
面向学术论义创新内容的知识图谱构建与应用
2021-12-21 13:58曹树金赵浜
现代情报 2021年12期
曹树金 赵浜






DOI.10.3969/j.issn.1008-0821.2021.12.003
[中图分类号]G250.2 [文献标识码]A [文章编号]1008-082l(2021)12-0028-10
知识图谱技术]作为人工智能领域的重要分支,于2012年被Google公司提出后迅速发展,实践成果丰富,已成为目前最高效的知识表示和组织形式之一。知识图谱本质上是以图这种基本结构类型归纳信息的数据表示形式,它是实体和关系构成的大型网络,与特定领域或组织有关。现有许多前沿知识图谱项目,例如DBPedia、YAGO、XLORE都是从维基百科、百度百科等开放数据源中抽取实体和关系而构建的。
知识图谱在学术领域也有广泛应用,典型的包括Microsoft Academic Graph、Springer Nature SciGraph、AMINER(aminer.org),它们主要包含诸如作者、科研机构、研究主题和引用的实体及其之间的关联信息,为学者进行科研关系网络的梳理提供了巨大便利。然而,它们的主要局限性是:上述关联关系都是和学术论文相关的粗粒度信息,而且它们通常将论文的内容表示为非结构化文本(标题、摘要或是全文),没有对论文内容进行更细粒度的抽取和组织,因而无法对知识内容的脉络(如理论发展路径)进行有效梳理。而论文的具体内容才是知识的核心载体。因此,这个领域的一个重大挑战是如何将学术论文中所表述的知识以图谱的形式组织并显陛地表示出来,以描述诸如研究方法、理论模型及影响因素、理论应用及学术贡献等有价值的知识实体及其之间复杂的关系。目前,抽取学术论文中知识实体以及论文中知识实体的关联,乃至论文间知识实体的关联.并以此构建知识图谱的研究较少。
国家标准将学术论文定义为:“学术论文是某一学术课题在实验性、理论性或观测性上具有新的科学研究成果或创新见解的知识和科学记录:或是某种已知原理应用于实际中取得新进展的科学总结”。由此可见,学术论文的价值主要体现在其所提出的新方法、新理论、新应用等创新贡献。将论文中的创新内容进行多粒度关联,通过对创新内容的分解与重组,并用于创新知识图谱等应用的实现具有可行性和巨大潜力,可以为科研用户提供有力支持,助力学术创新。在此背景下,本研究提出构建面向学术论文创新内容的知识图谱的新命题.旨在探索构建可以描述深层次论文内容及其关联的知识图谱,既为学术论文中创新情报的发现和组织提供工具,也为学术领域知识图谱构建的由广入深提供示例。
1相关研究
知識图谱的构建按知识获取的过程可划分为信息抽取、知识融合与知识加工3个层次。其中信息抽取的核心为命名实体识别、属性识别和关系识别,是图谱构建的基础环节;知识融合的关键是命名实体消歧和共指关系消解,是进行实体间有效关联的必要前提:知识加工的主要工作是本体构建与知识推理。
3个层次的研究都有出色的进展。在信息抽取方面,部分研究成果针对知识元素(实体、关系、属性)的抽取技术与方法,在限定领域、语言、主题的数据集上获得了较好的效果,同时尚存限制条件多、扩展性不好的问题。特别地,在生物与医学领域,命名实体与关系识别模型算法均有着良好的识别性能。而在情报学领域,由于学科本身的交叉融合性,研究会天然地涉及众多学科领域,因而针对情报学相关学术论文的知识元素抽取是一项很大的挑战。郑彦宁等探讨了信息与知识抽取技术在情报学中的难点与应用价值;王昊等应用Bi-LSTM-CRFs模型进行大规模语料训练与测试,探寻较优的情报学理论与方法术语识别效果。针对理论术语的识别,赵洪等提出了一种深度学习自训练算法以实现模型的弱监督学习,为理论术语抽取提供了有效方法;周萌等基于文本内容细粒度共现关系的抽取,揭示具体领域的整体、微观知识结构和知识演化情况;陈锋等验证了CRF模型配合词典法自动识别学术期刊中的理论的可行性,但选择语义特征、语义标注和语义消歧是需要解决的新问题。在知识融合方面,实体消歧从传统的规则匹配到统计、再到深度学习,有效的消歧模型往往整合了不同类型方法,以达到最优消歧效果。实体链接和跨语言知识库对齐是知识融合的重要手段,清华知识工程实验室构建的XLINK系统在这方面取得了一定的进展。另外,结合众包平台与知识库对齐模型可以有效地提高知识融合的质量。同样的,在知识加工方面,集成学习的知识推理效果要好于单个模型的知识推理;融合了领域主题词表与网络百科知识库的两阶段领域本体自动化构建方案在大规模领域本体构建时是可行有效的。
面向学术科研领域,学者们在进行着知识图谱构建的积极探索。Zhao H X等基于TextCNN的主题信息抽取模型,自动抽取文献主题、标题、状态、会议、组织机构等信息,构建技术领域知识图谱。李肖俊等从多源异构学术数据中进行学术实体及关系的抽取,提出适用于学术领域的图谱构建流程和本体模型。李娇等采用自顶向下的方式,通过主题词关联设计,构建了包含期刊论文、期刊、科研机构、科研人员及专题实体类型的科研知识图谱。张云中等从多源数据整合的视角,构建了可供知识问答的图情学术领域知识图谱。然而,诸多探索仍是将图谱定位于学术论文本身粗粒度信息的关联,少有研究从进一步挖掘论文中表述的更有价值的知识内容及论文中知识内容的关联,乃至论文间知识内容的关联的角度构建知识图谱。
创新l生是决定论文学术价值的内在依据,因此论文创新点也是挖掘论文中具有核心价值知识内容的关键切入点。针对论文创新内容的识别,精细化的语义识别与分类方法,规则抽取结合BERT深度学习模型,以及主题词表结合ALBERT深度学习模型等研究已取得一定的进展。笔者研究团队在此方面也进行了一定的探索——以情报学期刊论文为例,以创新对象和创新维度为线索,基于BERT深度学习模型识别表述学术论文创新内容的句子,并构建了检索入口。
综上,本研究将基于团队现有研究成果,进一步深入挖掘论文创新内容中蕴含的有价值知识实体以及知识实体间的关联.构建面向学术论文创新内容的知识图谱。
2知识图谱构建的研究设计
2.1研究基础
本研究基于部分现有研究成果:在对论文创新性特征识别归纳的基础上,以情报学期刊论文为原始语料,分别训练BERT语言模型抽取论文创新句。具体为:《数据分析与知识发现》(原《现代图书情报技术》)2009—2019年发表的1667篇文献中,抽取到的4518个创新句;《情报科学》2009—2019年發表的3793篇文献中,抽取到的5181个创新句。以此为语料基础,深入挖掘分析其中蕴含的创新内容,包括理论、方法、模型等实体及其之间的关联关系。
2.2知识图谱构建模式
知识图谱由本体模型和实体数据构成,前者是后者的上层抽象与约束,后者是前者的具体对象,是图谱的具体呈现。根据两者的构建次序,知识图谱可分为自顶向下和自底向上两种构建模式。通常在知识体系和数据情况完备的情形下,采用自顶向下的模式,即先从高质量数据中提取本体和模式信息,再将实体数据加入知识库中;而自底向上则是在面向开放的数据源以及没有系统知识体系的情形下,先抽实体再构本体的模式。两个模式并不互斥,实体和本体会随着其反映的世界的变化而拓展与变化,知识的融合与更新也是一个持续迭代的过程。在学术领域,科学研究处在动态变化中,知识体系也随之不断地发生变革。因此,本研究将融合两种模式,构建面向学术论文创新内容的知识图谱。
2.3研究方法与框架
知识的表示是一项复杂的任务。秦春秀等从文献的内外部特征,构建了面向科技文献知识表示的知识元本体模型,将创新点分为理论创新点、方法创新点和技术创新点。闫欣阳基于创新句的词频分析将论文的创新对象分为模型、方法、算法等10种。而针对理论,Pettigrew K E等将模型、框架、概念等对某种观点或理念的描述等同于理论的描述。由于知识体系的庞大以及描述形式的复杂多样性,知识本体的构建也是一项复杂的任务,因此,不妨针对具体语料,由关键对象入手。
2.3.1基于词频以及互信息和左右信息熵的关键对象分析
互信息和左右信息熵可以有效地发现新词和短语,也经常用于搜索引擎的自动推荐,是一种挖掘所关注领域关键信息的有效手段。
互信息(Mutual Information)是指两个事物集合之间的相互依赖程度,在文本处理中,词的互信息指两个词的相关程度,可以用式(1)来计算:
其中P(X,Y)是字符X与字符Y组合起来的字符在文本中出现的概率;P(X)是字符X在文本中出现的概率;P(Y)是字符Y在文本中出现的概率。互信息值越高,表明X和Y相关性越高,则X和Y组成短语的可能性越大;反之X和Y之间相关性越低,X和Y之间存在短语边界的可能性越大。
熵是表示随机变量不确定性的量度,熵越高就意味着不确定性越高,越难以预测。左右信息熵是通过计算一个字符片段左边和右边的信息熵,来反映一个词是否有丰富的左右搭配,以致是否达到一定阈值而形成一个新词。左右信息熵如式(2)、(3):
基于关键词频以及上述互信息、左右信息熵的简单求和,对语料基础进行初步分析,得出创新的关键对象,以此作为预构建本体的重要参考。
2.3.2基于ALBERT模型的知识实体抽取
ALBERT,即“A Lite”Version of BERT,是基于BERT模型的一种轻量级预训练语言模型。AL-BERT保留了BERT的模型结构,并在此基础上加入了3种改进策略:针对嵌入矩阵的分解式嵌入参数(Factorized Embedding Parameterization)、针对所有层的跨层参数共享(Cross-layer Parameter Sha-ring)、面向语句顺序预测的句间连贯性损失(Inter-sentence Coherence Loss)。使其有参数更少、训练更高效的优势,预训练小模型也能获得甚至超越BERT的性能。本研究预调用由Google提供的al-bert_base_zh中文语料,其参数量以及模型大小均为bert_base的1/10。同时,基于已获得的创新关键对象,进行实体类型的训练语料标注以及模型训练与调优,随之进行知识实体抽取。
2.3.3语义分析与图谱构建工具
语义分析目前已有许多成熟的工具可供选择,本研究选用完全开源的HanLP自然语言处理工具包。它基于PyTorch和TensorFlow 2.x双引擎,借助世界上最大的多语种语料库,可以完成中文分词、词性标注、命名实体识别、依存句法分析等多种自然语言处理任务,同时它的开源属性可便于学者和开发者进行必要的功能拓展。
针对知识图谱构建与可视化,本研究选用同样开源的SmartKG。它是一款由Microsoft开发的轻量级知识图谱构建与可视化工具,以属性图的方式存储实体节点和关联(Vertexes and Edges),并且实现了节点和关联的检索接口,以便在此之上开发上层应用,例如基于知识图谱的智能对话。
2.3.4知识图谱构建框架
与一般的知识图谱构建方案不同的是,本研究将本体构建的流程横跨整个知识获取的过程,并在知识实体抽取前加入关键对象分析这一图谱构建的预处理环节,使其带有一定的目的,使图谱更聚焦于想呈现的领域或关键内容,为知识本体的构建提供重要参考。本体从哲学角度看是对世界上客观存在及其关联的系统描述,从语言与计算机角度看是对某个领域甚至更广范围内概念及其之间关系的映射,并使之具有明确、一致的定义,以便人机以及机器间的交流。知识具有融合性,在考虑知识融合的过程中也会考虑本体的融合或者集成。知识图谱的构建并非一蹴而就,因而本体的构建与完善从某种程度上也可以被认为贯穿了图谱构建的始终。本研究采用的知识图谱构建框架如图1所示。
3知识图谱构建流程
3.1图谱构建的预处理——关键对象分析
利用Java环境下的HanLP自然语言处理框架,结合词频分析以及互信息和左右信息熵运算,对已经预先识别好的共计9699条论文创新句进行初步分析。首先得到词频数据(前10)如表1所示。
由上述词频数据可以得知,创新句子对模型的描述最为频繁,其次是方法。以上关键词包含了名词及动词。将二者结合,再进行互信息与左右信息熵的二元分析,得出结果如表2所示(已排除部分“动词+动名词”的无意义组合,例如“进行→分析”)。
上述结果中可以看出,创新句中对于方法和模型的确是最为关注的焦点,例如“分析→方法”“构建一模型”。由此可以将方法与模型作为本研究所欲呈现知识图谱的关键范畴。另外,虽然“提出→新的”与“提出→改进”对于关键对象的分析并没有实际意义,但是从侧面验证了本研究所基于的创新句的“创新性”。
以“模型”为例,进一步分析模型本体下可能关联的实体类型。部分结果如表3所示。
由上述结果可以看出.对模型的描述可以包含特征、情境、因素、指标等,其中“因素→模型”的频率较高,说明“因素”出现在“模型”附近的概率也较高,所以因素可当作构成模型本体的一种关键的实体类型。
3.2实体标注、模型训练与知识抽取
以预处理结果为重要参考,构建新的实体类型集合,其中包括基本理论、方法、模型、影响因素、特征指标、研究贡献。利用ALBERT深度学习模型,在Tensorflow_GPU1.15.0,CUDA10.0,Python3.7的系統环境下,进行实体标注、模型训练以及知识实体抽取。首先针对新构建的实体类型,对基于ALBERT的一般命名实体识别任务代码进行改造。本研究采用标准的BIO标注体系,即将每个元素标注为“B-X”“I-X”或者“O”。其中,“B-X”表示此元素所在的片段属于X类型并且此元素在此片段的开头,“I-X”表示此元素所在的片段属于X类型并且此元素在此片段的中间或结尾位置,“O”表示不属于任何类型。例如,将“X”表示为(Person,PER)人物,则BIO的3个标注为:B-PER(人名的开头),I-PER(人名的中间或结尾),0(不是名词短语)。针对标注改造的部分代码片段如图2所示。
本研究对9699条目标论文创新句随机选取480条作为标注对象。在albert_base_zh预训练模型的基础上继续进行模型训练。随后将余下的未标注语句导入模型中进行知识实体抽取,整理得到最终实体列表。
3.3实体关系梳理、实体消歧与知识融合
通过对知识实体的抽取,发现了不少熟知的理论模型,例如“信息系统持续使用模型”“期望确认模型”等,以及理论模型之间潜在的继承与发展关系。但在实体类型上存在一些分类的异议,本研究做了一些人为的评判与处理。例如:模型和理论之间本身就存在着概念的重合,上述“信息系统持续使用模型”与“期望确认模型”被训练过的AL-BERT识别为“模型”这一类型,而本研究人为地将这二者定为“基本理论”,因为二者影响深远,在他们基础上演化出了众多模型,不少创新是基于这样的“基本理论”实现的。针对继承与发展的关系,分析后可分为两种类型,一种是基于多个基本理论衍生出的另外一种模型,衍生的模型可能借鉴基本理论的相关影响因素,也可能借鉴基本理论的研究方法甚至是调查问卷的问项目或指标等,而这类模型和基本理论的应用方向又不完全一致;另外一种是基于一个基本理论派生出来的,新模型大多在基本理论基础上新增了影响因素甚至是新的维度,此类模型和基本理论的应用方向基本一致。基于此,本研究将理论模型问的继承发展关系定义为衍生和派生,这是从基本理论到新模型的关系方向:而将反向的相对应关系定义为使用和拓展。
抽取出来的理论、模型与方法有不少共指关系存在,例如“信息系统持续使用模型”与其对应英文简称“ECM-ISC”(Expectation Confirmation Model of IS Continuance),“德尔菲问卷调查”与“德尔菲法”这种不同的描述方式,以及“马尔可夫链”与“马尔科夫链”这种不同的译名。同一实体的两种不同表述出现在同个章节或句子时是一种共指消解问题,而两种表述出现在不同文献或数据源时准确说是一种实体对齐或者实体链接问题,它们针对的目的一致但处理方式是有所不同的,目前也没有统一有效的方法同时解决上述问题。本研究的处理方式为将所有表述(实体)都存储起来,并预先采用人工判断的方式为不同表述构建一个统一的实体,同时将其他同义实体与之在数据库层面建立一种指向的关联,最终使用统一的实体作为图谱中的真实节点。这样做有两个潜在目的:一是为以后针对更多数据源的实体抽取提供词典支持:二是为与其他知识库融合提供链接支持。
基于现有语料抽取到多数基本理论无法追溯到其文献源头,本研究采用人工采集的方式将相关实体信息补全至数据库。
3.4知识存储与图谱可视化呈现
本研究采用MongoDB作为数据库存储知识。MongoDB是一种基于分布式文件存储的数据库,以高拓展性和高性能的优势著称,作为NoSQL非关系型数据库的代表,多年以来在非关系型数据库的选择上都是业界最受欢迎的。实际上有部分大型知识库项目就是采用MongoDB作为存储的,进行适当的设计与改造后,MongoDB同样可以作为一种有效的图数据库使用。相比于更适合诸如最短路径、社区发现等图运算的以Neo4j为代表的图数据库,基于MongoDB构建上层应用系统会有更好的拓展性和适应性。
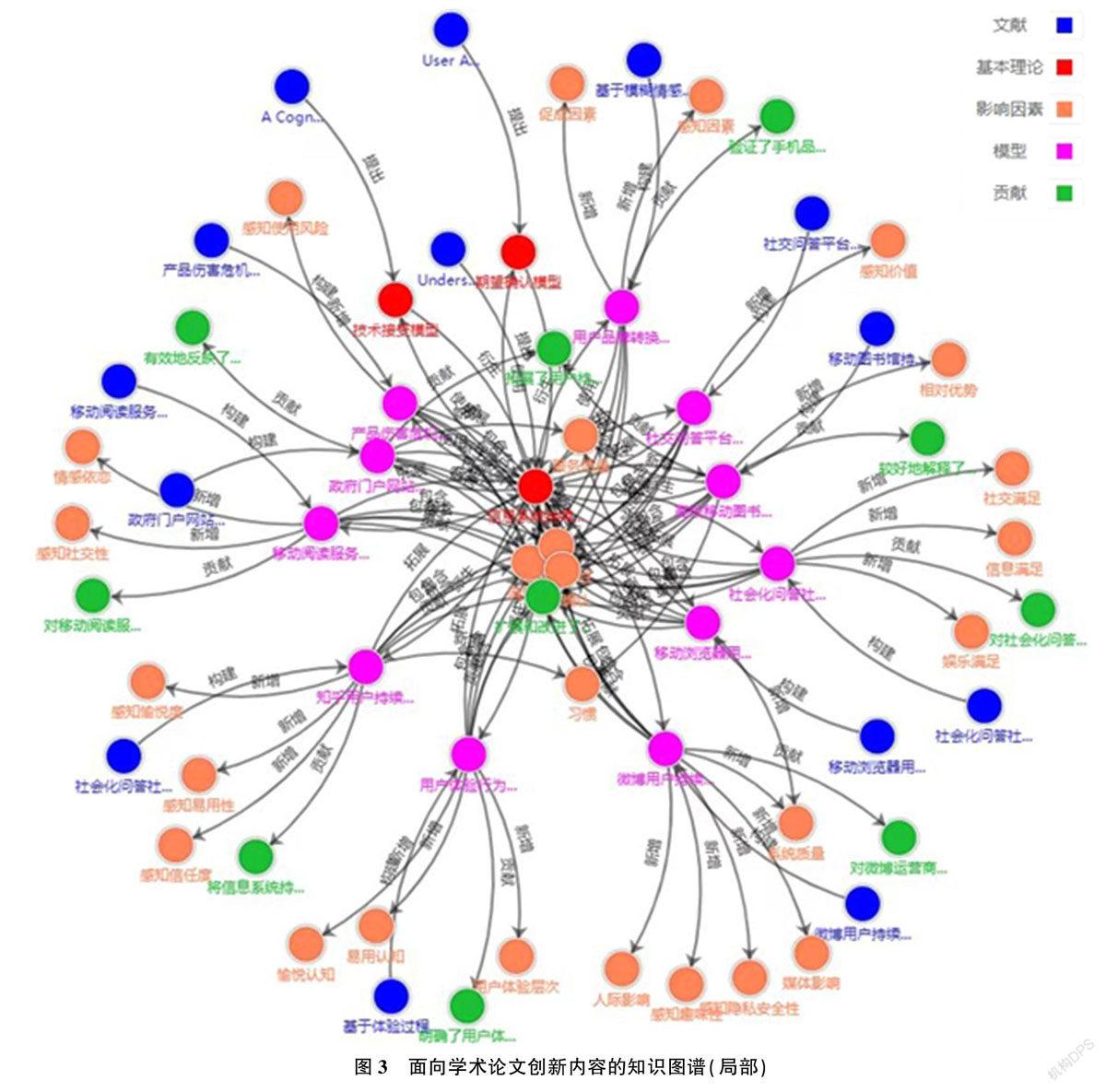
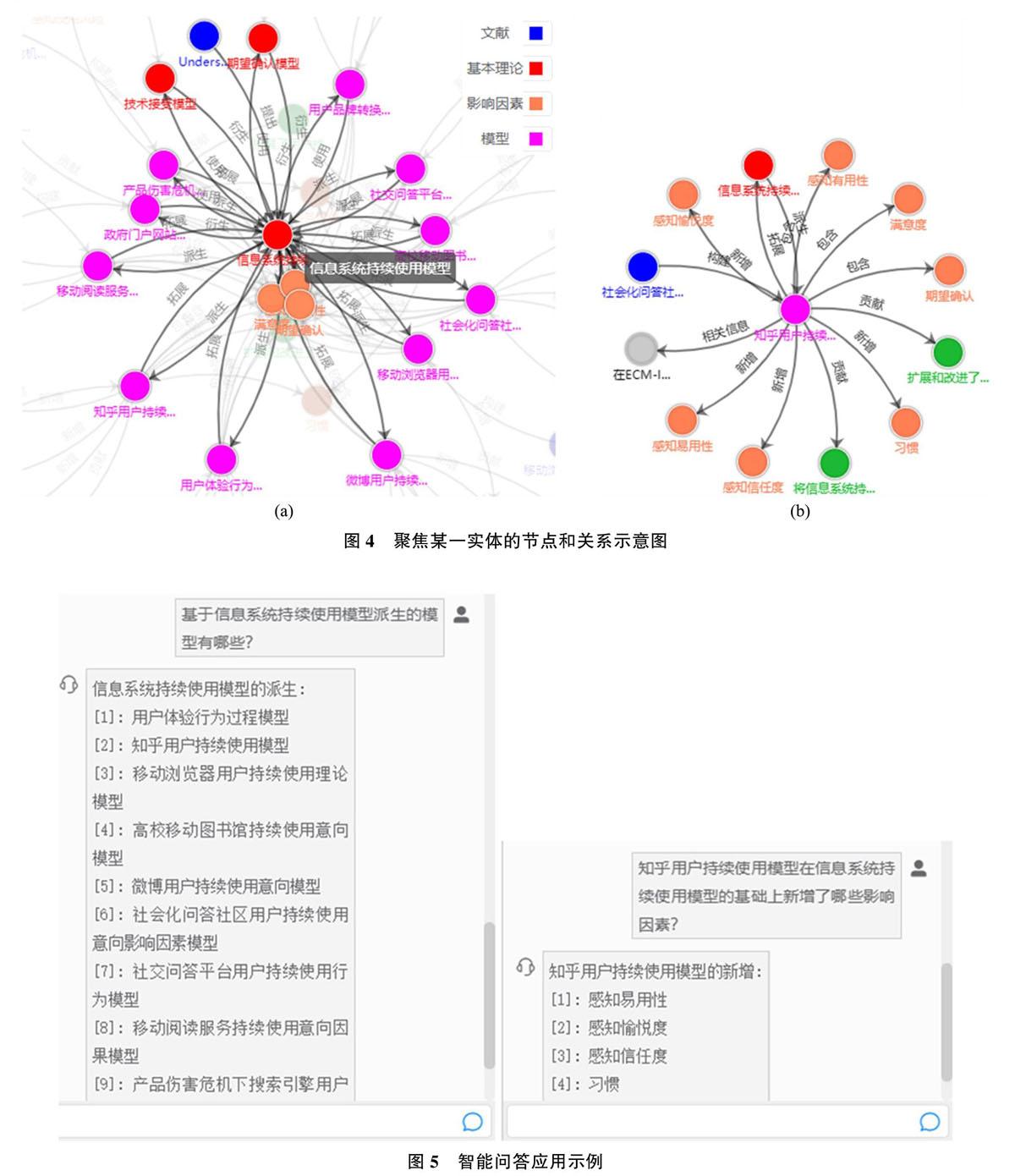
本研究将实体和关系以属性图的方式存储,属性图主要包含顶点(Vertex)和边(Edge)。相比于RDF三元组,属性图的结构更接近于图,也更利于图运算的效率。利用SmartKG,最终将存储的知识以图谱的形式呈现出来。图3为本研究所构建知识图谱的局部效果展示,呈现的基本内容为学术论文围绕“信息系统持续使用模型”展开的一系列理论与应用创新。图4(a)为聚焦于实体“信息系统持续使用模型”时呈现的与之直接相关的理论模型问的继承发展关系,包括“信息系统持续使用模型”自身的理论基础,以及在其基础上衍生派生的模型;图4(b)为展开具体的某一模型实体所呈现的信息,包括与该模型相关的文献、理论基础及新增的影响因素、理论与应用贡献等。
4知识图谱的应用
本研究基于学术论文创新内容所构建的知识图谱目前仅是一个雏形,未来将结合更多智能化手段实现当前流程中的人工处理环节,同时也将尝试与多种现有知识库的融合。在构建图谱的基础上,将在多个方向进行应用探索,以多种方式进行应用构建。
4.1语义搜索
Google提出知识图谱的主要目的就是为搜索引擎赋予更具智慧的思维,它将传统的搜索从Web链接转向概念链接,将搜索的原理从字符串的匹配转向主题和实体关联的匹配。通过对实体及属性的提取、同义拓展、关联推理等技术,可以实现更精准的语义关系判断,从而提供更符合用户搜索意图的结果。面向学术论文创新内容,可以搭建针对细粒度创新内容的检索系统,更加智能化地将搜索语句关联到论文创新点、创新句以及创新点对应的章节。同时,以语义搜索作为基础可为更复杂的应用如智能问答、推荐系统等提供服务支持。
4.2智能问答
通过对用户以自然语言提出的问题进行语法及语义分析,智能理解用户问题进而将其转化成结构化形式的查询语句,甚至是查询语句集,随后在知识图谱中高效检索其所需知识,并呈现最相关的答案。如图5所示,为本研究通过SmartKG实现的与理论发展相关的智能问答示例。如“某某理论模型派生的模型有哪些?”这类问题,智能问答机器人可以有效地回答基于这些基本理论而產生的理论创新有哪些。再如“某某模型在某某理论的基础上新增的影响因素”这类问题,同样可以有效得出这些新理论模型的具体创新点。目前的实现原理并不复杂,通过对问题语句进行分词和语义分析,提取出其中包含的实体与关系类型,并在图谱数据库中进行关联匹配与映射,输出对应的结果集合。
4.3推荐系统
从用户的角度,推荐系统是在信息过载情况下,解决高效获取感兴趣信息难题的重要工具。知识图谱可为处于推荐系统逻辑架构核心位置的推荐模型提供高效的运算支持,挖掘潜在关联需求并聚焦于关键数据。甚至可以为推荐理由进行可视化呈现,增强用户体验。在有了智能语义搜索服务的基础上,推荐系统可以根据用户的个性化设置以及系统活动记录,提取出用户阶段性的兴趣点,启发式地主动挖掘潜在“搜索语句”并呈现结果。比如推荐系统发现了用户对信息系统持续使用模型相关的创新很感兴趣,并检索了特别是问答社区这类平台的研究,推荐系统可以更加深入地纵向挖掘其中的实体关联,为用户提供更细致的研究进展,推荐系统也可以横向地挖掘该理论模型在其他类型平台或领域的创新,为用户呈现。
4.4知识发现
基于图数据结构,系统可以便捷地根据知识实体之间的关系,应用逻辑规则以及置信度评估知识的合理性,并通过知识图谱的自动构建、知识更新以及知识推理技术,实现从非结构化文本中提炼潜在知识,即知识图谱内逻辑规则的推理,甚至是知识实体之间缺失关系的补全,从而挖掘出以往未得到的新知识。以上述智能问答应用示例中的问题领域为例,对基本理论演化出的众多新模型中各自新增的影响因素在模型间进行相互对比,分析其语义问的异同,就可以挖掘出哪些因素可能被重复新增,哪些因素最具独特性,甚至以此可以推测出新模型的创新性指标。
4.5科研成果评价
通过对学术论文创新内容与研究贡献的抽取与图谱构建,可以有效关联学术论文中具有核心价值的知识内容,以及不同相关论文间理论与应用的发展脉络与创新程度,为科研成果的质量评价提供重要参考依据。将对树立以创新质量为导向的学术氛围、对“破五唯”进展起到积极推动作用。
目前,团队已经初步完成了面向学术论文创新内容的语义搜索与智能问答的简易实现,日后将进行更加细致的功能分析和更完善的系统构建,并以此为基础,进一步结合用户情境以及适当的规则机制,开展推荐系统、知识发现乃至科技成果创新评价等方面的研究。
5结论与展望
从论文内具有核心价值的创新内容中挖掘知识与知识问的关联,对于各领域的科学研究都有重要意义。本文从挖掘情报学领域的部分期刊论文的创新文本内容入手,结合多种语义分析方法、深度学习模型以及业界先进经验,构建面向学术论文创新内容的知识图谱,为可以描述深层次论文内容及其关联的知识图谱构建探索合理的切入点,并探讨及构建与之相关的实际应用。研究得出以下主要结论:
1)为构建面向学术论文创新内容的知识图谱,不拘泥于自底向上或是自顶向下的单一图谱构建模式,并利用互信息与左右信息熵,在实体抽取之前加入关键对象分析这一知识图谱构建的预处理环节,可有效地挖掘具体领域的关键范畴,为知识图谱中的本体初步构建提供重要参考。
2)知识图谱的构建需要采用多种技术工具与模型,本研究成功结合HanLP与ALBERT,Smart-KG与MongoDB等,构成了创新知识图谱的核心技术框架:同时,在完成论文创新内容实体问关系识别等复杂任务时,进行必要的人工分析和干预能够使构建的知识图谱更具逻辑性与拓展性,可为进一步的知识融合创造便利条件。
3)基于学术论文创新知识图谱,可以进一步开发面向论文创新内容的多粒度语义检索、智能问答、智能推荐、知识发现乃至创新性评价等系统或功能。
然而目前的研究仍有局限:①知识实体关系的抽取和实体消歧的工作依赖人工的分析处理,且实体属性的抽取并未深入进行:②对某些具体理论模型影响因素的抽取识别并不精准,特别是基于多个理论衍生出的新理论:③所选基础语料数据来源单一。
未来的研究希望可以加大智能化图谱构建相关技术的结合:深入探索本体构建与图谱构建在不同环节的相互影响,以求为知识的融合与更新过程提供更合理的机制:继续深挖基础语料的其他非关键知识实体,并尝试融合更多领域的创新内容文本数据源,拓展面向学术论文创新内容的知识图谱:另外,尝试融合现有的以文献、作者、研究主题、科研机构为主要实体的学术知识图谱,真正实现学术领域知识图谱的由广入深。
(责任编辑:孙国雷)
猜你喜欢
系统医学(2023年18期)2024-01-10
系统医学(2023年13期)2023-10-26
系统医学(2022年17期)2022-11-07
系统医学(2022年2期)2022-05-05
新世纪智能(数学备考)(2021年9期)2021-11-24
少先队活动(2020年12期)2021-01-14
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
中成药(2017年3期)2017-05-17
读者(2017年5期)2017-02-15
