
基于佐证图神经网络的多跳问题生成
2022-06-21 07:47庞泽雄
中文信息学报 2022年5期
庞泽雄, 张 奇
(复旦大学 计算机科学技术学院,上海 200443)
0 引言
问题生成任务(Question Generation,QG)旨在对给定的一段文本生成一个合理的问题,这在自然语言理解领域中是非常具有挑战性的一个课题。问题生成有很多潜在的应用场景,例如,在问答系统中利用QG模型提供标注数据[1],应用QG辅助教育领域中的测试和评估[2],在智能聊天机器人中实现持续对话[3]。
之前大多数问题生成相关研究关注于只需要初步推理的简单问题生成,例如,Du等[4]在SQuAD[5]数据集上使用一个含有答案的句子作为模型的输入就可以生成相对自然的问句。在现实应用中,多跳问题生成这一任务无疑更具挑战性,模型需要在理解多段文本的语义的情况下,根据多个不同的信息点进行多步推理才能生成足够复杂的高质量问题。
最近的一些研究已经在尝试去解决多跳问题生成所面临的一些挑战。Pan等[6]构建了一个语义级别的图网络去建模文档的表示,然后把图表示向量融入到多步的推理过程中;Xie等[7]直接利用QG的评价指标,通过强化学习方法去提升模型效果。然而文档中信息的重要性是不同的,只有小部分句子中包含有关键的信息点。以图1的样本为例,文档1和文档2中只有前两个句子之间含有与答案相关的关键信息(Apple Remote,Front Row)。在给定答案“keyboard function keys”时,模型需要准确地捕捉到“The device was originally designed to interact with the Front Row”这一信息点。因此,选择语义层次优先的句子,忽略无效的信息点,可以帮助构造一个更鲁棒的问题生成系统,本文把这一类提供支持事实信息的句子统称为佐证句(Evidence)。这种思想也十分类似于人类提问的过程,先提取出需要的知识点(what to ask),根据知识点构造自然问句(how to ask)。
本文提出了一个新的方法,基于佐证句选择的图神经网络(Graph-based Evidence Selection network,GES),它将多跳问题生成划分为两个子任务: 佐证句选择和问题生成,并把两个子任务统一到序列到序列(Seq2seq)的框架中来。我们首先使用基于自注意力机制的编码器得到不同文档的词嵌入表示,进一步得到各个句子的向量表示。然后我们引入图注意力网络(Graph Attention Network,GAT),融合不同句子间的信息,通过图神经网络的多步迭代来显式建模语义理解中的多步推理过程,基于句子层级的模型结构也体现了文档中的层次结构信息。判断句子是否为佐证句的二值信号会作为偏置信息输入到解码器中辅助问题的生成。因为佐证句预测是一个离散的任务,会阻碍梯度的回传,所以本文使用了直通估计量(straight-through estimator, STE)来处理反向传播,使得Seq2seq模型可以端到端地训练。
本文在HotpotQA数据集[8]上进行了充分的实验,在BLEU等文本生成通用的自动指标上取得了显著提升。佐证句预测的定量分析也表明GES模型可以准确地选出语义信息相对重要的句子,进而提升生成问题的质量。同时这也增强了多跳问题生成模型的可解释性,为后续该领域的进一步研究提供了相应的理论基础。
1 相关工作
随着深度学习和神经网络模型的发展,问题生成技术从基于规则的方法逐步过渡到基于序列到序列的神经网络方法,之后的大多数工作都是在此基础上的延伸。Zhou等[9]在编码中加入了命名实体,词性等语言学特征;Song等[10]在解码器中引入拷贝机制(copy mechanism)来解决稀有词问题(Out of vocabulary, OOV)。Tuan等[11]提出了多阶段注意力机制来建模文档中句子级别的信息交互。
近年来图神经网络也被应用于各种自然语言处理任务中,取得了很好的效果。Chen等[12]在编码—解码结构中引入了基于强化学习的图网络; Li等[13]在多文档摘要生成中引入了多种图表示学习来提升生成摘要的质量;Wang等[14]在抽取式摘要生成中引入了异质图神经网络来建模不同粒度的文本表示;Qiu等[15]在多跳问答中引入了一个动态融合图神经网络来提升模型效果。
与本文工作类似,Pan等[6]、Su等[16]也通过引入图神经网络的方法来辅助多跳问题生成。之前的工作大多是构建基于实体关系或者不同语义粒度的图模型来显式学习多段文本间的关系。而本文提出的方法是在此基础上利用图神经网络来辅助佐证句的选择,从而提升多跳问题生成的效果。
2 主要方法
2.1 问题定义
本节会对多跳问题生成给出一个准确的定义。给定不同文档组成的原文C=(c11,c12,…,cmn),其中,cmn代表文本中第m个句子的第n个单词,问题对应的答案A=(a1,a2,…,ak),问题生成任务的目标是生成一个连贯且符合逻辑的问句Q=(q1,q2,…,qt)。图2显示的是本文方法的结构图。
2.2 序列编码器
之前的问题生成模型大都使用了循环神经网络(RNN)作为Seq2seq框架的基础模型,而近年来基于自注意力机制的Transformer[17]已经在机器翻译或摘要生成等领域中广泛应用,并且取得了比RNN模型更好的效果。此外,在与问题生成互补的机器问答领域,基于Transformer的预训练语言模型展现出了与人类媲美的自然语言理解能力。因此本文引入BERT[18]作为Seq2seq框架的编码器。
在多跳问题生成中,模型需要处理多个句子的输入,为了标识每个对立的句子,在每个句子的开头我们加入了[SENT]标签,编码器最终输出的[SENT]向量就是对应句子的特征表示。受UniLM[19]的启发,我们将答案和原文拼接到一起输入到编码器中,通过分隔符[SEP]来区分不同的文本。序列编码器的隐层向量可以表示如式(1)所示。
E,H=Transformer(C,A)
(1)
其中,E=(e1,e2,…em,ea)代表各个句子和答案的隐向量表示,ei是Transformer最顶层第i个[SENT]标签的输出结果。
2.3 佐证句选择网络
佐证句任务旨在判断这个句子是否可以为问题生成提供支持事实,然后赋予对应的0或1二值符号。我们认为候选的佐证句含有与答案和原文最相关且最重要的信息。为了从冗长的文本中对信息点进行查找和推理,本文构建了一个句子级别的全连接图神经网络。
2.3.1 佐证图神经网络
一般地,给定编码器输出的句子隐向量表示作为图网络表示的初始值u0,佐证图神经网络由K层图注意力神经网络[20]组成,uk表示第k层图网络的隐层表示。首先我们通过一个多层感知机的结构来计算每个节点与相邻节点间的注意力权重,如式(2)所示。
(2)
其中,Wa,Wq,Wk都是可以学习的参数,“||”表示连接操作,与注意力机制相同,最后使用softmax函数来归一化权重,如式(3)所示。
(3)
然后我们通过注意力权重和相邻节点表示的线性运算得到对应节点在第k层的特征表示,如式(4)所示。
(4)
为了避免多步迭代后出现梯度消失的情况,在每一层图网络后我们加入了一个残差单元,因此第k层图网络的最终输出可以表示如式(5)所示。
(5)
2.3.2 佐证句预测
在堆叠多层图网络后,我们通过图模型的最终输出来判断这个句子是否为问题生成提供了支持事实,如式(6)、式(7)所示。
MLP是一个多层感知机,σ表示sigmoid非线性激活函数,gi是第i个句子被选为佐证句的概率,zi是一个二值控制门,决定句子是否被选为佐证句。
连同序列编码器输出的词表示,我们将佐证句的位置信息反馈给模型,用于辅助问题生成。因为zi是一个二元标量,我们使用一个词嵌入矩阵D∈R2×d得到一个和隐状态H同维度的词嵌入表示si。最后我们将si和对应句子的词表示相加得到最后的隐状态表示,如式(8)所示。
fij=LayerNorm(hij+si)
(8)
其中,hij代表第i个句子中第j个单词的隐状态,整个隐状态表示矩阵定义为F。
2.4 训练策略
模型通过最小化参数的负对数似然来训练,如式(9)所示。
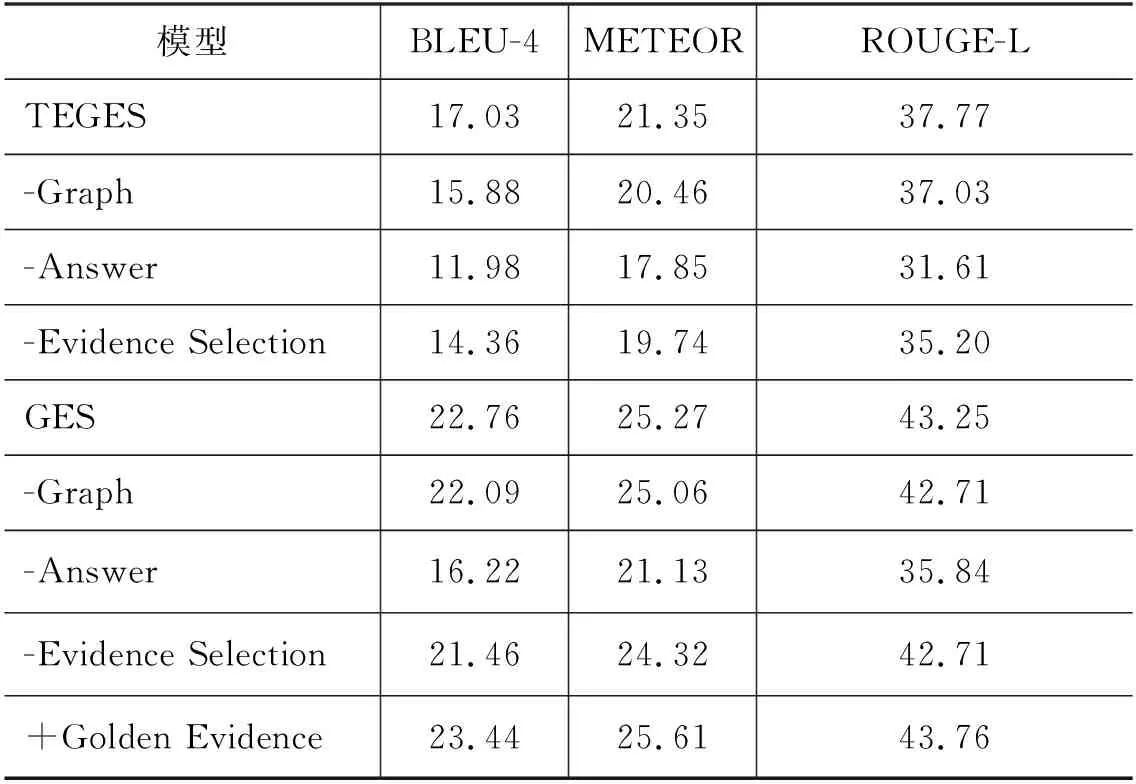
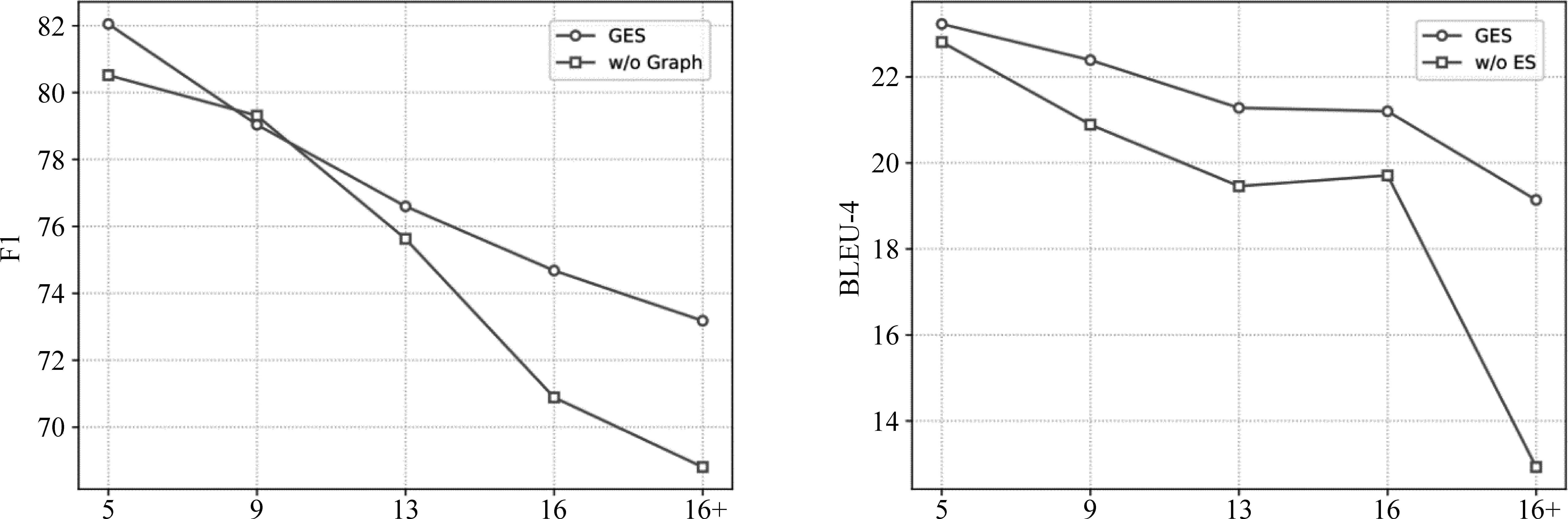
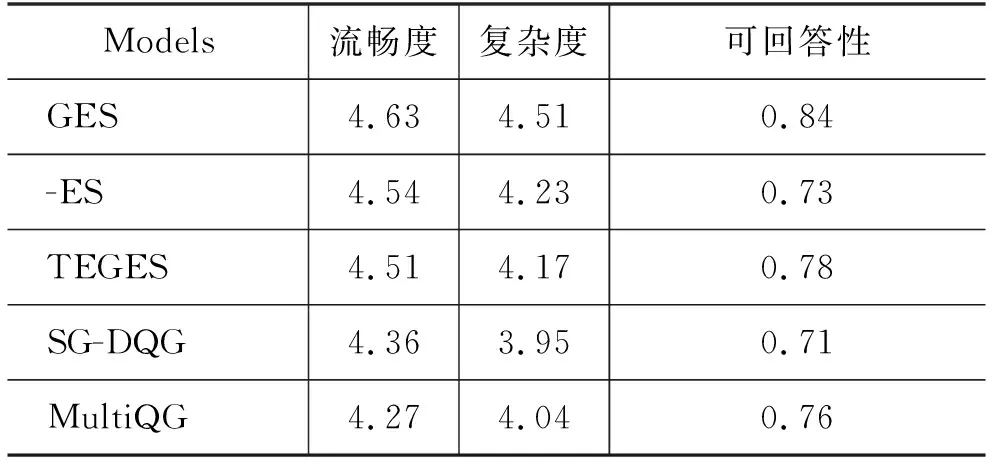
LMLE=-∑logP(qt|q (9) 2.4.1 参数共享 Seq2seq框架中的编码器是预训练语言模型,解码器是浅层Transformer,因此为了缓解训练不同步的问题,我们使用了参数共享的方法来初始化模型的词嵌入层。解码器中的词嵌入层和位置嵌入层都会与训练模型中保持一致。而解码器输入端标识佐证句位置信息的二元词嵌入矩阵也通过拷贝BERT中的segment embedding的参数来初始化。 2.4.2 直通估计量 在佐证句预测中,模型会得到一个二值信号,这是一个不连续的过程,导致训练时的梯度回传受阻。一种常见的解决方法是强化学习,通过从语言模型中采样一个动作,系统会利用奖励函数计算出一个得分,以此来指导模型训练。但是策略梯度方法会导致训练过程中的高方差问题[21],导致模型训练非常困难。参考之前训练不连续神经网络的工作[22],本文使用直通估计量去估计二值预测的梯度,对于编码器一个特定的参数θ,估计梯度计算如式(10)所示。 (10) 如图3所示,在正向传播时,模型通过离散化计算得到一个不连续的独热向量z。而在反向传导时,则通过一个连续而平稳的函数来估计z的梯度,所以梯度仍然可以正常回传。尽管这是一个有偏的估计,但直通估计量依然是一个高效的计算方法。 图3 直通估计量传播和回传过程 2.4.3 佐证句预测的监督学习 本文提出的方法以多篇文档和答案文本作为输入,预测佐证句并生成自然问句。在多跳问题生成任务中,数据集中有标注好的佐证句标签,我们通过这个监督信号来加速模型的训练。具体来说,对于输入中的每一个句子,标签fi∈{0,1}表示第i个句子是否为样例中的问答对提供了支持事实。我们通过BCE loss(Binary Cross-Entropy loss)引入这一信息,如式(11)所示。 LBCE=-∑ifiloggi+(1-fi)log(1-gi) (11) 因此,最后的损失函数可以表示如式(12)所示。 L=LMLE+λLBCE (12) 为了验证本文提出的方法在多跳问题生成任务中的表现,我们在HotpotQA数据集上开展了实验。HotpotQA是一个问答数据集,涵盖有超过113k基于维基百科的问答对。每一个数据样例由一个具体问题和两篇包含有支持事实的文档组成。数据集主要有两种类型: comparison和bridge。本文遵循原数据集的数据划分、90 447个样本组成的训练集和7 405个样本组成的测试集,同时我们从训练集随机选取了800个样本作为验证集。 在多跳问题生成中,数据处理一般有两种范式,句级和文档级。Pan等[6]预先从数据中提取出推理必须的佐证事实作为模型的输入,这是相对简化的处理,需要大量人力成本进行数据标注。本文提出的模型主要基于文档级的范式,更贴近现实需求。 本文所有的模型和实验都是基于PyTorch神经网络框架开展的。我们使用BERT自带的Wordpiece分词器来预处理文本,原文、答案以及问句的最大截断长度分别取512,10和40。其他参数的设置与BERT-based相同,12层网络,注意力头数为8,隐状态维度为768,所有的全连接层维度为2 048。模型使用AdamW优化器进行训练,初始学习率和权重衰退率分别设置为2e-5和0.001。 而在文本生成的推断中,模型使用beam search来缓解错误累积的问题,beam size为5。 同时为了验证本文方法的通用性,我们还在通用的Transformer上进行了实验,模型的参数设置与Vasvani等[17]相同,6层网络,注意力头数为8,隐状态维度为512。 参照之前的一些工作,本文采用三个自动评价指标来评测问题生成方法的效果,BLEU,METEOR和ROUGE-L。 本文采用的基线模型主要有: (1)NQG++[9]: 该模型在编码器中引入了丰富的语言学特征,包含实体信息、答案位置和词性标注等; (2)ASs2s[23]: 该模型用不同的编码器分开处理原文和答案文本,并基于key word-net结构进行特征的交互和匹配; (3)MP-GSA[24]: 该模型提出了门控注意力机制和最大值指针来提升文档级别的问题生成; (4)CGC-QG[25]: 该模型在Seq2seq模型前,引入了一个GCN来选择可能出现在问句中的关键词; (5)SG-DQG[6]: 该模型构建了一个语义图神经网络来提升多跳问题生成; (6)QG-Reward[7]: 该模型通过强化学习直接优化问题生成相对应的指标来提升模型效果; (7)MulQG[15]: 该模型在Seq2seq模型中引入了一个基于GCN的实体图神经网络。 表1展现了在HotpotQA数据集上的实验结果。表格第一部分是基于句级输入的基线模型结果,第二部分是文档级的结果,最后是本文提出方法的实验结果。句级范式通过移除冗余句子降低了多跳问题生成任务的难度,并且同时需要大量人力成本的投入。而GES只需要在模型训练阶段使用监督信号用于辅助训练,在实际的推断应用中,不需要标注的句级标签,模型就会自动预测潜在的佐证句并据此提升后续生成问句的质量。同时基于文档级输入的设定更符合现实情境的需求,也更具挑战性。 表1 HotpotQA数据集上的实验结果 从表1的结果来看,本文提出的GES方法相比于之前的基线模型在多个指标上有了非常显著的提升。简化的TEGES方法都明显优于之前的方法,在BLEU-4有1.6个点的提升。几个评价指标的显著提升证明了我们的方法可有效提取出不同文档间的关键信息点,过滤掉不相关的信息,进而提升生成问题的质量。 4.2.1 佐证句预测的影响 为了验证佐证句选择对多跳问题生成的作用,本文只保留了基础的Seq2seq框架并进行了实验,实验结果如表2所示。GES和TEGES的性能都有明显的下降,其中,BLEU-4分别从22.76下降到21.46,从17.03下降到14.36。 表2 消融实验结果 同时为了测试本文方法的理论上界,我们在解码器输入侧加入标注的佐证句位置信息而不是GES预测出的结果。模型在BLEU-4达到了23.44,一方面验证了本文方法思路的正确性,冗余信息的过滤确实可以有效提升问题生成系统的性能;另一方面,在一定程度上体现了GES良好的去噪能力,在预测结果带有一定噪声的情况下仍然能辅助提升多跳问题生成。 4.2.2 图神经网络的影响 从表2可以看出,当移除图神经网络后,模型性能有小幅下降,相对于GES,TEGES下降幅度更大。我们认为单纯从BERT学到的句级表示不足以准确预测出佐证句的位置信息,加入图神经网络,模型可以捕捉到分离信息点之间的联系,从而提升佐证句的预测精度。 4.2.3 预训练语言模型的影响 无论编码器是BERT还是基础的Transformer,GES在多个指标上都有显著的性能提升,这充分说明了本文提出方法的通用性和鲁棒性。GES的可移植性可以归因于以下几点: ①佐证句选择模块是独立于Seq2seq框架外的,即插即用; ②直通估计量和多任务学习的训练策略可以指导模型更好地学习; ③佐证句选择可以提升多跳问题生成这一客观规律的存在。 为了更好地分析本文模型在长文本下预测佐证句的效果,本文根据每个样例的句子数量划分了5个区间,在图4左图中,我们计算了GES预测佐证句的F1值。随着句子数量的增加,模型预测的精度略有下降,但是GES依然可以保持超过70%的F1值。同时图神经网络给予模型预测精度的提升幅度随着句子数量增加而提升,这也说明了图神经网络在佐证句预测中的重要性。 图4 不同句子数量对模型性能的影响左图显示的是有无图神经网络对佐证句预测精度的影响,右图是有无佐证句预测对问题生成性能的影响。 右图展现的是在不同文本长度下,GES给多跳问题生成带来的提升。显而易见,句子数量越多,BLEU-4提升的幅度越大。通过这个实验证明,佐证句选择可以筛选出重要的句子,从而提升多跳问题生成模型的表现。 为了更准确地评测问题生成模型的性能,我们从测试集随机抽取了100个样例,进行了人工评测,评测标准有以下几点: (1)流畅度:生成的问句是否在语法语义方面自然流畅,得分从1到5。 (2)复杂度:生成的问句是否需要两个或以上的信息点才可以推理回答,得分从1到5。 (3)可回答性:生成的问句是否可以从文档中得到回答,与给定的答案是否相符,分数为0或1。 实验结果表3所示。 表3 人工评测结果 基于Transformer结构的模型在流畅度上的得分明显优于其他模型。TEGES在三个评测指标上都明显优于baseline,进一步说明了佐证句预测对多跳问题生成性能的提升。此外,归功于Wordpiece分词器的作用,即使GES,TEGES没有使用拷贝机制,生成的问句也少有出现稀有词问题(OOV)。 本节进行用例分析,图5展现了一个具体例子以及本文提出方法和各种基线模型的对比。GES从两个文档中选出两个与答案“French and English”相关的佐证句,涵盖了所有用于问题生成的重要信息。通过佐证句选择来过滤噪声,本文模型可以生成需要复杂推理且可回答的合理问句。对比没有佐证句选择模块的方法可以发现,该模型会受到不相关噪声的干扰,例如,在图5中,生成的短语“in Clackamas County,Oregon”与该用例的问答无关,生成的问句与答案不符。显然,GES生成的样例也明显优于其他baseline模型,再次说明佐证句预测对多跳问题生成任务的辅助作用。 图5 生成问题样例 本文针对多跳问题生成任务提出了一种基于佐证句预测的神经网络方法。模型引入了图注意力神经网络来建模句子级别的语义关系,并根据图隐状态表示来预测出对问题生成最重要的句子,进而提升模型的性能。同时,我们使用直通估计量来端到端地训练模型。在HotpotQA数据上的实验结果表明,GES可以准确地捕获长文本中的佐证事实,有效辅助复杂自然问句的生成。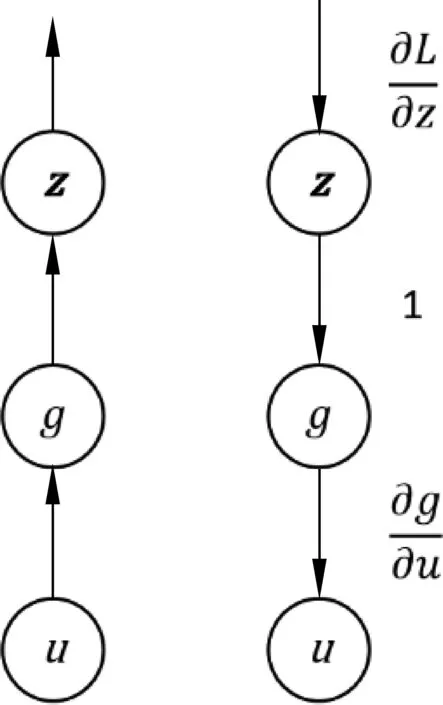
3 实验设置
3.1 数据集
3.2 实验细节
3.3 基线模型和评价指标
4 实验结果和分析
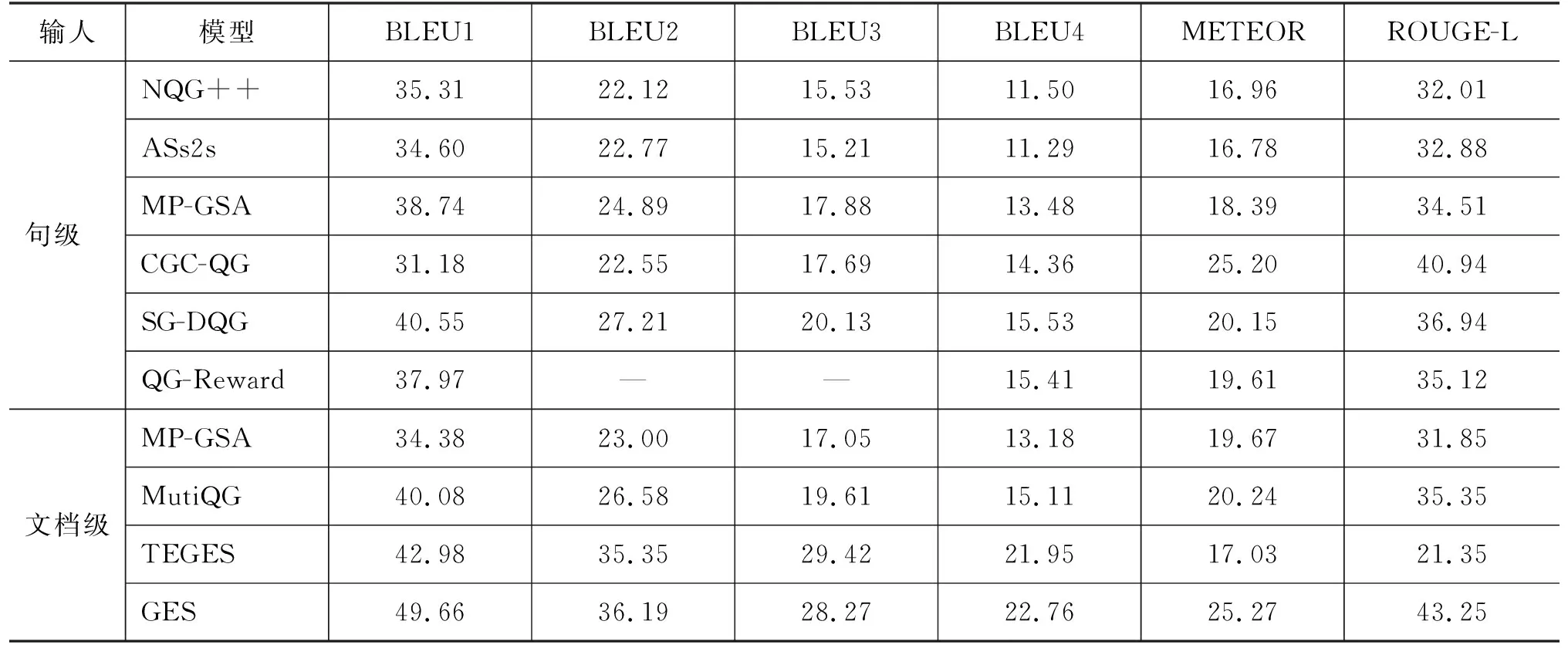
4.1 方法对比
4.2 消融实验
4.3 佐证句选择的定量实验分析
4.4 人工评测
4.5 用例分析

5 总结
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
客联(2022年3期)2022-05-31
现代电力(2022年2期)2022-05-23
锻压装备与制造技术(2021年5期)2021-11-13
中国新闻周刊(2021年26期)2021-07-27
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
电脑爱好者(2017年7期)2017-05-06
