
基于特征权重的词向量文本表示模型
2022-03-17 11:42蒋延杰李云红苏雪平张蕾涛贾凯莉陈锦妮
西安工程大学学报 2022年1期
蒋延杰,李云红,苏雪平,张蕾涛,贾凯莉,陈锦妮
(1.北京市组织机构代码管理中心,北京 100010;2.西安工程大学 电子信息学院,陕西 西安 710048)
0 引 言
文本表示是处理自然语言任务的前提,并且文本表示的质量与任务处理结果的好坏密切相关。文本表示可以对单词、短语、句子和文档等任何文本单元进行处理[1-3]。传统文本表示方法有词袋模型(bag of word,BOW)、N元语言模型(N-Gram model,N-Gram)和向量空间模型(vector space model, VSM)等。BOW通过One-hot编码将文本表示为高维稀疏向量,但却存在忽视词序、词义及上下文之间的关系,不能有效地捕捉文本的语义和语境,导致维数灾难等问题[4-5]。N-Gram作为词袋模型的扩展模型,解决了BOW无法捕捉语序和上下文信息,但无法解决词袋模型的维度灾难[6-7]。文献[8-10]提出向量空间模型,通过计算词频-逆文档频率(term frequency-inverse document frequency, TF-IDF)对文本中的某个特征词的特征选择作用的大小进行评估,得到文本表示,但同样存在表示不充分和维度灾难。文献[11-12]提出基于三层神经网络的文本表示模型,解决了上述模型忽略了词与词之间的语义关系。文献[13-15]提出基于浅层神经网络词嵌入模型(Word2vec),它包含了词向量CBOW和Skip-Gram模型,解决了传统文本表示中捕捉细粒度的语义、句法规则,但忽视了词序和统计信息的不足。Deps模型[14]作为Word2Vec的扩展模型,将Skip-Gram泛化为包含任意上下文,使用解析树中的相邻词来学习单词表示,可以很好地获取对中心词最具辨别力的上下文,但会导致语境缺失。文献[16-18]提出Glove模型,该模型利用文本语料库中的词与词的共现信息学习文本特征表示,可以捕捉到上下文信息,却没有考虑统计信息的影响,同时忽略了词序特征,影响了文本表示性能。
针对以上文本表示存在忽略语义、词序特征和存在维数灾难等问题,本文建立将TF-IDF、N-Gram、Glove相结合的无监督文本表示模型,在不增加计算复杂度的情况下,更好地对复杂文本特征进行表征,提升了文本分类的性能。
1 基础理论
1.1 TF-IDF模型
TF-IDF模型包括词频(term frequency, TF)和逆文档频率(inverse document frequency, IDF)2个部分,即
(1)
式中:TI表示词频逆文档频率;文档特征词分别用t、v表示;t和v同时出现的次数用mt,v表示;Σimi,v为v中所有词出现的总次数;D为文本总数;|v:wt∈dv|+1为特征词wt出现的文本数。
从式(1)可知,TF-IDF模型依据特征词在某一类文档中出现的次数较多,而在其他类别的文档出现的次数较少,从而过滤掉对某类文档不重要的词,但该算法忽视了语义信息及易受特征词位置的影响,除此之外,还会将某一类文档中出现次数较少的生僻字作为关键词。综上可知,用一种方法表示文本时,无法准确表达文本信息,影响分类任务的性能。
1.2 N-Gram模型
N-Gram模型是文本表示常用的模型之一,其定义为给定前n-1个标记后的第n个标记的条件概率,即
(2)
式中:S为1条有n个词的语句,由d1,d2,…,dn组成;di为句子中的某一个词;P(S)为S中n个词出现的概率连乘,则
(3)
(4)
该计算方式虽然简单,但会受词与词之间的相互影响。因此,提出n-1阶马尔可夫假设,假设句子中的任意一个单词dn的出现与前n-1个词有关,即
(5)
满足式(5)的为N-Gram模型。n取值合理,若n太大,则参数过多的情况无法解决。
1.3 Glove模型
Glove模型通过词共现概率比进行词向量学习,即
(6)
(7)

(8)

(9)
经过计算得
(10)
结合式(9),得
(11)
令式(11)中的F=exp(),得
(12)
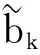
(13)
当式(13)中参数为零时,导致函数的发散情况,
令
ln(Xik)→ln(1+Xik)
它保持了X的稀疏性,同时避免了发散。除此之外,为了回避该模型存在对所有共现情况的权重相等,引入加权最小二乘回归并在代价函数中引入加权函数f(Xij)。该模型的损失函数,即
(14)
式中:V为词汇量大小。其中f(x)为
(15)
式中:xmax取值为100;α值为3/4。
2 融合特征权重的词向量文本表示模型
特征融合是以多种不同的角度从样本中抽取特征,并将这些特征通过某些计算手段进行融合,得到一种新形式的特征文件。本文利用矩阵相乘与矩阵相加的计算方式,将不同特征进行融合,建立一种基于特征权重的词向量文本表示模型。该模型的具体流程为Glove模型与TF-IDF模型进行矩阵相乘,得到TG文本表示模型,Glove模型与N-Gram模型矩阵相乘,得到NG文本表示模型,最后将TG与NG进行矩阵相加,得到最终融合的TN-Glove模型。其中,TG模型为给Glove词向量增加TF-IDF特征权重,而NG模型为给Glove词向量乘以N-Gram特征概率。文本表示模型通过给Glove词向量增加特征权重,获得新的文本表示。其中词向量并不是模型任务的最终结果,而是在训练过程中的附带产物——权重矩阵。词向量的维数是人为设定的固定值,百位级别的整数。Glove取值为300,即用300维的向量表示文本中的每个词。用ti表示文本中的一个词,则该词的词向量形式即
ti=(w1|ti,…,wn|ti)T
(16)
式中:n为词向量的维数,选取n=300;w1|ti为词ti的第一维词向量的值,依次类推,wn|ti为第n维词向量的值。式(16)为文本中词的表示方法,如果需要对语料库中的所有词进行表示,则需要将每个词表示成向量,然后堆叠成矩阵形式。通常词向量是针对文档中不重复的特征词,则词向量W表示为
W=[t1,t2…,tn]
(17)
式中:W代表Glove词向量矩阵,每个ti为n维的列向量,可记为W=(wij)n×n。
TG文本表示模型是在Glove词向量的基础上,结合特征选择方法TF-IDF。具体计算方式即
TG=TIW
(18)
式中:TG表示Glove与TF-IDF融合后的词向量矩阵;TI为通过TF-IDF模型计算的权重矩阵,记为TI=(TIij)m×n。TI和W的维度一样。因此,只需要用特征权重矩阵乘以词向量矩阵,则某一个语料库的文本TG(简记为TG)词向量形式即
TG=(tgij)m×n
(19)
NG文本表示模型是将N-Gram与Glove相结合,具体计算方式即
NG=PW
(20)
式中:NG表示N-Gram与Glove分后的词向量矩阵;P为通过N-Gram算法计算的概率矩阵,记为P=(pij)m×n。则某一个语料库的文本NG(简记为NG)词向量形式即
NG=(ngij)m×n
(21)
最后将TG与NG相加融合,得到TN-Glove文本表示模型,即
TN=TG+NG
(22)
TN-Glove模型流程如图1所示。

图 1 TN-Glove模型流程图Fig.1 Flow of TN-Glove model
从图1可以看出:TN-Glove文本表示模型首先需通过训练获得Glove词向量;然后,计算待分类文本的TF-IDF权重,并与对应的词向量进行相乘,得到文本的TG表示;同时,通过给Glove词向量乘以N-Gram概率得到NG文本表示模型;并将TG与NG进行相加融合,最后将TN-Glove文本表示模型表示输入到SVM分类器实现文本分类。
Glove模型首先能很好地表达语料库中的上下文信息;其次,该模型训练的并不是共现矩阵的所有元素,而是其中的非零元素,提高了训练速度,并且该模型能有效表达文本的语义和句法信息。将Glove模型与TF-IDF和N-Gram相融合,使TN-Glove文本表示模型拥有每种文本表示模型的优点,融合特征权重的词向量文本表示模型不仅考虑了语义和语序信息,而且通过词频信息保留文本中类别区分能力较强的特征词,改善了文本分类效果。
3 仿真与分析
3.1 实验数据
通过单标签文本数据集20NewsGroup和5AbstractsGroup对改进的文本表示模型进行验证。20NewsGroup数据集有多个不同的版本,是文本任务中经常使用的标准数据集,有20个类别的新闻文档,包含rec.autos、sci.space、misc.forsale等;5AbstractsGroup数据集为商业、人工智能、社会学、运输和法律等5个不同领域收集的学术论文。

表 1 单标签文本数据集信息统计
3.2 实验设置
1) 参数设置。实验在Linux系统中使用python语言实现,在Tensorflow框架下完成对文本表示模型性能的测试。参照Glove文本表示模型进行参数设置,并通过实验反复验证,最终设置本文模型主要参数的取值,实验参数设置见表2。

表 2 实验参数设置
2) 评价指标。采用文本分类中常用的准确率P、召回率R、F1值对文本分类结果进行评价,其中TP、FP、TN和FN分别代表正阳性、假阳性、正阴性和假阴性的分类数量。各评价指标的计算为
(23)
针对不同维度的词向量,分别对20NewsGroup和5AbstractsGroup 2个数据集进行实验,并与文本表示模型TF-IDF、N-Gram、Glove进行对比,用SVM分类器验证改进的模型性能。
3.3 模型性能验证
实验1使用数据集20NewsGroup对提出的改进文本表示模型进行验证。20NewsGroup数据集不同维度分类结果对比见表3。

表 3 20NewsGroup数据集不同维度分类结果对比
从表3可以看出:针对20NewsGroup数据集提出的文本表示模型中,TN-Glove模型的分类效果最好,获取文本隐藏信息的能力最强,TG模型次之,NG模型最差。分类效果会随着词向量的变化而变化,当利用TG模型对20NewsGroup数据集进行分类且词向量维度为300时,分类准确率和F1值较高;用NG模型进行分类,当词向量维度为300时,F1值略低于200维,其他指标都最高;用TN-Glove模型进行分类,当词向量维度为300时,评价指标都相对较高,因此词向量的维度取300。通过上述分析可得,TG、NG、TN-Glove模型可以有效地对文本信息进行表示,改善文本分类效果。
分别从TG、NG、TN-Glove 3种方案中选取300维词向量的结果用于对比,20NewsGroup数据集不同模型对比见表4。

表 4 20NewsGroup数据集不同模型对比
表4为TF-IDF、N-Gram和Glove 3种文本表示方法与论文的TG、NG、TN-Glove模型的对比结果。通过对比,本文提出的TG、NG、TN-Glove 3种文本表示模型,对20NewsGroup数据集的分类结果均优于常用的文本表示方法。因此,本文提出的TG、NG、TN-Glove模型可获取文本中的隐藏信息,更好地表征文本特征信息,提高文本的分类结果。
实验2使用数据集5AbstractsGroup验证改进的文本表示模型。5AbstractsGroup数据集不同维度分类结果对比见表5。

表 5 5AbstractsGroup数据集不同维度分类结果对比
从表5可以看出,针对5AbstractsGroup数据集,本文提出的TG、NG和TN-Glove 3种模型中,TN-Glove模型分类效果最好。词向量维度不同,分类效果也有稍许差距。当词向量维度为300时,用NG和TN-Glove模型进行分类,评价指标都相对较高。而用TG模型分类,当词向量维度为300时,指标召回率略低于500维,其他指标都为最高。通过数据分析发现,本文提出的文本表示模型可以更好地学习文本特征信息,改善文本分类效果。
和实验1采取一样的对比方法,选取TG、NG、TN-Glove模型中性能较好的300维词向量的实验结果作为对比,5AbstractsGroup数据集不同模型对比见表6。

表 6 5AbstractsGroup数据集不同模型对比
从表6可以看出,对比TF-IDF、N-Gram和Glove 3种模型,本文提出的TN-Glove模型分类效果均优于对比实验。虽然TG、NG模型的准确率低于Glove模型,但召回率和F1值相对有所提高。可见本文表示模型对文本信息准确表征,改善了分类效果。
综上可述,本文提出的TN-Glove文本表示模型,结合各种文本表示方法,对文本中隐藏特征进行了有效提取。
4 结 论
1) TN-Glove表示模型通过结合TF-IDF和N-Gram 2种文本表示的优点,不仅能更好地捕捉词与词之间的关联信息,获取文本的语义和语序信息,还能通过词共现矩阵掌握文本的全局信息,对类别区分能力较强的词进行保留。
2) TN-Glove文本表示方法可对文本特征信息有效表达,但本文模型只是从词一个方面获取文本特征。在以后的研究中,在保证训练速度的前提下,可从字符和词2个角度对文本特征信息进行获取,对RNN模型的文本表示性能进行研究。
