
改进的基于锚点的三维手部姿态估计网络
2022-04-12 09:25危德健王文明王全玉任好盼高彦彦王志
计算机应用 2022年3期
危德健,王文明,王全玉,任好盼,高彦彦,王志
(北京理工大学计算机学院,北京 100081)
0 引言
高效准确的3D 手部姿态估计在人机交互应用中非常重要,如虚拟现实和增强现实。随着深度相机和深度学习的快速发展,3D 手部姿态估计的准确度和速度在近年来都有不少提高,不过由于手部姿态的丰富性、不同关节点的相似性、自遮挡等问题,3D手部姿态估计仍然是一个有挑战的问题[1]。
深度图给出了被摄物体到摄像机的距离信息,相较于彩色(RGB)图,深度图对光照变化、阴影具有较高的鲁棒性。基于深度图的3D 手部姿态估计方法可以分成3 类:1)将深度图当作2D 图像,利用2D 卷积神经网络(Convolutional Neural Network,CNN)进行3D 手部姿态估计;2)将深度图转化为3D体素,使用3D CNN进行3D手部姿态估计;3)将深度图转化为点云数据,使用点云网络进行3D手部姿态估计。
将深度图转化成体素或点云,利用3D CNN 或点云网络可以更好地捕获3D 空间信息。Ge 等[2]利用3D CNN 进行手部姿态估计,利用基于截断的带符号距离函数(Truncated Signed Distance Function,TSDF)方法[3]将深度图转换为体素,使用3D CNN 预测关键点3D 坐标。Moon 等[4]提出的3D CNN 输出的不是关键点坐标,而是体素热图(Voxel Heatmap),通过取最大值的方法得到3D 关键点坐标。Ge等[5]最早使用PointNet 和点云数据估计3D 手部姿态,先将深度图转换为点云,经过下采样和归一化后输入给堆叠了两层PointNet 的网络,输出热图和单位矢量场,热图表示点到关键点的距离,单位矢量场表示点到关键点的方向,通过加权求和的方式计算关键点坐标。
基于体素的方法需要耗时的体素化过程,3D CNN 参数量大、计算速度较慢;基于点云的方法需要耗时的点云化过程,使用2D CNN 处理深度图的效率较高。Tompson 等[6]最早利用CNN 进行3D 手部姿态估计,网络的输出不是关键点坐标,而是表示关键点分布概率的热图,通过取最大值的方式得到2D 关键点坐标后,利用逆运动学结合深度值计算出3D关键点坐标。只采用单张深度图估计3D 手部姿态本质上是一个病态问题(Ill-posed Problem),因为手部姿态和对应的投影不一定一一对应,使用多个视角的图像可以解决此问题,但需要设置多台相机,相机之间校准麻烦,用户的活动范围也受到较大限制。Ge 等[7]将单张深度图转换为点云数据,投影到多个视图上,从而得到多个视角信息,利用多视图CNN生成不同视图的热图,从而提高3D 关键点估计的准确度。
根据网络输出类型可以分为基于回归(Regression Based)的方法和基于检测(Detection Based)的方法:基于回归的方法输出关键点坐标;基于检测的方法输出密集的估计,比如热图或者偏差向量(Offset Vector)。基于回归的方法准确度不高,基于检测的方法常用运算速度慢的反卷积提高特征图的分辨率,并且网络无法端到端训练。文献[8]中详细论述了基于回归的方法和基于检测的方法之间的关系,提出了使用取期望的后处理方式将两种方法结合以提高准确度。A2J(Anchor-to-Joint)[9]的思路与文献[8]一致,将基于检测的方法和基于回归的方法结合起来。A2J 包含两个步骤:1)在图上均匀设置锚点,先估计出锚点坐标到关键点坐标的偏差以及锚点的响应,锚点的坐标加上锚点坐标到关键点坐标的偏差,即为关键点坐标;2)使用可微分的softmax 函数将锚点的响应转化为锚点的权重,对偏差和权重用加权求和的方式计算得到关键点坐标。步骤1)输出密集的估计,步骤2)输出关键点坐标。但是A2J 的网络结构和损失函数设计不恰当,影响了网络估计结果的准确度;网络分支存在冗余层,影响网络的效率。
针对这些问题,本文提出了更加高效准确的HigherA2J网络,合并XY偏差估计分支和Z偏差估计分支,更好地利用深度图的3D 信息;去除网络分支中的冗余层,减少网络参数量,提高运行速度;设计关键点估计损失函数,去掉锚点围绕损失,增加偏差估计损失,更好地指导网络的学习。通过实验论证了HigherA2J 的准确度较高,运行速度较快。
1 HigherA2J回归网络
图1 是A2J 的网络结构,A2J 包含1 个骨干网络和3 个分支,骨干网络使用深度残差网络ResNet50[10],XY偏差估计分支预测锚点与关键点在图像平面坐标轴XY上的偏差,Z偏差估计分支预测锚点与关键点在深度坐标轴Z上的偏差,锚点响应估计分支预测锚点的响应强度。这3 个分支都采用相同的实现方式,包含4 个卷积核为3×3 的卷积层,每个卷积层后都有批归一化层(Batch Normalization,BN)和ReLU(Rectified Linear Unit,ReLU)激活函数。
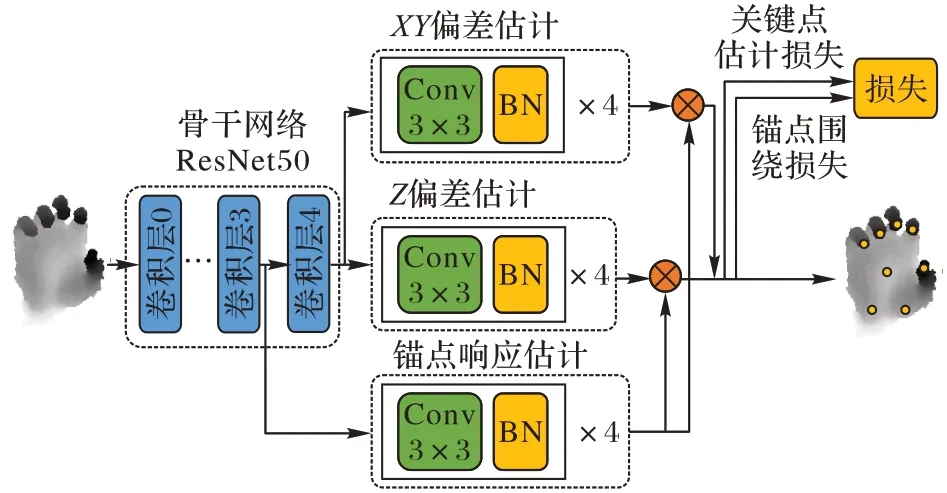
图1 A2J的网络结构Fig.1 Network structure of A2J
A2J 的网络结构存在的不足与解决办法如下:
1)3D 手部姿态估计计算手部关键点的3D 坐标A2J 将坐标的XY值和坐标的Z值分别用XY偏差估计分支和Z偏差估计分支计算,没有很好地利用深度图的3D特征。解决办法是将XY偏差估计分支和Z偏差估计分支合并为一个分支,即XYZ偏差估计分支,关键点坐标估计准确度得以提高。
2)偏差和响应的关系比较直观,偏差越小的锚点,响应强度越大,赋予的权重就越高,因为离关键点越近的锚点估计的可信度更高。在A2J 网络中,偏差估计分支的起始位置是骨干网络ResNet50 的卷积层4,锚点响应估计分支的起始位置是骨干网络ResNet50 的卷积层3,偏差估计分支的网络层更多,将学到更加丰富的特征,而这对于偏差和响应之间这种简单的关系没必要。解决办法是将锚点响应估计分支的起始位置也设置为骨干网络ResNet50 的卷积层4。
3)偏差和响应分支各包含8 个网络层(4 层卷积层+4 层BN 层),按照正态分布初始化权值,而骨干网络ResNet50 使用在ImageNet 上预训练的模型作为初始权值,所以骨干网络ResNet50 具有更强的视觉捕捉能力。偏差估计分支和响应估计分支的视觉捕捉能力不如骨干网络,影响网络训练的收敛速度。实验结果表明可以将分支的8 个网络层简化为用1个卷积核为3×3 的卷积层替代,使网络更快收敛。
对A2J 的网络结构进行以上修改,得到了HigherA2J 的网络结构,如图2 所示。
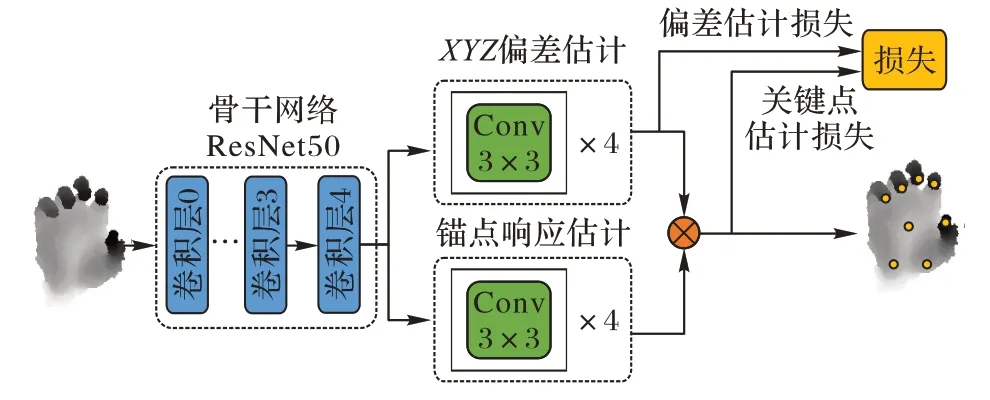
图2 HigherA2J的网络结构Fig.2 Network structure of HigherA2J
表1 展示了本文使用的符号。HigherA2J 由1 个2D CNN骨干网络ResNet50 和偏差估计分支、响应估计分支组成,两个分支分别预测了O(a,j)和P(a,j)。
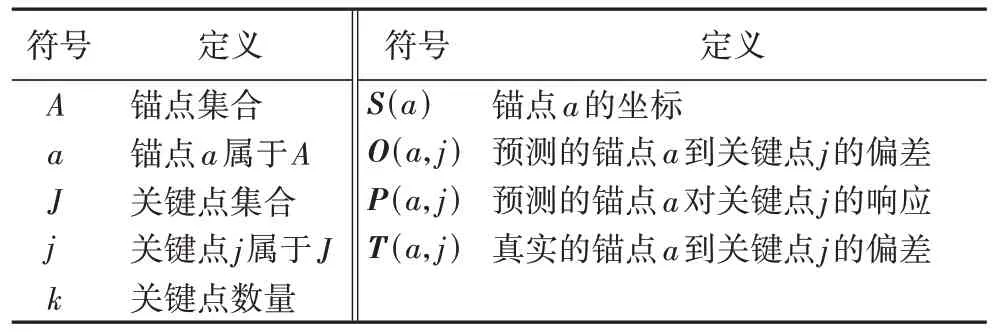
表1 符号定义Tab.1 Symbol definition
在图像上每隔16 个像素就设置1 个锚点,如图3 所示。每个锚点都预测了到所有关键点的偏差,偏差加上锚点本身的坐标即可得到关键点坐标,因此锚点可以看成是一种局部回归器。对于每个关键点来说,将所有锚点对它坐标的预测进行聚合得到最终的预测坐标。因为每个锚点的贡献程度不一样,响应估计分支估计每个锚点的响应,并通过softmax函数计算锚点权重。偏差的估计包含一定不确定性,加权求和的聚合方式可以减轻这种不确定性。关键点j的三维坐标可以通过将所有锚点对它估计的偏差和锚点权重进行加权求和得到:
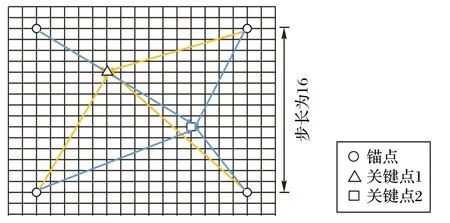
图3 锚点与关键点的关系Fig.3 Relationship between anchor points and key points
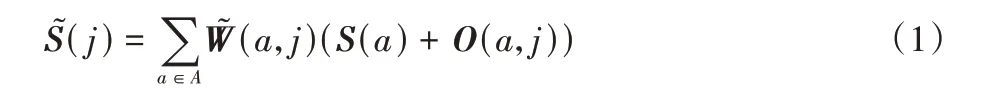
式中:(j)表示预测的关键点坐标,(a,j)是标准化后的权重,表示锚点a对于关键点j的权重。使用softmax 函数将所有锚点对关键点j的响应标准化得到(a,j),如式(2)所示:

1.1 骨干网络架构
卷积神经网络在图像分类、物体识别、目标跟踪等问题上展示了很强的能力。卷积神经网络由许多卷积层组成,每一层卷积层都输出对应的特征图作为下一层卷积层的输入,网络从浅到深不同的卷积层所学习的特征也是从低到高,因此可以通过增加网络深度来提取更加丰富的特征。然而实际上随着网络深度的加深,梯度消失、梯度爆炸的问题开始出现,反而降低了网络的准确度。He 等[10]提出的深度残差网络(ResNet)使得训练更深的网络成为了可能,深度残差网络在传统的前向传播基础上,增加可以跳过某些层的跃层连接(Shortcut Connection),利用这种方式构建的网络在实践中证明了ResNet 强大的学习能力。
深度残差网络是由卷积层单元构成,每个卷积层单元包含几个卷积层,假设卷积层单元输入为x,单元输出为H(x),传统网络直接拟合H(x),但是 ResNet认为H(x)=x+F(x),因此单元学习的就是F(x),称为残差。这样设计的好处是当x已经是最优结果时,单元学习的F(x)就会趋近于0,即使网络继续加深,也不会使结果变得更差。因此本文采用深度残差网络作为HigherA2J 的骨干网络。
HigherA2J 使用2D CNN ResNet50 作为骨干网络的一个优势便是可以利用丰富的RGB 数据对网络进行预训练,比如ImageNet 数据集。实践证明使用在ImageNet 数据集上预训练的模型具有更强的视觉特征捕捉能力,可以帮助网络更快收敛,降低误差。
为了更好地将ResNet 用于基于锚点的手部姿态估计任务,对ResNet 进行一些修改。将ResNet 网络的卷积层4 输出的特征图大小改为输入深度图的1/16 不是1/32,更好地保留了空间关系。将卷积层4 的卷积修改为dilation=2 的扩展卷积,以增大感受野。
1.2 偏差估计分支
偏差估计分支预测锚点到关键点的偏差O(a,j),如图4所示。该分支只使用一个卷积核为3×3 的卷积层,不会改变特征图的大小。因为输出特征图的大小是输入深度图的1/16,所以锚点分布为每隔16 个像素设置一个锚点。假设要预测k个关键点坐标,那么输出特征图的通道数为k× 3。
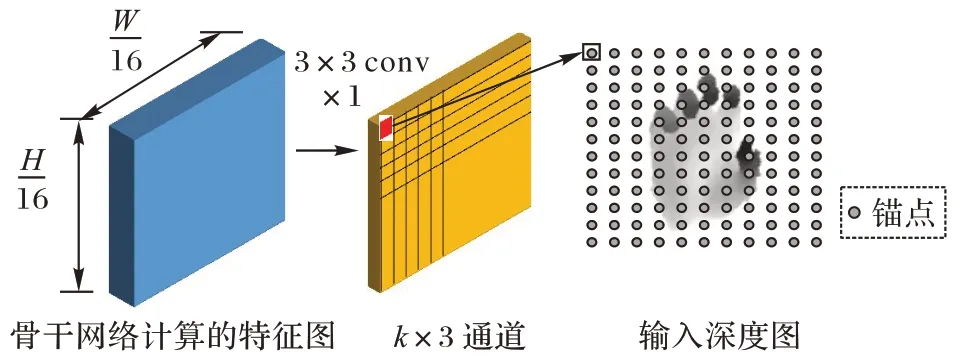
图4 偏差估计分支Fig.4 Offset estimation branch
1.3 锚点响应分支
虽然偏差估计分支估计每个锚点到所有关键点的偏差,可以通过求平均的方式得到关键点坐标,但是因为每个锚点的估计可信度不一样,离关键点越近的锚点估计可信度越高,应该给它赋予更高的权重,而不是简单求平均。因此使用锚点响应估计分支,给每个锚点赋予不同权重,降低偏差估计结果中的噪声,提高估计准确度。
另外许多基于检测的方法在对估计结果进行聚合时,会限制权重分布为固定大小,比如基于高斯热图的方法会限制生成的高斯块的大小,基于偏差向量的方法会限制候选点的分布范围或者数量,以避免相关性小的点影响估计准确度。这些方法会导致网络泛化性变差,并且当关键点周围的深度值缺失时,估计准确度下降。与文献[11]相似,本文设计的锚点响应估计分支,不限制锚点范围,所有锚点都参与了关键点位置的估计,并且锚点的分布是每隔16 个像素设置一个锚点,当深度图中部分深度值缺失时,也不会影响到估计准确度。
锚点响应估计分支预测锚点的响应P(a,j)。锚点响应估计分支和偏差估计分支几乎一样,唯一区别是锚点响应分支输出特征图的通道数为k× 1,而偏差估计分支输出特征图的通道数为k× 3。估计出的锚点响应会通过softmax 函数转变为锚点权重。
2 HigherA2J学习过程
2.1 数据预处理
手部在深度图中通常只占比较小的区域,因此首先需要找到深度图中的手部区域,裁剪出来后缩放到固定的大小作为HigherA2J 网络的输入。为了确定手部位置,可以使用COM(Center Of Mass)方法根据深度阈值计算手部中心点位置,不过该方法在背景杂乱时容易出错,出现只检测到部分手部的情况,为了提高准确度,按照文献[4]的方法,先使用COM 方法计算初始手部中心点,将手部区域裁剪出来;再训练一个2D 卷积网络,该网络以裁剪后的手部深度图作为输入,计算初始手部中心点到真实手部中心点的偏差,得到更准确的手部中心点坐标。
找到手部中心点后,使用中心点裁剪手部区域,将裁剪后的图像缩放成正方形图像作为HigherA2J 网络的输入。对于关键点j,Q(j)表示关键点j在裁剪后图像上的真实图像坐标,包含3 个值,分别使用Q(j,x)、Q(j,y)和Q(j,z)表示。为了使用一个分支预测Q(j),需要将Q(j)的三个值统一到可比较的维度。假设手部中心点的深度值为C,先将Q(j,z)减去C。假设缩放后的图像大小为h,那么Q(j,x)和Q(j,y)的取值范围为[0,h],将Q(j,z)的取值范围处理为[-h/2,h/2]。
2.2 损失计算
误差用于指导网络的学习,也被称为损失。如图1 所示,A2J 使用关键点估计损失和锚点围绕损失。关键点估计损失计算估计的关键点坐标和真实的关键点坐标之间的误差,锚点围绕损失的作用是让高响应锚点分布在关键点周围,而不是聚集在某一侧,因为实验发现当高响应锚点聚集在关键点某一侧时,对该关键点坐标的估计准确度较低。A2J 网络先输出密集的估计,即锚点坐标到关键点坐标的偏差和锚点的响应,再使用softmax 函数对偏差和响应加权求和得到关键点坐标。
锚点到关键点的偏差对关键点坐标估计准确度的影响很大,然而A2J 并没有计算网络输出的锚点坐标到关键点坐标的偏差的误差,因此HigherA2J 使用偏差估计损失计算该误差以提高关键点估计准确度。从图2 可以看出偏差估计损失和关键点估计损失计算网络不同阶段输出的误差。
偏差估计损失结合关键点估计损失提高了关键点估计的准确度,使高权重锚点的分布更加合理。实验发现锚点围绕损失的作用不是很大,因此HigherA2J 去掉了锚点围绕损失。
2.2.1 计算关键点估计损失
偏差估计分支计算锚点坐标到关键点坐标的偏差,锚点响应分支计算每个锚点的权重,通过加权求和的方式可以得到预测的所有关键点坐标。关键点估计损失定义为:
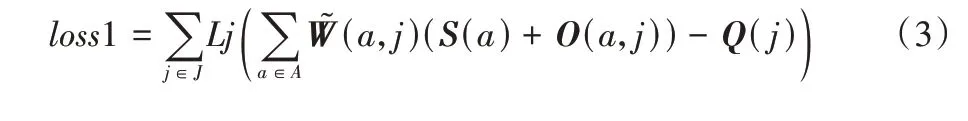
Lj是基于两点之间距离关系设计的距离损失函数。常用的指导网络学习的损失函数有L2 损失函数和L1 损失函数,离群点对L2 损失函数影响比较大,不利于网络的学习,因此基于偏差向量的估计方法通常使用L1 损失函数,但是L1 损失函数在0 点无法求导,L1 损失函数的改进版本SmoothL1 损失函数在0 点处可导。
虽然SmoothL1 损失函数可以指导网络训练得到不错的效果,但是SmoothL1 损失函数不能反映预测的关键点坐标和真实的关键点坐标在3D 空间上的距离,因此为了更好地指导网络学习对关键点坐标的预测,可以基于两点之间距离关系设计距离损失函数Lj:

2.2.2 计算偏差估计损失
使用SmoothL1 损失函数计算偏差估计的损失:
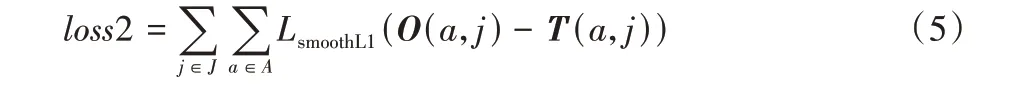
2.2.3 端到端训练
HigherA2J 使用以上两种损失监督网络的训练,和文献[11]类似,只是文献[11]的训练方式是先用偏差估计损失训练好网络,然后再用关键点估计损失对训练好的网络进行微调(fine-tune),实验发现这种训练方式不如同时用关键点估计损失和偏差估计损失对网络进行训练。损失计算公式为:

loss1 前的系数λ用于平衡关键点估计损失和偏差估计损失,λ=1。正则化通过Adam 优化器的权重衰减参数进行控制。
3 实验与结果分析
3.1 实验设置
3.1.1 数据集与评估方式
HANDS 2017 数据集[12]从BigHand 2.2M数据集[13]和First-Person Hand Action 数据集[14]中采样得到9.57E+5 的训练数据和2.95E+5 的测试数据,训练数据集包含5 名实验人员的手部图片,测试数据包含10 名实验人员的手部图片。标签为21 个关键点的3D 坐标。
NYU Hand Pose 数据集[6]包含7.2E+4 的训练数据和8.2+E3 的测试数据,每张深度图都包含36 个3D 关键点坐标。与文献[15-16]一致,选择正面拍摄的图片,使用36 个关键点中的14 个。
ICVL Hand Pose 数据集[17]包含2.2E+4 的训练数据和1.5E+3 的测试数据。标签是16 个关键点的3D 坐标。
使用平均距离误差对手部姿态估计的效果进行评估。
3.1.2 实现细节
本文的实验环境:操作系统为Ubuntu 18.04,CPU 为Intel Core-i5(2.9 GHz),内存16 GB,显卡为NVIDIA RTX 2060 6 GB。神经网络使用PyTorch 框架实现。
HigherA2J 的参数设置与A2J 基本一致。输入的深度图片处理为176×176 的分辨率。数据增强包括了随机缩放([0.5,1.5]),随机旋转([-180°,+180°]),随机平移([-5,+5])。以0.5 的概率添加随机噪声。使用Adam 作为优化器,学习率为0.000 35,权重衰减(Weight Decay)为10E-4。在NYU 数据集上训练35 个epoch,每训练10 个epoch 学习率降为之前的0.2 倍。在ICVL 和HANDS 2017 上训练17 个epoch,每训练7 个epoch 学习率降为之前的0.1 倍。
3.2 与主流方法对比
3.2.1 HANDS 2017 数据集对比分析
HigherA2J与前沿的3D 手姿态估计方法[4,9,16,18-19]相 比较,使用平均距离误差的实验结果在表2 中给出。表中:AVG 表示在所有实验人员提供的数据上的结果,SEEN 表示在训练数据中出现的实验人员提供的数据上的结果,UNSEEN 表示不在训练数据中出现的实验人员提供的数据上的结果,带有“*”的方法表示使用了模型集成技术。观察得到:1)HigherA2J 的平均误差比A2J 降低了0.1 mm。2)在有挑战性的百万级数据集上,HigherA2J 无论是在准确度还是在运行速度上都超过了所对比方法。3)值得注意的是虽然HigherA2J 在“UNSEEN”数据上的估计准确度较A2J 降低了0.4 mm,但是依旧比其他所比较方法优秀,而且HigherA2J 在“SEEN”数据上的估计准确度比A2J 提高了0.71 mm,平均估计准确度HigherA2J 优于A2J。
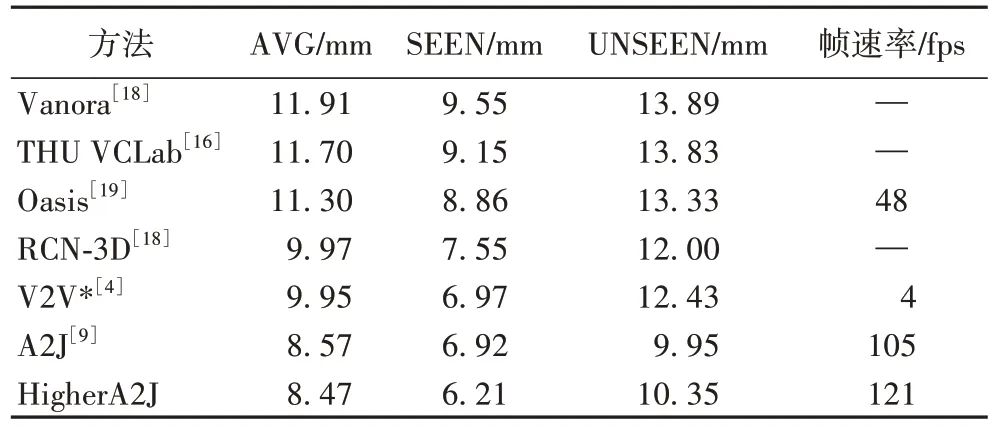
表2 在HANDS 2017数据集上的方法比较Tab.2 Method comparison on HANDS 2017 dataset
3.2.2 NYU和ICVL数据集对比分析
HigherA2J与前沿的3D 手姿态估计方 法[4-5,9,15-16,19-24]相比。使用平均距离误差的实验结果在表3 和表4 中给出。
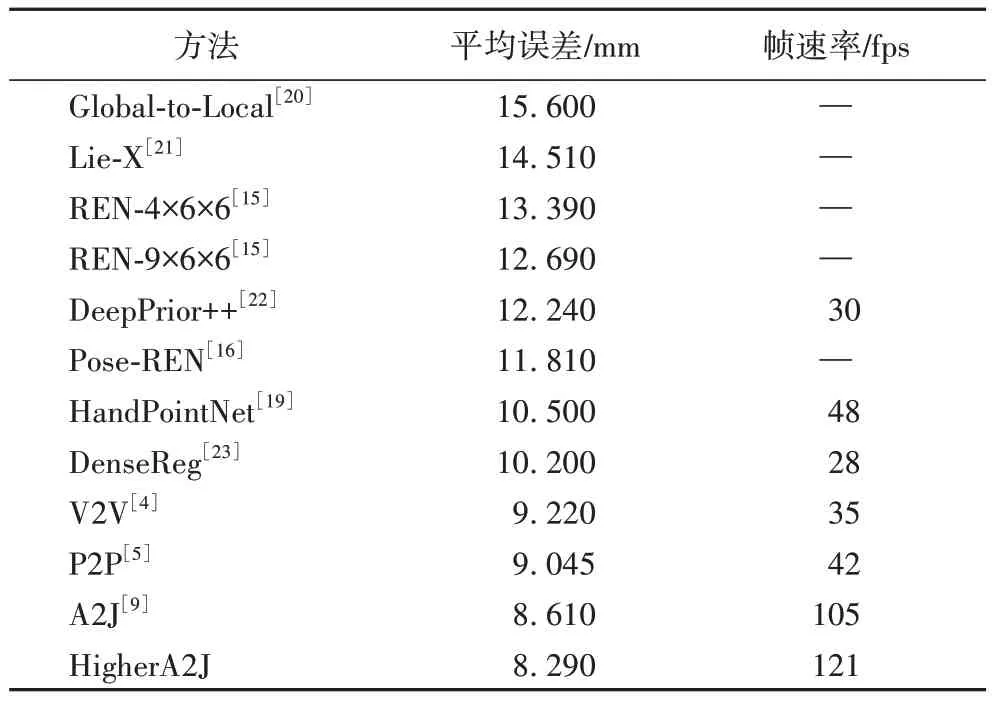
表3 在NYU数据集上的方法比较Tab.3 Method comparison on NYU dataset
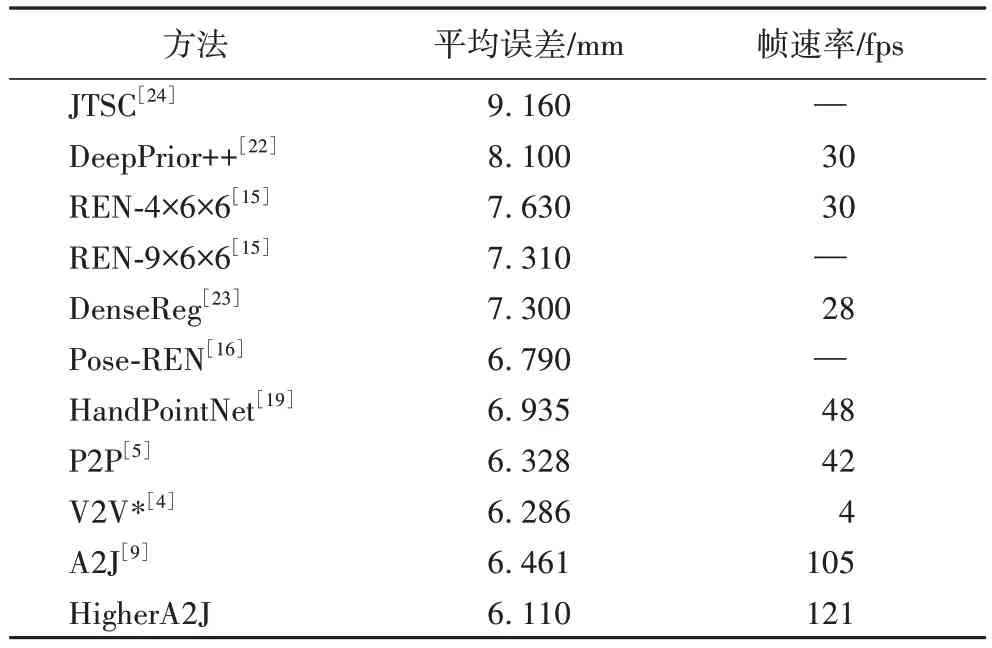
表4 在ICVL数据集上的不同方法比较Tab.4 Method comparison on ICVL dataset
表5 和表6 展示不同方法对各个关键点的估计误差。观察得到:1)HigherA2J 的平均误差比A2J 都有所降低,分别降低了0.32 mm 和0.35 mm。2)HigherA2J 无论是在准确度还是在运行速度上都超过了所对比的方法。3)A2J 方法在ICVL 数据集上的效果稍微差于V2V*和P2P,但是改进后的HigherA2J 方法比V2V*和P2P 效果都好,说明了基于锚点的方法的高效性。

表5 在NYU数据集上不同关键点的误差 单位:mmTab.5 Errors of different key points on NYU dataset unit:mm
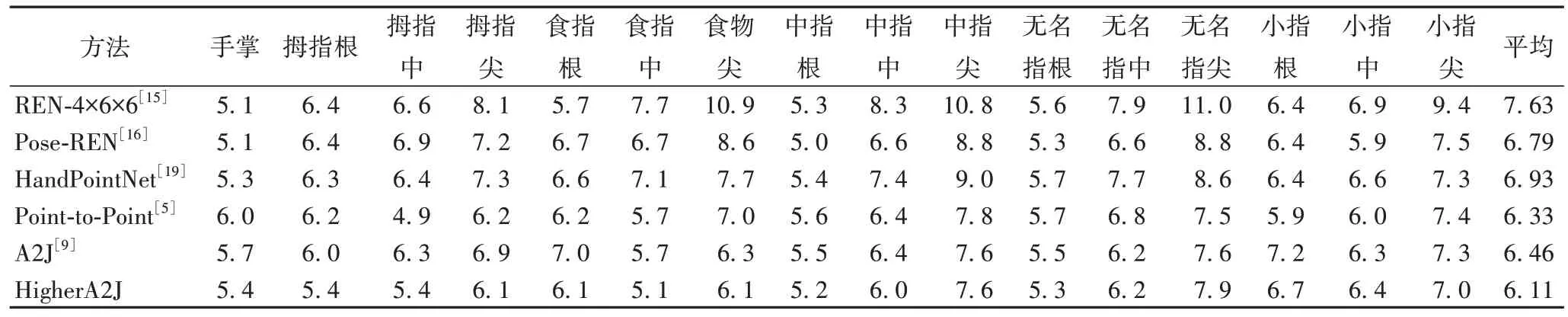
表6 在ICVL数据集上不同关键点的误差 单位:mmTab.6 Errors of different key points on ICVL dataset unit:mm
3.3 消融实验
如表7 所示,HigherA2J 的消融实验在NYU 数据上进行,每次实验去掉HigherA2J 相对于A2J 的一个改进点。

表7 在NYU数据集上的消融实验结果Tab.7 Ablation experimental results on NYU dataset
实验一,以HigherA2J 为基础,使用XY偏差估计分支和Z偏差估计分支替代XYZ偏差估计分支;实验二,在HigherA2J基础上去掉偏差估计损失;实验三,在HigherA2J 基础上使用SmoothL1 损失函数替换距离损失函数。观察得到:
1)XYZ偏差估计损失有效提高关键点估计准确度。
2)去掉偏差估计损失准确度较差,说明只要提高锚点对关键点的偏差估计准确度,可以提高关键点坐标预测准确度,验证了基于锚点的关键点估计方法的高效性。
3)使用SmoothL1 损失函数计算关键点误差效果不如使用距离损失函数,证明了距离损失函数的高效性。
为了进一步验证距离损失函数相对于SmoothL1 损失函数的高效性,使用不同的骨干网络(ResNet18、ResNet50)和数据集(NYU、ICVL)进行测试。如表8 所示,使用距离损失函数的网络的误差比使用SmoothL1 损失函数的网络的误差要小,证明了距离损失函数相较于SmoothL1 损失函数更适合于关键点估计。
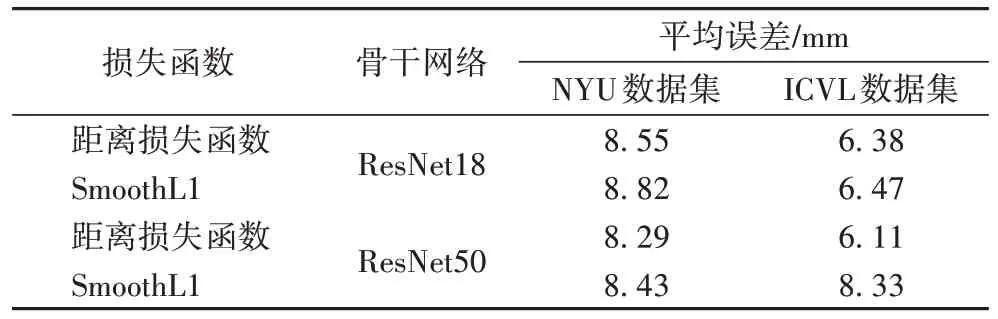
表8 在NYU数据集和ICVL数据集上距离损失函数和SmoothL1损失函数结果对比Tab.8 Result comparison between distance loss and SmoothL1 loss on NYU dataset and ICVL datasets
3.4 运行速度分析
HigherA2J 在NVIDIA RTX 2060 上的平均运行速度为121.17 frame/s(fps),对于每一张深度图需要1.75 ms 的图片读取和预处理,5.1 ms 的网络前向推理和后处理,证明了HigherA2J 具有优秀的实时性。
4 结语
本文提出了一种改进的基于锚点的手部姿态估计网络HigherA2J,在A2J 的基础上改进了网络结构和损失函数。在公共数据集NYU、ICVL 和HANDS2017 上的实验结果表明,HigherA2J 无论是准确度还是运行速度都超过了A2J。HigherA2J 运行速度快,骨干网络可以轻易地替换为轻量化网络,适合部署到嵌入式端。虽然基于锚点的关键点估计方式在局部特征的获取上取得了不错的效果,但是HigherA2J对全局特征的获取还不够优秀,下一步的研究方向是增强网络对于全局特征的获取能力以提高关键点坐标预测的准确度。
猜你喜欢
农业工程学报(2022年14期)2022-10-19
——《艺术史导论》评介
美育学刊(2022年5期)2022-10-18
科海故事博览·下旬刊(2022年4期)2022-05-07
中国信息化周报(2020年33期)2020-09-13
移动通信(2020年5期)2020-06-08
移动通信(2019年6期)2019-07-31
饮食与健康·下旬刊(2019年10期)2019-03-09
价值工程(2016年32期)2016-12-20
考试周刊(2016年34期)2016-05-28
中小企业管理与科技·中旬刊(2014年10期)2015-02-03
