
基于注意力机制的细粒度图像分类算法
2021-12-17 05:23杨丹蒋勇曾芳文帅
西南科技大学学报 2021年1期
杨 丹 蒋 勇 曾 芳 文 帅
(西南科技大学计算机科学与技术学院 四川绵阳 621010)
与普通图像分类不同,细粒度图像分类对同一类目标物体进行更细致的类别分类,比如分类车的款式、鸟的品种、方便面的品牌等,是计算机视觉的一个热门研究领域[1]。
有效定位目标物体的局部有区别性区域是细粒度图像分类亟待解决的主要问题之一。目前存在两种捕捉图像中目标局部区域特征的方法:(1)借鉴目标检测思想,先检测目标位置再分类。基于目标检测框架R-CNN,Zhang等[2]提出了Part-based R-CNN方法,使用Bounding Box标注框训练模型。首先在输入图像上通过自底向上的选择搜索算法产生候选框,然后使用R-CNN算法检测产生的候选框并评分,最后筛选出这些区域并提取特征进行分类。为了解决同一目标物体在不同姿态或不同拍摄角度下存在巨大差异的问题,Branson等[3]提出了Pose Normalized CNN方法。首先使用Deformable Part Model算法对输入图像进行局部区域位置检测,完成目标物体的局部区域定位,然后将检测到的区域裁剪下来进行姿态对齐,最后提取对齐后的图像的不同层的特征,将所有特征拼接起来训练线性支持向量机分类器完成分类。以上方法属于强监督学习方式,需要用到耗时耗力且成本高的人工标注信息,在实际应用中无法满足要求。(2)在卷积神经网络中引入注意力机制。Liu等[4]利用基于强化学习的视觉注意力模型定位物体的局部区域,首先使用全卷积网络提取特征,然后在特征图上生成多个部件的得分图以完成定位,从而更好地完成局部区域定位与分类。Fu等[5]提出了一种递归注意卷积神经网络(RA-CNN),该方法以相互增强的方式递归地学习局部区域和基于区域的特征表示。此类方法属于弱监督学习方式,仅靠图像类别标签完成分类从而节省了研究成本。
细粒度图像分类的另一个关键问题是图像特征信息表达不全面。受特征融合的启发,Lin等[6]提出了一种双线性模型B-CNN。此方法使用两个神经网络并行工作提取特征,然后融合两个特征,以构成表达图像信息能力强的特征。然而,B-CNN模型在进行特征提取时没有更好地获取局部显著特征从而影响了分类效果。由此,本文提出了一种基于注意力机制的改进双线性算法。该算法在特征提取器中加入了注意力模块CBAM[7],使局部区域特征显著利于分类。为了防止过拟合,本文采用了数据增强扩大训练集,使得算法有更强的适应性和迁移性。通过在CUB-200-2011数据集和Stanford Cars数据集上进行实验并与多种先进的算法比较,验证了改进算法的有效性。
1 基于注意力机制的B-CNN细粒度图像分类算法
1.1 双线性模型B-CNN
双线性模型B-CNN(Bilinear CNN)是由Lin等[6]从特征表示的研究点出发提出的一种用于细粒度图像分类的新颖网络模型,在公共数据集CUB-200-2011上识别精度达到了84.1%。B-CNN模型的网络结构如图1所示。该模型使用两个卷积神经网络作为特征提取器并行工作,输入图像分别进入到两个网络中得到图像的特征表示,然后将两个神经网络最后一层的图像特征做克罗内克积操作(矩阵外积),得到一个高维双线性特征向量,最后使用全连接层训练特征向量完成最后的分类工作。该模型能够在只有图像标签的情况下进行端到端的训练。

图1 B-CNN网络结构图Fig.1 B-CNN network structure diagram
用于细粒度图像分类的B-CNN由四元组B组成:B=(fA,fB,P,C),fA和fB是特征提取函数,P是池化函数,C是分类函数。
特征提取函数f(·)是一个特征映射函数,映射关系表示为f:L×I→Rc×D,I表示输入图像,L表示位置,Rc×D表示大小为c×D维特征。具体来讲,将输入图像I和图像对应的位置L通过特征映射函数(特征提取器)映射为一个大小为c×D维的特征,然后在特征的每个位置使用矩阵外积操作将特征汇聚成一个双线性特征,即位置l的fA和fB的双线性特征组合式为:
Bilinear(l,I,fA,fB)=fA(l,I)TfB(l,I)
(1)
为了获得双线性特征向量,使用池化函数P汇聚图像所有位置的双线性特征,得到表示全局图像Φ(I)的双线性向量,表达式为:
Φ(I)=∑l∈LBilinear(l,I,fA,fB)
(2)
如果fA和fB提取的特征图大小分别为C×M,C×N,则Φ(I)大小为M×N。再通过将Φ(I)重整为MN×1的双线性向量,最后使用分类函数C对双线性向量进行分类预测,这里采用的分类函数是Softmax。
1.2 注意力机制
近年来基于注意力机制的思想被广泛应用到深度学习的各个领域,因此注意力模型已经成为深度学习中炙手可热的研究点。注意力机制借鉴了人类视觉机制的思想,即通过快速扫描全局内容,获得需要重点关注的区域,然后对重点区域投入更多的精力进行处理以得到目标的细节内容。
在图像分类中注意力机制又分为硬注意力和软注意力两种。硬注意力通过对图像目标进行裁剪放大再裁剪,从而将一个目标放大到局部区域以获得部件的细节信息。使用硬注意力的代表文献包括文献[5]和文献[8],其中文献[5]利用互相强化的方式由粗到细的迭代裁剪以生成区域注意力,在训练过程中逐渐聚焦到关键区域;文献[8]使用Selective Search算法对输入图像生成候选框,此过程会产生许多含有目标的候选框,其中带有目标局部区域的候选框表示注意力区域,然后用谱聚类算法[9]将提取的特征分为K类,每类代表一个目标的局部区域位置,最后将每类的特征拼接成一个特征完成分类。
软注意力表示通过学习输入数据获得权重图。通过一系列学习得到的权重图即是注意力图,以文献[7]、文献[10]和文献[11]为代表。本文使用卷积注意力模块CBAM(Convolutional Block Attention Module),它属于软注意力。CBAM是一个完整的网络结构,该算法将注意力同时运用在通道和空间两个维度上,并直接嵌入神经网络以提升网络的特征提取能力。CBAM的网络结构如图2所示,其过程可以由下式描述:

图2 CBAM网络结构图Fig.2 CBAM network structure diagram
F′=MC(F)⊗F
(3)
F″=MS(F′)⊗F
(4)
其中:F∈RC×H×W是大小为H×W的C维输入特征;MC∈RC×1×1大小为1×1的C维通道注意力图;MS∈R1×H×W大小为H×W的空间注意力图。
通道注意力的计算公式如下:
MC(F)=σ(MLP(AvgPool(F))+
MLP(MaxPool(F)))
(5)
空间注意力MS(F)的计算公式如下:
MS(F)=σ(f7×7([AvgPool(f);
MaxPool(F)]))
(6)
其中:σ表示Sigmoid激活函数;MLP表示多层感知器;f7×7表示卷积核为7×7的卷积运算。
1.3 引入注意力机制的B-CNN
为了让双线性模型提取更充分的局部特征而达到更好的分类效果,在特征提取器中加入注意力模块CBAM,改进的B-CNN模型结构如图3所示。加入的注意力模块使特征提取的能力更强,特征能够较强地表达图像信息,因此分类效果得到了很大的提升。
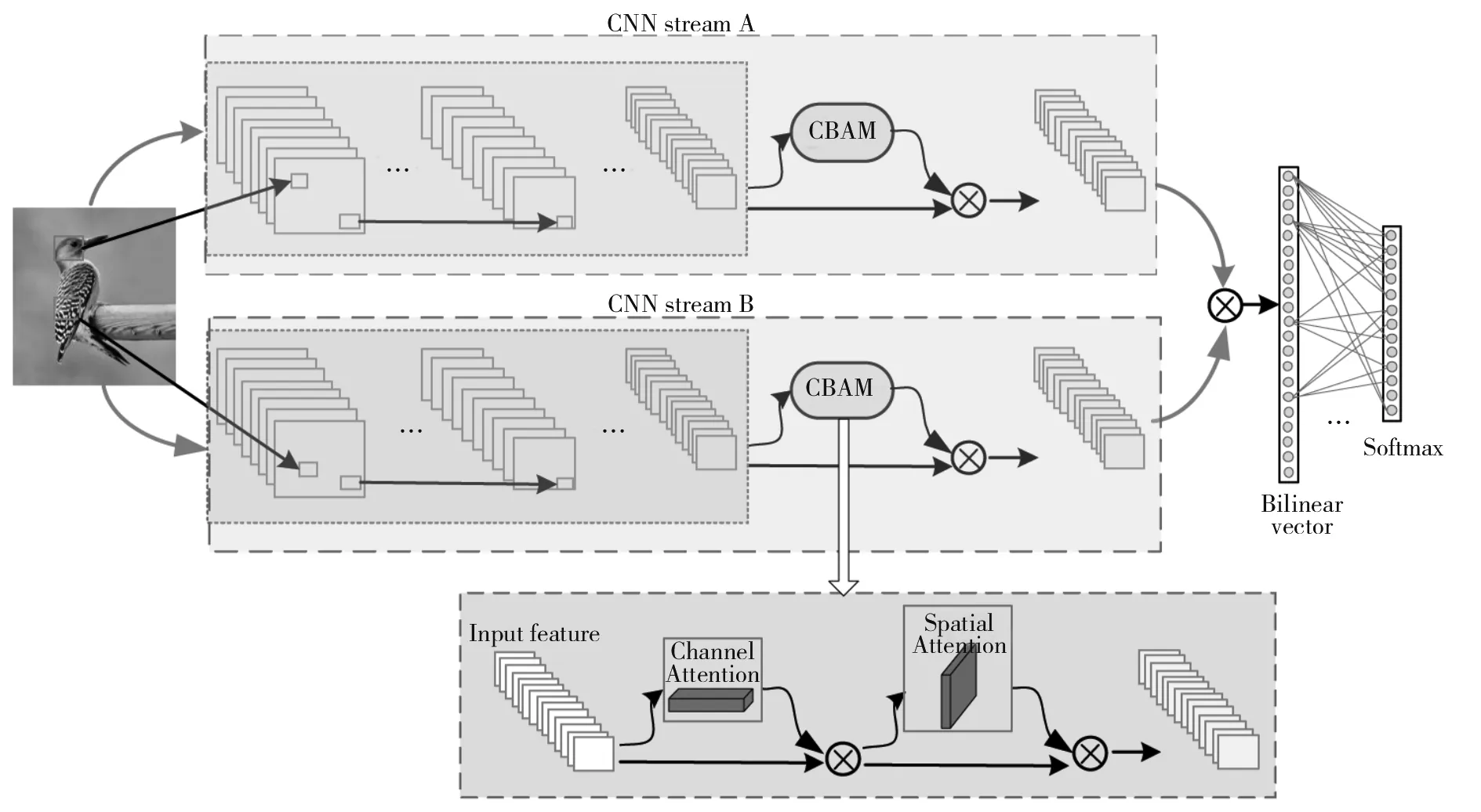
图3 改进的B-CNN模型网络结构图Fig.3 Improved B-CNN model network structure diagram
本文改进的注意力双线性网络是在两个特征提取VGG-16的最后一个卷积层的后面加入注意力模块,通过学习权重获得图像中重要信息以增强最后一层提取的特征,再对上下两路网络得到的特征进行融合,最后进行分类。
2 实验
2.1 实验数据集
在CUB-200-2011数据集和Stanford Cars数据集上进行实验,验证本文算法的有效性。CUB-200-2011是加州理工学院在2010年提出的用于细粒度图像分类的公共数据集,该数据集包含200个类别,其中共有11 788张鸟类图片,用于测试和训练的图片分别有5 794张和5 994张。Stanford Cars数据集是一个汽车类别数据集,该数据集包含196个类别,共计16 185张图像,其中训练集和测试集分别为8 144张和8 041张车辆图片。
在神经网络中训练数据过少容易造成过拟合导致模型的分类效果不佳,因此需要大量数据训练网络模型。本文采用数据增强的方法扩大训练数据来提高模型的识别性能。这里以CUB-200-2011数据集为例详细描述数据增强操作。CUB-200-2011训练集从原来的5 994张图片扩大到了27 800张,每类从30张扩到139张图片,实验中数据增强方式有以下几种:(1)随机水平翻转(左右翻转),随机概率为0.4;(2)随机垂直翻转,随机概率为0.8;(3)随机90度旋转,随机概率为0.1;(4)随机裁剪,随机概率值为0.5,裁剪区域值为0.7;(5)随机加亮度,最大亮度倍数为1.4,最小亮度倍数为0.6;(6)随机放大图片按照设定的范围值裁剪,随机概率为0.4,最大裁剪倍数为1.6,最小裁剪倍数为1.1。数据在增强过程中随机组合上述操作生成增强图片,将增强图片调整为448×448的同一尺寸,并按本文实验输入数据的需求格式制作数据集。在增强过程中放大裁剪操作能够有效去除部分背景,使图像在网络中能更准确定位目标的局部区域。如果背景复杂则关注点在目标整体,若去除背景则可以关注到局部区域更好完成分类。图4为部分增强裁剪操作后的示例,其中第一行表示原始图像,第二三行表示数据增强操作后的图片。

图4 原图和增强后图片示例Fig.4 Examples of original and enhanced images
2.2 实验环境与过程
本文实验硬件环境为:Ubuntu 18.04操作系统,处理器为Intel® Xeon(R) E5-2650 v4@2.20 GHz×48,显卡为TITAN V,显存12 GB,使用Spyder编辑器在Pytorch框架下实现。
在实验过程中使用预训练参数初始化模型能够使模型收敛更快,因此主干网络提取特征时使用 VGG-16在ImageNet上的预训练参数。本文在特征提取器VGG-16的最后一层添加注意力模块,且注意力模块随机初始化参数。
本文实验分两步:第一步,将数据集输入到网络中,使用VGG-16预训练参数初始化网络,固定注意力模块前的卷积层参数,只训练注意力模块和全连接层以得到模型的最优参数;第二步,使用模型最优参数初始化网络,微调所有层得到最终模型的分类精度。由于使用全连接层分类需要限制数据输入的大小,实验中数据输入网络后统一调整为448×448,采用带有动量为0.9和权重衰减系数为0.000 01的SGD优化器。
2.3 评价指标
本文实验以精度(Accuracy)为评价指标,计算公式如下:
(7)
其中:Accuracy 表示图像分类的精度;TP表示分类正确的图像个数;FP表示分类错误的图像个数;Accuracy值越大表示图像分类模型的分类效果越好。
2.4 数据增强和注意力模块的有效性验证
为了验证数据增强和注意力模块的有效性,本文在CUB-200-2011数据集上分别做了B-CNN +数据增强(B-CNN + Data),B-CNN + 注意力模块CBAM(B-CNN + CBAM)和B-CNN +数据增强 +注意力模块CBAM(B-CNN + Data + CBAM)的实验,实验结果如表1所示。
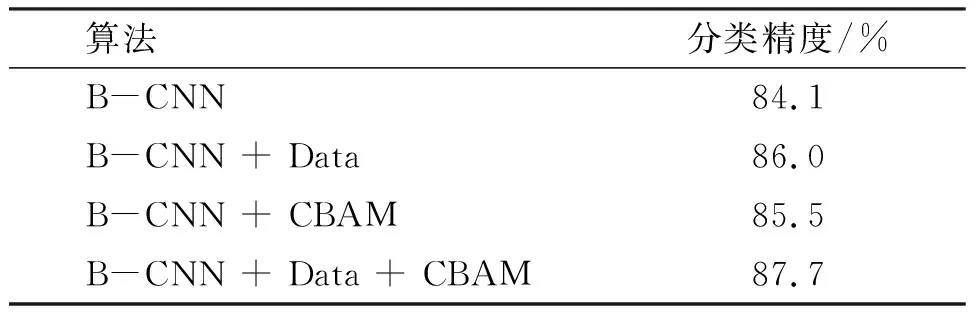
表1 数据增强和CBAM模块有效性验证Table 1 Data enhancement and CBAM module validation
从表1可知, B-CNN和B-CNN+ Data相比较,数据增强能提升算法的泛化能力,它通过扩充数据的相关特征,使得数据信息量更丰富进而提升算法精度。B-CNN和B-CNN + CBAM比较表明,注意力机制对算法的提升有促进作用,注意力机制能够最大限度地学习图像的特征信息,可以使网络模型对图像的显著特征重点关注。由B-CNN+ Data和B-CNN + CBAM可知,数据增强和注意力机制均能提高分类精度,数据增强能直接增强数据的相关特征从而提升算法性能,而注意力机制依托原始数据学习数据的重要特征信息提升算法效果。由B-CNN + Data + CBAM可知,在数据增强的基础上添加注意力机制不仅能增强数据的相关特征,还能充分利用这些特征从而提升算法的分类效果。
2.5 实验结果与分析
为了验证本文方法的有效性,将本文方法与目前细粒度图像分类领域的先进方法Cross-X[12],NTS-Net[13],MC-Loss(B-CNN)[14],SEF[15],A3M[16]进行对比。在数据集CUB-200-2011上的实验结果如表2所示。

表2 不同算法在CUB-200-2011数据集上的分类精度Table 2 Classification accuracy of different algorithms on the CUB-200-2011 dataset
从表2可知,本文算法的精度均比其他算法高。在CUB-200-2011数据集上精度达到了87.7%,超越了其他5种方法,与Cross-X算法效果一样。为了验证本文算法的通用性,在Stanford Cars数据集上进行实验,结果如表3所示。从表3可以看出,本文算法在Stanford Cars数据集上仍然能取得较好的效果,在Stanford Cars数据集上精度达到了93.1%,超越了其他5种算法。上述表中其他算法的分类精度值来源于原文章。

表3 不同算法在Stanford Cars数据集上的分类精度Table 3 Classification accuracy of different algorithms on the Stanford Cars dataset
实验证明数据增强与注意力模块能够明显提升分类精度,有注意力模块的网络能够最大限度地学习到图像的特征信息,所以图像更容易被分类正确。此外数据增强将图像丰富化,特别是剪裁操作能够降低部分背景因素导致的分类效果不佳的影响。
3 结论
本文对双线性网络(B-CNN)算法进行改进,利用注意力模块CBAM实现了一种基于注意力机制的双线性网络。首先对数据集进行增强以丰富数据,然后将数据送入改进的网络进行分类。在CUB-200-2011数据集和Stanford Cars数据集上与目前先进的细粒度图像分类算法进行比较,结果表明本文提出的算法能较好捕捉图像局部区域,从而实现了更好的细粒度图像分类效果。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
成都信息工程大学学报(2021年3期)2021-11-22
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
第二课堂(课外活动版)(2016年2期)2016-10-21
少儿科学周刊·少年版(2015年3期)2015-07-07
意林(2011年10期)2011-05-14
