
基于深度学习+自学习的小盒外观检测系统
2022-05-11 23:31陈天丽柳盼汪魁谢茜
今日自动化 2022年3期
陈天丽 柳盼 汪魁 谢茜



[摘 要]针对目前传统机器视觉方法配置参数繁琐,操作复杂,存在误剔或漏剔率偏高,及单一使用深度学习的方法检测效率偏低等问题,文中提出了一种基于深度学习+自学习的卷包香烟外观缺陷检测系统。利用图像增强、变换、滤波等方法对原始图像进行预处理得到处理后图像,后对处理后的图像进行评估,选择使用深度学习还是自学习的方法进行检测。结果表明,基于深度学习+自学习技术的卷包香烟外观缺陷检测方法比使用传统的机器视觉检测方法,或单一深度学习检测方法在检测耗时、准确率、误剔率的综合性能上要优越,具有较强的实用价值。
[关键词]机器视觉;缺陷检测;深度学习;自学习
[中图分类号]TM912 [文献标志码]A [文章编号]2095–6487(2022)03–0–05
Design of small box appearance defect detection system
based on deep learning + self-learning
Chen Tian-li,Liu Pan,Wang Kui,Xie Qian
[Abstract]In view of the cumbersome configuration parameters of the traditional machine vision method, the complicated operation, the high false or missed rejection rate, and the low detection efficiency of the single deep learning method,a method of appearance defects detection of cigarette box based on deep learning + self-learning is proposed. Use image enhancement, spatial filtering and other methods to preprocess the original image to obtain the processed image, and then evaluate the processed image, and choose whether to use deep learning or self-learning methods for detection. The results show that the cigarette box appearance defects detection system based on deep learning + self-learning technology is superior to traditional machine vision detection methods or a single deep learning detection method in terms of detection time, accuracy, and false rejection ,and has strong practical value.
[Keywords]machine vision;defects detection;deep learning;self-learning
在当前卷烟行业的包装机生产中,小盒外观检测普遍采用机器视觉的方法进行检测,机器视觉检测方法又分为基于传统图像处理检测方法及深度学习检测方法,这两种方法各有优缺点。例如使用传统检测算法,在对图像尺寸测量和对一些特征较为明显的固定区域进行检测时,其检准确率度及效率具有一定优势,但是对图像复杂特征的检测效果却不尽人意。而使用深度学习算法对图像的一些复杂特征的检测则具有较高准确率但其检测耗时相对较长,效率不高。现行业中普片使用的方案是基于单一的传统图像检测算法或是深度学习检测算法,鲜有将这两种算法的优势融合在一起进行外观检测的方案,其检测的综合效果上还存在一定的不足。
传统图像检测算法通常的做法是采集1张样本图片,然后使用阈值分割及形态学算法将缺陷特征筛选出来,这种做法的缺点是采集的样本单一且需要人工将阈值调节到适合的值,其稳定性及可操作性不高。本文提出的自学习算法则是基于传统的图像检测算的高层次封装,通过采集多张样本建立特征模型,可实现很好的检测效果。近年来基于深度学习的方法发展迅猛,越来越多的科研人员及企业开始投入到深度神经网络的研究中。根据深度神经网络检测框架的不同可以分为两类:①基于候选窗口的网络框架结构。这种网络结构首先用设定的窗口在图像上遍历,选出概率较大的目标区域,然后在对所选区域进行预测。这类网络结构的优势是精度比较高,但检测速度较慢,例如R-CNN、S PP-Net、Fast R-CNN、Faster R-CNN、R-FCN、Mask R-CNN等。②基于回归的网络框架结构。这种结构将检测看成回归问题,不需要计算候选区域,预测一步完成。这类框架检测速度比较快,但在精度方面一般弱于基于候选窗口的网络结构,例如YOLO系列、SSD、DSSD、FSSD、RetinaNet等。基于机器视觉的方法在工业检测领域有着良好的应用背景。付斌設计的机器视觉技术在烟草包装设备上的应用,该方案对单张样本使用阈值分割确定阈值然后对缺陷特征筛选,其检测效果对光照环境的依赖性较高,鲁棒性不强。张文、林建南等人设计的基于机器视觉的卷烟污点面积测量系统,该系统使用传统的图像算法,检测速度快,精度高,但其检测的缺陷特征简单,满足不了卷包多种缺陷类型及复杂特征的缺陷检测。陈智斌、农英雄、梁冬等人提出了基于深度学习的卷烟牌号识别方法,该方法使用CenterNet检测算法,在检测准确率及模型的鲁棒性取得了很好的效果,但是该方法不能兼容卷包检测中的一些测量性质的检测需求。为了满足卷包外观多种缺陷的检测需求,同时在检测的准确率、效率及算法的稳定性上达到最优的性能,本文设计1种基于深度学习+自学习技术的小盒烟包缺陷检测系统。
1 系统组成
基于深度学习+自学习的小盒外观缺陷检测系统包含硬件设计和检测算法设计两个主要模块,其中检测算法又包含深度学习检测算法和自学习检测。
1.1 硬件单元设计
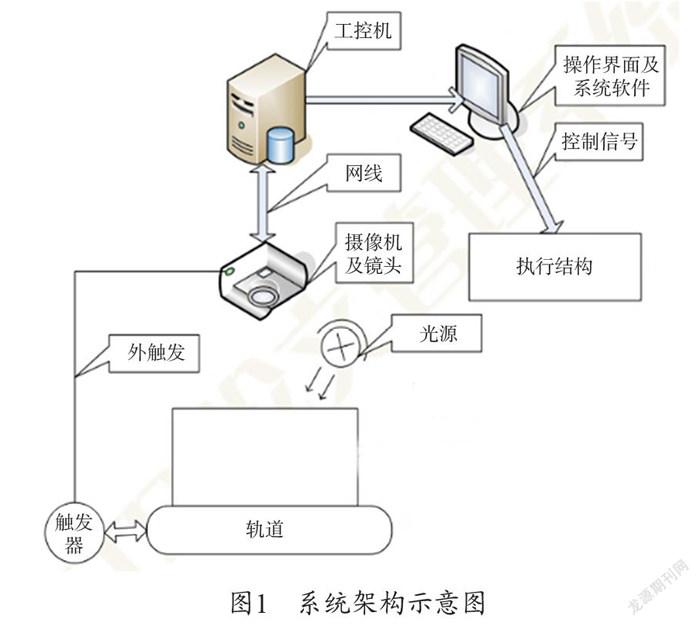
本系统是由镜头、光源、工控机、工业CCD、光电传感器、图像处理软件及执行机构等部分组成,系统的整体架构如下图1所示。系統设计的原理是小盒烟包运动到光电传感器的位置触发相机拍照,相机将采集到的烟包图像数据通过千兆网传送给工控机,然后图像处理软件通过本文设计的算法对采集到的烟包图像做缺陷检测,当检测到缺陷时,检测程序会通过工控机输出剔除信号通知执行机构执行剔除动作。
1.2 检测算法设计
系统的检测算法是通过深度学习+自学习的方案来实现,根据小盒外观的缺陷类型及背景的复杂程度来决定是使用深度学习检测方法还是自学习检测方法。检测算法流程图如图2所示。
1.2.1 深度学习模块
在深度学习检测模块中,本文采用的是1种改进的深度可分离的YOLO v5检测算法,相对于未改进的YOLO v5算法在参数量和模型大小上有明显的优势,在检测的mAP(均值平均精度)也有提升。
(1)YOLO v5。YOLO v5算法使用1种残差神经网络(Darknet-53)作为特征提取层,在花费更少浮点运算和时间的情况下达到与ResNet-152相似的效果。在预测输出模块,YOLO v5借鉴FPN(Feature Pyramid Network)算法思想,对多尺度的特征图进行预测,其结构示意图如图3所示。
(2)深度可分离卷积。传统的卷积算法在做计算时,每次参数的更新迭代都会对所有通道的对应区域进行计算,这就使得在卷积计算过程中需要涉及大量的模型参数和更多的浮点运算。而深度可分离卷积则是通过分组卷积的设计(每个通道作为一组),即先对每个通道的对应区域进行卷积运算,然后再在通道间进行信息交互,从而达到了将通道内卷积和通道间卷积分离的目的。
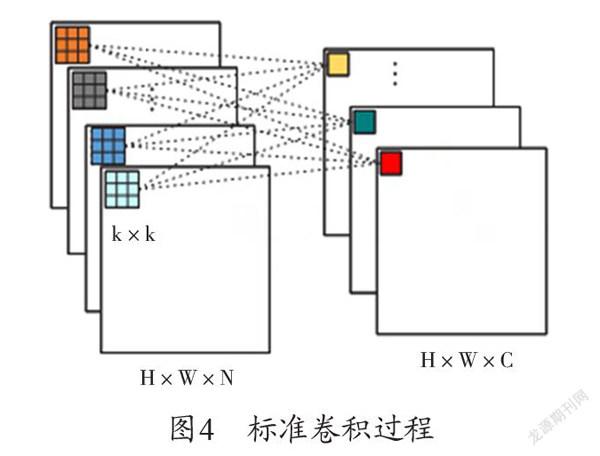
假设在传统卷积网络算法中,其输入图片的尺寸为H×W×N(H代表图片的高,W代表图片的宽,N代表图片的通道数)与C个尺寸为k×k×N(k×k代表卷积核的高和宽,N代表卷积核的通道数)的卷积核进行卷积运算时,其输出特征图的尺寸为H×W×C(padding=floor(k/2),stride=1)。在不考虑偏置(bias)的情况下,所需参数量为N×k×k×C,计算复杂度为O(H×W×k×k×N×C),卷积过程如下图4所示。
在深度可分离卷积中,是将卷积过程分为深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)两个部分。在深度卷积中,用尺寸大小为k×k卷积核对输入的同一通道类进行卷积运算,提取到的是1个通道内的特征信息,其参数量为N×k×k,计算复杂度为O(H×W×k×k×N),深度卷积不进行通道间的信息融合。逐点卷积则是利用C个尺寸大小为1×1×N的卷积核对通道间的信息进行融合,在实现通道间信息交互的同时可调控通道数量,其参数量为N×1×1×C,计算复杂度为O(H×W×1×1×N×C),卷积过程如下图5所示。
以3×3的卷积核为例,经过改进的深度可分离卷积网络所需的参数量仅约为传统卷积网络的1/9,并且运算量也降到约为原来的1/9,在不牺牲算法准确率的情况下降低了计算开销,提升了算法效率。
1.2.2 自学习模块
在自学习的缺陷检测算法中,通过学习正样本的特征建立起缺陷检测模型,可精确检测出烟包常见的缺陷。在实际使用中还可将误剔的烟包图像动态地添加到正样本图片中,实时优化模型。这种通过学习正样本图像特征的自学习算法,无论是检测准确性还是操作的方便性,相对于传统的基于单张图片的检测算法都具有无法比拟的优越性。自学习检测方法通过学习若干正样本的图像,建立器基于像素点的检测模型,在检测模型中计算出样本图像像素点的平均值及标准偏差。
像素点平均灰度计算公式:
M(x,y)=[P1(x,y)+P2(x,y)+……Pn(x,y)]/n (1)
像素点灰度标准偏差计算公式:
V(x,y)=sqrt(((P1(x,y)-M(x,y))2+(P2(x,y)-M(x,y))2+……(Pn(x,y)-M(x,y))2)/(n-1)) (2)
样本检测模型建立好之后,可以用此模型来检测烟包的缺陷,对于新输入的一张烟包图片,其检测算法流程如下。
(1)设置参数绝对阈值AbsThreshold和相对系数阈值VarThreshold。
(2)计算允许正常灰度值的最大值与最小值。
最大值:Gmax(x,y)=M(x,y)+max {AbsThreshold,VarThreshold*V(x,y)} (3)
最小值:Gmin(x,y)= M(x,y)-max{AbsThreshold,VarThreshold*V(x,y)} (4)
(3)将当前值C(x,y)与Gmax(x,y),Gmin(x,y)做对比,满足如下条件的像素点将被检测为缺陷点:
C(x,y)>Gmax(x,y) U C(x,y)<Gmin(x,y) (5)
2 实验与分析
2.1 试验设计
操作系统:Window10系统
硬件環境:CPU型号为Inter(R) Core(TM) i7-8700;主频为3.2 GHz安装内存为16 GB;深度学习框架是Tensor flow1.14;显卡配置为1块 Nvidia GeForce RTX 2080 Ti,显存为11 GB。具体实验环境见表1。
数据集选用武汉卷烟厂黄鹤楼软蓝的烟包图像,图像原始分辨率为640*480。该数据集中包含正常图片及漏烟、封签歪斜、边口炸裂、边角折叠4种常见的缺陷图片(图6所示),缺陷图像使用Labimg进行标注。实验时共选用16933图片进行测试,其中正常图片5124张,漏烟图片2955张,封签歪斜图片2933张,边口炸裂图片2980张,边口折叠图片2941张。具体实验数据见表2所示。在实验中,将图像裁剪成512*512的大小并输入到骨干网络,批量大小(batch size)设置为8,学习率设定为0.000125,并使用数据增强来提高模型的泛化能力,共训练100个epoch。
在自学习模块中采集正样本图片200张,设置绝对阈值AbsThreshold=20,相对系数为VarThreshold=2。
2.2 实验结果与分析
单一使用深度学习网络对数据集中的几种类型图片进行测试,其准确率、误剔率、平均耗时如表3所示。
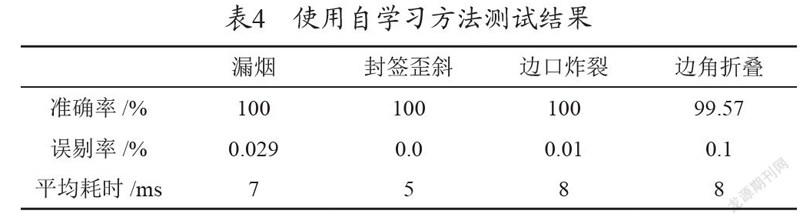
单一使用自学习的方法对数据集中的几种类型图片进行测试,其准确率、误剔率、平均耗时如表4所示。
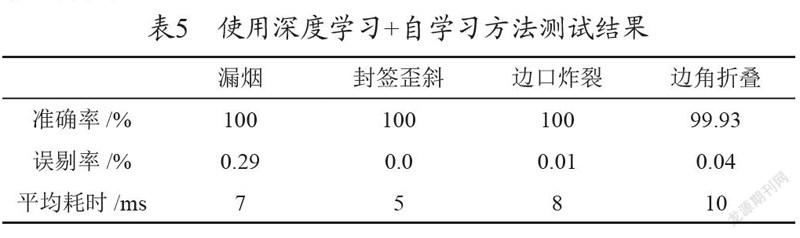
使用深度学习+自学习的方法对数据集中的几种类型图片进行测试,其准确率、误剔率、平均耗时如表5所示。
由上表测试数据可得出:
(1)封签歪斜这种缺陷,使用深度学习的方法检测效果并不理想,其准确率仅为96.57%,误剔率为0.11%,而使用自学习的方法准确率可达100%,误剔率0.0%。
(2)对于边角折叠这种缺陷,由于存在镭射过曝与折叠的白色区域在灰度和形态上存在一定的相似性,这种使用自学习方法在准确率和误剔率指标上没有使用深度学习网络检测的效果好。
(3)对于封签歪斜缺陷,使用传统测量这种定量方法进行检测效果更好;对于边角折叠这种缺陷,使用擅长模糊检测的深度学习网络来做检测更合适。
结论:使用深度学习+自学习的方法可以充分结合出两种检测方法的优势,其综合检测效果要优于单一使用深度学习检测方法或单一使用自学习检测
方法。
3 结语
本文提出了一种基于深度学习+自学习的方法来检测小盒外观表面缺陷。根据小盒外观的缺陷类型及缺陷背景的复杂程度,来分配使用深度学习方法检测或使用自学习方法检测,可以充分结合两种检测方法的优势,使其综合检测效果要优于单一使用深度学习方法或单一使用自学习的方法。在后续的研究中,研究的重点将集中在决策模块的开发,使其能根据缺陷类型及背景的复杂程度自动选择使用深度学习的方法或自学习的方法进行检测。
参考文献
[1] 李炜,黄心汉,王敏,等.基于机器视觉的带钢表面缺陷检测系统[J].华中科技大学学报(自然科学版),2003,31(2):72-74.
[2] LECUN Y,BENGIO Y,HINTON G.Deep learning[J].Nature,2015,521(7533):436-444.
[3] IGLOVIKOV I,SEFERBEKOV S,BUSLAEV A,et al.TernausNetV2:Fully convolutional network for instance segmentation[C].2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops.2018:233-237.
[4] 姚群力,胡显,雷宏.深度卷积神经网络在目标检测中的研究进展[J].计算机工程与应用,2018,54(17):1-9.
[5] GIRSHICK R,DONAHUE J,DARRELLAND T,et al.Rich feature hierarchies for accurate object detection andsemantic segmentation[C].Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.2014:580-587.
[6] HE K M,ZHANG X Y,REN S Q,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J].IEEE Transactions on Pattern Analysis & Ma-chine Intelligence,2015,37(9):1904-1916.
[7] GIRSHICK R.Fast R-CNN[C].IEEE International Conference on Computer Vision.2015:1440-1448.
[8] REN S Q,HE K M,GIRSHICK R,et al.Faster R-CNN:Towards real-time object detection with region proposal networks[C].International Conference on Neural Information Processing Systems,2015:91-99.
[9] CHEN X L,GUPTA A.An implementation of faster R-CNN with study for region sampling[J].arXiv:1702.02138,2017.
[10] DAI J F,LI Y,HE K M,et al.R-FCN:Object detectionvia region-based fully convolutional networks[J].Computer Vision and Pattern Recognition,2016,20:379-387.
[11] HE K M,GKIOXARI G,DOLL R P,et al.Mask R-CNN[C].IEEE International Conference on Computer Vision,2017:2980-2988.
[12] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once:Unified,real-time object detection[C].IEEE Conference on Computer Vision and Pattern Recognition,2016:779-788.
[13] REDMON J,FARHADI A.YOLO9000:Better,faster,stronger[C].IEEE Conference on Computer Vision and Pattern Recognition,2017:6517-6525.
[14] REDMON J,FARHADI A.YOLOv3:An incremental improvement[C].IEEE Conference on Computer Vision and Pattern Recognition,2018:89-95.
[15] LIU W,ANGUELOV D,ERHAN D,et al.SSD:Single shot multibox detector[C].European Conference on Computer Vision,2016:21-37.
[16] FU C Y,LIU W,RANGA A,et al.DSSD:Deconvolutional single shot detector[J].arXiv:1707.06659,2017.
[17] LI Z,ZHOU F.FSSD:Feature fusion single shot multibox detector[J].arXiv:1712.00690,2017.
[18] LIN T Y,GOYAL P,GIRSHICK R,et al.Focal loss for dense object detection [C].Proceedings of the IEEE International Conference on Computer Vision,2017:2980-2988.
[19] 陳治杉,刘本永.基于机器视觉的晶圆表面缺陷检测[J].贵州大学学报(自然科学版),2019,36(4):68-73.
[20] 姚明海,陈志浩.基于深度主动学习的磁片表面缺陷检测[J].计算机测量与控制,2018,26(9):29-33.
[21] 魏若峰.基于深度学习的铝型材表面瑕疵识别技术研究[D].杭州:浙江大学,2019.
[22] 高钦泉,黄炳城,刘文哲,等.基于改进CenterNet的竹条表面缺陷检测方法[J].计算机应用:1-8[2021-03-10].
[23] LIN T Y,DOLLÁR P,GIRSHICK R,et al.Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE,2017:936-944.
猜你喜欢
中国高新技术企业(2016年34期)2017-02-10
计算技术与自动化(2016年4期)2017-01-11
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
科教导刊(2016年25期)2016-11-15
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
软件工程(2016年8期)2016-10-25
科技视界(2016年20期)2016-09-29
企业导报(2016年10期)2016-06-04
