
基于集成学习的胎心率缺失值填补算法
2022-06-08 03:59范蒙蒙张烨菲邓艳军邵李焕
杭州电子科技大学学报(自然科学版) 2022年3期
范蒙蒙,张烨菲,邓艳军,邵李焕
(1.杭州电子科技大学通信工程学院,浙江 杭州 310018;2.杭州电子科技大学电子信息学院,浙江 杭州 310018)
0 引 言
胎心宫缩监护(Cardiotocography, CTG)广泛用于评估胎儿在子宫内的发育状况,胎心率(Fetal Heart Rate, FHR)是CTG的核心生理信号之一。FHR指胎儿心脏每分钟跳动的次数,胎儿的宫内窘迫状态[1]使得胎儿心率出现偏低或偏高的异常现象。采用CTG监测FHR,并结合胎心率曲线对胎儿在孕妇宫内的状态进行评估,对预防胎儿酸中毒或宫内缺氧等危险情况的发生以及提高胎儿的出生率和健康率具有非常重要的意义。实际临床监测中,常常出现胎儿翻身、探头位置固定不佳或孕妇体位变化等状况,获取不到完整的胎心率信号。缺失值填补方法主要包括基于插值类的方法、基于字典学习类的方法和基于统计学习的方法。基于插值类方法比较简单,容易实现,适合填补缺失较少的数据段[2-3],比如线性插值[4]、三次样条插值[5]等。相比于插值类方法而言,基于字典学习类方法的实现略显复杂,不过能承受较多的缺失数据,比如高斯过程[6]、最优方向法(Method of Optimal Direction, MOD)[7]、K-奇异值分解(K-Singular Value Decomposition, K-SVD)[8]、移不变字典学习(Shift-Invariant Dictionary Learning, SIDL)[9]等,但连续缺失大量数据时,出现训练速度慢或过拟合。基于统计学习的方法先根据数据的均值、方差等特征来确定一个特殊的概率分布,再将最适合假定概率分布的值作为缺失数据的填补值[10],比如概率主成分分析法(Probabilistic Principal Component Analysis,PPCA)[11]、矩阵分解[12]等,通常需要结合数据的内在统计特征,在一定程度上限制了其应用场景。集成学习是一种提升学习器性能的方法,不仅可以得到性能更优的学习器,还可以降低模型的偏差,为此,本文提出一种基于集成学习的胎心率缺失值填补算法,提高了FHR信号的完整性。
1 基于集成学习的缺失值填补算法
1.1 集成学习
集成学习主要是先通过训练数据集产生多个弱学习模型,再使用平均法、投票法或学习法的结合策略生成强学习模型[13]。一般而言,集成学习要求个体学习器既要有一定的准确性,又要有不同的个体差异,经过一定组合策略生成的学习器才更具泛化性能,更好地完成特定任务。
根据弱学习器之间是否存在依赖性,集成学习可以分为Boosting和Bagging两大类。Boosting依据前一学习器的表现对样本分布进行调整,并基于调整后的样本分布训练下一学习器,得到更优性能的学习器[14]。Bagging随机有放回抽取训练样本进行模型训练,其后训练学习器的性能有可能比前一个学习器要差[15]。与Boosting相比,Bagging可以减小方差以及过拟合的风险,但由于是重复有放回采样,会产生一定程度的偏差,影响最终结果。Boosting不仅使得训练学习器的性能越来越优,还可以降低模型的偏差,因此本文采用Boosting。
1.2 最小二乘提升算法
常用的Boosting算法有自适应提升(Adaptive Boosting, AdaBoost)、梯度树提升(Gradient Boosting Decision Tree, GBDT)和极端梯度提升(eXtreme Gradient Boosting, XGBoost)。AdaBoost是一种精度很高的分类器,不易发生过拟合,但对异常值很敏感;GBDT既可以解决分类问题,又可以解决回归问题,对异常值的鲁棒性很强;XGBoost在目标函数中引入正则项,既降低了模型的方差,又有助于防止过拟合,但计算复杂度高。
本文研究的缺失值填补属于回归问题,AdaBoost是分类器不能解决回归问题,XGBoost计算复杂度高,故本文算法选择GBDT来填补缺失值。最小二乘提升(Least-Squares Boosting, LSBoost)[16]作为GBDT算法中的一种,以均方差作为损失函数,算法描述如下。

输入:训练集{(xi,yi)}Ni=1;损失函数L(y,F)=(y-F)2/2;迭代次数M。其中,y表示预处理后的胎心率信号,h(x;α)表示弱学习器,ρ表示对应弱学习器的权重,Fm(x)表示训练好的强学习器模型,N表示模型训练集中的样本数。 初始化,F0(x)=y For m=1 to M do︰yi=yi-Fm-1(xi),i=1,…,N(ρm,αm)=argminα,ρ∑Ni=1[yi-ρh(xi;α)]2Fm(x)=Fm-1(x)+ρmh(x;αm) End for输出:预测的信号值y'i=Fm(xi)
1.3 数据集
本文使用的数据集来自捷克技术大学布尔诺大学(Czech Technical University-University Hospital in Brno, CTU-UHB)的CTG数据库,共有552个原始胎心率信号,从2009—2012年的捷克共和国布尔诺大学医院产科病房9 164次分娩CTG记录中获得,所有信号的采样频率均为4 Hz。CTU-UHB数据库中使用的孕妇和新生儿生理参数的详细信息参见文献[17]。本文从CTU-UHB数据库中随机选取100例信号进行实验,其中训练集占70%(共70例),测试集占30%(共30例)。
1.4 信号预处理
本文采用线性插值法对原始FHR信号中的不稳定部分进行预处理。首先,移除值为0且持续时间大于15 s的FHR信号;然后,针对不稳定信号,即相邻两点幅值之差的绝对值大于25 bpm的信号段,在前一稳定部分的最后一个采样点和下一稳定部分的第一个采样点之间进行插值。数据库中的每例FHR信号包括14 400个时间点,实验随机截取信号的2 400个时间点进行研究。预处理的效果如图1所示。
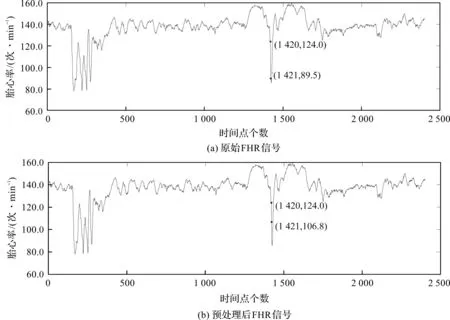
图1 FHR信号预处理结果
图1(a)中存在不稳定数据点(1 421,89.5),使用上一稳定部分的最后一个数据点(1 420,124.0)和下一稳定部分的第一个数据点(1 422,89.5)来构造线性方程,得到信号在1 421点处的胎儿心率值为106.8,即为通过线性插值进行预处理得到稳定的信号。
2 实验结果与分析
本文使用的实验数据来自CTU-UHB采集的CTG数据库,每例训练集的样本数N=1 680,迭代次数M=200,学习率为0.52。共进行3个实验,一是研究单段缺失的情况下,信号上升段、平稳段以及下降段所能承受的最大缺失点数;二是以更加直观的方式呈现缺失的单段数据在3种算法下的填补结果;三是研究多段缺失情况下,3种算法的恢复性能。使用均方根误差(Root Mean Square Error, RMSE)、平均绝对误差(Mean Absolute Error, MAE)以及欧氏距离(Euclidean Distance, ED)对算法的恢复性能进行评价。
2.1 单段缺失情况下,不同信号段允许缺失的最大点数
选取100例经过预处理的完整胎心率信号,在每例信号的平稳段、上升段和下降段各模拟30个缺失数据点,分别使用本文算法、均值填补算法、字典学习与稀疏编码填补算法对缺失值进行恢复,并绘制缺失点数与RMSE的曲线图,根据绘制出的曲线图确定每例信号的不同段允许缺失的最大点数,然后取平均值作为最终的结果。选择第125例信号的平稳段、上升段和下降段进行示例。
2.1.1 信号平稳段允许缺失的最大点数
在节能降耗检测工作中,能源计量技术发挥着重要的作用,该技术的有效应用可以极大地提升节能降耗数据采集与监测水平。本文主要对能源计量工作在节能降耗中的作用与地位进行简要分析,并且从节能降耗途径,能源计量的作用以及政策与公共节能3个角度进行了具体的分析。
信号平稳段的缺失模拟及恢复情况如图2所示。从图2可以看出,当缺失点数小于6时,字典学习与稀疏编码填补算法和均值填补算法的RMSE增长较快,本文算法的RMSE增加缓慢;当缺失点数大于6时,3种算法的RMSE都在增加,且增速相对之前较快。综合3种算法的性能表现,设定信号在平稳段的最大缺失长度为6。

图2 3种算法在信号平稳段允许缺失的最大点数
2.1.2 信号上升段允许缺失的最大点数
信号上升段的缺失模拟及恢复情况如图3所示。从图3可以看出,当缺失点数小于18时,字典学习与稀疏编码填补算法和本文算法的RMSE在缓慢增加,均值填补算法的RMSE增速相对较快;当缺失点数大于18时,字典学习与稀疏编码填补算法和均值填补算法的RMSE增速加快,但本文算法的RMSE仍在缓慢增加。综合3种算法的性能表现,设定信号在上升段的最大缺失长度为18。
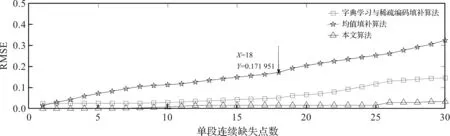
图3 3种算法在信号上升段允许缺失的最大点数
2.1.3 信号下降段允许缺失的最大点数
信号下降段的缺失模拟及恢复情况如图4所示。从图4可以看出,当缺失点数小于8时,字典学习与稀疏编码填补算法和本文算法的RMSE在缓慢增加,均值填补算法的RMSE增速相对较快;当缺失点数大于8时,3种算法的RMSE都在增加,且增速相对之前较快。综合3种算法的性能表现,设定信号在下降段的最大缺失长度为8。
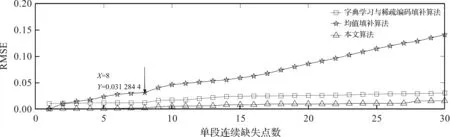
图4 3种算法在信号下降段允许缺失的最大点数
2.2 单段缺失情况下,不同信号段的填补结果
根据不同信号段上允许缺失的最大点数来模拟缺失的数据段,并绘制填补结果图,更加直观地分析本文算法、均值填补算法、字典学习与稀疏编码填补算法的恢复性能。
2.2.1 信号平稳段的填补结果
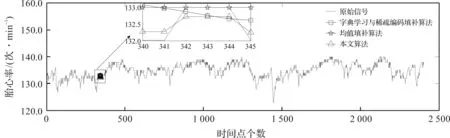
图5 3种算法在信号平稳段的填补结果
从图5可以看出,本文算法的填补结果与原始信号波形更相似,而均值填补算法和字典学习与稀疏编码填补算法的填补结果明显不太理想。
2.2.2 信号上升段的填补结果
由2.1.2节实验可知,信号上升段最多允许缺失18个数据点,随机将该上升段的连续18个点的值置为0,分别使用3种算法进行填补,填补结果如图6所示。

图6 3种算法在信号上升段的填补结果
从图6可以看出,本文算法的填补结果与原始信号重合程度较高,字典学习与稀疏编码填补算法次之,均值填补算法最差。
2.2.3 信号下降段的填补结果
由2.1.3节实验可知,信号下降段最多允许缺失8个数据点,随机将该下降段的连续8个点的值置为0,分别使用3种算法进行填补,填补结果如图7所示。

图7 3种算法在信号下降段的填补结果
从图7可以看出,均值填补算法的结果最差,而本文算法的填补结果与原始信号拟合程度较高。
2.3 多段缺失情况下,不同算法的恢复性能
在确定不同信号段允许缺失最大点数的基础上,选取100组信号进行实验,每组取3段,分别计算本文算法、均值填补算法、字典学习与稀疏编码填补算法在相同信号段上的RMSE,MAE和ED,并取其平均值,结果如表1所示。

表1 不同算法在不同信号段上的性能
从表1可以看出,本文算法的均方根误差、平均绝对误差和欧氏距离均小于其他2种算法,说明本文算法对FHR信号的恢复性能更优。
3 结束语
本文提出一种基于集成学习的胎心率缺失值填补算法。通过研究FHR信号段的缺失情况,采用集成学习方法进行FHR信号段的填补,提高了胎心信号缺失值的预测精度。下一步将继续优化算法,将算法运用到临床数据中,不断改进算法的可实践性。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
中国保健营养(2019年4期)2019-09-10
小学阅读指南·低年级版(2019年11期)2019-07-01
小天使·一年级语数英综合(2017年11期)2017-12-05
小学生导刊(低年级)(2016年11期)2016-11-14
读者(2016年14期)2016-06-29
母子健康(2016年2期)2016-05-18
数学大王·中高年级(2016年8期)2016-05-14
为了孩子(孕0~3岁)(2016年3期)2016-03-11
数学大王·中高年级(2014年7期)2014-08-06
