
基于人工神经网络技术构建围术期病人低体温风险预测模型
2022-03-17 07:23项海燕黄立峰朱锋杰
护理研究 2022年5期
项海燕,黄立峰,朱锋杰,张 浩
浙江大学医学院附属第二医院,浙江 310009
围术期低体温又称围术期非计划性低体温(inadvertent/unplanned perioperative hypothermia,IPH),指围术期内发生的非计划性的体温下降,核心温度低于36 ℃,但不包括治疗性或计划性的低体温[1]。IPH 可引起寒战、心血管系统风险、感染风险增加、麻醉苏醒延迟、凝血功能障碍等不良后果[2-4],是手术常见的并发症之一[5]。科学评估和早期预防是降低IPH 发生率的最有效措施[6]。预测模型(prediction model,PM)是临床决策支持中用于个体风险预测的有效工具,可以将复杂的临床指证转化为数据模型,辅助医护人员有效筛查、识别目标人群中的高危人群[7]。虽然已有使用回归模型函数模拟IPH 的预测模型,但其理论方法的局限和预测对象覆盖范围的局限[8],影响临床使用。基于深度学习的人工神经网络(artificial neural network,ANN)模型,不需要精确的数学假设,对研究数据本身的分布类型无任何分布要求,其处理非线性问题的能力也较传统的多元回归统计方法要强大[9]。由临床实践可知,IPH 的发生与各相关因素之间不是简单的线性关系,各因素之间也存在多重共线性,例如麻醉因素、手术因素和自身基础情况的相互影响关系。因此,本研究认为ANN 技术是适合于IPH 和其影响因素之间数据联系建模的方法。本研究回顾性收集临床病例数据,通过循证和临床相结合的方式筛选出IPH 的建模变量,基于ANN 新技术构建预测模型,并测试统计其相关性能指标,为科学预测IPH 提供一种新的建模思路,提高预测模型的临床适用性。
1 资料与方法
1.1 临床资料
1.1.1 收集数据 本研究经医院伦理委员会审核,收集某三级甲等医院2016 年1 月—2020 年9 月近5 年有围术期体温监测的手术病人相关数据,统一从医院电子病历系统和麻醉监测系统提取,总计107 386 例。纳入标准:术前体温正常;基础代谢正常;静脉全身麻醉病人(气管插管)。排除标准:因手术需要术中实施低体温的病人(如体外循环手术);围术期体温监测不全的病人;术前进行主动加温干预的病人。剔除标准:数据记录明显异常(因医护人员输入错误等引起,不符合人类临床特征)的病人;基础数据不全的病人(如身高、体重等);其他不符合建模要求的个别病例。经过筛选,符合建模要求的病例共19 068 例。
1.1.2 筛选变量 课题组通过检索PubMed、MedLine、Web of Science、中国生物医学文献系统、中国知网、万方数据库等数据库搜集相关文献,检索时限为建库至2020 年9 月30 日。采用澳大利亚Joanna Briggs Institute(JBI)循证中心和Johns Hopkins 标准[10],由2 名课题组成员(经过循证相关课程培训),以互盲方式对搜集的文献进行独立评价。文献的纳入标准:以上数据库收录有关IPH 循证研究的文献。文献的排除标准:非人体试验或相关报道;围术期基础体温有异常者或基础代谢有异常者。通读相关文献,归纳围术期手术病人发生IPH 的风险因素,构建本研究所需的风险因素池,将病例资料中属于风险因素池的风险因素作为建模变量。同时,依据临床经验和观察结果,课题组认为“手术体位”(风险因素池外)较手术器官部位划分(风险因素池内)更具有临床意义,对于IPH 更具有代表性,增加风险因素“手术体位”为变量,其包含平卧位、俯卧位、侧卧位和截石位4 种常见体位;将手术病人术前病房最后一次体温测量作为基础体温(T0),手术过程中监测最低体温为T1,麻醉复苏室时监测到的最低体温为T2,比较T1和T2,较低值为此病人围术期体温的最低值(T3)。其中,对于个别术中需要变换手术体位且不能明确归类“手术体位”的病例,给予剔除。
基于已收集的大数据病例资料变量种类和前期风险因素的筛选工作,最终确定建模变量包括手术病人年龄、身高、性别、美国麻醉医师协会(ASA)评分、体质指数(BMI)、基础体温、术前血压(收缩压和舒张压)、脉搏(心率)、手术时长、麻醉时长、复苏总时间(进出麻醉复苏室时间差)、插管时长(进入复苏室到气管插管拔除的时间)、术中尿量、出血量、输液量、总入量(包括输液和输血)、术前最近1 次血红蛋白(Hb)值、围术期最低体温、手术体位等约20 个风险因素。
1.2 数据预处理 将数据中T3≤36.0 ℃的病例记上低体温标签,依据人工智能深度学习建模要求,将19 068 例数据分成训练集和测试集两部分[11],其中训练集13 349 例,测试集5 719 例(大数据量建模选择7∶3的比例,经过多次随机分割,计算各数据集的基线特征,保证基线资料一致性情况下训练集和测试集的正负样本比例相同,即低体温病例占比相同)。性别、ASA 分级、手术体位为分类变量,采用独热(one-hot)编码[12];其余变量为连续变量,采用z-score 标准化处理,公式为:
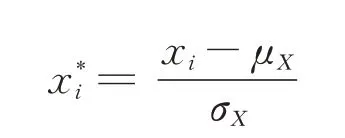
式中,μX是变量X的均值,σX是变量X的标准差,xi是变量X的第i 个取值。
1.3 建模方案 构建多层ANN 模型进行建模。模型包括输入层、隐藏层和输出层。见图1。

图1 深度ANN 结构逻辑图
其中,隐藏层有节点数量为16 和8 的2 层网络层组成(设置多种隐藏层大小,通过参数对比,最后得到16,8 的效果最好)。对二分类问题,模型利用对数损失通过惩罚错误的分类,衡量分类器的准确性。记标签为y,y ∈{0,1}。通过极大似然估计法来估计参数θ,似然函数为:
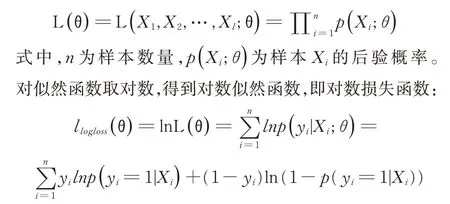
即令每个样本属于其真实标记的概率越大越好。
采用Adam 算法对目标函数进行优化[13],学习率为0.08,beta1=0.9,beta2=0.999,epsilon=10-8。输出层激活函数采用sigmoid[14],其余网络层激活函数采用线性修正单元(Rectified Linear Units,ReLU)[15]。对数据集进行100 次随机划分(通常选择100,500,1000次等,本研究选择100 次即可满足建模需要),得到100 个不同的训练集和测试集,重复进行试验,得到模型性能指标的95%置信区间。
利用知识蒸馏方法[16],将神经网络模型作为复杂模型,训练简单的逻辑回归模型,从而将神经网络从数据中学到的知识迁移到逻辑回归模型中,得到输入特征计算低温风险的函数表达式。
1.4 模型性能检测
1.4.1 预测模型的预测指标(见表1)
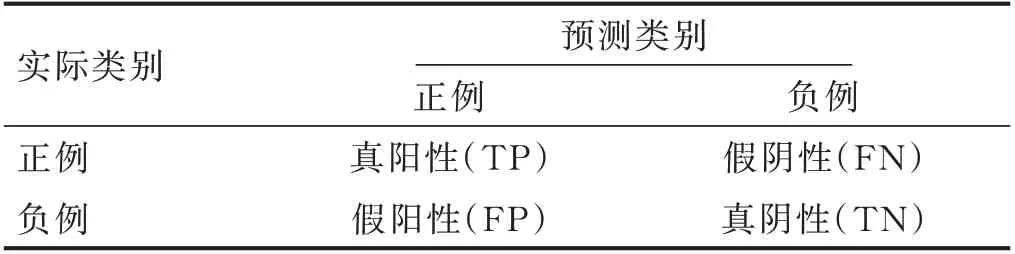
表1 预测模型实际类别和预测类别的关系
准确率表示全体样本中预测正确的样本的占比。一般而言,它的值越大意味着模型性能越好。阳性预测值(positive predictive value,PPV)/精确率(percision)表示被预测为正的样本中正样本的占比。阴性预测值(negative predictive value,NPV)表示被预测为负的样本中负样本的占比,与阳性预测值相对,一般而言,它的值越大意味着模型性能越好。真阳性率(true positive rate,TPR)/敏感度(sensitivity)/召回率(recall)在二分类问题中,真阳性率、敏感度和召回率3 个名词对应着同一个概念,表示正样本中被预测为正样本的占比。真阴性率(true negative rate,TNR)/特异度(specificity)在二分类问题中,真阴性率和特异度对应着同一个概念,表示负样本中被预测为负样本的占比,与真阳性率相对。一般而言,它的值越大意味着模型性能越好。本研究主要比较模型的准确率、阴性预测值和特异度。
1.4.2 预测效度分析 模型的预测效度采用受试者工作特征曲线(receiver operating characteristic curve,ROC)进行分析。分别用训练集和测试集计算ROC曲线及曲线下面积(area under curve,AUC)。通常认为,AUC>0.5,说明模型预测效度大于随机概率,越接近1,预测效度越好。
1.4.3 决策曲线分析 本研究采用决策曲线分析方法评估模型的临床实用性[17]。决策曲线以概率阈值为横坐标,以净收益(net benefit)为纵坐标绘制。净收益将模型的利弊与风险阈值结合起来,量化衡量模型对辅助决策带来的临床效用。净收益的计算公式如下[18]:
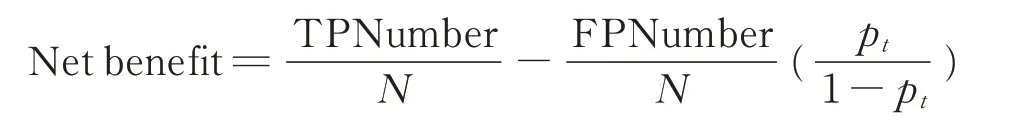
式中,Net benefit 为净收益,TPNumber 为真阳性病人数量,FPNumber 为假阳性病人数量,N为病人数量,pt为概率阈值。当模型预测风险大于概率阈值时,就界定样本为正例;否则,界定样本为负例。
决策曲线以概率阈值为横坐标,净收益为纵坐标绘制曲线。分别假设所有病人为正例和负例,得到两条决策曲线作为临床实用性比较的参照。如果模型的决策曲线在两条决策曲线的右上方,则模型的临床实用性优于随机方案,不会在临床使用中产生有害影响。
1.5 统计学方法 本研究使用Excel 2016 建立数据库。分类变量和连续变量分别采用独热编码和z-score标准化进行预处理。利用χ2检验比较分类变量分布之间的差异,利用t检验比较连续变量均值之间的差异。模型的性能检测使用准确率、阳性预测值、阴性预测值、敏感度、特异度及AUC 进行分析。所有的分析都使用R 版本4.0.2 和R 包进行[19],其中,神经网络模型采用H2O 包实现。
2 结果
2.1 数据资料基线特征比较
2.1.1 IPH 病人和正常病人的基线特征比较 统计发现,IPH 病人和体温正常病人在年龄、性别、ASA 评分、体重、身高、术前体温、舒张压、脉搏、尿量、输液量、手术时间、复苏时间、麻醉苏醒时间、BMI、Hb 和手术体位等方面差异均有统计学意义(P<0.05),说明两组病人的基线特征存在明显差异,如IPH 组病人年龄较大、身材偏瘦等。见表2。本研究筛选出的20 个变量整体对于IPH 的敏感度较好,超过50%的变量指标P≤0.001,这些变量能够反映IPH 病人的基线特征。可以推论,用这些变量指标构建的模型对于IPH会有较好的预测性能。
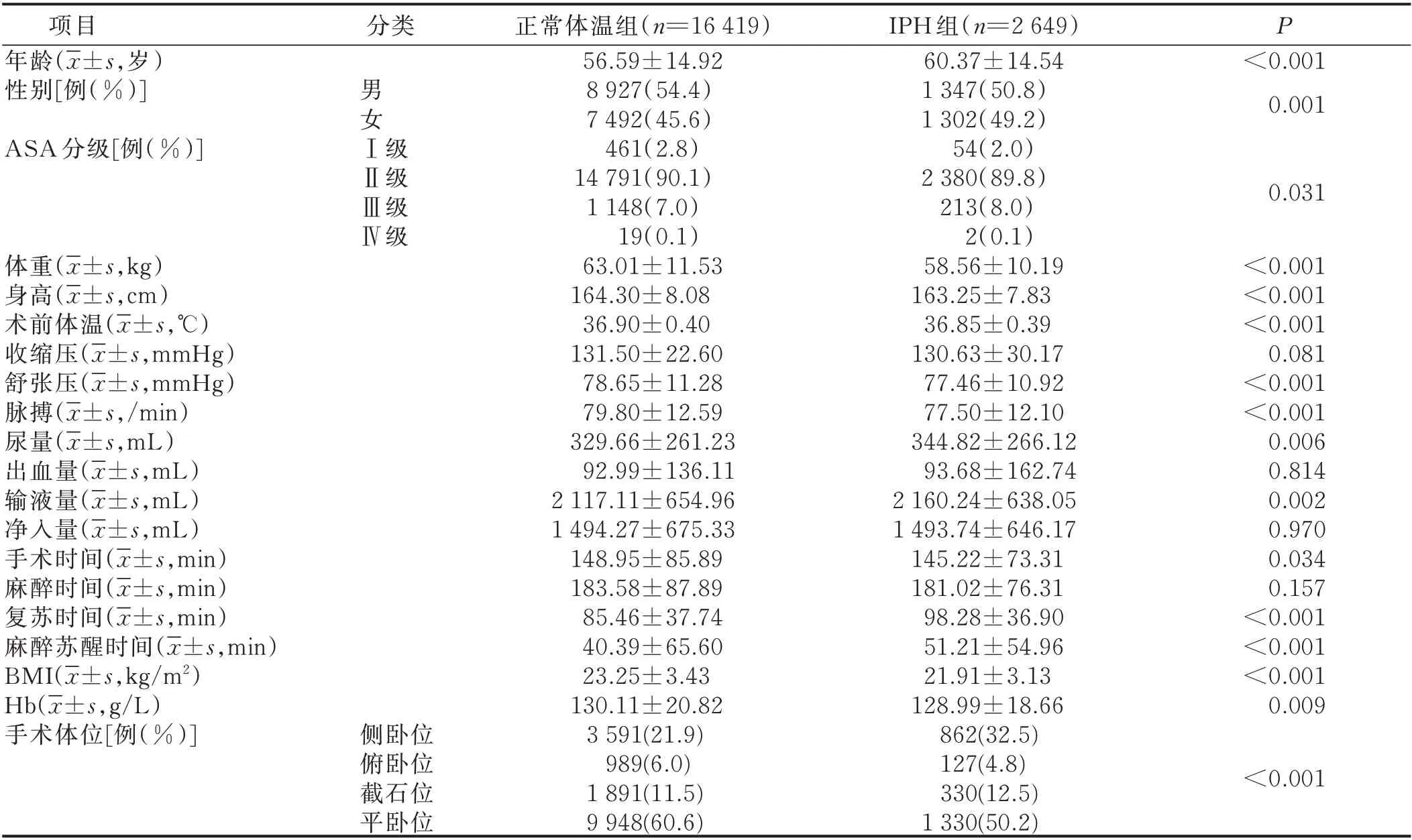
表2 IPH 病人和正常病人的基线特征比较
2.1.2 训练集和测试集病人的基线特征比较 训练集和测试集的病人基线资料比较差异无统计学意义(P>0.05),即两组病例资料的基线特征一致,具有可比性。见表3。
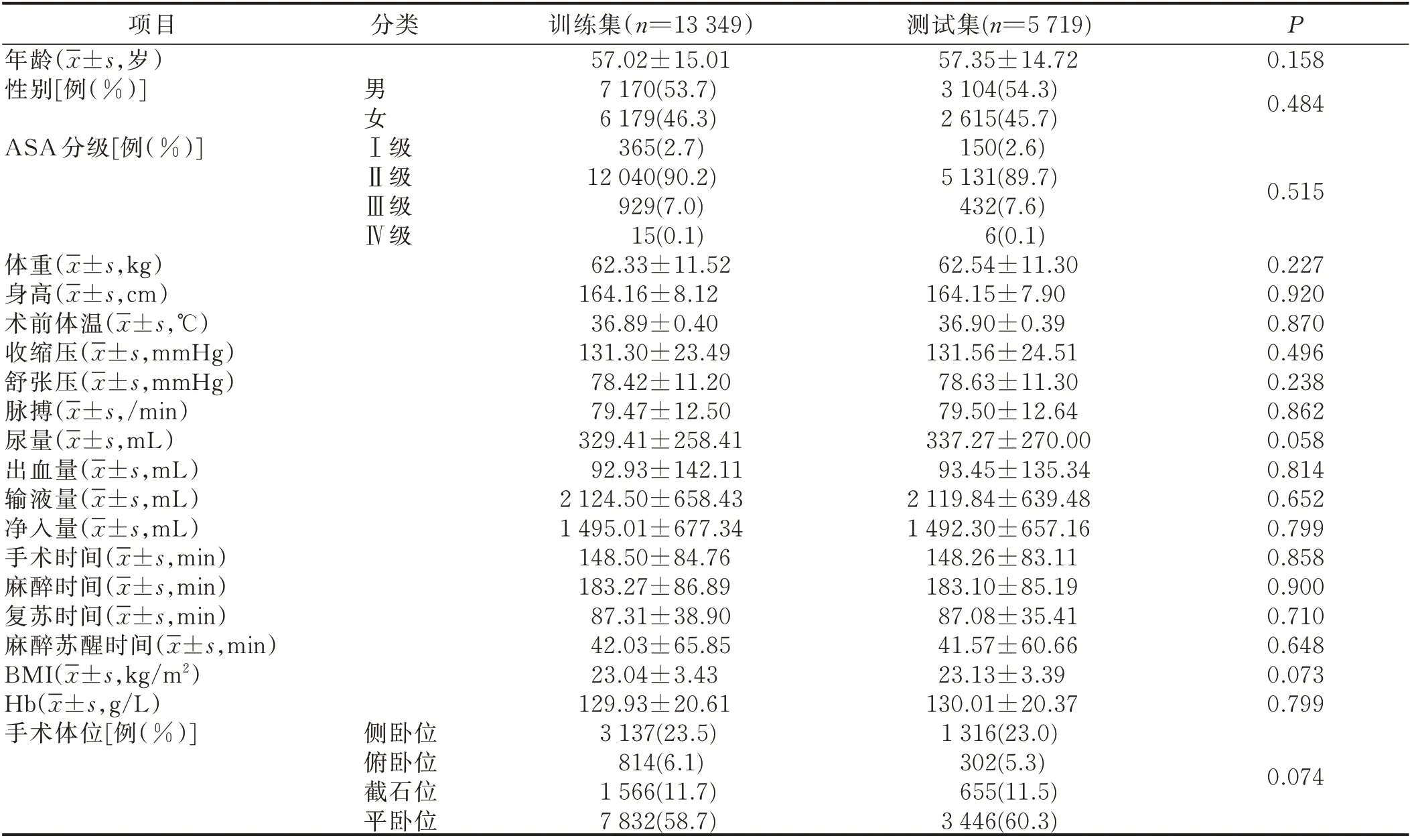
表3 训练集和测试集病人的基线特征比较
2.2 模型训练结果 基于知识蒸馏方法,将建模结果迁移到逻辑回归模型中,得到关于IPH 的建模函数表达式。通过分析发现,病人的性别(女)、ASA 分级、体重、净入量、手术体位等变量(数据归一化)对IPH 的发生有较大影响。

2.3 模型性能测试结果
2.3.1 准确率 统计发现,训练集和测试集的准确率均>75%,临床适用性较好;特异度均>0.8,认为此模型对于IPH 的特异度较高,符合建模预期。相关性能指标见表4。
表4 模型的各性能指标测试结果(±s)

表4 模型的各性能指标测试结果(±s)
项目训练集测试集准确率0.780 4±0.013 6 0.778 1±0.027 1阳性预测值0.256 9±0.012 0 0.231 2±0.025 5阴性预测值0.912 9±0.002 4 0.901 2±0.004 8敏感度0.516 4±0.026 4 0.364 0±0.052 6特异度0.823 0±0.020 0 0.844 9±0.039 6 AUC 0.724 3±0.008 6 0.700 3±0.009 3
2.3.2 预测模型的ROC 曲线 由表4 及图2、图3 可知,训练集的AUC为0.724 3,测试集的AUC为0.700 3,两者的0.5<AUC<1,说明此模型优于随机猜测,具有预测价值。
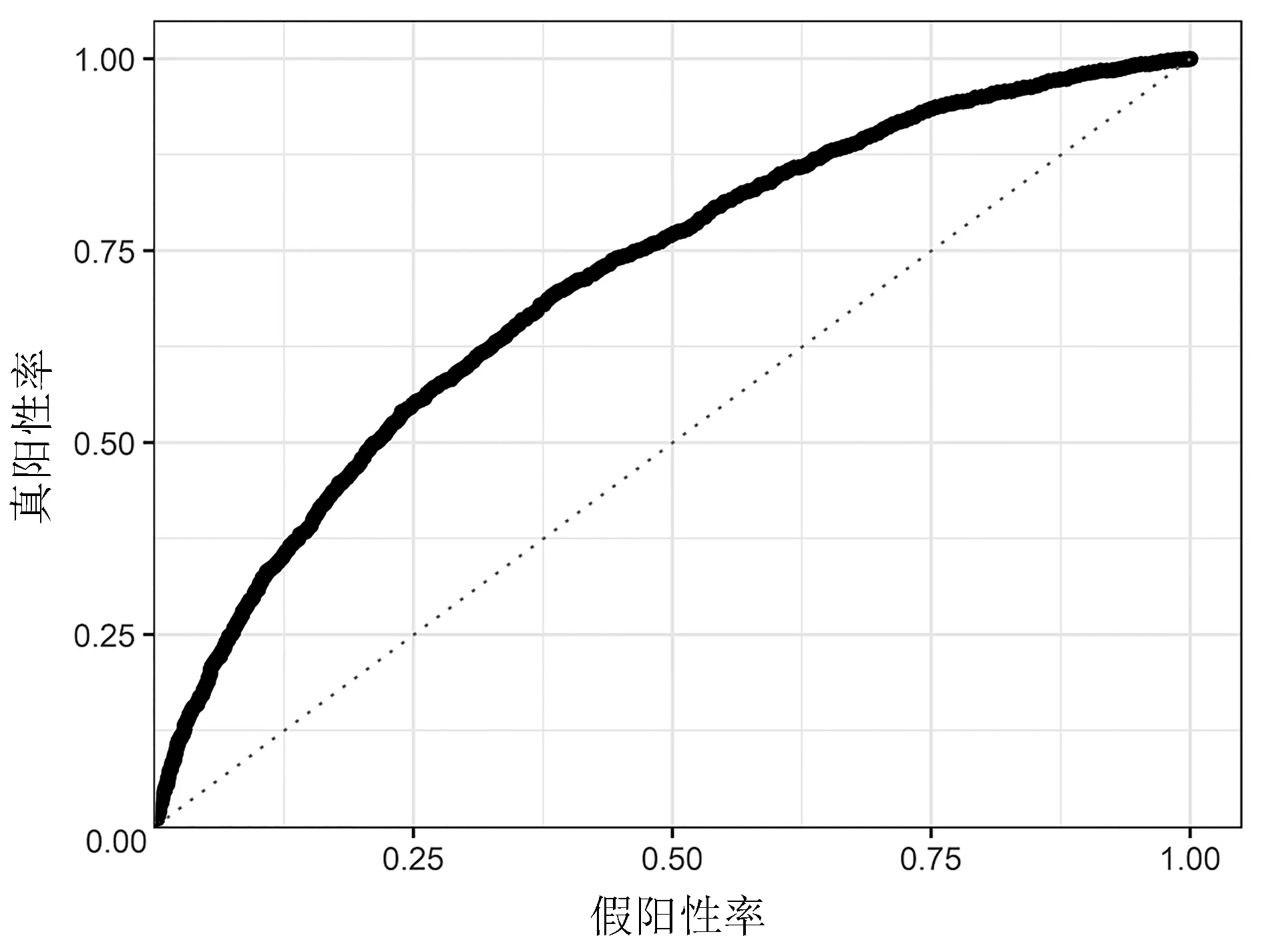
图2 训练集的ROC 曲线图
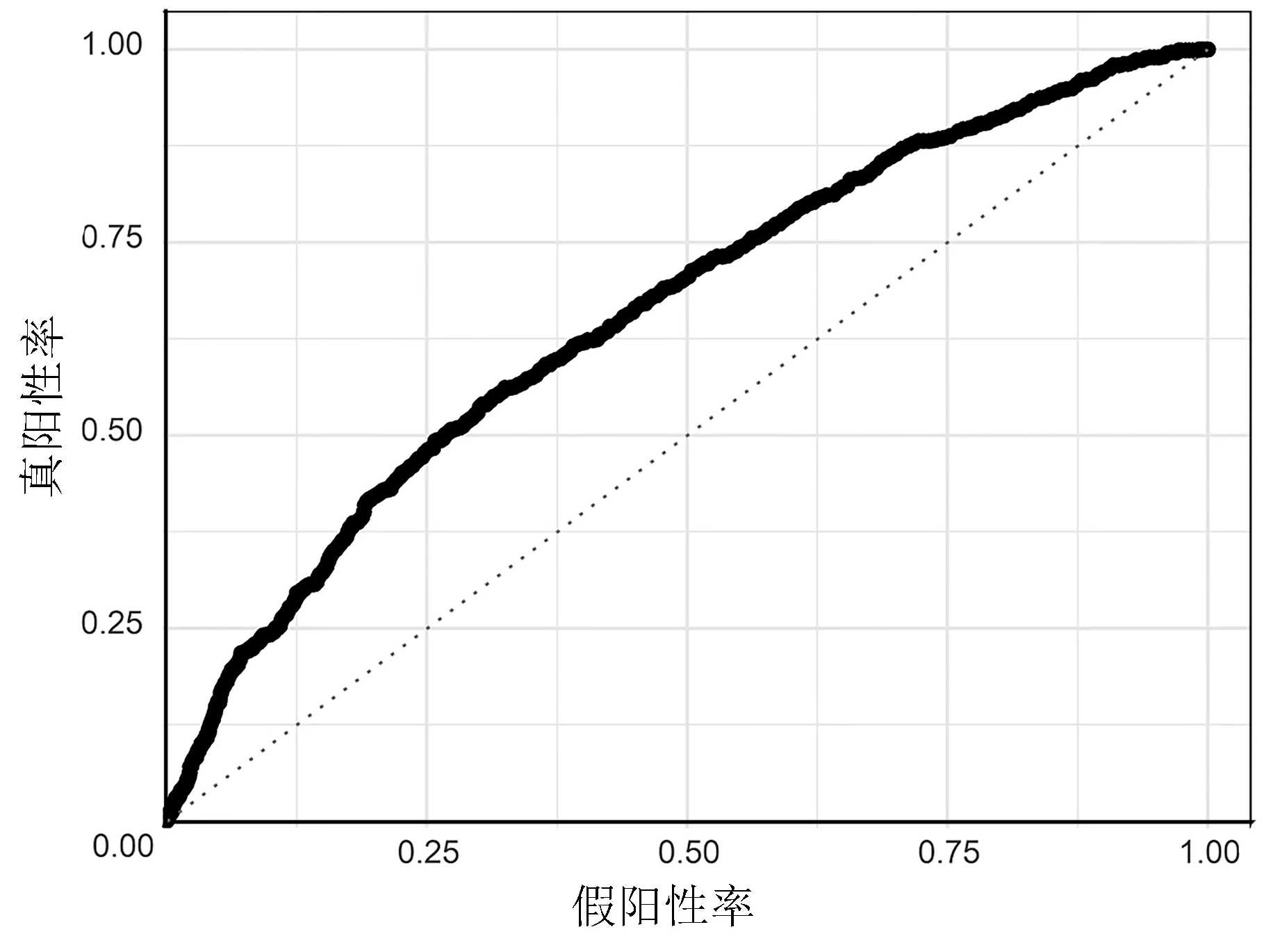
图3 测试集的ROC 曲线图
2.3.3 决策曲线分析 由图4 可知,模型的决策曲线在两条决策曲线的右上方,模型的临床实用性优于随机方案,较适合临床使用,符合建模预期。
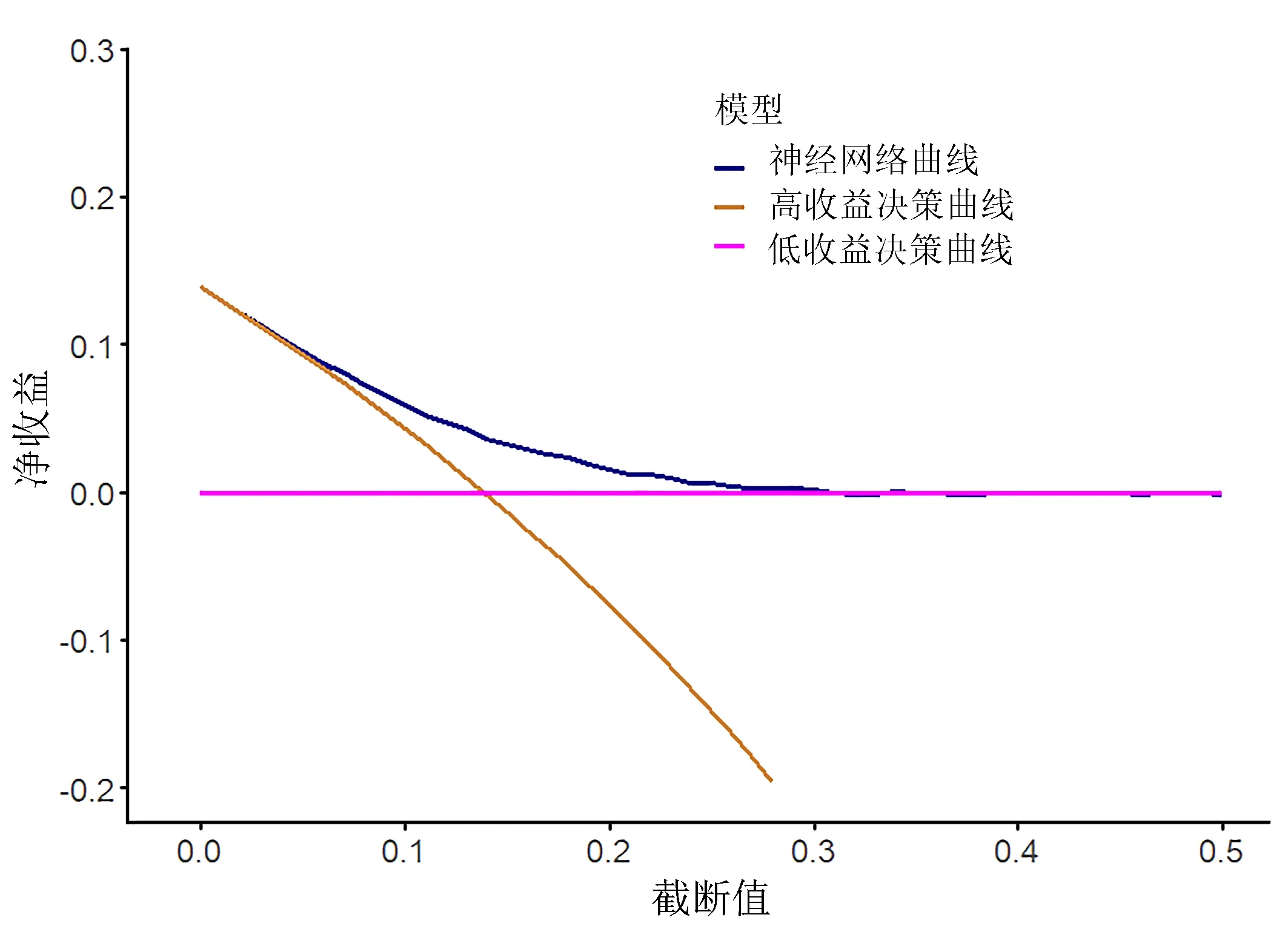
图4 预测模型的决策曲线
3 讨论
3.1 ANN 技术的特性适合IPH 的模型研究,基于大数据使其具有普适性 多元线性回归、Logistic 回归或Cox 回归模型等方法是目前医学领域中对于多变量研究常采用的建模类型。但以上方法对资料分布和类型有着较为严格的要求,影响其结果的适用性,有一定的局限。例如,有研究团队对IPH 进行回归分析下的模型研究,但其对年龄、手术类别等有较大限制,预测的准确率也有待验证检测[8],难以推广。目前,新兴的ANN 技术基于人工智能的深度学习理论,对资料类型和分布无特殊要求,具有良好的非线性处理能力、强大的容错性、较高的分类精确度等优点[11]。它在分析自变量和因变量之间复杂的非线性关系时,能够从训练集中挖掘规律,并给出具有确定算法与结构参数的网络结构,这对那些根本不能找到或模拟出准确数学表达公式的变量关系提供了新的思路。而医学领域的生理病理模型,从生物内外环境的复杂性来说,是一个综合体系,传统回归模型以统计和概率的方式筛选主要变量后建立函数模型,容易忽略其他次要变量隐含的影响。将ANN 技术用于IPH 的预测模型研究,可以充分利用各种变量之间的关系挖掘规律,避免了传统回归模型中可能存在的问题。
同时,ANN 技术的使用是基于大数据病例资料的计算,而通过大数据构建的预测模型通常其准确率和适用性都要优于小数据下的预测模型,大数据模型有更好的容错性和普适性。本研究预测模型的准确率>75%,且适用范围涵盖绝大部分全身麻醉手术病人(体外循环手术除外),较已报道的预测模型[8]更具有普适性。
3.2 预测模型性能检验结果良好,具有实用价值 从统计结果可知,本次ANN 技术建模的结果反映此预测模型的综合性能较好,其覆盖范围广(使用局限小)、良好以上(预测准确率>75%,特异性>0.8)的性能使其推广应用具有可行性。ROC 曲线分析结果显示,神经网络模型对低体温风险预测的AUC 为0.724 3,最佳临界点为0.175,对应特异度为0.823 0。在测试集上的AUC 为0.700 3,对应特异度为0.844 9。在临床实用性评价方面,图3 中预测曲线大部分完全处于两条决策线的右上区域或重叠,说明本次建模的预测模型具有较好的临床实用性。从以上几个主要反映预测模型性能的指标判断,基于ANN 技术的IPH 预测模型具有良好的性能,适合临床使用。
3.3 本研究的意义、局限与展望 本研究使用ANN的新方法来建立IPH 的预测模型,为临床科学预测IPH 提供了一种新的建模思路,是人工智能技术服务于临床护理的跨领域运用。研究结果显示,其模型具有良好的临床使用价值,可信度较好,在普适性上优于已有的研究报道结果,能够更加科学、有效地预测IPH的发生,为临床护理提供指导。
由于本研究是回顾性数据分析,虽然依托于电子病历系统和信息化技术较方便地收集了大量病例数据资料,但受限于资料完整性和监测数据收集种类,加上对于IPH 的风险因素的临床认知和研究还未完全透彻,不能完全搜罗自然状态下围术期病人发生IPH 的各个变量,从而影响预测模型的准确率。随着医护人员对于IPH 相关问题研究的不断深入和拓展,未来或许会发现更多的影响变量,能使构建的预测模型更接近临床。另外,随着信息化的普及,数据收集更加方便,数据种类更丰富,基于多中心的大数据建模也会提高预测模型的适用性。
猜你喜欢
中老年保健(2022年5期)2022-11-25
成都信息工程大学学报(2021年5期)2021-12-30
中学生数理化·中考版(2021年8期)2021-07-31
小学生学习指导(高年级)(2021年4期)2021-04-29
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
华声文萃(2020年4期)2020-05-19
党的生活(黑龙江)(2020年3期)2020-04-22
初中生世界·九年级(2020年2期)2020-04-10
电子制作(2018年17期)2018-09-28
晚晴(2016年11期)2016-12-20
