
基于数据分析角度论述游客目的地印象
2021-12-24 10:48蔡金勇罗浩杰李泽星沈洋
电子乐园·上旬刊 2021年3期
关键词:数据分析
蔡金勇 罗浩杰 李泽星 沈洋


摘要:本文旨在利用数据分析对游客对景区与酒店的评价进行数据挖掘,由于游客满意度与目的地美誉度紧密相关,游客满意度越高,目的地美誉度就越大。找出其中稳定客源、取得竞争优势、吸引游客到访消费等的主要原因。这对于旅游企业科学监管、资源优化配置以及市场持续开拓具有长远而积极的作用。
关键词:数据分析;jieba分词; 停用词; 均方误差; 编辑距离
一、问题重述
提升景区及酒店等旅游目的地美誉度是各地文旅主管部门和旅游相关企业非常重视和 关注的工作,涉及到如何稳定客源、取得竞争优势、吸引游客到访消费等重要事项。游客满意度与目的地美誉度紧密相关,游客满意度越高,目的地美誉度就越大。
二、景区及酒店印象分析
(一)使用方法
我们将会用到jieba分词的方法,有三种分词模式
(1) 精确模式:试图将句子最精确地切开,适合文本分析;
(2) 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义问题;
(3) 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
(二)问题解决
1.目的地TOP20热门词
本节使用jieba模块中的精准模式对网评文本进行分词,再使用中文常用停用词(中文停用词表“cn_stopwords.txt”,哈工大停用词表“hit_stopwords.txt”,百度停用词表“baidu_stopword.txt”,四川大学机器智能实验室停用词库“scu_stopwords.txt”)表对文本进行过滤,遍历所有词语,每出现一次加一,再将对应键值转换为列表,根据词语出现的次数进行从到大到小进行排列,将排名前二十的热词及热度输出。
2. 每家酒店和景区的印象词云表
我们将景区评论及酒店评论使用JupyterNotebook将其转换为矩阵,新建一个空列表list1,创建一个循环,将矩阵中第一列一样的评论依此增加如list1中,每次添加完一次之后对list1进行分词及过滤之后将前20个数据保存入对应名称的后缀为.csv的文件中。
总结:由于数据处理对象为景区评论和酒店评论,我们选用停用词表时可以选用针对性较强的,可以过滤更多无关词语。分词方法有很多,可以针对不同情况使用。待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
三、景区及酒店的综合评价
1. 数学模型及相应算法
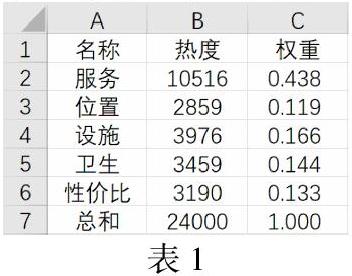
我们对问题一中的热度数据对景区及酒店的服务、位置、设施、卫生、性价比进行分析,在列表中卫生热度只有1931,而与其近似的干净则占热度3459,所以我们决定用干净的热度来表示卫生的热度。以及列表中性价比的热度为2237,与其近似的便宜热度为3190,及免费2360,考虑到有可能会有一句网评中都包含了这几个词语,所以我们决定用热度较高的便宜来表示性价比的热度。然后对这五个求权重得到下表:
提取出这五个的权重生成5×1的矩阵mat3,mat3则为评分权重矩阵。再将酒店评分提取出来生成5×50的矩阵mat1,将景区评分提取出来生成5×50的矩阵mat2。
用x1=np.dot(mat1,mat3)求得对酒店评分的预测矩阵,x2= np.dot(mat2,mat3)求得对景区的预测矩阵,在excel表中提取出酒店评分真实值y1及景区评分真实值y2。然后使用预测矩阵x减去真实矩阵y,分别得到差值矩阵d1,d2。
然后使用预测矩阵x减去真实矩阵y,分别得到差值矩阵d1,d2。
最后使用均方误差进行模型判断:
MSE:
计算酒店评分的均方误差:np.dot(np.transpose(d1),d1)/50
计算景区评分的均方误差:np.dot(np.transpose(d2),d2)/50
计算酒店加景区评分的均方误差:
(np.dot(np.transpose(d2),d2)+np.dot(np.transpose(d1),d1))/100
得到MSE(酒店)≈0.0098
MSE(景区)≈ 0.0121
MSE(酒店+景区)≈ 0.0109
当MSE越小,我们建立的模型越好。
四、网评文本的有效性分析
出于各种原因,网络评论常常出现内容不相关、简单复制修改和无有效内容等现象,为了解决这个问题,我们使用了计算编輯距离的方法。
1.算法
编辑距离,又称Levenshtein距离(也叫做Edit Distance),是指两个字串之间,由一个转成另一个所需的最少编辑操作次数,如果它们的距离越大,说明它们越是不同。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
代码实现:
Levenshtein.distance(’abc’,’cba’)
Levenshtein.distance(’kitten’,’sitting’)
2.问题解决
通过计算编辑距离,我们剔除距离小于0.5的数据,使得数据更加简洁,提高数据有效性。
在执行过程中,为了减少计算,我们首先对数据进行了清洗,主要用到了去停用词,结巴精准分词等方法,然后计算编辑距离。但是通过对比较结果进行分析,我们发现距离普遍较小,即相关性普遍较大,无法进行有效剔除。因此我们放弃了此方法,选择分析文本。
我们将每个文本与后面的文本进行比较,得到对应的相关性(代码用的是1-aa,因此,值越靠近1相关性越强):
我们将这些筛选出的相关度高的数据进行剔除,就整理出来了一个更有效的数据。
猜你喜欢
职工法律天地·下半月(2016年10期)2016-11-30
商情(2016年40期)2016-11-28
商(2016年32期)2016-11-24
科技资讯(2016年18期)2016-11-15
考试周刊(2016年84期)2016-11-11
科技视界(2016年18期)2016-11-03
中国市场(2016年36期)2016-10-19
商场现代化(2016年22期)2016-10-18
科技视界(2016年22期)2016-10-18
