
基于多维度聚类算法的重庆住宅空调使用特征分析
2022-05-13 06:35薛凯刘猛晏璐何昱洁
土木与环境工程学报 2022年4期
薛凯,刘猛,晏璐,何昱洁
(重庆大学 土木工程学院;国家级低碳绿色建筑国际联合研究中心;绿色建筑与人居环境营造国际合作联合实验室;风工程及风资源利用重庆市重点实验室,重庆 400045)
长江流域地区占中国国土面积的25%,人口占55%,GDP占近45%,是一个人口密集,经济、产业高度发达的地区。该地区夏季炎热、冬季阴冷,全年高湿,室内热环境恶劣。近年来,多数家庭将房间空调器作为改善室内热环境的重要措施,根据国家统计局数据,目前中国住宅房间空调器拥有量达3.6亿台[1],其中重庆地区已接近户均2台。龙惟定等[2]指出,随着每年34亿m2的城镇住宅面积的增长,维持住宅建筑环境的空调能耗仍会有明显上升,因此,控制房间空调器电耗是减少建筑间接碳排放的主要措施,对尽快实现“双碳”目标也有积极意义。近年来的研究表明,住宅空调使用模式是影响供暖空调能耗的主要因素[3-4];中国经济发展水平不均衡,住户的年龄、家庭条件等有很大差异,造成居民在空调使用习惯上有很大不同。多样化的居民使用习惯直接影响空调的运行功率与运行时长,进而影响房间空调器能耗。为总结出不同使用习惯的典型、剖析使用习惯之间的关系,对空调用户使用习惯的分类研究势在必行。
住宅空调使用习惯的研究方法常有调研法、实测法、模拟法等,然而,由于现有方法本身的局限性,均无法总结出典型用户群体及其使用习惯。对于调研实测法,研究机构开展了大量研究,其中,Guo等[5]通过调研总结出该地区人员的主观特点,但由于使用习惯具有多样性,调研法很难通过单一指标总结出一两种典型使用模式。何玥儿[6]发放了800余份问卷对重庆地区空调使用模式进行广泛调研,并将空调使用时刻信息作为分类依据,构建了老幼群体的全天使用、上班族的早、中、晚间歇运行以及早、晚间歇运行的3种典型使用模式。然而,基于调研的分类多是依据经验进行主观确定的[7],与实际情况存在差异。所以,通过调研与实测,可以获取一定主客观数据,但是数据质量、数据维度不够全面,导致典型行为获取具有局限性。模拟方法通常采用特定的理想条件,而实际情况却往往有很大出入。实际运行时,模型输入往往不一定遵照设定的理想条件,存在诸多不确定性[8]。在目前的建筑能耗模拟软件中,多数采用固定作息的方法进行描述,也有一些采用理想化反馈模型或随机模型等简化处理方式[9];还有大量学者采用验证模型的思路,如通过实测或调研辅助手段提升模型的精度。Knight等[10]采用ECOTECT软件模拟学校建筑的能耗,并与实际监测数据进行对比,发现模拟方法明显低估了建筑物的电耗情况,差异达到43%,通过进一步探索发现,造成差异的主要原因是用户对自身设备作息过于主观[8,10]。由于模拟方法对用户行为的设置一般简化为固定/静态方式[11],实际运行情况下的特别复杂行为模拟方法往往很难描述[12],导致模拟结果难以准确反映实际人的行为对建筑用能水平的影响。
从分类指标或特征来看,高岩等[3]、刘猛等[13]采用能耗模拟软件,结合标准与文献记录,将设置温度、空调作息作为分类指标,设置几种典型的空调使用模式,推广了“部分时间”、“部分空间”的住宅空调节能运行方式。这些研究的空调设置模式维度较为单一,指标具有局限性(如仅采用使用时刻作息等),仅仅实现对空调使用习惯模式的简单分类,常常与实测结果产生较大偏差。
由于影响用户使用行为的因素较为复杂,也就无法基于单一指标的简单量化进行分类(如平均值、分位数等),很多学者提出多指标聚类算法(或综合指标聚类)[14]。随着互联网、大数据、人工智能的兴起,智能空调不断涌现,更加客观、更大区域、更多样本、更高效率、更全方位的数据监测与获取方式成为了可能。陈焕新等[15-16]阐述了制冷空调行业中常用的聚类分析、关联规则分析等无监督学习算法的原理与应用,分析了大数据在空调系统优化、故障诊断、建筑能耗与维护预测等方面的用途,指出大数据在用于分析人的行为上具有明显的优势。Yu等[17]基于室外环境、建筑信息、人员信息、设备功能等4个指标,应用该算法对家庭用户进行聚类分析,研究结果可较好地用于评估设备对能耗的影响以及建筑能耗模拟的优化,作者在处理聚类指标过程中采用分类变量进行量化预处理,同时指出,由于调研方法的限制,对于众多参数影响下的建筑物能耗进行全面调查是不切实际的,查找典型指标进行研究可行性更高。康旭源等[18]采用聚类分析获取人员作息,分析了人员行为对建筑能耗的影响特点,通过人员位置信息大数据库,重构人员在室率指标,基于k-means聚类方法,获取了16栋不同建筑的典型人员作息曲线,为人员行为研究提供了数据支撑。
综上所述,因样本量以及研究方法的限制,现有多数研究采用的指标不够全面,且主观性强,无法真实反映用户的使用习惯特点;此外,对指标的预处理方式过于简单,导致与实际情况存在较大差异,多维度聚类分析则为人员行为分类研究提供了参考。笔者基于房间空调器监控平台,获取了近2 000台房间空调器详细、客观的运行数据,从空调使用时长、温度需求及能耗角度构建影响空调使用习惯的特征参数,提取多维度聚类特征,并通过数据清洗、衍生、标准化等预处理方法,对空调样本进行分群,提出房间空调器典型群体,并定性描述其使用特点。
1 研究方法
在机器学习中,聚类算法属于“无监督学习”算法的一种,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律[19]。笔者对空调行为习惯采用常用的k-means算法,在大样本的快速计算方面,比模糊划分算法、期望最大化算法等其他算法更具优势[20]。
1.1 聚类算法
聚类根据计算自身的距离或相似度将数据划分为若干组,划分的原则是组内距离最小而组间距离最大。k-means采用距离作为相似性评价指标,即认为两个样本距离越近,其相似度就越大[21]。采用欧氏距离度量样本间相似性[17]。
d(k,l)=
(1)
式中:k、l分别代表两个样本;xk1,k2,…,xkn分别为k样本的n个特征;xl1,xl2…xln分别为l样本的n个特征。直观来看,式(1)刻画了组内样本围绕该组均值的紧密程度,距离d越小,则组内样本的相似性越高。
采用k-means算法,对于每个簇而言,要求其簇内差异小,而簇外差异大,轮廓系数(Silhouette)正是描述簇内外差异的关键指标[22],见式(2)。
(2)
式中:a为某个样本与其所在簇内其他样本的平均距离;b为某个样本与其他簇样本的平均距离;由式(2)可知,S取值范围为(-1,1),当S越接近于1,则聚类效果越好,越接近-1,聚类效果越差,0代表聚类重叠,没有很好地划分聚类。轮廓系数指标针对样本空间中的一个特定样本,计算它与所在聚类其他样本的平均距离a以及该样本与距离最近的另一个聚类中所有样本的平均距离b,将整个样本空间中所有样本的轮廓系数取算数平均值,作为聚类划分的性能指标[23]。
聚类算法在训练之前需要对聚类各特征进行预处理,预处理方法主要有离群值检验、正态化以及标准化,具体处理方法见文献[24],其中,离群值检测采用分位数方法,剔除数据中距离上下分位数较远的值,一般取1.5倍的分位间距;正态化的作用使得各特征近似呈现正态分布,消除数据分布中“尾迹”的影响;标准化的作用是消除不同特征量纲的影响,使数据标准化为均值为0、方差为1的标准正态分布。
笔者基于机器学习工具Scikit-learn的k-means包进行训练,该工具基于Python语言,在处理大数据集时具有编程简单、运算速度快的优势。
1.2 数据描述
针对重庆地区空调使用行为习惯进行研究,从某空调制造企业大数据平台随机抽取重庆主城六区共计2 000台住宅空调样本,从2016年到2017年共计一整年的空调运行数据集,数据集参数范围、分辨率、采集方式、传感元件、采集频率等见表1。由于原始数据规模大,监测维度多,造成聚类分析计算距离失效,为避免“维数灾难”,需要基于行为研究对聚类参数进行重构与衍生[20]。

表1 数据采集参数Table 1 Data collection parameters
聚类参数(特征)的多维度衍生应遵从3个原则:1)聚类参数尽量反映原始参数的研究意义,并覆盖更多维度;2)聚类参数尽可能接近正态分布,由于原始数据在收集过程中会产生诸多“坏值”,导致原始数据往往会呈现偏态,会大大影响聚类用户群的识别;3)参数应该进行相关性检验,由于高度相关的特征/参数会影响聚类分析的结果,在开始聚类分析之前需要先对冗余变量进行筛选和剔除。通过使用习惯特点进行筛选与衍生,形成与使用习惯相关的5个维度参数。
2 结果
2.1 特征分析
1)运行参数
长江流域地区空调运行具有“部分时间”、“部分空间”的使用特点[25],其中“部分时间”即反映间歇运行的特性,采用单次开机运行时长反映该运行特点。如图1(a)所示,单位次数运行时长集中分布在0~10 h之间,根据多项夏热冬冷地区空调间歇运行研究,当单次运行时长分布在0~5 h之间时,可认为该样本偏好间歇运行[26-28]。
2)温度设置参数
将用户温度设置作为空调能耗影响的重要参数,由于夏热冬冷地区冬、夏季设置温度存在很大区别,为了描述季节性影响,构建综合性指标α来描述温度季节差异,衡量用户的综合温度设置偏好,见式(3)。
(3)
式中:Tcomfort,w与Tcomfort,s分别为冬、夏季舒适温度,按照暖通设计规范[29],分别取20 ℃[13]与26 ℃[30]。STweight代表某样本设置温度按时长加权的平均值。图1(b)为设置温度参数分布,该指标呈明显的双峰特点。总体上看,当α=1时,代表该用户偏好冬、夏季舒适温度设置;当α>1时,代表用户偏好冬季高温、夏季低温的设置方式,空调行为偏耗能;当α<1时,代表用户偏好冬季低温、夏季高温的设置方式,空调行为偏节能,从分布图可以看出,采用该设置方式的样本较少。
3)季节参数
为了衡量用户对季节的偏好特点,采用季节使用率之差β进行衡量,如式(4)。
β=Csummer/Cs,total-Cwinter/Cw,total
(4)
式中:β为季节使用率之差,%;Csummer与Cwinter分别为夏季与冬季开机运行小时数;Cs,total与Cw,total分别为夏季与冬季总小时数。图1(c)为季节参数分布。当β>0时,夏季运行率高于冬季,表示该用户偏好夏季运行;当β=0时,表示该用户冬、夏季运行率相差不大,季节差异不明显;当β<0时,表示冬季运行率更高,该用户偏好冬季运行,从分布图可以看出,该地区偏好冬季的样本少,也符合该地区夏季为主的特点。
4)环境参数
为了综合反映冬、夏季用户对舒适温度的容忍情况,采用开机运行期冬、夏季室内温度与舒适温度的差值之和(运行期室内温度γ)来描述用户对室内环境的需求,见式(5)。

图1 分布密度图Fig.1 Distribution density
γ=(Tin,s-Tcomfort,s)+(Tcomfort,w-Tin,w)
(5)
式中:Tin,s、Tin,w分别为冬、夏季空调开机时室内温度平均值,依照规范,夏热冬冷地区冬季与夏季舒适温度分别可取20、26 ℃。由式(5)可知,γ越大,表示对室内冬季偏冷与夏季偏热环境的适应能力越强;γ越小,表示对室内冬季过热与夏季过冷的适应能力越强。图1(d)为环境参数分布。
5)能耗参数
单位小时能耗可反映样本空调的制冷能力,间接反映用户的室内负荷特点,由图1(e)可知,单位小时能耗分布更接近正态分布,且“尾迹”不明显。
2.2 聚类可视化
为了得到聚类最优数目,选择聚类数目从2~9分别建模,并计算各类别下的平均轮廓系数,如图2所示。当聚类数目为2与3时,平均轮廓系数最高,聚类数目越多,轮廓系数越小,表示聚类效果越差,所以,主要讨论类别为2与3时的分类特点。
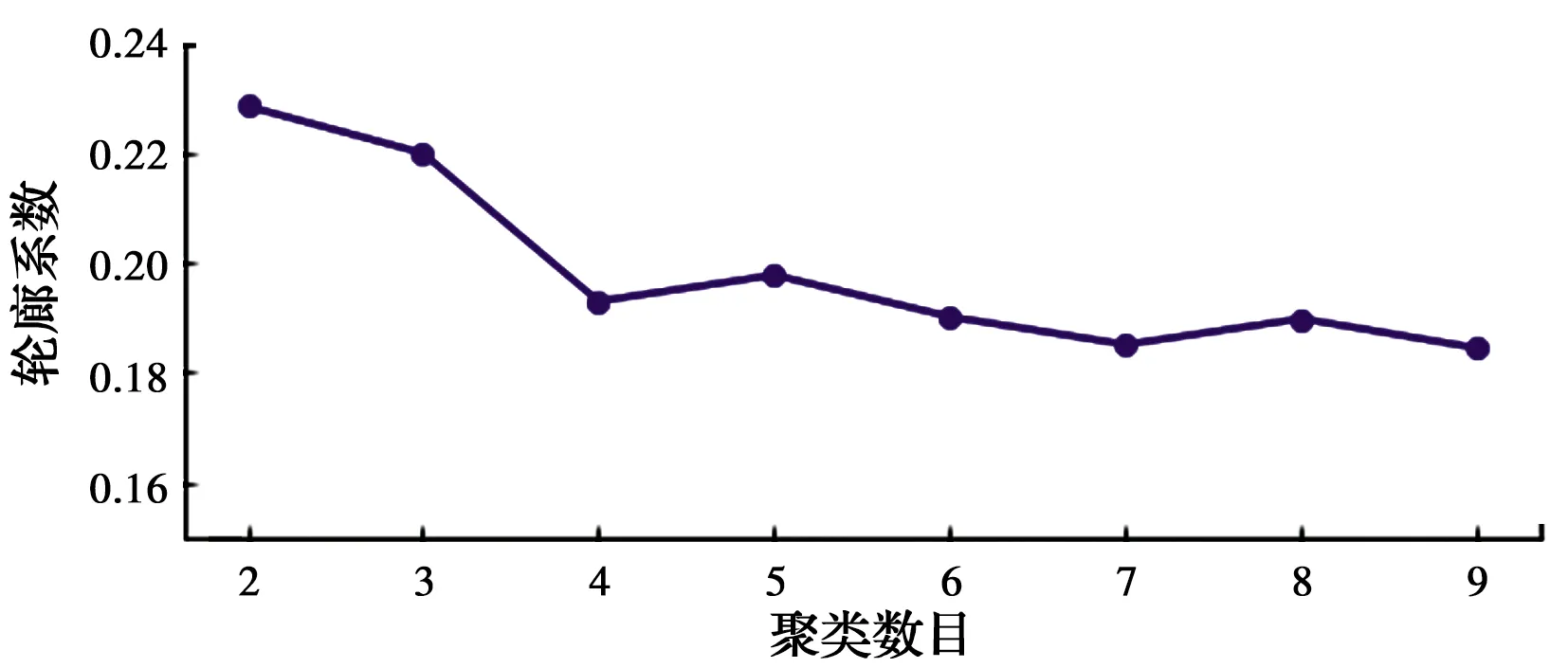
图2 不同聚类数目轮廓系数图Fig.2 Silhouette value diagram of different
为了在二维坐标系清晰展示样本分布,将5维数据转化为2维显示,如图3(a)所示,采用TSNE降维方法[22]并单独计算每个样本的轮廓系数,再进行排序,如图3(b)所示,其中红色虚线表示整体样本的平均轮廓系数。

图3 样本分布及轮廓系数排序Fig.3 Sample distribution and sorting of silhouette
聚类样本数量显示,聚类数目为2时,类别A样本占比57%,类别B占比43%;轮廓系数的总体均值约为0.22,两个类别轮廓系数分布合理。从图3(a)可以看出,在类别B中仍然有少量样本分类效果较差,轮廓系数为负,但仅有39个样本,占比不高(约占3.4%)。
如图3(b)所示,当样本数目为3时,各类别样本数占比分别为:47%(a),28%(b)和25%(c),轮廓系数为负的样本共计49个,约占4.2%,分布在类别b与类别c中;从两种聚类结果来看,类别c近似从类别A、B中各提取部分样本进行重新组合形成第3个类别,分类更加细化。
3 讨论
3.1 聚类特征差异性
为了进一步分析聚类结果下各个指标的分布情况以及不同类别之间的差异,采用雷达图显示特征分布,如图4所示。
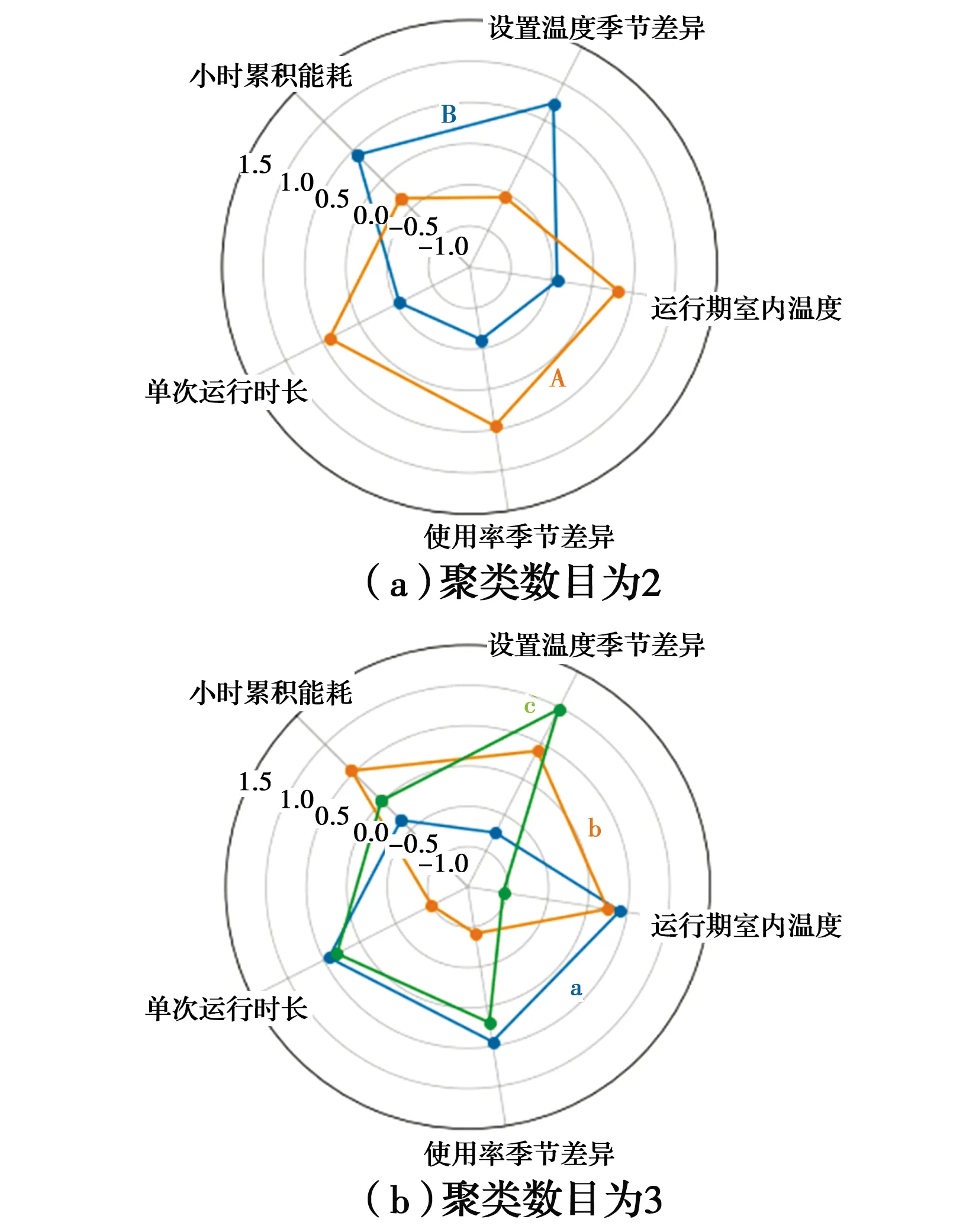
图4 特征差异性图Fig.4 Characteristic difference
当聚类类别为2时,从雷达图4(a)可以看出,5个特征在两个聚类类别中均表现出较为明显的差异,均可作为分离两个类别的优势特征;差异最大的特征为温度设置参数,A类用户设置温度参数α约为1.0左右,根据前文,该类用户偏好舒适温度设置(冬:20 ℃,夏:26 ℃);B类用户均值约为1.4左右,该类用户偏好冬季高温、夏季低温耗能设置行为。总体上,A类用户较B类用户更偏向节能行为,主要在夏季,经过统计,单位小时累积能耗类别A约为0.2~0.4 kW·h,类别B则略高,处于0.3~0.6 kW·h之间,类别B明显显示出高能耗的特点。
当聚类类别为3时,同样采用雷达图分析各个指标特征,如图4(b)所示,其中类别a对应类别A,二者各项指标差异不大,均反映夏季连续运行的偏好舒适温度运行的用户;对于b类来说,与B类各项指标差异不大,均反映冬、夏季均有空调需求,且多为间歇运行的用户群体;对于c类来说,指标设置温度、室内温度与a类差别大,其他3个指标与a类近似相等,两个类别均反映夏季连续运行的用户,差异在于对热环境需求不同,c类样本设置温度参数高、运行期室内温度低,更偏好耗能设置的“过”舒适环境(冬季过热与夏季过冷),a类倾向节能运行。
值得注意的是,两个聚类方式均能较好地分出用户使用习惯类群,聚为3类的分类方式在2类的基础上更加细化,新用户群体是否具有实际意义仍需进一步讨论。
3.2 聚类数目讨论
聚为两个类别时,样本分布较为均匀,轮廓系数更高,聚类错误率相对较低;聚为3类时,样本分布不均匀性提高,轮廓系数低,聚类错误率略高。但聚类数目的确定,除了采用传统的评估指标(如距离、轮廓系数),仍需结合实际问题具体探讨。样本分布占比如图5所示。

图5 不同聚类数目样本占比Fig.5 Proportion of samples with different
图5中外环代表聚类数目为2(A与B),内环代表聚类数目为3(a、b及c)。通过对不同聚类数目的5个特征进行分析,A与a、B与b的特点近似相同,所以,类别c可以看作是对聚2类时的进一步细分,即类别c从类别A中分出10%的样本,从类别B中分出15%的样本,共计25%的样本形成c类,为以夏季连续运行的用户群体,空调行为偏好耗能设置,对室内环境要求高,因此,聚2类中A、B的运行特点包含在聚3类时的运行特点中,为此,将聚类结果设置为3类进行后续分析,见表2。

表2 不同类别用户群空调行为偏好Table 2 Behavior preferences of air-conditioning with different clusters
由于夏热冬冷地区住宅空调夏季运行周期长,对空调器依赖性高,冬季采暖设备多样,所以,该地区空调仅采用夏季供冷单一方式的样本多。调研实测过程中,大量学者也指出,夏季存在低温设置的典型群体,如陈勰等[31]通过对青年人群体热感觉调研指出,夏季使用空调比例高的用户(依赖性更强)更适应较低的室温;简毅文等[32]、谭晶月[33]、郭祺[34]采用现场询问方式对空调设置习惯的调研中发现,有相当部分用户(超过40%)在夏季会选择采用26 ℃以下的低温设置,Haochen等[35]也指出,长江流域20%左右的用户会在夜间连续开启18~24 ℃的设置温度;柴盼等[36]通过调研也指出,有约30%的用户夏季会通过设置低于标准规定的温度来提高舒适度。部分热舒适研究学者也指出,体质较好的用户群体(如青年人等)会选择将室内环境设置较低温。
因此,在夏季采用耗能的低温设置群体客观存在,采用3个类别聚类更有实际意义。基于此,总结聚类3个用户群体的特点:
1)对于类别a用户群体,运行特点为夏季为主、连续运行、节能设置,空调使用过程具有较强的节能意识,对空调耗电较为关注,近似三代人家庭,能耗最低,可作为夏季空调运行的推荐模式。
2)对于类别b用户群体,运行偏好为冬、夏两用、间歇运行、耗能设置,结合重庆地区调研结果,重点在于间歇运行特点,与上班族或两代人家庭的特征较为近似,能耗最高。该类高能耗人群应予以重点关注,可采用合理的规划及必要的节能技术,如自然通风技术等降低能源消耗。
3)对于类别c用户群体,运行特点为夏季为主、连续运行、耗能设置,重点在于夏季长期低温运行,多为身体适应性较强的人群,近似单身青年等家庭。该类人群需要在满足舒适性的情况下增加节能意识,减少不必要的能源浪费,避免长期运行引发的“空调病”。
4 结论
通过多维度聚类算法,结合重庆地区房间空调器数据监测平台,选择合适的评估指标对空调用户群体进行分类,识别出该地区空调使用的典型群体,主要研究结论如下:
1)从空调使用时长、温度需求及能耗角度,构建了空调运行的5个聚类参数,包括单次运行时长、运行期室内温度、使用率季节差异、设置温度季节差异、小时累积能耗参数,剖析重庆地区空调使用习惯的典型特征并识别典型群体,指出多维度聚类算法可用于多样化空调使用习惯的研究。
2)通过特征差异性分析,指出重庆地区空调用户运行方式多样、季节性明显的特点,并挖掘出该地区3类典型空调使用习惯,即以夏季为主,连续运行的低能耗群体;以夏季为主,连续运行的高能耗群体;冬、夏两用,间歇运行能耗较高的群体。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
计算机应用与软件(2021年7期)2021-07-16
建材发展导向(2021年23期)2021-03-08
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
少儿画王(3-6岁)(2020年4期)2020-09-13
华人时刊(2018年15期)2018-11-10
东方教育(2018年20期)2018-08-22
互联网天地(2016年1期)2016-05-04
