
融合RoBERTa和特征提取的政务热线工单分类
2022-06-23 00:35陈钢
计算机与现代化 2022年6期
陈 钢
(长三角信息智能创新研究院,安徽 芜湖 241000)
0 引 言
政务热线在推动政府履职、满足群众需求、化解社会矛盾等方面发挥了重要作用[1]。近年来,各地政府在推动政务热线数字化转型中取得了一些成效,但在工单分类过程中还存在问题[2]。接线员对于每个政务热线工单需要选择相应的类型,而可选的工单类型通常多达几百个,造成工单分类环节费时费力。人工分类依赖于接线员对市民诉求内容的准确判断和对不同工单类型的深入了解,导致工单分类的准确率有待进一步提升。随着政务热线受理的城市事件种类越来越庞杂、数量越来越多,研究快速、准确的工单智能分类方法具有重要意义。
政务热线工单文本需要向量化后才能作为模型的标准输入,一般常用Word2vec、Glove等词向量模型对预处理后的工单文本进行向量化表示[3]。但这类模型无法关注到上下文的关联信息,难以处理自然语言文本中一词多义的情况,而包含大量先验知识的预训练语言模型可以有效解决这类问题[4]。通常而言,政务热线工单文本以叙事性描述为主,往往存在描述不清、要素不全等问题。RoBERTa预训练语言模型在语言表义方面具有较好的优势,可以更好实现中文词的语义嵌入,卷积神经网络(Convolution Neural Network, CNN)可以有效提取文本局部特征,双向门控循环单元(Bidirectional Gated Recurrent Unit, BiGRU)可以有效获取文本上下文依赖关系和全局结构信息,Attention机制能够凸显文本的重要特征以便更好地提取关键信息,从而提高分类性能。
综合上述模型优势,本文提出一种融合RoBERTa和事件特征提取的政务热线工单分类方法。首先,通过RoBERTa预训练语言模型获取政务热线工单文本的语义表征向量;其次,通过CNN和BiGRU分别对语义表征向量提取对应的局部特征和全局特征,并利用Self-Attention机制对BiGRU输出的隐藏状态进行处理,凸显重要性高的语义特征;最后对Self-Attention和CNN拼接向量通过全连接网络后输入分类器,完成政务热线工单分类。
1 相关工作
1.1 政务热线
文献[5]利用TD-IDF对人工记录的政务热线工单进行文本分析处理,提取原始数据中的时间、事件、地址以及用户投诉的关键信息,以此为政府服务提供合理的意见建议。文献[6]针对政务热线数据提取核心关键词,基于机器学习算法进行主题模型训练和时空模型训练及数据优化,实现了热点事件、热点区域的快速定位。文献[7]以三亚市的12345热线数据为研究对象,通过提取热线数据记录中的空间信息进行地理编码,结合热线记录的原始信息,刻画市民来电的时间、空间和类别特征。
1.2 工单分类
传统机器学习方法完成工单分类的过程是:首先人工提取特征,然后将多个特征串联起来组成一个高维度的特征向量,之后便可以使用传统的机器学习的各种分类器,如朴素贝叶斯[8]、决策树[9]、支持向量机[10]等完成工单分类。这种方法需要做大量的特征工程,特征的选取和分析方式复杂,可能会造成前端特征与后端任务的脱节,导致前端花费大量精力去构思出来的特征可能根本与指定的任务不相关[11]。另一种是利用基于深度学习的文本分类技术[12]完成自动的特征提取和分类任务。不同类型的工单在内容描述上可能存在很大的相似性,单一的卷积神经网络或循环神经网络模型均有其弊端,很难发现这种微小的差异,进而较难作出正确的判断。文献[13]采用K-means算法对所提取的特征词进行聚类处理,利用LDA模型求取语义影响力作为特征词的权重来完成95598工单分类。文献[14]通过TF-IDF算法找出关键词以及余弦相似度计算训练、测试文档间的相似度,最后使用深度玻尔兹曼机对电力投诉工单进行分类。文献[15]基于预训练BERT模型提出了95598客服工单自动分类的方法,设计了电力客服工单自动分类的流程。
1.3 RoBERTa模型
文献[16]针对中文任务对RoBERTa模型进行了改进,使用了针对中文的Whole Word Masking(WWM)训练策略,在不改变其他训练策略的基础上,提升了RoBERTa模型在中文任务上的实验效果。文献[17]引入了预训练模型RoBERTa-WWM,利用其生成含有先验知识的语义表示并依次输入双向长短时记忆和条件随机场模型,实现了面向中文电子病历的命名实体识别。文献[18]将RoBERTa-wwm-ext模型应用于中国公开法庭记录的数据集上进行非法行为与否的文本二分类任务,并通过与4种不同的模型对比证明了该模型在准确率和训练效率方面均为最优。文献[19]使用RoBERTa和互动注意网络得到上下文和部分词的注意力矩阵,对产品评论的情感性进行分析和分类,在中文数据集上准确率较高。
2 模型结构
2.1 设计思路
政务热线工单是接线员根据市民来电所记录的文本信息,其要素为时间、地点、人物、事件。为了确定政务热线工单类型,对文本中描述的事件特征提取至关重要。如果仅基于词级语义而忽视句级别语义特征来处理政务热线工单文本,只能关注到浅层文本信息,在事件主题的挖掘上会有较大的偏差。属于不同类型的工单在文本信息描述上具有很多相似性,利用单一神经网络方法很难发现这种微小的差异,进而较难作出正确的判断。例如“占道停车”属于交通道路类,而“占道修车”属于街面秩序类。
政务热线工单文本具有信息内容简短、特征稀疏的显著特点。RoBERTa模型针对BERT模型进行了多项改进,在多项自然语言处理基线任务上刷新了最优性能记录,其适应的下游任务与本文中任务对应的问题相匹配,可以用来对政务热线工单文本进行语义表征。CNN网络在卷积和池化操作时会丢失政务热线工单文本序列中词汇的位置和顺序信息,因此不能很好地捕捉工单文本的全局信息。循环神经网络无法解决长时依赖问题,且工单文本的重要特征也无法凸显。虽然通过GRU网络可以有效获取序列化句子的层级特征,然而单从一个方向提取特征不能完整地表示整个句子的上下文特征。为此,本文采用BiGRU网络,分别从2个方向对句子特征进行提取和组合。在BiGRU网络中引入Self-Attention机制,使得BiGRU网络在计算语义信息时根据其重要程度赋予不同的权重。如此,分类模型在保留政务热线工单文本特征最有效信息的基础上,能够最大程度地解决信息冗余问题,进而优化工单文本特征向量。
基于上述分析,本文提出的政务热线工单分类模型主要由语言编码层、特征提取层和分类层构成,如图1所示。该分类模型既可以凸显出工单文本重要的局部特征,又可以更加充分地提取工单文本上下文的句法结构和语义信息。

图1 模型结构
2.2 语义编码层
语义编码层对预处理后的工单文本进行语义信息提取,获得具有上下文特征信息的语义表征向量。为了使RoBERTa模型适用于中文环境下的工单分类,使用哈工大讯飞联合实验室发布的RoBERTa-wwm-ext作为文本特征提取模型并将经过预处理后的工单文本序列X={x1,x2,…,xn}输入其中。通过RoBERTa模型学习到每个词对应的表征向量X′={x′1,x′2,…,x′n},表征向量X′提取了政务热线工单文本的上下文信息和词本身的位置信息。文献[20]指出BERT不同层的输出对应学习到的内容有所不同,为了获取最佳编码效果,本文将RoBERTa模型12层Transformer编码器模块中若干层的编码输出进行加权来得到上下文嵌入矩阵,将最终编码结果输入到特征提取层中。
2.3 特征提取层
文献[21]将CNN-BiGRU模型运用于事件触发词提取任务中。然而,句子中每个词语的语义信息都有不同的贡献,BiGRU网络难以从句子序列中捕获重要语义信息。为此,本文提出一种基于CNN-BiGRU-Self-Attention的特征提取方法。首先通过CNN提取局部特征,其次利用BiGRU来获取文本上下文语义信息得到全局特征,最后对全局特征运用Self-Attetion后和局部特征进行拼接作为分类层的输入。特征提取层利用CNN与BiGRU-Self-Attention的融合网络从文本时序和空间2个层次上提取政务热线工单文本特征,优化工单文本的特征表示,提升工单分类性能。
2.3.1 CNN
本文主要利用CNN的特性对工单文本中的每个词提取局部特征形成语义特征向量,相当于采用卷积核在输入矩阵上滑动进行乘积求和的过程。将RoBERTa输出的工单文本编码向量S∈n×d(d表示编码向量中的字向量维度,本文中字向量编码维度为768维,n表示句子长度)作为CNN的输入序列并提取对应的局部特征,以特征向量的形式输出整句文本的语义特征,如图2所示。
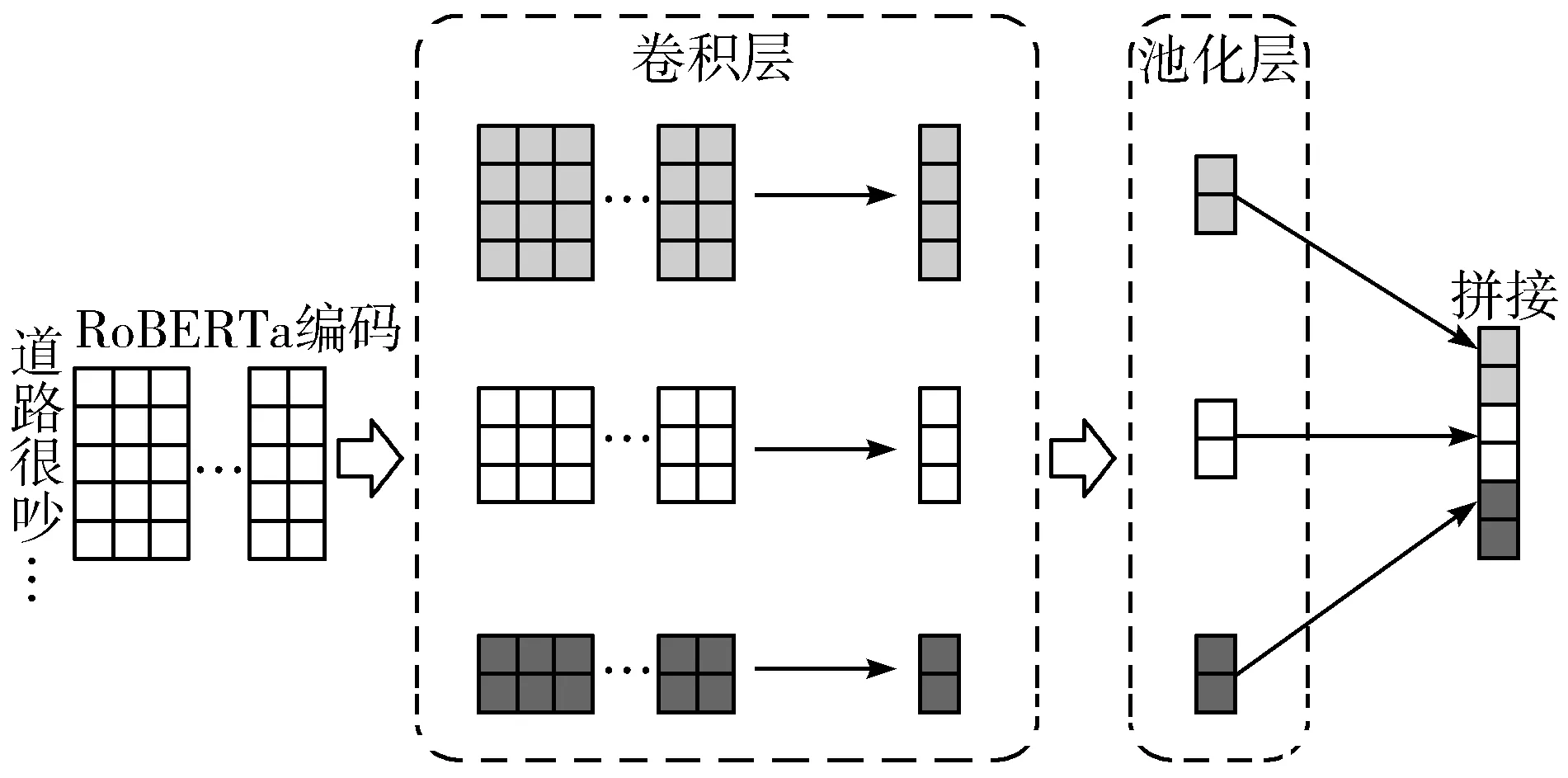
图2 CNN局部特征提取
设定卷积核u∈kernel×kernel,kernel表示卷积核的大小,本文模型中取多个尺寸的卷积核进行卷积,即kernel∈{2,3,4},相当于使用2×2、3×3与4×4的卷积核对句子进行卷积。对于输入S,通过重复应用卷积核u进行卷积操作得到特征向量O=(o0,o1,…,on-kernel),向量O中元素oi的计算公式为:
oi=ReLU(u·Si:i+kernel-1)
(1)
其中i=0,1,2,…,n-kernel,(·)表示矩阵的点乘操作,Si:j表示矩阵S从i行到j行的子矩阵,即第i个字到第j个字的字向量矩阵,ReLU是激活函数。
完成卷积操作后,得到的每个特征向量O都被送到池化层以生成潜在的局部特征。本文采用最大池化策略对卷积层输出结果进行池化,其作用是捕获卷积之后的最重要特征v,把一个变长句子处理为固定长度:
(2)
将卷积核扫描整个句子,可以得到包含局部特征信息的句子表征向量:
st=CNN(S,u)
(3)
由于本文中使用了2×2、3×3与4×4这3种不同宽度的卷积核进行卷积,因而可以获取工单文本在不同尺度上的文本局部特征。拼接各个卷积核的结果,得到整个句子的特征向量:
M=[st2,st3,st4]
(4)
其中M∈n×d,M中每行向量表示通过CNN所提到的局部特征。
2.3.2 BiGRU
在政务热线工单特征提取中,当前时间步长的隐藏状态与前一时刻和下一时刻相关联。采用单向GRU网络对文本序列建模时,状态总是由前向后传递,因此仅能获取文本前文信息,难以获取整个文本的上下文信息。BiGRU由前向GRU单元和后向GRU单元组成,利用2个并行通道,既能获得正向的累积依赖信息,又能获得反向的未来的累积依赖信息,提取的特征信息更加丰富。因此,本文使用BiGRU从工单文本表征向量中提取上下文信息,如图3所示。

图3 BiGRU网络结构
GRU可以通过门控机制选择保存上下文信息来解决RNN梯度消失或爆炸的问题。GRU单元由更新门和重置门组成,如图4所示。

图4 GRU单元结构
对于时间t,GRU隐藏状态计算公式如下:
rt=σ(wr·[ht-1,xt]+br)
(5)
zt=σ(wz·[ht-1,xt]+bz)
(6)
h′t=tanh(wh·[rt×ht-1,xt]+bh)
(7)
ht=(1-zt)×ht-1+zt×h′t
(8)
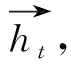
(9)
(10)
(11)
2.3.3 Self-Attention
Self-Attention机制是Attention机制的一种变体,利用Attention机制计算输入特征中不同位置之间的权重,降低了对外部信息的依赖[22]。例如政务热线工单文本“来电人反映保利时光印象小区旁边高速正在扩建,声音太大,扰民。”属于噪音污染,文本中“高速正在扩建”“声音太大”和“扰民”对于工单类型的识别具有很大帮助,在识别过程中可以加以高权重,而“保利时光印象小区”“旁边”等字词对工单类型的识别帮助较小,而且增加了识别难度,减弱了识别效果,因此可以给这些冗余实体加以较小的权重。同时,借由Attention机制对关键信息的跳跃捕捉,提高关键信息的传递效率,使得Self-Attention机制更擅长捕捉数据或特征的内部相关性。
因此,在BiGRU网络捕捉到上下文特征后,本文使用Self-Attention机制来提取工单文本句子中的重要信息,可以更好地为重要信息分配权重,将全局特征整合。融合Self-Attention机制后的BiGRU网络能够通过计算中间状态与最终状态之间的相关关系得到关于注意力的概率分布,减少了无效信息的影响,从而提高工单分类性能。
考虑Self-Attention机制无法从多个角度、多层次捕捉重要特征,需要使用多头注意力机制。多头注意力机制将输入映射到多个向量空间并计算向量空间中字符的上下文表示,重复该过程几次,最后将结果拼接在一起。多头注意力机制可以有效扩展模型对不同位置的感知能力,其计算公式如下:
m(h)=concat(score1(h),…,scoren(h))WO
(12)
其中h为BiGRU网络的输出,scorei为第i个Self-Attention机制的输出,n为重复次数,scorei计算方式如下:
scorei(h)=attention(hWiQ,hWiK,hWiV)
(13)
其中WiQ、WiK、WiV和WO为参数矩阵,用于将输入h映射到不同的向量空间。参数矩阵大小分别为WiQ∈Rd×dQ,WiK∈Rd×dQ,WiV∈Rd×dV,WO∈RndV×d,其中d是BiGRU网络的输出向量维度,dQ和dV是向量空间维度。Attention的计算公式为:
(14)
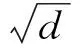
2.4 分类层
将Vconcat输入分类器中完成工单分类:
p=softmax(WVconcat+b)
(15)
其中W、b是可学习参数,p是各类别的分类预测概率。使用正确类别的负对数似然作为训练损失函数:
(16)
其中j是工单E的分类类别。
2.5 模型训练流程
本文提出的政务热线工单分类模型训练流程如图5所示。首先通过对工单文本进行分词处理、去除停用词以及合并同义词后,构建政务热线工单数据集。然后将数据集按一定比例划分为训练集、验证集和测试集,其中训练集用于模型训练,验证集通过不断迭代更新模型性能,测试集用来评估模型性能。最后,使用模型进行政务热线工单分类。

图5 分类模型训练流程图
3 实验结果与分析
3.1 实验环境与参数设置
本文使用基于CUDA 11.0的深度学习框架pytorch 1.7.1构建网络模型,实验在内存DDR4 64 GB,2.4 GHz Intel(R) Xeon(R) Silver 4210R CPU, NVIDIA GeForce GTX 3090的Ubuntu 18.04 LTS系统上进行。
在整体网络训练过程中,本文模型的超参数如表1所示。
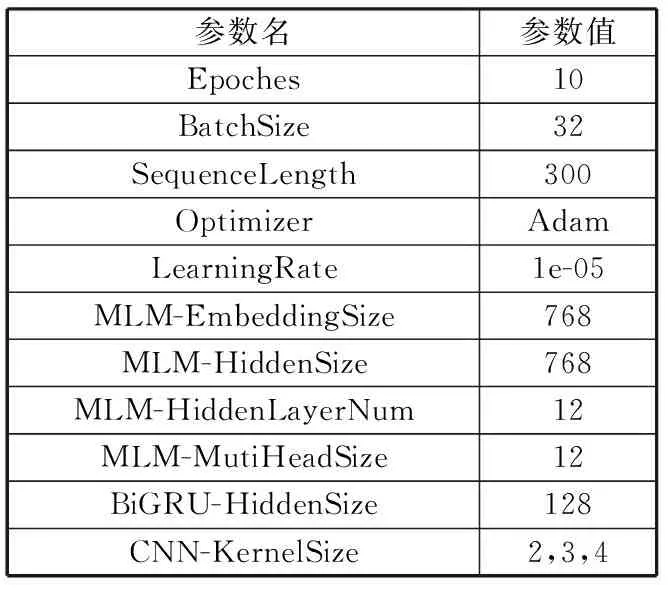
表1 超参数设置
3.2 数据集
本文从2018年1月1日—2021年6月30日期间安徽省芜湖市历史政务热线工单中挑选了60000条工单构建了实验数据集,数据集描述如表2所示。数据集包含工单文本数据和对应的工单类型,其中工单文本数据是芜湖市市民诉求文本信息,工单类型是由业务人员根据工单文本内容标注所得。同时,本文对60000条工单文本进行了统计分析,工单文本长度的均值为119.92个字,且95%的工单文本长度在287个字以内。

表2 数据集描述
3.3 RoBERTa组合输出实验
为了验证选取RoBERTa若干层加权编码的效果,本文对比了使用最后3层加权和使用原RoBERTa进行工单分类的性能,实验结果如表3所示。不难看出,取RoBERTa最后3层输出的加权求和结果作为工单文本语义编码的效果稍微优于使用原RoBERTa模型。对此实验结果而言,一个可行的解释是:RoBERTa模型不同层倾向于学习不同类型的语言学信息,表层信息特征主要集中在底层网络,句法信息特征主要集中在中间层网络,语义信息特征主要集中在高层网络。故此,本文选取RoBERTa模型最后3层的输出向量加权作为语义编码层的输出。
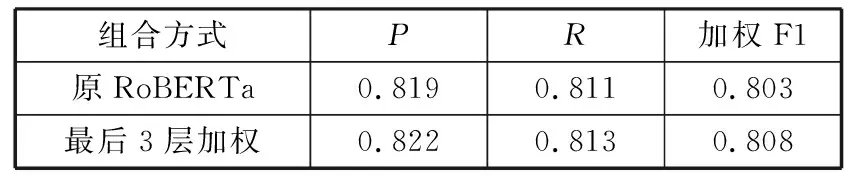
表3 组合输出实验结果
3.4 基线对比实验
本文采用精确率(P)、召回率(R)和加权F1值(根据各类型工单所占比例进行加权)作为政务热线工单分类性能的评价指标。为验证本文政务热线工单分类方法(为方便起见,将其命名为WOC-FE)的性能,与多种基线方法进行对比。文献[8]、文献[9]和文献[10]在对文本进行特征提取的基础上分别采用朴素贝叶斯、决策树和支持向量机的机器学习方法完成工单分类。文献[23]使用经过词嵌入之后的词向量作为输入并经过RNN网络和池化层完成文本分类。文献[24]使用基于单词层面注意力机制的BiGRU模型和基于句子层面注意力机制的BiGRU模型提取文本多层面的特征进行文本分类。实验对比结果如表4所示。

表4 基线对比结果
从表4中可以看出,本文提出的工单分类方法相较于其他基线方法在各项指标上均取得了最优效果,P、R和加权F1分别达到了82.24%、81.30%、80.77%。不难看出,基于传统机器学习的工单分类(文献[8]、文献[9]和文献[10])性能比基于深度学习(文献[23]和文献[24])和基于预训练语言模型(文献[15])的工单分类性能要差。这是因为机器学习方法仅简单地对文本中的词向量进行加权平均,没有提取文本更深层次的语义信息,而基于深度学习和预训练语言模型的分类方法可以获取更深层次的语义信息从而得到更好的分类效果。
在基于深度学习的工单分类方法中,文献[24]使用BiGRU作为文本提取模型来有效提取文本上下文信息,同时引入Attention机制来关注文本的不同层次特征,因此取得了比文献[23]更好的效果,平均提升了2个百分点。相较于基于深度学习的分类方法,预训练语言BERT模型能够更加有效地提取文本的上下文语义信息,因此文献[15]相比文献[24]在分类性能上平均提升了4个百分点。本文使用RoBERTa作为文本特征提取模型,并在此基础上引入了基于CNN的局部特征提取和基于BiGRU-Self-Attention的全局特征提取,兼顾到了文本局部信息和上下文语义信息,充分发挥了各网络的优势,相比其他方法取得了更好的分类性能。
3.5 消融实验
为了说明特征提取层的有效性,本文定量比较了是否使用特征提取层的实验结果(将未使用特征提取层的方法命名为WOC),对比结果如表5所示。可以看出,WOC-FE方法的各项评价指标均优于WOC方法,这表明加入了特征提取层后能够取得更好的分类性能。BiGRU通过前后2个方向获取序列向量中的特征信息,可以更好地捕获上下文信息。此外,将基于多窗口卷积的卷积神经网络融入BiGRU-Self-Attention模型,可以捕获字符的向量序列表达,对于获取多层次语义信息具有较大帮助。工单文本中的各个字词对上下文语义的影响因子不同,加入Self-Attention机制的方法可以给每个字词分配不同的权重以便凸显关键信息,分类效果可以获得明显提升。
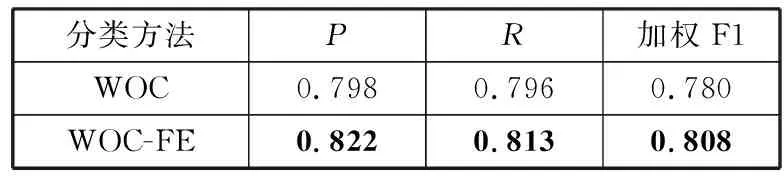
表5 消融实验结果
图6展示了特征提取层消融实验的验证集准确率对比曲线。可以看出,随着迭代次数的增加,图中曲线①逐渐超过曲线②,并稳定在曲线②的上方,说明了特征提取层可以提升政务热线工单分类的准确率。

图6 消融实验准确率对比
3.6 混淆矩阵
为了更加直观有效地展示工单分类效果,图7给出了实验结果的混淆矩阵热力图,图中方格颜色深浅表示预测准确率。可以看到,对角线上的方格颜色较深,这表明本文所提出分类方法在所选的20种工单类别上的分类性能均较好。

图7 混淆矩阵热力图
4 结束语
针对基于机器学习和深度学习技术对政务热线工单分类存在的问题,本文提出了一种基于组合神经网络的工单分类方法。该方法首先通过基于RoBERTa模型的语义编码层获取政务热线工单文本中的语义表征向量,然后通过由CNN-BiGRU-Self-Attention定义的特征提取层获取工单文本的局部特征和全局特征,并对全局特征进行处理以凸显重要性高的语义特征,最后将融合后的特征向量输入分类器来完成工单分类。基线对比实验说明了本文工单分类方法的有效性。政务热线工单具有重要的数据价值,本文下一步工作是融合政府部门业务数据来完成工单的自动分拨。
猜你喜欢
科技与创新(2022年22期)2022-11-18
今日农业(2022年15期)2022-09-20
今日农业(2022年14期)2022-09-15
今日农业(2022年13期)2022-09-15
电子测试(2022年7期)2022-04-22
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
