
基于深度学习的驾驶员分心行为识别
2022-06-23 00:35何丽雯张锐驰
计算机与现代化 2022年6期
何丽雯,张锐驰
(长安大学信息工程学院,陕西 西安 710061)
0 引 言
随着汽车保有量的逐年递增,道路交通问题层出不穷。在人员、机动车、道路环境三者构成的复杂道路交通系统中,驾驶员的决策和行为是影响交通安全的主要因素。根据美国高速公路安全管理局(National Highway Traffic Safety Administration, NHTSA)发布的调查结果显示[1],因驾驶员分心而导致的交通事故人员伤亡占死亡人数的64.4%。分心驾驶直接造成短时用于驾驶主任务的注意力资源下降,驾驶员的情景感知能力受到干扰,从而威胁驾驶安全。因此,在智能交通系统中,对于智能汽车,如果能够对驾驶员的视觉分心、听觉分心、生理分心及认知分心等各类不当驾驶行为进行实时准确的识别,以防止驾驶员因分心而无法及时处理突发事件,对有效提升道路交通安全具有重要意义。
传统的用于驾驶员行为识别的机器学习方法通常需要捕获驾驶员的状态信息,例如头部姿势、眼睛注视方向、手部运动,甚至生理信号(如脑电图、眼电图、肌电图等)。上述方法需要预先提取特定特征,对系统硬件有特定的要求,在实时场景中,泛化能力不足、计算效率偏低、财务成本较高,难以应用到实际的智能交通系统中。
随着深度学习理论与技术的日渐成熟,利用卷积神经网络进行驾驶员行为识别的优势逐渐凸显。其与传统机器学习方法的主要区别在特征提取阶段,深度学习方法通过自适应地对输入数据的低维特征进行多层次过滤、提取与组合,得到用于表示输入数据的高维抽象特征[2]。而卷积神经网络作为实现深度学习的一项重要技术,成功地应用到图像处理领域。因此,将深度卷积神经网络这种端到端地从输入数据中直接获得高维特征的方式应用到驾驶员分心行为识别任务当中,更易于实现。
在实时的驾驶员行为监控与识别系统中,使用车载设备采集到的原始图像中,驾驶员的身体位置区域占原始图像的比例通常不同,意味着背景中的无关信息(即噪声)也输入到模型中,干扰特征提取过程,导致分类效果和识别精度受限。立足于现有方法的不足,本文提出一种非侵入式的基于深度学习的驾驶员分心行为识别算法,先利用目标检测算法对原始图像进行处理,识别出驾驶员的位置,再应用迁移学习对预训练的卷积神经网络模型进行微调,训练模型以处理十分类任务,旨在提升驾驶行为识别的精度。
1 相关工作
驾驶员注意力和分心检测长期以来被认为是众多研究机构、汽车厂商的重点工作。早期的研究集中在驾驶员状态信息的捕获上,如头部姿势角度、眼睛注视方向、手和身体关节位置以及其他生理信号。具体而言,Kutila等[3]根据眼睛注视角度、头部角度、车道位置和面部表情等行为信息,提出了一种基于支持向量机(Support Vector Machine, SVM)的模型来检测驾驶员的认知分心,准确率约为65%~80%。Ohn-Bar等[4]将驾驶员的头部姿势、眼睛注视方向和手部运动结合起来,提出了一种多视图、多模态框架来描述驾驶员的行为。Rezaei等[5]提出了驾驶员头部姿态估计方法,同时分析驾驶员头部姿态和道路危险信息,实现了一个模糊融合系统。与行为信息相比,生理信息对认知的变化更为敏感。随着功能磁共振成像、功能近红外光谱、脑电图和脑磁图等脑成像技术的进步,大型神经群的活动也是探索注意力变化的一个重要来源[6-8]。Zhang等[9]从记录的脑电图和眼电图信号中检测和识别驾驶注意力分散状态。Wang等[10]使用脑电图信号测量的大脑信号来检测驾驶员查看地图这一分心行为,对改进未来智能导航系统的设计具有重要意义。
用以上方法进行驾驶员分心行为识别,提取驾驶员的某些特征时需要特定硬件设备(尤其是在获取生理信号时需要侵入式检测设备)。这类方法在实时的任务场景中步骤复杂,耗时且成本高,鲁棒性不强,为传统算法的通病。
近年来,由于并行计算硬件、更深层次卷积神经网络模型和大规模注释数据集的发展,计算机视觉领域取得了重大进展。越来越多的学者将基于卷积神经网络的自学习特征算法广泛应用到图像识别与分类、行为分析等领域,特别是对驾驶员的分心行为识别任务当中。Yan等[11]提出了一种基于视觉的驾驶员行为识别的系统,其主要思想是采用深度卷积神经网络,从原始图像中自动学习特征,以预测安全/不安全的驾驶姿势(包括正常驾驶、打电话、进食和吸烟)。与以前的方法相比,卷积神经网络可以直接从原始图像中自动学习特征表示,在东南大学驾驶数据集(the Southeast University Driving-Posture Dataset, SEU Dataset)上的总体准确率为99.78%,表明该方法的性能优于手工编码特征。Le等[12]提出了多尺度快速反应神经网络(MS-FRCNN)方法来检测手、手机和方向盘,提取几何信息以及计算在方向盘上的手的数量,以判定驾驶员是否存在分心行为,该方法在方向盘和手机使用检测方面相比Fast R-CNN有更好的性能。
上述研究虽取得一定研究成果,但分心驾驶检测类型较多,它们只实现了对个别类型分心驾驶行为的识别,对其它分心驾驶类型没有较好的研究成果。Tran等[13]提出了一种检测多类别分心驾驶行为的深度学习方法,并设计了一种基于双摄像头的同步图像识别系统,其将从驾驶员身体和面部采集的图像输入卷积神经网络,检测分心驾驶行为。该方法与前述方法的区别在于分别对驾驶员的身体运动和面部进行监控,将图像同时送入2个卷积神经网络,以确保分类性能,实现96.7%的识别准确率,且能够识别10种类型的分心行为。
而随着对卷积神经网络的不断深入研究,也有部分专家学者提出构建级联卷积神经网络检测框架[14],并将其应用于驾驶员行为检测。Xiong等[15]提出了一种基于深度学习的驾驶员手机使用检测算法,首先利用PCN(Progressive Calibration Networks)算法进行人脸检测和跟踪,确定打电话行为检测区域,其次采用基于卷积神经网络的驾驶员手机使用检测方法对候选区域内的手机进行检测。陈军等[16]提出了一种级联卷积神经网络检测框架,第一级卷积网络是一个轻量级的图像分类网络,负责对原始数据快速筛选;第二级卷积网络迁移学习VGG模型权重,对第一级输出的可疑分心行为图像进一步精确检测,此级联网络比单模型检测方法识别驾驶分心行为效果更好,且具有较强的鲁棒性和模型泛化能力。然而,在运用摄像头或Kinect传感器等设备采集图像时,通常背景中存在大量与驾驶员行为无关的信息,也一定程度上会导致分心行为识别精度受限。
综上,现有相关工作存在以下问题:1)分心行为种类繁多,应识别更多行为类别以避免动作误分类;2)经典单模型在同一数据集上的识别精度一定概率劣于级联网络模型;3)车载设备采集图像存在冗余信息,造成识别精度受限。为此,提出一种去除噪声干扰且能同时精确识别多种驾驶分心行为的级联模型,来有效提高驾驶行为的检测精度,是潜在的发展趋势。
2 研究思路
基于深度学习的驾驶员分心行为识别方法的整体过程如图1所示。模型以彩色图像作为输入,直接输出驾驶员行为信息,是一种端到端的、非侵入式的驾驶员行为检测算法。设计搭建一个级联卷积神经网络结构,由2个部分组成:1)利用目标检测算法预测驾驶员位置信息,确定候选区域;2)采用卷积神经网络模型对候选区域内的驾驶员分心行为进行精确识别。利用级联卷积神经网络模型,可以用自动的特征学习过程代替手工的特征提取过程。

图1 算法总体流程
2.1 确定候选区域
本文设计的驾驶员分心行为识别方法,期望在第一级卷积神经网络中,选择一个主要包含驾驶员身体区域的感兴趣区域(Interest of Region, ROI)作为候选区域,以达到提高整个算法分类精度的目的。具体地,对原始输入图像进行处理,根据不同驾驶行为特征确定目标检测区域,从背景中提取出局部区域,去除冗余信息,再将该级的输出作为下一级网络的输入。这不仅减少后续行为识别网络的计算负担,还为整个网络模型提供了高质量的行为特征。
2.2 精确识别分心行为
将上一级网络确定的候选区域送入本级卷积网络,对驾驶员分心行为进行精确识别。本级网络中,采用迁移学习策略,对预先训练好的经典卷积神经网络模型进行微调,将从大规模数据集中学习到的领域知识迁移到小规模的驾驶员行为识别任务中。本文期望实现准确识别的驾驶行为见表1。
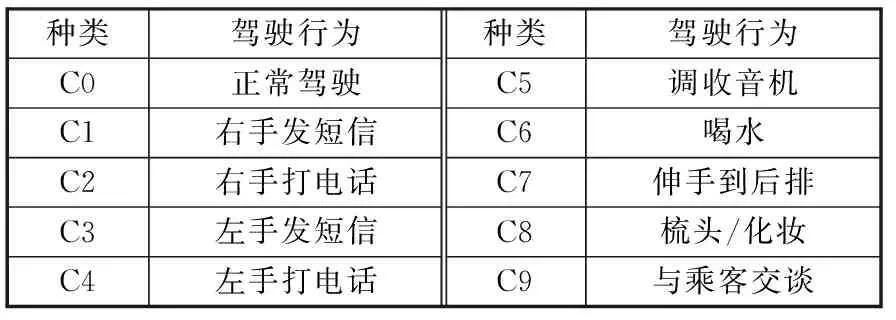
表1 驾驶员分心行为类别
3 模型构建
3.1 第一级网络构建
目前基于深度学习的目标检测算法主要分为2类。1)两阶段检测法:首先生成候选框区域,然后对候选框进行分类和调整,代表算法有R-CNN、Fast R-CNN、Faster R-CNN[17-19]等,这类算法精度较高,但存在检测速度慢、算法实时性低等问题;2)单阶段检测法,无需生成候选框区域,提高了目标检测的速度,代表算法是YOLO[20]、SSD[21]。图2对比了上述目标检测框架的精度(mAP)和速度(FPS)。

图2 目标检测算法性能对比
由图2可见,SSD算法有较高的准确度和性能,兼顾了速度和精度。因此,本文拟采用目标检测算法SSD作为第一级网络模型,将驾驶员原始图像作为SSD网络输入,确定候选区域。
SSD是一种直接预测对象类别和边界框的目标检测算法[22],在原始图像上直接通过分割好的窗口进行预测,故其速度快,可以达到实时检测的要求。SSD的主要思想是在图像的不同位置进行密集而均匀的采样。在采样时,综合利用不同卷积层的输出特征图,采用多框预测的方式为输出特征图的每个预测位置生成多个边界框,并设置不同的长宽比和尺度;然后通过卷积神经网络提取特征,直接进行分类和回归[23]。图3展示出了SSD网络的整体框架。

图3 SSD网络模型结构
SSD网络利用VGG16模型作为前馈卷积网络提取图像特征并对其进行了修改,即将VGG16的密集全连接层FC6和FC7层转化为3×3卷积层Conv6和1×1卷积层Conv7,同时将池化层pool5由原来的2×2-S2转换为3×3-S1,且去除所有的Dropout层和FC8层,并在VGG16提取特征以后增加了若干层卷积层,形成尺寸逐渐减小的“金字塔”型卷积神经网络结构[22]。在抽取不同尺度的特征图做检测时,低层特征图感受野小,可以检测小物体,而高层感受野较大,可以检测较大物体。故抽取Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2层的特征图,在不同尺寸的特征图层上构造不同尺度大小的边界框,分别进行检测和分类,生成固定大小的候选框集合。对于每个候选框,计算框中对象类别的置信度并确定其类别,最后经过非极大值抑制(Non-Maximum Suppression, NMS)方法来滤除一部分重叠度较大的候选框,生成最终的与驾驶员位置信息最匹配的检测框,作为第二级网络的输入。
3.2 第二级网络构建
设计第二级网络,旨在对前一级网络所确定的候选区域内的疑似分心行为图像进行精确识别,从而有效判决正常驾驶与9种常见驾驶分心行为。
在计算机视觉领域,使用预训练模型的常用方法是以训练好的通用模型为基础,将其视为一个固定的特征提取器而不调整模型参数,或者使用小规模数据集对预训练的模型参数进行微调。为此,本文应用迁移学习策略,对预训练模型的分类器和部分卷积层进行重新训练,使用驾驶员行为数据集对模型的部分卷积层参数在原基础上进行微调,可在较短时间内训练出精度较高的模型。
卷积神经网络模型按层次结构可划分为卷积基(包括池化层和卷积层)与密集全连接层。抽取不同深度的特征,从多个层次的表示中学习,有助于感知图片的整体信息。随着网络层次的增加,特征越来越抽象。浅层的卷积特征以方向线段为主,学习低阶的图像特征;深层则以较大的拐角及形状为主,学习高阶的图像特征。不同物体的浅层特征往往具有较大的相似性,从而训练中卷积基学到的表示更加通用。而密集全连接层舍弃了位置信息,得到某个类别出现在整张图像中的概率信息。因此,提取空间结构特征时,只需提取卷积基,保留卷积层的基本结构和性质,使其在特征提取和表示上保持优势;同时,释放密集全连接层,将预训练模型卷积基的通用权重参数应用到新的分类问题,从而可将大规模注释数据集ImageNet中学到的知识转移到驾驶员行为域。
本文选用VGG19、ResNet50、MobileNetV2这3种经典卷积神经网络模型作为驾驶员行为识别的预训练模型。上述3种模型均在ImageNet[24]上训练得到,常用作迁移学习的预训练模型。
3.2.1 VGG19
VGG19模型通过反复堆叠3×3的小型卷积核和2×2的最大池化层,构建了19层深的卷积神经网络,由16个卷积层和3个密集全连接层叠加而成。但VGG19模型有1000个类别输出,且大规模注释数据集并不总是可以用于特定的任务,因此必须对VGG19最后几层进行修改,以使模型能够满足本文待解决的十分类任务。具体地,在保留卷积层的基本结构和性质的同时,需要在提取的空间特征上添加自定义密集全连接层构成新的分类器,将生成1000个类别概率的原始VGG19模型的最后几层密集全连接层和输出层替换为10个类别概率的新的密集全连接层和Softmax层;再对模型进行微调,输出自己的分类预测。现提取VGG19整个卷积基,在该卷积基上训练自己的密集全连接分类器。在输入数据上端到端地运行模型,确保每个输入都可以经过卷积基。然后在此模型基础上进一步改进,重新训练其部分卷积层,让提取VGG特征上添加自定义密集全连接层后训练的模型中的抽象表示和驾驶行为识别相关。经过迁移学习改进后的VGG19模型如表2所示。

表2 迁移学习权重微调的VGG19配置
尽管VGG19有着优异的表现,但因其卷积层的通道数过大,需要耗费更多计算资源,导致更多的内存占用,故其并不高效。
3.2.2 ResNet50
在计算机视觉里,网络模型的深度和复杂度对于特征表示和泛化性能有显著影响。随着网络深度增加,提取到不同层的特征越丰富,则网络模型预测的准确度应该同步增加。然而,简单地叠加卷积层来增加模型的深度并不能提供更好的训练和泛化性能,成为训练深层次网络的障碍。因此,He等[25]引入了一种新的深度卷积神经网络模型,即残差网络(Residual Networks, ResNet),旨在构建更深层次的卷积神经网络。通过引入残差学习方案,ResNet在ILSVRC 2015中获得第一名,并在ImageNet检测、ImageNet定位、COCO检测2015和COCO分割中胜出。
图4(a)为残差学习块,其基础映射函数可以表示为H(x),x表示第一层的输入。假设残差网络存在一个显式的残差映射函数,使得F(x)=H(x)-x,并且原始映射可以表示为F(x)+x。若F(x)=0,就构成了一个恒等映射H(x)=x,表明可以让网络随深度增加而不退化。残差学习块的核心思想是:尽管H(x)和F(x)+x映射都能渐进地逼近所需函数,但学习F(x)+x的映射更加容易。ResNet在VGG19基础上,利用“短路连接”机制形成残差网络。图4(b)表示深度残差网络的完整结构,其中对每几个堆叠层执行残差学习。通过引入恒等映射和从浅层模型复制其他层,深度残差网络可以有效地解决模型越深时的模型退化问题[25]。于2015年提出的模型结构主要包括ResNet50和ResNet101等,考虑到计算成本,选用ResNet50作为预训练模型。经过迁移学习改进后的ResNet50模型如表3所示。

图4 残差学习块和深度残差网络

表3 迁移学习权重微调的ResNet50配置
3.2.3 MobileNetV2
多数卷积神经网络模型都需要很大的内存和计算量,特别是在训练过程中。若想部署在移动端,因存储空间和功耗的限制,需折中考虑准确度和计算量。鉴于此,近年来有研究人员提出了一种为移动和嵌入式设备设计的轻量化深度神经网络模型MobileNet[26]。
MobileNet由若干个深度可分离卷积模块(即Xception变体结构)组成。此模块本质上是对每个通道的输入用深度卷积(DepthWise Convolution)和逐点卷积(PointWise Convolution)替换标准卷积。该分解操作可以大幅度减少参数量和计算量、降低复杂度,尺度和速度上更易满足智能汽车车载嵌入式设备的要求。
MobileNetV2是MobileNetV1的改进版本,在保留MobileNetV1的深度可分离卷积模块的基础上,又结合了ResNet的快捷连接(shortcut connection)方式,解决了MobileNetV1在训练过程中易出现的梯度弥散问题,效果有所提升[27]。故本文拟选取MobileNetV2作为预训练模型并对其作出改进,经迁移学习后的模型结构见表4。

表4 迁移学习权重微调的MobileNetV2配置
4 实验与分析
4.1 数据预处理
随着信息交流趋向全球化,数据可以通过各种渠道采集,出现了很多完备且效果优秀的数据集。 本文实验基于美国State Farm公司的驾驶员驾驶行为开源数据集,训练和测试深度卷积网络模型。该数据集采集了26位不同肤色、种族、年龄的受试者的不同驾驶行为图片。每张图片都包含驾驶员行为类别标签,原始图像尺寸大小均为640×480像素,随机读取部分驾驶员图像见图5。

图5 State Farm数据集中驾驶员图像示例
State Farm数据集中,驾驶员驾驶行为被分为本研究预测的10类,用C0~C9依次表示。数据集由102150张标签图像组成,其中训练数据22424张,测试数据79726张。将原始训练集中的图像分为2类,80%的数据用于训练,其余20%作为验证集。
预处理阶段,为加快卷积神经网络训练过程,对原始RGB图像进行处理,统一转换为224×224×3的大小,以满足VGG19、ResNet50和MobileNetV2的输入要求。在训练时,为防止过拟合,增强模型泛化能力,对原始数据集做了以下处理来生成可信图像扩充数据集:1)采用数据增强技术,即对现有的训练样本作随机偏移与水平随机翻转等变换;2)使用ImageDataGenerator生成更多图像;3)采用分批、随机读取的形式以免数据按固定顺序训练。
4.2 模型训练
4.2.1 实验环境
本文实验开发环境见表5。

表5 实验环境
4.2.2 评估指标
在评价卷积神经网络的性能时,一般采用准确率作为评估指标,它反映了算法对全部样本的判定能力。准确率为识别正确的样本占总样本的比例,其公式为:
其中,FP为假正类(预测为正类,实际为负类),TP为真正类(正类判定为正类),FN为假负类(预测为负类,实际为正类),TN为真负类(负类判定为负类)。
4.2.3 模型训练
为了降低卷积层的更新速度,选择了一个小的初始学习率0.0001。训练过程中,对以下重要指标进行监控:1)训练损失和验证损失;2)训练准确率和验证准确率。为了得到准确且泛化性强的模型,采用早停(Early Stopping)法避免发生过拟合,具体地,设定当验证损失连续10轮(Epoch)都不再减少(即减少的阈值小于0.0003)时,提前终止训练。RMS-Prop优化器和分类交叉熵(Categorical Cross Entropy)也用于损失函数。驾驶员行为识别方法第二级网络模型训练过程的结果如图6~图8所示,图6~图8分别表示迁移学习VGG19、ResNet50和MobileNetV2模型训练过程在训练集和验证集上的损失曲线和准确率曲线。

图6 迁移学习VGG19模型训练过程损失/准确率曲线

图7 迁移学习ResNet50模型训练过程损失/准确率曲线

图8 迁移学习MobileNetV2模型训练过程损失/准确率曲线
迁移学习的VGG19模型深度有24层,参数达到了20.03 M(20029514)。训练到第25轮时提前终止训练,在训练集上的损失和准确率分别达到1.4691和99.22%,在验证集上的损失和准确率分别达到1.4812和98.78%。
迁移学习的ResNet50模型深度有168层,参数达到了23.61 M(23608202)。训练到第19轮时提前终止训练,在训练集上的损失和准确率分别达到1.5167和94.44%,在验证集上的损失和准确率分别达到1.4969和96.67%。
迁移学习的MobileNetV2模型深度有162层,参数量为2.26 M(2257984)。训练到第43轮时提前终止训练,在训练集上的损失和准确率分别达到1.4721和98.90%,在验证集上的损失和准确率分别达到1.4726和98.89%。
4.3 测试结果
利用测试集对模型的识别效果进行测试。第一级网络(SSD网络)输出结果见图9。为了评估本文提出的级联卷积神经网络框架与单级卷积神经网络的识别效果差异,设计了3组对比实验,并得到了不同模型在驾驶员行为数据集上的测试结果。实验1、实验2、实验3依次选取迁移学习的VGG19、ResNet50、MobileNetV2模型与本文提出的模型作为对比,在State Farm数据集上的测试结果见表6。

图9 SSD网络预测效果
如表6所示,单模型VGG19、ResNet50、MobileNetV2在驾驶员行为数据集上测试的平均准确率分别为85.68%、86.91%、89.38%。本文提出的级联网络模型SSD+VGG19、SSD+ResNet50、SSD+MobileNetV2在同一数据集上的平均准确率分别为92.93%、92.97%、93.63%,显然,平均识别准确率总体提升了4~7个百分点。实验结果表明,本文提出的基于级联卷积神经网络的驾驶员分心行为识别检测框架相比于只利用经过迁移学习权重微调的单级卷积神经网络模型的效果更好,并且可以实现9种驾驶员分心行为的精确检测。

表6 网络模型识别效果对比 单位: %
5 结束语
分心行为对道路交通的安全有显著影响,而驾驶员的知觉行为控制是导致各类分心行为发生的主要因素。由于智能电话、导航系统及车载多媒体系统的普及及其功能的日益丰富,诱发驾驶员分心行为的因素越来越多。通过精确的驾驶员行为识别,可以有效降低道路交通事故发生率。为提高识别精度,本文提出了一种去除冗余信息干扰且能同时精确识别多种驾驶分心行为的级联架构。在卷积神经网络单模型前先利用SSD目标检测算法对原始图像进行处理,从背景中提取出驾驶员身体区域,去除背景中的冗余信息。实验结果表明,在行为识别卷积神经网络模型之前引入SSD网络,相较于用原始图像训练的单模型,平均识别准确率总体提升了4~7个百分点,表明了采用级联架构的优越性。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
汽车实用技术(2022年7期)2022-04-20
汽车实用技术(2022年4期)2022-03-07
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
