
一种基于命名实体识别增强的对话状态追踪生成方法
2022-06-07 13:37欧中洪戴敏江谭言信宋美娜
陕西师范大学学报(自然科学版) 2022年3期
欧中洪,戴敏江,谭言信,宋美娜
(北京邮电大学 计算机学院(国家示范性软件学院), 北京 100876)
面向任务的多轮对话系统已普遍应用于日常生活,如阿里小蜜[1]、微软小冰[2]等。任务导向的对话系统可满足日常生活订餐、酒店预定、飞机火车预定等功能。对话状态追踪(dialogue state tracking,DST)是任务型多轮对话系统的关键组件,其目标是根据用户与系统的对话历史识别用户意图和用户对话目标。用户意图识别,即识别对话所属任务领域,如订餐、查询领域等,通常构建为分类任务;用户对话目标由特定任务领域的一系列槽构成,如订餐领域的槽包括餐馆名称、订餐时间等,这些槽集合可完整表述一项任务,如订餐。对话状态追踪器根据用户意图,针对特定领域槽识别对话历史中的实体作为值,更新历史对话状态,完成对话状态追踪。
对话状态追踪器目前主要采用3种方式构建:基于分类的方法、基于标注的方法和基于生成的方法。
基于分类的方法首先构建特定领域的槽值对本体集,形成完整的特定任务目标表示。如针对“订餐”领域,其可能的用户目标表示包括餐馆名称、餐馆地址、订餐时间等槽,同时针对每个槽需包含完整的值集合。基于分类的方法需保证槽值对本体集的完整性,才可进一步根据对话历史进行分类。但许多槽对应的值往往无法完整定义或难以槽值扩展,如时间槽值为连续值,无法定义完整的值集合,因此基于分类的方法只适用可分类的槽值,不适用完整的对话状态追踪以及新槽值扩展。
基于标注的方法可根据槽信息直接在对话历史中标注出对应值所在位置,然后通过对话状态更新器更新历史对话状态。基于标注的方法可有效解决基于分类的方法中无法完整定义槽值的问题,因为其可直接标注出对应的连续值,但对于用户输入错误或表述不完整的标注结果,难以直接用于对话状态表示,需进一步规范化处理,较为繁琐。
基于生成的方法根据对话历史表示以及槽信息生成完整值,并直接推理更新对话状态。基于生成的方法可生成整个词表的词分布,因此可同时解决用户输入错误、用户输入不完整以及对话中出现新词等问题。Wu等提出的Trade模型[3]借用指针网络[4]编码对话历史上下文与领域槽向量,然后基于注意力机制生成槽值中每个词在整个词表的概率分布,完成对话状态生成。基于生成的方法可解决基于分类的方法以及基于标注方法的一些弊端,但现有的生成方法没有有效利用槽值对本体集的知识信息,导致其命名实体识别能力(named entity recognition,NER)不如基于标注或分类的方法。
针对上述问题,本文提出一种基于指针网络的新型对话状态追踪生成方法。该方法基于指针网络构建命名实体识别指针和领域槽推理指针以改进原来的领域槽指针。命名实体识别指针以槽值对本体集中的槽值为识别目标,通过标注对话历史中包含的命名实体来提升命名实体识别能力;槽推理指针根据识别的命名实体词,基于对话历史进一步推理更新,完成对话状态追踪。
1 相关工作
对话系统主要分为基于管道(pipeline)的方法与基于深度学习的端到端方法。
基于管道方法的对话系统主要包含4个组成部分:自然语言理解(natural language understanding,NLU),对话状态追踪(dialogue state tracking,DST),对话策略学习(dialogue policy learning,DPL)和对话生成(dialogue language generation,DLG)。对话状态追踪是其中的关键组件。
传统基于管道方法的对话系统大多作用于单一领域多轮对话数据集DSTC2[5],其对话状态追踪依赖自然语言理解[6-10]。基于管道的方法首先根据自然语言理解得到命名实体;接着对实体进行去异化(delexicalization),即将标注错误或不完整的命名实体映射为正确实体;最后对话状态追踪模块对命名实体进行所属槽分类,构建完整对话状态。依据单领域数据集构建的对话状态追踪器难以进行多领域迁移,且多模块间存在误差传播,无法全局优化;此外,传统人工构建词典去异化的方法难以维护和扩展到新领域。
针对基于管道方法存在的问题,Henderson等和Zilka等提出基于深度学习的端到端方法,将自然语言理解模块和对话状态追踪模块联合训练,根据槽值对本体集进行分类[11-12]。Mrkšiĉ等通过将本体的槽值对编码为低维向量,利用深度学习的拟合能力计算对话历史向量与槽值对向量的相似度,选择相似度最大的槽值作为分类结果进行对话状态追踪[13]。基于深度学习的方法解决了基于管道的方法中多模块误差传播的问题,深度学习的拟合能力解决了传统方法需要人工构建词典进行去异化的问题,但基于槽值对本体集分类的方法不适用于连续槽值或不可穷举的槽值,如时间槽值等。
上述基于生成的方式,通过指针指向整个词表,解决了分类方法中无法有效分类连续值的问题;模型解码器通过参数共享来训练各领域槽指针,提升了模型效果。但模型只设计了领域指针和槽指针,参数共享方式粒度较粗,且生成方法没有有效利用槽值对本体集的知识信息,因此命名实体识别能力有待提升。
充分利用槽值对本体集的知识信息对于对话状态追踪,特别是命名实体识别能力提升具有重要作用。DST-Picklist整合了传统分类方法和最新的跨度预测方法的优势提升对话状态追踪效果[14],但DST-Picklist将2种方法分开构建为2个模型,没有做到模型的深度融合。DFGN模型通过第三方命名实体识别工具来识别命名实体,然后通过图卷积网络将实体信息传播回对话历史编码信息中,提升了命名实体的识别能力[15],但通过第三方工具进行命名实体识别对不同领域的命名实体识别效果欠佳。
此外,QA-DST将对话状态追踪任务视为阅读理解任务,将领域槽构建为问题句子编码,获得问题向量表示,将对应槽值作为阅读理解的选项进行选择[16]。近来,基于预训练语言模型Bert[17]和GPT[18]的 BERT-DST[19]方法利用Bert对对话历史进行跨度序列标注,预测对话历史中每个词作为槽值的起始-结束位置的概率分布,然后从对话历史中选择最优的起始-结束位置间的词作为槽值。上述方法只利用了深度学习的拟合能力完成对话状态追踪,忽略了对话状态更新时需要对多轮对话间的多个值进行推理选择的情况,导致推理更新效果较差。
本文充分利用槽值对本体集实体知识,将槽值对本体集识别与对话状态生成构建为深度融合模型,有效利用本体的知识信息提升命名实体识别效果,同时保证了深度学习模型可扩展的优点。
2 对话状态追踪建模
我们提出一种新型对话状态追踪模型NerInfer(named entity recognition and inference capabilities enhanced dialogue state tracker),基于指针网络提出命名实体识别指针和领域槽推理指针,以改进原来单一的领域槽指针。模型整体架构如图1所示。NerInfer模型主要由4部分构成:对话历史编码器、命名实体解码器、槽推理生成器和槽三分类门。NerInfer模型首先构建特定领域的命名实体识别指针(NER pointer),以槽值对本体集中的命名实体作为识别目标,在对话历史上基于注意力机制完成标注,训练指针的命名实体识别能力;其次,模型融合槽推理指针(DST inference pointer)和命名实体识别指针构建槽推理生成器(slot value inference generator)进行槽值生成。
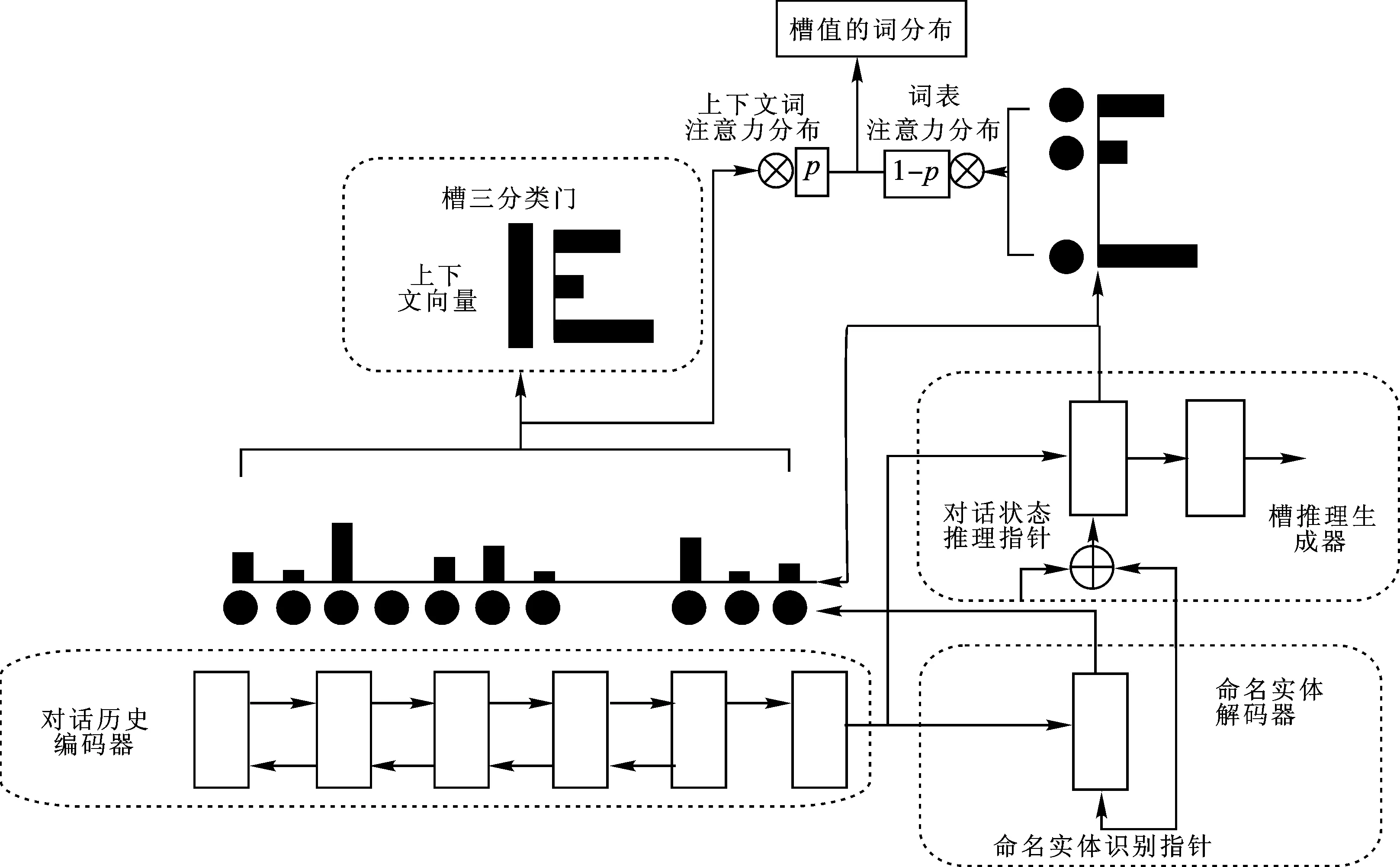
图1 对话状态追踪模型架构
2.1 符号定义
首先给出相关符号的定义。对话历史可表示为
H={(SS1,SU1),(SS2,SU2),…,(SSt,SUt)}。
(1)
式中:SS表示系统的回复对话序列,SU表示用户的对话序列,(SSi,SUi)表示第i轮对话,对话历史H一共包含t轮对话。对话状态表示为
B={B1,B2,…,Bt}。
(2)
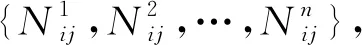
2.2 对话历史编码器
NerInfer采用双向门控循环单元(gate recurrent unit,GRU)作为对话历史的编码器,与Trade模型保持一致。其直接将对话历史按顺序进行拼接,作为对话历史编码器的输入
Hin=(SS1,SU1,…,SSt,UUt)∈R|w|×demb。
(3)
式中:|w|为对话历史中词的总个数;demb为词向量维度。通过双向GRU编码器编码,可获得每个词的隐向量
Hhid=(h1,h2,…,hw)∈R|w|×dhid,
(4)
式中dhid为隐向量维度。最后通过编码器获得对话历史的句子级表示hsent∈Rdhid。
2.3 解码器
原始的Trade模型直接将领域向量与槽向量相加作为槽生成器的第一步输入,通过向量相加的方式实现多个领域间的槽参数共享,让向量间互相学习槽值的识别能力。NerInfer将(领域,槽)向量构建为特定领域的命名实体识别指针向量Wdom-ner与特定槽的槽推理指针向量Winfe,这与现有研究中简单将领域向量与槽向量相加不同。一方面,由于不同领域的命名实体集合间没有交集,如饭店名称槽(restaurant-name slot)和酒店名称槽(hotel-name slot)对应的值属于槽值对本体集中的不同集合,通过领域向量与槽向量直接相加的方式,不但不利于共同学习槽值识别,而且会导致不同领域间的命名实体发生混淆。NerInfer针对不同领域设计不同的命名实体识别指针,分别学习各自领域内部的命名实体识别能力,从而减少领域间学习混淆的情况。另一方面,不同领域中的槽在多轮对话历史中的推理识别方式存在相似性(如图2)。不同领域的槽推理过程都会偏向于由系统给出多个命名实体选项,然后根据最新的用户对话选择方式推理更新槽值。而NerInfer模型只对槽推理指针的训练进行参数共享,以促进槽推理能力的联合学习。综上,领域槽值识别首先需要根据对话历史识别出相关的命名实体,然后通过推理选择正确的槽值来完成对话状态更新。

图2 对话推理过程
2.3.1 命名实体解码器
为了分别训练不同领域间的命名实体识别指针,以进一步增强对话状态追踪器的命名实体识别能力,NerInfer在不同领域中设立了在向量空间中完全独立的可训练向量。然后,NerInfer将槽值对本体集中的命名实体作为序列标注对象,训练命名实体识别指针的实体识别能力。在推理指针的辅助下,NerInfer增强了命名实体的推理选择能力。
首先,将命名实体识别指针向量Wdom-ner作为命名实体识别生成器的输入,其中dom为某一具体领域;然后,将对话历史的句子级表示hsent作为解码器的初始隐状态输入,得到隐向量hdom-ner;最后,将hdom-ner用于计算对话历史词级的注意力分布,得到dom领域下基于对话历史隐向量H的词分布注意力得分
Pdom-ner=Softmax(H·(hdom-ner)T)∈R|Hw|×|Ner|。
(5)
式中:|Hw|为对话历史中词的数目;|Ner|为槽值对本体集中特定领域的命名实体个数;通过Softmax函数计算整个序列中各个词作为命名实体的可能性大小,完成命名实体序列标注。
2.3.2 槽推理生成器
NerInfer将槽推理指针和领域相关的命名实体识别指针相加作为槽推理生成器的第一个输入
Wdom-slot=Winfe+Wdom-ner。
(6)
解码得到槽值识别指针Wdom-slot的隐向量表示hdom-slot,用于计算指针基于对话历史H和整个词表V的注意力得分
Pvocab=Softmax(V·(hdom-slot)T)∈R|V|,
(7)
Phistory=Softmax(H·(hdom-slot)T)∈R|Hw|。
(8)
式中:V为整个词表的可训练词向量;|V|为整个词表的词个数;H为对话历史的隐向量表示。
对以上两个词分布进行加权求和,得到基于对话历史和整个词表的最终槽值的词分布
Pvalue=Pgen×Pvocab+(1-Pgen)×Phistory∈R|V|。
(9)
式中:标量Pgen通过拼接指针隐向量hdom-slot、指针向量Wdom-slot以及基于注意力机制得到的对话历史表示c得到
Pgen=sigmoid(W·[hdom-slot;Wdom-ner;c]),
(10)
c=Phistory·H∈Rdhid。
(11)
2.4 三分类门
三分类门用于预测当前对话历史中某一领域槽的3种状态:第1种为存在用户指定的具体槽值;第2种为“dontcare”,表示槽可以填充任意值;第3种为不存在。基于注意力机制的对话历史表示c用于预测当前领域槽的3种状态:
G=Softmax(WTc)∈R3。
(12)
2.5 损失函数
NerInfer使用交叉熵损失函数Lg计算三分类门的预测损失
(13)
式中:G表示预测值;ygate表示真实值,用独热码表示。类似地,NerInfer使用另一个交叉熵损失函数Lv计算预测的槽值对应的词分布Pvalue与真实词yvalue之间的损失:
(14)
式中:V为词表中词的个数;N为槽值对本体集中命名实体槽值的个数。
最后,计算命名实体识别损失函数,同样使用交叉熵损失函数
(15)
最终,通过超参α、β、γ加权求和3个损失函数获得最终的损失函数
L=αLg+βLv+γLn。
(16)
3 实验验证
3.1 数据集
Multi-domain Wizard-of-Oz[20](MultiWOZ)是面向任务的多领域完全人工标注的多轮对话数据集,是目前最大的有标注对话任务数据集,包含景点(attraction)、医院(hospital)、警察局(police)、酒店(hotel)、餐厅(restaurant)、出租车(taxi)、火车(train)7个领域,共收集了10 438组对话。大约70%的对话超过10个回合,显示了语料库的复杂性;单领域和多领域对话的平均轮次分别为8.93和15.39,共115 434轮。MultiWOZ将对话建模任务分解为3个子任务来为每个子任务报告基准测试结果:对话状态跟踪、对话-行为-文本生成和对话上下文-文本生成。本文采用纠错后的MultiWOZ 2.1[5]版本数据集进行实验。
Trade模型中的槽值识别误差结果如图3所示。可以看出酒店、景点以及餐厅3个领域命名实体的识别准确率最低。因此,本文仅考虑对这3个命名实体进行实验,验证NerInfer模型的有效性。
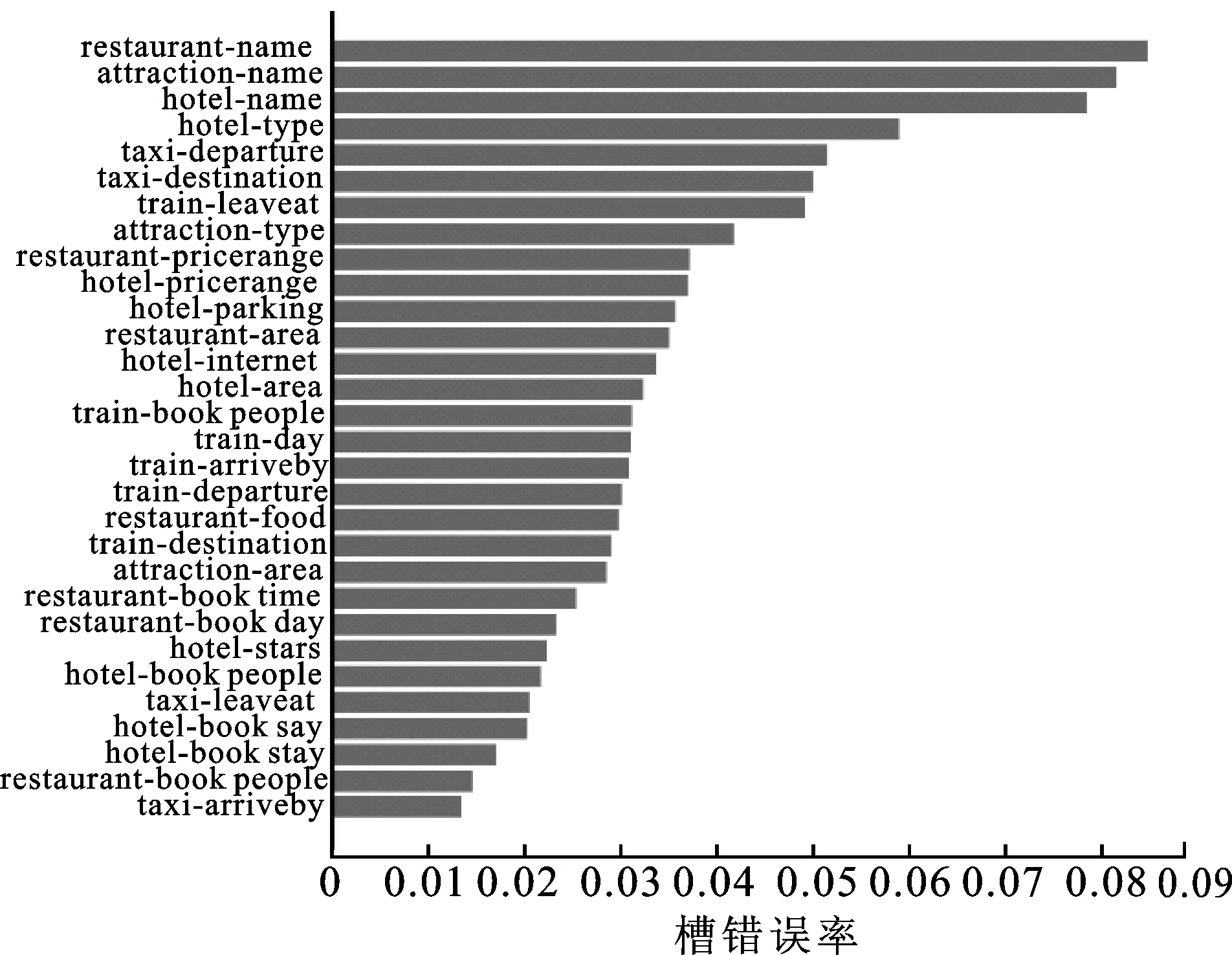
图3 Trade模型在多领域测试集上的槽错误率
3.2 训练细节
NerInfer模型的实验细节基本遵循Trade模型的设定。NerInfer模型使用Adam优化器[21],训练批次大小为32,学习率设定为[0.001,0.000 1],丢弃率[22]设定为0.2。损失函数的超参α、β、γ均设置为1。所有嵌入向量都使用 Glove Embeddings[23]和Character Embeddings[24]作为初始的词嵌入向量,词向量维度为400维,命名实体识别指针和槽推理生成都采用贪心策略。此外,与文献[25]类似,NerInfer模型采用掩码策略对输入序列加入掩码提升可扩展性。
3.3 实验结果
为验证本文所提出的NerInfer模型的有效性,把Trade模型以及消融实验分析得到的Trade-模型作为对比。
NerInfer模型旨在提升命名实体槽值的识别能力。为了改进原始Trade模型的缺陷,本文仅对酒店名称槽(hotel-name slot)、饭店名称槽(restaurant-name slot)和景点名称槽(attraction-name slot)3个领域的槽值进行对话状态追踪。此外,由于名称槽(name slot)的值实际指向命名实体,本文将其统称为命名实体槽(named entity slot)。
我们在验证集dev和测试集test上验证每个模型的性能,使用联合目标准确率(joint goal accuracy)、轮次槽值识别准确率(turn accuracy)和联合F1值(joint-F1)3个指标评估模型性能。联合目标准确率表示在一个完整对话的所有轮次中,所有槽值的预测均与真实槽值相同才能作为一次正确预测,是对话状态追踪器性能评估的核心指标;轮次槽值识别准确率仅需具体轮次对话中槽值识别与真值槽值相同即可作为一次正确预测;联合F1反映联合预测的精确率和召回率的调和平均结果。
为进行公平比较,在训练和测试模型时将3个模型的参数设置相同,并对每个模型进行4次实验,取平均结果作为最终实验结果。实验结果如表1所示。
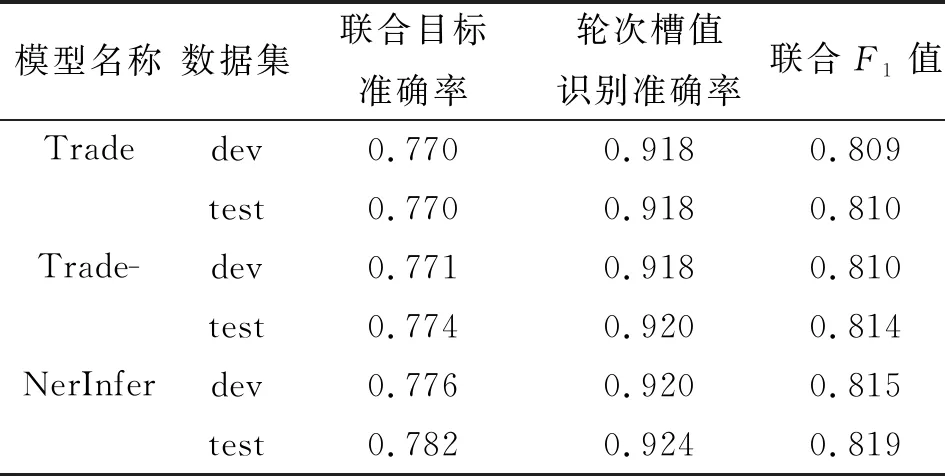
表1 实验结果
Trade模型是原始模型,直接使用单一的领域槽指针生成对应值,没有细分命名实体识别指针和槽推理指针。因此,模型的命名实体识别能力不足。
Trade-模型是对Trade模型进行消融改进以验证本文假设的模型。在Trade-模型中,去除指针中的名称槽向量,并保留领域向量。这可以确保在不同领域中,可以独立训练指针的命名实体识别能力,使得每个领域中识别的命名实体的值不会互相干扰。尽管这种改进削弱了推理能力,但它提高了命名实体识别能力。
NerInfer模型是本文提出的改进模型。在不同领域设置了不同的命名实体识别指针,并使用槽值对本体集中的命名实体作为序列标注值,以提高命名实体识别指针的识别能力。由于对话状态追踪器在不同领域中有相似推理过程,因此设置参数共享槽推理指针以联合学习槽推理能力。最后,将2个指针相加得到新的指针作为最终槽推理生成器的输入,完成对话状态追踪。
通过比较表1中Trade模型和消融后的Trade-模型,可发现Trade-模型提高了测试集的联合目标准确率,这表明Trade模型的完全参数共享指针不如Trade-模型在各自领域独立训练对应的命名实体识别指针效果好,即参数共享命名实体识别指针不仅没有推理能力,而且容易导致多个领域间的命名实体互相混淆,产生错误识别。但在实际情况下,由于不同领域中的命名实体间没有任何交集,因此移除参数共享部分的指针可以帮助提高在不同领域中命名实体的识别能力。
通过比较本文提出的NerInfer模型和Trade模型,可发现NerInfer模型在验证集和测试集上均有显著提升。从表1可以看出,NerInfer模型在测试集上取得了0.782的联合目标准确率,比Trade模型提高了1.2%;NerInfer模型的轮次准确率达到0.924,比Trade模型提高了0.6%;NerInfer模型的联合F1值增加到0.819。性能提升主要来自两方面:一方面,NerInfer模型在其各自领域中独立训练命名实体识别指针,并通过引入槽值对本体集的命名实体知识作为识别目标来进一步提高指针的命名实体识别能力;另一方面,NerInfer模型通过引入具有参数共享的槽推理指针,可以联合训练多个领域间的槽推理能力,从而改进实验结果。
4 实验结果分析
首先分析Trade模型的误差,并根据分析结果选择命名实体作为进一步实验目标;然后对NerInfer模型的实验结果进行误差分析,验证模型在命名实体识别能力和槽推理能力上的提升效果。
4.1 命名实体识别能力
根据图3给出的误差结果,可以看出Trade模型在多领域测试集上5个领域槽的错误率最高:景点名称槽(attraction-name slot)、酒店名称槽(hotel-name slot)、饭店名称槽(restaurant-name slot)、出租车目的地槽(taxi-destination slot)和出租车始发地槽(taxi-departure slot)。这表明Trade模型在预测命名实体槽值以及出租车领域槽值方面具有很大改进空间。类似地,出租车领域的槽值与命名实体槽值的集合也存在一定交集,如用户可能会在预定出租车的领域对话中指出需要从某个景点出发去饭店,此时出租车的始发地和目的地都是命名实体槽值。因此,针对命名实体槽进行实验提升命名实体对话状态追踪能力,对应出租车领域的命名实体识别识别能力和槽推理能力即可得到有效提高。由此,本文选择命名实体槽进行实验。
进一步分析原始Trade模型在命名实体槽(name slot)和出租车领域始发地槽(taxi-departure slot)和目的地槽(taxi-destination slot)的对话状态追踪交互结果。我们选择实验结果中出租车领域的槽(taxi-domain slot)与命名实体槽具有相同值的对话进行分析,即出租车领域的槽值也属于景点、饭店、酒店的命名实体集合。
分析结果如表2所示。其中,列表示两种槽具有相同值,如attraction-destination,该列表示景点名称槽(attraction-bame slot)和出租车目的地槽(taxi-destination slot)具有相同槽值;行表示统计结果,表格内的值表示对话轮次数。对话总轮次为满足出租车领域槽与命名实体槽具有相同值的对话总轮数,该统计来自整个数据集。“预测正确”代表实验结果为正确预测的对话总轮数;错误的预测值为空的结果分为3种类型:“均为空”表示将命名实体槽和出租车对应槽值都错误地预测为不存在;“命名实体为空”表示只有命名实体槽被错误地预测为不存在;“出租车为空”表示只有出租车领域错误地预测为值不存在。值错误预测同样分为3类:“均错误”表示两个槽的预测值不为空,但是值均不正确;其他两类含义与“错误预测为空”中情况类似。
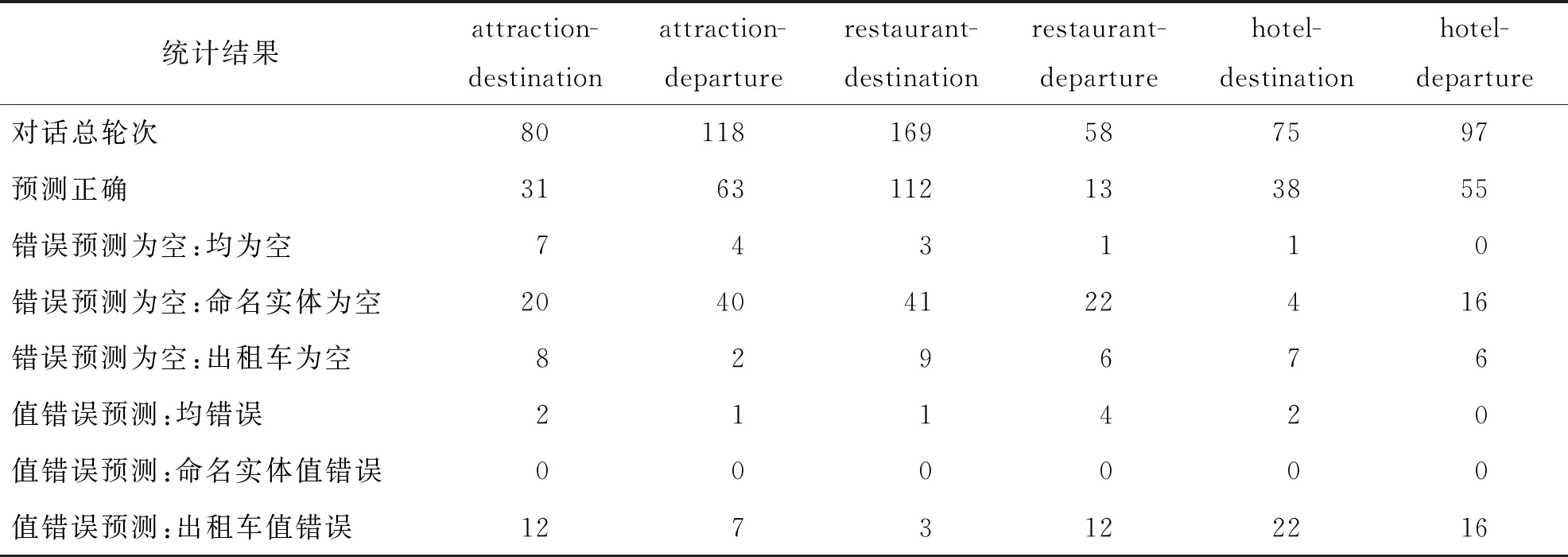
表2 对原始Trade模型的实验结果进一步详细分析的结果
实验结果显示命名实体槽值被错误地预测为空的对话轮次占据了错误预测结果的大多数。这意味着Trade模型从对话历史中识别命名实体的能力较弱;由于命名实体未被识别出来,即没有可以推理选择为槽值的候选项,导致对话状态更新时槽值无法更新。
“出租车值错误”显示出租车领域槽的值预测为其他命名实体值的情况占据了错误识别中很大一部分。在出租车领域,部分始发地槽和目的地槽可直接基于当前对话序列识别出对应值;但许多出租车的领域槽值与其他领域的命名实体槽值相关,对话状态追踪器需要根据对话历史上下文推理选择对应的命名实体槽值来更新对话状态。如用户希望从饭店A到达景点B,这时可能在出租车领域的当前对话中不涉及具体的命名实体槽值,却需要根据上文提到的饭店命名实体槽值和景点命名实体槽值来推理更新当前出租车领域的槽值。因此,出租车领域中值的错误预测情况与命名实体识别能力以及基于对话上下文的槽推理能力有关。综上,提高命名实体槽值的识别准确率,并提升多轮对话槽推理能力可有效提升Trade模型的性能。
4.2 实验误差分析
3个模型实验结果的进一步分析如表3和图4所示。分别对3个模型各领域的命名实体槽(name slot)进行统计分析,采用准确率、值错误率为评价指标。错误率细分为3种:“值错误率”表示槽值被错误地预测为其他命名实体槽值;“预测为空错误率”表示真实槽有对应的值,但是被错误地预测为空;“预测非空错误率”表示实际没有这样的槽值,但被错误地预测具有槽值。

表3 Trade模型、Trade-模型、NerInfer模型的实验结果对比分析
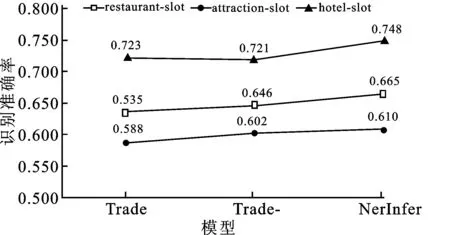
图4 Trade、Trade-、NerInfer模型预测准确率趋势图
从表3和图4可以看出,对于错误预测为空的值,NerInfer模型的错误率相比Trade模型和Trade-模型明显降低。因此,NerInfer模型中的命名实体识别指针帮助模型识别出更多命名实体,减少预测为空的情况,从而显著提高命名实体识别能力。更进一步,NerInfer模型可根据识别的所有槽值进行槽推理,完成对话状态更新。但从表3可发现,Trade模型的错误率较Trade-模型和NerInfer模型更低。这主要因为命名实体识别指针有助于找到更多相关的命名实体槽值,但其也会识别更多不相关的命名实体词,从而带来更多噪声。因此,即使加入参数共享的槽推理指针,总体的推理能力仍然减弱。为了进一步完善该部分,有必要提高槽推理指针的推理能力,以推理选择正确的实体值作为当前对话状态的槽值,这将是未来的工作方向。
5 结语
本文在分析Trade模型实验结果的基础上,发现命名实体识别准确率低的主要原因,并选择命名实体领域槽值进行实验。
基于槽值对本体集的命名实体知识信息,设计了命名实体识别指针与针对特定领域的槽推理指针,并基于2种指针设计槽推理生成器,实现了一种新的NerInfer模型,使模型在保留生成方法可扩展优点的基础上,有效利用槽值对本体知识信息。
在多任务多轮对话领域权威的MultiWOZ 2.1数据集上进行了一系列实验,实验结果表明所提出的方法能有效提升多轮对话系统对话状态追踪在命名实体识别和命名实体槽推理更新的效果。具体地,所提方法在联合目标准确率上提升了1.24%,联合F1值提升了0.96%。
未来,可进一步对其他领域的槽值进行实验,以及对需要推理识别的出租车领域进行实验,进一步提高出租车领域的命名实体识别准确率以及基于参数共享的推理指针在出租车等领域的槽值更新能力。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
软件学报(2020年6期)2020-09-23
中国外汇(2019年18期)2019-11-25
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
广东第二课堂·小学(2017年9期)2017-09-28
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
软件工程(2014年3期)2014-03-15
