不同零售商的价格数据越多)不影响系统预测精度,即边际收益降为零。Dosis and Sand-Zantman(2020)认为在标准的贝叶斯信息更新框架下,数据的边际报酬递减是成立的,原因是较早收到的信号比较晚收到的信号更能改变决策。
Posner and Weyl(2018)看法相反。他们认为,以机器学习为主要技术的人工智能与传统统计学习技术有较大区别。机器学习能完成传统统计学习难以实现的复杂功能,例如识别人脸、实现高水平围棋对弈等。而这些复杂功能必须经由较大规模的数据投入才能实现。因此,机器学习的数据要素投入呈现阶段性、波浪形的“边际报酬递增-边际报酬递减”形式。
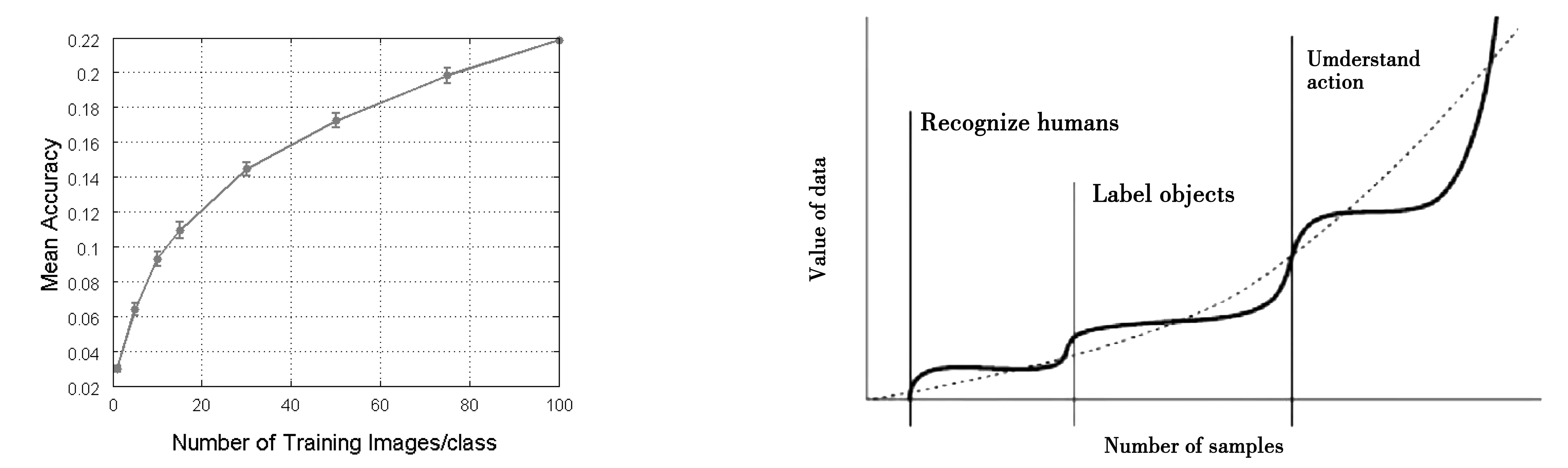
图1 机器学习样本量与平均准确度 图片来源:Varian(2018)。图2 机器学习样本量与数据价值图片来源:Posner and Weyl(2018)。
Varian(2018)和Posner and Weyl(2018)各自揭示了数据要素边际报酬的一个侧面。现实中,数据要素随规模不同,可能在不同阶段呈现边际报酬递增或边际报酬递减。因此,对数据要素边际报酬的讨论离不开微观层面技术经济特性的具体实证研究。
2.微观层面的规模报酬递增与网络效应
微观层面,要素的规模报酬指要素投入同比例变化引起的产出变化。众多实证文献指出数据要素可能存在规模报酬递增性,导致现实中大型厂商相比小型厂商不成比例地受益于数据要素。Begenau et al.(2018)就发现金融业数据要素强化大小企业的分化。然而,微观层面数据要素的规模报酬递增性来源何处,如何研究?Varian(2018)提出了微观层面数据要素规模报酬递增的三种来源。
(1)供给侧的固定成本效应。厂商为实现数据的处理、加工、分析,需要投入巨大的固定成本购买设备、开发软件。而数据本身的搜集、复制是自动化的过程,可变成本较低。因此,数据要素投入所耗费的总成本中固定成本占比较高。由此,更大规模的数据要素投入可以分摊较大比例的固定成本,从而降低平均成本,呈现数据要素的规模报酬递增性。Varian(2018)也指出,虽然软件的开发成本很高,但维护更新成本也不可忽视。未来能自主学习的智能软硬件,其可变成本的变化更需要关注。
(2)需求侧的网络效应。相当多的数据要素由互联网平台搜集。这些互联网数字平台的运营无可置疑呈现较强的网络效应。包括直接网络效应:对于微信等社交软件,消费者天然选择用户已经较多的产品;以及间接网络效应:对于操作系统等行业标准基础设施,用户较多、配套应用软件较丰富的系统容易吸引更多用户。直接和间接网络效应的存在,使得拥有数据规模更大的互联网平台能够通过吸引更多用户来搜集更多的潜在数据。需要指出,这种“数据网络效应”更多的是刻画和解释现实中互联网产品市场结构的特殊现象,和数据要素本身的普遍特性无关。
(3)“干中学”与累积效应。Varian(2018)认为,处理大数据的经验、技能本身比数据要素更稀缺。而且大数据的处理本身是信息科技的前沿,需要摸索经验。因此对数据要素的处理呈现较强的“干中学”效应。随着数据处理规模的增大,处理新增数据的成本投入相对降低,由此呈现规模报酬递增效应。
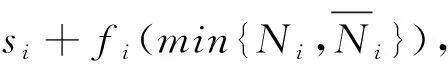
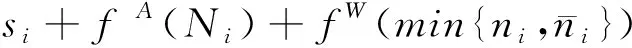
现有文献普遍认为数据要素存在微观层面的规模报酬递增,并能区分不同因素导致的规模报酬递增。通过对具体企业和行业的进一步研究,有望揭示数据要素的规模报酬对于不同企业和行业的异质性。
3.宏观层面数据要素的规模报酬递增:非竞争性与隐私成本
在宏观层面,数据要素的规模报酬可以分为总产出的规模报酬和净价值的规模报酬,这两方面与数据要素的非竞争性和隐私成本相关(1)内生经济增长理论较早就从技术知识的多部门可复用性推导出研发活动的规模报酬递增。例如Romer(1990)的研发模型就假设最终品部门和研发部门都将技术知识作为生产函数的投入,且一个部门使用技术知识不妨碍另一部门使用。。
(1)非竞争性
数据要素的非竞争性,来源于数据可以无成本地复制,因此一个使用者对数据的使用并不减少数据要素对其他使用者的供给。同一组数据可以同时被多个企业或个人使用,额外的使用者不会减少其他现存数据使用者的效用。从宏观经济层面来看,数据要素的非竞争性直接导致数据要素的规模报酬递增。
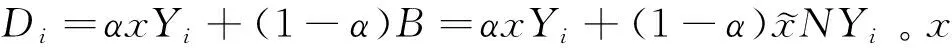
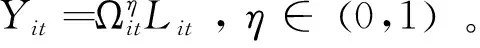
现有文献中通过刻画数据要素的非竞争性,容易在宏观经济增长模型中得到数据要素的宏观规模报酬递增性。需要指出,包含数据要素的宏观增长模型都需要设定数据要素的来源,Jones and Tonetti(2020)假定数据要素是社会产出的副产品,Veldkamp and Chung(2019)假定数据要素是消费的副产品。不同的假定都能将数据要素与宏观加总变量关联,但可能导致刻画的数据要素规模报酬递增的程度不一样。
(2)隐私成本
Veldkamp and Chung(2019)、Jones and Tonetti(2020)、Dosis and Sand-Zantman(2020)等多篇文献都将数据要素的隐私成本设定为数据使用量的二次项形式。这是一种在现实消费者隐私损失难以度量的情况下,沿用传统文献标准设定的做法。但二次项的凸性成本函数引出了关于数据要素的净价值是否存在规模报酬递增的疑问。例如在Dosis and Sand-Zantman(2020)设定下,给定线性产出和二次项隐私成本,数据要素的净价值是对数据量e严格凹的,因此数据要素净价值呈现规模报酬递减。对于那些数据产出呈现规模报酬递增的设定,如果结合二次项隐私成本,则更难考察数据净价值的规模报酬。当然,研究中也完全可以回避这一问题,只考察数据要素产出的规模报酬递增。
综上所述,数据要素的宏观规模报酬递增性主要来源于数据要素的非竞争性,但凸性隐私成本的存在可能导致数据要素的净产出不存在规模报酬递增。因此,未来的研究应更关注于隐私损失的刻画度量,以及数据要素宏观规模报酬递增效应的实证度量。
三、数据要素市场化
传统生产要素,如资本、劳动,其产权归属和市场交易机制较为直观、成熟。而数据要素由于存在非竞争性等技术经济特性,以及法律规定的不明确,导致其产权归属不确定。叠加数据要素交易场景的复杂性也导致学者难以探索数据要素市场化的一般机制。这一部分,我们将从数据产权归属和数据要素交易两个层面,讨论数据要素市场化问题。
(一)数据产权归属
需要指出,数据所有权这一概念在理论文献中存在争议。事实上,如Varian(2018)指出,数据与石油不同,由于数据有非竞争性,同样的数据可以为多方访问。“数据准入”(data access)比“数据所有权”(data ownership)更适合作为分析的基础。因此数据要素产权的定义,应包含数据搜集(或有权要求不被搜集)、访问、使用、交易等方面的权利束。在配置数据产权时,需要考虑(1)数据有隐私负外部性,赋予用户数据产权,不一定能实现有效的数据交易;(2)数据有非竞争性,用户可以将数据出售给多家厂商;(3)数据交易存在合约的不完全性和不可承诺性,用户有时难以相信厂商会合理使用数据;(4)个人数据牵涉到个人隐私,同时企业搜集处理数据也要付出成本,合理的数据产权归属应该平衡到所有这些方面。
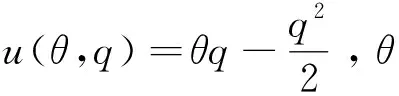
当数据处理和货币化变现是可缔约(contractible)时,按照科斯定理,数据产权归属不影响交易结果。厂商需要设定最优合约,给消费者提供一份包含用户给厂商支付t(θ), 服务使用量q(θ)和数据搜集量e(θ)的邀约{t(·),q(·),e(·)},并应用显示原理(revelation principle)诱使消费者透露真实类型θ。可以证明,最优合约中,厂商限制对高类型用户的数据搜集,换取这些用户消费更多服务;而厂商对低类型用户的数据搜集比例较高,原因是这些用户本身的服务消费较少,隐私总成本也较低。厂商无需以数据搜集换取高消费。
当数据处理和货币化是不可缔约(non-contractible)时,用户和厂商都无法在合约中承诺搜集多少数据(e)和加工多少数据。作者分别考察厂商和用户拥有数据产权的后果。由于数据处理不可缔约,厂商仍能就用户服务使用量q(θ)和支付t(θ)缔约,但无法承诺数据搜集量e(θ)。当厂商拥有数据产权时,厂商一定会尽其所能搜集数据使得e=q。作者证明此时厂商对于高类型用户的数据搜集相对可缔约情形是过度的,原因是高类型用户预计到自己消费服务后生成的数据会被完全搜集,因此会降低自身的服务消费量。
当用户拥有数据产权时,作者假设此时用户在使用服务,产生数据后,能控制δ比例的原始数据,可以决策将其变现。其余的1-δ比例的数据必须由厂商加工后才能变现,但由于无法在合约中进行约定数据加工量及其补偿,此时不存在事前合约激励厂商加工数据。另外,厂商和用户仍能就服务使用量q(θ)和支付t(θ)缔约,但数据搜集程度e(θ)无法缔约而是由消费者单方面决定。为了权衡数据要素变现收入和隐私损失,低类型消费者会选择最大程度的数据搜集e=q, 高类型消费者会选择只变现部分数据即e 作者讨论了不同参数下的最优数据产权配置。将产权配置给厂商有可能导致高类型用户担心隐私受损而不愿消费服务,将产权配置给用户可能导致厂商由于无法获得补偿而不愿加工数据。因此最优的产权配置需要权衡这两种效应。 Jones and Tonetti(2020)从宏观经济增长的视角考察了数据要素不同产权配置的影响。在这篇文章中,数据要素产权配置的核心权衡来源于消费者单期效用: 现有文献分别从微观、宏观两个层面探讨了数据要素产权归属的福利效应,覆盖了数据处理的不可缔约性、数据要素的非竞争性和隐私成本等,为数据要素的产权归属研究奠定了良好的基础。未来的文献有望在上述文献基础上,通过更细致的实证研究设计数据要素更细化的权利束安排。 数据要素交易深度嵌入不同行业数字化应用的具体场景,交易主体众多、交易对象和方式多样,因此对于数据要素交易的研究必须覆盖不同的交易场景。这一部分中,我们将依据微观经济理论文献,从不同的交易场景视角,探讨数据要素的交易机制。需要指出,虽然不少文献中明确了“信息”和“数据”的区别,指出数据是信息的载体,而数据要素的经济价值通过信息来实现(Jones and Tonetti, 2020)。但任何数据要素交易机制的设定,都必须涉及数据携带的信息价值实现的微观机理。因此,下文中对于数据要素交易机制的讨论可能涉及较为微观的信息设计问题。 1.双边交易机制设计 Dirk Bergemann应用微观经济理论中的信息设计、机制设计的思路和方法,研究了通过存在数据中间商的数据要素交易机制。这些双边数据要素交易机制有以下特征:(1)数据的作用在于提供信息,帮助数据买家与消费者更好匹配;(2)数据中间商可以通过提供事后信息、设定信息结构、收购并加工数据、提供事中信念更新机会等方式,交付数据。 作者使用机制设计方法,将数据商的试验菜单设计问题转化为一个说真话机制设计问题。最后得出卖家收益最大化的试验菜单:将事前信息较少的卖家视为高类型,事前信息较多的卖家视为低类型。数据卖家将给高类型完全信息的试验,给低类型部分信息的试验。这一试验以较小的概率告知买家其身处事前认为概率较低的状态,以较大的概率生成一个有噪音的信号。这样,低类型买家愿意出钱买数据,原因是这一数据交易以正概率改变买家的信念从而改进其收益。在整个机制的设定中,数据商需要在保障买家说真话的前提下,实现社会效率和信息租抽取尽可能兼得。 Bergemann et al.(2018)将数据交易深度嵌入到方兴未艾的信息设计(information design)文献,通过假定数据为买家提供有用的信息结构,以及将买家的信息结构偏好转化为可加总的效用函数,从而应用标准的机制设计方法得到数据卖家的最优信息匹配。然而,由于现实中的数据要素交易往往是打包的数据买卖,鲜少精细的信息结构匹配,Bergemann et al.(2018)这一贴合主流理论的模型难以直接应用于众多的现实数据要素交易场景。而Bergemann and Bonatti(2015)和Bergemann et al.(2021a,2021b)则为信息设计方法找到了较为符合现实的数据交易应用经济环境。 Bergemann and Bonatti(2015)考察数据商拥有关于消费者个人信息的数据(即所谓Cookie),并可以将查询消费者个人信息的机会售予广告主(advertiser)。具体来说,一单位连续统的消费者和广告主产生一个匹配价值:ν:[0,1]×[0,1]→V,广告主从消费者处得到的收益为:π(ν,q)≡νq-c·m(q),q代表消费者对广告商广告的注意程度,m(q)代表广告主为得到消费者注意而花费的广告成本。在初始状态,广告主除了一个共同初始信念(common prior)之外没有关于匹配价值ν(i,j)的额外信息,而数据商可以提供关于每一对消费者-广告商匹配价值的信息。因此广告主可以从数据商处购买与自己的匹配价值在任意范围内的消费者的个人身份信息。假设数据商关于单个消费者的身份信息售价统一为p,并且假设广告主对自己购买身份信息的消费者集合设定个性化的广告方案(即设定不同的q),而对自己没有购买信息的消费者集合设置统一的广告方案(即设定统一的q)。由此,作者考察广告主对消费者数据的需求量,以及数据商的最优数据定价。广告主购买消费者数据,需要权衡更多消费者数据带来的潜在匹配收益,以及增加的成本(包括数据购买成本和广告匹配成本)。对于数据买家(广告主)来说,高价值消费者的个人数据和广告投入是战略互补品,低价值消费者的个人数据和广告投入是战略互替品。数据商也根据广告主的需求设定最优垄断价格。作者成功地将经典微观经济理论中的垄断定价理论灵活应用于个人身份信息相关数据交易这一常见的数据要素化市场化场景。 Bergemann et al.(2021a)讨论了一个数据商从消费者手中购买数据,然后销售给厂商,帮助厂商调整产品质量和价格的经济场景。作者引入了个人数据的社会维度:单个消费者的数据能帮助预测其他消费者的行为,由此产生的数据外部性能降低数据商购买数据的成本。Bergemann et al.(2021a)中的数据商扮演了数据混淆、加工、转售的角色,并且利用消费者的隐私负外部性获利。 具体设定作者已在二(一)部分介绍。这里只需介绍文中的数据商角色和数据交易策略。 在上游数据市场,数据商事前(需求冲击实现前)从个体消费者手中购买关于需求信息的数据,并把个体数据加总或混淆后售予产品厂商。数据商可以对消费者有效承诺搜集个人信息的精度。具体来说,如果消费者i出售数据,数据商根据承诺能够得到关于他支付意愿wj的一个私有信号: 其中aj代表消费者j是否出售数据的决策;数据商可以承诺+j的精度,即“混淆”原始数据以照顾消费者的隐私需求;数据商也可以调整αij这一参数以“加总”不同消费者的信息。同样,数据商对下游产品厂商也能出售进一步加总和混淆加工后的原始数据。记数据商搜集消费者数据的政策wi→si为入口(inflow)信息结构S:RN→ΔRN,数据商将信号si再次加工后传给下游产品厂商信号ti为出口(outflow)信息结构T:RN→ΔRN。 综上所述,Dirk Bergemann的一系列研究成功应用了机制设计、信息设计、产业组织等领域的前沿理论,探索数据商的市场设计问题。其研究既涵盖关于数据交易的一般理论建模,也有对消费互联网平台这一数据要素重要应用场景中多种数据交易方式的市场设计。是对于数据要素交易机制综合了理论与实际的优秀应用微观理论研究。未来的实证研究可以基于这一系列研究进行拓展。 2. 市场结构与数据交易 现实中,数据要素的需求方主要是产业市场的企业。而数据要素交易将会透过市场结构的差异影响产业市场竞争的结果。机制设计/信息设计方法较为适用于一个数据商对多个数据需求方的情形。而无论数据要素供给端(数据商)存在竞争,还是需求端(产业市场厂商)存在产业竞争,都会使问题复杂化。一系列文献考察了数据要素交易机制与产业市场结构的关系。 Bounie et al.(2021)建构基于经典Hotelling模型的产业竞争模型,考察一个数据商可以将消费者需求信息分段售予两个竞争企业。通过控制数据的质量,数据商可以调控买家企业的竞争强度。数据买家根据获得的消费者信息,识别最有利可图的消费者身份,并据此定价。具体来说,一单位连续统的消费者均匀分布在线段[0,1]上,两个厂商彼此竞争,位于线段两段。任意位置的消费者最多消费1单位物品,获取效用V,并付出单位交通成本t。位于位置x的消费者从厂商1购物的效用为V-tx-p1。 厂商知道消费者均匀分布,但不知道具体位置(即消费者身份)因此无法实现价格歧视。厂商可以付出成本w购买数据,数据商提供的信息结构是把线段划分为n个任意大小的线段,厂商拥有这些数据后,可以针对特定线段的消费者设定不同价格实现价格歧视。厂商也知道竞争对手获得的信息结构及由此采取的策略。更精细的划分会导致(1)厂商更精细的价格歧视和更高的消费者剩余攫取;(2)厂商价格歧视策略导致低价格段的降价竞争加剧。数据商的最优数据出售策略是出售最有利可图的消费者信息,并将低价值的消费者信息保留不售,从而在获取对最有价值的消费者抽租的同时尽可能削减厂商竞争导致的损耗。最终均衡时,数据商只对一家厂商出售数据。 综上所述,Bimpikis et al.(2019)从市场环境不确定性角度,Bounie et al.(2021)从价格歧视角度,都刻画了数据要素的价值及存在产业市场竞争时,单个厂商效率和整个市场竞争的背离,以及对应的数据商抽租和效率的权衡。两者都显示,下游产业市场的竞争为数据要素交易的需求端增加了额外的复杂性。数据商需要考量下游产业市场竞争对数据要素经济价值的影响。 作者发现上下游企业的竞争不一定能提高厂商对消费者的补偿。原因是数据存在非竞争性(non-rivalry):如果多个上游数据商同时以相同价格向消费者求购数据,消费者可以将一份数据出售给多个厂商,导致上游数据供应过量,下游市场数据价格降低。预计到这一点,数据商不会以有竞争力的价格向消费者购买数据。最终形成的均衡特点是:(1)不同数据商只会采购互斥的数据集合,不会采购同一数据,导致下游厂商面临的加总数据集合与垄断数据商一致;(2)数据商在数据采购市场表现为垄断买家:给每个消费者的对价仅可补偿下游厂商使用数据给消费者带来的损失。 3. 消费者数据出售与数据市场有效性 现实中,数据要素交易除了有企业间的交易,还普遍存在企业用现金补贴或服务直接换取消费者个人数据的现象。这种“隐私换补贴”或“隐私换服务”的消费者-企业直接数据要素交易能否实现有效市场配置,是文献关心的内容。由于本文二(一)部分关于隐私负外部性的讨论已经覆盖了本部分的主要文献,这里将不再重复之前涉及文献的具体设定,而是聚焦市场均衡的福利效应。 Ichihashi(2021b)研究了一个企业从消费者手中购买数据的模型,在较为抽象和一般的层次上,结合信息设计和产业组织理论探讨了消费者出让数据交易的社会福利。假设消费者的数据出售行为会透露其他消费者的信息(数据的隐私外部性)、作者讨论了厂商如何利用数据外部性来降低数据采购的成本。具体设定已在二(一)部分中介绍。Ichihashi(2021b)将消费者数据出售刻画为厂商选择价格集合p=(p1,…,pn)并公布,其中pi是对消费者i的支付,然后所有消费者决定是否出售数据的时序。厂商的数据由出售了数据的消费者的数据(即统计试验)μi决定。 作者证明,当厂商对信息掌握越多对消费者有害,即μμ′意味着消费者效用ui(μ)≤ui(μ′)≤0时,此时完全替代的数据配置会最小化消费者福利,最大化企业利润,并导致数据售价为0。直觉是一个消费者透露个人信息会造成对其他消费者的损失,厂商可以利用这一外部性压低消费者对个人数据的要价。由此类推,而给定一些条件,完全互补的数据配置最大化消费者福利,最小化企业利润。当数据搜集对消费者有利,即μμ′意味着消费者效用ui(μ)≥ui(μ′)≥0,此时完全替代的数据配置会最大化消费者福利,最小化企业利润。而给定一些条件,完全互补的数据配置最小化消费者福利,最大化企业利润。 Acemoglu et al.(2021)设定平台与消费者之间的数据交易。作者假定消费者i如果出售数据,其效用为: ui(ai,a-i,p)=pi-viJi(ai=1,a-i) 其中pi为平台对消费者i的补偿,vi是消费者i的隐私偏好,Ji为以消费者i类型预测均方误差度量的信息泄露函数,不仅受到消费者i自身数据出售决策(ai=1)的影响,还受到其他消费者数据出售决策a-i的影响。作者发现平台与消费者的数据交易中,数据隐私外部性导致了过多的数据分享和过低的数据价值。作者证明(定理3),如果高类型(更重视隐私)的用户类型与其他用户类型无关联,则最终均衡是有效的。原因是高类型用户不会出售个人数据,而低类型(不重视自己隐私)的用户不管怎样都会出售个人数据,但他们的决策不影响高类型用户。作者还给出均衡时社会剩余为负的充分条件,满足这一条件时,数据市场只给社会带来净损失,完全关闭数据市场能改善社会福利。Acemoglu et al.(2021)的贡献在于给出隐私损失和隐私负外部性的客观度量,并成功引入了用户对隐私偏好的异质性。 Choi et al.(2019)假定消费者使用一个垄断在线平台的服务必须同意出让个人数据。消费者需要权衡出让数据的隐私损失和在线平台的服务。但同时,消费者出让的个人数据也会透露关于用户和非用户(即不同意以出让隐私为代价接受平台服务的消费者)的信息。具体设定见二(一)。通过考察社会最优和垄断定价时的门槛值u(即平台只服务对平台内容偏好超过u的消费者),作者可以检验数据要素和数据外部性对社会福利的影响。作者发现在一个没有数据搜集的简单垄断定价经济环境里,垄断平台服务的消费者数量相对于社会最优不足,而在有数据搜集和数据外部性的条件下,垄断平台服务的消费者和搜集的数据超过社会有效水平。Choi et al.(2019)的特点是使用精巧的经济环境设定,应用标准的垄断定价和机制设计方法,探讨在线平台“服务换隐私”这一较为符合现实的数据要素交易场景。 上述文献从不同角度探讨了消费者作为交易主体直接与厂商或互联网平台交易数据的福利效应。通过纳入隐私负外部性,这些文献都显示消费者与厂商的数据交易可能无法实现社会最优。这一结论具有重要的政策含义。 Fainmesser et al.(2019)的特点在于:(1)假定消费者隐私损失是客观的数据被窃取量,避开对用户主观隐私偏好的建模;(2)假设隐私损失来源于外界攻击,平台与用户利益本质一致,从而描述现实中数据存储和数据保护两类不同的策略;(3)根据网络效应区分数字平台的不同商业模式,梳理其数据隐私保护政策的差异。 综上所述,现有文献涵盖了消费者直接参与数据要素交易时的各种场景和各种设定,例如外部数据窃取、隐私负外部性、数字平台网络效应等。现有文献能有效解释部分互联网平台的隐私保护策略差异,并能定性评估消费者数据要素交易的福利效应。应用计量经济学方法对部分结论进行检验,并为更细致的数据隐私规制政策提供支撑,是未来研究可行的方向。 4.厂商数据交换与产品市场竞争 现实生活中,除了通过从数据商处购买数据,或者直接从消费者处搜集数据,厂商还热衷互相分享数据。Elsaify and Hasan (2021)搜集到包含1285家厂商的1600多个数据交易/交换数据。作者发现17%左右的厂商参与数据市场,80%左右被交易的数据为消费者数据,50%以上的数据交易是以厂商间数据互换而非直接交易的形式进行的。作者还发现市值最高、处理数据能力越强的大厂商越容易参与数据买卖。同时,多数数据交易发生在同行业厂商间。 同行业的厂商何时有交易数据的动机?产业市场竞争又如何影响同行业厂商分享数据的激励?Raith(1996)详尽探讨了同行业寡头竞争厂商分享数据的问题。 自然状态为τ=(τ1,…,τn)′,τi可以代表外生参数(例如企业边际成本或线性需求函数截距项)与均值的偏差。τi均值为0,方差为ts, 协方差为tn∈[0,ts]。τi进入厂商利润函数但厂商i并不知道其实现值(只知道分布)。在设定产量或价格前,企业接受到一个有噪音的关于τi的信号yi≡τi+ηi,ηi均值为0, 方差为uii, 协方差为un。作者考察了厂商间状态的关联度: (1)共同价值(Common Value):tn=ts=t。 此时所有企业面临的自然状态一致。 (2)独立私有价值(Independent and Private Value):tn=un=0。 此时不同厂商之间的自然状态不存在关联,且彼此收到的信号也不存在关联。 (3)完美信号的私有价值(Private Value and Perfect Signals):uii=un=0。此时不同厂商收到的信号不存在关联, 且能完美反映自然状态。 注意,在(2)、(3)两种情形下,厂商间分享信息无助于各自更好了解面临的市场状况(即自然状态),但可能影响厂商彼此策略的关联度。 企业间分享信息有两个效应:一方面每个厂商能更好了解市场状况,另一方面厂商间信息的同质性会影响竞争策略的关联性。作者证明,让对手更好了解关于他们自己利润函数的信息能增进策略关联,策略关联对厂商自身利润的影响取决于厂商策略是战略替代(例如古诺博弈)还是战略互补(伯特兰德博弈);而让对手更好了解厂商自身的利润函数的信息总能增进厂商自身的利润。 Raith(1996)详尽讨论了产业市场上厂商彼此交换数据的权衡与激励。然而,需要指出,由于年代较早,Raith(1996)的研究集中于厂商交换信息的激励,较少讨论在大数据、人工智能技术发达的今天,厂商通过共同汇集数据,发挥数据要素的非竞争性和规模报酬递增性,实现行业整体数字化升级的激励。当然,厂商的数据交易必然蕴含信息交换。本文作者参与广东省各地市企业数字化转型调研也发现多数企业仍然担心向其他企业分享数据可能泄露机密。Raith(1996)的研究结论仍然成立。当然,未来的研究可以更精细地区分企业交易数据要素的多重效应:提升行业总体产出、改变产业市场竞争策略、泄露自身部分信息;并对不同的产业市场开展更细致的产业研究。 之前探讨了数据要素的主要特性和市场化机制。本部分将从更微观的视角,梳理文献中提及的,数据作为一种生产要素在现实经济中发挥的作用。我们将从微观产业市场、金融市场、宏观经济增长等几个角度来介绍文献中对于数据要素经济价值的理论探讨和建模思路,并给出根据GDPR等实际政策评估的实证结果。 1. 产品市场的产品设计 在消费品市场上,数据的作用使企业能更好地设计产品,满足消费者的需求,从而获取更大的消费者剩余。现有文献通常外生假定(1)数据要素有助于降低成本或提升质量;(2)数据要素来源于需求量或生产过程;来体现数据要素的特殊性。同时,引入数据要素也为探讨数字经济的产业市场结构提供了新视野。 Corniere and Taylor(2020)与Hagiu and Wright(2020)一样,同样对数据要素的价值施加外生假定。作者假设有n家企业,每家企业i选择一个消费者效用水平ui,而消费者I从厂商i获取的实际效用为uiI=ui+iI。厂商产品的需求函数为Di(u),满足和即厂商设定的消费者效用水平越高,厂商销量越高;而竞争对手设定消费者效用水平越高,厂商销量越低。假设厂商从每个消费者上获取的收益为ri(ui,δi),其中δi代表厂商获取的消费者数据的质量。即数据要素通过改善同等质量的厂商产品与消费者的匹配度,进而提升厂商收益。通过检验数据质量δi对企业效用设定水平ui的影响,可以刻画数据要素是否促进产品市场的竞争。Corniere and Taylor(2020)的这一抽象框架可以应用于个性化产品定制、定向广告、价格歧视等数据要素价值实现的具体场景。 上面两篇文献都是从数据要素增进厂商产品与消费者的精准匹配这一角度设定数据要素的经济价值。而Prüfer and Schottmüller(2017)则强调了数据要素通过增进厂商对消费者未来需求的精准预测,从而降低创新成本,改善创新效能。具体来说,消费者根据两个寡头企业的产品质量差异Δ=q1-q2来选择购买的产品,企业能用获取的消费者信息改进产品,而企业获取的消费者信息与产品需求量Di成正比。每一期,企业选择创新幅度xi,t=qi,t-qi,t-1。假设企业创新成本c(x,Di)随数据量即需求量下降。因此企业产出呈现间接网络效应,产业市场可能呈现趋向完全垄断的多米诺趋势。 2. 金融市场的资产配置 3. AI训练 随着AI(人工智能)行业的发展,数据要素通过强化计算机统计学习,直接提升人工智能技术水平和辅助决策能力的功能受到了关注。Baraja et al.(2020)考察了AI行业中的数据要素价值。人工智能行业中,通过大数据训练模型能改善AI模型的精度,从而提升AI软件的性能。作者使用中国数据验证了这一假说。作者特别考察了中国人脸识别AI系统公司与政府签订的采购合约,与政府签约开发人脸识别系统的AI企业,有机会接触到政府拥有的人脸识别原始数据。而这些数据能帮助企业提升AI软件开发水平,而企业软件创新水平的提升,不仅有助于企业更好完成政府合约,还能帮助企业提升民用软件的水平。使用三重差分计量方法,作者检验发现获取“数据密集”(data-rich)政府合约的企业,相对于获得“数据贫乏”(data-scarce)合约的企业,在获得合约的三年后,无论是开发的面向政府的AI产品还是面向商业用途的AI产品都显著更多。显示了数据要素在AI行业的特殊应用价值。 4. 经济增长 上面讨论了不同行业中的数据生产要素的微观经济价值。如果将数据要素抽象为一种新型生产要素,可以通过经典的经济增长模型讨论数据要素的经济价值。 众多文献已经从理论层面阐述了数据价值产生经济价值的路径和领域。已有文献也应用实证方法评估数据要素的经济价值。 2018年,欧盟实施一般数据保护条例(GDPR),强化了对互联网平台搜集个人信息的限制,从而限制了数据要素的市场化。对于欧盟GDPR的研究有助于评估数据要素的实际经济价值。Aridor et al.(2020)研究了欧盟一般数据保护条例(GDPR)的经济效应。GDPR限制了互联网平台接触、使用、共享包含个人信息的数据。作者使用一个在线旅行平台的数据,采用双重差分法检验了GDPR的经济效应。发现GDPR实施后,由于允许消费者选择不提供个人信息,在线旅行平台的消费者数量减少了12.5%。Jia et al.(2021)也发现,GDPR降低了欧洲相对于美国互联网行业的融资水平。Johnson et al.(2021)则发现GDPR实施后,网站间数据分享减少,同时为网站提供服务的技术服务商市场集中度增大。 Bajari et al.(2020)使用周度零售价格数据检验数据规模对于亚马逊平台的零售价格预测系统的预测准确度的影响。作者发现数据跨度越长,系统价格预测越准确,尽管存在边际收益递减。同时,横向数据规模越大(即同时期不同零售商的价格数据越多)不影响系统预测精度。作者也确实发现亚马逊价格预测系统随时间不断改进预测精度,体现了数据要素的持续积累能力。 Hughes-Cromwick and Coronado(2019)实证检验了美国政府数据对企业的价值,通过搜集政府报告和对企业调查的数据,作者估算了美国政府数据对部分行业(汽车、能源、金融服务)企业的价值,并汇总了一系列研究对美国政府公开数据的行业价值的估算。作者总结说,随着信息技术的发展,政府数据对私营部门的价值越来越高。尽管公司部门也在积累自身数据,但只有把自身数据和公开的综合的政府数据结合,才能提供数据应用的关键场景,从而获取最大利益。 其中λit代表数据加工的劳动投入,ADM代表数据经理的生产率。通过求解企业的最优动态选择问题,作者可以将企业的最优数据要素存量写成关于企业薪资、劳动力和数据加工劳动投入的函数。在实证部分,应用投资管理行业企业数据,作者发现知识工作中劳动收入比例从44%下降到27%,体现了数据要素在该部门生产函数中的作用提升。 综上所述,现有文献或基于现实政策评估(GDPR),或基于微观数据统计预测及宏观数据拟合,检验了数据要素的经济价值,总体上确认了数据要素在产业市场中的作用趋向显著。未来的实证研究可以基于理论模型研究的成果,应用结构式计量的方法进一步检验数据要素的经济价值。 对数据要素市场化的研究,离不开对微观经济学前沿理论的跟踪。本部分将介绍三篇文献,分别依托信息设计理论、行为经济学理论和机制设计理论的前沿发展,拓展了数据要素的研究视野。 1.信息设计 Dirk Bergemann等学者长期深耕信息设计理论在数据要素市场化方面的应用。而Ichihashi(2020)则应用信息设计领域方兴未艾的贝叶斯劝说(Bayesian Persuasion)方法,考察了消费者对厂商的数据透露(disclosure)策略。该论文的核心权衡(trade-off)是消费者透露信息后能获得厂商更准确的产品推荐,但也会导致厂商有机会实施价格歧视。 作者假设存在一个生产K种产品的垄断厂商,一个有单位需求的消费。消费者对产品k的估价uk是服从独立同分布的随机变量,消费者效用为uk-p。 消费者起初不知道每种产品价值uk的实现值。消费者先选择一个信息透露策略φ:VK→Δ(M), 这一策略将u的实现值转换为对应的信号m的分布。作者用贝叶斯劝说(Bayesian Persuasion et al., 2011)设定消费者的信息透露。 例如厂商出售两种产品(K=2)的情形,δ∈[1/2,1]为透露水平,当uk=max{u1,u2}时以δ概率发送信号k∈{1,2}。 博弈初始,自然(nature)决定u的实现值,并根据消费者信息透露规则决定信号m~φ(·|u)。 在非歧视定价规则下,厂商先定价,在观测到消费者的信息透露策略φ和信号m后,再推荐产品k。 在歧视定价下,厂商先观测到消费者的信息透露策略φ和信号m后,再推荐产品和定价。无论哪种情况,只有在厂商推荐后,消费者才能观察到厂商所推荐产品k价值uk的实现值和价格。 这一模型应用信息设计理论捕捉了数据-隐私交易的几个特征:(1)消费者的信息透露策略可以解释为消费者对个人数据的保护策略,例如是否允许购物网站访问Cookies等;(2)消费者只有在获得厂商推荐后,才能知道(自然决定的)产品估价,这体现了推荐系统在当前消费互联网领域的普遍应用,以及消费者的有限注意力。作者证明,厂商有动机承诺不进行价格歧视,但非歧视定价反而有损消费者福利——原因是如果有价格歧视,消费者可以用信息披露影响价格,而没有价格歧视,消费者只能披露更多信息以换取准确推荐。如果消费者能预先承诺保留一部分信息,能改善自身处境。 2.行为理论 数据要素市场化的一大应用场景是消费者出让个人数据,换取消费互联网平台的更好服务。此时,对消费者偏好和理性程度的刻画成为评判数据市场社会福利的重要出发点。Liu et al.(2020)考察了当一部分消费者存在弱自我控制,容易受广告诱惑购买成瘾品时的个人数据交易问题,证明存在成瘾消费时,任何消费者向平台分享个人数据的行为都可能导致商家向低控制力消费者推送成瘾品广告的成本降低,从而损害社会福利。 具体设定如下:一个数字化平台服务一单位连续统消费者。平台可以搜集消费者的数字足迹,形成关于消费者偏好的有用信息。平台上有两个消费品卖家,分别出售两类消费品,一类是正常品A, 一类是成瘾品B。三类消费者{S,W,O}比例分别为πS、πW和1-πS-πW。分别代表强自制力、弱自制力和其他人。强自制力消费者永远不会购买成瘾品,弱自制力消费者在一定条件下会买成瘾品,第三类其他人则两种消费品都不买。根据行为经济学对成瘾品消费和自制力的建模思路,消费者的选择可以分为两步:第一步,消费者从一个菜单的集合中选择最优菜单;第二步,消费者从最优菜单中选择最终消费品。 Liu et al.(2020)捕捉了现实中个人数据要素市场化的一大特征:即互联网用户存在较大差异和分层。且互联网平台的营收,较多依赖于短视频、网页游戏甚至网络赌博等成瘾品销售。评估个人数据市场化的福利效应,不可忽视行为效应。 3. 机制设计 现实中,数据要素市场化不一定通过消费者-互联网平台交易或数据商交易的形式进行,传统行业生产过程和数字新基建中所产生的大量有用数据可以通过应用机制设计理论,设计社会有效或卖家收益最大化的机制,实现数据要素市场化。 数据要素深度嵌入当今中国经济的现实问题,而解决这些问题需要根据现有经济学理论,结合中国实际,开展规范、扎实、全面的实证研究。 1.数据要素度量与生产率测算 准确度量数据要素存量、增量及其要素生产率,评估数据要素的宏观和微观经济价值,是数据要素研究和政策应用的重要议题。当前中文文献中有较多对于数字经济定义、数字经济度量的讨论,但缺乏对于数据要素及其相关变量测算的研究。研究者可以跟踪Jones and Tonetti(2020)、Veldkamp and Chung(2019)等框架,应用宏观经济增长模型,测算中国的数据要素及其生产率。 2.数字税征收与区域经济协调发展 当今中国,数字化平台经济蓬勃发展。但互联网平台的业务跨越地理界限,定价方式不同于传统行业(例如淘宝、美团等互联网平台普遍为消费者提供免费甚至现金补贴),生产和消费普遍位置脱节。因此难以核算附加值和利益的地理归属。借鉴Jones and Tonetti(2020)、Veldkamp and Chung(2019)等的宏观经济增长模型框架,以及现有文献中对数据要素微观市场价值的评估方法,可以开展中国各地区、各行业数据要素对平台经济营收贡献的实证研究,从而为全国统一的数字税征收开辟方向,促进区域经济协调发展。 3.隐私保护与数据交易 中国互联网消费者隐私保护意识较弱,且付费意愿低,因此“隐私换服务”类型的数据要素市场化交易盛行。借鉴现有关于消费者作为数据卖家的数据要素交易文献,对消费者隐私损失、成瘾品消费、付费意愿、隐私外部性等影响个人数据交易有效性的种种因素做出系统的实证评估,从而为设计有中国特色的个人隐私保护机制和个人数据交易机制提供思路。事实上中国互联网平台的丰富数据也为评估现实世界中的消费者隐私偏好提供了极大便利。Chen et al.(2021)就利用手机支付宝小程序数据,结合问卷调查,发现对隐私偏好更高的用户同时也对数字平台的服务依赖更高,从而为解释“隐私悖论”提供了新思路。 4.数据特性与平台反垄断 2020年以来,互联网平台反垄断成为热门的政策议题。众多文献已经指出,数据要素的规模报酬递增性是导致产业市场企业分化和平台垄断的重要因素。在设计反垄断制度时,必须考虑到互联网平台对用户数据的独占导致的反竞争效应,并设计合适的规制政策予以限制。同时,现有文献也多指出了数据要素存在非竞争性,因此设计强制性的数据分享政策不仅有利于反垄断,更有利于数据要素的充分利用。实证研究可以在数据要素的市场结构效应、反垄断政策的政策评估、数据要素在不同行业的市场价值和非竞争性效应评估等方面为互联网平台反垄断提供思路。
(二)数据要素交易机制
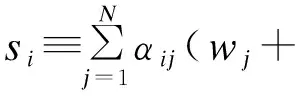
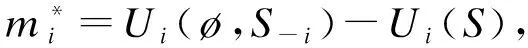

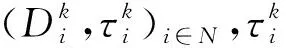
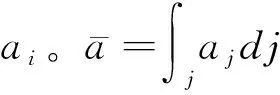
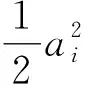
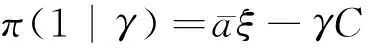
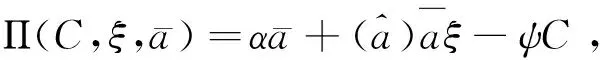
四、数据要素的经济价值与实证评估
(一)数据要素的经济价值
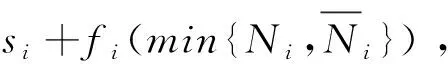
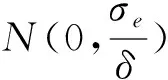
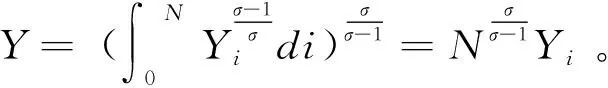
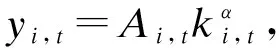
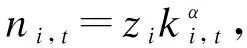
(二)数据要素经济价值的实证评估
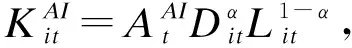
五、数据要素研究趋势与展望
(一)追踪学术前沿,创新理论工具

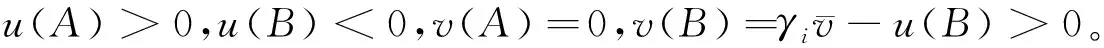
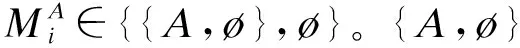
(二)聚焦中国问题,解决实证疑难
猜你喜欢
建材发展导向(2022年14期)2022-08-19
中外玩具制造(2021年2期)2021-02-07
当代水产(2020年4期)2020-06-16
新商务周刊(2018年20期)2018-12-07
汽车观察(2018年10期)2018-11-06
商情(2018年15期)2018-06-04
山东青年(2016年2期)2016-02-28
债券(2015年9期)2015-09-29
声屏世界(2015年2期)2015-03-11
商场现代化(2014年20期)2014-09-28
