
一种基于FPGA的通用卷积神经网络加速器的设计与实现
2022-06-16 05:25李沙沙李夏禹刘珊珊赵晓冬
复旦学报(自然科学版) 2022年1期
李沙沙,李夏禹,刘珊珊,赵晓冬,俞 军
(上海复旦微电子集团股份有限公司,上海 200082)
得益于互联网的发展(使得神经网络能够获得大量的训练数据)、计算机自身算力的提升、以及算法技术的进步,卷积神经网络(Convolutional Neural Network, CNN)在21世纪10年代取得了爆发性的进展。如今,CNN已在经济、社会治理、日常生活等方方面面得到了广泛的应用,并产生了积极的影响,推动着各个产业进行智能化的转型。伴随着应用场景的拓宽,新的网络结构不断涌现,网络运算量及存储需求不断增大,对硬件提出了更高的挑战。为了实现更小的延时、更低的功耗、更好的性能,探索神经网络的硬件加速方案已经十分必要。
本文提出了一种具有可配置性的卷积神经网络终端推理芯片,可用于完成图像分类和目标识别任务。通过采用一套专用的CNN指令集,灵活控制硬件支持不同的CNN网络,具有较强的通用性;在领域相关文献的基础上,结合硬件资源限制,设计了采用权重固定数据流的卷积方式,高效地复用了权重值,充分利用了现场可编程门阵列(Field Programmable Gate Array, FPGA)的并行性;对数字信号处理器(Digital Signal Processing, DSP)器件进行了拆分,使一个DSP可同时实现2个8 bit乘法,实现了算力的加倍;在平均池化的计算中,采取了一种“伪卷积”的方式,以卷积介质访问控制层乘加器阵列(Multiplier and Accumulation, MAC)阵列来实现平均池化,避免消耗额外的逻辑资源;最后在Xilinx Kintex-7 XC7K325T FPGA上进行了验证。
1 CNN网络介绍及硬件加速原理
第1个成功商用的卷积神经网络是LeNet[1],它包含2个卷积层和2个全连接层,卷积核的尺寸都是5×5,每个卷积层后紧跟着一个平均池化层,仅使用一个sigmoid函数作为激活函数层。2012年的AlexNet[2]是第1个赢得ImageNet挑战赛的CNN,它包含5个卷积层和3个全连接层,不同层的卷积核尺寸不相同,在每个卷积层后都引入了激活函数ReLu(Rectified Linear Unit, 修正线性单元)。VGG16[3]的网络层数增加到16层,其中卷积层达到了13层,并在所有层采取3×3大小的卷积核减小计算负担。2014年的GoogLeNet[4]的层数则更深,它引入了inception块,一个inception块中有4条并行的路径,使用1×1卷积来减小通道数,使用3×3和5×5这两个不同大小的卷积核以在不同尺度上处理输入图片。2015年的ResNet[5]的思想是采用残差块来解决训练中的梯度越来越小的现象。残差块在传统的路径外增加了一条路径,使得输入特征图可以跳过两层卷积,与原路径的输出结果相加,将浅层的信息带入了更深的层,以增强训练效果。
网络结构的推陈出新以及网络深度和参数的不断增加,对卷积神经网络加速器的通用性、算力及存储能力都带来了挑战。FPGA因为灵活性高,可支持各类不同的任务,同时成本相对较低,较好地平衡了性能、灵活性、成本等因素,十分适用于实现CNN硬件加速的任务。而针对算力及存储压力: 一方面可以优化卷积的运算方式、减少乘加次数,一方面可以采取诸如数据复用等方法减少片外访存。在优化卷积运算的方向上,典型方法是winograd算法[6],商汤科技发布了一种利用winograd在FPGA上实现卷积的结构[7],利用转换矩阵减少矩阵乘中的乘法运算,以降低计算复杂度,但当卷积核尺寸较大时,加法的数量会大幅增加;优化卷积还可以利用卷积中矩阵的稀疏性。寒武纪公司的Cambricon-X芯片[8]使用一个索引表来描述非零权重之间的距离,在计算时根据此表进行解码来得到输入激活的索引,以减少对权重中0元素的计算。而在数据复用的方向上,可以通过设计数据的流动方式,来减少访存,提高效率。典型的数据流包括权重固定、输出固定、行固定等[9]。深鉴科技于2017年提出了Angel-eye[10],其采取一种权重固定的数据流,在不同的处理元件(Prcocessing Element, PE)里固定着不同输出通道的权重值,各PE间共享输入通道特征值,并行计算各输出通道卷积。在寒武纪的ShiDianNao[11]加速器中,采用了一种输出固定的数据流来实现数据复用,每一个PE会计算一个感受野的卷积。每一拍计算一个乘积并寄存在PE内部,与下一拍本PE的计算结果累加,直到一个感受野的乘累加结束再统一输出。但由于参数全存储在片上静态随机存储器SRAM(Static RAM),对于网络规模有了很大的限制。在Eyeriss[12]中还有一种行固定的数据流,它在每个PE里都暂存一行的权重值,这样只要让一行输入特征值在PE中滑动,就可以用一个PE计算一行的结果。但由于在每个PE内部都做了较大的buffer缓存,同样不适用于网络较大的情况。
可以看到,以往的许多工作往往较为专用,缺乏通用性及可扩展性。本文所提出的CNN加速引擎,通过指令集的控制可支持各种不同的卷积尺寸以及网络大小,在具备通用性的同时充分地利用了FPGA的硬件资源,达到了较高的算力及能效。
2 CNN加速引擎硬件设计
2.1 核心架构
本文中CNN核心加速引擎的架构如图1所示,采用2块SRAM分别存储输入特征图(Input Feature Map, IFM)和输出特征图(Output Feature Map, OFM);采用1个MAC和单独的激活池化单元完成卷积、激活、池化、全连接等运算;通过指令分发模块将指令传输到各自对应的指令执行模块,控制数据的流动与计算。

图1 CNN加速引擎的架构Fig.1 CNN acceleration engine architecture
在一次网络推理中,首先主机会通过PCIe或AXI总线将权重参数、待测图片、指令等数据写入双倍数据速率(Double Data Rate, DDR),并且通过配置寄存器启动硬件工作。接下来指令分发模块会从DDR中读取指令分发到各个子模块的指令控制模块中,开始从DDR中读取数据到片上进行缓存和运算。为了提高效率以及进行数据复用,在IFM RAM和OFM RAM以外,额外采取了先进先出(First Input First Dutput, FIFO)模块来存放从DDR中读取的权重数据及卷积偏置(bias)数据。同步后的权重和输入特征图会被送入MAC阵列进行卷积乘加操作,并将结果写入OFM RAM。在得到最终卷积结果后从OFM RAM中读出并进行激活和池化运算,最终写入DDR。
2.2 计算模块
本文中的计算模块主要包含MAC阵列和激活池化单元。
卷积运算是CNN推理过程中运算量占比最大的部分。假如输入特征图的通道数为ic,卷积核的输出通道数为oc,卷积核长度为kw、宽度为kh,输出特征图的长度为ow、宽度为oh,则最直接的算法如图2所示。

图2 卷积算法Fig.2 Convolution algorithm
这种算法中的计算不存在并行性,显然不能直接应用,在本文中对该算法进行了改进,如图3所示。

图3 改进后的卷积算法Fig.3 Improved convolution algorithm
首先根据硬件资源将卷积核按输出通道分组,每组包含固定数目(如OC_num)个输出通道。一组内的不同输出通道并行计算,计算完一组的卷积再计算下一组。在计算一组内卷积时,再将输入特征图在面上划分为一定数目的大Tile,如图3中Tile1所示。对于每个大Tile,里面再按照输入通道分为小tile。每个小tile包含固定数目(如IC_num)个输入通道,一个小tile内的各个输入通道计算是并行的,各个小tile之间的结果需要累加。每次运算会将一个小tile从DDR中加载到存放输入特征图的RAM里,和固定数目个输出通道进行卷积。在小tile的内部计算中,对于一个输出通道的卷积核,无论它的尺寸是多少,均展开为该卷积核尺寸个1×1× IC_num的卷积核去扫描整个输入特征图,因此可支持任意尺寸的卷积核。而由于加载输入特征图是通过指令控制的,因此卷积的填充(Padding)和步长(Stride)可通过指令参数寻址读取相应地址的特征值来实现。通过这样的改进,实现了输入通道间和输出通道间的并行计算,有效复用了权重值和输入特征值。
基于以上算法,结合硬件资源限制,本文设计了脉动阵列形式的MAC阵列。如图4所示,MAC阵列由64行×16列个PE单元组成,可并行计算64个输入通道,32个输出通道的卷积结果。在计算过程中,卷积的权重值固定在每个PE内,输入特征图按照通道并行输入到阵列,从左至右传递;而每一行的PE都会计算当前输入特征值和权重值的乘积,并将此乘积与上一行PE传来的部分和相加并向下传递,最后输出多个通道的输出特征图中间结果。在阵列的输入一侧和输出一侧根据脉动阵列的运算形式添加了三角形的延迟链,用以将数据对齐。由于数据在阵列中脉动,每个单元的数据仅向邻近的单元传递,因此具备高集成度,工作频率高的特点。同时,针对输入通道数较小的输入层,本文根据卷积核的尺寸对输入特征图进行重排。比如对于输入通道以及长和宽都为3的卷积核,会将这个卷积核对应的27个特征图数据都当做不同输入通道数据进行排列(相应的会去改变卷积核的排布),通过这种方式将3通道拓展至27通道,从而提高MAC利用率。
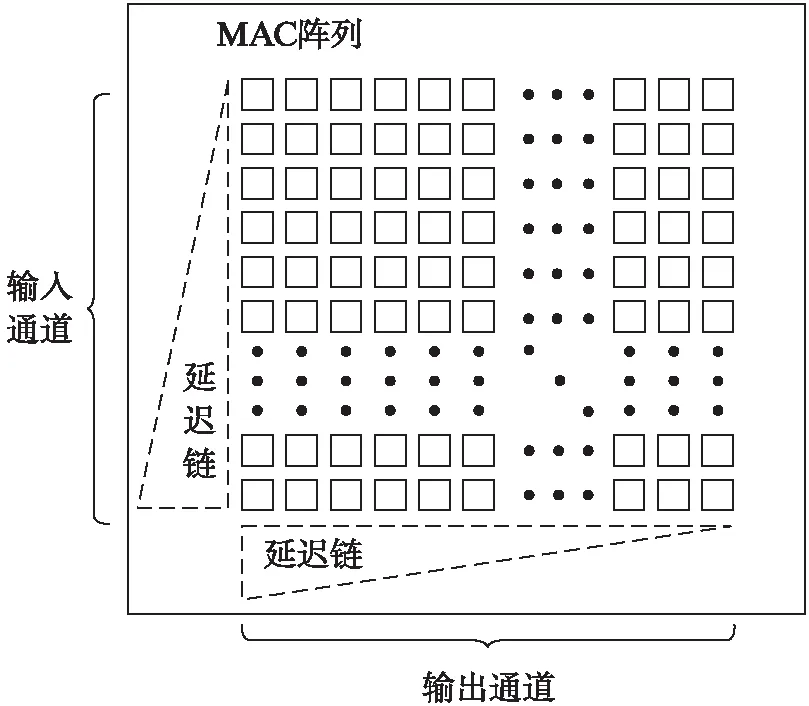
图4 卷积乘累加阵列Fig.4 MAC array
MAC阵列中单个PE的结构如图5所示,包含有: 一组输入数据寄存器缓存数据,一组预载入参数寄存器和两组权重参数寄存器。输入数据和权重进行乘加运算,运算的结果存储在结果寄存器中,并向下方的PE传递。权重参数先存储在预载入寄存器中,需进行计算时载入权重寄存器中。这里一个PE单元中包含2个乘法器的原因是这2个8 bit乘法器实际是由一个DSP拆分得到的。在PE中,一个输入特征值b需要分别与2个输出通道的权重值a和d相乘。由于DSP48E1最大支持25 bit×18 bit的乘法,我们通过做运算P=(a≪16+d)×b,使用1个DSP单元实现了a×b和d×b。

图5 处理单元的电路结构Fig.5 PE architecture
当卷积完成后,会将卷积结果从OFM RAM中读出,进行激活与池化运算。激活池化单元中包含激活表模块和最大池化模块。激活函数大部分是非线性函数,目前常用的实现激活函数的方法主要包括: 使用查找表(look_up_table)查出结果、采用分段线性函数逼近原函数、有理数近似法、坐标旋转数字计算方法(Coordinate Rotation Digital Computer, CORDIC)[13]。查找表法简单通用,且精度较高,但会消耗存储资源。分段线性逼近其实仍然需要使用查找表,但它是将激活函数划分成一个一个的直线段,表中只需存储每个分段的斜率和截距(或段首段尾的输出值),对输入数据进行查表得到其所在分段的参数,再通过线性运算得出结果。有理数近似法是将函数利用数学方法展开,同样需要较高的计算资源。而CORDIC算法则是采用一些加法、减法、移位等较为基础的计算来实现乘法,较为通用,但性能不高。本文在对硬件资源和激活精度进行综合考量之后,选择使用查表法实现激活,在激活表模块中例化了32个256深度的查找表,可同时对64个输出通道的结果进行激活。
最大池化模块采用比较器实现,其结构如图6所示。一组池化数据会携带pool first和pool last信号,每一拍新输入的数据会和上一拍的数据进行比较,将较大数在寄存器里暂存,当pool last信号到来后输出最终结果。由于池化具有空间特征,因此从OFM RAM中取数需要按照池化的要求来寻址,得到的数据先进行激活再进行池化。取数时采用了二重矩形寻址。如图7所示,假如最大池化的池化尺寸是2×2,那么每个loop1就是一个2×2池化区域的寻址,它们的大小和寻址跳转方式都相同,而loop2会产生每个loop1的首地址,通过这样的跳转,完成整个特征图的池化。
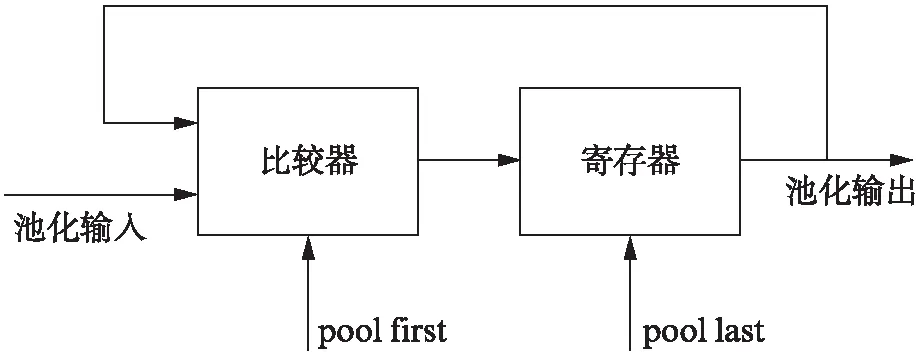
图6 池化结构Fig.6 Pooling structure

图7 池化寻址Fig.7 Pooling module addressing
平均池化是对一个池化区域的特征值取平均值,假如直接用逻辑实现的话,会消耗除法器资源。事实上平均池化相当于给一个池化区域的所有特征值乘以1再相加,最后再除以池化尺寸,这个特征值乘累加的过程和卷积是一致的,因此可以直接使用卷积MAC阵列来实现累加。而最后除以池化尺寸的操作,可以通过构造伪卷积的权重值来实现。采用这种伪卷积的方式实现平均池化时,无论池化尺寸是多大,都采取1×1的卷积,通过在指令中控制累加的次数来适配不同的池化尺寸。且一个filter中,只有一个通道的值为池化尺寸的倒数,其他通道均为0,所有filter排布在一起,非零值呈对角线分布,如图8所示,以3输入通道为例示意,当输入特征图是3通道时,卷积核的输出通道也是3。
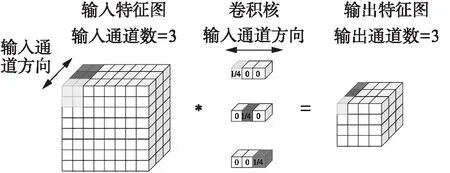
图8 平均池化的实现Fig.8 Implementation of average pooling

图9 输入特征图缓存Fig.9 IFM RAM
2.3 片上存储
如前文所述,片外存储器DDR虽然容量较大,但带宽不足,且高频地进行数据搬运也会造成巨大的能耗。因此需要片上存储,来增加访存速度,降低访存功耗。在本文中,主要采取了两类SRAM: 存放输入特征图的IFM RAM和存放输出特征图的OFM RAM。为了提高效率,降低数据的等待时间,在IFM RAM和OFM RAM中均采取了乒乓的设计。以IFM RAM为例,在从DDR中读取输入特征图写入IFM SRAM0的同时,可以并行地从IFM SRAM1中取数进行后续的卷积操作,这样当IFM SRAM1中数据计算完成,可不间断地从IFM SRAM0继续取数,如图9所示。
此外,为了进一步提高效率,还采用了2个FIFO分别用于存放权重数据和卷积偏置数据。只要FIFO为空,就会不断地执行指令,将权重和偏置从DDR中读到片上,在FIFO中进行缓存。这样使得MAC阵列在需要更新权重数据时,不用等待从DDR中读数这一过程,而是可直接从FIFO中读取。
2.4 控制逻辑
为了能够灵活地实现不同网络的推理,本文设计了一套专用的CNN指令集,共包含11条指令。每条指令的位宽都是固定的64 bit,指令的高4 bit标识指令的ID,根据ID进行指令的分发;指令的低60 bit是指令的参数,根据指令的不同可携带卷积核尺寸、池化尺寸、DDR寻址基地址等各种信息。指令的数据格式如表1所示,各条指令的含义如表2所示,在整个电路中,各个执行模块顺序执行分发给自己的指令,各模块彼此之间并行运行,通过IFM RAM和OFM RAM的状态来做指令同步。指令只有在存储器状态标志满足要求的时候才可开始执行,而部分指令执行完成后又会去设置存储器和DDR的状态标志位,以此来满足网络推理的顺序要求,实现指令同步。

表1 指令数据格式
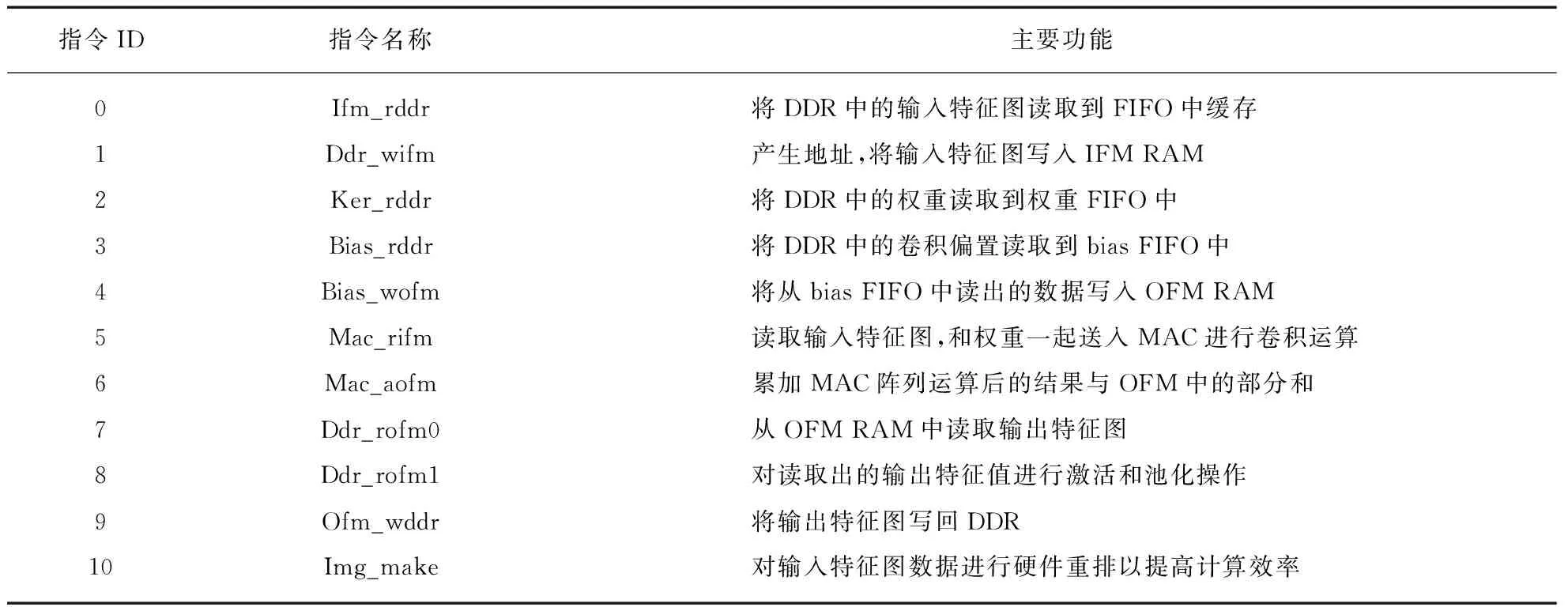
表2 指令含义
以OFM RAM为例,它的有效状态有3个: S0代表SRAM可被写入;S1代表可被读出进行累加;S2代表可被读出到DDR。上电后进入初始状态S0,当网络开始运算,可以执行读取bias的指令;读取完成后状态跳转到S1,可以执行MAC阵列累加指令;当累加完成,状态跳转到S2,可以执行特征图写入DDR的指令;当写DDR完成,回到初始状态,可以开始读取后续的输入特征值进行下一次计算。状态转移过程如图10所示。不同网络层的计算中,通过DDR的状态来保证这一层读取的数据是上一层的有效输出数据。
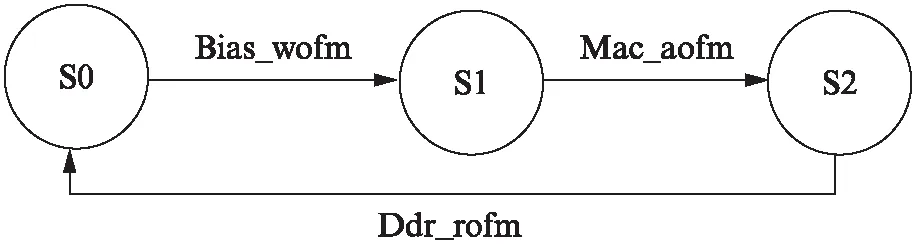
图10 OFM RAM的状态转移Fig.10 State transition of OFM RAM
3 实验结果与分析
3.1 实验设计
本文采用Xilinx KC705开发板,基于Xilinx XC7K325T FPGA进行了实现与测试。在主机提供客户端程序,通过PCIe接口将待识别图片数据、网络模型数据、指令、控制信号等传输到FPGA端,并将数据与指令写入片外DDR,控制信号写入寄存器。开始网络计算后,读取DDR中的指令与数据到CNN加速引擎中进行网络推理,计算完成之后,仍将结果写入DDR,再通过PCIe返回主机。整体平台结构如图11所示,无PS接口,采用PL实现CNN加速引擎。加速引擎工作时钟为200 MHz,包含2 048个int8乘法器,片外挂载一块2 GB的DDR。

图11 整体平台结构Fig.11 Overall platform structure
3.2 资源占用
本文采用vivado 2018.3工具进行布局布线,最终资源占用情况如图12所示,可以看到,片上的DSP资源基本已全被利用,而BRAM资源约使用了一半。这是由于DSP数量有限,一次只能从RAM中读取固定数量的数据进行乘加操作,在这种情况下,再增大RAM对效率的提升是没有意义的。
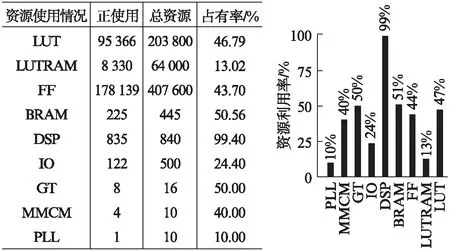
图12 资源利用率Fig.12 Utilization of resources
3.3 网络推理效率及精度
本文的CNN加速引擎对应开发了一套软件开发包(Software Development Kit, SDK),可将CNN网络算法编译生成平台支持的指令序列,并将指令序列和网络参数部署到硬件上,控制硬件完成网络推理。通过该软件,可得到整个网络或每层的带宽资源占用情况、加速引擎运行时间、加速引擎MAC利用率等信息。MAC利用率是一段时间里的实际计算量与理论上应该完成的计算量之比。
对经典分类和检测网络的上板运行情况进行了分析,结果如表3所示。可以看到,所有网络的MAC利用率都达到了70%以上,MAC阵列在大部分时间都得到了充分的利用,且DDR空闲时间充裕,带宽与算力之间相对匹配。对于不同的网络,根据其网络中每层通道数及尺寸的不同,MAC利用率会有一些差异。当某层网络输入通道数较小时,在实际计算时会将通道补齐到MAC阵列的输入通道数64,于是有效的MAC利用率变低;而SSD300的MAC利用率会超过100%,是由于软件编译时对原始网络进行了一定的优化,从而使MAC利用率大于100%。

表3 网络推理效率

表4 网络推理准确度
对Yolo V2及VGG16网络进行了上板推理精度测试,结果如表4所示。表中定点结果与浮点结果的误差主要是网络量化引入的,量化带来的精度损失与网络模型的具体结构有关。虽然VGG16在加速平台上定点化后top1精度损失了大约2个百分点,但Yolo V2在量化后的mAP反而略有提升。总体来讲,精度误差在可接受范围内,取得了较好的加速效果。
3.4 性能
将本文与其他基于FPGA的主流加速器进行了对比,结果如表5(见第76页)所示。可见,与其他工作相比,本文工作在保持较低功耗的同时达到了极高的算力和能效,算力达到819.20 GOP/s,能效达到63.00 GOP/(s·W),约为其他工作的3~10倍。除去硬件平台不同带来的影响,主要是因为将每个DSP拆分成2个乘法器的方法极大提高了MAC阵列的计算能力,而高效的卷积数据流使MAC阵列达到了极高的利用率,充分利用了芯片的硬件资源。

表5 加速器性能对比
4 结 语
本文首先介绍了经典CNN网络的结构变迁,结合一些已有的CNN加速器设计讨论了硬件加速的原理,然后提出了一种基于FPGA的卷积神经网络终端推理芯片,对其整体架构、核心电路以及网络层映射进行了介绍。通过指令控制,本文的CNN加速器可支持各种类型的网络及各种尺寸的输入图片或卷积核,具有较强的通用性。在Xilinx XC7K325T芯片上进行实验,在200 Mhz的时钟频率下,算力可达到819.20 GOP/s,能效可达到63.00 GOP/(s·W),相较同类产品具有显著优势。
猜你喜欢
计算机应用(2022年9期)2022-09-25
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
软件导刊(2022年3期)2022-03-25
北京航空航天大学学报(2022年2期)2022-03-08
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
学校教育研究(2020年11期)2020-06-08
航空科学技术(2019年2期)2019-09-10
智能计算机与应用(2018年2期)2018-05-23
