
基于改进的DeepLabV3+模型结合无人机遥感的水稻倒伏识别方法
2022-01-05 07:21慕涛阳胡晓宇
中国农业大学学报 2022年2期
慕涛阳 赵 伟 胡晓宇 李 丹
(东北林业大学 信息与计算机工程学院,哈尔滨 150040)
水稻是我国重要的粮食作物,水稻产量的波动会对粮食安全产生一定的影响。水稻生长容易受到不良气象因素影响从而导致水稻产生倒伏现象,形成大范围倒伏灾害,不仅会造成较大的产量和质量损失,而且对农业机械的自动化收割产生不利影响,造成农户经济损失。因此监测水稻倒伏受灾区域对提升农业机械的收割效率和降低农民经济损失具有重要意义[1]。
传统遥感影像数据获取为人工获取,所需要的人力物力较大,获取倒伏信息的成本高、效率低,大面积快速监测的手段非常有限,并且受勘测人员的主观影响较大。目前利用无人机获取遥感数据进行倒伏监测可以降低数据获取的时间成本,无人机具有获取遥感数据灵活方便、图像的空间分辨率高等优点,可以较好的应用于农作物灾情监测等领域。已有研究[2]表明利用无人机遥感技术在小尺度范围使用航拍摄影的方式,可以提取小尺度农作物的倒伏信息,并提出了相应的农作物倒伏面积信息提取的方法:1)对植被各光谱之间的差异进行分析,快速获取玉米倒伏灾情信息[3];2)经过构建5种典型特征组合,对农作物倒伏面积进行特征组合提取[4];3)采用色彩或者阈值分割来分析倒伏情况并对倒伏面积进行提取[5];4)基于分水岭算法结合自适应阈值分割的混合算法[6];5)采用色彩或者阈值分割来分析倒伏情况并对倒伏面积进行提取[7]。以上方法[8-11]的缺点是倒伏与非倒伏区域区分不明显,并且使用的算法模型的效率较低,降低了水稻倒伏识别模型的工程实用性。
水稻倒伏监测的另1种手段是使用雷达遥感技术[12]。已有研究使用地基雷达进行植被检测[13-14],地基雷达对测量物体有一定的穿透力,能够不受云雾雨水影响,对待测物体群体结构产生的变化很敏感[15-17],同时可以模拟出被测物体的3维点云模型,能够对农作物进行生长状态识别与监测[18]。目前雷达遥感的研究对不平整且碎块较多的地面,其结果会受到一定的影响,并且对大范围农作物的识别监测需要耗费大量的资源,研究成本高昂。
综合研究表明,目前的水稻倒伏识别方法无法满足大范围的水稻倒伏区域识别,存在识别时效低、精度低、成本高的缺点。本研究拟将深度可分离卷积和混合域注意力机制引入DeepLabV3+模型中,将无人机遥感图像与改进DeepLabV3+深度学习模型结合,降低识别成本,增强模型对水稻倒伏识别的鲁棒性和泛化能力。
1 材料与方法
1.1 研究区域概述及试验装备
本试验于2020年10月12日在黑龙江省佳木斯市七星农场(132.133° E,47.516° N)进行。该农场地处三江平原腹地,地势低平,坡降平缓,总面积约103 000 hm2,以水稻为产业支柱。该地区属中温带大陆性季风气候,年平均气温3 ℃,冬长夏短,无霜期约140 d,年平均降水量527 mm,日照时数2 525 h,适宜的温度、肥沃的土壤共同组成了水稻生长的理想环境。
数据采集试验部分使用大疆悟Inspire1无人机,搭载的相机型号为DJI FC6310R。倒伏识别试验硬件方面,CPU为Intel Xeon Gold 6128,内存64 GB,显卡为GTX 1080Ti×3。倒伏识别试验软件方面,系统版本为Ubuntu 18.04.2,CUDA版本为9.0。基于Python编程语言使用TensorFlow框架和Keras框架进行深度学习模型的搭建。
1.2 数据采集
2020年10月上旬佳木斯市出现台风等强对流天气,导致七星农场内出现多处水稻倒伏灾情。2020年10月12日,以七星农场内倒伏最为严重的区域作为试验区域,使用无人机搭载RGB载荷平台对试验区域的水稻冠层进行低空拍摄。数据获取于当日09:00,天气晴,航拍时无人机飞行高度为448 m,飞行速度5 m/s,航向重叠率90%,旁向重叠率80%,规划主航线条数12条,航点数140个,获取原始图像346张,单张原始图像分辨率183点/cm,获取试验区域面积约1.2 hm2。利用倒伏分级方法,将水稻分为倒伏、半倒伏和未倒伏3种状态[19]。
使用Pix4D mapper软件对原始遥感图像进行拼接校正[20]。Pix4D mapper是1款便捷、高效的无人机遥感数据处理软件。应用该软件的图像拼接功能对采集的图像进行正射校正和图像拼接[21]。首先进行航片对齐,并解算图片的空中三角测量数据,然后进行几何校正、关键点匹配、解算数据构建密集点云及纹理信息,最后得到大范围水稻倒伏的数字正射影像。
1.3 数据集及预处理
得到水稻倒伏区域的数字正射影像后,由于计算机内存较低且高分辨率遥感图像的尺寸不同,不能直接将遥感图像直接输入到深度学习网络中进行训练。需要先将数字正射影像进行标注和裁剪,标注分为倒伏、半倒伏、未倒伏和其他杂物4部分,分别用红、黄、绿和黑色进行标注。数据集预处理具体过程如下:
数据标注。本研究使用Labelme工具进行图像标注,Labelme是1款开源的轻量级图像标注软件,能够对图像数据进行标注。
数据裁剪。在对原始图像进行标注之后,再对原始图像和标注图像进行裁剪。
数据增强。在数据增强过程中时进行模糊、镜像、噪声、旋转、随机偏斜等操作。为了增加深度学习模型的鲁棒性,本研究在增加噪声时加入了高斯噪声及椒盐噪声。
数据集划分。在经过数据增强后,得到5 000余幅高分辨遥感数据集。将数据集随机划分训练集、测试集和验证集,以0.7∶0.15∶0.15的比例进行测试。2种典型特征的水稻倒伏图像见图1。

图1 2种典型特征的水稻倒伏原始图与标注图Fig.1 Original and annotated images of two typical characteristics of rice lodging
1.4 SVM支持向量机算法
传统机器学习算法SVM支持向量机算法是有监督学习分类算法的1种,是在特征空间上使用间隔最大化学习策略的线性分类器。SVM支持向量机算法的主要思想是在特征空间中寻找超平面,使用极低的错分率将正负样本区分,经过学习获取对样本求解的最大边距超平面。SVM支持向量机算法在学习非线性方程时提供了1种优秀的方法。
1.5 改进DeepLabV3+网络结构
1.5.1DeepLabV3+网络结构
目前语义分割所需要面对的问题主要是,图像的连续池化和下采样的问题,大多数语义分割网络采用空洞卷积的方法进行处理。为了解决多尺度目标的问题,DeeplabV3+语义分割模型中引入了编码器和解码器结构,模型融合了ASPP结构和Encoder-Decoder方法[22]。不仅可以充分挖掘多尺度的上下文信息,而且可以使用重构图像空间信息的方法确定物体的边界。ASPP对于输入特征图x,其输出特征图(y)为:
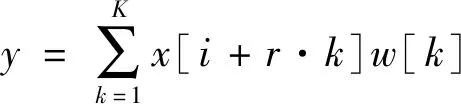
(1)
式中:i为1维输入信号;w[k]为滤波器数值;r为膨胀率;K为空洞卷积的长度。
DeepLabV3+的空洞卷积结构是在传统网络的标准卷积的结构基础上进行拓展,空洞卷积的感受野计算与标准卷积核一致,其空洞卷积感受野的值K为:
K=k+(k-1)(r-1)
(2)
式中:k为原始卷积核大小;r为空洞卷积实际卷积核的大小。
DeeplabV3+网络结构主要分为解码层和编码层[23]。DeeplabV3+的编码模块是由DeepLabV3作为编码器,利用卷积核生成任意维度的特征。DeeplabV3+的解码模块,首先将图像的编码特征进行双线性上采样,然后将主干网络所输出的特征进行拼接,由于所输出的特征可能会超出编码特征,所以在拼接特征前需要采用11卷积,对特征进行操作,以减少通道个数。同时处理时采用3×3卷积和4因子的双线性内插上采样方式,接着与经过4倍双线性内插上采样的特征图进行融合,最后经过3×3卷积后4倍双线性内插上采样将图片恢复至原图的分辨率,完成语义分割。DeeplabV3+的网络结构见图2。

图2 DeeplabV3+网络结构Fig.2 DeeplabV3+ network structure
相比较于传统的DeepLab系列模型,DeepLabV3+中的编码特征需要直接将双线性采样从1/16上采样还原到原始分辨率[24],DeepLabV3+改进了使用空间金字塔池的DeepLabV3,同时使得编码器能够应用于卷积,因此可以经过任意分辨率来提取特征[25]。DeepLabV3+能够改善图片分割、语义分割的效果,其原因与加入的解码模块相关,新的解码模块提高了模型处理图像边界的效果,较好的保留了目标的边缘细节信息[26],而且encode-decoder能够实现对Atrous convolution的灵活控制,从而能够有效的获得编码特征的分辨率,使得DeepLabV3+模型在语义分割的精度和效率都达到了非常好的效果。DeepLabV3+的网络结构分为EnCoder和DeCoder,其中EnCoder模块与DeepLabV3模型相同,DeCoder模块类似于Unet模型的上采样部分,可以帮助图像上采样的过程中更加的平滑。
1.5.2建立改进DeepLabV3+网络结构
本研究以DeepLabV3+网络模型为主网络,对DeepLabV3+网络从2个方面进行改进。首先,将ASPP结构中的标准卷积替换为深度可分离卷积,空洞卷积替换为空洞深度可分离卷积,加快结构信息的传输速度,提高网络效率;其次,将卷积注意力机制(CBAM)嵌入进DeepLabV3+网络结构中,提高卷积神经网络的注意力,减少无关特征对识别精度的影响。CBAM包括空间注意力与通道注意力机制2个模块,能够实现通道权重与空间权重的自学习。
经过随机画出4个3×3卷积操作,能够更加形象的表现通道分离的过程,此时深度可分离卷积的结构见图3。输入特征后将每个通道进行3×3卷积,使其通道分离。随后拼接特征,进行1×1卷积,得到输出特征。深度可分离卷积主要可以应用在DeepLabV3+模型中的ASPP模块,如ResNet、VGG[13]等网络使用堆叠大量的卷积层和池化层来使网络同时学习特征图的空间相关性和通道相关性[27],而深度可分离卷积先是逐个通道学习特征的空间相关性,再用标准卷积学习特征的通道相关性[28]。深度可分离卷积与空洞卷积相比,深度可分离卷积可以使用更少的参数来进行特征学习,提升网络的迭代效率。本研究在DeepLabV3+模型的ASPP模块中将标准卷积替换为深度可分离卷积、空洞卷积替换为空洞深度可分离卷积,在不降低预测精度的前提下,能够大幅提升DeepLabV3+网络模型的训练效率。
通过原原本本向农民反复宣传中央有关文件精神,使他们对土地流转形式、流转程序、履行手续以及对自身权益的影响等问题有基本的认识。

图3 深度可分离卷积结构Fig.3 Deep separable convolution structure
卷积注意力机制是结合空间与通道的卷积注意力模块,本研究引入卷积注意力机制构建的混合域注意力机制模块,使得卷积神经网络更加关注关键信息,抑制非关键信息。混合域注意力机制模块分为通道注意力和空间注意力2个模块,DeepLabV3+模型在进行下采样时会丢失信息,造成精度降低。本研究引入了混合域注意力机制模块,将注意力映射从特征图的通道和空间2个维度进入,对特征图进行自适应的特征优化,降低非关键信息的干扰,提升DeepLabV3+网络的表征能力。CBAM卷积注意力模块结构见图4。

图4 CBAM卷积注意力模块结构Fig.4 Convolutional block attention module
输入特征图后,通道注意力将特征图压缩为1维矢量,逐元素求和合并,产生通道注意力图。通道注意力可以关注特征图上的重要内容,经过平均值池化对特征图的所有像素点产生反馈值,最大值池化在进行梯度反向传播时,只在特征图响应最大的地方产生梯度反馈。输入1个H×W×C的特征图F,对特征向量使用最大池化和平均池化进行压缩,通道注意力机制为:

(3)

通道注意力模块输出后的特征图经过空间注意力模块,经过全局最大池化和全局平均池化,生成2个1通道特征图,然后将2个结果进行连接,降维成1维卷积经过sigmoid生成空间特征,将之前提取到的通道数为1的特征图合并,生成最终的2通道特征图。特征图F的空间注意力机制为:

(4)
本研究经过改进DeepLabV3+网络结构,凸显对于模型网络学习有利影响的通道信息,并降低消极冗余通道信息,加强优势特征的针对性,使得模型分割效果更为精细,同时可以在不影响模型运行时间的基础上,增强深度学习网络的鲁棒性和泛化能力[29]。
2 试验与结果分析
2.1 试验参数设置及网络训练
为加速深度学习模型的收敛,本研究将数据集随机划分训练集、测试集和验证集,并且以0.7∶0.15∶0.15的比例进行测试。循环次数设置为1 000,初始学习率设置为1×10-3,根据试验环境配置将batchsize设置为4。
本研究采用改进的DeepLabV3+网络模型作为主网络模型进行训练,骨干网络模型分为ResNet50与ResNet101,总体来看两者的精度值都随着训练次数的增加而增加并且逐渐稳定,但是ResNet101骨干网络收敛速度明显更快、精度更高。ResNet101使用批归一化的方法来化解梯度消失的现象,降低了网络训练过程中对于初始值权重的依赖,并且在使用堆叠残差网络模块搭建网络模型时,不会出现模型退化现象,训练后期的波动更小。因此本研究将ResNet101作为改进DeepLabV3+的骨干网络。为了探究对于DeepLabV3+模型的改进效果,对比DeepLabV3+模型在改进前后的收敛速度以及精度对比。改进DeepLabV3+与DeepLabV3+模型在验证集的识别精度对比见图5,可以看出,改进后的DeepLabV3+模型在水稻倒伏数据集上识别精度更高,同时收敛速度更快,后期的波动更小,说明改进后的DeepLabV3+模型的鲁棒性和模型的泛化能力更强,识别效果优于DeepLabV3+模型。

图5 DeepLabV3+模型改进前(a)和改进后(b)对水稻倒伏的识别精度Fig.5 The accuracy map of rice lodging recognition before (a)and after (b)improvement of DeepLabV3+ model
2.2 模型评价指标
(5)
(6)
(7)
(8)
(9)
(10)
(11)
式中:TP表示被正确分割为水稻倒伏区域的像素数量;TN表示被正确标记为其他不相关区域的像素数量;FN表示为被错误标记为水稻倒伏区域的像素数量;FP表示为被错误标记为其他的水稻倒伏区域的像素数量;PE表示真实样本数乘实际样本数与总样本平方的比;A为人工标记的正确图像面积;B为深度学习模型识别得到的图像面积;k表示图像类别个数。
2.3 阈值分割倒伏区域识别方法
本试验采用传统的阈值分割识别技术对倒伏面积进行提取,使用植被指数对水稻倒伏区域进行识别。对水稻倒伏影像进行基于颜色植被指数的识别,使用的植被指数有过绿指数(2G-R-B)、过绿-过红指数(3G-2.4R-B)、归一化绿-红差值指数((G-R)/(G+R))和绿叶指数((2G-R-B)/(2G-R-B)),经过对比分析,发现过绿指数能够在提取出相对精准的水稻倒伏植被信息后,并且产生的噪音点较少,所以本试验使用ENVI软件采用过绿指数对水稻倒伏图像进行提取,计算得出水稻倒伏遥感图像的过绿指数结果。
经过阈值分割得到水稻倒伏图像的像素分布在-11~60区间内,将-11~0的像素分为背景,0~10的像素分为未倒伏水稻,10~20的像素分为半倒伏水稻,20~60的像素分为倒伏水稻。经过图片上色后,生成倒伏预测图。过绿指数计算结果与阈值分割识别结果见图6。
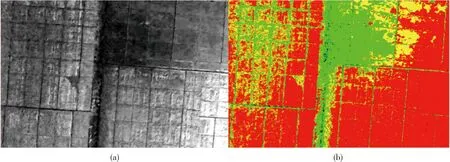
图6 水稻倒伏过绿指数结果(a)与阈值分割识别效果(b)Fig.6 Rice lodging green index result (a)and threshold segmentation recognition effect (b)
阈值分割识别之后,使用均值哈希算法对阈值分割识别图与标注图进行对比,得到均值哈希算法相似度为30,表明阈值分割识别图的精度低于0.5,精度较低,传统的阈值分割技术倒伏与非倒伏区域区分不明显,达不到实际倒伏识别所需精度。
2.4 模型对比分析
本研究使用传统机器学习算法SVM与改进的DeepLabV3+模型进行对比。改进后的DeepLabV3+深度学习模型的准确率远远高于传统的机器学习算法,并且在试验过程中,传统机器学习的准确率较低,准确率为0.58,Kappa系数为0.53,平均交并比为0.55;改进后的DeepLabV3+模型的准确率为0.99,Kappa系数为0.98,平均交并比为0.97。相对于传统机器学习SVM算法,改进后的DeepLabV3+有着更高的准确率、平均交并比和Kappa系数,拥有着更高的水稻倒伏识别工程的实用性。对水稻倒伏识别评估结果对比见表1。
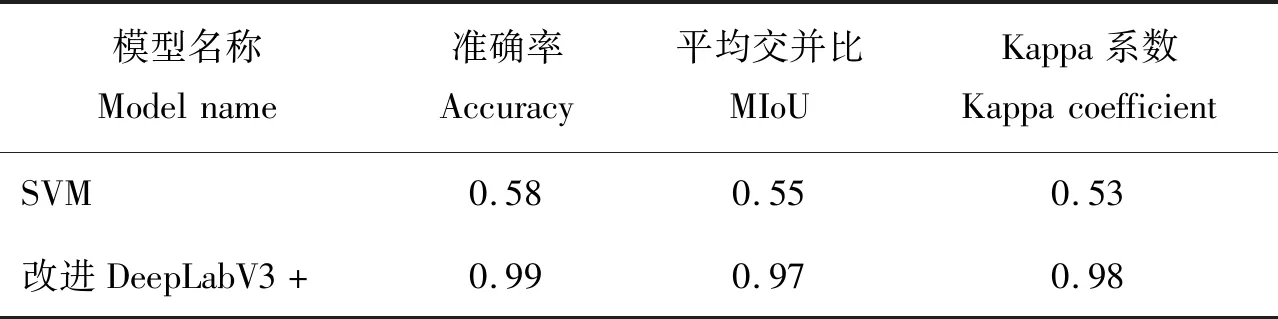
表1 SVM与改进DeepLabV3+模型对水稻倒伏的识别结果Table 1 Evaluation results of SVM algorithm and improved DeepLabV3+ model for rice lodging recognition
本试验采用10种深度学习模型与改进DeepLabV3+模型进行对比试验,其中包括NetAdapt、BiseNet、DeepLabV3+、DenseASPP、SegNet、ICNet、FRNN、GCN、MobileUNet和RefineNet。经过对比分析11种模型在标注完成的水稻倒伏图像上的分类所需要的时间与分类准确率,得出1种准确率较高、分类预测时间能够满足实际作业需求的模型。10种模型在经过训练和预测水稻倒伏区域的准确率、Kappa系数、像素准确率、召回率、平衡F分数、平均交并比、交并比与训练时间见表2。
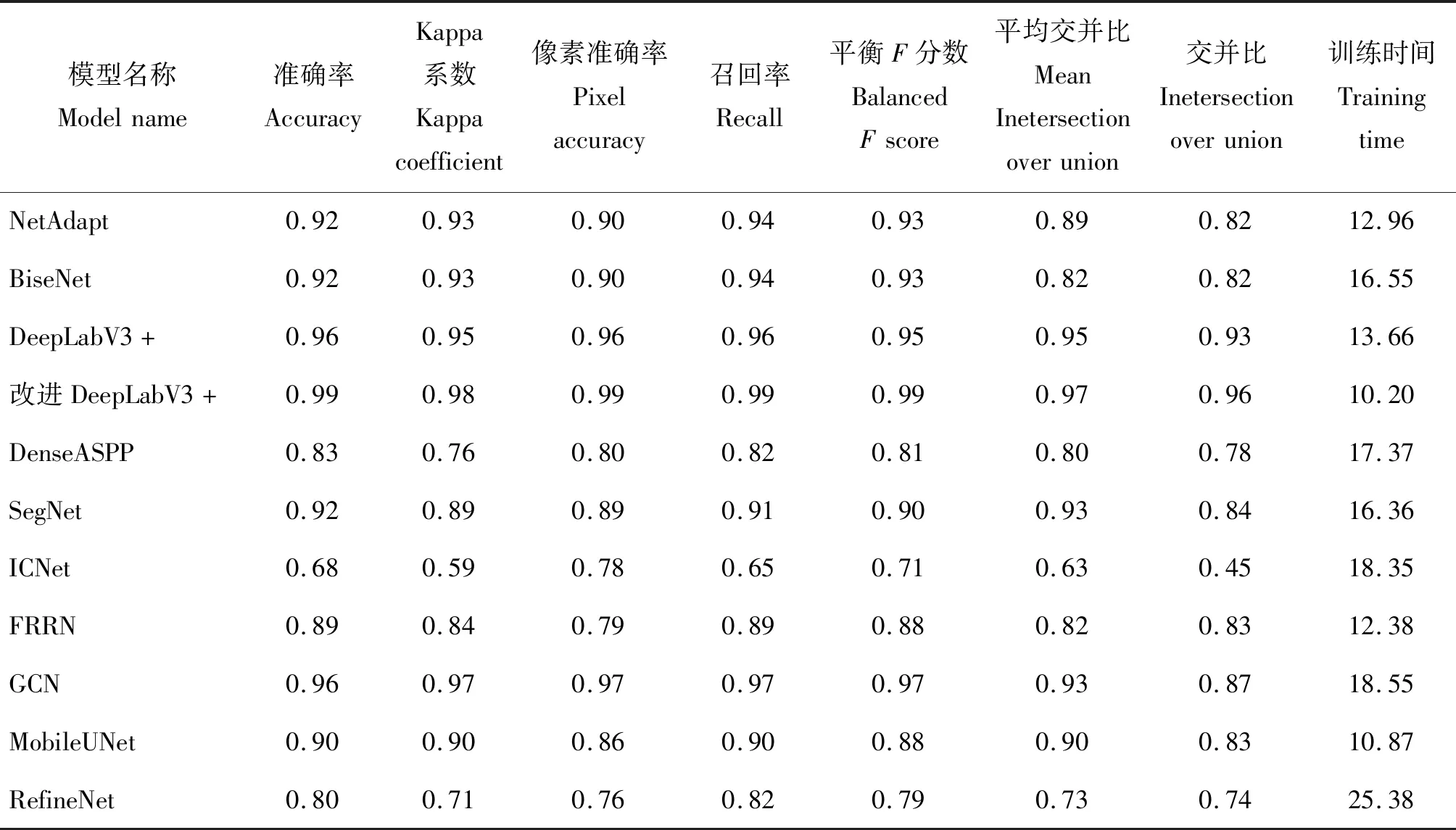
表2 各模型对水稻倒伏识别的评估结果Table 2 Evaluation results of various models on rice lodging recognition
根据训练模型对倒伏面积进行预测得到各模型对于水稻倒伏区域的提取结果见图7。可见,改进DeepLabV3+模型和其他10种模型都完成了对水稻倒伏的识别,但各个模型之间的识别差异较大。相比较于改进后的DeepLabV3+模型,DeepLabV3+模型在识别精度等各项指标方面低于改进后的DeepLabV3+模型,同时预测图的效果有少量的明显识别错误。RefineNet、DenseASPP、ICNet和BiseNet网络模型的各项指标较低,其预测效果图与原图差距较大,存在大量的识别错误,不适合作为水稻倒伏识别的网络模型。NetAdapt、SegNet、FRRN和MobileUNet网络模型各项评价指标较为均衡,可以较好的实现水稻倒伏识别,但仍然存在少量明显的错误,其中将背景识别为倒伏水稻的错误最为明显。改进后的DeepLabV3+模型与GCN模型在预测图上的效果最好,对倒伏识别的错误较少,但GCN模型的预测图相比标注图,边缘处理效果较为模糊,相比较于改进DeepLabV3+,GCN模型的精度略低,改进DeepLabV3+模型的MIoU和IoU明显优于GCN,同时改进DeepLabV3+预测图的边缘处理更为平滑,预测图显示效果优于GCN网络模型。总体来看,改进DeepLabV3+模型对于水稻倒伏识别的效果最好,特征提取更加迅速,预测识别图边缘处理圆滑并且细节处理更优秀,其准确率、Kappa系数、MIoU与训练时间均优于其他网络结构。

图7 标注图(a)与各模型对水稻倒伏的识别效果(b)~(l)Fig.7 Annotated image (a)and each model on the recognition effect of rice lodging (b)-(l)
综上,与传统的阈值分割技术和机器学习算法以及其他深度学习算法相比,改进DeepLabV3+模型在指标评价和识别效果图均具有较大的优势,表现出良好的泛化能力,能够满足对于水稻倒伏识别准确率高和识别速度快的要求,在水稻倒伏识别方面有一定的现实应用价值。
2.5 倒伏智能评估系统
为满足水稻倒伏识别的实际应用场景,满足农户单人对大范围倒伏区域进行识别,本研究使用C# 与Python语言开发水稻倒伏智能评估系统。系统实现了从无人机遥感图像获取的预处理到深度学习模型的识别以及灾情报告单打印的功能。系统模块主要分为预处理模块、倒伏识别模块和倒伏面积计算模块。预处理模块使用了开源代码GIMP工具,可以实现对图片的裁剪、缩放和更改格式等操作。倒伏识别模块使用预训练的改进DeepLabV3+模型,能够以较高的精度对水稻倒伏区域进行识别提取。倒伏面积计算模块提取倒伏区域后利用比例尺计算实际的倒伏面积,使用Python-Word开源库将数据保存到word中,方便查勘人员进行定损报告单打印。为了更好的体现深度学习模型对于水稻倒伏灾情的识别效果,本试验首先将无人机航拍数据整合成大尺度图片,使用深度学习模型对于大尺度图片进行识别,最后将原图与模型识别图进行融合,生成更为直观的灾情效果图。倒伏面积预测功能与灾情效果图功能的系统界面见图8。

图8 改进DeepLabV3+的水稻倒伏预测功能(a)与灾情效果输出功能(b)界面Fig.8 Improved some functional interfaces of DeepLabV3+’s rice lodging recognition system
该系统实现了自动化倒伏识别、倒伏面积提取和定损计算,解决了传统查勘定损效率低、强度大、定损标准不统一和取证保全不足等问题,为解决水稻倒伏识别和查勘定损提出了一种标准化的解决方案。
3 结束语
本研究针对当前水稻倒伏识别存在的问题,提出了一种无人机遥感图像结合改进DeepLabV3+模型的水稻倒伏识别方法。使用搭载高分辨率RGB相机载荷平台的无人机,获取水稻倒伏的遥感图像;改进的DeepLabV3+模型识别水稻倒伏的准确率、Kappa系数、像素准确率、召回率、平衡F分数、平均交并比和交并比分别达到了0.98、0.98、0.99、0.99、0.99、0.97和0.96,分割效果远超阈值分割识别以及传统的机器学习算法和其他10种深度学习算法;建立了一套完整的水稻倒伏识别系统,为非专业人士使用无人机遥感图像结合深度学习提供了途径。
本研究提出的基于无人机遥感图像结合改进DeepLabV3+模型的水稻倒伏识别方法解决了水稻倒伏识别难、成本高的问题,改进的DeepLabV3+模型在保证识别速度的基础上,达到了较高的识别精度,为大面积、高效率、低成本的水稻倒伏监测研究提供了一种有效的方法。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
现代电子技术(2022年11期)2022-06-14
计算技术与自动化(2022年1期)2022-04-15
小雪花·成长指南(2022年1期)2022-04-09
建材发展导向(2021年19期)2021-12-06
科技研究(2021年15期)2021-09-10
上海师范大学学报·自然科学版(2019年5期)2019-12-13
分析化学(2017年12期)2017-12-25
中国新通信(2017年9期)2017-05-27
第二课堂(课外活动版)(2016年2期)2016-10-21
